Diketahui bahwa kompetensi CTO diuji hanya untuk kedua kalinya peran ini dimainkan. Karena itu adalah satu hal untuk bekerja di perusahaan selama beberapa tahun, berkembang dengan itu dan, berada dalam konteks budaya yang sama, secara bertahap mendapatkan lebih banyak tanggung jawab. Dan itu hal lain - untuk segera mengambil jabatan direktur teknis di sebuah perusahaan dengan barang bawaan dan banyak masalah yang tersusun rapi di bawah karpet.
Dalam hal ini, pengalaman Leon Fayer, yang ia bagikan di
DevOpsConf , tidak hanya langsung unik, tetapi dikalikan dengan pengalaman dan jumlah peran berbeda yang ia coba untuk dirinya sendiri selama lebih dari 20 tahun sangat berguna. Di bawah potongan, kronologi peristiwa lebih dari 90 hari dan banyak kisah yang menyenangkan untuk ditertawakan ketika mereka terjadi pada orang lain, tetapi yang tidak begitu menyenangkan untuk dihadapi secara langsung.
Leon sangat berwarna dalam bahasa Rusia, jadi jika Anda memiliki 35-40 menit, saya sarankan menonton videonya. Versi teks untuk menghemat waktu di bawah.
Versi pertama dari laporan ini adalah deskripsi terstruktur yang baik tentang bekerja dengan orang-orang dan proses, yang berisi rekomendasi yang bermanfaat. Tapi dia tidak menyampaikan semua kejutan yang ditemui di sepanjang jalan. Oleh karena itu, saya mengubah format dan menguraikan masalah yang muncul di perusahaan saya di depan saya seperti kotak tembakau, dan metode untuk menyelesaikannya dalam urutan kronologis.
Satu bulan sebelumnya
Seperti banyak cerita bagus, yang ini dimulai dengan alkohol. Kami duduk dengan teman-teman di bar, dan sebagaimana seharusnya di antara orang-orang TI, semua orang menangis tentang masalah mereka. Salah satu dari mereka baru saja berganti pekerjaan dan berbicara tentang masalahnya dengan teknologi, dan dengan orang-orang, dan dengan tim. Semakin lama saya mendengarkan, semakin saya menyadari bahwa dia hanya perlu mempekerjakan saya, karena justru itulah masalah yang telah saya pecahkan selama 15 tahun terakhir. Saya memberitahunya, dan hari berikutnya kami bertemu di lingkungan kerja. Perusahaan itu disebut Strategi Mengajar.
Strategi Mengajar memimpin pasar untuk program pendidikan untuk anak-anak yang sangat muda - sejak lahir hingga tiga tahun. Perusahaan "kertas" tradisional sudah berusia 40 tahun, dan versi digital SaaS dari platform 10. Baru-baru ini, proses mengadaptasi teknologi digital dengan standar perusahaan telah dimulai. Versi "baru" diluncurkan pada tahun 2017 dan hampir seperti yang lama, hanya saja itu bekerja lebih buruk.
Hal yang paling menarik adalah bahwa lalu lintas perusahaan ini sangat dapat diprediksi - dari hari ke hari, dari tahun ke tahun, Anda dapat memprediksi dengan jelas berapa banyak orang yang akan datang dan kapan. Misalnya, antara jam 1 hingga 3 sore, semua anak di taman kanak-kanak tidur, dan guru mulai memasukkan informasi. Dan ini terjadi setiap hari kecuali akhir pekan, karena pada akhir pekan hampir tidak ada yang bekerja.
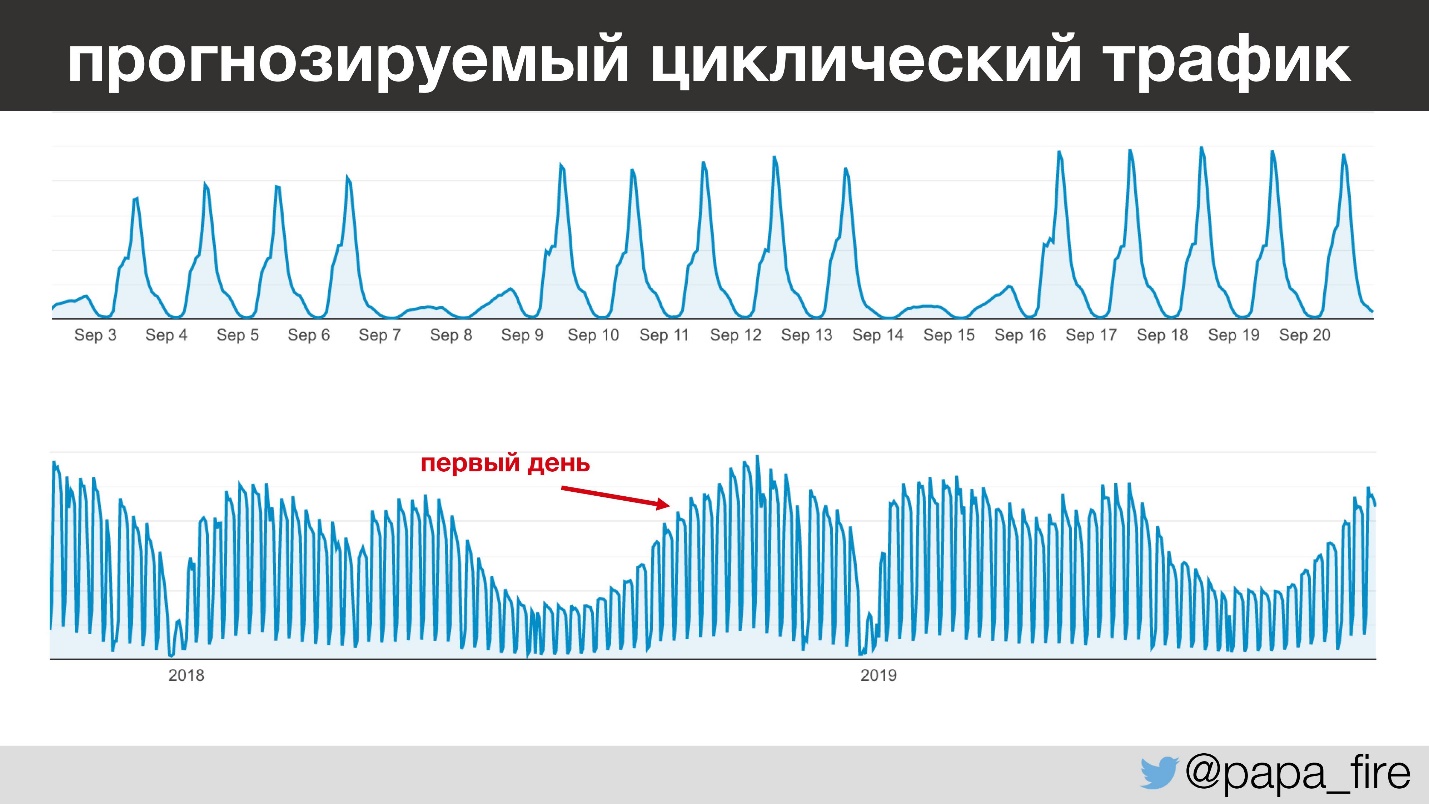
Melihat sedikit ke depan, saya memulai pekerjaan saya selama periode lalu lintas tahunan terbesar, yang menarik karena berbagai alasan.
Platform, yang tampaknya baru berusia 2 tahun, memiliki tumpukan aneh: ColdFusion & SQL Server 2008. ColdFusion, jika Anda tidak tahu, tetapi kemungkinan besar tidak tahu, adalah perusahaan PHP yang muncul pada pertengahan 90-an, dan sejak itu saya bahkan belum pernah mendengarnya. Juga ada: Ruby, MySQL, PostgreSQL, Java, Go, Python. Tetapi monolit utama bekerja pada ColdFusion dan SQL Server.
Masalahnya
Semakin saya berbicara dengan karyawan perusahaan tentang pekerjaan dan masalah apa yang dihadapi, semakin saya menyadari bahwa masalahnya tidak hanya bersifat teknis. Oke, teknologinya sudah tua - dan mereka tidak bekerja pada itu, tetapi ada masalah dengan tim dan dengan proses, dan perusahaan mulai memahami ini.
Secara tradisional, teknisi duduk di sudut dan melakukan beberapa pekerjaan mereka. Tetapi semakin banyak bisnis mulai melalui versi digital. Oleh karena itu, di perusahaan selama setahun terakhir sebelum pekerjaan saya dimulai, yang baru muncul: dewan direksi, CTO, CPO dan direktur QA. Artinya, perusahaan mulai berinvestasi di bidang teknologi.
Jejak warisan yang berat tidak hanya dalam sistem. Perusahaan memiliki proses legacy, legacy people, legacy culture. Semua ini harus diubah. Saya pikir itu pasti tidak akan membosankan, dan memutuskan untuk mencobanya.
Dua hari sebelumnya
Dua hari sebelum memulai pekerjaan baru, saya tiba di kantor, mengisi surat-surat terakhir, berkenalan dengan tim dan menemukan bahwa tim sedang berjuang dengan masalah pada waktu itu. Terdiri dari fakta bahwa waktu buka halaman rata-rata melonjak menjadi 4 detik, yaitu 2 kali.
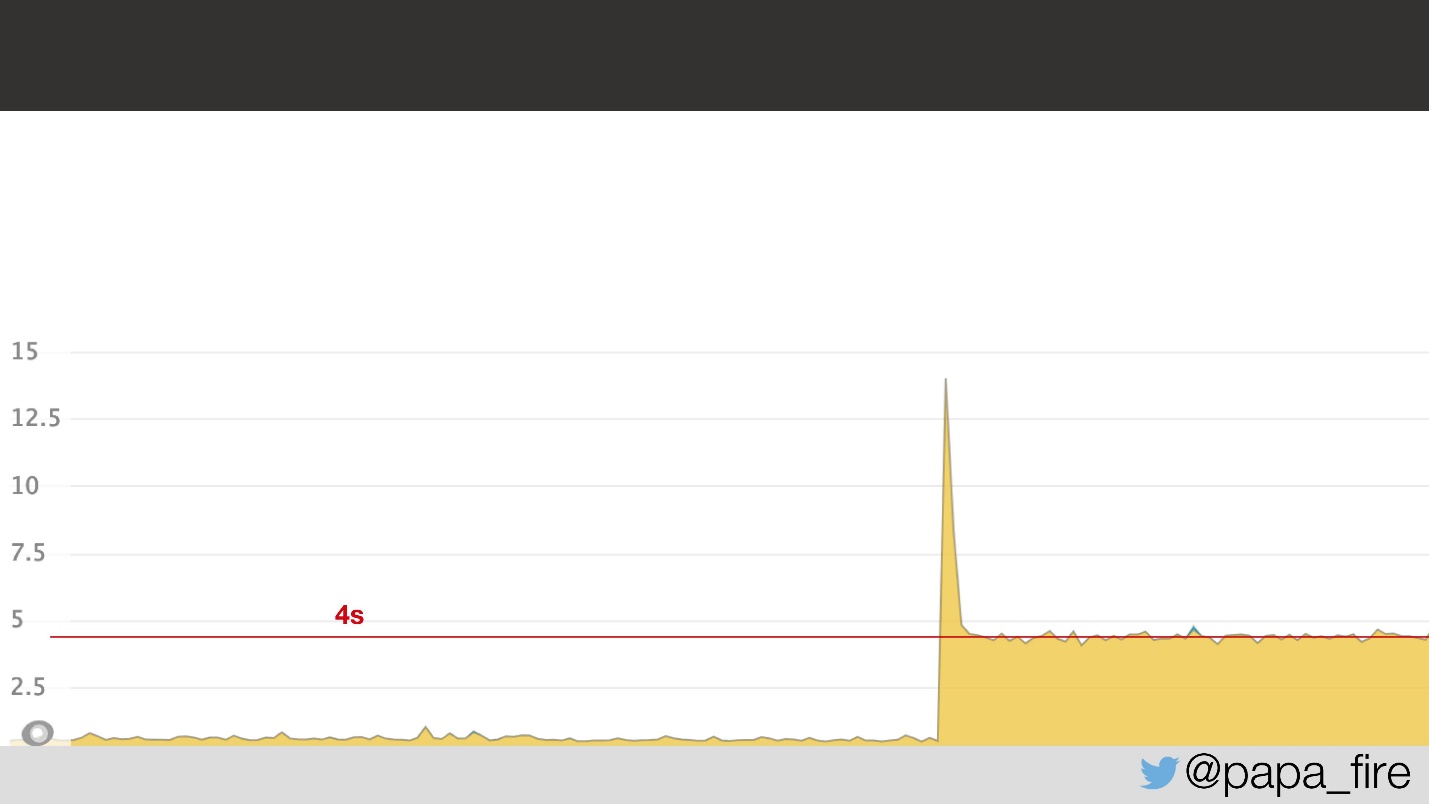
Dilihat dari jadwal, jelas sesuatu terjadi, dan tidak jelas apa. Ternyata masalahnya adalah latensi jaringan di pusat data: latensi 5 ms di pusat data dikonversi menjadi 2 detik untuk pengguna. Mengapa ini terjadi, saya tidak tahu, tetapi bagaimanapun juga diketahui bahwa masalahnya ada di pusat data.
Hari pertama
Dua hari berlalu, dan pada hari kerja pertama saya, saya menemukan bahwa masalahnya tidak hilang.
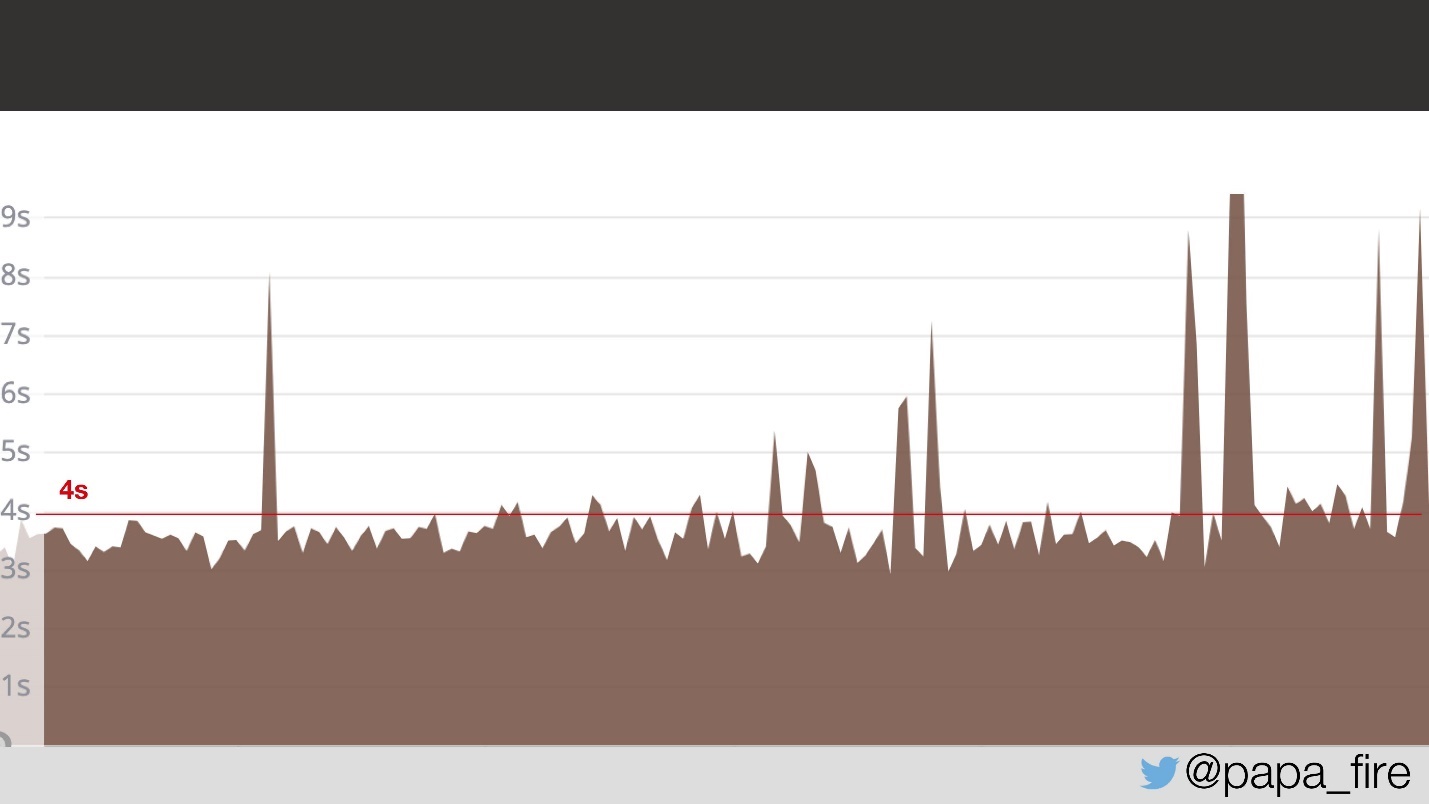
Selama dua hari, pengguna halaman memuat rata-rata 4 detik. Saya bertanya apakah mereka menemukan apa masalahnya.
- Ya, kami membuka tiket.
- Dan?
"Yah, mereka belum menjawab kita."Kemudian saya menyadari bahwa semua yang telah saya ketahui sebelumnya hanyalah puncak kecil gunung es yang harus saya lawan.
Ada kutipan bagus yang sangat cocok untuk kasus ini:
"Terkadang Anda perlu mengubah organisasi untuk mengubah teknologi."
Tetapi karena saya mulai bekerja di waktu tersibuk tahun ini, saya harus melihat kedua opsi untuk menyelesaikan masalah: cepat dan dalam jangka panjang. Dan mulailah dengan apa yang penting sekarang.
Hari ketiga
Jadi, memuat membutuhkan waktu 4 detik, dan dari 13 hingga 15 puncak terbesar.
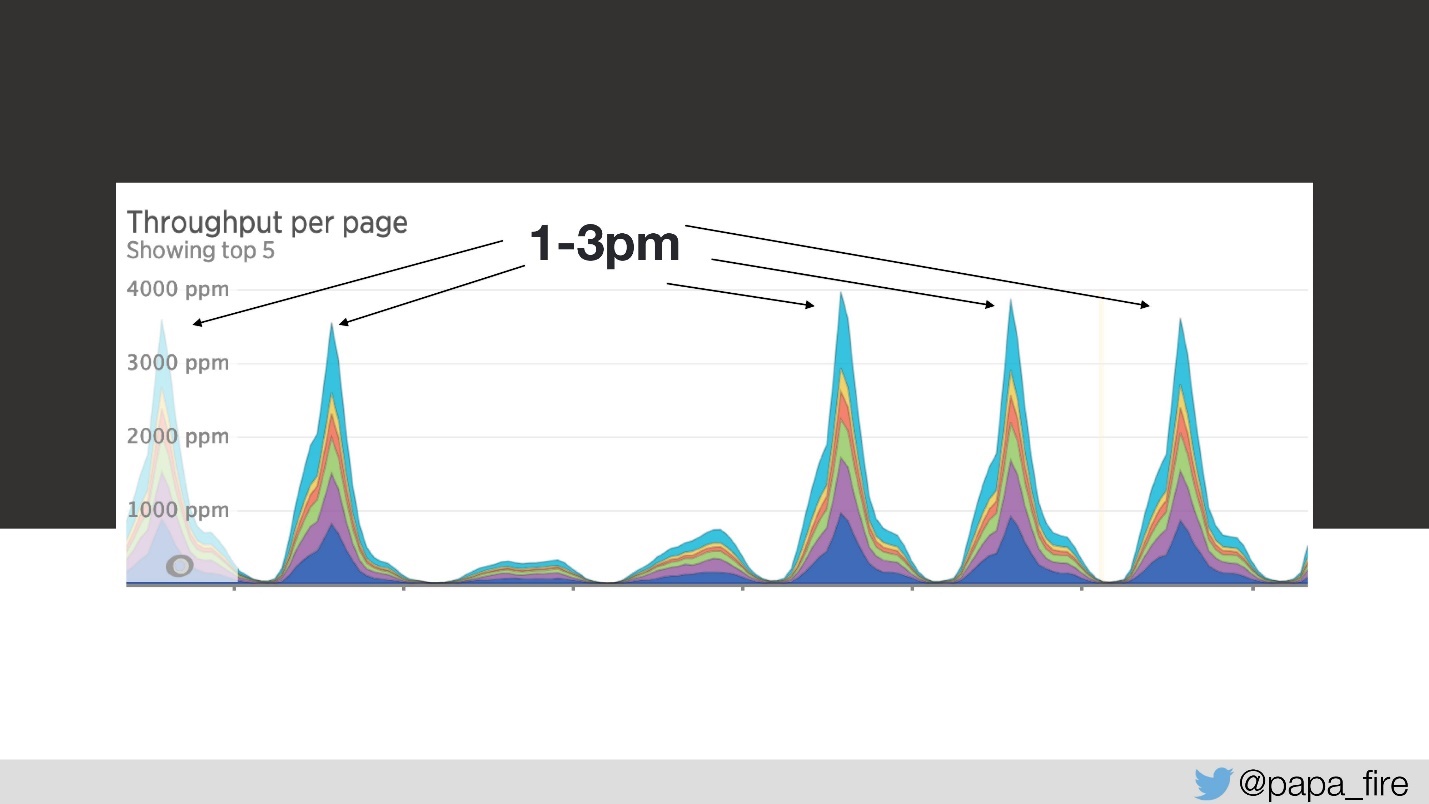
Pada hari ketiga, pada interval waktu ini, kecepatan unduh terlihat seperti ini:
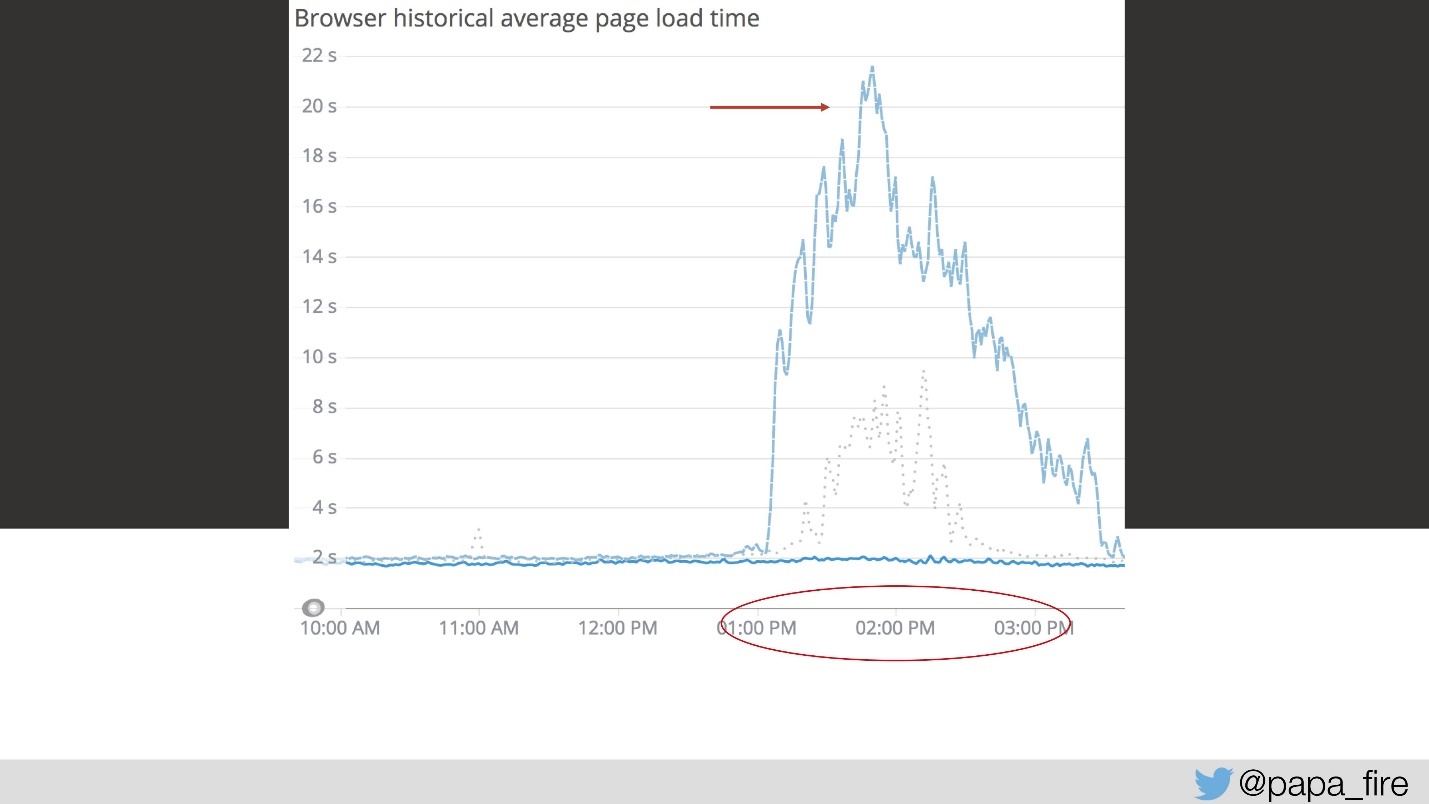
Dari sudut pandang saya, tidak ada yang berhasil sama sekali. Dari sudut pandang orang lain, itu bekerja sedikit lebih lambat dari biasanya. Tapi itu tidak terjadi begitu saja - ini adalah masalah serius.
Saya mencoba meyakinkan tim, dan mereka menjawab bahwa mereka hanya perlu lebih banyak server. Ini, tentu saja, adalah solusi untuk masalah tersebut, tetapi tidak selalu merupakan satu-satunya dan paling efektif. Saya bertanya mengapa tidak ada server yang cukup, berapa banyak traffic. Saya mengekstrapolasi data dan mendapatkan bahwa kami memiliki sekitar 150 permintaan per detik, yang pada dasarnya sesuai dengan batas yang masuk akal.
Tetapi kita tidak boleh lupa bahwa sebelum Anda mendapatkan jawaban yang benar, Anda perlu mengajukan pertanyaan yang tepat. Pertanyaan saya berikutnya adalah: berapa banyak server frontend yang kita miliki? Jawabannya "membingungkan saya" - kami memiliki 17 server frontend!
- Saya malu untuk bertanya, 150 dibagi 17, apakah akan menghasilkan sekitar 8? Anda ingin mengatakan bahwa setiap server melewatkan 8 permintaan per detik, dan jika ada 160 permintaan per detik besok, kita akan membutuhkan 2 server lagi?Tentu saja, kami tidak memerlukan server tambahan. Solusinya ada di kode itu sendiri, dan di permukaan:
var currentClass = classes.getCurrentClass(); return currentClass;
Ada fungsi
getCurrentClass() , karena semua yang ada di situs berfungsi dalam konteks kelas - dengan benar. Dan untuk fungsi yang satu ini pada setiap halaman ada
200+ permintaan .
Solusi dengan cara ini sangat sederhana, tidak perlu menulis ulang apa pun: hanya saja jangan meminta informasi yang sama lagi.
if ( !isDefined("REQUEST.currentClass") ) { var classes = new api.private.classes.base(); REQUEST.currentClass = classes.getCurrentClass(); } return REQUEST.currentClass;
Saya sangat senang karena saya memutuskan bahwa hanya pada hari ketiga saya menemukan masalah utama. Karena saya naif, ini hanya salah satu dari begitu banyak masalah.
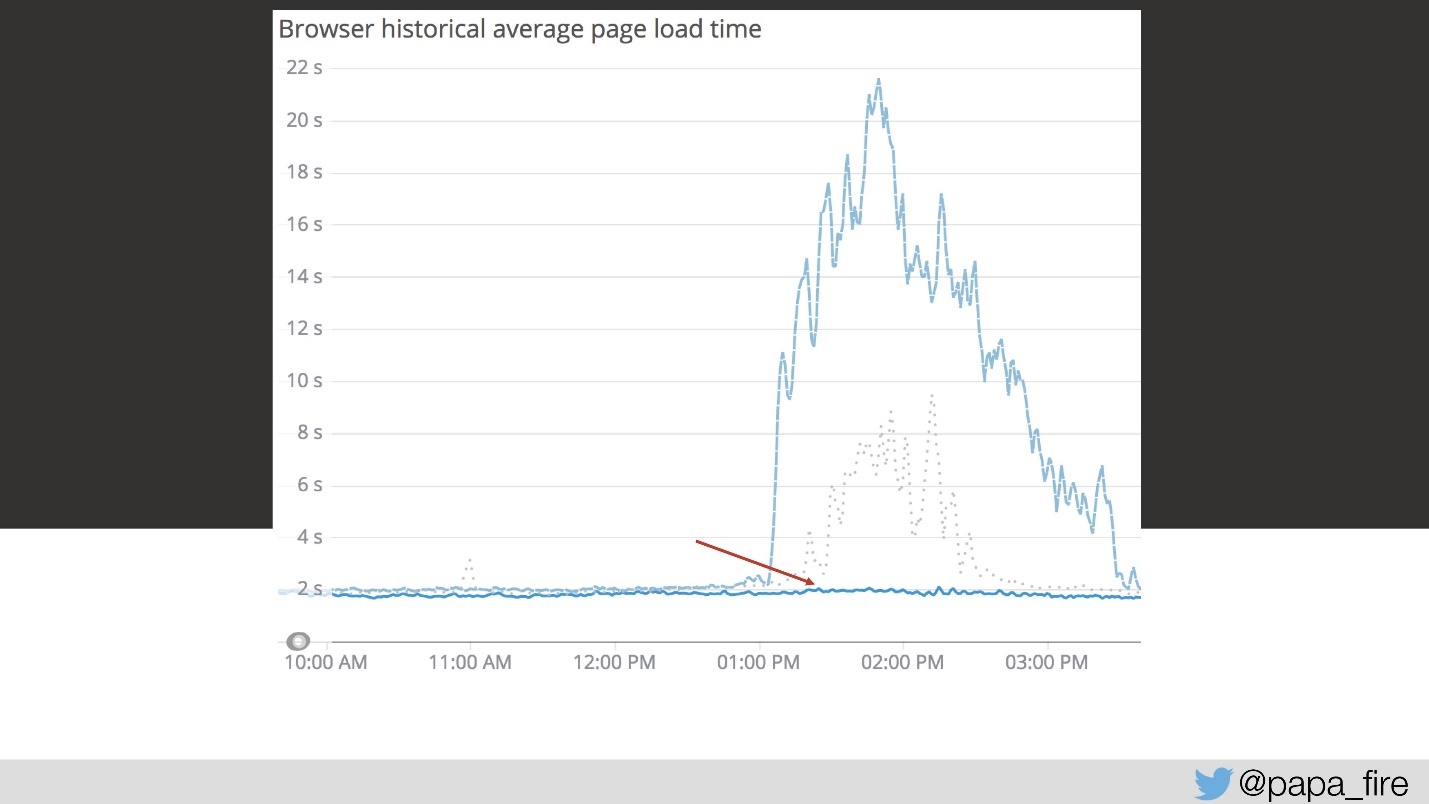
Tetapi solusi untuk masalah pertama ini menurunkan jadwal jauh lebih rendah.
Pada saat yang sama, kami terlibat dalam optimasi lainnya. Terlihat banyak sekali segala sesuatu yang bisa diperbaiki. Sebagai contoh, pada hari ketiga yang sama saya menemukan bahwa masih ada cache dalam sistem (pada awalnya saya berpikir bahwa semua permintaan langsung dari database). Ketika saya memikirkan cache, saya memperkenalkan Redis standar atau Memcached. Tapi hanya saya yang berpikir demikian, karena untuk caching pada sistem itu MongoDB dan SQL Server digunakan - yang sama dari mana data baru saja dibaca.
Sepuluh hari
Minggu pertama saya berurusan dengan masalah yang perlu diselesaikan sekarang. Di suatu tempat di minggu kedua saya pertama kali datang ke stand-up untuk berbicara dengan tim, melihat apa yang terjadi dan bagaimana keseluruhan proses berlangsung.
Sekali lagi, sesuatu yang menarik ditemukan. Tim terdiri dari: 18 pengembang; 8 penguji; 3 manajer; 2 arsitek. Dan mereka semua berpartisipasi dalam ritual umum, yaitu, lebih dari 30 orang datang ke stand setiap pagi dan mengatakan apa yang mereka lakukan. Jelas bahwa pertemuan itu tidak memakan waktu 5 atau 15 menit. Tidak ada yang mendengarkan siapa pun, karena semua orang bekerja pada sistem yang berbeda. Dalam formulir ini, 2-3 tiket per jam pada sesi perawatan sudah merupakan hasil yang baik.
Hal pertama yang kami lakukan adalah membagi tim menjadi beberapa di sepanjang lini produk. Untuk bagian dan sistem yang berbeda, kami mengidentifikasi tim terpisah yang mencakup pengembang, penguji, manajer produk, analis bisnis.
Sebagai hasilnya, kami menerima:
- Pengurangan stand-up dan aksi unjuk rasa.
- Pengetahuan produk.
- Rasa memiliki. Ketika sebelum orang selalu berbicara tentang sistem, mereka tahu bahwa orang lain mungkin harus bekerja dengan bug mereka, tetapi tidak untuk diri mereka sendiri.
- Kolaborasi antar kelompok. Anda tidak dapat mengatakan bahwa QA tidak banyak berkomunikasi dengan programmer sebelumnya, produk melakukan hal sendiri, dll. Sekarang mereka memiliki titik tanggung jawab bersama.
Kami terutama berfokus pada efisiensi, produktivitas, dan kualitas - ini adalah masalah yang kami coba selesaikan dengan transformasi tim.
Hari kesebelas
Dalam proses mengubah struktur tim, saya menemukan bagaimana
Poin Cerita dihitung. 1 SP sama dengan satu hari, dan setiap tiket mereka berisi SP baik untuk pengembangan dan QA, yaitu, setidaknya 2 SP.
Bagaimana saya menemukan ini?
Ditemukan bug: di salah satu laporan, di mana tanggal mulai dan berakhirnya periode saat laporan dibutuhkan dimasukkan, hari terakhir tidak diperhitungkan. Artinya, suatu tempat dalam permintaan itu bukan <=, tetapi hanya <. Saya diberitahu bahwa ini adalah tiga Poin Cerita, yaitu,
3 hari .
Setelah itu kita:
- Revisi sistem peringkat Story Points. Sekarang memperbaiki bug kecil yang dapat dengan cepat melewati sistem dengan cepat mencapai pengguna.
- Kami mulai menggabungkan tiket terkait untuk pengembangan dan pengujian. Sebelumnya, setiap tiket, setiap bug adalah ekosistem tertutup, tidak melekat pada hal lain. Mengubah tiga tombol pada satu halaman bisa menjadi tiga tiket berbeda dengan tiga proses QA berbeda, bukan satu tes otomatis pada halaman.
- Mereka mulai bekerja dengan pengembang tentang pendekatan untuk menilai biaya tenaga kerja. Tiga hari untuk mengubah satu tombol tidak lucu.
Hari kedua puluh
Di suatu tempat pada pertengahan bulan pertama, situasinya sedikit stabil, saya menemukan apa yang terutama terjadi, dan sudah mulai melihat ke masa depan dan berpikir tentang solusi jangka panjang.
Tujuan jangka panjang:
- Platform terkelola Ratusan permintaan di setiap halaman - ini tidak serius.
- Tren yang dapat diprediksi. Ada puncak lalu lintas berkala yang pada pandangan pertama tidak berkorelasi dengan metrik lainnya - perlu untuk memahami mengapa ini terjadi dan belajar untuk memprediksi.
- Ekstensi platform. Bisnis terus tumbuh, semakin banyak pengguna datang, lalu lintas meningkat.
Sering dikatakan di masa lalu: "Mari kita menulis ulang semuanya dalam [bahasa / kerangka kerja], semuanya akan bekerja lebih baik!"
Dalam kebanyakan kasus, ini tidak berfungsi, yah, jika yang ditulis ulang akan bekerja sama sekali. Oleh karena itu, kami perlu membuat peta jalan - strategi konkret yang menggambarkan langkah demi langkah bagaimana tujuan bisnis akan dicapai (apa yang akan kami lakukan dan mengapa), yang:
- mencerminkan misi dan tujuan proyek;
- memprioritaskan tujuan utama;
- berisi jadwal pencapaian mereka.
Sebelum ini, tidak ada yang berbicara dengan tim tentang tujuan perubahan apa yang dilakukan. Ini membutuhkan tingkat keberhasilan yang tepat. Untuk pertama kalinya dalam sejarah perusahaan, kami menetapkan KPI untuk kelompok teknis, dan indikator ini terkait dengan yang organisasi.
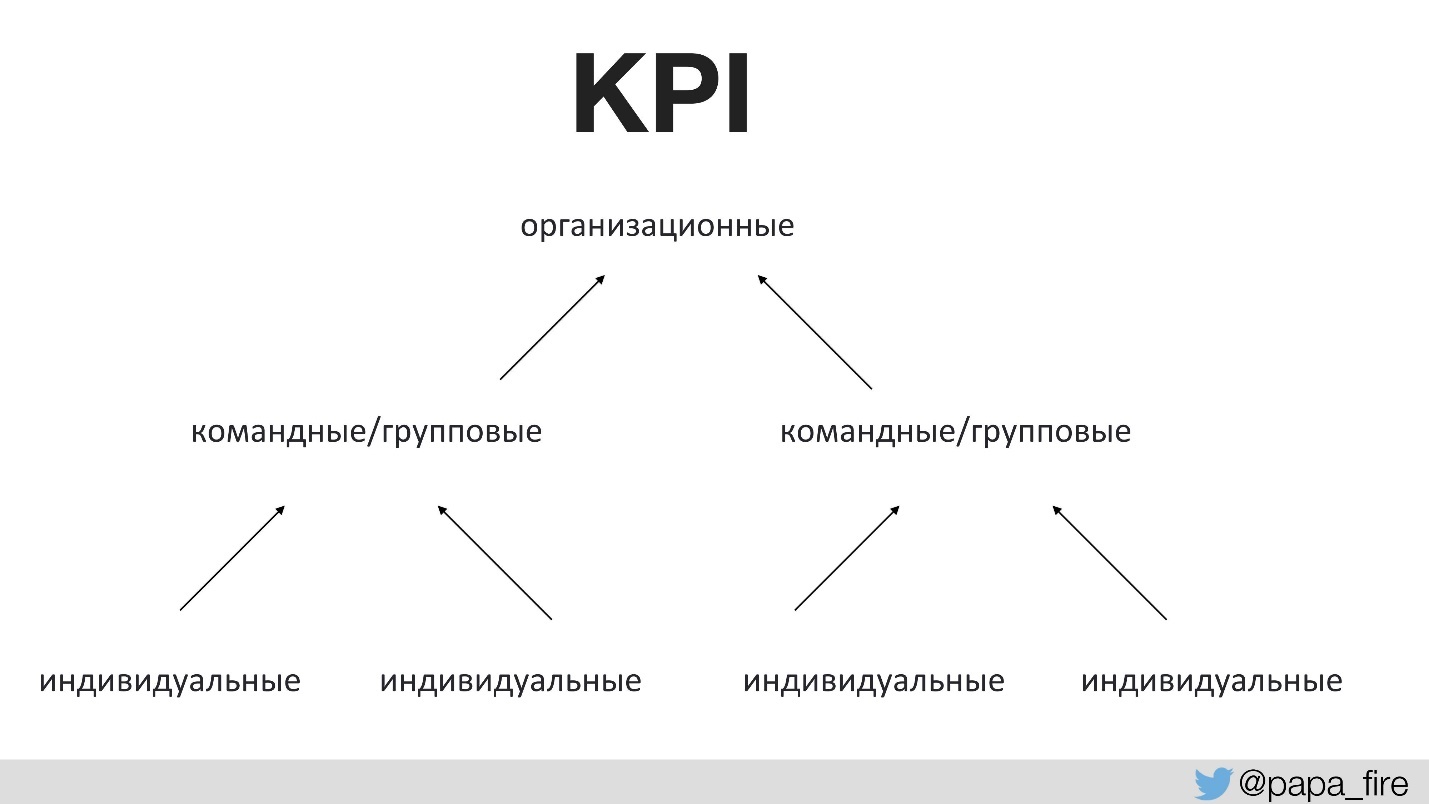
Yaitu, KPI organisasi didukung oleh tim, dan KPI tim sudah didukung oleh masing-masing. Kalau tidak, jika KPI teknologi tidak setuju dengan yang organisasi, maka semua orang menarik selimutnya sendiri.
Sebagai contoh, salah satu KPI organisasi adalah meningkatkan pangsa pasar melalui produk baru.
Bagaimana Anda dapat mendukung tujuan memiliki lebih banyak produk baru?
- Pertama, kami ingin menghabiskan lebih banyak waktu mengembangkan produk baru alih-alih memperbaiki bug. Ini adalah solusi logis yang mudah diukur.
- Kedua, kami ingin mendukung peningkatan volume transaksi, karena semakin besar pangsa pasar, semakin banyak pengguna, dan karenanya, semakin banyak lalu lintas.
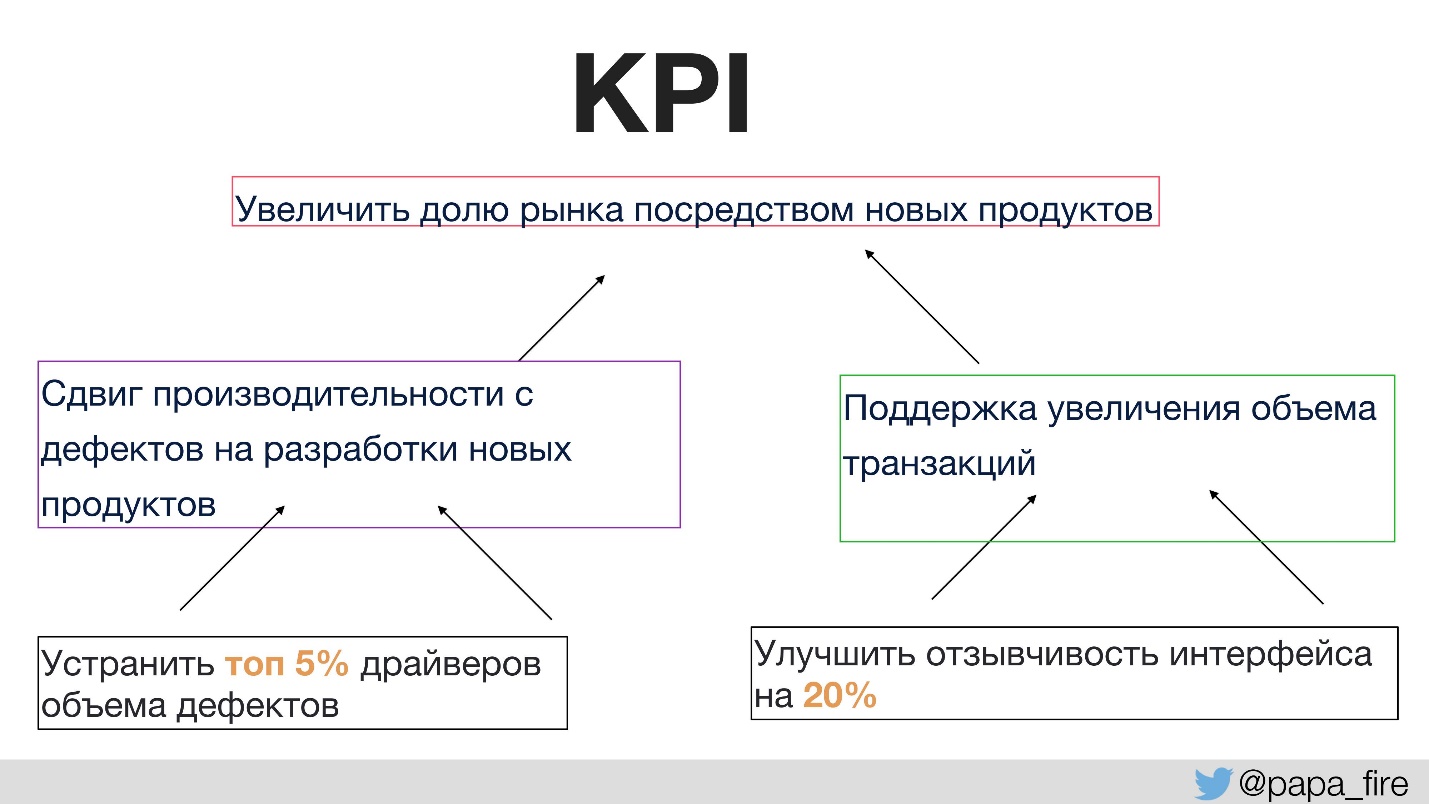
Maka KPI individual yang dapat dieksekusi dalam grup akan, misalnya, berada di tempat asal cacat utama. Jika Anda fokus pada bagian khusus ini, Anda dapat membuat jumlah cacat jauh lebih kecil, dan kemudian menambah waktu untuk mengembangkan produk baru dan lagi untuk mendukung KPI organisasi.
Dengan demikian, setiap keputusan, termasuk penulisan ulang kode, harus mendukung tujuan spesifik yang telah ditetapkan perusahaan untuk kita (pertumbuhan organisasi, fungsi baru, rekrutmen).
Selama proses ini, sesuatu yang menarik muncul yang menjadi berita tidak hanya untuk teknisi, tetapi secara umum di perusahaan: semua tiket harus difokuskan pada setidaknya satu KPI. Artinya, jika produk mengatakan ingin membuat fitur baru, pertanyaan pertama harus ditanyakan: "KPI apa yang didukung fitur ini?" Jika tidak ada, maka saya minta maaf - sepertinya ini adalah fitur yang tidak perlu.
Hari ketiga puluh
Pada akhir bulan, saya menemukan satu lagi nuansa yang tidak ada tim Ops saya yang pernah melihat kontrak yang kami simpulkan dengan klien. Anda mungkin bertanya mengapa harus melihat kontak.
- Pertama, karena SLA terdaftar dalam kontrak.
- Kedua, SLA semuanya berbeda. Setiap klien datang dengan persyaratan mereka, dan departemen penjualan menandatangani tanpa melihat.
Nuansa menarik lainnya - dalam kontrak dengan salah satu pelanggan terbesar tertulis bahwa semua versi perangkat lunak yang didukung platform harus n-1, yaitu, bukan versi terbaru, tetapi versi kedua dari belakang.
Jelas seberapa jauh kami dari n-1 jika platformnya menggunakan ColdFusion dan SQL Server 2008, yang pada bulan Juli tidak lagi didukung sama sekali.
Empat puluh lima hari
Di suatu tempat di pertengahan bulan kedua, saya punya cukup waktu luang untuk duduk dan melakukan
pemetaan aliran nilai sepenuhnya untuk seluruh proses. Ini adalah langkah-langkah yang perlu diambil, mulai dari menciptakan produk hingga mengirimkannya kepada konsumen, dan Anda perlu mengecatnya sedetail mungkin.
Anda memecah proses menjadi potongan-potongan kecil dan melihat apa yang membutuhkan terlalu banyak waktu, apa yang dapat dioptimalkan, ditingkatkan, dll. Misalnya, berapa lama permintaan dari produk tersebut, melewati perawatan, ketika mencapai tiket yang bisa diambil pengembang, QA, dll. Anda melihat setiap langkah secara detail dan berpikir bahwa Anda dapat mengoptimalkan.
Ketika saya melakukan ini, dua hal menarik perhatian saya:
- persentase tinggi dari tiket pulang dari QA kembali ke pengembang;
- tarik permintaan ulasan membutuhkan waktu terlalu lama.
Masalahnya adalah kesimpulannya seperti ini: sepertinya butuh banyak waktu, tapi kami tidak yakin berapa banyak.
"Tidak mungkin memperbaiki apa yang tidak bisa diukur."
Bagaimana membuktikan seberapa serius masalahnya? Apakah ini menghabiskan berhari-hari atau berjam-jam?
Untuk mengukur ini, kami menambahkan beberapa langkah ke proses Jira: "ready for dev" dan "ready for QA", untuk mengukur berapa lama setiap tiket menunggu dan berapa kali kembali ke langkah tertentu.
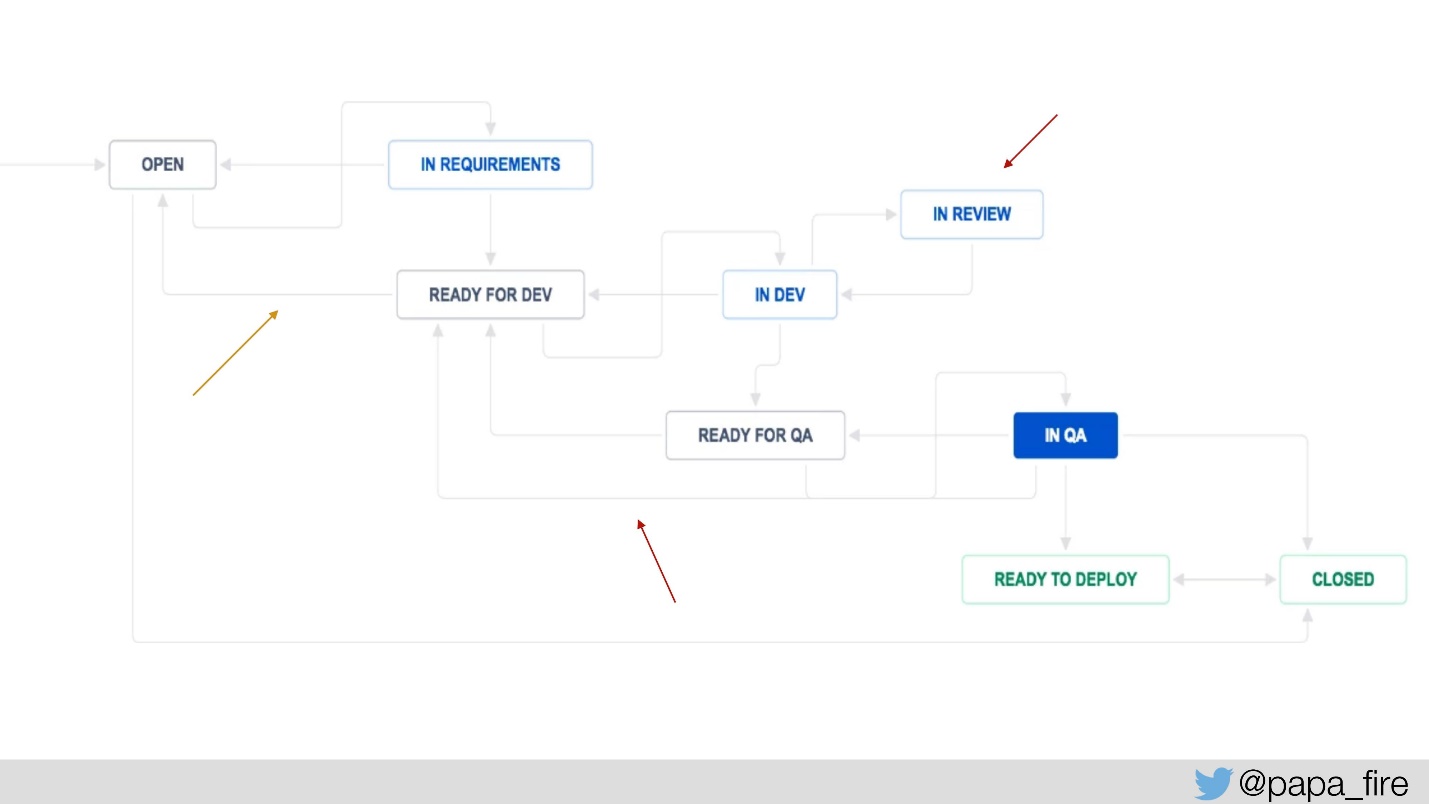
Kami juga menambahkan "sedang ditinjau" untuk mengetahui rata-rata berapa tiket yang ditinjau, dan itulah sebabnya mereka sudah menari. Kami memiliki metrik sistem, sekarang kami menambahkan metrik baru, dan mulai mengukur:
- Efisiensi proses: kinerja dan terencana / disampaikan.
- Kualitas proses: jumlah cacat, cacat dari QA.
Sangat membantu untuk memahami apa yang berjalan baik dan apa yang buruk.
Hari kelima puluh
Ini semua, tentu saja, bagus dan menarik, tetapi menjelang akhir bulan kedua terjadi sesuatu yang, pada prinsipnya, dapat diprediksi, meskipun saya tidak mengharapkan skala seperti itu. Orang-orang mulai pergi, karena puncak telah berubah. Orang-orang baru datang ke kepemimpinan yang mulai mengubah segalanya, dan yang lama berhenti. Dan biasanya di perusahaan yang berumur beberapa tahun, semua teman dan semua saling kenal.
Ini sudah diduga, tetapi skala PHK tidak terduga. Misalnya, dalam satu minggu, dua pemimpin tim secara bersamaan mengajukan pemecatan mereka sendiri. Karena itu, saya tidak harus melupakan masalah lain, tetapi untuk fokus
menciptakan tim . Ini adalah masalah yang panjang dan sulit, tetapi dia harus menghadapinya karena dia ingin menyelamatkan orang-orang yang tersisa (atau kebanyakan dari mereka). Entah bagaimana perlu bereaksi terhadap fakta bahwa orang-orang pergi untuk menjaga moralitas dalam tim.
Secara teori, ini bagus: orang baru datang yang memiliki carte blanche lengkap yang dapat menilai keterampilan tim dan mengganti personil. Bahkan, Anda tidak bisa hanya membawa orang baru karena berbagai alasan.
Selalu butuh keseimbangan.- Tua dan baru. Kita perlu menjaga orang tua yang dapat mengubah dan mendukung misi. Tetapi pada saat yang sama, kita perlu membawa darah baru, kita akan membicarakannya nanti.
- Pengalaman Saya banyak berbicara dengan junior yang baik yang membakar dan ingin bekerja untuk kami. Tetapi saya tidak dapat mengambil mereka, karena tidak ada cukup banyak tuan yang akan mendukung junior dan menjadi mentor bagi mereka. Pertama-tama perlu untuk mencapai puncak dan hanya kemudian pemuda.
- Wortel dan tongkat.
Saya tidak punya jawaban yang bagus untuk pertanyaan tentang keseimbangan apa yang benar, bagaimana cara mempertahankannya, berapa banyak orang yang akan pergi dan berapa banyak yang harus didorong. Ini adalah proses yang murni individual.
Hari kelima puluh satu
Saya mulai melihat dari dekat ke tim untuk memahami siapa yang saya miliki, dan sekali lagi ingat:
"Sebagian besar masalah adalah masalah orang."
Saya menemukan bahwa dalam tim, dengan demikian - baik pengembang dan Ops - memiliki tiga masalah besar:
- Kepuasan dengan keadaan saat ini.
- Kurangnya tanggung jawab - karena tidak ada yang pernah membawa hasil kerja para pemain untuk mempengaruhi bisnis.
- Takut akan perubahan.

Perubahan selalu membuat Anda keluar dari zona nyaman Anda, dan semakin muda, semakin mereka tidak suka perubahan, karena mereka tidak mengerti mengapa dan tidak mengerti bagaimana. Jawaban paling umum yang saya dengar adalah: "Kami tidak pernah melakukan itu." Dan itu sampai pada titik absurditas sepenuhnya - perubahan sekecil apa pun tidak berlalu tanpa seseorang menjadi marah. Dan tidak masalah seberapa besar perubahan itu menyangkut pekerjaan mereka, orang-orang berkata: "Tidak, mengapa? Itu tidak akan berhasil. "
Tetapi Anda tidak bisa menjadi lebih baik tanpa mengubah apa pun.
Saya memiliki percakapan yang benar-benar tidak masuk akal dengan seorang karyawan, saya mengatakan kepadanya ide-ide saya untuk optimasi, yang dia katakan kepada saya:
- Ah, kamu tidak melihat apa yang kita miliki tahun lalu!
"Jadi apa?"
"Sekarang jauh lebih baik daripada sebelumnya."
"Jadi tidak mungkin lebih baik?"
- Kenapa?Pertanyaan bagus - mengapa? Seolah, jika sekarang lebih baik daripada sebelumnya, maka semuanya sudah cukup baik. Ini mengarah pada kurangnya tanggung jawab, yang pada prinsipnya benar-benar normal. Seperti yang saya katakan, tim teknis agak menyendiri. Perusahaan percaya bahwa mereka seharusnya, tetapi
tidak ada yang menetapkan standar . Mereka tidak pernah melihat SLA dalam dukungan teknis, jadi itu cukup “dapat diterima” untuk grup (dan itu paling mengejutkan saya):
- 12 detik mengunduh;
- 5-10 menit downtime setiap rilis;
- Pemecahan masalah kritis membutuhkan berhari-hari dan berminggu-minggu;
- kurangnya tugas 24x7 / on-call.
Tidak ada yang pernah mencoba bertanya mengapa kita tidak melakukannya dengan lebih baik, dan tidak ada yang menyadari bahwa itu tidak seharusnya.
Sebagai bonus, ada masalah lain:
kurangnya pengalaman . Para senior pergi, dan tim muda yang tersisa tumbuh di bawah rezim sebelumnya dan diracuni olehnya.
Untuk semua ini, orang juga takut gagal, tampak tidak kompeten. Ini diungkapkan dalam kenyataan bahwa, pertama,
dalam keadaan apa pun mereka tidak meminta bantuan . Berapa kali kami berbicara dalam kelompok dan secara individu, dan saya berkata: "Ajukan pertanyaan jika Anda tidak tahu bagaimana melakukan sesuatu." Saya percaya diri dan tahu bahwa saya dapat memecahkan masalah, tetapi itu akan memakan waktu. Karena itu, jika Anda dapat bertanya kepada seseorang yang tahu bagaimana menyelesaikannya dalam 10 menit, saya akan bertanya. Semakin sedikit pengalaman yang Anda miliki, semakin Anda takut untuk bertanya karena Anda pikir Anda akan dianggap tidak kompeten.
Ketakutan untuk mengajukan pertanyaan ini memanifestasikan dirinya dalam bentuk yang menarik. Misalnya, Anda bertanya: "Bagaimana kabarmu dengan tugas ini?" - "Tinggal beberapa jam lagi, aku sudah menyelesaikannya." Hari berikutnya Anda bertanya lagi, Anda mendapatkan jawaban bahwa semuanya baik-baik saja, tetapi ada satu masalah, itu akan siap pada akhir hari. Hari lain berlalu, dan sampai Anda menekan dinding dan memaksa seseorang untuk berbicara, semuanya berlanjut. Seseorang ingin menyelesaikan masalahnya sendiri, dia percaya bahwa jika dia tidak menyelesaikannya, itu akan menjadi kegagalan besar.
Itu sebabnya
pengembang melebih-lebihkan . Lelucon itu ketika mereka membahas tugas tertentu, mereka memberi saya sosok sedemikian rupa sehingga saya sangat terkejut. Untuk yang saya diberitahu bahwa dalam perkiraan pengembang termasuk waktu tiket akan kembali dari QA, karena mereka akan menemukan kesalahan di sana, dan waktu yang PR akan ambil, dan waktu yang orang-orang perlu melihatnya akan sibuk - yaitu, semuanya itu hanya mungkin.
Kedua, orang-orang yang takut terlihat tidak kompeten,
menganalisis dengan tidak perlu . Ketika Anda mengatakan apa yang sebenarnya perlu dilakukan, itu dimulai: "Tidak, tetapi bagaimana jika kita berpikir di sini?" Dalam hal ini, perusahaan kami tidak unik, itu adalah masalah standar anak muda.
Sebagai tanggapan, saya memperkenalkan praktik-praktik berikut:
- Aturannya adalah 30 menit. Jika dalam setengah jam Anda tidak dapat menyelesaikan masalah, minta seseorang untuk membantu. Ini berhasil dengan berbagai keberhasilan, karena orang masih tidak bertanya, tetapi setidaknya proses telah dimulai.
- Kecualikan semua hal, kecuali esensi , dalam memperkirakan jangka waktu tugas, yaitu, pertimbangkan hanya berapa lama untuk menulis kode.
- Pendidikan berkelanjutan bagi mereka yang terlalu menganalisis. Itu hanya pekerjaan konstan dengan orang-orang.
Hari ke enam puluh
Sementara saya melakukan semua ini, saatnya untuk mencari tahu anggaran. Tentu saja, saya menemukan banyak hal menarik di mana kami menghabiskan uang. Sebagai contoh, kami memiliki seluruh rak di pusat data yang terpisah, di mana ada satu server FTP yang digunakan oleh satu klien. Ternyata "... kami pindah, tetapi dia tetap, kami tidak mengubahnya." Itu 2 tahun yang lalu.
Yang menarik adalah tagihan layanan cloud. Saya yakin bahwa alasan utama besarnya tagihan untuk layanan cloud adalah pengembang yang memiliki akses tanpa batas ke server untuk pertama kalinya dalam hidup mereka. Mereka tidak perlu bertanya: "Tolong beri saya server uji," mereka dapat mengambil. Plus, pengembang selalu ingin membangun sistem yang sedemikian keren sehingga Facebook dengan Netflix iri.
Tetapi pengembang tidak memiliki pengalaman dalam membeli server dan kemampuan untuk menentukan ukuran server yang tepat, karena mereka tidak membutuhkannya sebelumnya. Dan biasanya mereka tidak sepenuhnya memahami perbedaan antara skalabilitas dan kinerja.
Hasil Inventarisasi:
- Kami meninggalkan satu pusat data.
- Mengakhiri kontrak dengan 3 layanan log. Karena kami memiliki 5 dari mereka - setiap pengembang yang mulai bermain dengan sesuatu mengambil yang baru.
- Mematikan 7 sistem AWS. Sekali lagi, tidak ada yang menghentikan proyek yang mati, mereka semua terus bekerja.
- Mengurangi biaya perangkat lunak sebanyak 6 kali.
Tujuh puluh hari kelima
Waktu berlalu, dan setelah dua setengah bulan saya harus bertemu dengan dewan direksi. Dewan direksi kami tidak lebih baik dan tidak lebih buruk dari yang lain, ia ingin mengetahui segalanya seperti semua dewan direksi. Orang-orang menginvestasikan uang dan ingin memahami seberapa banyak yang kami lakukan cocok dengan KPI yang ditetapkan.
Dewan Direksi menerima banyak informasi setiap bulan: jumlah pengguna, pertumbuhan mereka, layanan apa yang mereka gunakan dan bagaimana, produktivitas dan produktivitas, dan akhirnya, kecepatan pemuatan halaman rata-rata.
Satu-satunya masalah adalah saya percaya bahwa nilai rata-rata adalah kejahatan murni. Tetapi dewan direksi sangat sulit dijelaskan. Mereka terbiasa beroperasi dengan angka agregat, dan tidak, misalnya, dengan penyebaran waktu muat per detik.
Dalam hal ini, ada beberapa hal menarik. Sebagai contoh, saya mengatakan bahwa Anda perlu membagi lalu lintas antara server web individual tergantung pada jenis konten.

Yaitu, ColdFusion melewati Jetty dan nginx dan meluncurkan halaman. Dan gambar, JS dan CSS melewati nginx terpisah dengan konfigurasi mereka sendiri. Ini adalah praktik standar yang saya
tulis beberapa tahun yang lalu. , … 200 .
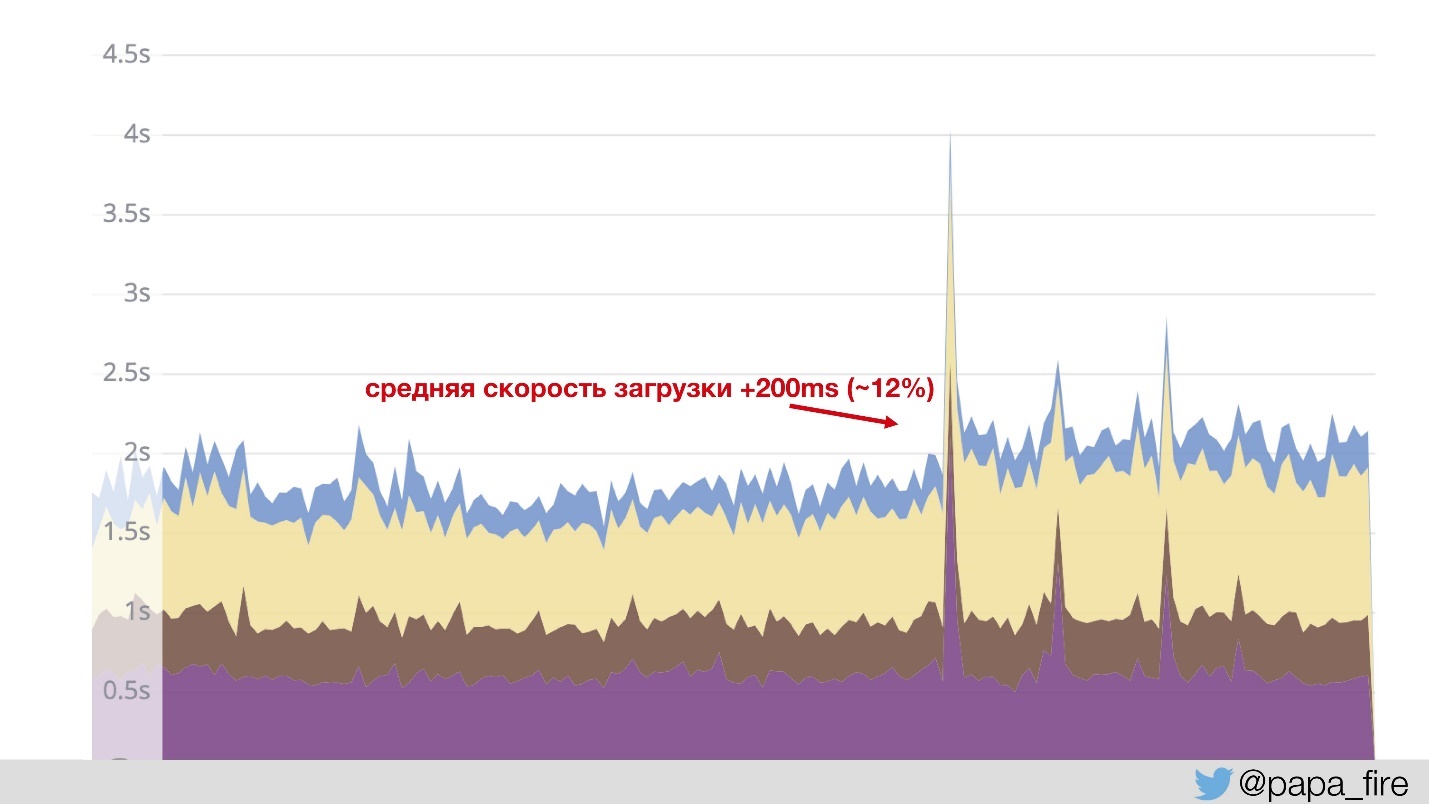
, , Jetty. — . , , , - 12%?
, — . , , .

— , . . - , .
Kesimpulan
. , , , . , ,
SEQUENCE .
nextID , .
, . , , — .

. , :
.
twitter ,
facebook medium .
legacy : , . c DevOpsConf , . youtube , , DevOps.