Setiap
gambar raster dapat direpresentasikan sebagai
matriks dua dimensi . Ketika datang ke warna, idenya dapat dikembangkan dengan melihat gambar dalam bentuk
matriks tiga dimensi , di mana pengukuran tambahan digunakan untuk menyimpan data untuk masing-masing warna.
Jika kita menganggap warna akhir sebagai kombinasi dari yang disebut warna primer (merah, hijau dan biru), dalam matriks tiga dimensi kami, kami menentukan tiga bidang: yang pertama untuk merah, yang kedua untuk hijau dan yang terakhir untuk biru.
Kami akan menyebut setiap titik dalam matriks ini piksel (elemen gambar). Setiap piksel berisi informasi intensitas (biasanya dalam bentuk nilai numerik) dari setiap warna. Misalnya,
piksel merah berarti memiliki 0 hijau, 0 biru dan maksimum merah.
Pixel merah muda dapat dibentuk menggunakan kombinasi tiga warna. Menggunakan rentang numerik dari 0 hingga 255, piksel pink didefinisikan sebagai
Merah = 255 ,
Hijau = 192, dan
Biru = 203 .

Artikel ini diterbitkan dengan dukungan EDISON.
Kami mengembangkan aplikasi untuk pengawasan video, streaming video , serta perekaman video di ruang bedah .
Teknik pengkodean warna alternatif
Untuk mewakili warna yang membentuk gambar, ada banyak model lain. Misalnya, Anda dapat menggunakan palet yang diindeks di mana hanya satu byte diperlukan untuk mewakili setiap piksel, alih-alih tiga yang diperlukan saat menggunakan model RGB. Dalam model seperti itu, Anda dapat menggunakan matriks 2D alih-alih matriks 3D untuk mewakili setiap warna. Ini menghemat memori, tetapi memberi lebih sedikit warna.

RGB
Sebagai contoh, lihat gambar ini di bawah ini. Wajah pertama sepenuhnya dicat. Lainnya adalah bidang merah, hijau, dan biru (intensitas warna yang sesuai ditunjukkan dalam skala abu-abu).

Kita melihat bahwa nuansa merah pada dokumen asli akan berada di tempat yang sama di mana bagian paling terang dari orang kedua diamati. Sedangkan kontribusi biru terutama dapat dilihat hanya di mata Mario (wajah terakhir) dan elemen pakaiannya. Perhatikan di mana ketiga bidang warna memberikan kontribusi paling sedikit (bagian paling gelap dari gambar) - ini adalah kumis Mario.
Untuk menyimpan intensitas setiap warna, sejumlah bit diperlukan - nilai ini disebut
kedalaman bit . Katakanlah 8 bit dihabiskan (berdasarkan nilai dari 0 hingga 255) pada satu bidang warna. Kemudian kita memiliki kedalaman warna 24 bit (8 bit * 3 R / G / B pesawat).
Properti lain dari gambar adalah
resolusi , yang merupakan jumlah piksel dalam satu dimensi. Ini sering disebut sebagai
lebar × tinggi , seperti di bawah ini dalam contoh gambar 4 oleh 4.

Properti lain yang kami tangani ketika bekerja dengan gambar / video adalah
rasio aspek , yang menggambarkan hubungan proporsional yang biasa antara lebar dan tinggi gambar atau piksel.
Ketika mereka mengatakan bahwa film atau gambar berukuran 16 x 9, biasanya mengacu pada
rasio aspek tampilan (
DAR - dari
Display Aspect Ratio ). Namun, terkadang ada beberapa bentuk piksel yang berbeda - dalam hal ini kita berbicara tentang
rasio piksel (
PAR - dari
Pixel Aspect Ratio ).


Catatan untuk nyonya rumah: DVD sesuai dengan DAR 4 oleh 3
Meskipun resolusi sebenarnya dari DVD adalah 704x480, namun tetap mempertahankan rasio aspek 4: 3 karena PAR diatur ke 10:11 (704x10 / 480x11).
Dan akhirnya, kita dapat mendefinisikan
video sebagai urutan
n bingkai selama periode
waktu tertentu , yang dapat dianggap sebagai dimensi tambahan. Dan
n kemudian adalah frame rate atau jumlah frame per detik (
FPS - from
Frames per Second ).

Jumlah bit per detik yang diperlukan untuk menampilkan video adalah
bit rate-nya .
bitrate = lebar * tinggi * kedalaman bit * frame per detik
Misalnya, untuk video dengan 30 frame per detik, 24 bit per pixel, resolusi 480x240, 82.944.000 bit per detik atau 82.944 Mbps (30x480x240x24) akan diperlukan - tetapi ini adalah jika Anda tidak menggunakan metode kompresi apa pun.
Jika laju bit
hampir konstan , maka itu disebut
laju bit konstan (
CBR - dari
laju bit konstan ). Tetapi bisa juga bervariasi, dalam hal ini disebut
laju bit variabel (
VBR - from
variable bit rate ).
Grafik ini menunjukkan VBR terbatas ketika tidak terlalu banyak bit dihabiskan dalam kasus bingkai yang sepenuhnya gelap.

Awalnya, para insinyur mengembangkan metode untuk menggandakan frame rate yang dirasakan dari tampilan video tanpa menggunakan bandwidth tambahan. Metode ini dikenal sebagai
video interlaced ; pada dasarnya, ia mengirim setengah layar di "frame" pertama, dan setengah lainnya di "frame" berikutnya.
Saat ini, visualisasi pemandangan terutama dilakukan dengan menggunakan
teknologi pemindaian progresif . Ini adalah metode untuk menampilkan, menyimpan atau mentransmisikan gambar bergerak di mana semua garis dari setiap frame digambar secara berurutan.

Baiklah kalau begitu! Sekarang kita tahu bagaimana gambar direpresentasikan dalam bentuk digital, bagaimana warnanya diatur, berapa banyak bit per detik yang kita habiskan untuk menampilkan video jika kecepatan transmisi konstan (CBR) atau variabel (VBR). Kami tahu tentang resolusi yang diberikan menggunakan frame rate yang diberikan, berkenalan dengan banyak istilah lain, seperti video interlaced, PAR dan beberapa lainnya.
Penghapusan Redundansi
Diketahui bahwa video tanpa kompresi tidak dapat digunakan secara normal. Video setiap jam dengan resolusi 720p dan frekuensi 30 frame per detik akan menempati 278 GB. Kami tiba pada nilai ini dengan mengalikan 1280 x 720 x 24 x 30 x 3600 (lebar, tinggi, bit per piksel, FPS dan waktu dalam detik).
Menggunakan
algoritma kompresi lossless seperti DEFLATE (digunakan dalam PKZIP, Gzip, dan PNG) tidak akan cukup mengurangi bandwidth yang diperlukan. Anda harus mencari cara lain untuk mengompres video.
Untuk ini, Anda dapat menggunakan fitur-fitur dari visi kami. Kami membedakan kecerahan yang lebih baik daripada warna. Video adalah sekumpulan gambar berurutan yang berulang seiring waktu. Ada perbedaan kecil antara bingkai yang berdekatan dari adegan yang sama. Selain itu, setiap frame berisi banyak area yang menggunakan warna yang sama (atau serupa).
Warna, kecerahan, dan mata kita
Mata kita lebih sensitif terhadap kecerahan daripada warna. Anda dapat melihat sendiri dengan melihat gambar ini.
Jika Anda tidak melihat bahwa di bagian kiri gambar warna kotak
A dan
B sebenarnya sama, maka ini normal. Otak kita membuat kita lebih memperhatikan chiaroscuro daripada warna. Di sisi kanan antara kotak yang ditandai ada jumper dengan warna yang sama - karena itu kita (yaitu otak kita) dapat dengan mudah menentukan bahwa, sebenarnya, warna yang sama ada di sana.
Mari kita lihat (disederhanakan) bagaimana mata kita bekerja. Mata adalah organ kompleks yang terdiri dari banyak bagian. Namun, kami paling tertarik pada kerucut dan tongkat. Mata berisi sekitar 120 juta batang dan 6 juta kerucut.
Anggap persepsi warna dan kecerahan sebagai fungsi terpisah dari bagian mata tertentu (pada kenyataannya, semuanya agak lebih rumit, tapi kami akan menyederhanakannya). Sel batang terutama bertanggung jawab untuk kecerahan, sedangkan sel kerucut bertanggung jawab untuk warna. Kerucut dibagi menjadi tiga jenis, tergantung pada pigmen yang terkandung: S-cone (warna biru), M-cone (warna hijau) dan L-cone (warna merah).
Karena kita memiliki lebih banyak batang (kecerahan) daripada kerucut (warna), kita dapat menyimpulkan bahwa kita lebih mampu membedakan antara transisi antara gelap dan terang daripada warna.

Fungsi sensitivitas kontras
Para peneliti dalam psikologi eksperimental dan banyak bidang lain telah mengembangkan banyak teori penglihatan manusia. Dan salah satunya disebut fungsi sensitivitas kontras . Mereka terkait dengan pencahayaan spasial dan temporal. Singkatnya, ini tentang berapa banyak perubahan yang diperlukan sebelum pengamat melihatnya. Perhatikan bentuk jamak dari kata "function." Hal ini disebabkan oleh fakta bahwa kita dapat mengukur fungsi sensitivitas untuk kontras tidak hanya untuk gambar hitam dan putih, tetapi juga warna. Hasil percobaan ini menunjukkan bahwa dalam kebanyakan kasus, mata kita lebih sensitif terhadap kecerahan daripada warna.
Karena diketahui bahwa kami lebih sensitif terhadap kecerahan gambar, Anda dapat mencoba menggunakan fakta ini.
Model warna
Kami menemukan sedikit cara untuk bekerja dengan gambar berwarna menggunakan skema RGB. Ada model lain. Ada model yang memisahkan pencahayaan dari warna dan dikenal sebagai
YCbCr . Ngomong-ngomong, ada model lain yang membuat pemisahan serupa, tetapi kami hanya akan mempertimbangkan yang satu ini.
Dalam model warna ini,
Y adalah representasi kecerahan, dan dua saluran warna digunakan:
Cb (biru jenuh) dan
Cr (jenuh merah). YCbCr dapat diperoleh dari RGB, serta transformasi terbalik dimungkinkan. Dengan menggunakan model ini, kita dapat membuat gambar penuh warna, seperti yang kita lihat di bawah:

Konversi antara YCbCr dan RGB
Seseorang akan keberatan: bagaimana mungkin untuk mendapatkan semua warna jika hijau tidak digunakan?
Untuk menjawab pertanyaan ini, ubah RGB ke YCbCr. Kami menggunakan koefisien yang diadopsi dalam
standar BT.601 , yang direkomendasikan oleh unit
ITU-R . Unit ini mendefinisikan standar video digital. Misalnya: apa itu 4K? Apa yang seharusnya menjadi frame rate, resolusi, model warna?
Pertama, kami menghitung kecerahan. Kami menggunakan konstanta yang diusulkan oleh ITU dan mengganti nilai RGB.
Y = 0,299
R + 0,587
G + 0,114
BSetelah kami mendapatkan kecerahan, kami akan memisahkan warna biru dan merah:
Cb = 0,564 (
B -
Y )
Cr = 0,713 (
R -
Y )
Dan kita juga dapat mengonversi kembali dan bahkan menjadi hijau dengan YCbCr:
R =
Y + 1,402
CrB =
Y + 1,772
CbG =
Y - 0,344
Cb - 0,714
CrBiasanya, display (monitor, TV, layar, dll.) Hanya menggunakan model RGB. Tetapi model ini dapat diatur dengan berbagai cara:

Downsampling warna
Dengan gambar yang disajikan sebagai kombinasi kecerahan dan warna, kita dapat menggunakan sensitivitas yang lebih tinggi dari sistem visual manusia terhadap kecerahan daripada warna jika kita secara selektif menghapus informasi. Downsampling warna adalah metode pengkodean gambar menggunakan resolusi warna yang lebih rendah daripada kecerahan.
Bagaimana bisa diterima untuk mengurangi resolusi warna ?! Ternyata sudah ada beberapa skema yang menjelaskan cara menangani resolusi dan penggabungan
(Warna akhir = Y + Cb + Cr).Skema ini dikenal sebagai
sistem subsampling dan dinyatakan dalam bentuk rasio 3 kali lipat -
a : x : y , yang menentukan jumlah sampel sinyal luminansi dan perbedaan warna.
a - pengambilan sampel horizontal standar (biasanya sama dengan 4)
x - jumlah sampel warna pada baris pertama piksel (resolusi horizontal relatif terhadap
a )
y adalah jumlah perubahan sampel warna antara baris piksel pertama dan kedua.
Pengecualiannya adalah 4 : 1 : 0 , yang menyediakan satu sampel warna di setiap blok resolusi kecerahan 4 kali 4.
Skema umum yang digunakan dalam codec modern:
- 4 : 4 : 4 (tanpa downsampling)
- 4 : 2 : 2
- 4 : 1 : 1
- 4 : 2 : 0
- 4 : 1 : 0
- 3 : 1 : 1
YCbCr 4: 2: 0 - Contoh Penggabungan
Berikut adalah fragmen gambar gabungan menggunakan YCbCr 4: 2: 0. Harap dicatat bahwa kami hanya menghabiskan 12 bit per piksel.
Ini adalah bagaimana gambar yang sama dikodekan oleh jenis-jenis utama dari subsampling warna. Baris pertama adalah YCbCr akhir, baris bawah menunjukkan resolusi warna. Hasil yang sangat layak, mengingat sedikit kerugian dalam kualitas.

Ingat, kami menghitung ruang penyimpanan 278 GB untuk file video berdurasi satu jam dengan resolusi 720p dan 30 frame per detik? Jika kita menggunakan YCbCr 4: 2: 0, maka ukuran ini akan berkurang setengahnya - 139 GB. Sejauh ini, masih jauh dari hasil yang dapat diterima.
Anda bisa mendapatkan histogram YCbCr sendiri dengan FFmpeg. Dalam gambar ini, biru menang atas merah, yang terlihat jelas pada histogram itu sendiri.

Warna, kecerahan, gamut warna - ulasan video
Disarankan untuk menonton video yang luar biasa ini. Ini menjelaskan apa itu kecerahan, dan memang semua titik ditempatkan di atasnya tentang kecerahan dan warna.
Jenis bingkai
Kami melanjutkan. Mari kita coba menghilangkan redundansi dalam waktu. Tapi pertama-tama, mari kita mendefinisikan beberapa terminologi dasar. Misalkan kita memiliki film dengan 30 frame per detik, berikut adalah 4 frame pertamanya:




Kita dapat melihat banyak pengulangan dalam bingkai: misalnya, latar belakang biru yang tidak berubah dari bingkai ke bingkai. Untuk mengatasi masalah ini, kita dapat mengklasifikasikannya secara abstrak sebagai tiga jenis bingkai.
I-frame ( I ntro Frame)
I-frame (bingkai referensi, bingkai kunci, bingkai internal) bersifat otonom. Terlepas dari apa yang perlu divisualisasikan, bingkai-I, pada kenyataannya, adalah foto statis. Frame pertama biasanya merupakan frame-I, tetapi kami akan secara teratur mengamati frame-I di antara jauh dari frame pertama.
P-frame ( P redicted Frame)
Bingkai-P (bingkai yang diprediksi) mengambil keuntungan dari kenyataan bahwa hampir selalu gambar saat ini dapat diputar menggunakan bingkai sebelumnya. Misalnya, di frame kedua, satu-satunya perubahan adalah bola ke depan. Kita bisa mendapatkan frame 2 hanya dengan sedikit memodifikasi frame 1, hanya menggunakan perbedaan antara frame-frame ini. Untuk membangun bingkai 2, lihat bingkai 1 yang mendahuluinya.
←

B-frame ( B i-predictive Frame)
Bagaimana dengan tautan tidak hanya ke masa lalu, tetapi juga ke bingkai di masa depan, untuk memberikan kompresi yang lebih baik? Ini pada dasarnya adalah B-frame (bingkai dua arah).
←
→
Penarikan menengah
Jenis bingkai ini digunakan untuk memberikan kompresi terbaik. Kami akan membahas bagaimana ini terjadi di bagian selanjutnya. Sementara itu, kami mencatat bahwa I-frame adalah yang paling "mahal" dalam hal memori, P-frame jauh lebih murah, tetapi B-frame adalah pilihan paling menguntungkan untuk video.

Redundansi temporal (prediksi antar-bingkai)
Mari kita lihat peluang apa yang kita miliki untuk meminimalkan pengulangan waktu. Jenis redundansi ini dapat diselesaikan dengan menggunakan metode peramalan bersama.
Kami akan mencoba menghabiskan sesedikit mungkin bit untuk mengkodekan urutan frame 0 dan 1.

Kita dapat
mengurangi , hanya mengurangi frame 1 dari frame 0. Kita mendapatkan frame 1, kita hanya menggunakan perbedaan antara itu dan frame sebelumnya, pada kenyataannya, kita hanya mengkodekan sisa yang dihasilkan.

Tetapi bagaimana jika saya memberi tahu Anda bahwa ada metode yang lebih baik yang menggunakan bit lebih sedikit lagi ?! Pertama, mari kita hancurkan frame 0 ke dalam kotak blok yang jelas. Dan kemudian kami mencoba membandingkan blok dari frame 0 dengan frame 1. Dengan kata lain, kami mengevaluasi pergerakan antar frame.
Dari Wikipedia - blokir kompensasi gerak
Kompensasi gerak blok membagi bingkai saat ini menjadi blok-blok terpisah dan vektor kompensasi gerak melaporkan asal-usul blok-blok tersebut (kesalahpahaman yang umum adalah bahwa frame sebelumnya dibagi menjadi blok-blok terpisah, dan vektor-vektor kompensasi gerak menentukan ke mana blok-blok ini pergi. Bahkan, sebaliknya, yang sebelumnya dianalisis bingkai, dan yang berikutnya, ternyata bukan dari mana balok bergerak, tetapi dari mana asalnya). Biasanya, blok sumber tumpang tindih dalam bingkai sumber. Beberapa algoritma kompresi video mengumpulkan frame saat ini dari bagian tidak hanya satu, tetapi beberapa frame yang sebelumnya ditransmisikan.

Dalam proses evaluasi, kita melihat bahwa bola telah bergerak dari
( x = 0, y = 25) ke
( x = 6, y = 26) , nilai
x dan
y menentukan vektor gerak. Langkah lain yang dapat kita ambil untuk menyelamatkan bit adalah mengkodekan hanya perbedaan vektor gerakan antara posisi terakhir dari blok dan yang diprediksi, sehingga vektor gerakan akhir akan menjadi
(x = 6-0 = 6, y = 26-25 = 1).Dalam situasi nyata, bola ini akan dibagi menjadi
n blok, tetapi ini tidak mengubah esensi masalah ini.
Objek dalam bingkai bergerak dalam tiga dimensi, jadi saat bola bergerak, ia bisa menjadi lebih kecil secara visual (atau lebih banyak jika bergerak ke arah penonton). Adalah normal bahwa tidak akan ada kecocokan sempurna antara blok. Berikut ini adalah pandangan gabungan dari penilaian kami dan gambaran nyata.

Tetapi kita melihat bahwa ketika kita menerapkan estimasi gerakan, data untuk pengkodean terasa lebih sedikit daripada saat menggunakan metode yang lebih sederhana dalam menghitung delta antar frame.

Akan seperti apa kompensasi gerak sebenarnya
Teknik ini berlaku segera untuk semua blok. Seringkali, bola bergerak bersyarat kami akan dibagi menjadi beberapa blok sekaligus.

Anda dapat merasakan konsep-konsep ini sendiri menggunakan
Jupyter .
Untuk melihat vektor gerakan, Anda dapat membuat video dengan prediksi eksternal menggunakan
ffmpeg .
 dengan ffmpeg")
Anda juga dapat menggunakan
Intel Video Pro Analyzer (berbayar, tetapi ada versi percobaan gratis, yang hanya dibatasi oleh sepuluh frame pertama).

Redundansi Spasial (Prakiraan Internal)
Jika kami menganalisis setiap frame dalam video, kami menemukan banyak area yang saling berhubungan.

Mari kita telaah contoh ini. Adegan ini terutama terdiri dari biru dan putih.

Ini adalah I-frame. Kami tidak dapat mengambil frame sebelumnya untuk perkiraan, tetapi akan berubah menjadi kompres. . , , - .
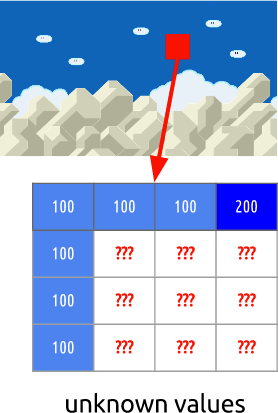
, . , .
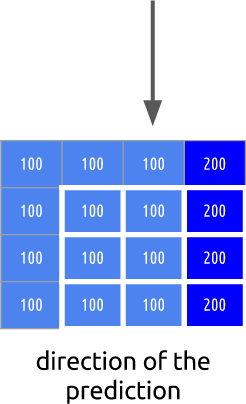
. ( ), . , .
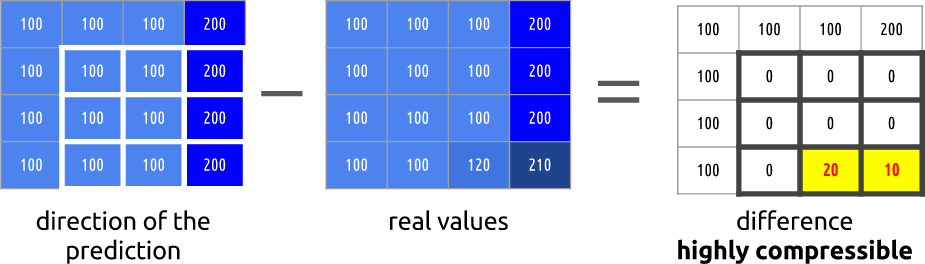
, ffmpeg. ffmpeg.
 dengan ffmpeg") Atau Anda dapat menggunakan Intel Video Pro Analyzer (seperti yang saya sebutkan di atas, dalam versi uji coba gratis ada batasan pada 10 frame pertama, tetapi ini sudah cukup untuk Anda pada awalnya).
Atau Anda dapat menggunakan Intel Video Pro Analyzer (seperti yang saya sebutkan di atas, dalam versi uji coba gratis ada batasan pada 10 frame pertama, tetapi ini sudah cukup untuk Anda pada awalnya).

Baca juga blognya
Perusahaan EDISON:
20 perpustakaan untuk
aplikasi iOS yang spektakuler