Kami telah menggunakan layanan cloud untuk waktu yang lama: surat, penyimpanan, jejaring sosial, pesan instan. Semuanya bekerja dari jarak jauh - kami mengirim pesan dan file, dan semuanya disimpan dan diproses di server jarak jauh. Cloud gaming juga berfungsi: pengguna terhubung ke layanan, memilih game dan meluncurkan. Ini nyaman bagi pemain, karena permainan mulai hampir seketika, tidak memakan memori, dan tidak membutuhkan komputer gaming yang kuat.

Untuk layanan cloud, semuanya berbeda - ia memiliki masalah penyimpanan data. Setiap permainan dapat berbobot puluhan atau ratusan gigabyte, misalnya, "The Witcher 3" membutuhkan 50 GB, dan "Call of Duty: Black Ops III" - 113. Pada saat yang sama, pemain tidak akan menggunakan layanan dengan 2-3 game, setidaknya beberapa lusinan diperlukan . Selain menyimpan ratusan game, layanan ini perlu memutuskan berapa banyak penyimpanan yang harus dialokasikan per pemain, dan skala ketika ada ribuan dari mereka.
Haruskah semua ini disimpan di server mereka: berapa banyak yang mereka butuhkan, di mana menempatkan pusat data, bagaimana cara "menyinkronkan" data antara beberapa pusat data dengan cepat? Beli "awan"? Gunakan mesin virtual? Apakah mungkin untuk menyimpan data pengguna dengan kompresi 5 kali dan menyediakannya secara real-time? Bagaimana cara mengecualikan pengaruh pengguna terhadap satu sama lain selama penggunaan mesin virtual yang sama secara konsisten?
Semua tugas ini berhasil diselesaikan di Playkey.net - platform game berbasis cloud.
Vladimir Ryabov (
Graymansama ) - kepala departemen administrasi sistem - akan berbicara secara rinci tentang teknologi ZFS untuk FreeBSD, yang membantu dalam hal ini, dan garpu baru ZOL (ZFS di Linux).
Seribu server perusahaan berlokasi di pusat data jarak jauh di Moskow, London dan Frankfurt. Ada lebih dari 250 game dalam layanan ini, yang dimainkan oleh 100 ribu pemain sebulan.
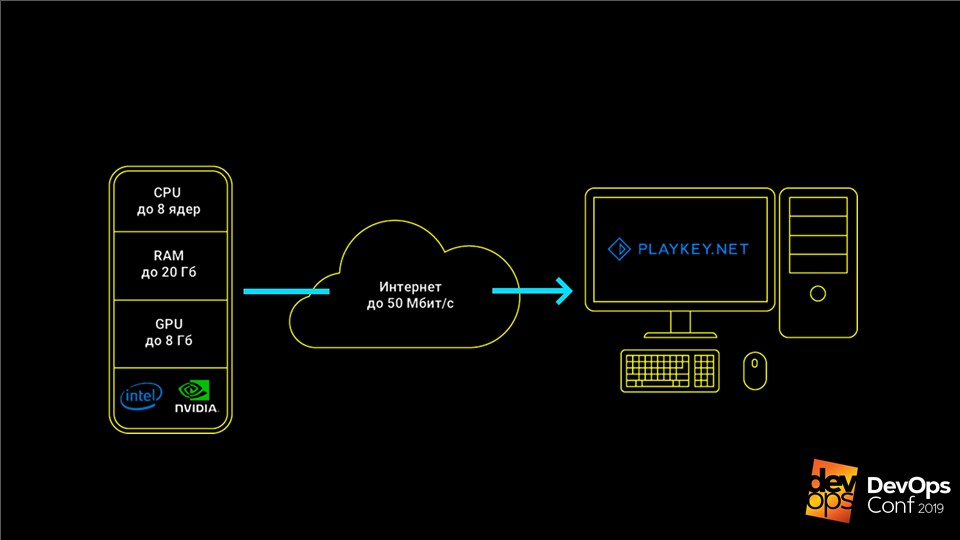
Layanan berfungsi seperti ini: permainan berjalan di server perusahaan, pengguna menerima aliran kontrol dari keyboard, mouse atau gamepad, dan aliran video dikirim sebagai tanggapan. Hal ini memungkinkan Anda untuk memainkan game top-end modern di komputer dengan perangkat keras yang lemah, laptop dengan video terintegrasi, atau di Mac yang tidak dirilis sama sekali untuk game-game ini.
Game harus disimpan dan diperbarui
Data utama untuk layanan cloud gaming adalah distribusi game, yang dapat melebihi ratusan GB, dan menghemat pengguna.
Ketika kami masih kecil, kami hanya memiliki selusin server dan katalog sederhana 50 game. Kami menyimpan semua data secara lokal di server, diperbarui secara manual, semuanya baik-baik saja. Tetapi waktunya telah tiba untuk tumbuh dan kami berangkat
ke awan AWS .
Dengan AWS, kami mendapat beberapa ratus server, tetapi arsitekturnya tidak berubah. Mereka juga server, tetapi sekarang virtual, dengan disk lokal di mana distribusi permainan berada. Namun, memperbarui secara manual pada seratus server akan gagal.
Kami mulai mencari solusi. Awalnya kami mencoba memperbarui melalui
rsync . Tetapi ternyata ini sangat lambat, dan beban pada simpul utama terlalu banyak. Tetapi ini bahkan bukan yang terburuk: ketika kami memiliki online rendah, kami mematikan beberapa mesin virtual agar tidak membayar untuk mereka, dan ketika memperbarui, data tidak dituangkan ke server yang dimatikan. Semuanya dibiarkan tanpa pembaruan.
Solusinya adalah torrent - program
BTSync . Ini memungkinkan Anda untuk menyinkronkan folder pada sejumlah besar node tanpa secara eksplisit menentukan node pusat.
Masalah pertumbuhan
Untuk sementara, semua ini bekerja dengan sangat baik. Tetapi layanan ini berkembang, ada lebih banyak game dan server. Jumlah penyimpanan lokal juga meningkat, kami harus membayar lebih dan lebih. Di awan itu mahal, terutama untuk SSD. Pada satu titik, bahkan pengindeksan folder biasa untuk memulai sinkronisasi mulai memakan waktu lebih dari satu jam, dan semua server dapat diperbarui selama beberapa hari.
BTSync telah menciptakan masalah lain dengan lalu lintas jaringan yang berlebihan. Pada saat itu, di Amazon dibayar bahkan di antara virtual internal. Jika peluncur game klasik membuat perubahan kecil pada file besar, maka BTSync segera percaya bahwa seluruh file telah berubah, dan mulai mentransfer sepenuhnya ke semua node. Akibatnya, bahkan pemutakhiran 15 MB dapat menghasilkan puluhan GB lalu lintas sinkronisasi.
Situasi menjadi kritis ketika penyimpanan tumbuh menjadi 1 TB. Baru saja merilis game baru World of Warships. Distribusinya memiliki beberapa ratus ribu file kecil. BTSync tidak dapat mencernanya dan mendistribusikannya ke semua server lain - ini memperlambat distribusi game lain.
Semua faktor ini menciptakan dua masalah:
- menghasilkan penyimpanan lokal mahal, tidak nyaman dan sulit diperbarui;
- awannya sangat mahal.
Kami memutuskan untuk kembali ke konsep server fisik kami.
Sistem penyimpanan sendiri
Sebelum pindah ke server fisik, kita harus menyingkirkan penyimpanan lokal. Ini membutuhkan
sistem penyimpanannya sendiri
- penyimpanan . Ini adalah sistem yang menyimpan semua distribusi dan mendistribusikannya secara terpusat ke semua server.
Tampaknya tugasnya sederhana - sudah berulang kali diselesaikan. Namun dengan game ada nuansa. Misalnya, sebagian besar gim hanya menolak untuk bekerja jika diberi akses hanya baca. Bahkan dengan start-up biasa yang biasa, mereka suka menulis sesuatu ke file mereka, dan tanpa itu mereka menolak untuk bekerja. Sebaliknya, jika sejumlah besar pengguna diberikan akses ke satu set distribusi, mereka mulai saling mengalahkan file dengan akses kompetitif.
Kami memikirkan masalahnya, memeriksa beberapa kemungkinan solusi, dan datang ke
ZFS - Zettabyte File System di FreeBSD .
ZFS di FreeBSD
Ini bukan sistem file biasa. Sistem klasik pada awalnya diinstal pada satu perangkat, dan untuk bekerja dengan beberapa disk sudah memerlukan manajer volume.
ZFS awalnya dibangun di atas kolam virtual.
Mereka disebut
zpool dan terdiri dari grup disk atau array RAID. Seluruh volume disk ini tersedia untuk semua sistem file di dalam zpool. Itu karena ZFS awalnya dikembangkan sebagai sistem yang akan bekerja dengan sejumlah besar data.
Bagaimana ZFS membantu menyelesaikan masalah kami
Sistem ini memiliki
mekanisme luar biasa
untuk membuat snapshot dan klon . Mereka dibuat secara
instan , dan beratnya hanya beberapa KB. Ketika kami membuat perubahan pada salah satu klon, itu meningkat dengan volume perubahan ini. Pada saat yang sama, data di klon yang tersisa tidak berubah dan tetap unik. Ini memungkinkan Anda untuk mendistribusikan disk
10 TB dengan akses eksklusif ke pengguna akhir, hanya menghabiskan beberapa KB.
Jika klon tumbuh dalam proses membuat perubahan pada sesi game, apakah mereka tidak akan mengambil ruang sebanyak semua game? Tidak, kami menemukan bahwa bahkan dalam sesi permainan yang cukup panjang, rangkaian perubahan jarang melebihi 100-200 MB - ini tidak penting. Oleh karena itu, kami dapat memberikan akses penuh ke hard drive berkapasitas tinggi penuh ke beberapa ratus pengguna secara bersamaan, hanya menghabiskan 10 TB dengan ekor.
Cara Kerja ZFS
Deskripsinya tampak rumit, tetapi ZFS bekerja cukup sederhana. Mari kita menganalisis kerjanya dengan contoh sederhana - buat
zpool data dari disk
zpool create data /dev/da /dev/db /dev/dc tersedia
zpool create data /dev/da /dev/db /dev/dc .
Catatan Ini tidak diperlukan untuk produksi, karena jika setidaknya satu disk mati, seluruh kumpulan akan dilupakan. Lebih baik gunakan grup RAID.Kami membuat
zfs create data/games sistem file
zfs create data/games , dan di dalamnya perangkat blok dengan nama
data/games/disk 10 TB. Perangkat ini tersedia di
/dev/zvol/data/games/disk sebagai disk biasa - Anda dapat melakukan manipulasi yang sama dengannya.
Kemudian kesenangan dimulai. Kami memberikan disk ini melalui
iSCSI ke panduan pembaruan kami - mesin virtual biasa yang menjalankan Windows. Kami menghubungkan disk, dan menempatkan game di dalamnya hanya dari Steam, seperti pada komputer di rumah biasa.
Isi disk dengan game. Sekarang tetap mendistribusikan data ini ke
200 server untuk pengguna akhir.
- Buat snapshot disk ini dan menyebutnya versi pertama -
zfs snapshot data/games/disk@ver1 . Buat clone zfs clone data/games/disk@ver1 data/games/disk-vm1 , yang akan menuju ke mesin virtual pertama. - Kami memberikan klon melalui iSCSI dan KVM meluncurkan mesin virtual dengan disk ini . Itu memuat, masuk ke kumpulan server yang dapat diakses untuk pengguna, dan mengharapkan pemain.
- Ketika sesi pengguna selesai, kami mengambil semua simpanan pengguna dari mesin virtual ini dan meletakkannya di server terpisah . Kami mematikan mesin virtual dan menghancurkan klon -
zfs destroy data/games/disk-vm1 . - Kami kembali ke langkah pertama, lagi buat klon dan mulai mesin virtual.
Ini memungkinkan kami untuk memberi setiap pengguna berikutnya
mesin yang selalu bersih , yang tidak ada perubahan dari pemain sebelumnya. Disk setelah setiap sesi pengguna dihapus, dan ruang yang ditempati pada sistem penyimpanan dibebaskan. Kami juga melakukan operasi serupa dengan disk sistem dan dengan semua mesin virtual kami.
Baru-baru ini, saya menemukan video di YouTube, di mana pengguna yang puas selama sesi permainan memformat hard drive kami di server, dan sangat senang bahwa dia telah merusak segalanya. Ya, tolong, hanya untuk membayar - dia bisa bermain dan menikmati. Bagaimanapun, pengguna berikutnya akan selalu mendapatkan mesin virtual yang bersih dan fungsional, apa pun yang dilakukan sebelumnya.
Menurut skema ini, game hanya didistribusikan ke 200 server. Kami menghitung angka 200 secara eksperimental: ini adalah jumlah server di mana beban kritis pada drive penyimpanan tidak terjadi. Ini karena
gim memiliki profil memuat yang agak spesifik :
gim ini banyak membaca pada tahap peluncuran atau pada tahap pemuatan level, dan selama gim, sebaliknya, praktis tidak menggunakan disk. Jika profil pemuatan Anda berbeda, maka angkanya akan berbeda.
Dalam skema lama, untuk melayani secara simultan 200 pengguna, kami membutuhkan 2.000 TB penyimpanan lokal. Sekarang kita dapat menghabiskan sedikit lebih dari 10 TB untuk kumpulan data utama, dan masih ada 0,5 TB dalam persediaan untuk perubahan pengguna. Meskipun ZFS suka ketika memiliki setidaknya 15% ruang kosong di kolam renangnya, menurut saya kami telah menghemat banyak.
Bagaimana jika kita memiliki beberapa pusat data?
Mekanisme ini hanya akan berfungsi di dalam satu pusat data, di mana server dengan sistem penyimpanan dihubungkan oleh setidaknya 10 gigabit antarmuka. Apa yang harus dilakukan jika ada beberapa DC? Bagaimana cara memperbarui disk utama dengan game (dataset) di antara mereka?
Untuk ini, ZFS memiliki solusi sendiri -
mekanisme Kirim / Terima . Perintah eksekusi sangat sederhana:
zfs send -v data/games/disk@ver1 | ssh myzfsuser@myserverip zfs receive data/games/disk
Mekanisme ini memungkinkan Anda mentransfer dari satu sistem penyimpanan ke snapshot lain dari sistem utama. Untuk pertama kalinya, Anda harus mengirim semua 10 terabyte data yang ditulis ke master node ke sistem penyimpanan kosong. Tetapi dengan pembaruan berikutnya, kami hanya akan mengirim perubahan dari saat kami membuat snapshot sebelumnya.
Sebagai hasilnya, kita mendapatkan:
- Semua perubahan dilakukan secara terpusat pada satu sistem penyimpanan . Kemudian mereka menyebar ke semua pusat data lainnya dalam jumlah berapapun, dan data pada semua node selalu identik.
- Mekanisme Kirim / Terima tidak takut terputus . Data tidak diterapkan ke dataset utama sampai sepenuhnya ditransmisikan ke slave node. Jika koneksi terputus, data tidak mungkin rusak, dan ulangi saja prosedur pengiriman.
- Setiap node dapat dengan mudah menjadi master node selama kecelakaan hanya dalam beberapa menit, karena data pada semua node selalu identik.
Deduplikasi dan cadangan
ZFS memiliki fitur lain yang bermanfaat -
deduplikasi . Fungsi ini membantu
untuk tidak menyimpan dua blok data yang identik . Sebaliknya, hanya blok pertama yang disimpan, dan di tempat yang kedua, tautan ke yang pertama disimpan. Dua file yang identik akan mengambil ruang sebagai satu, dan jika mereka cocok dengan 90%, mereka akan mengisi 110% dari volume aslinya.
Fungsi ini banyak membantu kami dalam menyimpan pengguna. Dalam satu permainan, pengguna yang berbeda memiliki penyimpanan yang serupa, banyak file yang sama. Melalui penggunaan deduplikasi, kita dapat menyimpan data lima kali lebih banyak. Rasio deduplikasi kami adalah 5,22. Secara fisik, kami memiliki 4,43 terabyte, kami mengalikannya dengan faktor, dan kami mendapatkan hampir 23 terabyte data nyata. Ini menghemat ruang dengan menghindari penyimpanan duplikat.
Jepretan baik untuk cadangan . Kami menggunakan teknologi ini pada penyimpanan file kami. Misalnya, jika Anda menyimpan satu gambar setiap hari selama sebulan, Anda dapat menggunakan klon kapan saja pada hari apa pun di bulan itu dan mengeluarkan file yang hilang atau rusak. Ini menghilangkan kebutuhan untuk memutar kembali seluruh penyimpanan atau menggunakan salinan lengkapnya.
Kami menggunakan klon untuk membantu pengembang kami . Misalnya, mereka ingin mengalami migrasi yang berpotensi berbahaya di pangkalan tempur. Tidak cepat untuk menggunakan cadangan klasik dari database yang mendekati 1 TB. Oleh karena itu, kami cukup menghapus klon dari disk dasar dan menambahkannya secara instan ke instance baru. Sekarang pengembang dapat dengan aman menguji semuanya di sana.
API ZFS
Tentu saja, semua ini harus otomatis. Mengapa naik di server, bekerja dengan tangan Anda, menulis skrip, jika ini dapat diberikan kepada programmer? Karena itu, kami menulis
API Web sederhana kami.
Kami membungkus semua fungsi ZFS standar di dalamnya, memutus akses ke yang berpotensi berbahaya dan dapat merusak seluruh sistem penyimpanan, dan memberikan semua ini kepada programmer. Sekarang
semua operasi disk secara terpusat dan dilakukan oleh kode, dan kami
selalu tahu status setiap disk . Semuanya bekerja dengan baik.
Zool - ZFS di Linux
Kami memusatkan sistem dan berpikir, apakah ini begitu baik? Memang, sekarang untuk ekstensi apa pun, kita segera perlu membeli beberapa rak server: mereka terikat pada sistem penyimpanan, dan itu tidak masuk akal untuk membagi sistem. Apa yang harus dilakukan ketika kami memutuskan untuk menggelar demo kecil untuk menunjukkan teknologi kepada mitra di negara lain?
Berpikir, kami sampai pada ide lama - untuk
menggunakan drive lokal , tetapi hanya dengan semua pengalaman dan pengetahuan yang kami terima. Jika Anda memperluas ide secara lebih global, lalu mengapa tidak memberi pengguna kami kesempatan tidak hanya untuk menggunakan server kami, tetapi juga untuk menyewa komputer mereka?
Garpu
ZFS yang relatif baru
di Linux - Zool membantu kami dalam hal ini.
Sekarang setiap server memiliki penyimpanannya sendiri.
Hanya itu tidak menyimpan data 10 terabyte, seperti dalam kasus instalasi terpusat, tetapi hanya 1-2 distribusi dari game yang dilayaninya. Satu SSD sudah cukup untuk ini. Semua ini berfungsi dengan baik: setiap pengguna berikutnya selalu mendapatkan mesin virtual yang bersih, serta pada instalasi tempur.
Namun, di sini kami menemui dua masalah.
Bagaimana cara memperbarui?
Perbarui terpusat melalui SSH, seperti yang kami lakukan di pusat data tidak akan berfungsi . Pengguna dapat terhubung ke jaringan lokal atau hanya dimatikan, tidak seperti sistem penyimpanan, dan Anda tidak ingin meningkatkan begitu banyak koneksi SSH.
Kami mengalami masalah yang sama seperti ketika menggunakan rsync. Namun, torrent di atas ZFS tidak lagi dapat diperoleh. Kami dengan cermat memikirkan cara kerja mekanisme Kirim: mengirim semua blok data yang diubah ke penyimpanan akhir, di mana Receive menerapkannya ke dataset saat ini. Mengapa tidak menulis data ke file, alih-alih mengirimnya ke pengguna akhir?
Hasilnya adalah apa yang kita sebut
diff . Ini adalah file di mana semua blok yang diubah antara dua foto terakhir secara berurutan ditulis. Kami meletakkan perbedaan ini pada CDN, dan mengirimkannya ke semua pengguna kami melalui HTTP: itu menghidupkan mesin, melihat bahwa ada pembaruan, kempes dan menerapkannya ke dataset lokal menggunakan Terima.
Apa yang harus dilakukan dengan driver?
Server terpusat memiliki konfigurasi yang sama, dan
pengguna akhir selalu memiliki komputer dan kartu video yang berbeda . Bahkan jika kita mengisi distribusi OS dengan semua driver yang mungkin sebanyak mungkin, pertama kali dimulai, ia masih ingin menginstal driver ini, maka itu akan restart, dan kemudian, mungkin, lagi. Karena setiap kali kami memberikan klon bersih, maka semua korsel ini akan muncul setelah setiap sesi pengguna - ini buruk.
Kami ingin menjalankan inisialisasi: tunggu hingga Windows dinyalakan, instal semua driver, lakukan semua yang diinginkannya, dan baru kemudian beroperasi pada drive ini. Tetapi masalahnya adalah bahwa jika Anda membuat perubahan pada dataset utama, pembaruan akan pecah, karena data pada sumber dan pada penerima akan berbeda, dan diff tidak akan berlaku.
Namun, ZFS adalah sistem yang fleksibel dan memungkinkan kami membuat penopang kecil.
- Seperti biasa, buat snapshot:
zfs snapshot data/games/os@init . - Buat klonnya -
zfs clone data/games/os@init data/games/os-init - dan jalankan dalam mode inisialisasi. - Kami menunggu semua driver untuk menginstal dan semuanya akan reboot.
- Matikan mesin virtual dan potret kembali. Tapi kali ini, bukan dari dataset asli, tetapi dari klon inisialisasi:
zfs snapshot data/games/os-init@ver1 . - Kami membuat klon foto dengan semua driver yang diinstal. Ini tidak akan lagi reboot:
zfs clone data/games/os-init@ver1 data/games/os-vm1 . - Kemudian kami mengerjakan kelompok klasik.
Sekarang sistem ini berada pada tahap pengujian alpha. Kami mengujinya pada pengguna sungguhan tanpa pengetahuan Linux, tetapi mereka berhasil menyebarkan semuanya di rumah. Tujuan utama kami adalah agar setiap pengguna cukup mencolokkan USB flash drive yang dapat di-boot ke komputer mereka, sambungkan drive SSD tambahan dan menyewakannya di platform cloud kami.
Kami hanya membahas sebagian kecil fungsi ZFS. Sistem ini dapat melakukan banyak hal yang lebih menarik dan berbeda, tetapi hanya sedikit orang yang tahu tentang ZFS - pengguna tidak ingin membicarakannya. Saya harap setelah artikel ini pengguna baru akan muncul di komunitas ZFS.
Berlangganan saluran telegram atau buletin untuk mempelajari tentang artikel dan video baru dari konferensi DevOpsConf . Selain buletin, kami mengumpulkan berita dari konferensi mendatang dan memberi tahu, misalnya, apa yang akan menarik bagi penggemar DevOps di Saint HighLoad ++ .