Saya akan melanjutkan analisis yang tidak tergesa-gesa tentang implementasi tipe dasar dalam CPython,
kamus dan
bilangan bulat sebelumnya dipertimbangkan. Mereka yang berpikir bahwa tidak ada yang menarik dan licik dalam penerapannya didorong untuk bergabung dengan artikel ini. Mereka yang sudah membacanya tahu bahwa CPython memiliki banyak fitur menarik dan fitur implementasi. Mereka dapat bermanfaat untuk diketahui saat menulis skrip Anda sendiri, atau sebagai panduan untuk solusi arsitektur dan algoritmik. String tidak terkecuali di sini.
Mari kita mulai dengan penyimpangan singkat ke dalam sejarah. Python muncul pada 1990-91. Awalnya, ketika mengembangkan basis encoding di python, ada satu byte, ascii tua yang bagus. Tetapi, pada waktu yang hampir bersamaan (sesaat kemudian), umat manusia sudah lelah berurusan dengan “kebun binatang” penyandian, dan pada tahun 1991 standar Unicode diusulkan. Namun, pertama kali juga, itu tidak berhasil. Pengenalan pengkodean dua byte dimulai, tetapi segera menjadi jelas bahwa dua byte tidak akan cukup untuk semua orang, pengodean 4 byte diusulkan. Sayangnya, mengalokasikan 4 byte untuk setiap karakter tampak seperti pemborosan ruang disk dan memori, terutama di negara-negara di mana satu byte ascii sudah cukup sebelumnya. Beberapa kruk digergaji menjadi pengodean 2-byte untuk mendukung lebih banyak karakter, dan semua ini mulai menyerupai situasi sebelumnya dengan “kebun binatang” penyandian.
Tetapi pada tahun 1993 utf-8 diperkenalkan. Yang merupakan kompromi: ascii adalah himpunan bagian yang valid dari utf-8, semua karakter lain memperluasnya, namun, untuk mendukung kemungkinan ini, saya harus berpisah dengan panjang tetap masing-masing karakter. Tetapi dialah yang ditakdirkan untuk
memerintah semua orang untuk menjadi Unicode, yaitu, satu pengkodean didukung oleh sebagian besar program di mana sebagian besar file disimpan. Ini terutama dipengaruhi oleh perkembangan Internet, karena halaman web biasanya digunakan hanya utf-8.
Dukungan untuk pengkodean ini secara bertahap diperkenalkan ke bahasa pemrograman yang, seperti python, dikembangkan sebelum utf-8, dan oleh karena itu digunakan pengkodean lainnya. Ada
PEP dengan angka 100 bagus yang membahas dukungan Unicode. Dan dalam
PEP-0263 menjadi mungkin untuk mendeklarasikan penyandian file sumber. Pengodean masih merupakan pengkodean dasar, awalan `u` digunakan untuk menyatakan string unicode, bekerja dengan mereka masih tidak nyaman dan cukup alami. Tetapi ada kesempatan untuk menciptakan bid'ah berikut:
class 비빔밥: _ = 2 א = 비빔밥() print(א)
Pada 3 Desember 2008, sebuah peristiwa bersejarah terjadi untuk seluruh komunitas python (dan mengingat betapa luasnya bahasa ini telah menyebar sekarang, lalu, mungkin, untuk seluruh dunia) - python 3. dirilis. Diputuskan untuk mengakhiri masalah sekali dan untuk semua karena banyak penyandian, dan karenanya Unicode telah menjadi basis penyandian. Tetapi kita ingat bahwa pengkodean itu rumit dan tidak berhasil pertama kali. Kali ini tidak berhasil.
Kelemahan utama utf-8 adalah bahwa panjang karakter tidak tetap, yang mengarah pada fakta bahwa operasi sederhana seperti mengakses indeks memiliki kompleksitas O (N), karena offset elemen tidak diketahui sebelumnya, selain itu, mengetahui ukuran buffer, dialokasikan untuk menyimpan string, Anda tidak dapat menghitung panjangnya dalam karakter.
Untuk menghindari semua masalah ini dalam python, diputuskan untuk menggunakan pengkodean 2 dan 4 byte (tergantung pada platform). Penanganan indeks disederhanakan - hanya perlu mengalikan indeks dengan 2 atau 4. Namun, ini memerlukan masalah:
- Setiap platform memiliki encoding sendiri, yang dapat menyebabkan masalah dengan portabilitas kode
- Peningkatan konsumsi memori dan / atau masalah penyandian untuk karakter rumit yang tidak cocok menjadi dua byte
Solusi untuk masalah ini diusulkan dalam
PEP-393 , dan kami akan membicarakannya.
Diputuskan untuk meninggalkan garis sebagai array karakter, untuk memfasilitasi akses dengan indeks dan operasi lainnya, namun, panjang karakter mulai bervariasi. Saat membuat string, interpreter memindai semua karakter dan mengalokasikan untuk setiap jumlah byte yang diperlukan untuk menyimpan yang "terbesar", yaitu, jika Anda mendeklarasikan string ascii, maka semua karakter akan menjadi byte tunggal, namun, jika Anda memutuskan untuk menambahkan satu karakter ke string dari Cyrillic, semua karakter sudah dua byte. Ada tiga opsi yang mungkin: 1, 2, dan 4 byte per karakter.
Jenis string (PyUnicodeObject) dideklarasikan
sebagai berikut :
typedef struct { PyCompactUnicodeObject _base; union { void *any; Py_UCS1 *latin1; Py_UCS2 *ucs2; Py_UCS4 *ucs4; } data; } PyUnicodeObject;
Pada gilirannya, PyCompactUnicodeObject mewakili
struktur berikut (disediakan dengan beberapa penyederhanaan dan komentar saya):
typedef struct { PyASCIIObject _base; Py_ssize_t utf8_length; char *utf8; Py_ssize_t wstr_length; } PyCompactUnicodeObject; typedef struct { PyObject_HEAD Py_ssize_t length; Py_hash_t hash; struct { unsigned int interned:2; unsigned int kind:3; unsigned int compact:1; unsigned int ascii:1; unsigned int ready:1; unsigned int :24; } state; wchar_t *wstr; } PyASCIIObject;
Jadi, 4 representasi garis dimungkinkan:
- string lawas, siap
* structure = PyUnicodeObject structure * : !PyUnicode_IS_COMPACT(op) && kind != PyUnicode_WCHAR_KIND * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 0 * ready = 1 * data.any is not NULL * utf8 data.any utf8_length = length ascii = 1 * utf8_length = 0 utf8 is NULL * wstr with data.any wstr_length = length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_4)=4 * wstr_length = 0 wstr is NULL
- string lawas, belum siap
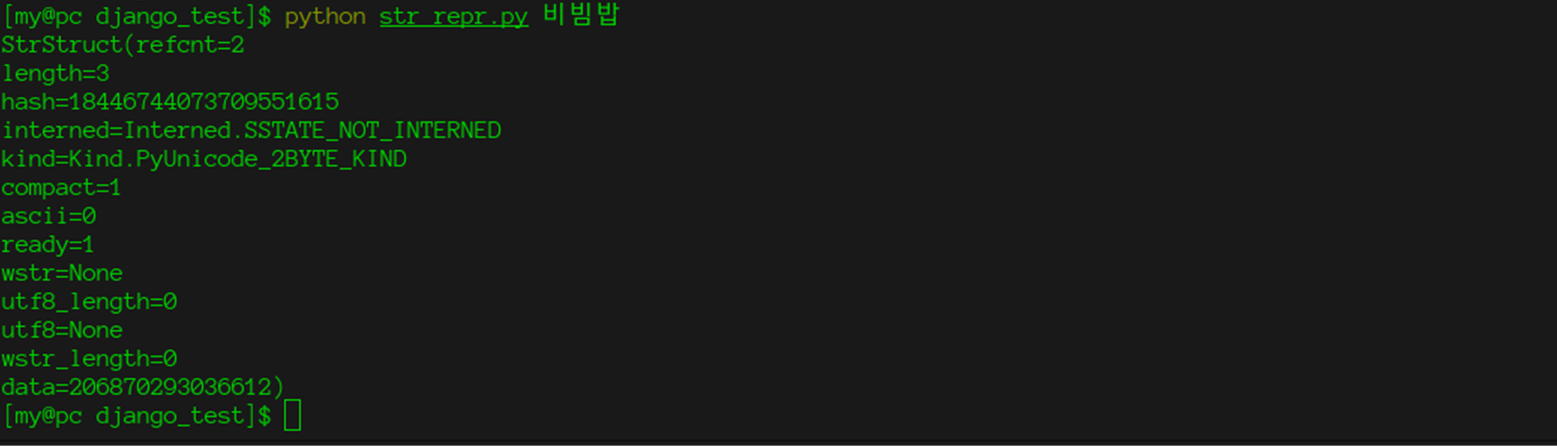
* structure = PyUnicodeObject * : kind == PyUnicode_WCHAR_KIND * length = 0 (use wstr_length) * hash = -1 * kind = PyUnicode_WCHAR_KIND * compact = 0 * ascii = 0 * ready = 0 * interned = SSTATE_NOT_INTERNED * wstr is not NULL * data.any is NULL * utf8 is NULL * utf8_length = 0
- ascii kompak
* structure = PyASCIIObject * : PyUnicode_IS_COMPACT_ASCII(op) * kind = PyUnicode_1BYTE_KIND * compact = 1 * ascii = 1 * ready = 1 * (length — utf8 wstr ) * (data ) * ( ascii utf8 string data)
- padat
* structure = PyCompactUnicodeObject * : PyUnicode_IS_COMPACT(op) && !PyUnicode_IS_ASCII(op) * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 1 * ready = 1 * ascii = 0 * utf8 data * utf8_length = 0 utf8 is NULL * wstr data wstr_length=length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_t)=4 * wstr_length = 0 wstr is NULL * (data )
Perlu dicatat bahwa python 3 juga mendukung sintaksis untuk mendeklarasikan string unicode melalui awalan `u`.
>>> b = u"" >>> b ''
Fitur ini ditambahkan untuk memfasilitasi kode porting dari versi kedua ke yang ketiga dalam
PEP-414 hanya dalam Februari 2012, izinkan saya mengingatkan Anda bahwa python 3 dirilis pada Desember 2008, tetapi tidak ada yang terburu-buru dengan transisi.
Berbekal pengetahuan ini dan modul ctypes standar, kita dapat mengakses bidang internal string.
import ctypes import enum import sys class Interned(enum.Enum):
Dan bahkan "mematahkan" penerjemah, seperti yang Anda lakukan pada bagian
sebelumnya .
PENOLAKAN: Kode berikut diberikan sebagaimana adanya, penulis tidak bertanggung jawab dan tidak dapat menjamin keadaan penerjemah, serta kesehatan mental Anda dan kolega Anda, setelah menjalankan kode ini. Kode ini diuji pada cpython versi 3.7 dan, sayangnya, tidak berfungsi dengan string ascii.
Untuk melakukan ini, ubah kode yang dijelaskan di atas menjadi:
def make_some_magic(str1, str2): s1 = StrStruct.from_address(id(str1)) s2 = StrStruct.from_address(id(str2)) s2.data = s1.data if __name__ == '__main__': string = "비빔밥" string2 = "háč" print(string == string2)
Contoh-contoh ini menggunakan interpolasi string yang ditambahkan dalam
python 3.6 . Python tidak segera datang ke metode ini menghasilkan string:% sintaks, format, sesuatu yang
mirip dicoba (deskripsi yang lebih rinci dengan contoh-contoh dapat ditemukan di
sini ).
Mungkin perubahan ini untuk waktunya (sebelum python 3.8 dengan operator `: =`) adalah yang paling kontroversial. Diskusi (dan kecaman) dilakukan baik pada
reddit dan bahkan dalam bentuk
PEP . Gagasan perbaikan / koreksi diungkapkan dalam bentuk menambahkan
garis-i yang dapat digunakan pengguna untuk menulis parser, untuk kontrol yang lebih baik dan untuk menghindari injeksi SQL dan masalah lainnya. Namun, perubahan ini ditunda, sehingga orang terbiasa dengan f-line dan mengidentifikasi masalah, jika ada.
F-lines memiliki satu kekhasan (drawback): Anda tidak dapat menentukan karakter khusus dengan garis miring di dalamnya, misalnya, '\ n' '\ t'. Namun, ini dapat dengan mudah dielakkan dengan mendeklarasikan baris terpisah yang berisi karakter khusus dan meneruskannya ke f-line, yang dilakukan pada contoh di atas, tetapi Anda dapat menggunakan tanda kurung bersarang.
>>> number = 2 >>> precision = 3 >>> f"{number:.{precision}f}" 2.000
Seperti yang Anda lihat, string menyimpan hash mereka, ada
saran untuk menggunakan nilai ini untuk membandingkan string, berdasarkan aturan sederhana: jika string adalah sama, maka mereka memiliki hash yang sama, dan itu berarti bahwa string dengan hash yang berbeda tidak sama. Namun, itu tetap tidak terpenuhi.
Ketika membandingkan dua string, diperiksa apakah pointer ke string merujuk ke alamat yang sama, jika tidak, maka perbandingan karakter-per-karakter atau memcmp dimulai dalam kasus di mana hal ini diizinkan.
int PyUnicode_Compare(PyObject *left, PyObject *right) { if (PyUnicode_Check(left) && PyUnicode_Check(right)) { if (PyUnicode_READY(left) == -1 || PyUnicode_READY(right) == -1) return -1; if (left == right) return 0; return unicode_compare(left, right);
Namun, nilai hash secara tidak langsung mempengaruhi perbandingan. Faktanya adalah bahwa di cpython, string diinternir, yaitu disimpan dalam satu kamus. Ini tidak benar untuk semua baris, semua konstanta, kunci kamus, bidang dan variabel, dan garis ascii dengan panjang kurang dari 20 diinternir.
if __name__ == '__main__': string = sys.argv[1] string2 = sys.argv[2] print(id(string) == id(string2))
$ python check_interned.py aa True $ python check_interned.py 비빔밥 비빔밥 False $ python check_interned.py aaaaaaaaaaaaaaaaaaaaaaaaaaaaa aaaaaaaaaaaaaaaaaaaaaaaaaaaaa False
Dan senar kosong umumnya singleton
static PyUnicodeObject * _PyUnicode_New(Py_ssize_t length) { PyUnicodeObject *unicode; size_t new_size; if (length == 0 && unicode_empty != NULL) { Py_INCREF(unicode_empty); return (PyUnicodeObject*)unicode_empty; } ... }
Seperti yang dapat kita lihat, cpython mampu membuat implementasi string yang efisien, tetapi pada saat yang sama. Dimungkinkan untuk mengurangi memori yang digunakan dan mempercepat operasi dalam beberapa kasus, berkat memcmp, fungsi memcpy, alih-alih operasi karakter demi karakter. Seperti yang Anda lihat, tipe string sama sekali tidak semudah diimplementasikan seperti yang terlihat pertama kali. Tetapi pengembang cpython telah cukup mendekati bisnis mereka dan oleh karena itu kita dapat menggunakannya dan bahkan tidak berpikir tentang apa yang ada di balik tudung.