Sudah lama menjadi ide untuk melihat apa yang dapat Anda lakukan dengan ELK dan sumber-sumber log dan statistik yang diimprovisasi. Pada halaman Habr, saya berencana untuk menunjukkan contoh praktis tentang bagaimana, menggunakan mini-server rumah, Anda dapat membuat, misalnya, honeypot dengan sistem analisis log berdasarkan pada tumpukan ELK. Pada artikel ini saya akan memberi tahu Anda tentang contoh paling sederhana menganalisis log firewall menggunakan tumpukan ELK. Di masa depan saya ingin menggambarkan pengaturan lingkungan untuk menganalisis lalu lintas Netflow dan dump pcap oleh Zeek.
Jika Anda memiliki alamat IP publik dan perangkat yang kurang lebih pintar sebagai gateway / firewall, Anda dapat mengatur honeypot pasif dengan mengatur permintaan masuk untuk port TCP dan UDP yang "lezat". Ada contoh mengkonfigurasi router Mikrotik di bawah kucing, tetapi jika Anda memiliki router vendor yang berbeda (atau sistem keamanan lainnya), Anda hanya perlu mencari tahu sedikit format data dan pengaturan khusus vendor, dan Anda akan mendapatkan hasil yang sama.
Penafian
Artikel ini tidak berpura-pura menjadi asli, artikel ini tidak membahas masalah toleransi kesalahan layanan, keamanan, praktik terbaik, dll. Penting untuk mempertimbangkan materi ini sebagai materi akademik, sangat cocok untuk berkenalan dengan fungsionalitas dasar tumpukan ELK dan mekanisme analisis log dari perangkat jaringan. Namun, itu mungkin menarik untuk pemula juga.
Proyek ini diluncurkan dari file docker-compose, dan sangat mudah untuk menggunakan lingkungan Anda yang serupa, bahkan jika Anda memiliki router vendor yang berbeda, Anda hanya perlu memahami sedikit tentang format data dan pengaturan khusus vendor. Untuk selebihnya, saya mencoba menjelaskan sebanyak mungkin semua nuansa yang terkait dengan mengkonfigurasi pipa Logstash dan pemetaan Elasticsearch dalam versi ELK saat ini. Semua komponen sistem ini di-host di
github , termasuk konfigurasi layanan. Pada akhir artikel, saya akan melakukan bagian Pemecahan Masalah, yang akan menjelaskan langkah-langkah untuk mendiagnosis masalah populer pendatang baru di bisnis ini.
Pendahuluan
Di server itu sendiri, saya telah menginstal sistem virtualisasi Proxmox, di dalamnya di wadah Docker mesin KVM diluncurkan. Diasumsikan bahwa Anda tahu cara kerja buruh pelabuhan dan buruh pelabuhan, karena ada cukup contoh konfigurasi tentang penggunaan Internet. Saya tidak akan menyentuh masalah menginstal Docker, saya akan menulis sedikit tentang docker-compose.
Gagasan untuk meluncurkan honeypot muncul dalam proses mempelajari Elasticsearch, Logstash dan Kibana. Dalam karir profesional saya, saya tidak pernah terlibat dalam administrasi dan umumnya menggunakan tumpukan ini, tetapi saya memiliki proyek hobi, berkat itu saya telah mengembangkan minat besar dalam mengeksplorasi kemungkinan yang ditawarkan oleh mesin pencari Elasticsearch dan Kibana, yang dengannya Anda dapat menganalisis dan memvisualisasikan data.
Saya bukan server NUC mini terbaru dengan RAM 8GB hanya cukup untuk memulai tumpukan ELK dengan satu simpul elastis. Dalam lingkungan produksi, ini, tentu saja, tidak direkomendasikan, tetapi tepat untuk pelatihan. Mengenai masalah keamanan, ada komentar di akhir artikel.
Internet penuh dengan instruksi untuk menginstal dan mengkonfigurasi tumpukan ELK untuk tugas-tugas serupa (misalnya,
menganalisis serangan brute force pada ssh menggunakan Logstash versi 2 ,
menganalisis log Suricata menggunakan Filebeat versi 6 ), tetapi dalam kebanyakan kasus, karena perhatian tidak dibayarkan ke rincian, untuk itu 90 persen dari materi akan untuk versi 1 hingga 6 (pada saat penulisan, versi ELK saat ini adalah 7.5.0). Ini penting, karena dari versi 6 Elasticsearch
memutuskan untuk menghapus entitas tipe pemetaan, sehingga mengubah sintaks kueri dan struktur peta. Memetakan template di Elastic umumnya merupakan objek yang sangat penting, dan agar nantinya tidak ada masalah dengan pengambilan sampel data dan visualisasi, saya menyarankan Anda untuk tidak terlibat dalam copy-paste dan mencoba memahami apa yang Anda lakukan. Selanjutnya saya akan mencoba menjelaskan dengan jelas apa arti operasi dan konfigurasi yang dijelaskan.
Pengaturan router
Untuk jaringan rumah, saya menggunakan Mikrotik sebagai router, jadi contohnya adalah untuknya. Tetapi hampir semua sistem dapat dikonfigurasi untuk mengirim syslog ke server jauh, baik itu router, server, atau sistem keamanan lain yang dapat login.
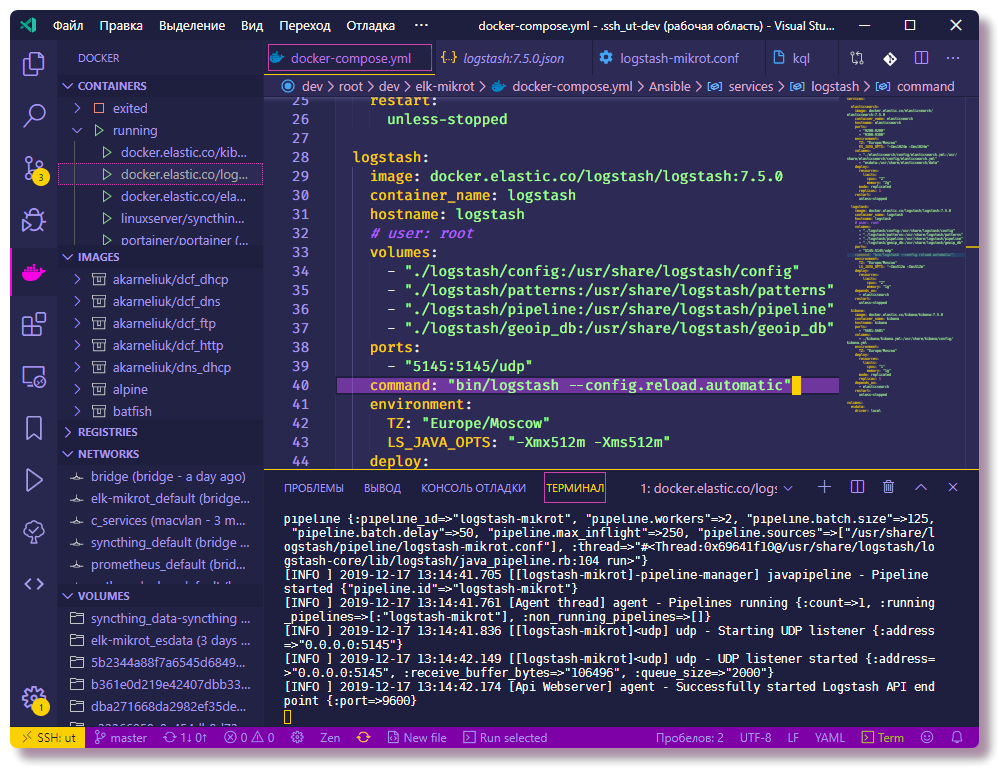
Mengirim pesan syslog ke server jauh
Di Mikrotik, untuk mengkonfigurasi logging ke server jauh melalui CLI, cukup masukkan beberapa perintah:
/system logging action add remote=192.168.88.130 remote-port=5145 src-address=192.168.88.1 name=logstash target=remote /system logging add action=logstash topics=info
Mengkonfigurasi aturan firewall dengan logging
Kami hanya tertarik pada data tertentu (nama host, alamat ip, nama pengguna, url dll.), Dari mana Anda bisa mendapatkan visualisasi atau seleksi yang indah. Dalam kasus paling sederhana, untuk mendapatkan informasi tentang pemindaian port dan upaya akses, Anda perlu mengkonfigurasi komponen firewall untuk mencatat pemicu aturan. Di Mikrotik, saya membuat aturan di tabel NAT, bukan Filter, karena di masa depan saya akan menempatkan chanipots yang akan meniru pekerjaan layanan, ini akan memungkinkan saya untuk menyelidiki lebih banyak informasi tentang perilaku botnet, tetapi ini adalah skenario yang lebih maju dan bukan tentang saat ini.
Perhatian! Dalam konfigurasi di bawah ini, port TCP standar dari layanan SSH (22) dilingkarkan ke jaringan lokal. Jika Anda menggunakan SSH untuk mengakses router dari luar dan pengaturan memiliki port 22 (
layanan ip cetak di CLI dan
layanan ip> di Winbox), Anda harus menugaskan kembali port untuk manajemen SSH, atau jangan masukkan aturan terakhir dalam tabel.
Juga, tergantung pada nama antarmuka WAN (jika jembatan WAN tidak digunakan), Anda perlu mengubah parameter
dalam-antarmuka ke yang sesuai.
/ip firewall nat add action=netmap chain=dstnat comment="HONEYPOT RDP" dst-port=3389 in-interface=bridge-wan log=yes log-prefix=honeypot_rdp protocol=tcp to-addresses=192.168.88.201 to-ports=3389 add action=netmap chain=dstnat comment="HONEYPOT ELASTIC" dst-port=9200 in-interface=bridge-wan log=yes log-prefix=honeypot_elastic protocol=tcp to-addresses=192.168.88.201 to-ports=9211 add action=netmap chain=dstnat comment=" HONEYPOT TELNET" dst-port=23 in-interface=bridge-wan log=yes log-prefix=honeypot_telnet protocol=tcp to-addresses=192.168.88.201 to-ports=2325 add action=netmap chain=dstnat comment="HONEYPOT DNS" dst-port=53 in-interface=bridge-wan log=yes log-prefix=honeypot_dns protocol=udp to-addresses=192.168.88.201 to-ports=9953 add action=netmap chain=dstnat comment="HONEYPOT FTP" dst-port=21 in-interface=bridge-wan log=yes log-prefix=honeypot_ftp protocol=tcp to-addresses=192.168.88.201 to-ports=9921 add action=netmap chain=dstnat comment="HONEYPOT SMTP" dst-port=25 in-interface=bridge-wan log=yes log-prefix=honeypot_smtp protocol=tcp to-addresses=192.168.88.201 to-ports=9925 add action=netmap chain=dstnat comment="HONEYPOT SMB" dst-port=445 in-interface=bridge-wan log=yes log-prefix=honeypot_smb protocol=tcp to-addresses=192.168.88.201 to-ports=9445 add action=netmap chain=dstnat comment="HONEYPOT MQTT" dst-port=1883 in-interface=bridge-wan log=yes log-prefix=honeypot_mqtt protocol=tcp to-addresses=192.168.88.201 to-ports=9883 add action=netmap chain=dstnat comment="HONEYPOT SIP" dst-port=5060 in-interface=bridge-wan log=yes log-prefix=honeypot_sip protocol=tcp to-addresses=192.168.88.201 to-ports=9060 add action=dst-nat chain=dstnat comment="HONEYPOT SSH" dst-port=22 in-interface=bridge-wan log=yes log-prefix=honeypot_ssh protocol=tcp to-addresses=192.168.88.201 to-ports=9922
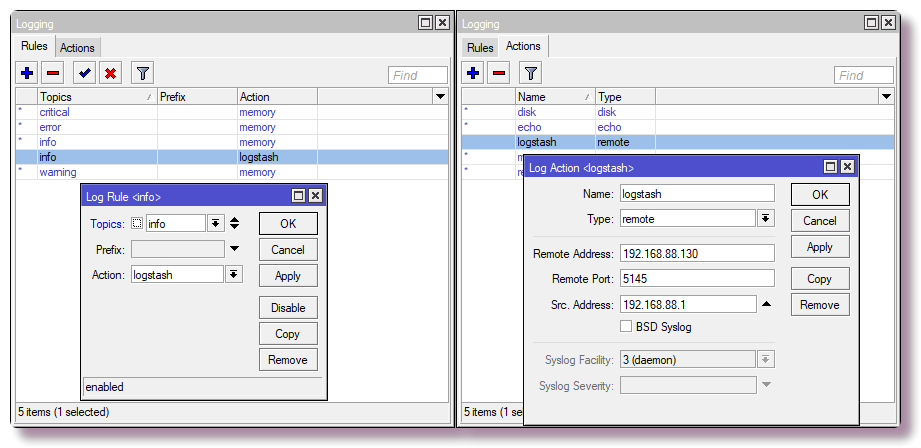
Di Winbox, hal yang sama dikonfigurasi di
tab IP> Firewall> NAT .
Sekarang router akan mengarahkan paket yang diterima ke alamat lokal 192.168.88.201 dan port khusus. Saat ini tidak ada yang mendengarkan port ini, sehingga koneksi akan terputus. Di masa depan, di buruh pelabuhan, Anda dapat menjalankan honeypot, yang ada banyak untuk setiap layanan. Jika ini tidak direncanakan, maka alih-alih aturan NAT, Anda harus menulis aturan dengan tindakan drop di rantai Filter.
Mulai ELK dengan komposisi buruh pelabuhan
Selanjutnya, Anda dapat mulai mengonfigurasi komponen yang akan memproses log. Saya menyarankan Anda untuk segera berlatih dan mengkloning repositori untuk melihat file konfigurasi sepenuhnya. Semua konfigurasi yang dijelaskan dapat dilihat di sana, dalam teks artikel saya hanya akan menyalin sebagian dari konfigurasi.
❯❯ git clone https://github.com/mekhanme/elk-mikrot.git
Dalam lingkungan pengujian atau pengembangan, paling mudah menjalankan wadah buruh pelabuhan menggunakan komposisi buruh pelabuhan. Dalam proyek ini, saya menggunakan file pembuatan docker dari
versi terbaru
3.7 saat ini, itu membutuhkan mesin docker versi 18.06.0+, jadi ada baiknya memperbarui
docker , serta
menulis docker .
❯❯ curl -L "https://github.com/docker/compose/releases/download/1.25.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose ❯❯ chmod +x /usr/local/bin/docker-compose
Karena dalam versi terbaru dari docker-compose, parameter mem_limit telah
terpotong dan
deploy ditambahkan, yang hanya berjalan dalam mode swarm (
docker stack deploy ), meluncurkan konfigurasi
docker-compose up dengan batas yang menyebabkan kesalahan. Karena saya tidak menggunakan segerombolan, dan saya ingin memiliki batas sumber daya, saya harus memulainya dengan opsi
--compatibility , yang mengubah batas dari buruh pelabuhan-membuat versi baru ke setara non-las.
Uji coba semua wadah (di latar belakang -d):
❯❯ docker-compose --compatibility up -d
Anda harus menunggu sampai semua gambar diunduh, dan setelah peluncuran selesai, Anda dapat memeriksa status wadah dengan perintah:
❯❯ docker-compose --compatibility ps
Karena kenyataan bahwa semua kontainer akan berada di jaringan yang sama (jika Anda tidak secara eksplisit menentukan jaringan, sebuah jembatan baru dibuat, yang sesuai dalam skenario ini) dan docker-compose.yml berisi parameter container_name untuk semua
kontainer , kontainer tersebut sudah memiliki konektivitas melalui DNS bawaan buruh pelabuhan Akibatnya, tidak perlu mendaftarkan alamat IP dalam konfigurasi wadah. Dalam konfigurasi Logstash, subnet 192.168.88.0/24 terdaftar sebagai lokal, selanjutnya dalam konfigurasi akan ada penjelasan yang lebih rinci, yang dengannya Anda dapat membelokkan contoh konfigurasi sebelum memulai.
Konfigurasikan Layanan ELK
Selanjutnya akan ada penjelasan tentang cara mengkonfigurasi fungsionalitas komponen ELK, serta beberapa tindakan lain yang perlu dilakukan pada Elasticsearch.
Untuk menentukan koordinat geografis berdasarkan alamat IP, Anda harus mengunduh database
GeoLite2 gratis dari MaxMind:
❯❯ cd elk-mikrot && mkdir logstash/geoip_db ❯❯ curl -O https://geolite.maxmind.com/download/geoip/database/GeoLite2-City-CSV.zip && unzip GeoLite2-City-CSV.zip -d logstash/geoip_db && rm -f GeoLite2-City-CSV.zip ❯❯ curl -O https://geolite.maxmind.com/download/geoip/database/GeoLite2-ASN-CSV.zip && unzip GeoLite2-ASN-CSV.zip -d logstash/geoip_db && rm -f GeoLite2-ASN-CSV.zip
Pengaturan logstash
File konfigurasi utama adalah
logstash.yml , di mana saya mendaftarkan opsi untuk memuat ulang konfigurasi secara otomatis, pengaturan lainnya untuk lingkungan pengujian tidak signifikan. Konfigurasi pemrosesan data (log) di Logstash dijelaskan dalam file
conf yang terpisah, biasanya disimpan dalam direktori
pipa . Dalam skema, ketika
beberapa saluran pipa digunakan, file
pipelines.yml menjelaskan
saluran pipa yang diaktifkan. Pipeline adalah rangkaian tindakan pada data yang tidak terstruktur untuk menerima data dengan struktur spesifik pada output. Skema dengan
pipelines.yml yang dikonfigurasi secara terpisah adalah opsional, Anda dapat melakukannya tanpa mengunduh semua konfigurasi dari direktori
pipa yang terpasang, namun, dengan file
pipelines.yml yang spesifik, konfigurasinya lebih fleksibel, karena Anda dapat menghidupkan dan mematikan file
conf dari direktori
pipa. konfigurasi yang diperlukan. Selain itu, memuat ulang konfigurasi hanya berfungsi dalam skema beberapa saluran pipa.
❯❯ cat logstash/config/pipelines.yml - pipeline.id: logstash-mikrot path.config: "pipeline/logstash-mikrot.conf"
Berikutnya adalah bagian terpenting dari konfigurasi Logstash. Deskripsi pipa terdiri dari beberapa bagian - di awal, plugin ditunjukkan di bagian
Input dengan bantuan Logstash menerima data. Cara termudah untuk mengumpulkan syslog dari perangkat jaringan adalah dengan menggunakan plugin input
tcp /
udp . Satu-satunya parameter yang diperlukan untuk plugin ini adalah
port , itu harus ditentukan sama seperti pada pengaturan router.
Bagian kedua adalah
Filter , yang mengatur tindakan lebih lanjut dengan data yang belum terstruktur. Dalam contoh saya, pesan syslog yang tidak perlu dari router dengan teks tertentu dihapus. Ini dilakukan dengan menggunakan kondisi dan tindakan
penurunan standar, yang membuang seluruh pesan jika kondisi terpenuhi. Dalam
kondisi tersebut , bidang
pesan diperiksa untuk keberadaan teks tertentu.
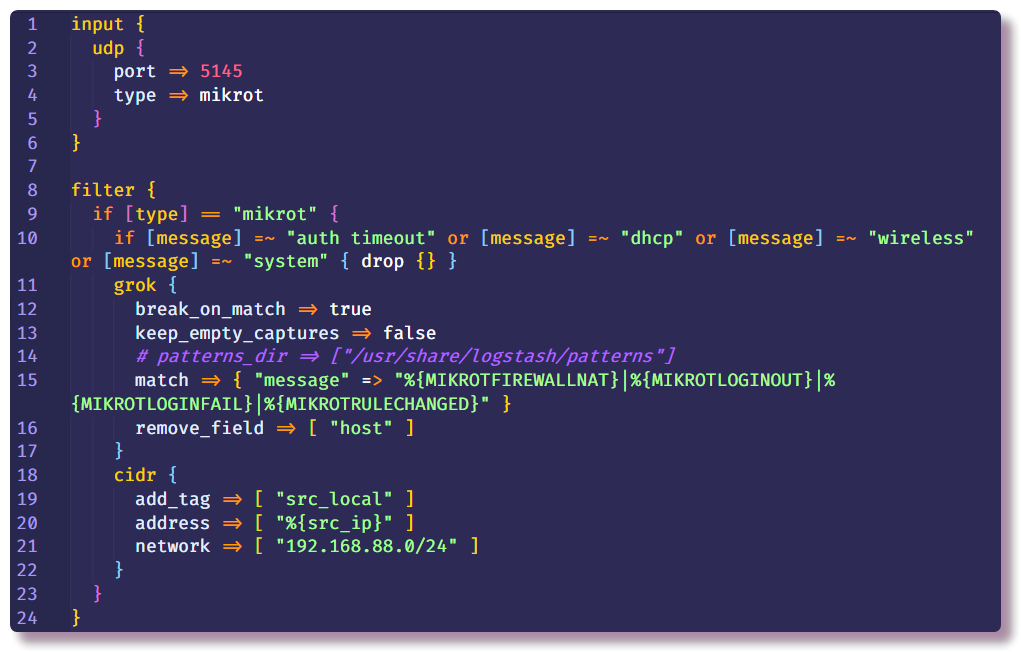
Jika pesan tidak jatuh, ia masuk lebih jauh ke rantai dan memasuki filter
grok . Seperti yang dikatakan dalam dokumentasi,
grok adalah cara yang bagus untuk mengurai data log yang tidak terstruktur menjadi sesuatu yang terstruktur dan dapat ditanyakan . Filter ini digunakan untuk memproses log dari berbagai sistem (linux syslog, server web, database, perangkat jaringan, dll.). Berdasarkan
pola yang sudah jadi, Anda dapat, tanpa menghabiskan banyak waktu, membuat parser untuk urutan berulang lebih atau kurang. Lebih mudah menggunakan
parser online untuk validasi (dalam versi terbaru Kibana, fungsi serupa ada di bagian
Dev Tools ).
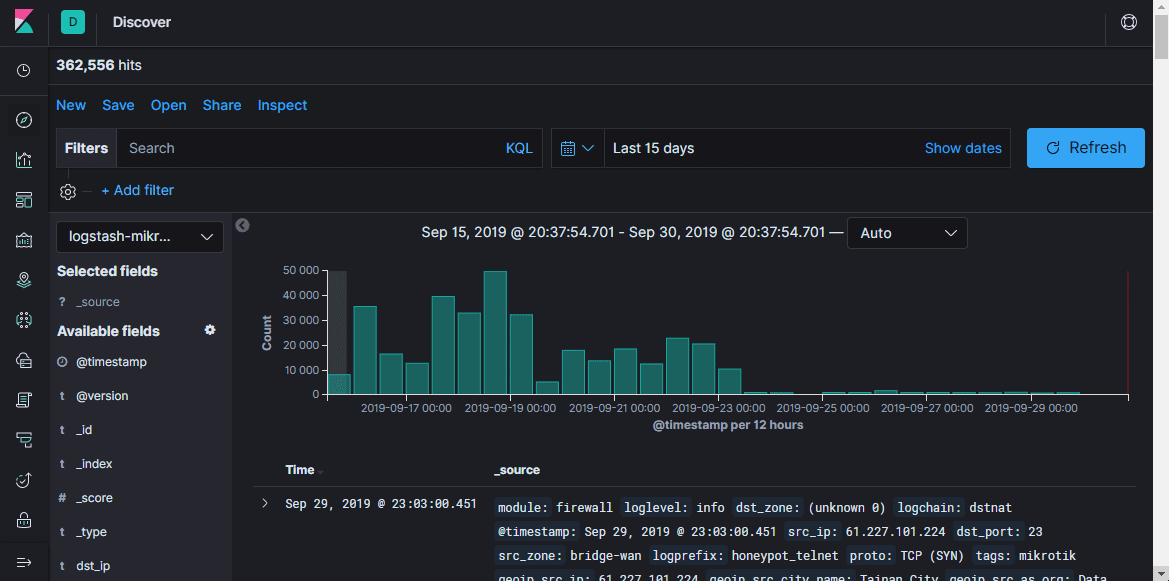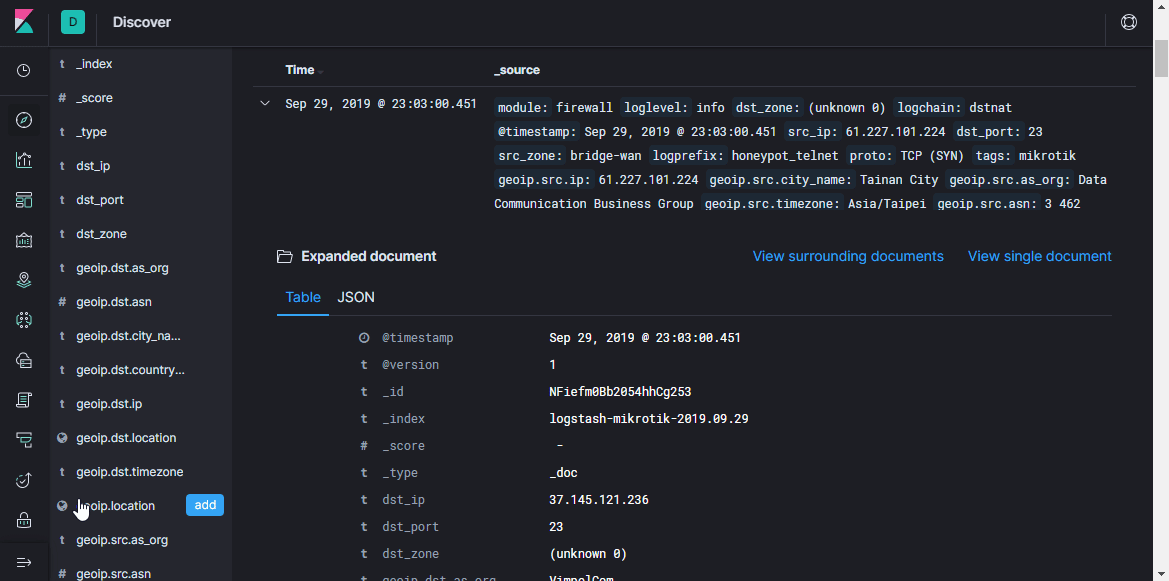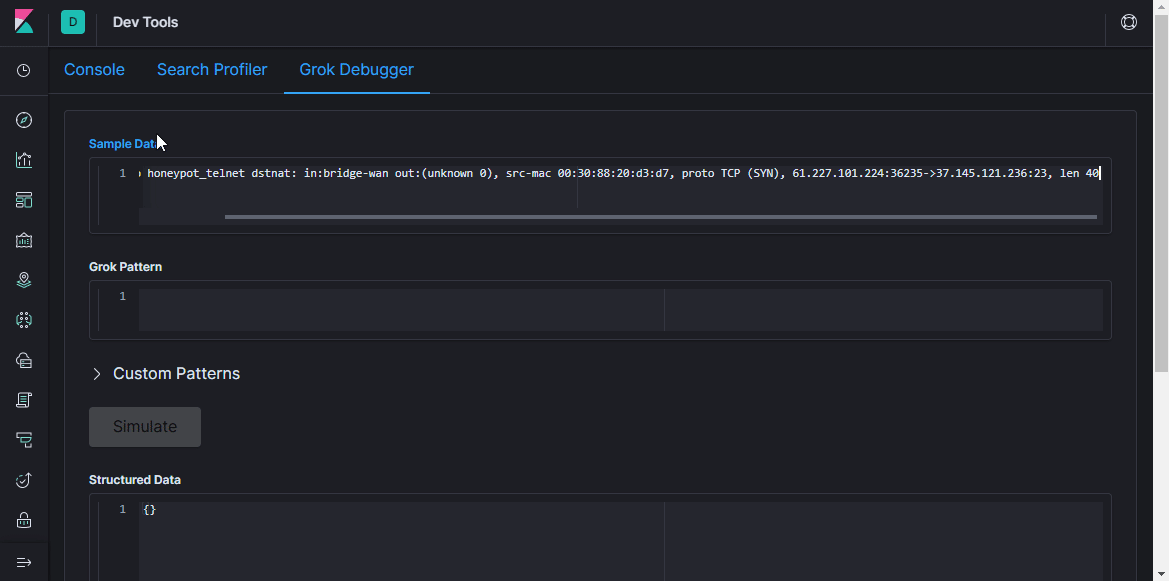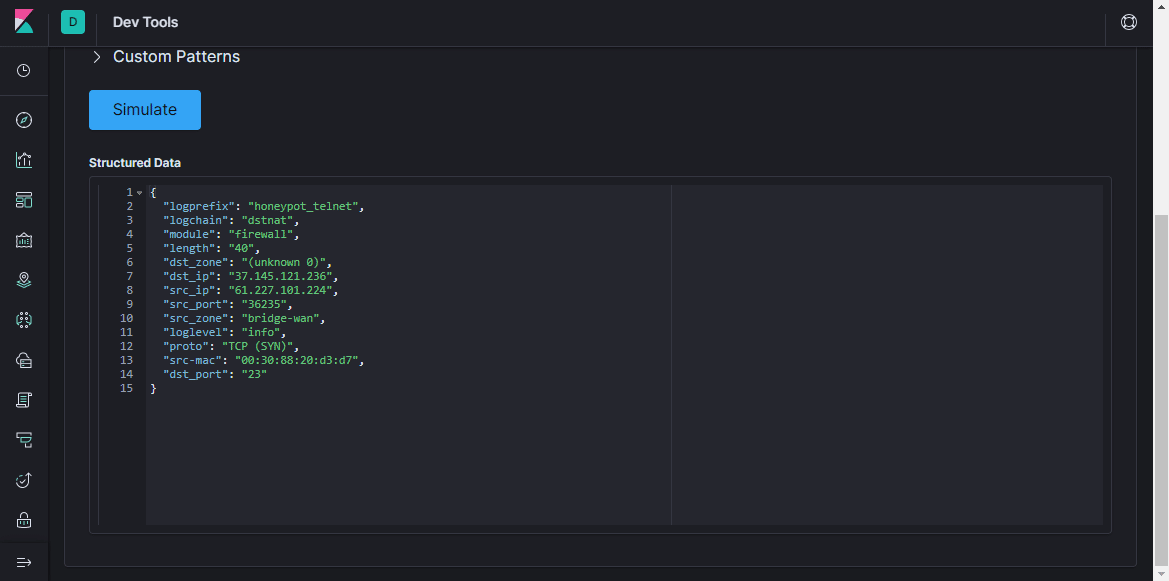
Volume
"./logstash/patterns:/usr/share/logstash/patterns" terdaftar di
docker-compose.yml , dalam direktori
pola ada file dengan pola komunitas standar (hanya untuk kenyamanan, lihat apakah saya lupa), serta file dengan pola beberapa jenis pesan Mikrotik (modul
Firewall dan
Auth) , dengan analogi, Anda dapat menambahkan templat Anda sendiri untuk pesan dari struktur yang berbeda.
Opsi standar
add_field dan
remove_field memungkinkan Anda untuk menambah atau menghapus bidang dari pesan yang sedang diproses di dalam filter apa pun. Dalam hal ini, bidang
host dihapus, yang berisi nama host dari mana pesan diterima. Dalam contoh saya, hanya ada satu host, jadi tidak ada gunanya di bidang ini.
Selanjutnya, di bagian
Filter yang sama, saya mendaftarkan filter
cidr , yang memeriksa bidang dengan alamat IP untuk kepatuhan dengan kondisi entri di subnet yang diberikan dan meletakkan tag. Berdasarkan tag pada rantai selanjutnya, tindakan akan dilakukan atau tidak dilakukan (jika secara khusus, ini dilakukan agar tidak melakukan pencarian geoip untuk alamat lokal di masa mendatang).
Mungkin ada sejumlah bagian
Filter , sehingga ada lebih sedikit kondisi dalam satu bagian, di bagian baru saya mendefinisikan tindakan untuk pesan tanpa tag
src_local , yaitu, peristiwa firewall diproses di sini di mana kami tertarik pada alamat sumber.
Sekarang kita perlu berbicara lebih banyak tentang dari mana Logstash mendapatkan informasi GeoIP. Logstash mendukung database GeoLite2. Ada beberapa opsi basis data, saya menggunakan dua basis data: GeoLite2 City (yang berisi informasi tentang negara, kota, zona waktu) dan GeoLite2 ASN (informasi tentang sistem otonom tempat alamat IP berada).

Plugin
geoip juga terlibat dalam menambahkan informasi GeoIP ke pesan. Dari parameter, Anda harus menentukan bidang yang berisi alamat IP, basis yang digunakan, dan nama bidang baru di mana informasi akan ditulis. Dalam contoh saya, hal yang sama dilakukan untuk alamat IP tujuan, tetapi sejauh ini dalam skenario sederhana ini informasi ini tidak akan menarik, karena alamat tujuan akan selalu menjadi alamat router. Namun, di masa mendatang akan dimungkinkan untuk menambahkan log ke pipa ini tidak hanya dari firewall, tetapi juga dari sistem lain di mana akan relevan untuk melihat kedua alamat.
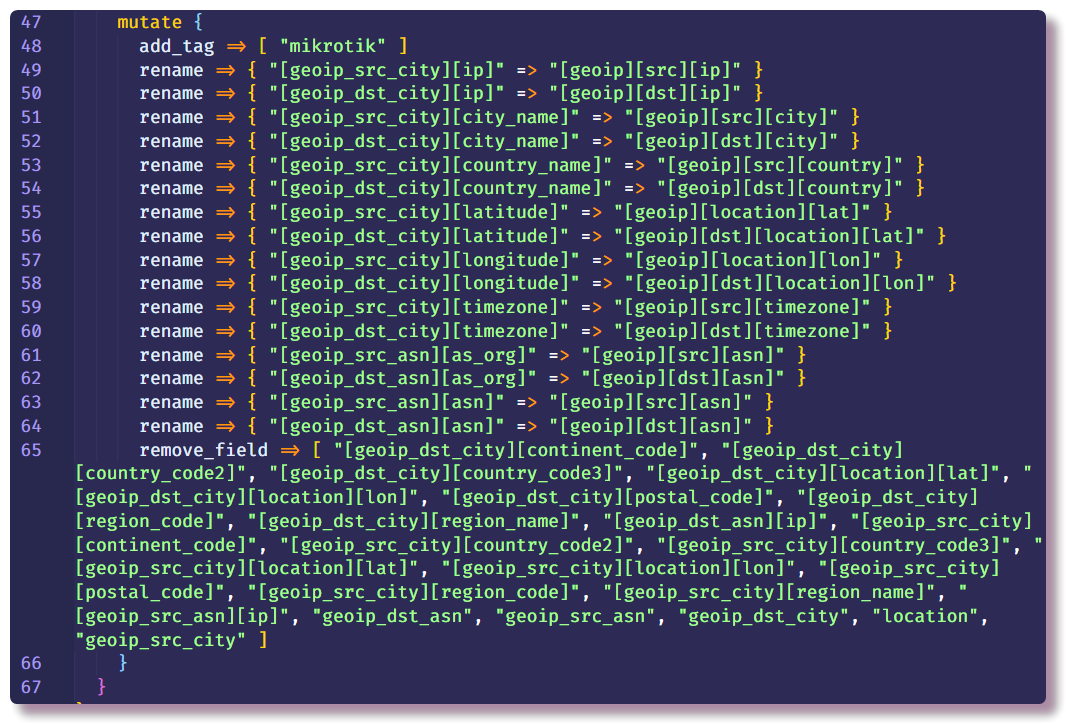
Filter
mutasi memungkinkan Anda untuk mengubah bidang pesan dan memodifikasi teks dalam bidang itu sendiri, dokumentasi menjelaskan secara rinci banyak contoh tentang apa yang dapat Anda lakukan. Dalam hal ini, digunakan untuk menambahkan tag, mengganti nama bidang (untuk visualisasi log lebih lanjut di Kibana, diperlukan format tertentu dari objek
geo-point , saya akan menyentuh topik ini lebih lanjut) dan menghapus bidang yang tidak perlu.
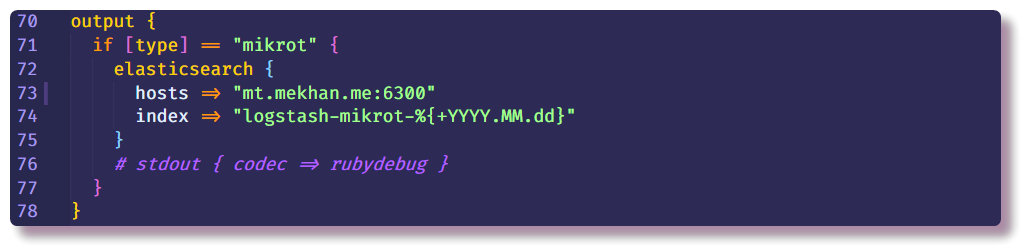
Ini mengakhiri bagian pemrosesan data dan hanya dapat menunjukkan tempat untuk mengirim pesan terstruktur. Dalam hal ini, Elasticsearch akan mengumpulkan data, Anda hanya perlu memasukkan alamat IP, port dan nama indeks. Anda disarankan untuk memasukkan indeks dengan bidang tanggal variabel sehingga indeks baru dibuat setiap hari.
Menyiapkan Pencarian Elastics
Kembali ke Elasticsearch. Pertama, Anda perlu memastikan bahwa server sudah aktif dan berjalan. Elastis paling efisien berinteraksi dengan melalui API Istirahat di CLI. Dengan menggunakan curl, Anda dapat melihat status node (ganti localhost dengan host ip docker):
❯❯ curl localhost:9200
Maka Anda dapat mencoba membuka Kibana di
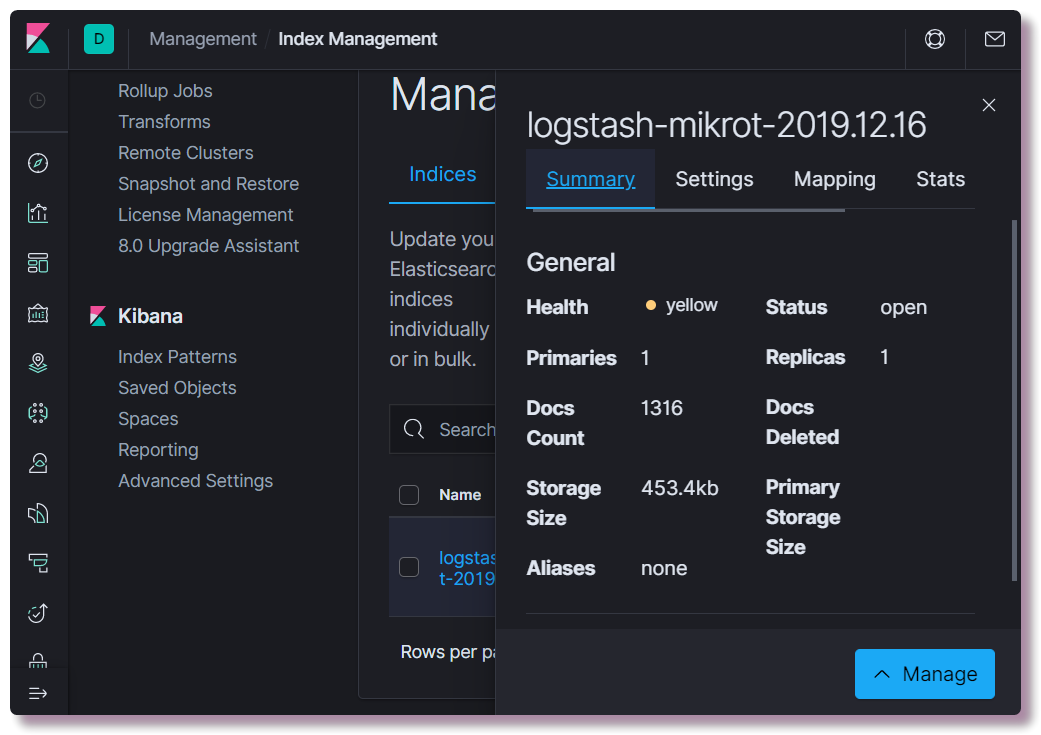
localhost : 5601. Tidak perlu mengkonfigurasi apa pun di antarmuka web Kibana (kecuali mengubah tema menjadi gelap). Kami tertarik untuk melihat apakah suatu indeks telah dibuat. Untuk melakukan ini, buka bagian
Manajemen dan pilih
Manajemen Indeks Pencarian Elastik di kiri atas. Di sini Anda dapat melihat berapa banyak dokumen yang diindeks, berapa banyak menghabiskan ruang disk, Anda juga dapat melihat informasi tentang pemetaan indeks dari informasi yang berguna.
Saat itu Anda perlu mendaftarkan templat pemetaan yang benar. Informasi ini diperlukan untuk Elastis sehingga ia memahami tipe data mana yang termasuk bidang. Misalnya, untuk membuat pilihan khusus berdasarkan alamat IP, untuk bidang
src_ip ,
Anda harus secara eksplisit menentukan tipe data
ip , dan untuk menentukan lokasi geografis, Anda perlu menentukan bidang
geoip.location dalam format tertentu dan mendaftarkan jenis
geo_point . Semua bidang yang mungkin tidak perlu dijelaskan, karena untuk bidang baru, tipe data ditentukan secara otomatis berdasarkan pola dinamis (
panjang untuk angka dan
kata kunci untuk string).
Anda dapat menulis templat baru menggunakan curl, atau langsung dari konsol Kibana (bagian
Dev Tools ).
❯❯ curl -X POST -H "Content-Type: application/json" -d @elasticsearch/logstash_mikrot-template.json http://192.168.88.130:9200/_template/logstash-mikrot
Setelah mengubah pemetaan, Anda perlu menghapus indeks:
❯❯ curl -X DELETE http://192.168.88.130:9200/logstash-mikrot-2019.12.16
Ketika setidaknya satu pesan masuk dalam indeks, periksa pemetaan:
❯❯ curl http://192.168.88.130:9200/logstash-mikrot-2019.12.16/_mapping
Untuk penggunaan lebih lanjut data di Kibana, Anda perlu membuat
pola dalam
Manajemen> Pola Indeks Kibana . Masukkan
nama indeks dengan simbol * (
logstash-mikrot *) sehingga semua indeks cocok, pilih bidang
cap waktu sebagai bidang dengan tanggal dan waktu. Di bidang
ID pola indeks kustom , Anda dapat memasukkan ID pola (misalnya,
logstash-mikrot ), di masa depan ini dapat menyederhanakan mengakses objek.
Analisis dan Visualisasi Data di Kibana
Setelah membuat
pola indeks , Anda dapat melanjutkan ke bagian yang paling menarik - analisis dan visualisasi data. Kibana memiliki banyak fungsi dan bagian, tetapi sejauh ini kita hanya akan tertarik pada dua.
Temukan
Di sini Anda dapat melihat dokumen dalam indeks, memfilter, mencari, dan melihat informasi yang diterima. Penting untuk tidak melupakan timeline, yang menetapkan kerangka waktu dalam kondisi pencarian.
Visualisasikan
Di bagian ini, Anda dapat membangun visualisasi berdasarkan data yang dikumpulkan. Yang paling sederhana adalah menampilkan sumber pemindaian botnet pada peta geografis, baik bertitik atau dalam bentuk peta panas. Ada juga banyak cara untuk membuat grafik, membuat pilihan, dll.
Di masa depan saya berencana untuk menceritakan secara lebih rinci tentang pemrosesan data, mungkin visualisasi, mungkin sesuatu yang menarik. Dalam proses belajar saya akan mencoba menambah tutorial.
Pemecahan masalah
Jika indeks tidak muncul di Elasticsearch, Anda harus terlebih dahulu melihat Logstash log:
❯❯ docker logs logstash --tail 100 -f
Logstash tidak akan berfungsi jika tidak ada konektivitas dengan Elasticsearch, atau kesalahan dalam konfigurasi pipa adalah alasan utama dan menjadi jelas setelah studi yang cermat terhadap log yang ditulis ke json docker secara default.
Jika tidak ada kesalahan dalam log, Anda perlu memastikan bahwa Logstash menangkap pesan pada soket yang dikonfigurasi. Untuk tujuan debug, Anda dapat menggunakan
stdout sebagai
output :
stdout { codec => rubydebug }
Setelah itu, Logstash akan menulis informasi debag ketika pesan diterima langsung ke log.
Memeriksa Elasticsearch sangat sederhana - cukup buat ikal permintaan GET pada alamat IP dan port server, atau pada titik akhir API tertentu. Misalnya, lihat status indeks dalam tabel yang dapat dibaca manusia:
❯❯ curl -s 'http://192.168.88.130:9200/_cat/indices?v'
Kibana juga tidak akan memulai jika tidak ada koneksi ke Elasticsearch, mudah untuk melihatnya melalui log.
Jika antarmuka web tidak terbuka, maka Anda harus memastikan bahwa firewall dikonfigurasi dengan benar atau dinonaktifkan di Linux (di Centos ada masalah dengan
iptables dan
buruh pelabuhan , mereka dipecahkan berdasarkan saran dari
topik ). Perlu juga dipertimbangkan bahwa pada peralatan yang tidak terlalu produktif, semua komponen dapat dimuat selama beberapa menit. Dengan kekurangan memori, layanan mungkin tidak memuat sama sekali. Lihat penggunaan sumber daya wadah:
❯❯ docker stats
Jika tiba-tiba seseorang tidak tahu cara mengubah konfigurasi kontainer dengan benar dalam file
docker-compose.yml dan memulai kembali kontainer, ini dilakukan dengan mengedit
docker-compose.yml dan menggunakan perintah yang sama dengan parameter yang sama, restart:
❯❯ docker-compose --compatibility up -d
Pada saat yang sama, di bagian yang diubah, objek lama (wadah, jaringan, volume) dihapus dan yang baru diciptakan kembali sesuai dengan konfigurasi. Data layanan tidak hilang pada saat yang sama, karena
volume bernama digunakan , yang tidak dihapus dengan wadah, dan konfigurasi dipasang dari sistem host, Logstash bahkan dapat memantau file konfigurasi dan memulai kembali konfigurasi pipa ketika file diubah.
Anda dapat memulai kembali layanan secara terpisah dengan
perintah restart buruh pelabuhan (tidak perlu berada di direktori dengan
buruh pelabuhan-compose.yml) :
❯❯ docker restart logstash
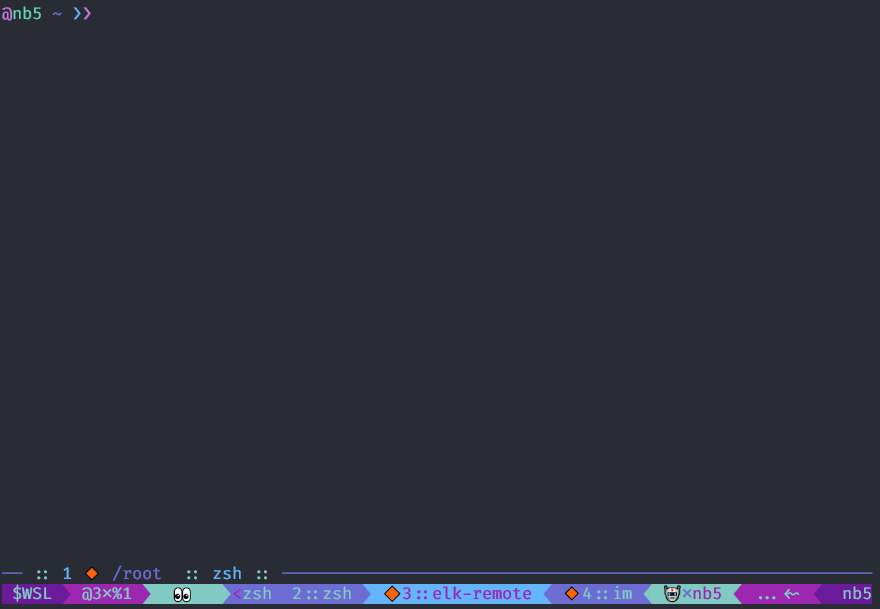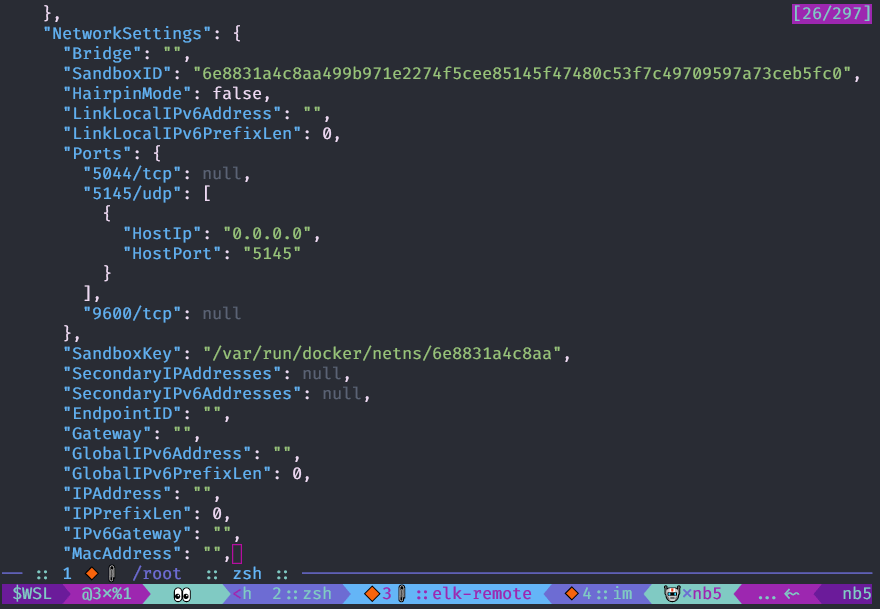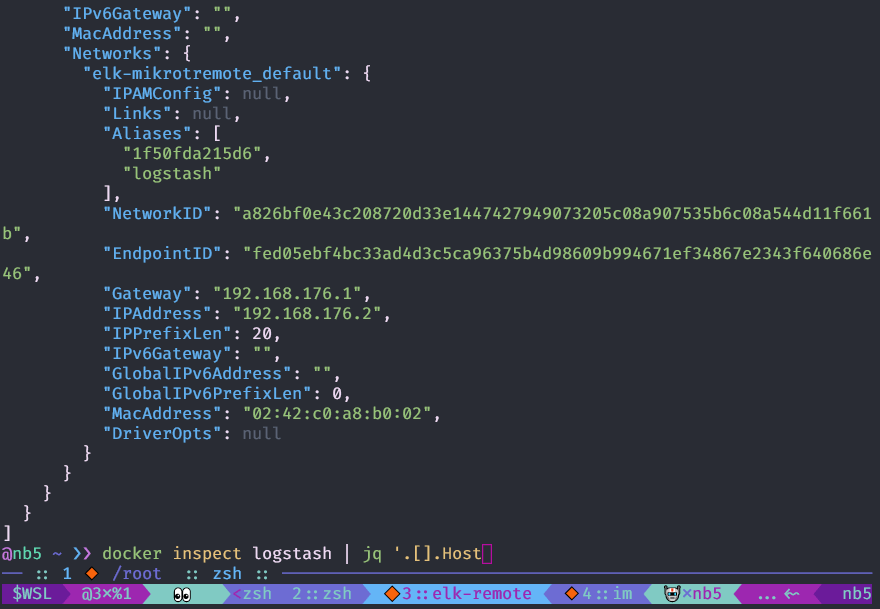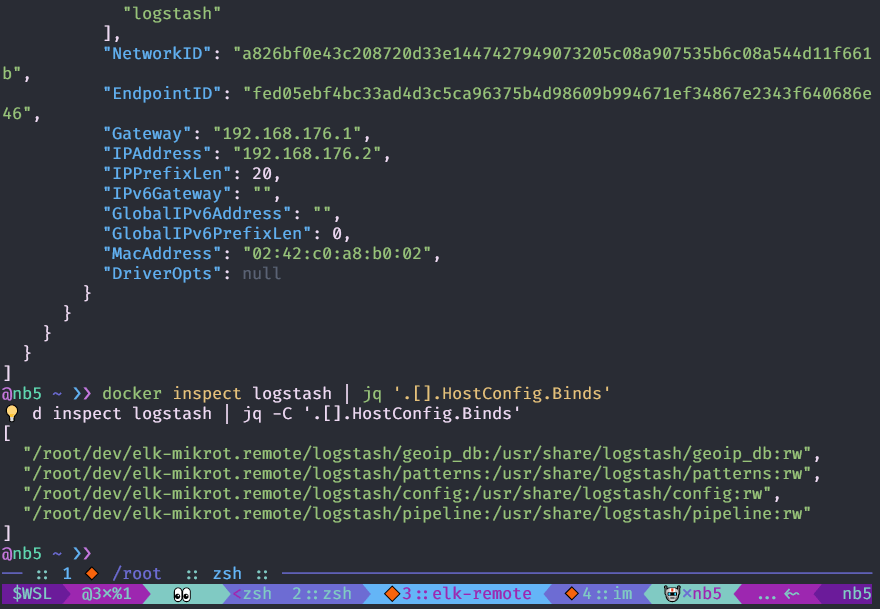
Anda dapat melihat konfigurasi objek
buruh pelabuhan dengan perintah
buruh pelabuhan memeriksa , lebih mudah untuk menggunakannya dengan
jq .
Kesimpulan
Saya ingin mencatat bahwa keamanan dalam proyek ini tidak dilaporkan karena ini merupakan lingkungan pengujian (dev) dan tidak direncanakan untuk dirilis di luar router. Jika Anda menggunakannya untuk penggunaan yang lebih serius, Anda harus mengikuti praktik terbaik, menginstal sertifikat untuk HTTPS, membuat cadangan, pemantauan normal (yang tidak dimulai di sebelah sistem utama). Omong-omong, Traefik berjalan di buruh pelabuhan saya di server saya, yang merupakan proxy terbalik untuk beberapa layanan, dan juga mengakhiri TLS dengan sendirinya dan melakukan otentikasi. Yaitu, berkat DNS yang dikonfigurasi dan proksi balik, menjadi mungkin untuk mengakses antarmuka web Kibana dari Internet dengan HTTPS dan kata sandi yang tidak dikonfigurasi (seperti yang saya pahami, dalam versi komunitas Kibana tidak mendukung perlindungan kata sandi untuk antarmuka web). Saya berencana untuk menjelaskan pengalaman saya lebih lanjut dalam mengatur Traefik untuk digunakan pada jaringan rumah dengan Docker.