
Itu 2019, dan kami masih belum memiliki solusi standar untuk agregasi log di Kubernetes. Dalam artikel ini, kami ingin, menggunakan contoh dari praktik nyata, untuk membagikan penelusuran kami, masalah yang dihadapi, dan solusinya.
Namun, untuk memulainya, saya akan membuat reservasi agar pelanggan yang berbeda memahami hal yang sangat berbeda dengan mengumpulkan log:
- seseorang ingin melihat log keamanan dan audit;
- seseorang - logging terpusat dari seluruh infrastruktur;
- dan bagi seseorang cukup mengumpulkan hanya log aplikasi, tidak termasuk, misalnya penyeimbang.
Tentang bagaimana kami menerapkan berbagai "Wishlist" dan kesulitan apa yang kami temui, di bawah cut.
Teori: Tentang Alat Pencatatan
Latar belakang pada komponen sistem logging
Penebangan telah berlangsung lama, sebagai akibatnya kami telah mengembangkan metodologi untuk mengumpulkan dan menganalisis log, yang kami gunakan saat ini. Kembali pada 1950-an, Fortran memperkenalkan analog standar I / O stream yang membantu programmer men-debug programnya. Ini adalah log komputer pertama yang membuat hidup lebih mudah bagi programmer pada masa itu. Hari ini kita melihat di dalamnya komponen pertama dari sistem logging -
sumber atau “penghasil” log .
Ilmu komputer tidak diam: jaringan komputer muncul, kelompok pertama ... Sistem kompleks yang terdiri dari beberapa komputer mulai berfungsi. Sekarang administrator sistem dipaksa untuk mengumpulkan log dari beberapa mesin, dan dalam kasus khusus mereka dapat menambahkan pesan-pesan kernel OS jika mereka perlu menyelidiki kegagalan sistem. Untuk menggambarkan sistem pengumpulan log terpusat,
RFC 3164 keluar pada awal 2000-an, yang distandarisasi remote_syslog. Jadi komponen penting lainnya muncul:
pengumpul (pengumpul) log dan penyimpanannya.
Dengan peningkatan volume log dan adopsi luas teknologi web, muncul pertanyaan tentang log mana yang harus ditunjukkan kepada pengguna. Alat konsol sederhana (awk / sed / grep) digantikan oleh
pemirsa log yang lebih canggih - komponen ketiga.
Sehubungan dengan peningkatan volume log, hal lain menjadi jelas: log dibutuhkan, tetapi tidak semua. Dan log yang berbeda membutuhkan tingkat keamanan yang berbeda: beberapa dapat hilang setiap hari, sementara yang lain perlu disimpan selama 5 tahun. Jadi, komponen penyaringan dan perutean untuk aliran data telah ditambahkan ke sistem pencatatan - sebut saja
filter .
Repositori juga membuat lompatan besar: mereka beralih dari file biasa ke database relasional, dan kemudian ke repositori berorientasi dokumen (misalnya, Elasticsearch). Jadi penyimpanan dipisahkan dari kolektor.
Pada akhirnya, konsep log itu sendiri telah meluas ke beberapa aliran abstrak peristiwa yang ingin kita pertahankan untuk sejarah. Lebih tepatnya, dalam kasus ketika perlu untuk melakukan investigasi atau menyusun laporan analitis ...
Akibatnya, dalam periode waktu yang relatif singkat, pengumpulan log telah berkembang menjadi subsistem penting, yang dapat disebut sebagai salah satu subbagian dalam Big Data.
 Jika dulunya cetakan biasa cukup untuk "sistem logging", sekarang situasinya telah banyak berubah.
Jika dulunya cetakan biasa cukup untuk "sistem logging", sekarang situasinya telah banyak berubah.Kubernet dan Log
Ketika Kubernetes datang ke infrastruktur, masalah yang ada saat mengumpulkan kayu bulat tidak lewat begitu saja. Dalam beberapa hal, ini menjadi semakin menyakitkan: pengelolaan platform infrastruktur tidak hanya disederhanakan, tetapi juga rumit. Banyak layanan lama mulai bermigrasi ke trek layanan-mikro. Dalam konteks log, ini menghasilkan semakin banyak sumber log, siklus hidup khusus mereka, dan kebutuhan untuk melacak log interkoneksi semua komponen sistem ...
Ke depan, saya dapat mengatakan bahwa sekarang, sayangnya, tidak ada opsi logging standar untuk Kubernet yang akan berbeda dari yang lain. Skema yang paling populer di komunitas adalah sebagai berikut:
- seseorang sedang menyebarkan tumpukan EFK (Elasticsearch, Fluentd, Kibana);
- seseorang sedang mencoba Loki yang baru dirilis atau menggunakan operator Logging ;
- kami (dan mungkin bukan hanya kami? ..) sebagian besar puas dengan pengembangan kami sendiri - loghouse ...
Sebagai aturan, kami menggunakan bundel seperti itu di kluster K8 (untuk solusi yang di-host-sendiri):
Namun, saya tidak akan memikirkan petunjuk untuk pemasangan dan konfigurasi mereka. Sebagai gantinya, saya akan fokus pada kekurangan mereka dan lebih banyak kesimpulan global tentang situasi dengan log pada umumnya.
Berlatih dengan log di K8s

"Log sehari-hari", berapa banyak dari Anda? ..
Pengumpulan log terpusat dengan infrastruktur yang cukup besar membutuhkan sumber daya yang cukup besar yang akan dihabiskan untuk mengumpulkan, menyimpan, dan memproses log. Selama pengoperasian berbagai proyek, kami dihadapkan dengan berbagai persyaratan dan masalah operasional yang timbul.
Mari kita coba ClickHouse
Mari kita lihat repositori terpusat pada sebuah proyek dengan aplikasi yang menghasilkan cukup banyak log: lebih dari 5000 baris per detik. Mari kita mulai bekerja dengan log-nya, menambahkannya ke ClickHouse.
Segera setelah realtime maksimum diperlukan, server ClickHouse 4-inti sudah kelebihan beban pada subsistem disk:

Jenis unduhan ini disebabkan oleh kenyataan bahwa kami mencoba menulis ke ClickHouse secepat mungkin. Dan database merespons hal ini dengan peningkatan disk, yang dapat menyebabkan kesalahan berikut:
DB::Exception: Too many parts (300). Merges are processing significantly slower than insertsFaktanya adalah bahwa
tabel MergeTree di ClickHouse (mengandung data log) memiliki kesulitan sendiri selama operasi penulisan. Data yang dimasukkan ke dalamnya menghasilkan partisi sementara, yang kemudian bergabung dengan tabel utama. Akibatnya, rekaman sangat menuntut pada disk, dan juga memiliki batasan, pemberitahuan yang kami terima di atas: tidak lebih dari 300 subpartisi dapat bergabung dalam 1 detik (sebenarnya, ini adalah 300 insert'ov per detik).
Untuk menghindari perilaku ini, Anda
harus menulis di ClickHouse sebanyak mungkin dan tidak lebih dari 1 kali dalam 2 detik. Namun, menulis dalam jumlah besar menunjukkan bahwa kita sebaiknya jarang menulis di ClickHouse. Hal ini, pada gilirannya, dapat menyebabkan buffer overflows dan hilangnya log. Solusinya adalah meningkatkan buffer Fluentd, tetapi kemudian konsumsi memori akan meningkat.
Catatan : Masalah lain dengan solusi ClickHouse kami adalah bahwa partisi dalam kasus kami (loghouse) diimplementasikan melalui tabel eksternal yang ditautkan oleh tabel Merge . Ini mengarah pada fakta bahwa ketika mengambil sampel interval waktu yang besar, RAM yang berlebihan diperlukan, karena metatable melewati semua partisi - bahkan partisi yang jelas tidak mengandung data yang diperlukan. Namun, sekarang pendekatan ini dapat dengan aman dinyatakan usang untuk versi ClickHouse saat ini (sejak 18.16 ).Akibatnya, menjadi jelas bahwa ClickHouse tidak memiliki sumber daya yang cukup untuk setiap proyek untuk mengumpulkan log secara real time (lebih tepatnya, distribusinya tidak akan bijaksana). Selain itu, Anda harus menggunakan
baterai , yang akan kami kembalikan. Kasus yang dijelaskan di atas adalah nyata. Dan pada saat itu kami tidak dapat menawarkan solusi yang andal dan stabil yang sesuai untuk pelanggan dan memungkinkan untuk mengumpulkan kayu dengan penundaan minimum ...
Bagaimana dengan Elasticsearch?
Elasticsearch dikenal menangani banyak hal. Mari kita coba di proyek yang sama. Sekarang bebannya adalah sebagai berikut:
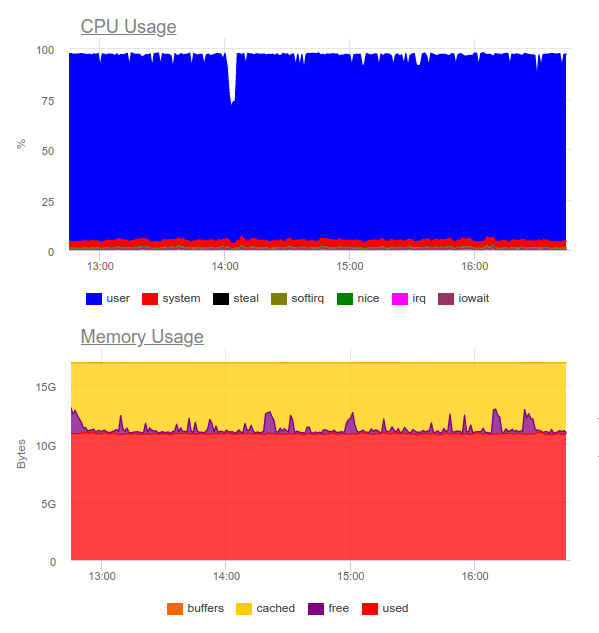
Elasticsearch mampu mencerna aliran data, namun, menulis volume seperti itu sangat memanfaatkan CPU. Ini diputuskan oleh organisasi cluster. Secara teknis murni, ini bukan masalah, tetapi ternyata hanya untuk pengoperasian sistem pengumpulan log kita sudah menggunakan sekitar 8 core dan memiliki komponen tambahan yang sangat dimuat dalam sistem ...
Intinya: opsi ini dapat dibenarkan, tetapi hanya jika proyek besar dan manajemennya siap untuk menghabiskan sumber daya yang signifikan pada sistem logging terpusat.
Kemudian muncul pertanyaan logis:
Log apa yang benar-benar dibutuhkan?

Mari kita coba untuk mengubah pendekatan itu sendiri: log harus informatif sekaligus, dan tidak mencakup
setiap peristiwa dalam sistem.
Katakanlah kita memiliki toko online yang makmur. Log mana yang penting? Mengumpulkan sebanyak mungkin informasi, misalnya, dari gateway pembayaran adalah ide bagus. Tetapi dari layanan pengiris gambar dalam katalog produk, tidak semua log penting bagi kami: hanya kesalahan dan pemantauan lanjutan yang cukup (misalnya, persentase 500 kesalahan yang dihasilkan komponen ini).
Jadi kami sampai pada
kesimpulan bahwa
penebangan terpusat jauh dari selalu dibenarkan . Sangat sering, klien ingin mengumpulkan semua log di satu tempat, walaupun sebenarnya hanya 5% dari pesan yang penting untuk bisnis diperlukan dari seluruh log:
- Terkadang cukup untuk mengkonfigurasi, katakanlah, hanya ukuran log kontainer dan pengumpul kesalahan (misalnya, Sentry).
- Untuk menyelidiki insiden, peringatan kesalahan dan log lokal besar itu sendiri seringkali cukup.
- Kami memiliki proyek yang sepenuhnya biaya hanya tes fungsional dan sistem pengumpulan kesalahan. Pengembang tidak memerlukan log seperti itu - mereka melihat semuanya pada jejak kesalahan.
Ilustrasi kehidupan
Contoh yang baik adalah cerita lain. Kami menerima permintaan dari tim keamanan salah satu klien yang sudah memiliki solusi komersial yang dikembangkan jauh sebelum penerapan Kubernetes.
Butuh "berteman" dengan sistem pengumpulan log terpusat dengan sensor perusahaan untuk mendeteksi masalah - QRadar. Sistem ini dapat menerima log menggunakan protokol syslog, untuk mengambilnya dari FTP. Namun, mengintegrasikannya dengan plugin remote_syslog untuk fluentd tidak langsung berfungsi
(ternyata, kami bukan satu-satunya ) . Masalah dengan mengonfigurasi QRadar ada di sisi tim keamanan klien.
Akibatnya, sebagian log yang penting untuk bisnis diunggah ke FTP QRadar, dan bagian lainnya dialihkan melalui syslog jarak jauh langsung dari node. Untuk melakukan ini, kami bahkan menulis
bagan sederhana - mungkin ini akan membantu seseorang memecahkan masalah yang sama ... Berkat skema yang dihasilkan, klien sendiri menerima dan menganalisis log kritis (menggunakan alat favoritnya), dan kami dapat mengurangi biaya sistem logging, hanya mempertahankan yang terakhir bulan.
Contoh lain cukup menunjukkan bagaimana tidak melakukannya. Salah satu klien kami untuk menangani
setiap peristiwa yang datang dari pengguna, melakukan multiline
output informasi yang
tidak terstruktur ke log. Seperti yang Anda tebak, log seperti itu sangat tidak nyaman untuk dibaca dan disimpan.
Kriteria untuk Log
Contoh-contoh tersebut mengarah pada kesimpulan bahwa, selain memilih sistem untuk mengumpulkan log, Anda juga harus
merancang log itu sendiri ! Apa persyaratannya di sini?
- Log harus dalam format yang dapat dibaca mesin (mis. JSON).
- Log harus kompak dan dengan kemampuan untuk mengubah tingkat logging untuk men-debug masalah yang mungkin terjadi. Pada saat yang sama, di lingkungan produksi, Anda harus menjalankan sistem dengan tingkat pencatatan seperti Peringatan atau Kesalahan .
- Log harus dinormalisasi, yaitu, dalam objek log, semua baris harus memiliki tipe bidang yang sama.
Log yang tidak terstruktur dapat menyebabkan masalah dengan memuat log ke dalam repositori dan menghentikan pemrosesan mereka sepenuhnya. Sebagai ilustrasi, berikut adalah contoh dengan kesalahan 400, yang pasti banyak ditemui dalam log fluentd:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"Kesalahan berarti bahwa Anda mengirim bidang yang tipenya tidak stabil ke indeks dengan pemetaan siap. Contoh paling sederhana adalah bidang dalam log nginx dengan variabel
$upstream_status . Itu dapat memiliki nomor atau string. Sebagai contoh:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}Log menunjukkan bahwa server 10.100.0.10 merespons dengan kesalahan 404 dan permintaan pergi ke penyimpanan konten lain. Akibatnya, dalam log, artinya menjadi seperti ini:
"upstream_response_time": "0.001, 0.007"Situasi ini begitu luas sehingga bahkan memenangkan
penyebutan terpisah
dalam dokumentasi .
Dan bagaimana dengan keandalan?
Ada kalanya semua log vital tanpa kecuali. Dan dengan ini, skema pengumpulan log untuk K8 yang diusulkan / dibahas di atas memiliki masalah.
Misalnya, fluentd tidak dapat mengumpulkan kayu dari wadah yang berumur pendek. Di salah satu proyek kami, wadah dengan migrasi basis data hidup kurang dari 4 detik, dan kemudian dihapus - sesuai dengan anotasi yang sesuai:
"helm.sh/hook-delete-policy": hook-succeededKarena itu, log migrasi tidak masuk ke repositori. Kebijakan
before-hook-creation dapat membantu dalam kasus ini.
Contoh lain adalah rotasi log Docker. Misalkan ada aplikasi yang aktif menulis ke log. Dalam kondisi normal, kami berhasil memproses semua log, tetapi segera setelah masalah muncul - misalnya, seperti dijelaskan di atas dengan format yang salah - pemrosesan berhenti, dan Docker memutar file. Intinya - log bisnis-kritis dapat hilang.
Itulah mengapa
penting untuk memisahkan aliran kayu , menanamkan pengiriman yang paling berharga langsung ke dalam aplikasi untuk memastikan keamanannya. Selain itu, tidak akan berlebihan untuk membuat semacam
"akumulator" log yang dapat bertahan dari tidak tersedianya penyimpanan sementara mempertahankan pesan penting.
Akhirnya, jangan lupa bahwa
penting untuk memantau setiap subsistem dengan cara yang berkualitas . Kalau tidak, mudah untuk menghadapi situasi di mana fluentd berada dalam keadaan
CrashLoopBackOff dan tidak mengirim apa pun, dan ini menjanjikan hilangnya informasi penting.
Kesimpulan
Pada artikel ini, kami tidak mempertimbangkan solusi SaaS seperti Datadog. Banyak masalah yang dijelaskan di sini telah diselesaikan dengan satu atau lain cara oleh perusahaan komersial yang berspesialisasi dalam mengumpulkan kayu bulat, tetapi tidak semua orang dapat menggunakan SaaS karena berbagai alasan
(yang utama adalah biaya dan kepatuhan terhadap 152--) .
Pengumpulan log terpusat pada awalnya terlihat seperti tugas sederhana, tetapi tidak sama sekali. Penting untuk diingat bahwa:
- Detail masuk hanya komponen penting, dan untuk sistem lain, Anda dapat mengonfigurasi pemantauan dan pengumpulan kesalahan.
- Log dalam produksi harus diminimalkan agar tidak memberi beban tambahan.
- Log harus dapat dibaca mesin, dinormalisasi, memiliki format yang ketat.
- Log yang benar-benar kritis harus dikirim dalam aliran terpisah, yang harus dipisahkan dari yang utama.
- Perlu mempertimbangkan baterai log, yang dapat menghemat dari semburan muatan tinggi dan membuat beban pada penyimpanan lebih seragam.

Aturan sederhana ini, jika diterapkan di mana-mana, akan memungkinkan sirkuit yang dijelaskan di atas berfungsi - meskipun mereka tidak memiliki komponen penting (baterai). Jika Anda tidak mematuhi prinsip-prinsip tersebut, tugas tersebut akan dengan mudah membawa Anda dan infrastruktur ke komponen sistem yang sangat sarat muatan (dan pada saat yang sama tidak efektif).
PS
Baca juga di blog kami: