
Pada konferensi pengembang perangkat lunak sistem dan alat - OS DAY 2016, yang diadakan di Innopolis pada 9-10 Juni 2016 (Kazan) ketika membahas laporan arsitektur multiseluler, gagasan itu menyatakan bahwa itu akan paling efektif dalam menyelesaikan masalah kecerdasan buatan. Kondisi untuk pengembangan prosesor tujuan umum baru yang berfokus pada tugas AI telah dikembangkan tahun ini.
Neuroprocessor S2 Multiclet, proyek yang pertama kali dipresentasikan di Huawei Innovation Forum 2019, adalah pengembangan lebih lanjut dari arsitektur multicell. Ini berbeda dari multisel yang dibuat sebelumnya dengan sistem perintah, yaitu, pengenalan tipe baru data berukuran kecil (dengan titik tetap dan mengambang) dan operasi dengannya. Jumlah sel meningkat - 256 dan frekuensi - 2,5 GHz, yang seharusnya memberikan kinerja puncak 81,9 TFlops pada 16F dan, karenanya, membuatnya sebanding, dalam hal perhitungan saraf, dengan kemampuan TPU ASIC khusus modern (TPU-3: 90 TFlops di 16F).
Karena efisiensi menggunakan prosesor sangat tergantung pada optimalitas kompiler, skema optimisasi kode yang dikembangkan telah dikembangkan.
Mari kita pertimbangkan lebih terinci.
Artikel sebelumnya menyebutkan optimisasi kompiler yang layak diterapkan. Di sana Anda dapat menemukan materi tentang arsitektur multiseluler jika Anda belum terbiasa dengannya.
Menghasilkan Perintah Dua-Argumen dengan Dua Konstanta
Format instruksi baru telah diperkenalkan dengan prosesor S1, yang memungkinkan kedua argumen ditetapkan sebagai nilai konstan. Ini memungkinkan Anda untuk mengurangi jumlah perintah dalam kode, menyingkirkan perintah yang tidak perlu seperti memuat untuk memuat konstanta di sakelar.
Sebagai contoh:
load_l func wr_l @1, #SP
dapat diganti dengan:
wr_l func, #SP
Atau bahkan dua tim sekaligus:
load_l [foo] load_l [bar] add_l @1, @2
Ada dua alamat konstan, dan membaca dari mereka juga dapat diganti secara langsung ke argumen perintah:
add_l [foo], [bar]
Optimasi ini diterapkan untuk semua orang yang mendukung format ini. Sayangnya, itu ternyata sangat tidak efektif, karena dua alasan:
- Jumlah situasi di mana optimasi tersebut dapat dilakukan sangat kecil. Dalam kode arbitrase, situasi jarang muncul ketika Anda perlu memproses dua nilai yang diketahui sebelumnya. Paling sering, hal-hal seperti itu diputuskan pada tahap kompilasi, dan hanya sedikit yang harus dilakukan dalam runtime. Biasanya ini adalah beberapa operasi pada alamat, sekali lagi, konstan.
- Menghapus perintah beban tidak membebaskan prosesor dari proses menghasilkan konstanta, tetapi hanya dari mengambil perintah beban terpisah, yang hanya memberikan akselerasi yang lemah, dan itupun tidak selalu.
Optimalisasi transfer register virtual antara unit dasar
Dalam LLVM, blok dasar adalah bagian linier di mana kode dieksekusi tanpa bercabang. Paragraf dalam arsitektur multiseluler melakukan fungsi yang persis sama, oleh karena itu, paling sering ketika menghasilkan kode, satu paragraf mencerminkan satu blok dasar. Dalam prosesor R1, setiap transfer register virtual antara paragraf dilakukan melalui memori dengan menulis nilai register yang diinginkan ke stack dan membacanya kembali ke paragraf yang membutuhkan register ini. Mekanisme ini dibagi menjadi 2 bagian: transfer register virtual ke paragraf lain untuk penggunaan langsung dan transfer register virtual sebagai parameter untuk simpul phi.
Phi node adalah konsekuensi dari bentuk
SSA (Static Single Assignment) di mana bahasa presentasi LLVM diwakili. Dalam bentuk ini, variabel (atau, seperti dalam kasus LLVM IR - register virtual) dapat ditulis hanya sekali. Misalnya, kode semu ini:
a = 1; if (v < 10) a = 2; else a = 3; b = a;
tidak disajikan dalam bentuk SSA, karena nilai variabel
a dapat ditimpa. Kode dapat ditulis ulang dalam bentuk ini, jika Anda menggunakan phi node:
a1 = 1; if (v < 10) a2 = 2; else a3 = 3; b = phi(a2, a3);
Node phi memilih a2 atau a3, tergantung dari mana aliran kontrol berasal:
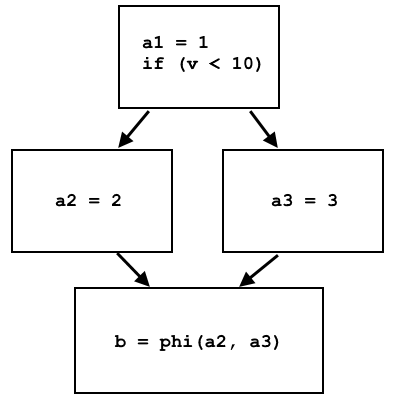
Dalam phi IR LLVM, node diimplementasikan sebagai instruksi terpisah, yang memilih register virtual yang berbeda tergantung pada unit dasar mana kontrol berasal. Implementasi pada prosesor instruksi ini melalui memori cukup sederhana: blok dasar yang berbeda menulis data yang berbeda ke sel memori yang sama, dan sebagai pengganti node phi, sel memori ini dibaca, dan data akan berbeda tergantung pada blok dasar sebelumnya.
Formulir SSA menyiratkan bahwa ketika register diinisialisasi, nilai akan selalu sama. Ketika transfer langsung register virtual dilakukan, ketika nilai setiap register virtual ditulis ke sel memori terpisahnya sendiri, kondisi SSA terpenuhi tanpa masalah: data ada di memori sampai ditimpa. Namun, jika kita ingin mentransfer register melalui switch, kita harus ingat: ukurannya hanya 63 sel, dan nilai apa pun menghilang ketika 63 perintah dieksekusi. Oleh karena itu, jika register virtual ditulis dalam beberapa paragraf pertama, dan digunakan setelah ratusan lainnya selesai, maka tidak mungkin untuk mentransfernya melalui sakelar; hanya memori yang tersisa.
Implementasi optimasi ini dimulai tepat dengan optimalisasi node phi, karena, tidak seperti transfer langsung register virtual, nilai parameter untuk node phi selalu diinisialisasi langsung dalam paragraf sebelumnya (blok dasar), yang memungkinkan Anda untuk tidak terlalu memikirkan apakah switch cukup besar. jika kita ingin melewatkan parameter ini melaluinya.
Assembler multiseluler memungkinkan Anda untuk menetapkan nama ke hasil perintah, dan menggunakan hasilnya dengan nama ini. Alih-alih setiap programmer harus menghitung berapa banyak perintah hasil ini diperoleh kembali, assembler menghitung ini sendiri:
result := add_l [A], [B] ; ; ; wr_l @result, C
Mekanisme ini berfungsi sempurna dalam paragraf saat ini, karena ini adalah bagian linier dan urutan perintahnya diketahui di sana. Ini digunakan secara aktif ketika kompiler menghasilkan kode: semua perintah diberikan nama dan kompiler tidak perlu khawatir tentang penomoran perintah. Lebih tepatnya, itu tidak perlu, karena jika kita ingin mendapatkan hasil dari perintah yang dieksekusi dalam paragraf lain, maka mekanismenya tidak berfungsi: pada tahap perakitan tidak mungkin untuk mengetahui paragraf mana yang sebenarnya dieksekusi oleh paragraf sebelumnya jika ada beberapa input pada perintah saat ini. Oleh karena itu, satu-satunya pilihan adalah mengakses hasil tim melalui nomor. Untuk alasan ini, Anda tidak bisa hanya membuang catatan / bacaan tambahan dari memori di paragraf yang berdekatan dan mengganti referensi register dari perintah read dengan perintah di paragraf sebelumnya.
Di sini perlu diperhatikan konsekuensi yang sangat penting: jika sebuah paragraf memiliki beberapa input, maka
@ 1 pada perintah pertama bagian ini dapat merujuk ke hasil yang sama sekali berbeda, tergantung pada paragraf mana yang sebelumnya. Simpul Phi hanya situasi seperti itu. Sebelumnya, di semua blok dasar menginisialisasi node phi, data ditulis ke sel memori yang sama, dan di tempat node phi ada pembacaan dari sel ini. Dengan demikian, sama sekali tidak penting tempat di mana ada catatan dalam sel ini di paragraf sebelumnya, sama seperti tempat di mana sel ini dibaca. Jika Anda menyingkirkan penggunaan memori - itu berubah.
Untuk mengizinkan host phi menggunakan sakelar alih-alih memori, berikut ini dilakukan:
- Semua node phi dalam unit dasar saat ini dihitung (dan mungkin ada beberapa), ditandai dengan nomor seri dan diatur dalam urutan ini
- Untuk setiap simpul phi, blok dasar yang menginisialisasinya dilewati; perintah untuk memuat nilai ke sakelar ( loadu_q ), ditandai dengan nomor seri dari simpul phi yang sesuai, ditambahkan ke dalamnya
- Instruksi phi dari simpul itu sendiri juga digantikan oleh loadu_q dengan nomor seri
- Semua perintah yang ditambahkan disusun kembali dalam urutan yang diberikan
Poin keempat diperlukan karena alasan yang telah ditunjukkan: jika kita ingin perintah
loadu_q @ 3 mengakses hasil khusus untuk simpul phi-nya, maka semua paragraf inisialisasi dari perintah yang memuat data ke sakelar harus dalam urutan yang persis sama. Mari kita beri contoh hasil nyata dari kompilasi kode di mana ada dua node phi dalam satu unit dasar.
Paragraf dengan inisialisasi node ph:
LBB1_27: LBB1_30: SR4 := loadu_q @1 setjf_l @0, LBB1_31 setjf_l @0, LBB1_31 SR4 := loadu_q [#SP + 8] SR5 := loadu_q [#SP + 16] SR5 := loadu_q [#SP] SR6 := loadu_l 0x1 SR6 := add_l @SR4, 0xffffffff SR7 := add_l @SR6, [@SR4] loadu_q @SR5 wr_l @SR7, @SR4 loadu_q @SR6 loadu_q @SR6 complete loadu_q @SR5 complete
Paragraf dengan dua node phi:
LBB1_31: SR4 := loadu_q @2 SR5 := loadu_q @2 SR6 := loadu_l [#SP + 124] SR7 := loadu_l [#SP + 120] setjf_l @0, @SR7 setrg_q #RETV, @SR4 wr_l @SR5, @SR6 setrg_q #SP, #SP + 120 complete
Sebelumnya, alih-
alih perintah
loadu_q, akan ada tulisan ke memori dan dibaca dari itu.
Dalam proses penerapan optimasi ini, ada juga beberapa masalah yang tidak diperkirakan sebelumnya:
- Beberapa optimasi kode yang ada mengatur ulang perintah di tempat, misalnya, menempatkan alamat paragraf berikutnya ke bagian paling awal dari yang sekarang, atau lokasi memori membaca / menulis perintah di awal / akhir paragraf, masing-masing. Optimalisasi ini terjadi setelah operasi dengan phi nodes (yang disebut menurunkan instruksi LLVM sebelum instruksi prosesor), sehingga sering mengganggu urutan dibangun perintah loadu_q . Agar tidak mengganggu pekerjaan optimasi ini, saya harus membuat pass LLVM terpisah, yang mengatur perintah untuk node phi dalam urutan yang benar setelah semua manipulasi lainnya dengan perintah.
- Ternyata suatu situasi dapat muncul di mana satu unit dasar menginisialisasi node phi untuk dua unit dasar yang berbeda. Artinya, mengikuti algoritma yang ditunjukkan, blok-blok dasar ini akan ditambahkan ke perintah inisialisasi loadu_q untuk setiap node phi. Dalam hal ini, bahkan jika mereka hanya memiliki satu simpul phi, di bagian inisialisasi akan ada 2 perintah loadu_q , yang, secara logis, keduanya harus berada di tempat terakhir, yang, tentu saja, tidak mungkin. Untungnya, situasi seperti itu cukup langka, jadi jika ada unit dasar di mana node phi diinisialisasi untuk lebih dari satu unit dasar lainnya, maka hanya yang pertama menggunakan saklar sesuai dengan algoritma, untuk sisanya - seperti sebelumnya, melalui memori.
Semua optimasi phi node ini dapat ditambah sedikit lagi. Misalnya, jika Anda melihat paragraf
LBB1_30 di atas, Anda dapat melihat bahwa
loadu_q memerintahkan nilai-nilai yang tidak digunakan di tempat lain. Yaitu, jika Anda menghapus
loadu_q dan mengatur perintah yang membuat nilai-nilai ini dalam urutan yang sama, maka perintah
loadu_q @ 2 di bagian selanjutnya juga akan memuat nilai yang benar.
Tingkatan yang dicapai
Hasil optimasi saat ini diuji pada benchmark CoreMark dan WhetStone, deskripsi yang dapat ditemukan di
artikel sebelumnya . Mari kita mulai dengan hasil CoreMark pada inti S2 dibandingkan dengan hasil lama (versi sebelumnya dari kompiler pada inti S1).
Nilai-nilai CoreMark / MHz relatif ditampilkan dalam histogram:

Untuk mendapatkan perkiraan akselerasi hanya karena optimalisasi node phi, Anda dapat menghitung ulang indikator CoreMark pada satu multisel pada inti S1 dan S2 untuk frekuensi 1600 MHz: masing-masing adalah 1147 dan 1224, yang berarti peningkatan sebesar 6,7%.
Dengan WhetStone, situasinya agak berbeda. Perubahan dalam kernel di sini mempengaruhi hasil, di samping itu, benchmark ini berjalan pada satu inti (multicell) dan dihitung dalam hal megahertz, sehingga frekuensi prosesor tidak memainkan peran apa pun.
Kartu Skor Whetstone:
Sekarang jelas bahwa bahkan ketika menggunakan versi kompiler sebelumnya pada kernel S1, indeks keseluruhan lebih tinggi, terutama karena tes titik mengambang MFLOPS1-3. Kelemahan ini diperhatikan selama pengujian dan disebabkan oleh fakta bahwa conveyor internal blok floating point di S2, dibandingkan dengan S1, adalah satu langkah lebih jauh. Akibatnya, rantai berurutan dari perintah terkait data kehilangan satu ukuran pada setiap perintah. Perlunya langkah ini disebabkan oleh pengurangan durasi clock cycle (peningkatan frekuensi prosesor dari 1,6 GHz menjadi 2,5 GHz dan peningkatan nomenklatur perintah, misalnya, tampilan perintah perkalian dengan akumulasi MAC). Keputusan ini bersifat sementara. Upaya untuk mengurangi panjang pipa sedang berlangsung, dan di masa depan ini akan diperbaiki, tetapi tes dilakukan pada versi S2 saat ini.
Untuk mengevaluasi percepatan optimasi kompiler, WhetStone juga dikompilasi pada versi sebelumnya dan diluncurkan pada versi S2 saat ini. Indikator total adalah 0,3068 MWIPS / MHz versus 0,3267 MWIPS / MHz pada kompiler baru, yaitu yang menunjukkan akselerasi 6,5% karena optimasi di atas.
Sistem optimisasi yang dikembangkan dan diuji memungkinkan Anda untuk mengimplementasikan skema optimasi selanjutnya, yaitu transfer langsung register virtual melalui sakelar. Seperti yang telah disebutkan, tidak setiap salinan register virtual dapat dilakukan melalui sakelar. Karena ukuran saklar yang terbatas dan ketidakmampuan untuk mengakses dengan benar hasil paragraf sebelumnya jika ada beberapa titik masuk ke yang sekarang (ini sebagian diselesaikan oleh node phi), satu-satunya pilihan yang mungkin adalah menyalin register virtual dari satu paragraf langsung ke paragraf berikutnya, tetapi hanya ada satu sebelumnya . Kasus-kasus seperti itu, pada kenyataannya, tidak sedikit, cukup sering perlu untuk mentransfer data secara langsung, meskipun berapa banyak akselerasi kode yang akan diberikan untuk mengatakan di muka, tentu saja, sulit.