
Kita menjadi apa yang kita lihat. Pertama kita membentuk alat, lalu alat membentuk kita.
—Marshal McLuhan
Saya ingin mengucapkan terima kasih dan terima kasih kepada teman baik saya Ricardo Sueiras atas ulasannya, kontribusi dan untuk tidak membiarkan saya meninggalkan artikel ini belum selesai. Ricardo, kamu hanya legenda!
Penting untuk diingat bahwa chaos engineering bukanlah saat Anda melepaskan monyet dan memasuki kegagalan tanpa pandang bulu. Rekayasa kekacauan adalah teknik eksperimen formal yang terdefinisi dengan baik.
"Rekayasa kekacauan melibatkan pengamatan yang cermat, skeptisisme yang parah tentang objek pengamatan, karena asumsi kognitif mengubah interpretasi hasil. Teknik ini melibatkan perumusan hipotesis melalui induksi berdasarkan pengamatan yang sama; pengujian eksperimental dan pengukuran berdasarkan kesimpulan yang dibuat dari hipotesis yang sama; penyesuaian atau penolakan hipotesis berdasarkan hasil eksperimen "
—Wikipedia
Rekayasa kekacauan dimulai dengan memahami keadaan stabil dari sistem yang Anda hadapi, kemudian merumuskan hipotesis, dan akhirnya sebuah eksperimen yang menegaskan hal itu, membantu meningkatkan margin keamanan sistem.
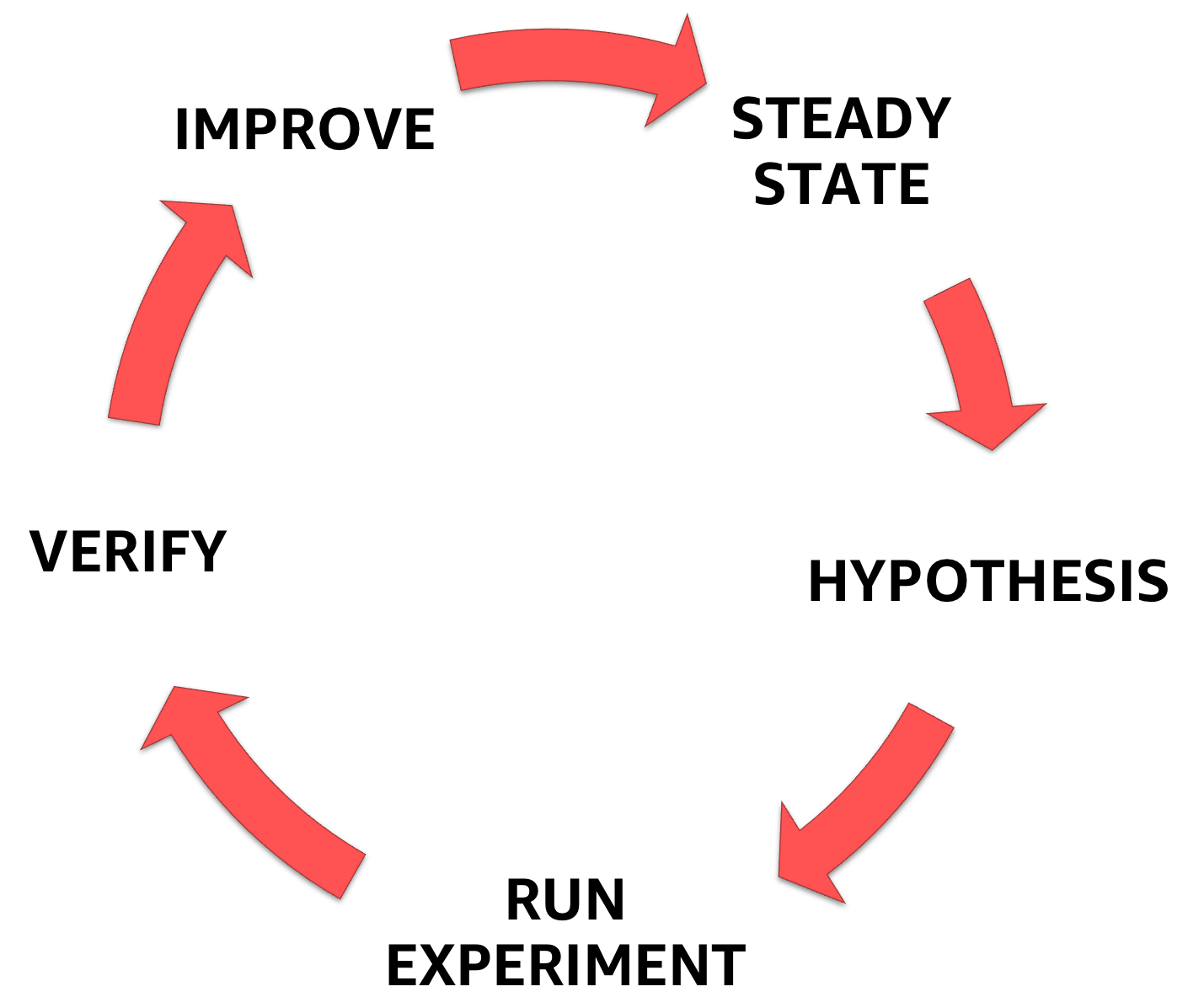
Tahapan Rekayasa Kekacauan
Pada bagian pertama dari serangkaian artikel, saya memperkenalkan chaos engineering dan mendiskusikan setiap langkah metodologi yang dijelaskan di atas.
Pada bagian kedua , saya memeriksa bidang-bidang di mana Anda perlu berinvestasi ketika merancang eksperimen tentang rekayasa kekacauan, dan bagaimana memilih hipotesis yang tepat.
Pada bagian ketiga ini, saya akan fokus pada percobaan itu sendiri dan menyajikan pilihan alat dan metode yang mencakup berbagai kegagalan.
Daftar ini tidak lengkap, tetapi untuk memulainya, dan untuk memberikan makanan untuk dipikirkan, itu sudah cukup.
Pengenalan kegagalan - untuk apa dan untuk apa?
Kegagalan digunakan untuk memverifikasi bahwa respons sistem memenuhi spesifikasi dalam kondisi beban normal. Untuk pertama kalinya teknik ini digunakan ketika kegagalan diperkenalkan pada tingkat "besi" - pada tingkat kontak, dengan mengubah sinyal listrik pada perangkat.
Dalam pemrograman, pengenalan kegagalan membantu meningkatkan stabilitas sistem perangkat lunak dan memungkinkan Anda untuk mengoreksi kelemahan dalam perlawanan terhadap potensi kegagalan dalam sistem. Ini disebut troubleshooting. Ini juga membantu untuk menilai kerusakan akibat kegagalan - mis. radius kerusakan, bahkan sebelum kegagalan terjadi di lingkungan produksi. Ini disebut prediksi kesalahan.
Pengenalan kegagalan memiliki beberapa manfaat utama, membantu:
- Memahami dan mempraktikkan respons terhadap kecelakaan dan insiden.
- memahami efek dari kegagalan nyata.
- memahami efektivitas dan keterbatasan mekanisme toleransi kesalahan.
- menghilangkan kesalahan desain dan mendeteksi titik kegagalan umum.
- memahami dan meningkatkan kemampuan pengamatan sistem.
- memahami radius kegagalan kegagalan dan mempersempitnya.
- memahami penyebaran kesalahan antar komponen sistem.
Kategori Kegagalan
Ada 5 kategori pengenalan kegagalan: pada tingkat (1) sumber daya; (2) jaringan dan dependensi; (3) aplikasi, proses, dan layanan; (4) infrastruktur; dan (5) tingkat manusia **.
Selanjutnya, saya akan memeriksa masing-masing kategori dan memberikan contoh memperkenalkan kegagalan untuk masing-masing kategori. Saya juga akan mempertimbangkan contoh memperkenalkan kegagalan dan instrumen orkestrasi all-in-one.
** Penting! Dalam posting ini saya tidak menyentuh pengenalan kegagalan di tingkat manusia, tetapi saya akan mempertimbangkannya sebagai berikut.
1 - Pengenalan kegagalan di tingkat sumber daya, alias kurangnya sumber daya.
Ya, teknologi cloud telah mengajarkan kita bahwa sumber daya hampir tidak terbatas, tetapi saya segera mengecewakan Anda: mereka tidak terbatas. Mesin virtual, wadah, fungsi, dll. - terlepas dari abstraksi, sumber daya akhirnya berakhir. Melampaui batas yang diijinkan, kehabisan sumber daya maksimum disebut kelelahan.

Kurangnya sumber daya meniru penolakan serangan layanan , tetapi bukan serangan biasa, untuk menyusup ke server yang dimaksud. Pengenalan kegagalan ini mungkin tersebar luas, karena, mungkin, tidak sulit untuk digunakan.
Menguras sumber daya CPU, memori, dan I / O
Salah satu alat favorit saya adalah stress-ng, korespondensi alat pengujian stres asli , yang ditulis oleh Amos Waterland .
Dengan stress-ng, kesalahan dapat dimasukkan dengan memuat berbagai subsistem fisik komputer, serta mengendalikan antarmuka inti sistem menggunakan tes stres. Tes stres berikut tersedia: CPU, cache CPU, perangkat, I / O, interupsi, sistem file, memori, jaringan, OS, pipa, penjadwal, dan VM. Halaman manual menyertakan deskripsi lengkap dari semua tes stres yang tersedia, dan hanya ada 220 di antaranya!
Di bawah ini adalah beberapa contoh praktis tentang bagaimana menggunakan stres:
Beban pada CPU matrixprod memberikan campuran operasi yang tepat dengan memori, cache dan floating point. Ini mungkin. Cara terbaik untuk menghangatkan CPU dengan baik.
❯ stress-ng —-cpu 0 --cpu-method matrixprod -t 60s
Beban iomix-bytes menulis N-byte untuk setiap iomix handler iomix ; Standarnya adalah 1 GB dan ideal untuk melakukan tes stres I / O. Dalam contoh ini, saya akan mengatur 80% ruang kosong pada sistem file.
❯ stress-ng --iomix 1 --iomix-bytes 80% -t 60s
vm-bytes bagus untuk tes stres memori. Dalam contoh ini, stress-ng menjalankan 9 stress test dari memori virtual, yang secara bersamaan mengkonsumsi 90% dari memori yang tersedia per jam. Dengan demikian, setiap pengujian rambut menghabiskan 10% dari memori yang tersedia.
❯ stress-ng --vm 9 --vm-bytes 90% -t 60s
Ruang diska pada hard drive
dd adalah utilitas baris perintah yang dikompilasi untuk mengonversi dan menyalin file. Namun, dd dapat membaca dan / atau menulis dari file-file perangkat khusus seperti /dev/zero dan /dev/random untuk tugas-tugas seperti mencadangkan sektor boot dari hard disk dan mendapatkan sejumlah data acak yang tetap. Dengan demikian, ini dapat digunakan untuk memperkenalkan kegagalan pada server dan mensimulasikan overflow disk. Apakah file log Anda membanjiri server dan menjatuhkan aplikasi? Jadi, dd akan membantu - dan itu akan menyakitkan!
Gunakan dd dengan sangat hati-hati. Masukkan perintah yang salah - dan data pada hard akan dihapus, dihancurkan atau ditimpa!
❯ dd if=/dev/urandom of=/burn bs=1M count=65536 iflag=fullblock &
Perlambatan API Aplikasi
Kinerja, ketahanan, dan skalabilitas API sangat penting. API sangat penting untuk membangun aplikasi dan mengembangkan bisnis Anda.
Pengujian beban adalah cara yang bagus untuk menguji aplikasi Anda sebelum mulai diproduksi. Ini juga merupakan metode beban stres yang keren, karena sering mengungkapkan pengecualian dan batasan yang, dalam keadaan lain, akan tetap tidak terlihat sebelum bertemu dengan lalu lintas nyata.
wrk adalah alat pembandingan HTTP yang memberikan tekanan signifikan pada sistem. Saya terutama ingin menguji pemeriksaan aksesibilitas API, terutama ketika menyangkut pemeriksaan kinerja , karena mereka mengungkapkan banyak hal mengenai keputusan desain di tingkat kode pengembang: bagaimana cara cache dikonfigurasikan? Bagaimana batas kecepatan diterapkan? Apakah sistem memprioritaskan pemeriksaan kesehatan terkait penyeimbang beban?
Di sinilah untuk memulai:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/health
Perintah ini memulai 12 utas dan membuat 400 koneksi HTTP terbuka selama 20 detik.
2 - Memperkenalkan kegagalan dan ketergantungan tingkat jaringan
Buku Peter Deutsch , The Eight Fallacy of Distributed Computing, adalah kumpulan asumsi yang dibuat pengembang saat merancang sistem terdistribusi. Dan kemudian jawabannya terbang dalam bentuk tidak dapat diaksesnya, dan Anda harus mengulang semuanya. Asumsi yang keliru ini adalah:
- Jaringannya andal.
- Penundaannya adalah 0.
- Bandwidth tidak terbatas.
- Jaringan aman.
- Topologi tidak berubah.
- Hanya ada satu administrator.
- Biaya transfer 0.
- Jaringannya homogen.
Daftar ini adalah titik awal yang baik untuk memilih failover jika Anda menguji untuk melihat apakah sistem terdistribusi Anda dapat menangani kegagalan jaringan.
Memperkenalkan latensi jaringan, kehilangan, dan pemadaman
Memperkenalkan latensi jaringan, kehilangan atau gangguan
tc ( traffic control ) adalah alat baris perintah Linux yang digunakan untuk mengkonfigurasi penjadwal batch kernel Linux. Ini mendefinisikan bagaimana paket-paket di-antri untuk pengiriman dan penerimaan di antarmuka jaringan. Operasi termasuk antrian, definisi kebijakan, klasifikasi, perencanaan, pembentukan, dan kerugian.
tc dapat digunakan untuk mensimulasikan penundaan dan kehilangan paket untuk aplikasi UDP atau TCP atau untuk membatasi penggunaan bandwidth layanan tertentu - untuk mensimulasikan kondisi lalu lintas Internet.
- Pengenalan penundaan 100 ms
#Start ❯ tc qdisc add dev etho root netem delay 100ms #Stop ❯ tc qdisc del dev etho root netem delay 100ms
- Pengenalan penundaan 100 ms dengan delta 50 ms
#Start ❯ tc qdisc add dev eth0 root netem delay 100ms 50ms #Stop ❯ tc qdisc del dev eth0 root netem delay 100ms 50ms
- kerusakan 5% dari paket jaringan
#Start ❯ tc qdisc add dev eth0 root netem corrupt 5% #Stop ❯ tc qdisc del dev eth0 root netem corrupt 5%
- Paket loss 7% dengan korelasi 25 persen
#Start ❯ tc qdisc add dev eth0 root netem loss 7% 25% #Stop ❯ tc qdisc del dev eth0 root netem loss 7% 25%
Penting! 7% sudah cukup untuk aplikasi TCP tidak turun.
Bermain dengan "/ etc / hosts" - tabel pencarian statis untuk nama host
/etc/hosts adalah file teks sederhana yang mengaitkan alamat IP dengan nama host, satu baris setiap kali. Setiap node memerlukan satu baris yang berisi informasi berikut:
IP_address canonical_hostname [aliases...]
File host adalah salah satu dari beberapa sistem yang mengakses node jaringan pada jaringan komputer dan menerjemahkan nama host yang dipahami orang ke alamat IP. Dan ya, Anda dapat menebaknya: berkat itu, mudah untuk menipu komputer. Berikut ini beberapa contohnya:
- Blokir akses ke DynamoDB API untuk instance EC2
#Start # make copy of /etc/hosts to /etc/host.back ❯ cp /etc/hosts /etc/hosts.back ❯ echo "127.0.0.1 dynamodb.us-east-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-east-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-west-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.eu-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.eu-north-1.amazonaws.com" >> /etc/hosts #Stop # copy back the old version /etc/hosts ❯ cp /etc/hosts.back /etc/hosts
- Blokir akses ke API EC2 dari instance EC2
#Start # make copy of /etc/hosts to /etc/host.back ❯ cp /etc/hosts /etc/hosts.back ❯ echo "127.0.0.1 ec2.us-east-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-east-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-west-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.eu-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.eu-north-1.amazonaws.com" >> /etc/hosts #Stop # copy back the old version /etc/hosts ❯ cp /etc/hosts.back /etc/hosts
Tonton langsung: pertama, API EC2 tersedia dan ec2 describe-instances berhasil kembali.
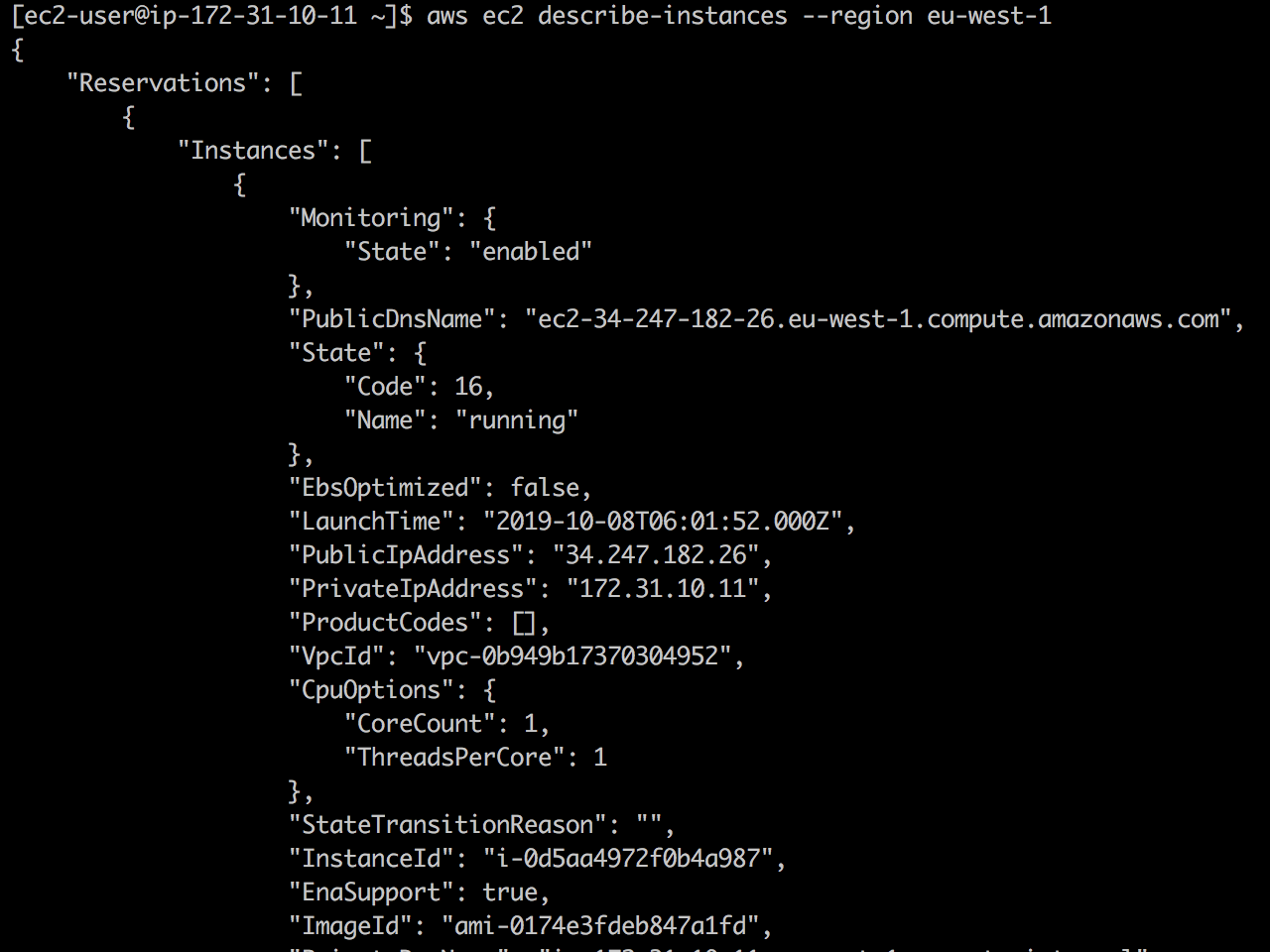
Setelah saya menambahkan 127.0.01 ec2.eu-west-1.amazonaws.com ke /etc/hosts , dan panggilan EC2 API turun.

Tentu saja, ini berfungsi untuk semua API AWS.
Saya akan menceritakan lelucon tentang DNS ...

... tapi, saya khawatir, itu hanya akan sampai pada hari kedua. Maksudku, setelah 24 jam.
Pada 21 Oktober 2016, karena serangan DDoS Dyn, sejumlah platform dan layanan yang layak di Eropa dan Amerika Utara tidak tersedia. Menurut laporan ThousandEyes pada kinerja DNS di seluruh dunia pada tahun 2018 , 60% dari perusahaan dan penyedia SaaS masih mengandalkan satu sumber penyedia DNS dan, dengan demikian, menjadi rentan terhadap kegagalan DNS. Dan karena tidak akan ada Internet tanpa DNS, akan bagus untuk mensimulasikan kegagalan DNS untuk mengevaluasi ketahanan Anda terhadap kegagalan DNS berikutnya.
Blackholing adalah metode di mana mereka secara tradisional mengurangi kerusakan serangan DDoS . Lalu lintas jaringan yang buruk dialihkan ke lubang hitam dan dibuang untuk membatalkan. Versi /dev/null untuk bekerja di jaringan :-) Anda dapat menggunakannya untuk mensimulasikan hilangnya lalu lintas jaringan atau protokol dari DNS yang sama, katakanlah.
Untuk tugas ini, Anda memerlukan alat iptables , yang digunakan untuk mengkonfigurasi, memelihara dan memverifikasi paket IP di kernel Linux.
Untuk mendapatkan lalu lintas DNS melalui lubang hitam, coba ini:
#Start ❯ iptables -A INPUT -p tcp -m tcp --dport 53 -j DROP ❯ iptables -A INPUT -p udp -m udp --dport 53 -j DROP #Stop ❯ iptables -D INPUT -p tcp -m tcp --dport 53 -j DROP ❯ iptables -D INPUT -p udp -m udp --dport 53 -j DROP
Pengenalan kegagalan menggunakan Toxiproxy.
Alat-alat Linux seperti tc dan iptables satu - tetapi bukan satu-satunya - masalah serius. Mereka memerlukan izin root untuk menjalankan, dan ini menciptakan masalah untuk beberapa organisasi dan lingkungan. Mohon cinta dan budi - Toxiproxy !
Toxiproxy adalah proksi TCP open source yang dikembangkan oleh tim insinyur Shopify . Ini membantu mensimulasikan kondisi jaringan dan sistem yang kacau atau sistem nyata. Tempatkan di antara berbagai komponen arsitektur seperti yang ditunjukkan di bawah ini.
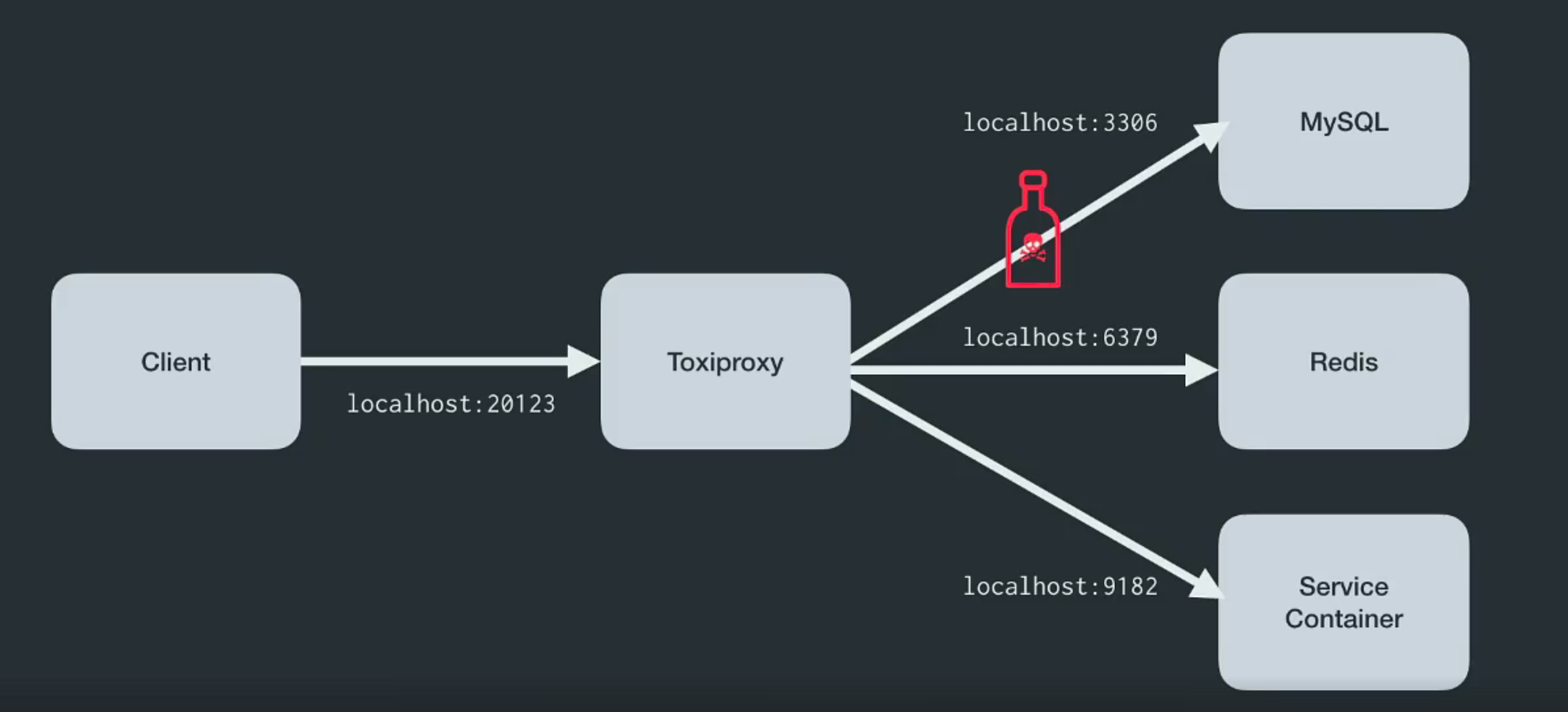
Itu dibuat khusus untuk pengujian, CI, dan lingkungan pengembangan, dan memperkenalkan kebingungan yang telah ditentukan atau acak yang dikendalikan melalui pengaturan. Toxiproxy menggunakan racun untuk memanipulasi hubungan antara klien dan kode pengembang, dan itu dapat dikonfigurasi melalui API HTTP . Dan baginya dalam kit ada racun yang cukup untuk memulai.
Contoh berikut menunjukkan bagaimana Toxiproxy bekerja dengan kode klien toksik dengan memperkenalkan penundaan 1000 ms dalam koneksi antara klien Redis saya, redis-cli, dan Redis itu sendiri.
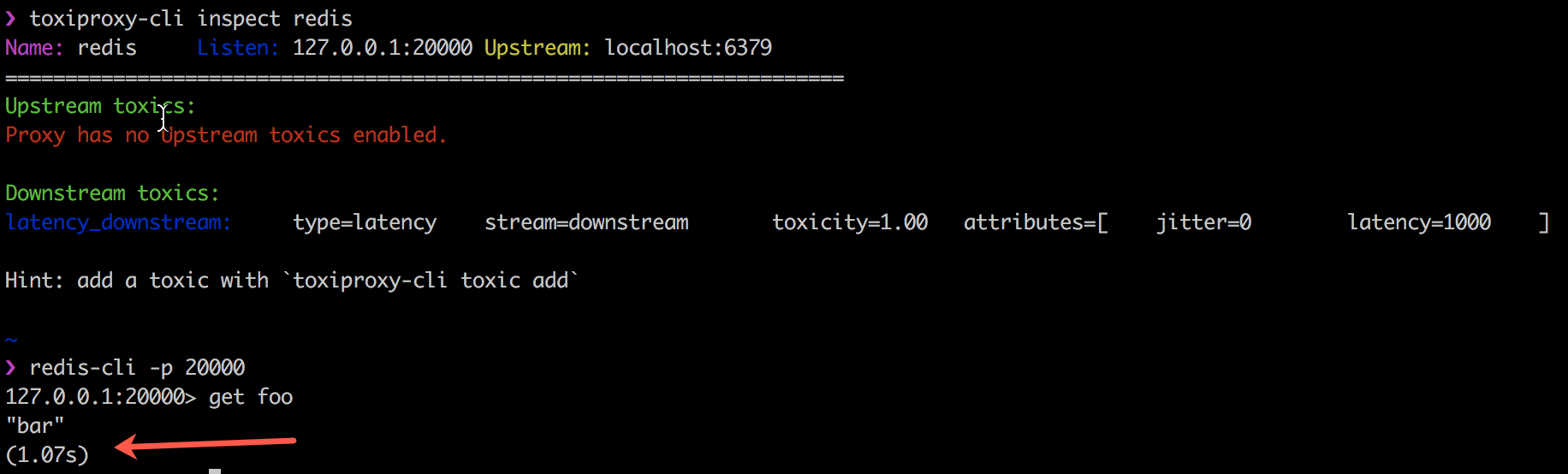
Toxiproxy telah berhasil digunakan oleh Shopify di semua lingkungan produksi dan pengembangan sejak Oktober 2014. Informasi lebih lanjut ada di blog mereka.
3 - Pengenalan kegagalan pada tingkat aplikasi, proses dan layanan
Perangkat lunak sedang jatuh. Ini fakta. Dan apa yang kamu lakukan? Haruskah saya masuk melalui SSH di server dan memulai kembali proses yang gagal? Sistem kontrol proses menyediakan fungsi kontrol keadaan atau keadaan perubahan tipe mulai, berhenti, restart. Sistem kontrol biasanya digunakan untuk memastikan kontrol proses yang stabil. systemd hanyalah alat seperti itu, menyediakan batu bata kontrol proses dasar untuk Linux. Supervisord menawarkan kontrol beberapa proses pada sistem operasi seperti UNIX.
Saat Anda menggunakan aplikasi, Anda harus menggunakan alat ini. Ini tentu praktik yang baik untuk menguji kerusakan dari membunuh proses kritis. Pastikan Anda menerima peringatan dan proses memulai ulang secara otomatis.
- bunuh proses Java
❯ pkill -KILL -f java #Alternative ❯ pkill -f 'java -jar'
- bunuh proses Python
❯ pkill -KILL -f python
Tentu saja, Anda dapat menggunakan perintah pkill untuk membunuh beberapa proses lain yang berjalan pada sistem.
Memperkenalkan Kegagalan Database
Jika ada pesan kegagalan yang operator tidak suka menerima, maka ini adalah pesan yang terkait dengan kegagalan basis data. Data sepadan dengan bobotnya dalam emas, dan karenanya, setiap kali basis data macet, risiko kehilangan data pelanggan meningkat.

Ini akan menjadi perawatan yang mudah. Dan-dan-dan-dan-dan-begitu ... semuanya telah jatuh
Terkadang kemampuan untuk memulihkan data dan membawa database ke dalam kondisi kerja secepat mungkin menentukan masa depan perusahaan. Sayangnya, itu juga tidak selalu mudah untuk mempersiapkan berbagai mode kegagalan database - dan banyak dari mereka akan muncul hanya di lingkungan produksi.
Namun, jika Anda menggunakan Amazon Aurora , Anda bisa menguji ketahanan cluster database Amazon Aurora untuk kegagalan menggunakan permintaan failover .
Amazon Aurora Crash Pendahuluan
Permintaan kegagalan dikeluarkan sebagai perintah SQL ke instance Amazon Aurora dan memungkinkan Anda untuk menjadwalkan simulasi dari salah satu peristiwa berikut:
- Gagal menulis contoh DB.
- Replika Aurora.
- Kerusakan disk.
- Disk overload.
Saat mengirim permintaan untuk kegagalan, Anda juga harus menentukan jumlah waktu selama peristiwa kegagalan akan disimulasikan.
- Penyebab Kegagalan Amazon Aurora Instance:
ALTER SYSTEM CRASH [ INSTANCE | DISPATCHER | NODE ];
- mensimulasikan kegagalan Aurora Replica:
ALTER SYSTEM SIMULATE percentage PERCENT READ REPLICA FAILURE [ TO ALL | TO "replica name" ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
- mensimulasikan kegagalan disk untuk kelompok basis data Aurora:
ALTER SYSTEM SIMULATE percentage PERCENT DISK FAILURE [ IN DISK index | NODE index ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
- mensimulasikan kegagalan disk untuk kelompok basis data Aurora:
ALTER SYSTEM SIMULATE percentage PERCENT DISK CONGESTION BETWEEN minimum AND maximum MILLISECONDS [ IN DISK index | NODE index ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
Kecelakaan di dunia aplikasi tanpa server
Kegagalan bisa menjadi tantangan nyata jika Anda menggunakan komponen tanpa server, karena layanan tanpa server seperti AWS Lambda tidak secara bawaan mendukung failover.
Memperkenalkan Kegagalan Lambda
Untuk memahami masalah ini, saya menulis perpustakaan python kecil dan lapisan lambda - untuk memperkenalkan kegagalan pada AWS Lambda . Saat ini, keduanya mendukung penundaan, kesalahan, pengecualian, dan pengenalan kode kesalahan HTTP. Kegagalan dicapai dengan mengkonfigurasi AWS SSM Parameter Store sebagai berikut:
{ "isEnabled": true, "delay": 400, "error_code": 404, "exception_msg": "I really failed seriously", "rate": 1 }
Anda dapat menambahkan dekorator python ke fungsi handler untuk memperkenalkan kegagalan.
- melempar pengecualian:
@inject_exception def handler_with_exception(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_exception('foo', 'bar') Injecting exception_type <class "Exception"> with message I really failed seriously a rate of 1 corrupting now Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/.../chaos_lambda.py", line 316, in wrapper raise _exception_type(_exception_msg) Exception: I really failed seriously
- masukkan kode kesalahan "HTTP tidak valid":
@inject_statuscode def handler_with_statuscode(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_statuscode('foo', 'bar') Injecting Error 404 at a rate of 1 corrupting now {'statusCode': 404, 'body': 'Hello from Lambda!'}
- masukkan penundaan:
@inject_delay def handler_with_delay(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_delay('foo', 'bar') Injecting 400 of delay with a rate of 1 Added 402.20ms to handler_with_delay {'statusCode': 200, 'body': 'Hello from Lambda!'}
Klik di sini untuk mempelajari lebih lanjut tentang perpustakaan python ini.
Memperkenalkan Kegagalan Lambda Melalui Batasan Concurrency
Lambda secara default, untuk alasan keamanan, menyesuaikan eksekusi paralel dari semua fungsi di wilayah tertentu per akun. Eksekusi paralel mengacu pada beberapa eksekusi kode fungsi yang terjadi setiap saat. Mereka digunakan untuk skala panggilan fungsi ke permintaan masuk. Tapi itu bisa berfungsi untuk tujuan yang berlawanan: menghentikan eksekusi Lambda.
❯ aws lambda put-function-concurrency --function-name <value> --reserved-concurrent-executions 0
Perintah ini akan mengurangi concurrency menjadi nol, menyebabkan kegagalan kueri dengan kesalahan seperti "pengereman" - DTC 429 .
Thundra - jejak transmisi tanpa server
Thundra adalah alat pemantauan aplikasi tanpa server yang memiliki kemampuan bawaan untuk menyuntikkan kegagalan ke dalam aplikasi tanpa server. Dia membuat pembungkus pembungkus untuk memperkenalkan kegagalan seperti "tidak ada penangan kesalahan" untuk operasi dengan DynamoDB, "tidak ada kesalahan netralisasi" untuk sumber data, atau "tidak ada batas waktu dalam permintaan HTTP keluar". Saya belum mencobanya sendiri, tetapi dalam posting ini untuk kepengarangan Yan Chui dan dalam video yang luar biasa ini oleh Marsha Villalba, prosesnya dijelaskan dengan baik. Itu terlihat menjanjikan.
Dan dalam kesimpulan bagian tentang aplikasi tanpa server, saya akan mengatakan bahwa Yan Chui memiliki artikel yang bagus tentang kesulitan rekayasa kekacauan dalam kaitannya dengan aplikasi tanpa server. Saya merekomendasikan semua orang untuk membacanya.
4 - Pengenalan kegagalan di tingkat infrastruktur
Semuanya dimulai dengan pengenalan kegagalan di tingkat infrastruktur - untuk Amazon dan Netflix. Pengenalan kegagalan pada tingkat infrastruktur - dari memutuskan seluruh pusat data hingga menghentikan secara acak - mungkin yang paling mudah untuk diterapkan.
Dan, tentu saja, contoh " monyet kekacauan " muncul di benak pertama.
Menghentikan instance EC2 yang dipilih secara acak di zona ketersediaan tertentu.
Dalam masa pertumbuhannya, Netflix ingin memperkenalkan aturan arsitektur yang tangguh. Dia mengerahkan "chaos monkey" sebagai salah satu aplikasi AWS pertama yang menginstal microservices stateless berskala - dalam arti bahwa setiap instance dapat dihancurkan atau diganti secara otomatis tanpa menyebabkan hilangnya status sama sekali. The Chaos Monkey memastikan bahwa tidak ada yang melanggar aturan ini.
Skenario berikutnya - mirip dengan "monyet kekacauan" - adalah untuk menghentikan setiap kejadian secara acak, di zona ketersediaan khusus dalam wilayah yang sama.
❯ stop_random_instance(az="eu-west-1a", tag_name="chaos", tag_value="chaos-ready", region="eu-west-1")
import boto3 import random REGION = 'eu-west-1' def stop_random_instance(az, tag_name, tag_value, region=REGION): ''' >>> stop_random_instance(az="eu-west-1a", tag_name='chaos', tag_value="chaos-ready", region='eu-west-1') ['i-0ddce3c81bc836560'] ''' ec2 = boto3.client("ec2", region_name=region) paginator = ec2.get_paginator('describe_instances') pages = paginator.paginate( Filters=[ { "Name": "availability-zone", "Values": [ az ] }, { "Name": "tag:" + tag_name, "Values": [ tag_value ] } ] ) instance_list = [] for page in pages: for reservation in page['Reservations']: for instance in reservation['Instances']: instance_list.append(instance['InstanceId']) print("Going to stop any of these instances", instance_list) selected_instance = random.choice(instance_list) print("Randomly selected", selected_instance) response = ec2.stop_instances(InstanceIds=[selected_instance]) return response
Apakah Anda tag_name tag_value dan tag_value ? Hal-hal kecil seperti itu akan mencegah kegagalan contoh yang salah. # tanpa belajar

Dan ya ... restart basis data - bagus [bukan, bukan itu contoh]
5 - Pengenalan kegagalan dan alat orkestrasi all-in-one
Kemungkinan Anda tersesat dalam banyak alat. Untungnya, ada beberapa perkenalan penolakan dan alat orkestrasi yang mencakup sebagian besar dari mereka dan mudah digunakan.
Salah satu alat favorit saya adalah Chaos Toolkit , platform rekayasa kekacauan open source yang secara komersial didukung oleh tim ChaosIQ yang hebat. Berikut adalah beberapa di antaranya: Russ Miles , Sylvain Helleguarch dan Marc Parrien .
Chaos Toolkit mendefinisikan API deklaratif dan dapat diperluas untuk melakukan eksperimen rekayasa kekacauan dengan mudah. Ini termasuk driver untuk AWS, Google Cloud Engine, Microsoft Azure, Cloud Foundry, Humino, Prometheus, dan GREMLIN.
Ekstensi adalah serangkaian pemeriksaan dan tindakan yang digunakan untuk eksperimen sebagai berikut: kami menghentikan instance yang dipilih secara acak di zona ketersediaan tertentu jika tag-key berisi chaos-ready .
{ "version": "1.0.0", "title": "What is the impact of randomly terminating an instance in an AZ", "description": "terminating EC2 instance at random should not impact my app from running", "tags": ["ec2"], "configuration": { "aws_region": "eu-west-1" }, "steady-state-hypothesis": { "title": "more than 0 instance in region", "probes": [ { "provider": { "module": "chaosaws.ec2.probes", "type": "python", "func": "count_instances", "arguments": { "filters": [ { "Name": "availability-zone", "Values": ["eu-west-1c"] } ] } }, "type": "probe", "name": "count-instances", "tolerance": [0, 1] } ] }, "method": [ { "type": "action", "name": "stop-random-instance", "provider": { "type": "python", "module": "chaosaws.ec2.actions", "func": "stop_instance", "arguments": { "az": "eu-west-1c" }, "filters": [ { "Name": "tag-key", "Values": ["chaos-ready"] } ] }, "pauses": { "after": 60 } } ], "rollbacks": [ { "type": "action", "name": "start-all-instances", "provider": { "type": "python", "module": "chaosaws.ec2.actions", "func": "start_instances", "arguments": { "az": "eu-west-1c" }, "filters": [ { "Name": "tag-key", "Values": ["chaos-ready"] } ] } } ] }
Melakukan percobaan di atas sederhana:
❯ chaos run experiment_aws_random_instance.json
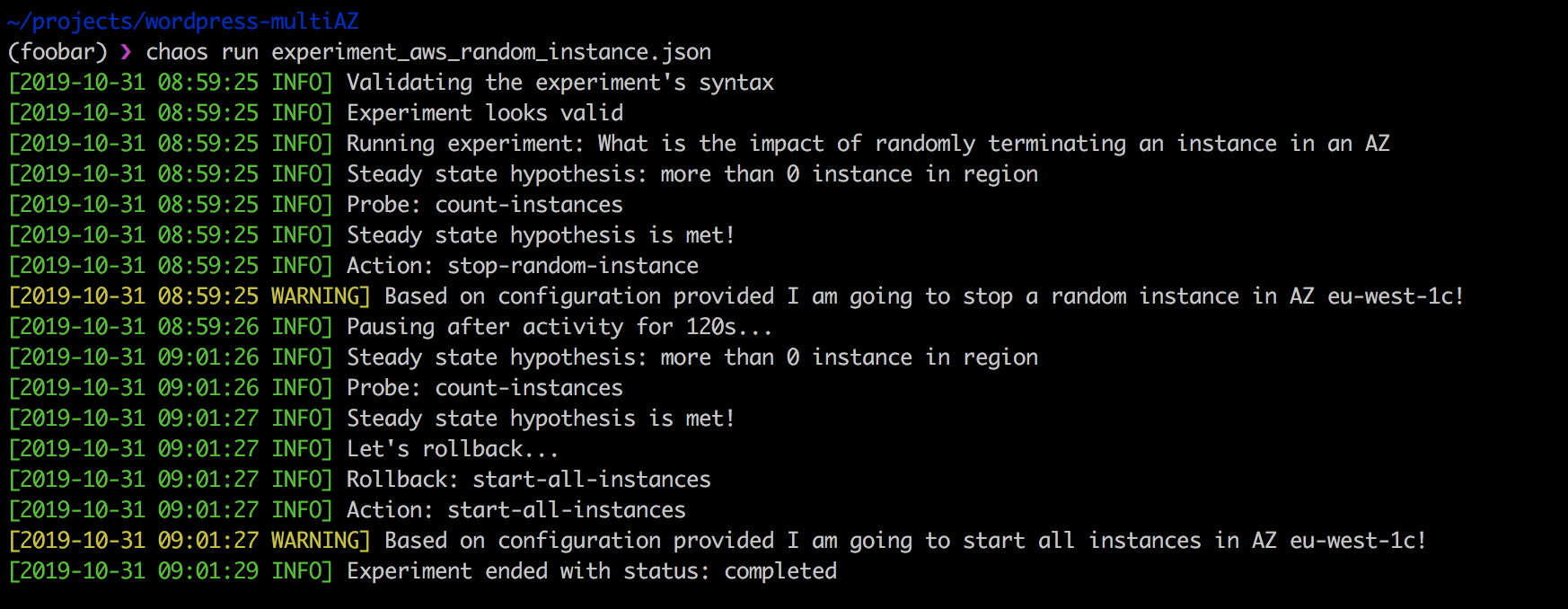
Kekuatan dari Chaos Toolkit adalah, pertama, ini adalah open source dan dapat disesuaikan dengan kebutuhan Anda. Kedua, sangat cocok dengan pipa CI / CD dan mendukung pengujian kekacauan terus menerus.
Kelemahan dari Chaos Toolkit adalah butuh waktu untuk menguasainya. Selain itu, tidak ada eksperimen yang sudah jadi di dalamnya, jadi Anda harus menulis sendiri. Namun, saya akrab dengan tim di ChaosIQ, yang bekerja tanpa lelah, memahami tugas ini.
GREMLIN
Favorit saya yang lain adalah GREMLIN. Ini berisi serangkaian mode komprehensif untuk memperkenalkan kegagalan dalam alat sederhana dengan antarmuka pengguna yang intuitif. Kekacauan Seperti Layanan.
GREMLIN mendukung pengenalan kegagalan pada level sumber daya, jaringan dan kueri , memungkinkan Anda untuk bereksperimen dengan cepat dengan seluruh sistem, termasuk dengan perangkat keras, berbagai penyedia cloud, lingkungan kemas, termasuk Kubernetes, aplikasi dan, sampai batas tertentu, aplikasi tanpa server.
Plus bonus - orang-orang dari GREMLIN adalah orang hebat yang menulis konten hebat untuk blog dan selalu siap membantu! Berikut adalah beberapa di antaranya: Matthew , Colton , Tammy , Rich , Ana dan HML .
GREMLIN tidak memiliki tempat untuk digunakan:
Pertama masuk ke aplikasi GREMLIN dan pilih "Buat Serangan".
Tetapkan tujuan - contoh.
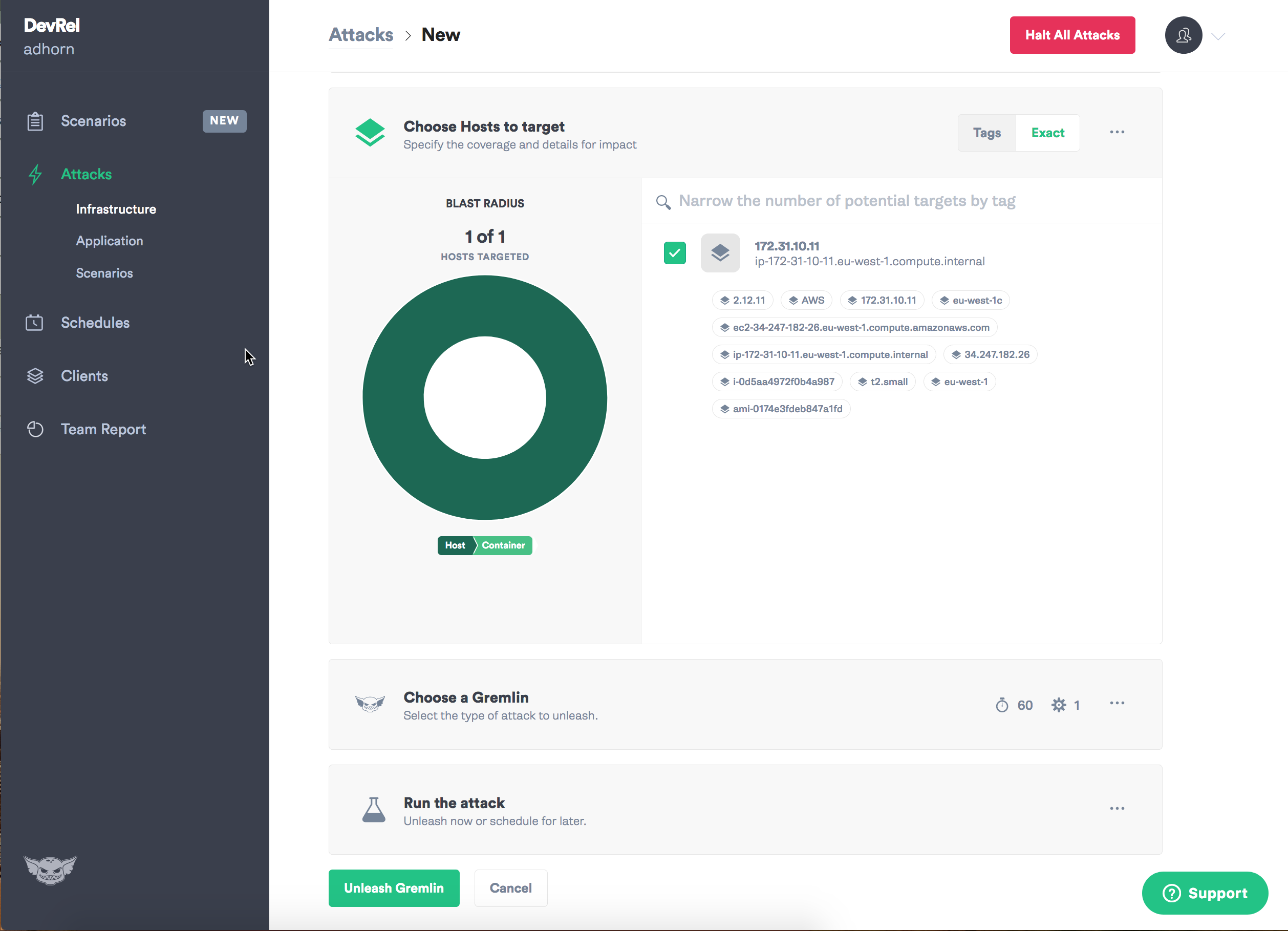
Pilih jenis kegagalan yang ingin Anda perkenalkan, dan mungkin kekacauan mulai!
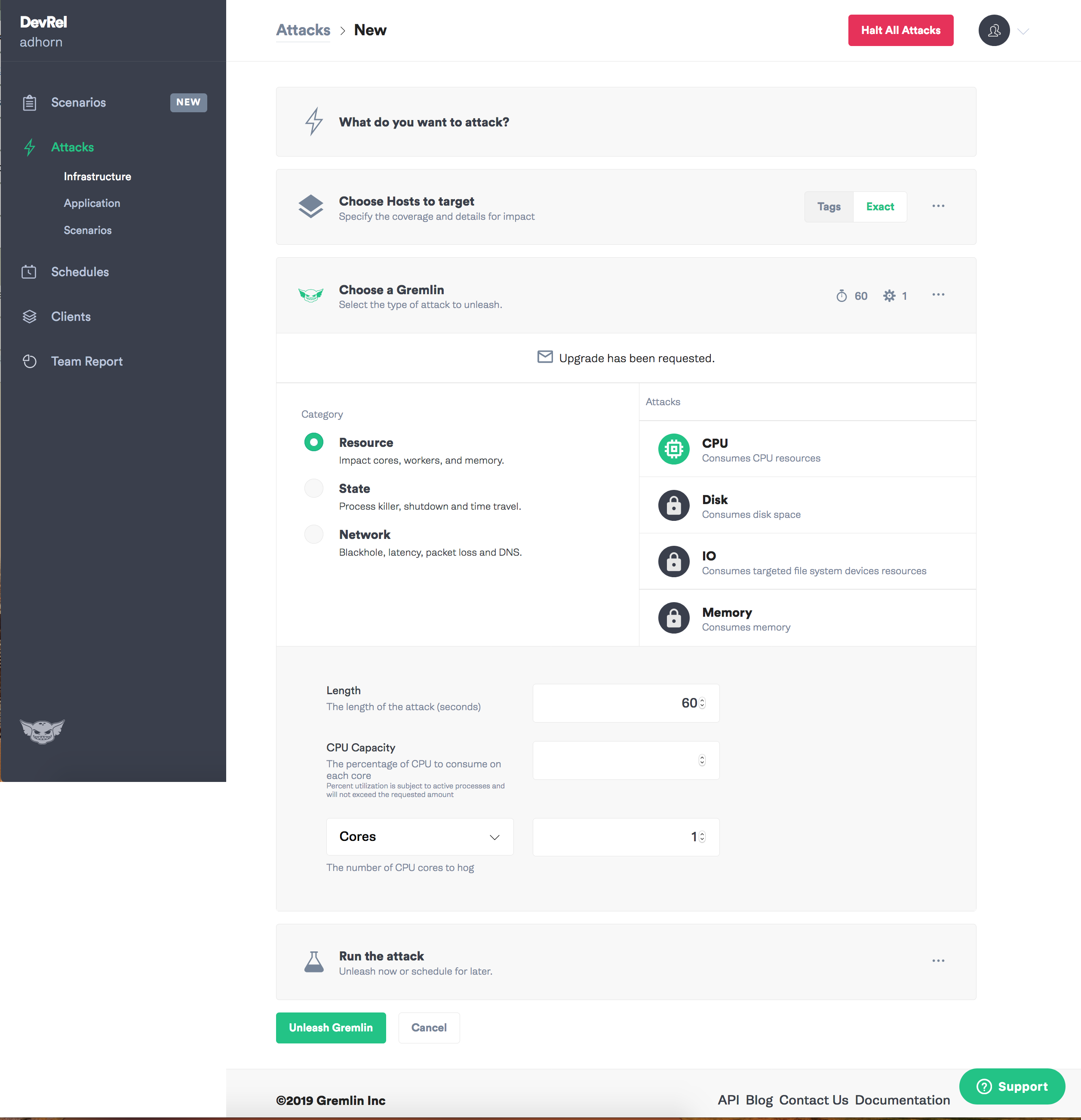
Saya harus mengakui bahwa saya selalu menyukai GREMLIN: dengan itu, percobaan pada rekayasa kekacauan secara intuitif sederhana.
— , . . , Gremlin- daemon , , .
Run Command AWS System Manager
Run command EC2 , 2015 , . — 2, . , , Systems Manager.
Run Command DevOps ad-hoc , .
, Run Command , Windows, -.
AWS System Manager . — !
!
, .
1 — - — , - . . — , — , , . , ! :
" . ".
— , - Amazon Prime Video
2 — , , . , -.
3 — , , .
4 — , , , . , - — , .
, , , . , . , , :-)
—