Penguatan Pembelajaran sering menggunakan rasa ingin tahu sebagai motivasi untuk AI. Memaksa dia untuk mencari sensasi baru dan menjelajahi dunia. Tapi hidup ini penuh kejutan yang tidak menyenangkan. Anda dapat jatuh dari tebing dan dari sudut pandang keingintahuan akan selalu menjadi sensasi yang sangat baru dan menarik. Tapi jelas bukan apa yang harus diperjuangkan.
Pengembang dari Berkeley membalikkan tugas agen virtual dengan terbalik: bukan keingintahuan yang membuat kekuatan pendorong utama, tetapi keinginan untuk menghindari hal baru dengan segala cara. Tetapi "tidak melakukan apa-apa" lebih sulit daripada kedengarannya. Ditempatkan dalam lingkungan yang terus berubah, AI harus belajar perilaku yang kompleks untuk menghindari sensasi baru.
Penguatan Pembelajaran mengambil langkah-langkah malu-malu untuk membangun AI yang kuat. Dan sementara semuanya terbatas pada dimensi yang sangat rendah, secara harfiah unit-unit di mana agen virtual harus bertindak (lebih disukai secara wajar), dari waktu ke waktu muncul ide-ide baru bagaimana meningkatkan pelatihan kecerdasan buatan.
Tetapi tidak hanya algoritma pembelajaran yang rumit. Lingkungan juga semakin sulit. Kebanyakan lingkungan pembelajaran penguatan sangat sederhana dan memotivasi agen untuk menjelajahi dunia. Ini bisa berupa labirin yang harus dielakkan sepenuhnya untuk menemukan jalan keluar, atau permainan komputer yang harus diselesaikan hingga akhir.
Tetapi dalam jangka panjang, makhluk hidup (masuk akal dan tidak begitu) berusaha tidak hanya untuk menjelajahi dunia di sekitar mereka. Tetapi juga untuk menjaga semua kebaikan yang ada dalam hidup mereka yang pendek (atau tidak demikian).
Ini disebut homeostasis - keinginan tubuh untuk mempertahankan keadaan konstan. Dalam satu bentuk atau lainnya, ini biasa terjadi pada semua makhluk hidup. Pengembang dari Berkeley memberikan contoh aneh: semua prestasi umat manusia, pada umumnya, dirancang untuk melindungi dari kejutan yang tidak menyenangkan. Untuk melindungi terhadap entropi lingkungan yang semakin meningkat. Kami membangun rumah tempat kami menjaga suhu konstan, terlindung dari perubahan cuaca. Kami menggunakan obat untuk selalu sehat dan sebagainya.
Seseorang dapat berdebat dengan ini, tetapi sebenarnya ada sesuatu dalam analogi ini.
Para lelaki mengajukan pertanyaan - apa yang akan terjadi jika motivasi utama AI adalah mencoba menghindari hal-hal baru? Minimalkan kekacauan sebagai fungsi pembelajaran objektif, dengan kata lain.
Dan mereka menempatkan agen di dunia berbahaya yang terus berubah.
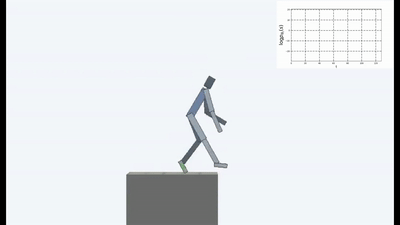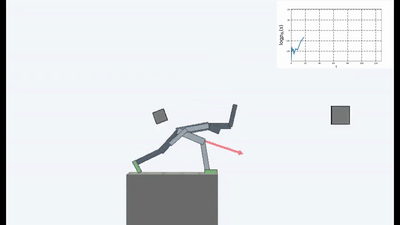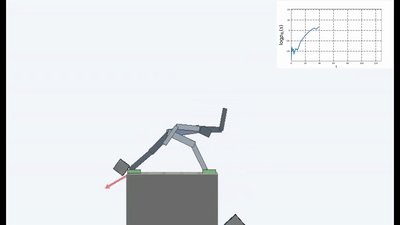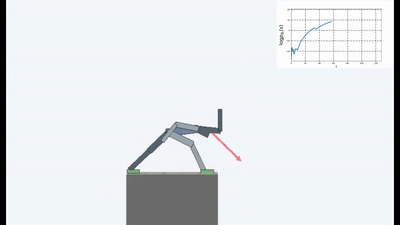
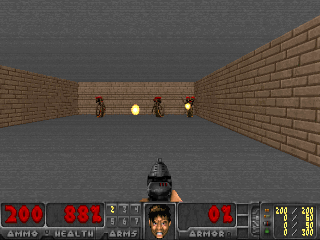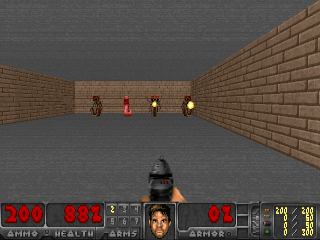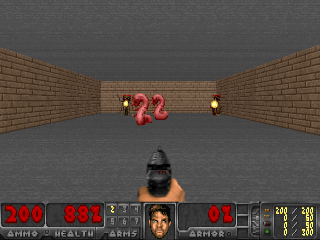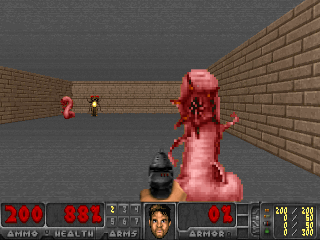
Hasilnya menarik. Dalam banyak kasus, pembelajaran seperti itu telah melampaui pembelajaran berbasis kurikulum, dan lebih sering, dalam hal kualitas, mendekati pembelajaran dengan seorang guru. Artinya, untuk pelatihan khusus untuk mencapai tujuan tertentu - untuk memenangkan permainan, melalui labirin.
Ini tentu saja logis, karena jika Anda berdiri di jembatan yang runtuh, maka untuk terus berada di atasnya (untuk mempertahankan keteguhan dan menghindari sensasi baru jatuh), Anda harus terus-menerus menjauh dari tepi. Lari dengan sekuat tenaga untuk tetap diam, seperti kata Alice.

Dan faktanya, dalam algoritma pembelajaran penguatan apa pun, ada momen seperti itu. Karena kematian dalam permainan dan akhir episode yang cepat akan dihukum dengan hadiah negatif. Atau, tergantung pada algoritma, dengan mengurangi hadiah maksimum yang bisa diterima agen jika tidak jatuh terus menerus dari tebing.
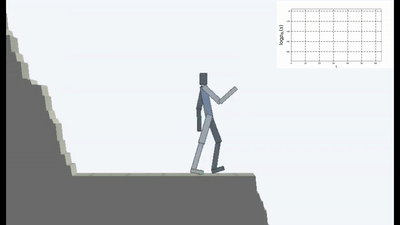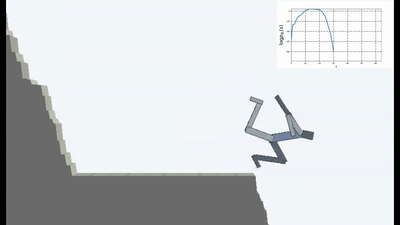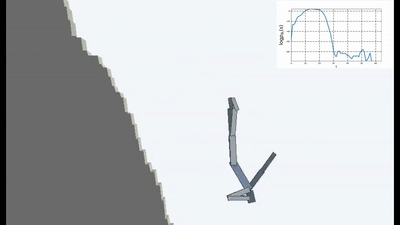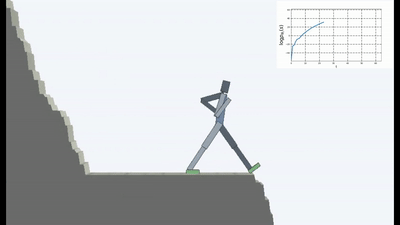
Tapi itu dalam formulasi seperti itu, ketika AI tidak memiliki tujuan lain selain keinginan untuk menghindari kebaruan, sepertinya itu digunakan untuk pertama kalinya dalam pembelajaran yang diperkuat.
Menariknya, dengan motivasi seperti itu, agen virtual belajar memainkan banyak game yang memiliki tujuan untuk menang. Misalnya, tetris.

Atau lingkungan dari Doom, di mana Anda perlu menghindari bola api terbang dan menembak lawan yang mendekat. Karena banyak tugas yang dapat dirumuskan sebagai tugas mempertahankan keteguhan. Bagi Tetris, ini adalah keinginan untuk menjaga ladang kosong. Apakah layar terus terisi? Oh sayang, apa yang akan terjadi ketika itu diisi sampai akhir? Tidak, tidak, kami tidak membutuhkan kebahagiaan seperti itu. Terlalu banyak kejutan.
Dari sisi teknis, ini diatur cukup sederhana. Ketika seorang agen menerima keadaan baru, ia mengevaluasi seberapa akrab keadaan ini. Artinya, seberapa banyak negara baru itu termasuk dalam distribusi negara yang ia kunjungi sebelumnya. Agen masuk ke keadaan yang lebih akrab, semakin besar hadiahnya. Dan tugas kebijakan pembelajaran (ini semua adalah istilah dari Penguatan Pembelajaran, jika ada yang tidak tahu) adalah memilih tindakan yang akan mengarah pada transisi ke keadaan yang paling akrab. Selain itu, setiap negara baru yang diperoleh digunakan untuk memperbarui statistik negara-negara yang akrab dengan yang negara baru dibandingkan.
Menariknya, dalam proses AI, saya secara spontan belajar untuk memahami bahwa keadaan baru memengaruhi apa yang dianggap baru. Dan Anda dapat mencapai kondisi yang dikenal dengan dua cara: pergi ke kondisi yang sudah dikenal. Atau masuk ke negara yang akan memperbarui konsep kegigihan / keakraban lingkungan, dan agen akan berada dalam keadaan baru, dibentuk oleh tindakannya, keadaan yang sudah dikenal.
Ini memaksa agen untuk mengambil tindakan terkoordinasi yang rumit, jika hanya tidak melakukan apa-apa dalam hidup.
Paradoksnya, ini mengarah ke analog rasa ingin tahu dari pembelajaran biasa, dan memaksa agen untuk menjelajahi dunia di sekitarnya. Tiba-tiba di suatu tempat ada tempat yang bahkan lebih aman daripada di sini dan sekarang? Di sana Anda benar-benar dapat menikmati kemalasan dan tidak melakukan apa pun, sehingga menghindari masalah dan sensasi baru. Tidak berlebihan untuk mengatakan bahwa pemikiran seperti itu mungkin terjadi pada kita semua. Dan bagi banyak orang, ini adalah kekuatan pendorong nyata dalam kehidupan. Meskipun dalam kehidupan nyata, tidak satu pun dari kita harus berurusan dengan tetris yang mengisi ke atas, tentu saja.
Sejujurnya, ini adalah kisah yang rumit. Tetapi latihan menunjukkan bahwa itu berhasil. Para peneliti membandingkan algoritma ini dengan perwakilan terbaik berdasarkan rasa ingin tahu: ICM dan RND . Yang pertama adalah mekanisme keingintahuan yang efektif yang sudah menjadi klasik dalam pembelajaran dengan penguatan. Agen tidak hanya berusaha untuk negara-negara baru yang asing dan karena itu menarik. Ketidaktahuan situasi dalam algoritme tersebut diperkirakan dengan apakah agen dapat memprediksinya (dalam yang sebelumnya ada secara harfiah penghitung negara yang dikunjungi, tapi sekarang semuanya telah sampai pada perkiraan integral yang disediakan oleh jaringan saraf). Tetapi dalam hal ini, dedaunan yang bergerak di pohon atau white noise di TV akan memiliki kebaruan yang tak ada habisnya untuk agen seperti itu, dan akan menyebabkan rasa penasaran yang tiada habisnya. Karena dia tidak pernah dapat memprediksi semua keadaan baru yang mungkin dalam lingkungan yang sepenuhnya acak.
Oleh karena itu, dalam ICM, agen hanya mencari negara-negara baru yang dapat memengaruhi tindakannya. Bisakah AI memengaruhi white noise di TV? Tidak. Sangat tidak menarik. Dan bisakah itu memengaruhi bola jika Anda memindahkannya? Ya Jadi bermain dengan bola itu menarik. Untuk melakukan ini, ICM menggunakan ide yang sangat keren dengan Inverse Model, dengan mana Forward Model dibandingkan. Lebih detail dalam karya aslinya .
RND adalah pengembangan baru dari mekanisme rasa ingin tahu. Yang dalam praktiknya telah melampaui ICM. Singkatnya, jaringan saraf berusaha untuk memprediksi output dari jaringan saraf lain, yang diprakarsai oleh bobot acak dan tidak pernah berubah. Diasumsikan bahwa semakin akrab situasi (diumpankan ke input dari kedua jaringan saraf, saat ini dan dimulai secara acak), semakin sering jaringan saraf saat ini akan dapat memprediksi keluaran yang diprakarsai secara acak. Saya tidak tahu siapa yang menciptakan semua ini. Di satu sisi, saya ingin berjabat tangan dengan orang seperti itu, dan di sisi lain, memberikan tendangan untuk distorsi semacam itu.
Tetapi dengan satu dan lain cara, dan pelatihan tentang gagasan mempertahankan homeostasis dan berusaha menghindari hal baru, dalam banyak kasus dalam praktiknya mencapai hasil yang lebih baik daripada kurikulum berdasarkan ICN atau RND. Apa yang tercermin dalam grafik.
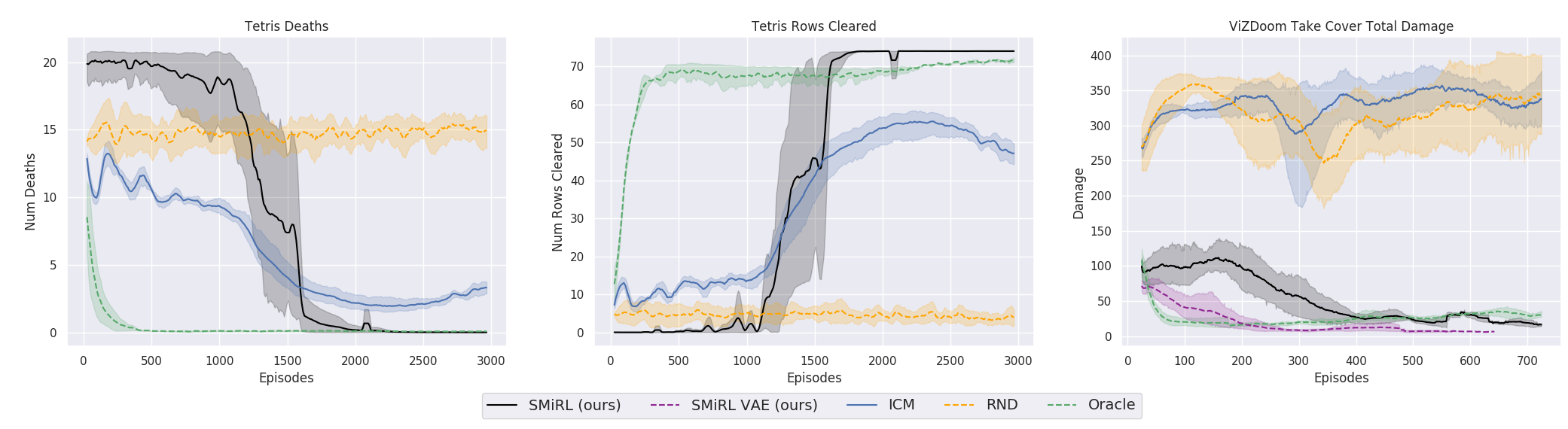
Tetapi di sini perlu diperjelas bahwa ini hanya untuk lingkungan yang digunakan para peneliti dalam pekerjaan mereka. Mereka berbahaya, acak, berisik, dan dengan meningkatnya entropi. Benar-benar bisa lebih menguntungkan untuk tidak melakukan apa pun di dalamnya. Dan hanya sesekali bergerak secara aktif ketika bola api terbang di Anda atau jembatan di belakang Anda mulai runtuh. Namun, para peneliti dari Berkeley bersikeras, tampaknya dari pengalaman hidup mereka yang sulit, bahwa lingkungan seperti itu jauh lebih dekat dengan kehidupan nyata yang kompleks daripada yang sebelumnya digunakan dalam pelatihan penguatan. Yah, saya tidak tahu, saya tidak tahu. Dalam hidup saya, bola api dari monster yang terbang ke saya dan labirin tidak berpenghuni dengan keluar tunggal ditemukan dengan frekuensi yang kira-kira sama. Tetapi tidak dapat disangkal bahwa pendekatan yang diusulkan, dengan segala kesederhanaannya, menunjukkan hasil yang luar biasa. Ada kemungkinan bahwa di masa depan kedua pendekatan harus dikombinasikan secara wajar - homeostasis dengan pelestarian keteguhan positif dalam jangka panjang dan rasa ingin tahu untuk studi lingkungan saat ini.
Tautan ke karya asli