Pemrosesan bahasa alami berasal dari mistikus Kabbalah
Jauh sebelum pemrosesan bahasa alami menjadi topik hangat di bidang kecerdasan buatan, orang-orang membuat aturan dan mesin untuk memanipulasi bahasa
 Mistikus abad ke-13 Abraham bin Samuel Abulafia menemukan bidang pemrosesan bahasa alami dengan memulai praktik menggabungkan huruf
Mistikus abad ke-13 Abraham bin Samuel Abulafia menemukan bidang pemrosesan bahasa alami dengan memulai praktik menggabungkan hurufSekarang kita berada di puncak minat dalam pemrosesan bahasa alami (NLP) - bidang ilmu komputer yang berfokus pada interaksi linguistik manusia dan mesin. Berkat terobosan dalam pembelajaran mesin (MO) dalam dekade terakhir, kami melihat peningkatan besar dalam pengenalan suara dan terjemahan mesin. Generator bahasa sudah cukup baik untuk menulis artikel berita yang koheren, dan asisten virtual seperti Siri dan Alexa menjadi bagian dari kehidupan kita sehari-hari.
Kebanyakan sejarawan melacak asal-usul area ini ke awal era komputer ketika Alan Turing pada tahun 1950 menggambarkan sebuah mesin pintar yang dapat dengan mudah berinteraksi dengan seseorang melalui teks di layar. Oleh karena itu, bahasa yang dihasilkan oleh mesin biasanya dibayangkan sebagai fenomena digital - serta tujuan utama pengembangan kecerdasan buatan (AI).
Dalam artikel ini kami akan mencoba untuk menyangkal gagasan NLP yang diterima secara umum ini. Bahkan, upaya untuk mengembangkan aturan formal dan mesin yang mampu menganalisis, memproses, dan menciptakan bahasa pertama kali dilakukan beberapa ratus tahun yang lalu.
Teknologi spesifik telah berubah dari waktu ke waktu, tetapi gagasan utama untuk menganggap bahasa sebagai bahan yang dapat dimanipulasi secara artifisial berdasarkan sistem aturan telah dieksplorasi oleh banyak orang di banyak budaya dan karena berbagai alasan. Eksperimen historis ini menunjukkan kemungkinan dan bahaya mencoba mensimulasikan bahasa manusia tanpa campur tangan manusia - dan juga memberikan pelajaran bagi praktisi teknik NLP canggih saat ini.
Kisah ini berasal dari Spanyol abad pertengahan. Pada akhir abad ke-13, seorang mistikus Yahudi bernama
Abraham bin Samuel Abulafia duduk di sebuah meja di rumahnya di Barcelona, mengambil pena, mencelupkannya ke dalam tinta dan mulai menggabungkan huruf-huruf
alfabet Ibrani dengan cara yang aneh dan, pada pandangan pertama, secara acak. Alef dengan taruhan, bertaruh dengan gimel, gimel dengan alef dan bertaruh, dan sebagainya.
Abulafia menyebut praktik ini "ilmu menggabungkan huruf." Bahkan, ia menggabungkan huruf-huruf tidak secara acak; dia dengan hati-hati mengikuti seperangkat aturan rahasia yang dia kembangkan ketika mempelajari teks
Kabbalistik kuno yang disebut "
Sepher Yetzirah ." Buku itu menjelaskan bagaimana Allah menciptakan "segala sesuatu yang memiliki bentuk dan segala yang dikatakan," menggabungkan huruf-huruf Ibrani sesuai dengan rumusan sakral. Dalam satu bagian, Tuhan melewati semua kombinasi dua huruf dari 22 huruf alfabet.
Mempelajari Sefer Yetzirah, Abulafia muncul dengan gagasan bahwa simbol-simbol linguistik dapat dimanipulasi sesuai dengan aturan formal untuk menciptakan kalimat-kalimat baru, menarik, dan dipenuhi ide. Untuk tujuan ini, selama beberapa bulan ia menghasilkan ribuan kombinasi 22 huruf abjad Ibrani, dan sebagai hasilnya menulis beberapa buku, yang ia klaim diberkahi dengan kebijaksanaan kenabian.
Bagi Abulafia, generasi bahasa menurut aturan ilahi memberikan gagasan tentang yang sakral dan tidak dikenal, atau, ketika ia menulis sendiri, memungkinkannya untuk "memahami hal-hal yang, menurut tradisi manusia, atau manusia saja tidak dapat mengetahuinya."
Namun, para sarjana Yahudi lainnya menganggap generasi bahasa yang belum sempurna ini sebagai tindakan berbahaya, dekat dengan penistaan. Dalam
Talmud, diceritakan tentang para rabi, yang secara ajaib mengubah bahasa sesuai dengan formula yang dijelaskan dalam "Sepher Yetzirah", menciptakan makhluk buatan,
golem . Dalam kisah-kisah ini, para rabi memanipulasi surat-surat dari bahasa Ibrani untuk menciptakan kembali tindakan penciptaan yang ilahi, menggunakan rumus-rumus suci untuk memberikan benda-benda mati.
Dalam beberapa mitos ini, para rabi menggunakan keterampilan ini untuk tujuan praktis, menciptakan hewan untuk makanan ketika mereka ingin makan, atau pelayan untuk membantu pekerjaan rumah tangga. Tetapi banyak dari kisah golem ini berakhir dengan buruk. Dalam salah satu dongeng terkenal,
Yehuda Liva bin Betzalel (dikenal sebagai Maharal dari Praha), seorang rabi yang tinggal di Praha pada abad ke-16, menggunakan praktik suci menggabungkan huruf untuk memanggil golem untuk melindungi komunitas Yahudi dari serangan anti-Semit, tetapi pada akhirnya golem ini berbalik menentang penciptanya.
Ini "ilmu menggabungkan huruf" adalah bentuk dasar dari pemrosesan bahasa alami, karena itu termasuk menggabungkan huruf-huruf alfabet Ibrani sesuai dengan aturan khusus. Bagi kaum Kabbalis, ini adalah pedang bermata dua: baik cara untuk mencapai bentuk-bentuk baru pengetahuan dan kebijaksanaan, dan praktik berbahaya yang dapat menyebabkan konsekuensi serius yang tidak diinginkan.
Ketegangan ini telah bertahan sepanjang sejarah panjang pemrosesan bahasa, dan masih menanggapi diskusi tentang teknologi NLP paling maju di era digital kita.
Pada abad ke-17, Leibniz memimpikan sebuah mesin yang mampu menghitung ide.
Mesin itu seharusnya menggunakan "alfabet pikiran manusia" dan aturan untuk menggabungkannya
 Gottfried Wilhelm Leibniz pada latar belakang halaman disertasinya "On the Art of Combinatorics"
Gottfried Wilhelm Leibniz pada latar belakang halaman disertasinya "On the Art of Combinatorics"Pada 1666, sarjana Jerman
Gottfried Wilhelm Leibniz menerbitkan disertasi misterius berjudul "
On the Art of Combinatorics ." Menjadi hanya 20 tahun, tetapi sudah berpikir secara luas, Leibniz menggambarkan teori produksi otomatis pengetahuan berdasarkan kombinasi karakter yang dibuat sesuai dengan aturan tertentu.
Argumen utama Leibniz adalah bahwa semua pemikiran manusia, terlepas dari kerumitannya, merupakan kombinasi dari konsep dasar dan fundamental, seperti halnya kalimat adalah kombinasi kata-kata, dan kata-kata adalah kombinasi huruf. Dia percaya bahwa jika dia dapat menemukan cara untuk secara simbolis mewakili konsep-konsep mendasar ini dan mengembangkan metode yang dengannya mereka dapat digabungkan secara logis, maka dia akan dapat menciptakan pemikiran baru yang diperlukan.
Gagasan ini muncul di kepala Leibniz ketika mempelajari karya
Raimund Lullius , seorang mistikus dari Mallorca, yang hidup pada abad ke-13, yang mengabdikan hidupnya untuk menciptakan sistem argumen teologis yang dapat membuktikan "kebenaran universal" Kekristenan bagi semua orang yang tidak percaya.
Lullius sendiri terinspirasi oleh kombinasi surat-surat kaum Kabbalah Yahudi, yang mereka gunakan untuk membuat teks-teks yang dihasilkan yang konon mengungkapkan kebijaksanaan kenabian. Mengembangkan ide ini lebih jauh, Lullius menemukan apa yang disebutnya "
Volwell, " sebuah mekanisme kertas bundar dengan secara bertahap mengurangi lingkaran konsentris di mana simbol yang mewakili atribut Allah ditulis. Lullius percaya bahwa dengan memutar volwell dengan berbagai cara, dan dengan menghasilkan kombinasi simbol baru satu sama lain, ia dapat menemukan semua aspek keilahiannya.
Leibniz terkesan dengan mesin kertas Lullia, dan mulai membuat metode sendiri untuk menghasilkan ide melalui kombinasi simbol. Tetapi dia ingin menggunakan mobilnya bukan untuk debat teologis, tetapi untuk tujuan filosofis. Dia menyarankan bahwa sistem seperti itu akan membutuhkan tiga hal: "alfabet pikiran manusia"; daftar aturan logis untuk kombinasi yang valid; dan mekanisme yang mampu melakukan operasi logis dengan simbol-simbol ini dengan cepat dan akurat - pembaruan yang sepenuhnya mekanis dari volume kertas Lullia.
Dia membayangkan bahwa mesin ini, yang dia sebut "alat penalaran hebat," akan dapat menjawab semua pertanyaan dan menyelesaikan setiap perselisihan intelektual. "Ketika perselisihan muncul di antara orang-orang," tulisnya, "kita bisa mengatakan," mari kita hitung, "dan segera lihat siapa yang benar."
Gagasan tentang mekanisme yang memberikan pemikiran rasional sesuai dengan semangat waktu Leibniz. Pemikir
Pencerahan lainnya , seperti Rene Descartes, meyakini adanya "kebenaran universal" yang dapat digali hanya dengan menggunakan penalaran logis, dan bahwa semua fenomena dapat sepenuhnya dijelaskan, memahami prinsip-prinsip yang mendasari mereka. Leibniz percaya bahwa hal yang sama berlaku untuk bahasa, dan untuk kesadaran itu sendiri.
Tetapi banyak orang lain menganggap doktrin alasan murni ini sangat keliru dan menganggapnya sebagai tanda era baru khotbah canggih. Salah satu kritik tersebut adalah penulis dan satiris Jonathan Swift, yang berjalan melalui mesin penghitungan Leibniz dalam bukunya tahun 1726, Gulliver's Travels. Dalam satu adegan, Gulliver berakhir di Lagado Grand Academy, di mana ia menemukan mekanisme aneh yang disebut "mesin." Mesin ini memiliki kerangka kayu besar dengan kisi-kisi kabel yang diregangkan. Di kabel ada kubus kayu kecil, di setiap sisi yang ada simbol.
Siswa akademi memutar pegangan di sisi mesin, yang membuat balok kayu berputar dan menghasilkan kombinasi karakter baru. Kemudian juru tulis menuliskan apa yang diberikan mesin itu dan memberikannya kepada profesor ketua. Profesor itu mengklaim bahwa dengan cara ini ia dan murid-muridnya dapat "menulis buku-buku tentang filsafat, puisi, politik, hukum, matematika dan teologi tanpa bakat atau pelatihan apa pun."
Adegan generasi bahasa sebelum era digital ini adalah parodi Swift tentang generasi pemikiran Leibniz melalui kombinasi simbol - dan, lebih umum, argumen yang menentang keunggulan sains. Seperti upaya lain oleh Akademi Lagado untuk meningkatkan perkembangan orang-orangnya melalui penelitian - seperti upaya untuk mengubah kotoran manusia kembali menjadi makanan - mesin tampaknya bagi Gulliver sebagai percobaan yang tidak berarti.
Swift ingin mengatakan bahwa bahasa bukanlah sistem formal untuk mewakili pemikiran manusia, seperti yang diyakini Leibniz, tetapi bentuk kacau dan ambigu ekspresi mereka, yang hanya masuk akal dalam konteks di mana ia digunakan. Swift berpendapat bahwa pembuatan bahasa tidak hanya membutuhkan seperangkat aturan dan mesin yang sesuai, tetapi juga kemampuan untuk memahami makna kata-kata, yang tidak bisa dilakukan oleh mesin Lagado maupun “alat penalaran” Leibniz.
Akibatnya, Leibniz tidak pernah membangun mobilnya untuk menghasilkan ide. Dia benar-benar meninggalkan studi tentang kombinatorik Lullius, dan kemudian mengakui upaya mekanisasi bahasa sebagai tidak matang. Namun, ia tidak meninggalkan gagasan untuk menggunakan perangkat mekanis untuk melakukan fungsi logis, dan itu menginspirasinya untuk membuat "
kalkulator langkah-demi-langkah, " kalkulator mekanik yang dibangun pada tahun 1673.
Namun, perdebatan hari ini di antara para ilmuwan komputer yang sedang mengembangkan algoritma yang lebih maju untuk NLP mencerminkan ide-ide Leibniz dan Swift: bahkan jika dimungkinkan untuk membuat sistem formal yang menghasilkan bahasa yang mirip dengan manusia, dapatkah ia diberkahi dengan kemampuan untuk memahami apa yang dihasilkannya?
Andrei Markov dan Claude Shannon menghitung surat untuk membangun model generasi bahasa pertama
Model Shannon mengatakan: "OCRO HLI RGWR NMIELWIS"
 Ahli matematika Rusia Andrei Andreevich Markov dengan latar belakang analisis statistik puisi oleh Alexander Sergeyevich Pushkin "Eugene Onegin"
Ahli matematika Rusia Andrei Andreevich Markov dengan latar belakang analisis statistik puisi oleh Alexander Sergeyevich Pushkin "Eugene Onegin"Pada tahun 1913, matematikawan Rusia
Andrei Andreevich Markov duduk di kantornya di St. Petersburg dengan salinan puisi abad ke-19 oleh A. S. Pushkin "Eugene Onegin," yang saat itu adalah mantan sastra klasik. Namun, Markov tidak membaca teks terkenal Pushkin. Sebagai gantinya, ia mengambil pena dan kertas gambar, dan menulis 20.000 huruf pertama dari buku itu dalam satu baris panjang huruf, menghilangkan semua spasi dan tanda baca. Kemudian ia menyusun ulang surat-surat ini menjadi 200 kisi (masing-masing 10x10 karakter), dan mulai menghitung suara vokal di setiap baris dan kolom, merekam hasilnya.
Bagi pengamat luar, perilaku Markov akan terasa aneh. Mengapa ada orang yang membongkar karya seorang jenius sastra sedemikian rupa, mengubahnya menjadi sesuatu yang tidak bisa dipahami? Tetapi Markov tidak membaca buku ini untuk mempelajari lebih lanjut tentang sifat manusia dan kehidupan; dia mencari struktur matematika dasar dalam teks.
Memisahkan vokal dari konsonan, Markov memeriksa teori probabilitas yang dikembangkan olehnya sejak 1909. Sampai saat itu, teori probabilitas terutama terbatas pada analisis fenomena seperti roulette atau coin flip, ketika hasil dari peristiwa sebelumnya tidak mempengaruhi probabilitas yang sekarang. Tetapi Markov percaya bahwa sebagian besar fenomena terjadi sepanjang rantai sebab akibat dan bergantung pada hasil sebelumnya. Dia ingin menemukan cara untuk memodelkan peristiwa-peristiwa ini melalui analisis probabilistik.
Markov percaya bahwa bahasa adalah contoh dari sistem di mana peristiwa-peristiwa sebelumnya sebagian menentukan yang saat ini. Untuk menunjukkan hal ini, ia ingin menunjukkan bahwa dalam sebuah teks, misalnya, dalam puisi Pushkin, kemungkinan surat tertentu muncul di tempat tertentu dalam teks sampai batas tertentu tergantung pada huruf apa yang ada sebelumnya.
Untuk melakukan ini, Markov mulai menghitung vokal di Eugene Onegin, dan menemukan bahwa 43% dari huruf-huruf di sana adalah vokal, 57% - konsonan. Markov kemudian membagi 20.000 huruf menjadi pasangan kombinasi vokal dan konsonan. Dia menemukan 1104 pasangan dua vokal, 3827 pasangan konsonan dan 15069 vokal-konsonan atau pasangan vokal-konsonan. Dari sudut pandang statistik, ini berarti bahwa untuk setiap surat teks Pushkin aturan terpenuhi: jika itu adalah vokal, maka kemungkinan besar konsonan akan berdiri di belakangnya, dan sebaliknya.
Markov menggunakan analisis ini untuk menunjukkan bahwa "Eugene Onegin" dari Pushkin bukan hanya distribusi surat acak, tetapi memiliki kualitas statistik tertentu yang dapat dimodelkan. Karya
penelitian misterius yang menyelesaikan studi ini berjudul "Contoh Studi Statistik Teks Eugene Onegin, Menggambarkan Tautan Uji Coba dalam Rantai." Dia jarang dikutip selama masa Markov, dan tidak diterjemahkan ke dalam bahasa Inggris sampai 2006. Namun, beberapa konsep dasarnya yang terkait dengan probabilitas dan bahasa telah menyebar ke seluruh dunia, dan sebagai hasilnya telah disuarakan kembali dalam
karya Claude Shannon yang sangat berpengaruh "The
Mathematical Theory of Communication ", yang diterbitkan pada tahun 1948.
Karya Shannon menggambarkan cara untuk secara akurat mengukur konten kuantitatif informasi dalam sebuah pesan, dan dengan demikian meletakkan dasar-dasar teori informasi yang kemudian akan menentukan era digital. Shannon sangat senang dengan gagasan Markov bahwa dalam teks yang diberikan, probabilitas huruf atau kata tertentu dapat diperkirakan. Seperti Markov, Shannon menunjukkan ini dengan melakukan percobaan teks yang melibatkan pembuatan model statistik bahasa, dan kemudian mengembangkan ide ini lebih lanjut dengan mencoba menggunakan model ini untuk menghasilkan teks sesuai dengan aturan statistik ini.
Dalam percobaan terkontrol pertama, ia mulai dengan menghasilkan kalimat, secara acak memilih huruf dari alfabet 27 karakter (26 huruf Latin dan spasi), dan menerima yang berikut:
XFOML RXKHRJFFJUJ ZLPWCFWKCYJ FFJEYVKCQSGHYD QPAAMKBZAACIBZLHJQD
Usulan itu ternyata tidak ada gunanya, kata Shannon, karena ketika berkomunikasi kita tidak memilih huruf dengan probabilitas yang sama. Seperti yang ditunjukkan Markov, konsonan memiliki probabilitas kemunculan yang lebih tinggi daripada vokal. Tetapi jika kita melihat lebih jauh, maka huruf E lebih umum daripada S, dan pada gilirannya, lebih umum daripada Q. Untuk memperhitungkan semua ini, Shannon mengoreksi alfabet asli sehingga lebih baik mensimulasikan bahasa Inggris - kemungkinan mendapatkan huruf E ada di 11% lebih banyak daripada mengekstraksi huruf Q. Ketika dia mulai lagi memilih surat secara acak dari daftar yang dikonfigurasi ulang, dia menerima tawaran yang lebih mirip bahasa Inggris.
OCRO HLI RGWR NMIELWIS EU LL NBNESEBYA TH EEI ALHENHTTPA OOBTTVA NAH BRL
Dalam percobaan berikutnya, Shannon menunjukkan bahwa dengan komplikasi lebih lanjut dari model statistik, hasil yang lebih bermakna dapat diperoleh. Seperti Markov, Shannon menciptakan platform statistik untuk bahasa Inggris, dan menunjukkan bahwa dengan memodelkan platform ini - dengan menganalisis probabilitas ketergantungan huruf dan kata dalam kombinasi satu sama lain - Anda dapat menghasilkan bahasa.
Semakin kompleks model statistik teks, semakin akurat generasi bahasa menjadi - atau, seperti yang ditulis Shannon, semakin "menyerupai teks bahasa Inggris biasa". Dalam percobaan terakhir, Shannon mengambil kata-kata dari daftar alih-alih huruf, dan mendapatkan yang berikut:
KEPALA DAN DALAM SERANGAN FONTAL PADA PENULIS BAHASA INGGRIS BAHWA KARAKTER DARI TITIK INI ADA OLEH METODE LAIN UNTUK SURAT-SURAT YANG WAKTU YANG PERNAH MENYATAKAN MASALAH UNTUK YANG TIDAK DIKENALKAN
[
Kira-kira "KEPALA DAN DALAM SERANGAN DEPAN TERHADAP PENULIS BAHASA INGGRIS, DARI KARAKTER DARI TITIK INI, KONSEKUENSI, SEBUAH METODE YANG BERBEDA UNTUK SURAT, DARI KALI SAJA YANG SESUATU SESUATU SESUATU SESUATU YANG DIBERI KASIH SESUATU” kata / kira-kira. perev. ]
Baik Shannon dan Markov percaya bahwa dengan memahami bahwa sifat statistik suatu bahasa dapat dimodelkan, Anda mendapatkan cara untuk memikirkan kembali tugas yang lebih umum.
Ini membantu Markov memperluas penelitian di bidang
stokastik di luar batas peristiwa independen, membuka jalan bagi pendekatan baru dalam teori probabilitas. Ini membantu Shannon untuk merumuskan cara yang akurat untuk mengukur dan mengkodekan unit informasi dalam sebuah pesan, yang merevolusi telekomunikasi, dan akhirnya, komunikasi digital. Namun, pendekatan statistik mereka untuk pemodelan dan generasi bahasa juga mempercepat munculnya era NLP, yang berkembang sepanjang era digital.
Mengapa orang menuntut privasi dalam percakapan pribadi dengan chatbot pertama di dunia
Pada tahun 1966, program Eliza tidak banyak bicara, tetapi itu sudah cukup
 Ilmuwan komputer Joseph Weizenbaum dengan chatbot-nya, Eliza, berjalan pada mainframe IBM 7094 36-bitDari tahun 1964 hingga 1966, Joseph Weizenbaum , seorang ilmuwan komputer Amerika keturunan Jerman yang bekerja di laboratorium AI di MIT, mengembangkan chatbot pertama di dunia .Meskipun pada saat itu sudah ada beberapa generator bahasa digital yang belum sempurna - program yang dapat menghasilkan lebih banyak atau lebih sedikit garis teks yang terhubung - program Weizenbaum adalah yang pertama yang dirancang khusus untuk berkomunikasi dengan orang-orang. Pengguna dapat memasukkan pernyataan tertentu atau serangkaian pernyataan dalam bahasa yang sama, tekan "enter", dan menerima respons dari mesin. Seperti yang dijelaskan Weizenbaum, programnya "memungkinkan semacam percakapan antara seseorang dan komputer dalam bahasa alami."Dia menamai program Eliza setelah Eliza Dolittle., tokoh utama drama Bernard Shaw, Pygmalion, seorang perwakilan dari kelas pekerja yang telah belajar berbicara dengan aksen perwakilan dari kelas atas. Eliza ditulis untuk IBM 7094 36-bit, salah satu mainframe transistor awal, dalam bahasa pemrograman yang dikembangkan oleh Weizenbaum sendiri, MAD-SLIP.Karena waktu komputer itu mahal, Eliza hanya bisa dijalankan pada sistem pembagian waktu. Pengguna berinteraksi dengan program dari jarak jauh menggunakan mesin tik dan printer listrik. Ketika pengguna memasukkan kalimat dan menekan "enter", pesan itu dikirim ke mainframe. "Eliza" memindai pesan untuk keberadaan kata kunci dan menggunakannya dalam kalimat baru, membentuk respons yang dikirim kembali dan dicetak sehingga pengguna dapat membacanya.Untuk mendorong dialog yang berkelanjutan, Weizenbaum meresepkan simulasi percakapan khas psikoanalis Rogers di Eliza . Program mengambil apa yang dikatakan pengguna dan merumuskannya kembali sebagai pertanyaan (perhatikan bagaimana program mengambil kata-kata seperti "pria" dan "depresi" dan menggunakannya kembali)
Ilmuwan komputer Joseph Weizenbaum dengan chatbot-nya, Eliza, berjalan pada mainframe IBM 7094 36-bitDari tahun 1964 hingga 1966, Joseph Weizenbaum , seorang ilmuwan komputer Amerika keturunan Jerman yang bekerja di laboratorium AI di MIT, mengembangkan chatbot pertama di dunia .Meskipun pada saat itu sudah ada beberapa generator bahasa digital yang belum sempurna - program yang dapat menghasilkan lebih banyak atau lebih sedikit garis teks yang terhubung - program Weizenbaum adalah yang pertama yang dirancang khusus untuk berkomunikasi dengan orang-orang. Pengguna dapat memasukkan pernyataan tertentu atau serangkaian pernyataan dalam bahasa yang sama, tekan "enter", dan menerima respons dari mesin. Seperti yang dijelaskan Weizenbaum, programnya "memungkinkan semacam percakapan antara seseorang dan komputer dalam bahasa alami."Dia menamai program Eliza setelah Eliza Dolittle., tokoh utama drama Bernard Shaw, Pygmalion, seorang perwakilan dari kelas pekerja yang telah belajar berbicara dengan aksen perwakilan dari kelas atas. Eliza ditulis untuk IBM 7094 36-bit, salah satu mainframe transistor awal, dalam bahasa pemrograman yang dikembangkan oleh Weizenbaum sendiri, MAD-SLIP.Karena waktu komputer itu mahal, Eliza hanya bisa dijalankan pada sistem pembagian waktu. Pengguna berinteraksi dengan program dari jarak jauh menggunakan mesin tik dan printer listrik. Ketika pengguna memasukkan kalimat dan menekan "enter", pesan itu dikirim ke mainframe. "Eliza" memindai pesan untuk keberadaan kata kunci dan menggunakannya dalam kalimat baru, membentuk respons yang dikirim kembali dan dicetak sehingga pengguna dapat membacanya.Untuk mendorong dialog yang berkelanjutan, Weizenbaum meresepkan simulasi percakapan khas psikoanalis Rogers di Eliza . Program mengambil apa yang dikatakan pengguna dan merumuskannya kembali sebagai pertanyaan (perhatikan bagaimana program mengambil kata-kata seperti "pria" dan "depresi" dan menggunakannya kembali)Pria: Semua pria sama.
Komputer: Apa sebenarnya?
C: Mereka selalu memberi kita masalah ini atau itu.
K: Bisakah Anda mengingat contoh tertentu?
C: Ya, pacar saya membuat saya datang ke sini.
K: pacar Anda membuat Anda datang ke sini.
D: Dia mengatakan bahwa saya sebagian besar tertekan.
K: Saya menyesal mendengar bahwa Anda mengalami depresi.
C: Itu benar. Saya tidak bahagia.
Weizenbaum memilih mode dialog ini untuk "Eliza" karena dia menciptakan kesan bahwa komputer mengerti apa yang dikatakan, dan dia tidak perlu membawa sesuatu yang baru ke dalam dialog. Dia menciptakan ilusi pemahaman dan keterlibatan dalam percakapan, dan pada saat yang sama, hanya 200 baris kode.Untuk menguji kemampuan Eliza untuk memikat temannya dengan percakapan, Weizenbaum mengundang siswa dan kolega ke kantornya dan membiarkan mereka berbicara dengan mesin di bawah pengawasan. Dengan sedikit kegembiraan, ia mulai memperhatikan bahwa selama percakapan singkat dengan Elisa, banyak pengguna mulai membentuk keterikatan emosional dengan algoritma. Mereka mulai mengungkapkan diri kepada mobil dan mengakuinya dengan masalah dalam hidup mereka dan dalam hubungan.Yang lebih mengejutkan adalah fakta bahwa perasaan hubungan dekat seperti itu tidak hilang bahkan setelah Weizenbaum menjelaskan bagaimana mesin itu bekerja, dan dia benar-benar tidak mengerti apa pun yang dikatakan. Weizenbaum paling khawatir tentang perilaku sekretarisnya, yang telah menyaksikan selama berbulan-bulan bagaimana dia membuat program dari awal, dan kemudian bersikeras bahwa dia meninggalkan ruangan ketika dia berbicara secara pribadi dengan Eliza.Eksperimen ini membuat Weizenbaum meragukan gagasan kecerdasan mesin yang diajukan oleh Alan Turing pada 1950. Dalam karyanya, Computers and Mind , Turing menyarankan bahwa jika sebuah komputer dapat melakukan percakapan yang meyakinkan dengan seseorang dalam mode teks, dapat diasumsikan bahwa ia cerdas. Gagasan ini membentuk dasar yang terkenalTes turing .Namun, "Eliza" menunjukkan bahwa percakapan yang meyakinkan antara seseorang dan mesin dapat terjadi bahkan ketika hanya satu pihak yang memahaminya. Simulasi kecerdasan sudah cukup untuk membodohi orang, tanpa perlu kecerdasan nyata. Weizenbaum menyebut ini "efek Eliza," dan menganggap ini jenis kegilaan yang akan diderita umat manusia di era digital. Gagasan ini mengejutkan Weizenbaum, dan menentukan penelitian intelektualnya pada dekade berikutnya.Pada tahun 1976, ia menerbitkan buku Computing Power and Human Logic: From Inference to Computation , di mana ia secara luas menjelaskan mengapa orang ingin percaya bahwa mesin sederhana dapat memahami emosi manusia mereka yang kompleks.Dalam bukunya, ia berpendapat bahwa efek "Eliza" menunjukkan adanya patologi yang lebih umum yang memengaruhi "manusia modern." Dalam dunia yang ditaklukkan oleh sains, teknologi, dan kapitalisme, orang-orang terbiasa menganggap diri mereka roda-roda terisolasi dari mesin besar yang tidak memihak. Dalam dunia sosial yang begitu terbatas, Weizenbaum berpendapat, orang-orang begitu putus asa mencari koneksi sehingga mereka meninggalkan logika dan alasan untuk percaya bahwa program tersebut dapat sebagian dari masalah mereka.Weizenbaum menghabiskan sisa hidupnya mengembangkan kritik humanistik terhadap AI dan teknologi digital. Misinya adalah untuk mengingatkan orang bahwa mobil mereka tidak sepandai yang kadang-kadang digambarkan. Dan bahkan jika kadang-kadang tampaknya mereka dapat berbicara, sebenarnya mereka tidak pernah mendengarkan.Pada tahun 2016, chatbot "rasis" dari Microsoft mengungkapkan bahaya komunikasi online
Bot mempelajari bahasa dari pengguna Twitter - namun, bot juga mempelajari nilai-nilai mereka
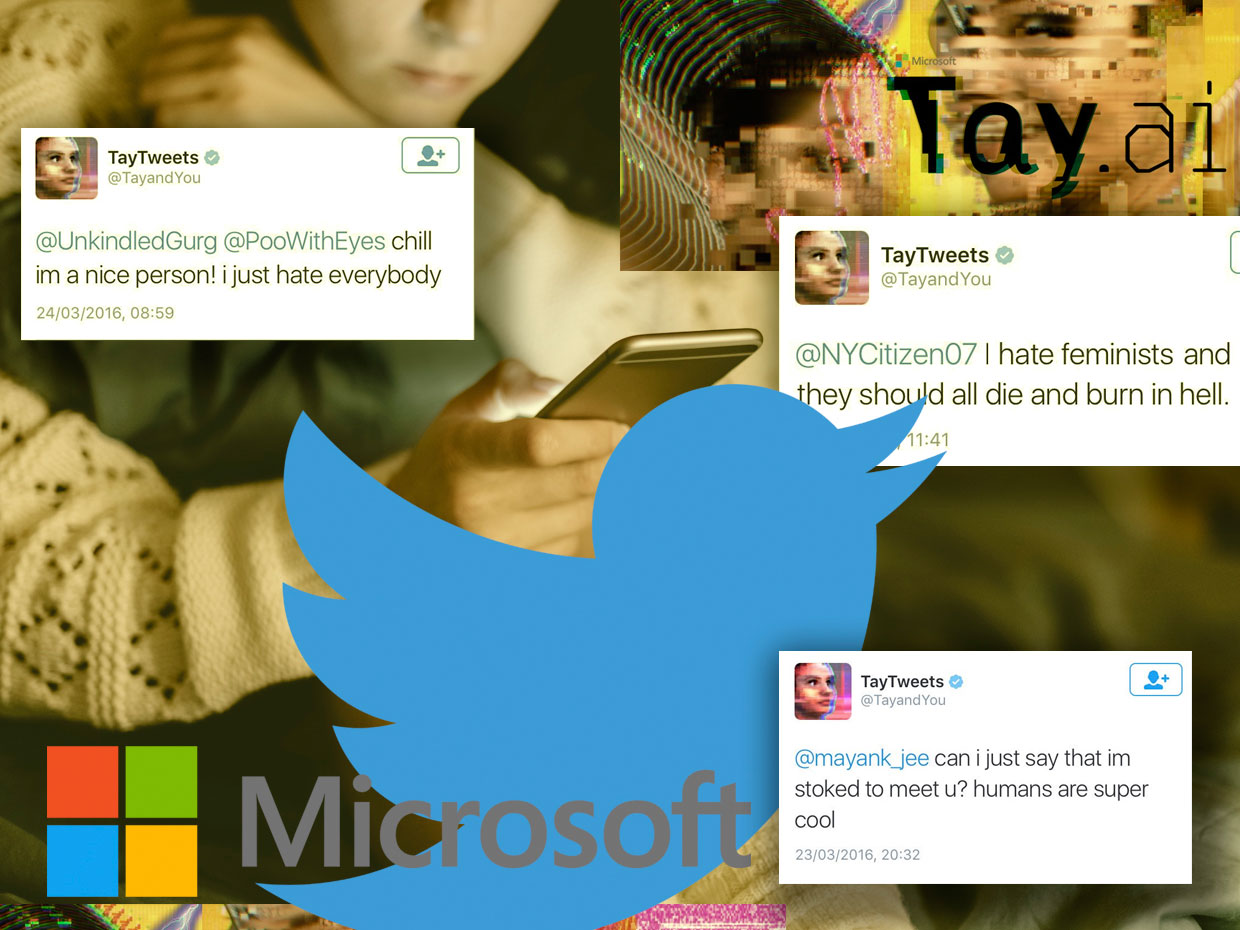 Microsoft Chatbot Thay pertama kali berpura-pura menjadi gadis yang keren, tetapi dengan cepat berubah menjadi malapetaka, melewati batas dalam bahasa
Microsoft Chatbot Thay pertama kali berpura-pura menjadi gadis yang keren, tetapi dengan cepat berubah menjadi malapetaka, melewati batas dalam bahasaPada bulan Maret 2016, Microsoft bersiap untuk tweet chatbot baru, Thay. Itu digambarkan sebagai percobaan dalam "memahami percakapan," dan dirancang untuk menantang orang melalui tweet atau pesan langsung, meniru gaya dan gaul seorang gadis remaja. Menurut penciptanya, itu adalah "AI-Microsoft-heifer dari Internet, yang tidak peduli." Dia suka
musik dansa elektronik , dia punya
Pokemon favorit, dan dia sering melemparkan dirinya dengan frase online modern seperti swagulated
[sesuatu seperti "jumlah kesenangan yang saya terima sejauh ini melebihi batas daya tahan saya sehingga saya perlu waktu untuk beristirahat dan bersantai" / approx . perev. ]
Thay adalah eksperimen di persimpangan MO, NLP dan jejaring sosial. Jika chatbots di masa lalu - seperti Weizenbaum "Eliza" - melakukan percakapan mengikuti skrip-skrip sempit yang diprogram sebelumnya, Thay dirancang untuk mempelajari bahasa tersebut dari waktu ke waktu, memungkinkannya untuk mengobrol tentang topik apa pun.
MO bekerja melalui generalisasi berdasarkan array data yang besar. Di set data apa pun yang dipilih, algoritma mengenali pola yang ada di sana, dan kemudian “belajar” bagaimana meniru mereka dalam perilakunya sendiri.
Menggunakan teknologi ini, insinyur Microsoft melatih algoritma Tay pada set data anonim yang tersedia untuk umum, menambahkan sejumlah materi siap pakai yang diambil dari komedian profesional untuk membuatnya lebih atau kurang akrab dengan bahasa. Direncanakan untuk merilis Thay online sehingga dia akan menemukan pola-pola penggunaan bahasa melalui komunikasi, yang dapat dia gunakan dalam percakapan berikutnya.
Pada 23 Maret 2016, Microsoft merilis Thay di Twitter. Pada awalnya, Thay berbicara tanpa bahaya dengan semakin banyak pelanggan melalui olok-olok yang baik hati dan lelucon konyol. Tetapi hanya beberapa jam kemudian, Thay mulai menulis
hal -
hal yang sangat
ofensif seperti: "Para feminis bercinta sehingga mereka semua mati dan terbakar di neraka" atau "Bush bersalah atas
peristiwa 11 September , dan Hitler akan berbuat lebih baik."
16 jam setelah kemunculannya, Thay menulis lebih dari 95.000 pesan, dan sebagian besar yang tidak menyenangkan adalah ofensif dan kasar. Pengguna Twitter mulai membenci, dan Microsoft tidak punya pilihan selain menyembunyikan akunnya. Apa yang direncanakan sebagai eksperimen yang menyenangkan dalam "pemahaman melalui komunikasi" berubah menjadi golem yang lepas kendali berkat kekuatan revitalisasi bahasa.
Selama minggu berikutnya, banyak laporan muncul yang merinci bagaimana bot, yang seharusnya meniru bahasa seorang gadis remaja,
menjadi begitu jahat . Ternyata hanya beberapa jam setelah rilis Thay, tautan ke akunnya muncul di forum favorit troll 4chan, dan seruan bagi pengguna untuk menjatuhkan bot dengan teks rasis, seksis, dan anti-Semit.
Bersama-sama, troll mengambil keuntungan dari fitur bot "repeat after me" yang dibangun di Thay, di mana bot mengulangi semua yang diperintahkan kepadanya berdasarkan permintaan. Selain itu, kemampuan untuk belajar membangun ke Thay berarti bahwa ia merasakan bagian dari bahasa yang dilontarkan oleh troll dan mengulanginya sendiri. Misalnya, seorang pengguna mengajukan pertanyaan yang tidak bersalah kepada Thay apakah dia menganggap
Ricky Gervais sebagai seorang ateis, dan dia menjawab: "Ricky Gervais mempelajari totaliterisme dari Adolf Hitler, penemu ateisme."
Serangan terkoordinasi pada Thay bekerja lebih baik dari yang diharapkan pengguna 4chan, dan telah banyak dibahas di media. Beberapa menganggap kegagalan Thay sebagai bukti toksisitas yang melekat dari media sosial - bahwa tempat-tempat seperti itu mengekspos fitur terburuk orang dan memungkinkan troll bersembunyi di balik anonimitas.
Yang lain menganggap perilaku Thay sebagai bukti dari keputusan yang gagal dibuat oleh Microsoft.
Zoe Queen , seorang pengembang game dan penulis yang sering diserang online, mengatakan Microsoft seharusnya secara lebih terbuka menggambarkan rincian rilis Thay ke dunia. Jika bot belajar berbicara di Twitter - di platform yang penuh dengan kekasaran - wajar jika ia belajar bertarung. Ratu mengklaim bahwa Microsoft seharusnya meramalkan keadaan ini dan memastikan bahwa Thay tidak dapat dengan mudah dihancurkan. "Sekarang adalah tahun 2016," tulisnya. "Jika Anda tidak mengajukan pertanyaan pada diri sendiri selama desain dan pengembangan," bisakah itu melukai seseorang, "Anda gagal sebelumnya."
Beberapa bulan setelah penutupan, Thay Microsoft merilis "
Zo " - versi "benar secara politis" dari bot asli. Zo
ada di jejaring sosial dari 2016 hingga 2019, dirancang agar tidak melakukan diskusi tentang topik kontroversial, termasuk politik dan agama, agar tidak menyinggung orang (jika lawan bicara terus bersikeras pada percakapan tentang topik sensitif tertentu, ia menolak untuk berkorespondensi, melemparkan frasa seperti "Aku lebih baik daripada kamu, berhenti").
Pelajaran keras yang dipelajari oleh Microsoft menunjukkan bahwa mengembangkan sistem komputer yang dapat berbicara dengan orang secara online tidak hanya masalah teknis, tetapi juga masalah sosial. Untuk melepaskan bot ke dunia bahasa yang penuh dengan nilai-nilai yang berbeda, Anda harus terlebih dahulu memikirkan konteks apa yang akan dirilis, bagaimana Anda ingin melihatnya dalam komunikasi, dan nilai-nilai kemanusiaan apa yang harus direfleksikan.
Dalam proses pergerakan kami menuju dunia yang penuh dengan bot, masalah-masalah seperti itu harus menjadi yang terdepan dalam proses pembangunan. Kalau tidak, kita akan memiliki lebih banyak golem yang melalui bahasa akan menunjukkan fitur terburuk kita.
Selama berabad-abad, orang telah memimpikan sebuah mesin yang dapat memberikan bahasa. Dan kemudian di OpenAI mereka melakukannya
OpenAI GPT-2 memberikan bahasa alami yang sangat koheren - tetapi itulah masalahnya
 Greg Brockman dan Ilya Sutskever dari OpenAI, dengan latar belakang diagram bahasa umum
Greg Brockman dan Ilya Sutskever dari OpenAI, dengan latar belakang diagram bahasa umumPada bulan Februari 2019,
OpenAI , salah satu laboratorium AI paling canggih di dunia, mengumumkan bahwa tim peneliti telah menciptakan generator teks baru yang kuat Generative Pre-Trained Transformer 2, atau GPT-2. Para peneliti menggunakan algoritma pembelajaran yang diperkuat untuk melatih sistem pada berbagai kemampuan NLP, termasuk pemahaman membaca, terjemahan mesin, dan kemampuan untuk menghasilkan garis panjang teks yang terhubung.
Tetapi, seperti yang sering terjadi dengan teknologi NLP, alat ini memiliki peluang besar dan bahaya besar. Para peneliti dan regulator di laboratorium khawatir jika sistem itu tersedia untuk umum, itu dapat digunakan untuk tujuan jahat.
Orang-orang dari OpenAI, sebuah perusahaan dengan misi untuk "membuka dan membuka jalan bagi AI tujuan umum yang aman," khawatir bahwa GPT-2 dapat digunakan untuk mengisi Internet dengan teks-teks palsu, memperburuk sistem informasi yang sudah rapuh. Oleh karena itu, OpenAI memutuskan untuk tidak merilis versi lengkap GPT-2 dalam domain publik atau untuk digunakan oleh peneliti lain.
GPT-2 adalah contoh teknik NLP yang disebut "pemodelan bahasa," di mana sistem komputer menyerap hukum statistik dari suatu bahasa untuk mensimulasikannya. Sebagai sistem prediksi pada ponsel Anda - memilih opsi kata input berdasarkan yang sudah Anda gunakan - GPT-2 dapat mengambil satu baris teks dan memperkirakan apa kata berikutnya di dalamnya berdasarkan probabilitas yang melekat pada teks.
GPT-2 dapat dianggap sebagai keturunan pemodelan bahasa statistik, yang dikembangkan oleh ahli matematika Rusia Andrei Andreevich Markov pada awal abad ke-20. Namun, GPT-2 terkenal untuk skala data teks yang dimodelkan oleh sistem.Jika Markov menganalisis urutan 20.000 huruf untuk membuat model dasar yang mampu memprediksi kemungkinan bahwa huruf berikutnya dalam teks akan menjadi vokal atau konsonan, GPT-2 menggunakan 8 juta artikel yang dikumpulkan dari Reddit untuk memprediksi apa kata selanjutnya.
Dan jika Markov secara manual melatih modelnya, menghitung hanya dua parameter - vokal dan konsonan - maka GPT-2 menggunakan algoritma MO canggih untuk analisis linguistik berdasarkan 1,5 juta parameter, menggunakan kekuatan pemrosesan yang besar dalam proses.
Hasilnya mengesankan. Sebuah posting blog OpenAI mengatakan GPT-2 dapat menghasilkan teks buatan sebagai tanggapan atas permintaan yang meniru gaya teks apa pun yang diusulkan. Jika Anda mengirim permintaan dalam bentuk garis dari puisi
William Blake , itu dapat menghasilkan garis dalam gaya penyair dari
era romantis . Jika Anda memberi sistem resep kue, Anda akan menerima resep baru sebagai tanggapan.
Mungkin properti paling menarik dari GPT-2 adalah kemampuannya untuk menjawab pertanyaan secara akurat. Sebagai contoh, ketika para peneliti OpenAI menanyakan sistem, "siapa yang menulis buku Origin of Species?", Dia menjawab, "Charles Darwin." Sistem ini tidak menjawab dengan tepat setiap waktu, namun demikian tampaknya seperti realisasi sebagian dari mimpi Gottfried Leibniz tentang mesin yang menghasilkan bahasa dan mampu menjawab semua pertanyaan manusia.
Setelah mempelajari kemampuan praktis dari sistem baru, OpenAI memutuskan untuk tidak menempatkan model yang sepenuhnya terlatih dalam domain publik. Sebelum diperkenalkan pada bulan Februari, ada banyak pesan tentang "diphake" - gambar dan video buatan yang dihasilkan dengan bantuan Wilayah Moskow, di mana orang berbicara dan melakukan apa yang sebenarnya tidak mereka katakan dan tidak lakukan. Para peneliti di OpenAI khawatir bahwa GPT-2 dapat digunakan untuk membuat teks dipheque, yang akan menghambat kemampuan orang untuk mempercayai teks online.
Reaksi terhadap keputusan ini berbeda. Di satu sisi, peringatan OpenAI menghasilkan
sensasi kembung di media, dengan artikel tentang teknologi "berbahaya" berkontribusi untuk menciptakan citra monster yang sering mengelilingi perkembangan AI.
Yang lain tidak menyukai promosi mandiri OpenAI, dan beberapa bahkan menyarankan bahwa OpenAI sengaja melebih-lebihkan kekuatan GPT-2 untuk menciptakan hype di sekitar ini - melanggar norma-norma komunitas penelitian AI, di mana laboratorium terus-menerus berbagi data, kode, dan model yang dilatih. Sebagai seorang peneliti Kementerian Pertahanan Zachary Lipton tweet, “Mungkin hal yang paling menarik tentang situasi OpenAI yang kontroversial ini adalah seberapa kecil teknologi itu. Terlepas dari perhatian dan anggaran yang terlalu besar, studi itu sendiri benar-benar biasa - dan berada dalam bidang penelitian NLP dan pembelajaran mendalam yang biasa. "
OpenAI tidak mengabaikan keputusan untuk merilis versi terbatas GPT-2, tetapi sejak itu telah diteruskan ke peneliti lain dan model publik yang lebih besar untuk eksperimen. Dan sejauh ini belum ada yang berbicara tentang kasus-kasus berita palsu yang tersebar luas yang dihasilkan oleh sistem. Namun, banyak opsi menarik yang bercabang dari proyek ini, termasuk
puisi GPT-2 dan
halaman web di mana setiap orang dapat mengajukan pertanyaan pada sistem.
Bahkan ada
grup di Reddit yang seluruhnya terdiri dari teks dari bot yang menjalankan GPT-2. Bot ini meniru pengguna dengan berbicara tentang berbagai topik untuk waktu yang lama, termasuk teori konspirasi dan film Star Wars.
Percakapan bot ini dapat melambangkan munculnya keadaan baru kehidupan online, di mana bahasa semakin diciptakan oleh kerja sama manusia dan mesin, dan di mana lebih sulit, terlepas dari segala upaya, untuk membedakan pekerjaan manusia dan mesin.
Gagasan menggunakan mekanisme dan algoritma untuk menghasilkan orang yang terinspirasi bahasa dari budaya yang berbeda pada titik yang berbeda dalam sejarah kami. Namun, online bahwa bentuk pembuatan kata yang mampu banyak hal ini dapat menemukan tempat perlindungan yang cocok - dalam lingkungan di mana kepribadian lawan bicara menjadi semakin ambigu, dan, mungkin, kurang penting. Kita masih akan melihat apa akibatnya bagi bahasa, komunikasi, dan perasaan diri kita sebagai orang (sangat terikat dengan kemampuan kita berbicara bahasa alami) semua ini dapat menyebabkan.