Hai, Habrovsk. Hari ini, kelas akan dimulai pada kelompok pertama dari kursus PostgreSQL . Dalam hal ini, kami ingin memberi tahu Anda tentang bagaimana webinar terbuka untuk kursus ini berlangsung.
Dalam
pelajaran terbuka berikutnya, kami berbicara tentang tantangan apa yang dihadapi database SQL di era cloud dan Kubernetes. Dan pada saat yang sama kami memeriksa bagaimana database SQL beradaptasi dan bermutasi di bawah pengaruh panggilan ini.
Webinar ini diselenggarakan oleh
Valery Bezrukov , Manajer Pengiriman Praktik Google Cloud di EPAM Systems.
Ketika pohon-pohon kecil ...
Untuk memulai, mari kita ingat bagaimana pilihan DBMS dimulai pada akhir abad terakhir. Namun, ini tidak akan sulit, karena pilihan DBMS pada masa itu dimulai dan diakhiri dengan
Oracle .

Di akhir tahun 90-an - awal dari tantangan, pada kenyataannya, tidak ada pilihan khusus, jika kita berbicara tentang basis data industri yang dapat diukur. Ya, ada IBM DB2, Sybase, dan beberapa database lain yang muncul dan menghilang, tetapi secara umum mereka tidak begitu terlihat terhadap Oracle. Dengan demikian, keterampilan insinyur pada masa itu entah bagaimana terikat pada satu-satunya pilihan yang ada.
Oracle DBA harus dapat:
- Instal Oracle Server dari distribusi
- mengkonfigurasi Oracle Server:
- buat:
- Cadangkan dan pulihkan;
- melakukan pemantauan;
- berurusan dengan permintaan suboptimal.
Pada saat yang sama, Oracle DBA tidak terlalu diperlukan:
- dapat memilih DBMS optimal atau teknologi penyimpanan dan pemrosesan data lainnya;
- memberikan ketersediaan tinggi dan skalabilitas horizontal (ini tidak selalu merupakan masalah DBA);
- Pengetahuan yang baik tentang bidang subjek, infrastruktur, arsitektur terapan, OS;
- melakukan bongkar muat data, migrasi data antara DBMS yang berbeda.
Secara umum, jika kita berbicara tentang pilihan pada masa itu, maka itu menyerupai pilihan di toko Soviet di akhir tahun 80-an:

Waktu kita
Sejak itu, tentu saja, pohon-pohon telah tumbuh, dunia telah berubah, dan entah bagaimana menjadi seperti ini:

Pasar DBMS juga telah berubah, yang dapat dilihat dengan jelas dari laporan Gartner terbaru:

Dan di sini perlu dicatat bahwa awan menempati ceruk mereka, popularitasnya sedang tumbuh. Jika Anda membaca laporan Gartner yang sama, kami akan melihat kesimpulan berikut:
- Banyak pelanggan sedang dalam perjalanan untuk memindahkan aplikasi ke cloud.
- Teknologi baru pertama kali muncul di cloud dan bukan fakta bahwa mereka akan pernah pindah ke infrastruktur bebas cloud.
- Model penetapan harga pay-as-you-go telah menjadi akrab. Semua orang ingin membayar hanya untuk apa yang mereka gunakan, dan ini bahkan bukan tren, tetapi hanya pernyataan fakta.
Apa sekarang?
Hari ini kita semua ada di awan. Dan pertanyaan-pertanyaan yang kita miliki adalah pertanyaan pilihan. Dan itu sangat besar, bahkan jika kita hanya berbicara tentang pilihan teknologi DBMS dalam format lokal. Kami juga telah mengelola layanan dan SaaS. Dengan demikian, pilihannya menjadi lebih rumit setiap tahun.
Bersamaan dengan pertanyaan pilihan,
faktor restriktif juga berlaku:
- harga . Banyak teknologi masih membutuhkan uang;
- keterampilan . Jika kita berbicara tentang perangkat lunak bebas, maka pertanyaan tentang keterampilan muncul, karena perangkat lunak bebas membutuhkan orang yang menggunakan dan mengoperasikannya dengan kompetensi yang memadai;
- fungsional . Tidak semua layanan yang tersedia di cloud dan dibangun, katakanlah, bahkan berdasarkan Postgres yang sama, memiliki fitur yang sama dengan Postgres di tempat. Ini adalah faktor penting yang perlu Anda ketahui dan pahami. Selain itu, faktor ini menjadi lebih penting daripada pengetahuan tentang beberapa fitur tersembunyi dari satu DBMS.
Apa yang menunggu dari DA / DE:- pemahaman yang baik tentang area subjek dan arsitektur terapan;
- kemampuan untuk memilih teknologi DBMS yang tepat, dengan mempertimbangkan tugas;
- kemampuan untuk memilih metode optimal untuk menerapkan teknologi yang dipilih dalam konteks keterbatasan yang ada;
- kemampuan untuk melakukan migrasi dan migrasi data;
- kemampuan untuk mengimplementasikan dan mengoperasikan solusi yang dipilih.
Contoh berikut
berdasarkan pada GCP menunjukkan bagaimana pilihan teknologi tertentu untuk bekerja dengan data diatur tergantung pada strukturnya:

Perhatikan bahwa PostgreSQL tidak ada dalam skema, dan semua karena bersembunyi di bawah terminologi
Cloud SQL . Dan ketika kita masuk ke Cloud SQL, kita perlu membuat pilihan lagi:

Perlu dicatat bahwa pilihan ini tidak selalu jelas, oleh karena itu pengembang aplikasi sering dipandu oleh intuisi.
Total:- Semakin jauh, semakin relevan pertanyaan pilihan. Dan bahkan jika Anda hanya melihat GCP, layanan yang dikelola, dan SaaS, maka beberapa penyebutan RDBMS hanya muncul pada langkah ke-4 (dan ada Spanner terdekat). Plus, pilihan PostgreSQL muncul secara umum pada langkah ke-5, dan di sebelahnya ada juga MySQL dan SQL Server, yaitu ada banyak, tetapi Anda harus memilih .
- Kita tidak boleh lupa tentang batasan latar belakang pencobaan. Sebagian besar semua orang menginginkan kunci pas, tetapi mahal. Akibatnya, kueri khas terlihat seperti ini: "Tolong lakukan Spanner untuk kami, tetapi untuk harga Cloud SQL, well, Anda adalah profesional!"

Apa yang harus dilakukan
Tanpa berpura-pura menjadi kebenaran tertinggi, katakanlah yang berikut:
Perlu mengubah pendekatan untuk belajar:- untuk belajar, seperti yang diajarkan sebelum DBA, tidak masuk akal;
- pengetahuan tentang satu produk tidak lagi cukup;
- tetapi untuk mengetahui lusinan pada level satu adalah tidak mungkin.
Anda perlu tahu tidak hanya dan tidak seberapa banyak produk, tetapi:
- gunakan case aplikasinya;
- metode penyebaran yang berbeda;
- kelebihan dan kekurangan masing-masing metode;
- produk serupa dan alternatif untuk membuat pilihan yang terinformasi dan optimal dan tidak selalu mendukung produk yang sudah dikenal.
Anda juga harus dapat melakukan migrasi data dan memahami prinsip-prinsip dasar integrasi dengan ETL.
Kasus nyata
Di masa lalu, Anda harus membuat backend untuk aplikasi seluler. Pada saat itu mulai bekerja di atasnya, backend sudah dikembangkan dan siap untuk implementasi, dan tim pengembangan menghabiskan sekitar dua tahun pada proyek ini. Tugas-tugas berikut telah ditetapkan:
- membangun CI / CD;
- untuk meninjau arsitektur;
- laksanakan semuanya.
Aplikasi itu sendiri adalah microservice, dan kode Python / Django dikembangkan dari awal dan langsung dalam GCP. Adapun target audiens, diasumsikan bahwa akan ada dua wilayah - AS dan Uni Eropa, dan lalu lintas didistribusikan melalui penyeimbang Beban Global. Semua beban kerja dan beban kerja komputasi bekerja di Google Kubernetes Engine.
Adapun data, ada 3 struktur:
- Penyimpanan Awan
- Datastore;
- Cloud SQL (PostgreSQL).
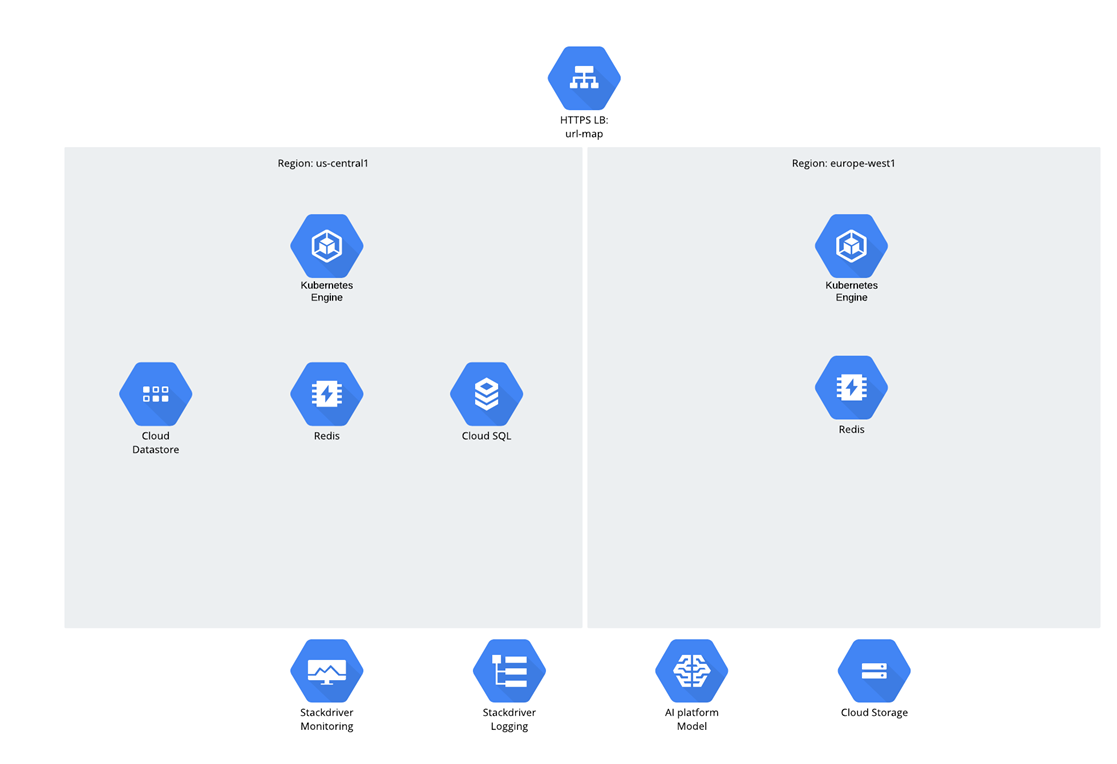
Anda mungkin bertanya-tanya mengapa Cloud SQL dipilih? Sejujurnya, pertanyaan seperti itu dalam beberapa tahun terakhir telah menyebabkan beberapa jeda canggung - ada perasaan bahwa orang-orang mulai malu dengan database relasional, tetapi bagaimanapun mereka terus menggunakannya secara aktif ;-).
Untuk kasus kami, Cloud SQL dipilih karena alasan berikut:
- Seperti disebutkan, aplikasi ini dikembangkan menggunakan Django, dan memiliki model untuk memetakan data persisten dari database SQL ke objek Python (Django ORM).
- Kerangka itu sendiri mendukung daftar DBMS yang cukup terbatas:
- PostgreSQL
- MariaDB;
- MySQL
- Oracle
- SQLite
Karenanya, PostgreSQL dipilih secara intuitif dari daftar ini (sebenarnya, bukan Oracle, sebenarnya).
Apa yang hilang:- aplikasi ini dikerahkan hanya di 2 wilayah, dan rencana muncul ketiga (Asia);
- Basis data berada di wilayah Amerika Utara (Iowa);
- di pihak pelanggan, ada kekhawatiran tentang kemungkinan keterlambatan akses dari Eropa dan Asia dan gangguan dalam layanan jika terjadi downtime DBMS.
Terlepas dari kenyataan bahwa Django sendiri dapat bekerja dengan beberapa database secara paralel dan membaginya dengan membaca dan menulis, tidak ada begitu banyak catatan dalam aplikasi (lebih dari 90% - membaca). Dan secara umum, dan secara umum, jika Anda bisa membuat
replika-baca dari pangkalan utama di Eropa dan Asia , ini akan menjadi solusi kompromi. Nah, apa yang begitu rumit?
Dan kesulitannya adalah bahwa pelanggan tidak ingin menolak untuk menggunakan layanan yang dikelola dan Cloud SQL. Dan kemungkinan Cloud SQL saat ini terbatas. Cloud SQL mendukung Ketersediaan tinggi (HA) dan Baca Replika (RR), tetapi RR yang sama hanya didukung di satu wilayah. Setelah membuat database di wilayah Amerika, tidak mungkin membuat replika-baca di wilayah Eropa menggunakan Cloud SQL, meskipun postgres itu sendiri tidak mengganggu. Korespondensi dengan karyawan Google tidak mengarah pada apa pun dan berakhir dengan janji-janji dengan gaya "kita tahu masalahnya dan sedang mengatasinya, suatu hari nanti masalah ini akan terselesaikan."
Jika Anda daftar kemungkinan tesis Cloud SQL, itu akan terlihat seperti ini:
1. Ketersediaan tinggi (HA):- dalam satu wilayah;
- melalui replikasi disk
- Mekanisme postgreSQL tidak digunakan;
- kontrol otomatis dan manual mungkin - failover / failback;
- saat beralih, DBMS tidak tersedia selama beberapa menit.
2. Baca Replika (RR):- dalam satu wilayah;
- siaga panas;
- Replikasi streaming PostgreSQL.
Selain itu, seperti kebiasaan, ketika memilih teknologi Anda selalu menemukan beberapa
keterbatasan :
- pelanggan tidak ingin menghasilkan entitas dan menggunakan IaaS, kecuali melalui GKE;
- pelanggan tidak ingin menggunakan layanan mandiri PostgreSQL / MySQL;
- baik, secara umum, Google Spanner akan sangat cocok jika itu bukan karena harganya, namun, Django ORM tidak dapat bekerja dengannya, jadi masalahnya bagus.
Melihat situasinya, pelanggan menerima pertanyaan pengisian ulang:
"Bisakah Anda melakukan sesuatu yang mirip dengan membuatnya seperti Google Spanner, tetapi juga berfungsi dengan Django ORM?"Opsi No. 0
Hal pertama yang terlintas dalam pikiran:
- Tetap dalam CloudSQL
- tidak akan ada replikasi terintegrasi antar daerah dalam bentuk apa pun;
- coba sekrup replika ke Cloud SQL yang ada oleh PostgreSQL;
- suatu tempat dan entah bagaimana memulai contoh PostgreSQL, tetapi setidaknya master tidak menyentuh.
Sayangnya, ternyata ini tidak dapat dilakukan, karena tidak ada akses ke host (itu ada di proyek lain pada umumnya) - pg_hba dan seterusnya, dan masih ada akses di bawah superuser.
Opsi No. 1
Setelah merenungkan lebih lanjut dan mempertimbangkan keadaan sebelumnya, aliran pemikiran agak berubah:
- kami masih mencoba untuk tetap berada dalam ruang lingkup CloudSQL, tetapi kami beralih ke MySQL, karena Cloud SQL oleh MySQL memiliki master eksternal, yang:
- adalah proxy untuk MySQL eksternal;
- terlihat seperti instance MySQL;
- Diciptakan untuk migrasi data dari cloud lain atau Di tempat.
Karena mengatur replikasi MySQL tidak memerlukan akses ke host, pada dasarnya semuanya berfungsi, tetapi sangat tidak stabil dan tidak nyaman. Dan ketika kami melangkah lebih jauh, itu menjadi sangat menakutkan, karena kami mengerahkan seluruh struktur dengan terraform, dan tiba-tiba ternyata master eksternal tidak didukung oleh terraform. Ya, Google memiliki CLI, tetapi untuk beberapa alasan semuanya berfungsi sesekali - itu dibuat, tidak dibuat. Mungkin karena CLI diciptakan untuk migrasi data di luar, dan bukan untuk replika.
Sebenarnya, ini memperjelas bahwa Cloud SQL tidak cocok dengan kata sama sekali. Seperti yang mereka katakan, kami melakukan semua yang kami bisa.
Opsi 2
Karena tidak berfungsi untuk tetap berada dalam Cloud SQL, kami mencoba merumuskan persyaratan untuk solusi kompromi. Persyaratannya adalah sebagai berikut:
- bekerja di Kubernetes, penggunaan maksimum sumber daya dan kemampuan Kubernetes (DCS, ...) dan GCP (LB, ...);
- kurangnya pemberat dari tumpukan hal-hal yang tidak perlu di cloud seperti HA proxy;
- kemampuan untuk menjalankan HA PostgreSQL atau MySQL di wilayah utama; di wilayah lain - HA dari RR wilayah utama ditambah salinannya (untuk keandalan);
- multi master (tidak ingin menghubunginya, tapi itu tidak terlalu penting)
.
Sebagai hasil dari persyaratan ini, di cakrawala akhirnya muncul
opsi dan binding DBMS yang sesuai :
- MySQL Galera;
- CockroachDB;
- Alat PostgreSQL
:
- pgpool-II;
- Patroni.
MySQL Galera
Teknologi MySQL Galera dikembangkan oleh Codership dan merupakan plugin untuk InnoDB. Fitur:
- multi-master;
- replikasi sinkron
- membaca dari sembarang simpul;
- merekam ke sembarang simpul;
- mekanisme HA terpadu;
- Ada grafik Helm dari Bitnami.
Cockroachdb
Menurut uraian, benda itu sepenuhnya bombastis dan merupakan proyek sumber terbuka yang ditulis dalam Go. Peserta utama adalah Lab Kecoak (didirikan oleh imigran dari Google). DBMS relasional ini pada awalnya dibuat untuk didistribusikan (dengan penskalaan horizontal di luar kotak) dan toleran terhadap kesalahan. Penulisnya dari perusahaan menguraikan tujuan "menggabungkan kekayaan fungsionalitas SQL dengan ketersediaan horizontal yang akrab dengan solusi NoSQL."
Bonus yang bagus adalah dukungan untuk protokol koneksi postgres.
Pgpool
Ini merupakan tambahan untuk PostgreSQL, pada kenyataannya, entitas baru yang mengambil alih semua koneksi dan memprosesnya. Ini memiliki penyeimbang loader dan parser sendiri, dilisensikan di bawah lisensi BSD. Ini memberikan banyak peluang, tetapi terlihat agak menakutkan, karena kehadiran entitas baru bisa menjadi sumber beberapa petualangan tambahan.
Patroni
Ini adalah hal terakhir yang dilihat mata, dan, ternyata, tidak sia-sia. Patroni adalah utilitas open source, yang, pada dasarnya, adalah daemon Python yang secara otomatis memelihara cluster PostgreSQL dengan berbagai jenis replikasi dan pengalihan peran otomatis. Potongan itu ternyata sangat menarik, karena terintegrasi dengan baik dengan cuber dan tidak membawa entitas baru.
Yang akhirnya memilih
Pilihannya tidak mudah:
- CockroachDB - api, tapi bodoh;
- MySQL Galera juga tidak buruk, banyak digunakan di mana, tapi MySQL;
- Pgpool - banyak entitas tambahan, integrasi begitu saja dengan cloud dan K8;
- Patroni - integrasi sempurna dengan K8, tanpa entitas tambahan, terintegrasi dengan baik dengan GCP LB.
Dengan demikian, pilihan jatuh pada Patroni.
Kesimpulan
Waktunya telah tiba untuk meringkas. Ya, dunia infrastruktur TI telah berubah secara signifikan, dan ini baru permulaan. Dan jika awan sebelumnya hanyalah jenis infrastruktur lain, sekarang semuanya berbeda. Selain itu, inovasi di awan terus-menerus muncul, mereka akan muncul dan, mungkin, mereka hanya akan muncul di awan, dan hanya kemudian, melalui kekuatan startup, mereka akan ditransfer ke Di tempat.
Adapun SQL, SQL akan hidup. Ini berarti bahwa PostgreSQL dan MySQL harus diketahui dan Anda harus dapat bekerja dengannya, tetapi yang lebih penting, untuk dapat menerapkannya dengan benar.