Cepat atau lambat, setiap layanan yang berkembang harus mengevaluasi kemampuan teknisnya. Berapa banyak pengunjung yang bisa kami layani? Berapa kapasitas sistem? Sudahkah kami mencapai batas dan tidak akan jatuh jika kami menarik beberapa ribu pengguna lagi? Berapa banyak sumber daya komputasi tambahan yang dianggarkan untuk tahun depan untuk memenuhi rencana pertumbuhan?
Jawaban dapat diperoleh secara analitis dengan menjawab pertanyaan kepada pengembang / DevOps / SRE / admin yang berpengalaman. Keandalan penilaian tergantung pada sejumlah besar faktor: mulai dari langkah mengisi sistem dengan fungsionalitas dan grafik hubungan antara komponen-komponen dan berakhir dengan waktu yang dihabiskan pakar dalam lalu lintas. Semakin kompleks sistem, semakin banyak keraguan dalam kecukupan penilaian analitis.
Nama saya Maxim Kupriyanov, selama lima tahun sekarang saya telah bekerja di Yandex.Market. Hari ini saya akan memberi tahu para pembaca Habr bagaimana kami belajar untuk mengevaluasi kapasitas layanan kami dan apa yang terjadi.
Kami pergi ke posisi itu
Struktur komponen Pasar agak rumit, jadi kami memutuskan untuk mengevaluasi kapasitas hanya layanan terbesar dan termahal dalam penskalaan. Selain itu, jumlah permintaan harian untuk mereka harus jelas tergantung pada ukuran audiens harian Pasar (pengguna aktif harian, DAU). Kenapa tepatnya dari DAU? Karena analis, membuat ramalan selama berbulan-bulan dan bertahun-tahun ke depan, selalu menghitung ukuran audiens di masa depan, dan kami akan mengambil keuntungan dari keadaan yang menyenangkan ini.
Sekarang mari kita bicara tentang yang tanpanya mustahil membangun penilaian objektif: tentang metrik layanan. Jika jumlah permintaan layanan tergantung pada DAU, maka kita pasti membutuhkan metrik "permintaan per detik" (permintaan per detik, RPS). Selain itu, untuk menilai kualitas layanan, Anda perlu mengetahui persentase kesalahan dan waktu respons (waktu permintaan). Kesalahan akan dianggap sebagai respons dengan kode HTTP 500 atau lebih tinggi. Kesalahan dari rentang 4xx adalah sisi klien dan dalam sistem yang biasanya berfungsi biasanya tidak mengatakan apa-apa tentang masalah layanan. Mengenai waktu, di sini lazim untuk menghitung dan menyimpan persentil ke-80, 95, 99, dan 99,9 kali respons, tetapi rangkaian tertentu mungkin sedikit berbeda dari layanan ke layanan.
Jadi, kami memiliki metrik frekuensi permintaan, persentase kesalahan, dan sekumpulan persentil waktu respons. Dan kita juga tahu layanan DAU untuk setiap hari dan untuk periode mendatang (dalam bentuk perkiraan). Mengingat bahwa pola rata-rata perilaku pengguna tidak berubah terlalu banyak dari hari ke hari, mari kita katakan yang berikut: mengetahui RPS dalam periode paling aktif hari kerja (RPS puncak), kami dapat memprediksi RPS puncak untuk periode mendatang, dengan ketentuan kami memiliki perkiraan DAU. Dan sebaliknya: jika kita tahu berapa banyak permintaan per detik yang dapat ditahan sistem tanpa melanggar perjanjian tentang waktu tanggapan dan persentase kesalahan, maka kita dapat memperkirakan berapa banyak audiens yang dapat kita layani, yaitu, kita tahu kapasitas sistem.
Yah, kami memutuskan tugas: untuk memperbaiki timing tanggapan dan persentase kesalahan dalam bentuk perjanjian dan menemukan RPS maksimum yang dapat ditahan oleh sistem dalam kondisi ini. Bagaimana kita memutuskan?
Kami menembak sasaran
Berikut ini adalah pendekatan klasik untuk menyelesaikan masalah: kami mengumpulkan situs uji, mengambil log sistem akses dari lingkungan produksi, membuat kartrid mereka dan memecat sistem, meningkatkan frekuensi permintaan, hingga situs menunjukkan penurunan signifikan dalam pengaturan waktu tanggapan dan / atau kesalahan. Pada titik ini, kami menghentikan dan memperbaiki frekuensi permintaan (RPS yang sama). Kemenangan Bagaimanapun caranya. Dan inilah alasannya:
- situs pengujian, sebagai suatu peraturan, tidak identik dengan platform di bawah layanan di lingkungan produksi;
- kode layanan berubah setiap hari, atau bahkan lebih sering;
- eksperimen dapat memengaruhi beban;
- keparahan permintaan pengguna tergantung pada waktu hari dan kondisi lainnya;
- layanan modern jarang bekerja secara terpisah, lebih sering mereka membuat subqueries ke layanan lain, dan ini harus diperhitungkan entah bagaimana.
Peningkatan: kami akan memecat layanan secara otomatis setiap hari, mengumpulkan kartrid dari majalah pada jam sibuk. Dan agar tidak menyia-nyiakan sumber daya di lokasi pengujian, kami akan mulai membayar komponen yang menarik bagi kami pada saat yang bersamaan. Kedengarannya rumit dan tidak menyelesaikan semua masalah. Tapi opsi apa lagi yang ada?
Simulasikan kenyataan
Ide umumnya adalah ini: kami menyalin bagian dari lalu lintas dari penyeimbang ke situs, tempat kami mengumpulkan analog penuh dari lingkungan produksi dalam miniatur dan, menyesuaikan volume lalu lintas yang disalin, kami mulai mencari titik degradasi. Idenya indah, dan kami di Market melakukan ini untuk menguji fungsionalitas baru dan membandingkan perilaku versi baru dengan yang lama. Rekan saya, Eugene,
membicarakan hal ini secara mendetail - lihat bagian tentang kelompok bayangan. Tetapi ada kesulitan yang jelas juga:
- masalah berinteraksi dengan komponen eksternal tidak terpecahkan, karena sangat mahal untuk membuat salinan dari seluruh lingkungan produksi;
- log permintaan dari sistem cermin dapat secara tidak sengaja bercampur dengan log dari lingkungan produksi, yang berarti bahwa perlu untuk membangun suatu sistem dengan menandai lalu lintas cermin sehingga kemudian dapat ditemukan dan dibersihkan;
- permintaan biasanya dicerminkan baik secara penuh atau sebagai persentase dari total, dan keakuratan tersebut tidak sesuai dengan kami (tetapi ini dapat diselesaikan, kami sedang bekerja ke arah ini).
Secara umum, imitasi produksi adalah pendekatan yang sangat bagus dan menjanjikan, tetapi sangat mahal dan dengan keterbatasan yang signifikan.
Pengujian langsung dalam produksi
Dan akhirnya kami sampai pada kelezatannya. Untuk setiap komponen yang diuji, kami menaikkan contoh terpisah dalam produksi, frekuensi permintaan yang diatur dari penyeimbang dengan akurasi tinggi. Terakhir kali,
pembaca bertanya kepada kami : "Apakah HAProxy cukup untuk Anda? Apakah ada kebutuhan untuk menulis sesuatu milik Anda sendiri? " Jadi, ini adalah kasus yang sangat langka ketika itu tidak cukup dan saya harus menulis.
Pada saat yang sama, ada layanan terpisah yang memonitor dengan ketat metrik instance yang dimuat dan, ketika indikator mendekati nilai kritis, ia menutup katup pada penyeimbang, mengurangi frekuensi permintaan. Jika layanan bekerja dalam batas yang dapat diterima, katup, sebaliknya, terbuka. Tentu saja, ambang batas waktu dan kesalahan saat memuat layanan langsung terasa lebih konservatif (biasanya sebesar 5-10%) daripada di tempat pelatihan, karena kami tidak ingin memperburuk interaksi dengan pengguna. Jadi, instance yang dimuat selalu berfungsi hingga batasnya. Kami memperbaiki indikator ini. Dan kemudian kita memiliki aritmatika: kita tahu jumlah inti layanan yang dimuat setiap saat, kita tahu DAU kemarin. Dari ini, kami mempertimbangkan opsi daur ulang, cadangan kapasitas dan perilaku sistem saat menonaktifkan satu atau lokasi lain. Semua ini diletakkan di dasar di mana grafik yang indah dibangun. Berdasarkan data ini, ketika kapasitas turun di bawah ambang batas, peringatan dipicu.
Mari kita lihat grafiknya
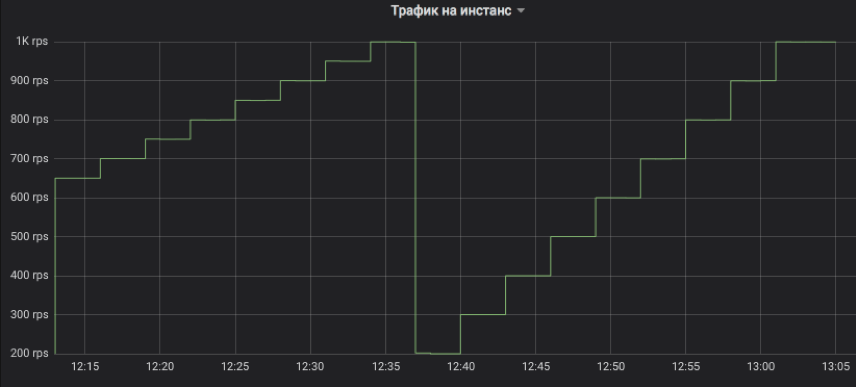
Ini adalah bagaimana kami mengontrol arus lalu lintas ke contoh yang diuji. Langkahnya dapat berupa kelipatan 1 RPS. Pada grafik, sebagai ilustrasi, kami memodelkan pendakian dengan interval tiga menit: pertama, dari 650 ke 1K RPS dengan peningkatan 50, dan kemudian dari 200 hingga 1K RPS dengan peningkatan 100. Mari saya ingatkan Anda, ini adalah lalu lintas pengguna nyata yang menerima jawaban oleh pelanggan.
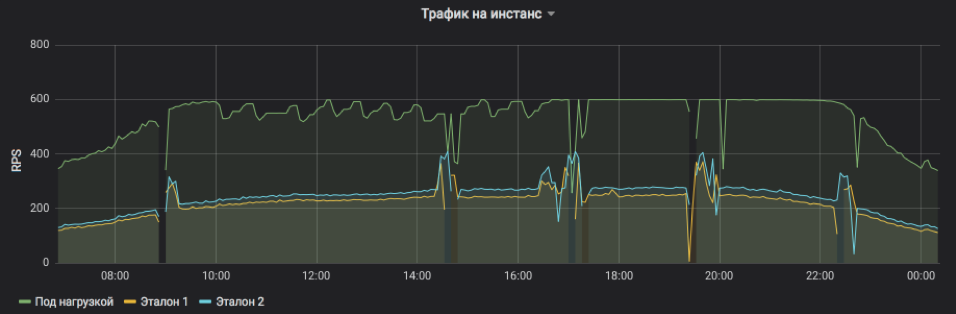
Ini menunjukkan RPS untuk tiga contoh: satu di bawah beban dan dua kontrol. Subjek secara artifisial menetapkan batas atas 600 RPS. Layanan mungkin lebih, tetapi menjadi terlalu tidak stabil dan tergantung pada pengaruh eksternal. Jelas terlihat bahwa pada paruh pertama permintaan layanan, rata-rata, lebih berat dan mesin virtual tidak dapat mencapai kapasitas puncaknya dalam kondisi yang dapat diterima, tetapi menjelang malam, semuanya kembali normal. Semburan dan kelalaian pada bagan adalah contoh restart untuk meletakkan rilis dan pembaruan lainnya (mereka semua sedang diseimbangkan, tidak ada yang terluka). Dan penyesuaian RPS selangkah demi selangkah pada subjek uji hanyalah karya algoritma yang mencari batas kemungkinan.

Frekuensi permintaan layanan dan beban yang satu instance dapat tahan terlihat jelas.
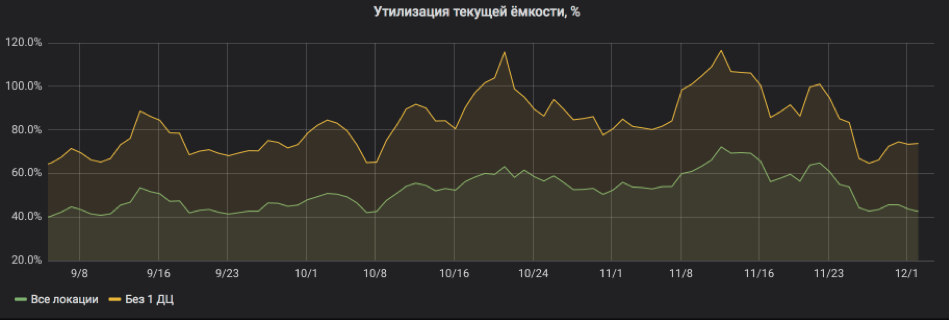
Dan di sini kita menghitung ulang semuanya dalam persen pemanfaatan. Grafik menunjukkan bahwa layanan dimuat cukup berat dan ketika salah satu lokasi dimatikan, ada risiko untuk pergi ke SLA. Tapi sekarang semuanya baik-baik saja: sumber daya telah ditambahkan ke layanan, daur ulang telah kembali ke batas yang dapat diterima.
Dengan demikian, pengujian beban dalam produksi memungkinkan Anda untuk dengan cepat mengevaluasi kapasitas sistem dan memperkirakan konsumsi sumber daya untuk periode mendatang. Pada saat yang sama, sistem ini sebenarnya tidak menambah pengeluaran yang cukup besar dan Anda dapat bekerja dengan aman dengan layanan-layanan stateful, karena kami tidak menghasilkan traffic baru, tetapi hanya mendistribusikan secara akurat salah satunya. Dan akhirnya: untuk bekerja, sebagai suatu peraturan, tidak diperlukan untuk mengubah kode dari sistem eksperimental itu sendiri, yang memungkinkan pengujian bahkan aplikasi warisan.
Renungkan
Metodologi ini belum bekerja di Pasar selama lebih dari satu tahun, dan kami dapat berbagi pengamatan dan rekomendasi:
- Di sebelah instance yang dimuat, harus ada satu kontrol biasa, dan lebih disukai steam, karena degradasi sering terjadi bukan karena instance kelebihan beban, tetapi karena masalah umum dengan layanan secara keseluruhan.
- Teknik ini hanya berfungsi dengan baik pada komponen yang bebannya lebih tinggi dari ratusan permintaan per detik untuk suatu lokasi. Alasannya cukup sederhana: kita perlu memuat instance yang diuji dan satu atau dua kontrol. Jika tidak ada lalu lintas yang cukup, kami tidak akan mencapai kejenuhan atau kami tidak akan dapat membandingkan dengan jujur. Dan jika batas RPS per instance sangat kecil, maka langkah minimum mengubah frekuensi permintaan menjadi 1 RPS mungkin terlalu kasar.
- Lebih baik untuk menguji front dan backend di lokasi yang berbeda, sehingga artefak backend pengujian beban tidak mempengaruhi estimasi kapasitas depan.
- Ketika kami menganalisis waktu respons dan mencari tanda-tanda degradasi, kami biasanya mengambil agregat lima menit dan menghitung median agar tidak bereaksi terhadap semburan acak.
- Alasan utama bahwa instance yang dimuat dari layanan macet adalah ruang disk untuk file log (log). Mereka selalu melupakannya.
- Masuk ke disk I / O-load dari server-web adalah alasan yang sangat umum untuk pemburukan waktu, bahkan pada SSD. Selalu nyalakan buffering, rekaman asinkron, dan yang lainnya, hanya untuk tidak menunggu sampai rekaman berakhir.
- Beban malam tidak bersifat indikatif, karena permintaan rata-rata lebih berat karena bagian robot yang lebih besar. Oleh karena itu, untuk memperkirakan kapasitas, lebih baik untuk memperbaiki kisaran dari waktu cahaya konvensional hari itu, dan pada malam hari hanya untuk mengurangi aliran permintaan jika tanda-tanda degradasi muncul.
- Persentil ke-99 dari timing tanggapan tidak berguna untuk estimasi kapasitas, karena jaminan ketersediaan jaringan jarang melebihi 99%.
- Mulai jadwal waktu dan catat rilis layanan dan acara penting lainnya. Ini membantu untuk menemukan apa yang menyebabkan penurunan kapasitas.
- Dalam analisis terperinci tentang penyebab degradasi, pelacakan juga berguna: header marker ditambahkan ke setiap permintaan layanan, yang bergerak dari depan ke backend terakhir dan memasukkan semua log. Dengan cara ini Anda dapat melacak seluruh jalur permintaan dan memahami apa yang menyebabkan keterlambatan.