 Apa?
Apa? Codec video adalah bagian dari perangkat lunak / perangkat keras yang mengompresi dan / atau mendekompresi video digital.
Untuk apa? Meskipun ada batasan tertentu dalam hal bandwidth,
dan dalam hal jumlah ruang penyimpanan, pasar membutuhkan video berkualitas tinggi yang semakin banyak. Ingat bagaimana di posting terakhir kami menghitung minimum yang diperlukan untuk 30 frame per detik, 24 bit per pixel, dengan resolusi 480x240? Menerima 82.944 Mbps tanpa kompresi. Kompresi adalah satu-satunya cara untuk mentransfer HD / FullHD / 4K ke layar TV dan Internet. Bagaimana ini dicapai? Sekarang kita akan mempertimbangkan secara singkat metode utama.

Terjemahan dibuat dengan dukungan Perangkat Lunak EDISON.
Kami terlibat dalam integrasi sistem pengawasan video , serta mengembangkan mikrotomograf .
Codec vs Container
Kesalahan pemula yang umum adalah mengacaukan codec video digital dan wadah video digital. Wadah adalah format tertentu. Pembungkus yang berisi metadata video (dan mungkin audio). Video terkompresi dapat dianggap sebagai muatan kontainer.
Biasanya, ekstensi file video menunjukkan jenis wadah. Sebagai contoh, file video.mp4 kemungkinan besar merupakan wadah
MPEG-4 Bagian 14 , dan file bernama video.mkv kemungkinan besar adalah
boneka Rusia. Untuk sepenuhnya percaya diri dalam format codec dan wadah, Anda dapat menggunakan
FFmpeg atau
MediaInfo .
Sedikit sejarah
Sebelum kita sampai ke
Bagaimana? , mari selami sedikit sejarah untuk mendapatkan pemahaman yang lebih baik tentang beberapa codec lama.
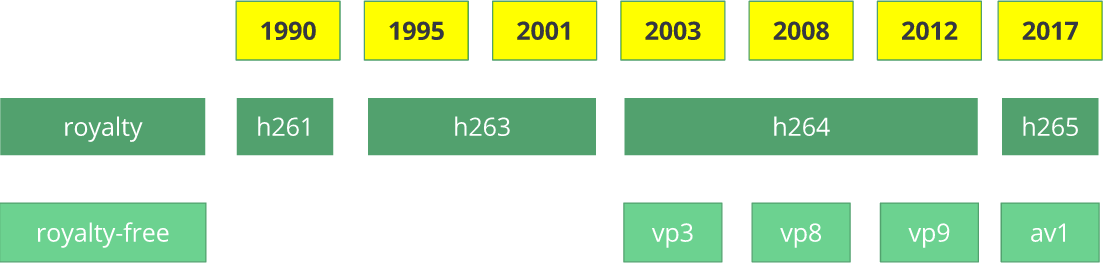
Codec video
H.261 muncul pada tahun 1990 (secara teknis - pada tahun 1988) dan diciptakan untuk bekerja dengan kecepatan transfer data 64 Kbps. Ini sudah menggunakan ide-ide seperti subsampling warna, blok makro, dll Pada tahun 1995, standar codec video
H.263 diterbitkan, yang dikembangkan hingga tahun 2001.
Pada tahun 2003, versi pertama
H.264 / AVC selesai. Pada tahun yang sama, TrueMotion merilis codec video gratisnya yang memampatkan video lossy yang disebut
VP3 . Pada 2008, Google membeli perusahaan ini, merilis
VP8 di tahun yang sama. Pada Desember 2012, Google merilis
VP9 , dan didukung sekitar ¾ pasar peramban (termasuk perangkat seluler).
AV1 adalah codec video open source baru gratis yang dikembangkan
oleh Open Media Alliance (
AOMedia ), yang mencakup perusahaan terkenal seperti Google, Mozilla, Microsoft, Amazon, Netflix, AMD, ARM, NVidia, Intel dan Cisco . Versi pertama dari codec 0.1.0 diterbitkan pada 7 April 2016.
Kelahiran AV1
Pada awal 2015, Google mengerjakan
VP10 , Xiph (milik Mozilla) mengerjakan
Daala , dan Cisco membuat codec video gratis bernama
Thor .
Kemudian
MPEG LA pertama kali mengumumkan batas tahunan untuk
HEVC (
H.265 ) dan biaya 8 kali lebih tinggi daripada untuk H.264, tetapi mereka segera mengubah aturan lagi:
tidak ada batasan tahunan,
biaya konten (0,5% dari pendapatan) dan
biaya unit sekitar 10 kali lebih tinggi daripada untuk H.264.
Open Media Alliance dibuat oleh perusahaan dari berbagai bidang: produsen peralatan (Intel, AMD, ARM, Nvidia, Cisco), penyedia konten (Google, Netflix, Amazon), pembuat browser (Google, Mozilla) dan lainnya.
Perusahaan memiliki tujuan yang sama - video codec tanpa royalti. Kemudian datang
AV1 dengan lisensi paten yang jauh lebih sederhana. Timothy B. Terriberry membuat presentasi yang memukau, yang menjadi sumber konsep AV1 saat ini dan model lisensinya.
Anda akan terkejut mengetahui bahwa Anda dapat menganalisis codec AV1 melalui browser (mereka yang tertarik dapat pergi ke
aomanalyzer.org ).

Codec universal
Mari kita menganalisis mekanisme dasar yang mendasari codec video universal. Sebagian besar konsep ini berguna dan digunakan dalam codec modern seperti
VP9 ,
AV1, dan
HEVC . Saya memperingatkan Anda bahwa banyak hal yang dijelaskan akan disederhanakan. Contoh dunia nyata kadang-kadang akan digunakan (seperti halnya H.264) untuk menunjukkan teknologi.
Langkah 1 - membelah gambar
Langkah pertama adalah membagi bingkai menjadi beberapa bagian, subbagian, dan lainnya.

Untuk apa? Ada banyak alasan. Ketika kita membagi gambar, kita dapat lebih akurat memprediksi vektor gerakan menggunakan bagian kecil untuk bagian bergerak kecil. Sedangkan untuk latar belakang statis, Anda dapat membatasi diri ke bagian yang lebih besar.
Biasanya, codec mengatur bagian-bagian ini menjadi beberapa bagian (atau fragmen), blok makro (atau blok-blok pohon pengkodean) dan banyak subbagian. Ukuran maksimum partisi ini bervariasi, HEVC menetapkan 64x64, sementara AVC menggunakan 16x16, dan subbagian dapat dibagi hingga 4x4.
Ingat jenis-jenis bingkai dari artikel terakhir ?! Hal yang sama dapat diterapkan pada blok, jadi, kita dapat memiliki fragmen I, blok B, blok makro P, dll.
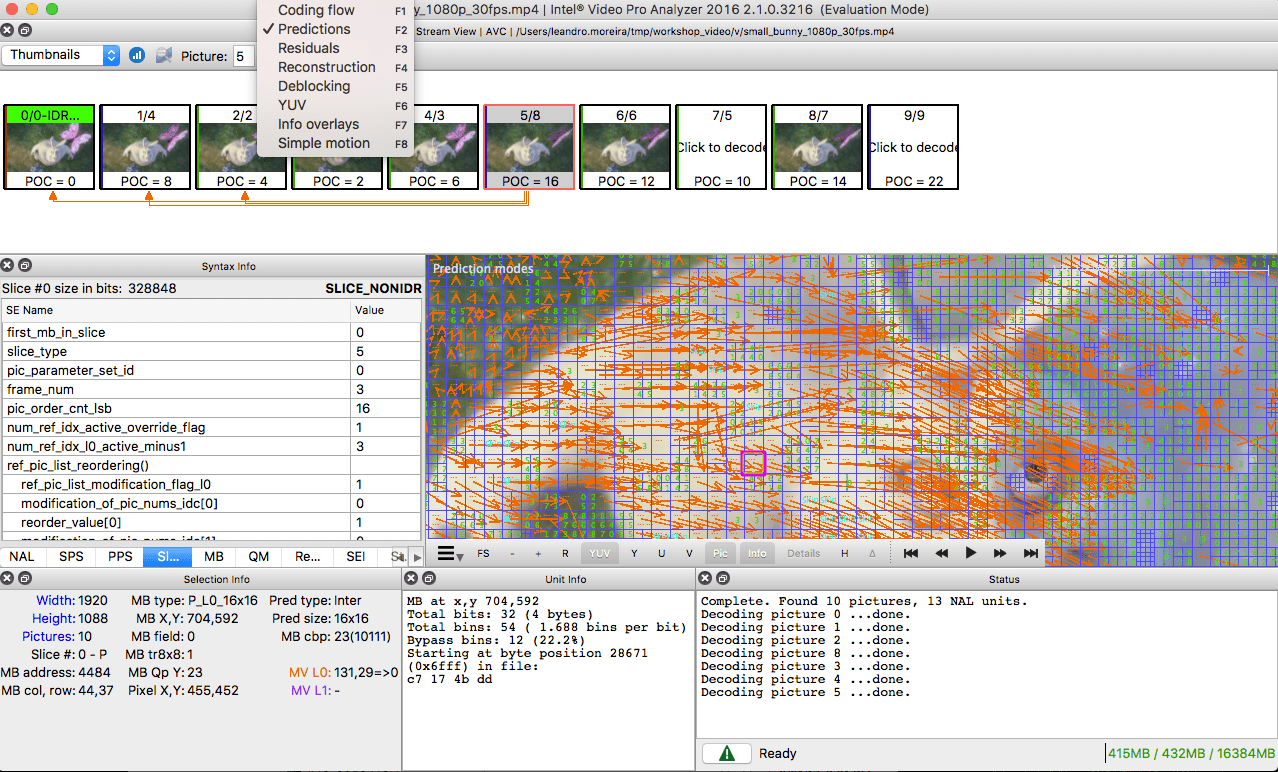
Bagi mereka yang ingin berlatih, lihat bagaimana gambar akan dibagi menjadi beberapa bagian dan subbagian. Untuk melakukan ini, Anda dapat menggunakan
Intel Video Pro Analyzer yang telah disebutkan di artikel sebelumnya (yang dibayar, tetapi dengan versi percobaan gratis, yang memiliki batas pada 10 frame pertama). Bagian-bagian
VP9 dianalisis di sini:

Langkah 2 - peramalan
Segera setelah kami memiliki bagian, kami dapat membuat perkiraan
astrologi pada mereka. Untuk
prediksi-ANT, perlu untuk memindahkan
vektor dan sisa
gerak , dan untuk prediksi INTRA,
arah ramalan dan sisanya ditransmisikan.
Langkah 3 - konversi
Setelah kami mendapatkan blok residu (bagian yang diprediksi → bagian yang sebenarnya), dimungkinkan untuk mengubahnya sedemikian rupa untuk mengetahui piksel mana yang dapat dibuang, sambil mempertahankan kualitas keseluruhan. Ada beberapa transformasi yang memberikan perilaku yang akurat.
Meskipun ada metode lain, mari kita pertimbangkan secara lebih terperinci
diskrit cosinus transform (
DCT - dari
diskrit cosinus transform ). Fitur utama DCT:
- Mengubah blok piksel menjadi blok koefisien frekuensi yang berukuran sama.
- Menyegel kekuatan, membantu menghilangkan redundansi spasial.
- Memberikan reversibilitas.
2 Februari 2017 Sintra R.J. (Cintra, RJ) dan Bayer F.M. (Bayer FM) menerbitkan artikel tentang konversi mirip DCT untuk kompresi gambar, hanya membutuhkan 14 tambahan.
Jangan khawatir jika Anda tidak mengerti manfaat dari setiap item. Sekarang, dengan contoh nyata, kami akan memverifikasi nilai sebenarnya.
Mari kita ambil blok 8x8 piksel seperti ini:
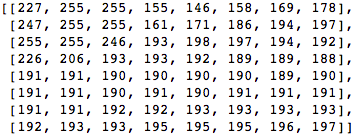
Blok ini dirender ke dalam gambar berikut 8 x 8 piksel:
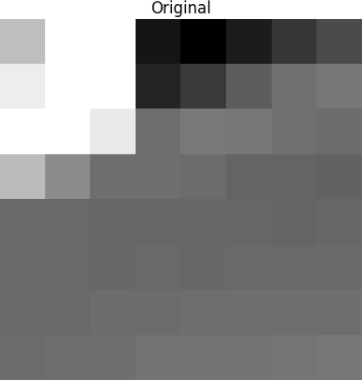
Terapkan DCT ke blok piksel ini dan dapatkan blok koefisien ukuran 8x8:
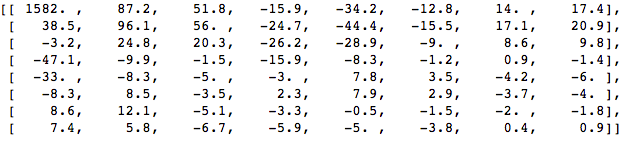
Dan jika kita membuat blok koefisien ini, kita mendapatkan gambar berikut:
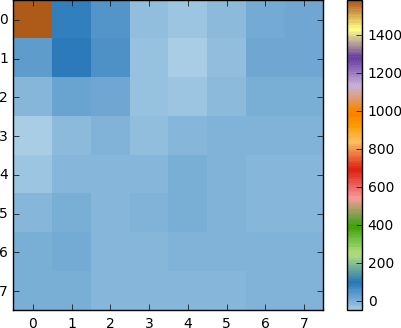
Seperti yang Anda lihat, ini tidak seperti gambar aslinya. Anda mungkin memperhatikan bahwa koefisien pertama sangat berbeda dari yang lainnya. Koefisien pertama ini dikenal sebagai koefisien DC yang mewakili semua sampel dalam array input, sesuatu yang mirip dengan nilai rata-rata.
Blok koefisien ini memiliki sifat yang menarik: ia memisahkan komponen frekuensi tinggi dari yang frekuensi rendah.
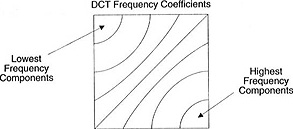
Pada gambar, sebagian besar daya terkonsentrasi pada frekuensi yang lebih rendah, oleh karena itu, jika Anda mengubah gambar menjadi komponen frekuensinya dan membuang koefisien frekuensi yang lebih tinggi, Anda dapat mengurangi jumlah data yang diperlukan untuk menggambarkan gambar tanpa mengorbankan kualitas gambar terlalu banyak.
Frekuensi berarti seberapa cepat sinyal berubah.
Mari kita coba menerapkan pengetahuan yang diperoleh dalam contoh uji dengan mengubah gambar asli ke frekuensi (blok koefisien) menggunakan DCT, dan kemudian membuang beberapa koefisien yang paling tidak penting.
Pertama, konversikan ke domain frekuensi.
Selanjutnya, kami membuang sebagian (67%) dari koefisien, terutama sisi kanan bawah.
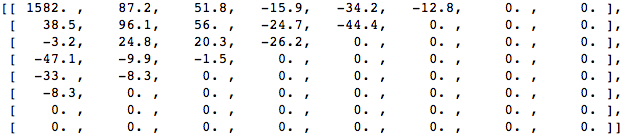
Akhirnya, kami mengembalikan gambar dari blok koefisien yang dibuang ini (ingat, itu harus dapat dibalik) dan dibandingkan dengan aslinya.
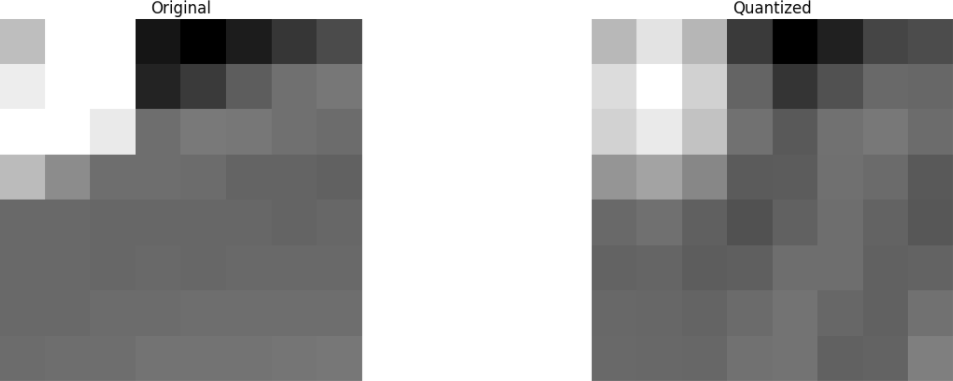
Kita melihat bahwa itu menyerupai gambar asli, tetapi ada banyak perbedaan dari aslinya. Kami melempar 67,1875% dan masih mendapatkan sesuatu yang menyerupai sumber aslinya. Anda dapat lebih sengaja membuang koefisien untuk mendapatkan gambar dengan kualitas yang lebih baik, tetapi ini adalah topik berikutnya.
Setiap koefisien dihasilkan menggunakan semua piksel.
Penting: setiap koefisien tidak langsung ditampilkan pada satu piksel, tetapi merupakan jumlah tertimbang dari semua piksel. Grafik yang luar biasa ini menunjukkan bagaimana koefisien pertama dan kedua dihitung menggunakan bobot yang unik untuk setiap indeks.
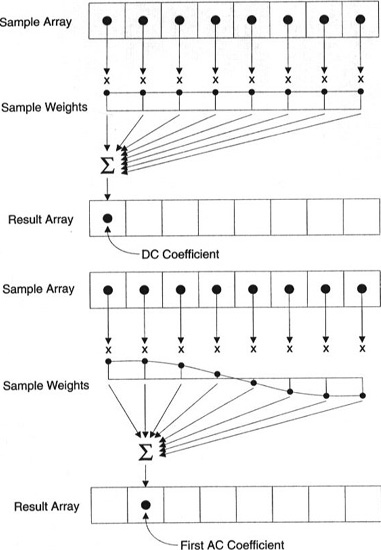
Anda juga dapat mencoba memvisualisasikan DCT dengan melihat pencitraan sederhana berdasarkan itu. Misalnya, di sini adalah simbol A yang dihasilkan menggunakan masing-masing koefisien bobot:

Langkah 4 - kuantisasi
Setelah kami membuang beberapa koefisien pada langkah sebelumnya, pada langkah terakhir (transformasi), kami menghasilkan bentuk kuantisasi khusus. Pada titik ini, dibiarkan kehilangan informasi. Atau, lebih sederhana, kami akan menghitung koefisien untuk mencapai kompresi.
Bagaimana blok koefisien dapat dikuantifikasi? Salah satu metode paling sederhana adalah kuantisasi seragam, ketika kita mengambil blok, membaginya dengan satu nilai (dengan 10) dan melengkapi apa yang terjadi.
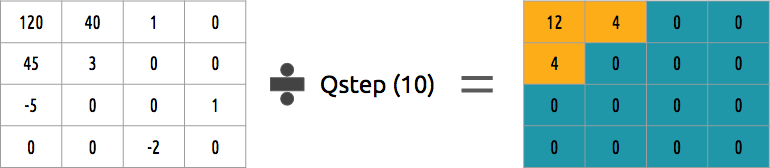
Bisakah kita membalikkan blok koefisien ini? Ya, kami bisa, dengan mengalikan dengan nilai yang sama dengan yang kami bagi.
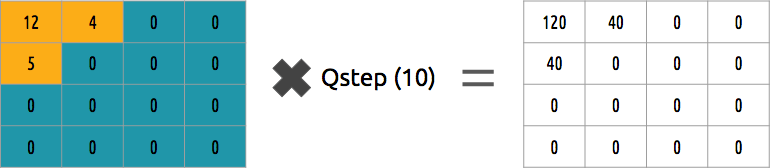
Pendekatan ini bukan yang terbaik, karena tidak memperhitungkan pentingnya setiap koefisien. Seseorang dapat menggunakan matriks kuantizer alih-alih nilai tunggal, dan matriks ini dapat menggunakan properti DCT, menghitung sebagian besar kanan bawah dan minoritas kiri atas.
5 langkah - pengkodean entropi
Setelah kami menghitung data (blok gambar, fragmen, bingkai), kami masih bisa memampatkannya tanpa kehilangan. Ada banyak cara algoritmik untuk mengompres data. Kita akan secara singkat berkenalan dengan beberapa dari mereka, untuk pemahaman yang lebih dalam, Anda dapat membaca buku "
Memahami Kompresi: Kompresi Data untuk Pengembang Modern " ("
Memahami Kompresi: Kompresi Data untuk Pengembang Modern ").
Pengkodean Video dengan VLC
Misalkan kita memiliki aliran karakter:
a ,
e ,
r dan
t . Probabilitas (mulai dari 0 hingga 1) dari seberapa sering setiap simbol muncul dalam aliran disajikan dalam tabel ini.
Kami dapat menetapkan kode biner yang unik (lebih disukai yang kecil) ke kode yang paling memungkinkan, dan kode yang lebih besar lebih kecil kemungkinannya.
Kami mengompres aliran, dengan asumsi bahwa pada akhirnya kami menghabiskan 8 bit untuk setiap karakter. Tanpa kompresi pada karakter, 24 bit akan dibutuhkan. Jika setiap karakter diganti dengan kodenya, maka kita mendapat penghematan!
Langkah pertama adalah menyandikan karakter
e , yaitu 10, dan karakter kedua adalah
a , yang ditambahkan (tidak secara matematis): [10] [0], dan akhirnya,
t karakter ketiga, yang membuat bitstream terkompresi akhir kami sama dengan [10] [0] [1110] atau
1001110 , yang hanya membutuhkan 7 bit (3,4 kali lebih sedikit ruang daripada yang asli).
Harap perhatikan bahwa setiap kode harus berupa kode unik dengan awalan.
Algoritma Huffman akan membantu menemukan angka-angka ini. Meskipun metode ini bukan tanpa cacat, ada codec video yang masih menawarkan metode algoritmik ini untuk kompresi.
Encoder dan decoder harus memiliki akses ke tabel simbol dengan kode binernya. Oleh karena itu, perlu juga mengirim tabel dalam input.
Pengkodean aritmatika
Misalkan kita memiliki aliran karakter:
a ,
e ,
r ,
s dan
t , dan probabilitasnya diwakili oleh tabel ini.
Dengan tabel ini, kami membuat rentang yang berisi semua karakter yang mungkin, diurutkan berdasarkan jumlah terbesar.

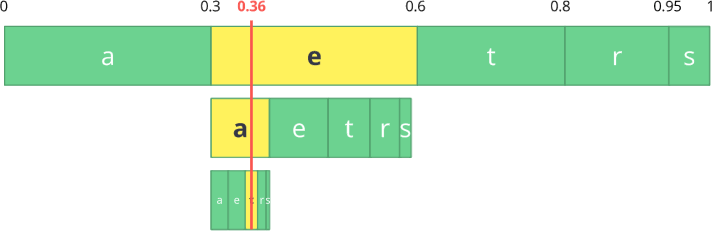
Sekarang mari kita kodekan aliran tiga karakter:
makan .
Pertama, pilih karakter pertama
e , yang berada dalam sub-rentang 0,3 hingga 0,6 (tidak termasuk). Kami mengambil subrange ini dan membaginya lagi dalam proporsi yang sama seperti sebelumnya, tetapi sudah untuk rentang baru ini.

Mari kita lanjutkan untuk mengkodekan aliran
makan kita. Sekarang kita ambil simbol kedua
a , yang ada di subrange baru dari 0,3 ke 0,39, dan kemudian kita mengambil simbol
t terakhir kita dan, mengulangi proses yang sama lagi, kita mendapatkan subrange terakhir dari 0,354 ke 0,372.
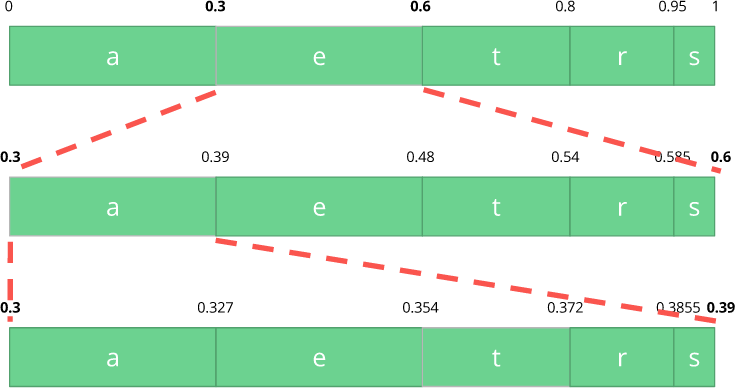
Kami hanya perlu memilih nomor di sub-rentang terakhir dari 0,354 hingga 0,372. Mari kita pilih 0,36 (tetapi Anda dapat memilih nomor lain dalam sub-rentang ini). Hanya dengan nomor ini kita dapat mengembalikan aliran asli kita. Seolah-olah kami sedang menggambar garis dalam rentang untuk menyandikan aliran kami.
Operasi sebaliknya (yaitu,
decoding ) sama mudahnya: dengan angka kami 0,36 dan rentang awal kami, kami dapat memulai proses yang sama. Tapi sekarang, menggunakan nomor ini, kami mengungkapkan aliran yang disandikan menggunakan nomor ini.
Dengan rentang pertama, kami perhatikan bahwa nomor kami sesuai dengan sepotong, oleh karena itu, ini adalah karakter pertama kami. Sekarang lagi, kami membagikan subband ini, melakukan proses yang sama seperti sebelumnya. Di sini Anda dapat melihat bahwa 0,36 sesuai dengan karakter
a , dan setelah mengulangi prosesnya, kita sampai pada karakter terakhir
t (membentuk stream
makan asli yang disandikan).
Baik encoder dan decoder harus memiliki tabel probabilitas simbol, oleh karena itu, perlu untuk mengirimkannya dalam data input.
Cukup elegan, bukan? Seseorang yang datang dengan solusi ini sangat pintar. Beberapa codec video menggunakan teknik ini (atau, dalam hal apa pun, menawarkannya sebagai opsi).
Idenya adalah untuk memampatkan bitstream terkuantisasi lossless. Tentunya dalam artikel ini tidak ada detail, alasan, kompromi, dll. Tetapi Anda, jika Anda seorang pengembang, harus tahu lebih banyak. Codec baru mencoba menggunakan algoritma pengkodean entropi yang berbeda, seperti
ANS .
6 langkah - format bitstream
Setelah melakukan semua ini, tetap membongkar frame terkompresi dalam konteks langkah-langkah yang diambil. Dekoder harus secara eksplisit diinformasikan tentang keputusan yang dibuat oleh pembuat sandi. Dekoder harus dilengkapi dengan semua informasi yang diperlukan: kedalaman bit, ruang warna, resolusi, informasi perkiraan (vektor gerakan, prediksi-directional INTER), profil, level, laju bingkai, jenis bingkai, nomor bingkai, dan banyak lagi.
Kami akan melihat bitstream
H.264 . Langkah pertama kami adalah membuat bitstream H.264 minimum (FFmpeg secara default menambahkan semua parameter pengkodean, seperti
SEI NAL - sedikit lebih jauh kita akan mengetahui apa itu). Kita dapat melakukan ini menggunakan repositori dan FFmpeg kita sendiri.
./s/ffmpeg -i /files/i/minimal.png -pix_fmt yuv420p /files/v/minimal_yuv420.h264Perintah ini akan menghasilkan bitstream
H.264 mentah dengan satu frame, resolusi 64x64, dengan ruang warna
YUV420 . Gambar berikut digunakan sebagai bingkai.

H.264 Bitstream
Standar
AVC (
H.264 ) mendefinisikan bahwa informasi akan dikirim dalam bingkai makro (dalam pengertian jaringan) yang disebut
NAL (ini adalah tingkat abstraksi jaringan). Tujuan utama NAL adalah menyediakan presentasi video yang "ramah jaringan". Standar ini harus bekerja pada TV (berdasarkan aliran), di Internet (berdasarkan paket).

Ada penanda sinkronisasi untuk menentukan batas elemen NAL. Setiap penanda sinkronisasi berisi nilai
0x00 0x00 0x01, dengan pengecualian yang paling pertama, yaitu
0x00 0x00 0x00 0x01. Jika kita menjalankan
hexdump untuk bitstream H.264 yang dihasilkan, kami akan mengidentifikasi setidaknya tiga pola NAL di awal file.
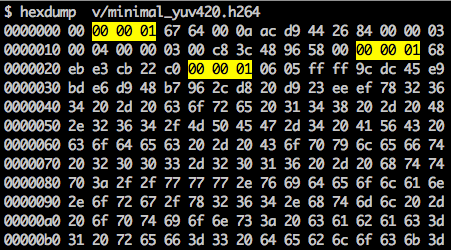
Seperti yang dinyatakan, decoder harus tahu tidak hanya data gambar, tetapi juga detail video, bingkai, warna, parameter yang digunakan, dan banyak lagi. Byte pertama dari setiap NAL mendefinisikan kategori dan jenisnya.
Biasanya bitstream NAL pertama adalah
SPS . Jenis NAL ini bertanggung jawab untuk melaporkan variabel penyandian umum, seperti profil, level, resolusi, dan banyak lagi.
Jika kita melewatkan token sinkronisasi pertama, kita dapat mendekode byte pertama untuk mencari tahu apa jenis NAL yang pertama.
Misalnya, byte pertama setelah penanda sinkronisasi adalah
01100111 , di mana bit pertama (
0 ) berada di bidang f
orbidden_zero_bit . 2 bit berikutnya (
11 ) memberi tahu kita bidang
nal_ref_idc, yang menunjukkan apakah NAL ini adalah bidang referensi atau tidak. Dan sisa 5 bit (
00111 ) memberi tahu kita bidang
nal_unit_type, dalam hal ini adalah blok NAL SPS (
7 ).
Byte kedua (
biner =
01100100 ,
hex =
0x64 ,
dec =
100 ) di SPS NAL adalah bidang
profile_idc, yang menunjukkan profil yang digunakan pembuat enkode. Dalam kasus ini, profil tinggi terbatas digunakan (mis. Profil tinggi tanpa dukungan untuk segmen-B dua arah).

Jika kita membiasakan diri dengan spesifikasi bitstream
H.264 untuk SPS NAL, kita akan menemukan banyak nilai untuk nama parameter, kategori, dan deskripsi. Misalnya, mari kita lihat bidang
pic_width_in_mbs_minus_1 dan
pic_height_in_map_units_minus_1 .
Jika kami melakukan beberapa operasi matematika dengan nilai-nilai bidang ini, maka kami mendapatkan izin. Anda dapat membayangkan
1920 x 1080 menggunakan
pic_width_in_mbs_minus_1 dengan nilai
119 ((119 + 1) * macroblock_size = 120 * 16 = 1920) . Sekali lagi, menghemat ruang, alih-alih mengkodekan 1920 mereka melakukannya dengan 119.
Jika kita terus memeriksa video yang kita buat dalam bentuk biner (misalnya:
xxd -b -c 11 v / minimal_yuv420.h264 ), maka kita dapat pergi ke NAL terakhir, yang merupakan bingkai itu sendiri.

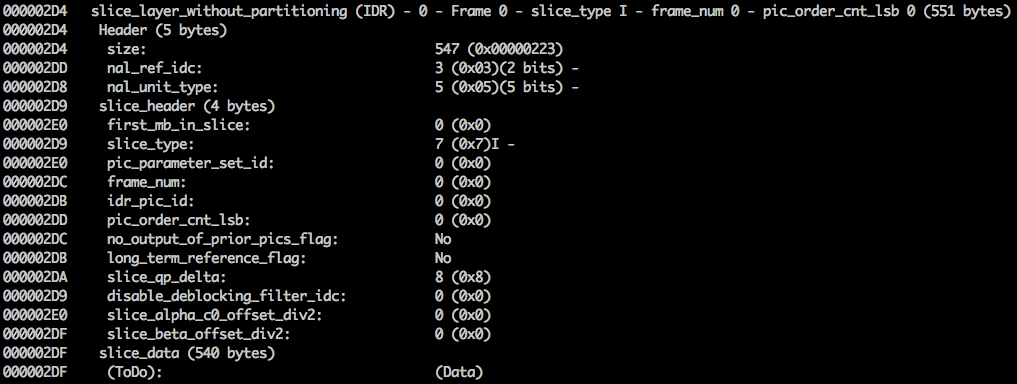
Di sini kita melihat nilai 6 byte pertama:
01100101 10001000 10000100 00000000 00100001 11111111 . Karena diketahui bahwa byte pertama menunjukkan jenis NAL, dalam hal ini (
00101 ) ini adalah fragmen IDR (5), dan kemudian dimungkinkan untuk mempelajarinya lebih lanjut:

Dengan menggunakan informasi spesifikasi, dimungkinkan untuk mendekode jenis fragmen (
slice_type ) dan nomor bingkai (
frame_num ) di antara bidang-bidang penting lainnya.
Untuk mendapatkan nilai beberapa bidang (
ue (
v ),
me (
v ),
se (
v ) atau
te (
v )), kita perlu mendekode fragmen menggunakan dekoder khusus berdasarkan
kode Golomb eksponensial . Metode ini sangat efektif untuk mengkodekan nilai variabel, terutama ketika ada banyak nilai default.
Nilai
slice_type dan
frame_num dari video ini adalah 7 (fragmen-I) dan 0 (frame pertama).
Bitstream dapat dianggap sebagai protokol. Jika Anda ingin tahu lebih banyak tentang bitstream, Anda harus merujuk pada spesifikasi
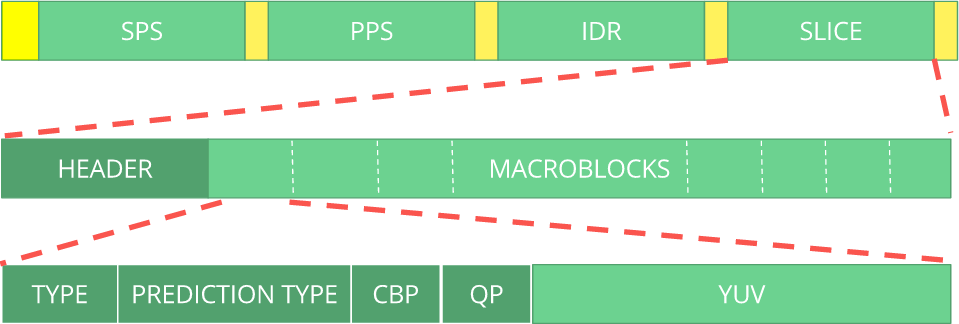
ITU H.264 . Berikut ini adalah makro yang menunjukkan di mana data gambar berada (
YUV dalam bentuk terkompresi).
Anda dapat menjelajahi bitstream lainnya, seperti
VP9 ,
H.265 (
HEVC ), atau bahkan bitstream
AV1 baru terbaik kami. Apakah mereka semua sama? Tidak, tetapi berurusan dengan setidaknya satu lebih mudah untuk memahami sisanya.
Ingin berlatih? Jelajahi H.264 Bitstream
Anda dapat menghasilkan video single-frame dan menggunakan MediaInfo untuk memeriksa bitstream H.264 . Bahkan, tidak ada yang mencegah Anda dari melihat kode sumber yang menganalisis bitstream H.264 ( AVC ).
Untuk latihan, Anda dapat menggunakan Intel Video Pro Analyzer (Saya sudah mengatakan bahwa program ini berbayar, tetapi apakah ada versi uji coba gratis dengan batas 10 bingkai?).
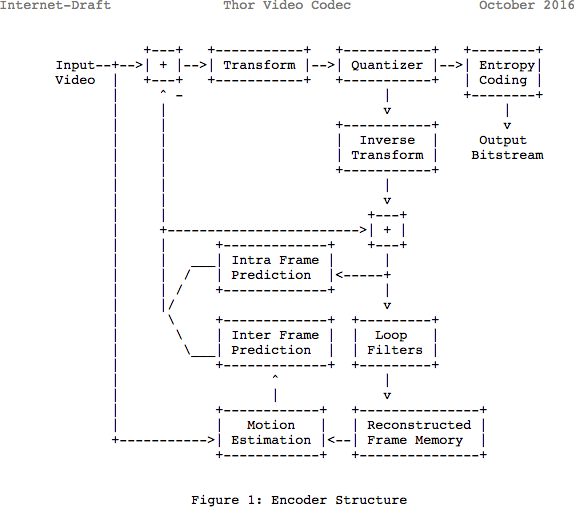
Ulasan
Perhatikan bahwa banyak codec modern menggunakan model yang sama dengan yang baru mereka pelajari. Di sini, mari kita lihat diagram blok codec video
Thor . Ini berisi semua langkah yang telah kami ambil. Inti dari posting ini adalah bagi Anda untuk setidaknya lebih memahami inovasi dan dokumentasi di bidang ini.
Sebelumnya, diperkirakan 139 GB ruang disk akan diperlukan untuk menyimpan file video yang tahan satu jam dengan kualitas 720p dan 30 fps. Jika Anda menggunakan metode yang dibahas dalam artikel ini (prakiraan antar-bingkai dan internal, konversi, kuantisasi, pengkodean entropi, dll.), Maka Anda dapat mencapainya (dengan asumsi bahwa kami menghabiskan 0,031 bit per piksel), video memiliki kualitas yang cukup memuaskan, yang memakan waktu hanya 367,82 MB, bukan memori 139 GB.
Bagaimana H.265 mencapai rasio kompresi yang lebih baik daripada H.264?
Sekarang Anda tahu lebih banyak tentang cara kerja codec, lebih mudah untuk memahami bagaimana codec baru dapat memberikan resolusi lebih tinggi dengan bit lebih sedikit.
Saat membandingkan
AVC dan
HEVC , jangan lupa bahwa ini hampir selalu merupakan pilihan antara beban CPU dan rasio kompresi yang lebih tinggi.
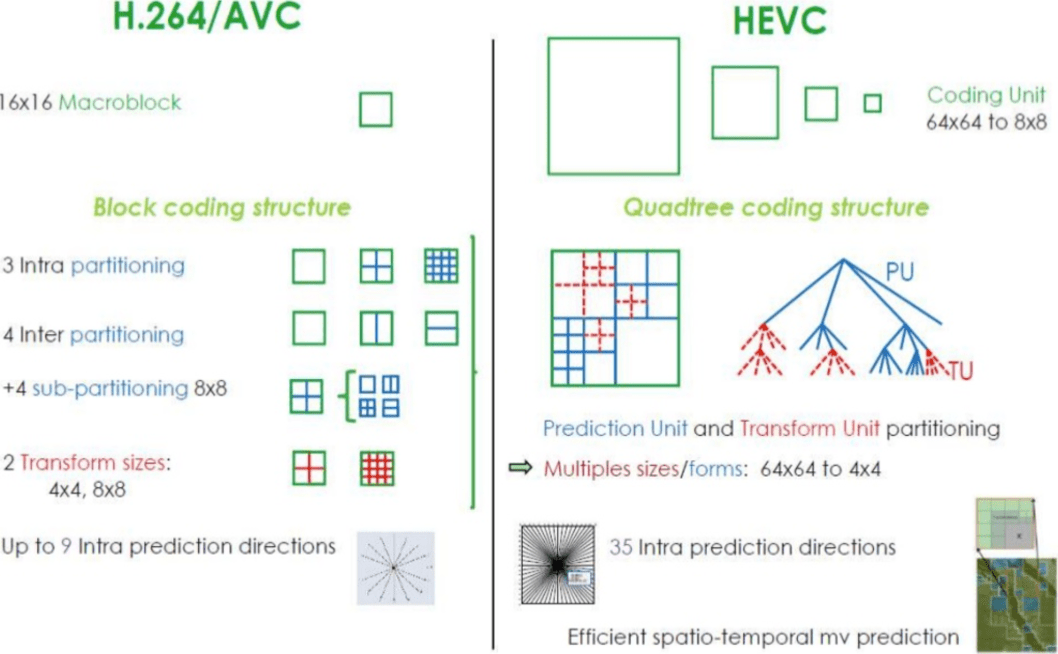
HEVC memiliki lebih banyak opsi untuk bagian (dan subbagian) daripada
AVC , lebih banyak arahan untuk perkiraan internal, peningkatan kode entropi, dan banyak lagi. Semua peningkatan ini membuat
H.265 mampu mengompresi 50% lebih dari
H.264 .

Baca juga blognya
Perusahaan EDISON:
20 perpustakaan untuk
aplikasi iOS yang spektakuler