Semakin kompleks sistemnya, semakin tumbuh dengan semua jenis peringatan. Dan ada kebutuhan untuk menanggapi peringatan ini, mengagregasikannya dan memvisualisasikannya. Saya pikir situasi yang akrab bagi banyak orang sebelum kutu gugup.
Keputusan yang akan dibahas bukanlah yang paling tidak terduga, tetapi pencarian tidak menghasilkan artikel lengkap tentang topik ini.
Oleh karena itu, saya memutuskan untuk berbagi pengalaman FunCorp dan berbicara tentang bagaimana proses tugas dibangun, siapa yang menelepon, mengapa dan bagaimana Anda bisa melihat semuanya.

Apa itu PagerDuty?
Jadi, untuk menyelesaikan semua masalah ini, kami mulai mencari alat yang praktis. Setelah pencarian singkat, kami memilih PagerDuty. Bagi kami, PD merupakan solusi yang cukup lengkap dan ringkas dengan banyak integrasi dan pengaturan. Seperti apa dia?
Singkatnya, PagerDuty adalah platform pemrosesan insiden yang dapat menangani insiden yang masuk melalui berbagai integrasi, menyesuaikan urutan tugas dan kemudian mengingatkan insinyur tugas tergantung pada tingkat insiden (pada panggilan tingkat tinggi, dengan dorongan rendah dari aplikasi / sms) .
Siapa orang yang bertugas?
Ini mungkin hal pertama yang harus dilakukan untuk menyiapkan PD.
FunCorp, seperti perusahaan lain, memiliki posisi kehormatan yang sedang bertugas. Ini ditransmisikan dari insinyur ke insinyur sekali sehari. Ada yang disebut sebagai baris pertama dan kedua sebagai respons terhadap peringatan dari PagerDuty. Misalkan peringatan prioritas tinggi tiba, dan jika 10 menit setelah panggilan ke petugas dari baris pertama tidak ada reaksi padanya (mis. Dia tidak dipindahkan ke status mengakui atau menyelesaikan), panggilan tersebut dialihkan ke insinyur tugas kedua. Ini dikonfigurasikan di PagerDuty sendiri melalui Kebijakan Eskalasi.
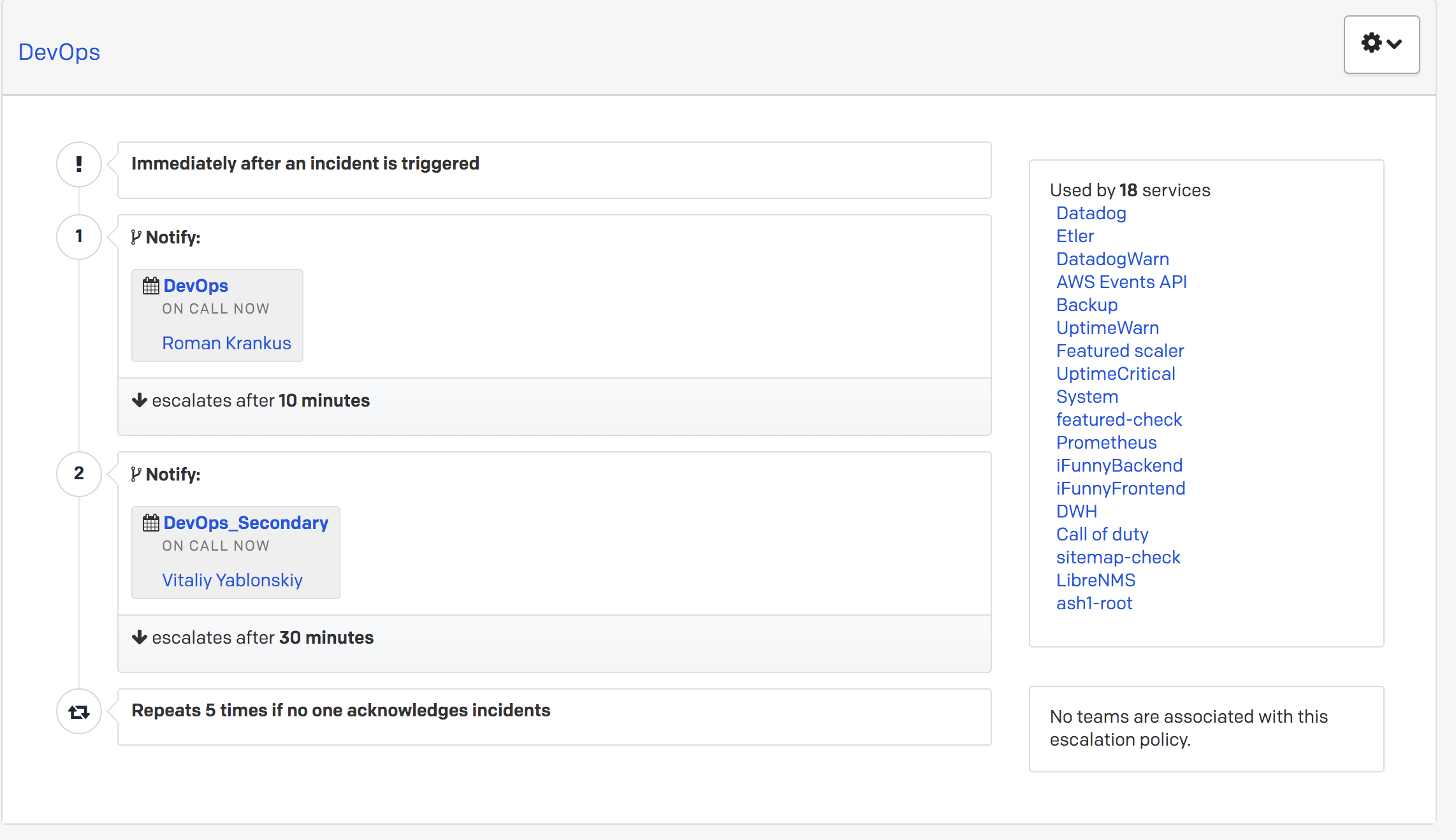
Jika petugas kedua tidak merespons, maka pemberitahuan kembali ke petugas
utama .
Dengan demikian, setiap peringatan prioritas tinggi yang masuk tidak dapat tetap tidak diproses.
Sekarang mari kita lihat dari mana datangnya insiden tersebut.
Integrasi apa yang kami gunakan?
Banyak berbagai insiden dari berbagai layanan dituangkan ke dalam PD. Kami sekarang memiliki sekitar 25 layanan seperti itu, dan untuk pemrosesan mereka kami menggunakan beberapa integrasi yang sudah jadi.
Sistem pengumpulan metrik utama adalah Prometheus. Banyak yang telah ditulis tentang hal itu di Habré, saya hanya akan mengatakan bahwa kami memiliki beberapa lingkungan berbeda: satu mengumpulkan metrik dari mesin virtual dan buruh pelabuhan, yang lain dari layanan Amazon, yang ketiga dari "mesin besi". Terutama digunakan sebagai pengekspor metrik adalah Telegraf.
Di sini juga, saya pikir semuanya jelas dari namanya. Integrasi ini digunakan untuk mengirim pemberitahuan dari beberapa skrip yang dieksekusi di mahkota. PD memberi Anda alamat tertentu yang Anda kirimi surat. Saat membuat layanan dengan integrasi seperti itu, Anda dapat menetapkan prioritas dalam urutan bagaimana insiden yang masuk akan diproses, cara membuat lansiran (untuk setiap surat masuk, untuk surat masuk + aturan tertentu, dll.).

Menurut saya, integrasi yang sangat menarik. Ada kalanya sesuatu terjadi, tetapi tidak dilindungi oleh insiden. Karenanya, kami menambahkan integrasi dari Slack untuk membuat insiden. Yaitu, di perusahaan Slack Anda dapat menulis
/ callofduty semuanya melambat dan segera rusak dan proses PD ini dan mengirimkan insiden ke insinyur tugas.
Kami lakukan:

Kita melihat:

Integrasi HTTP. Di sini, pada kenyataannya, tidak ada yang sangat menarik, hanya permintaan POST dengan badan dalam format JSON. Misalnya, dari yang menarik: kami menggunakannya untuk pemantauan eksternal menggunakan
https://www.statuscake.com/ . Layanan ini memeriksa ketersediaan situs kami dari seluruh dunia. Dalam kasus ketika kita mendapatkan kode respons yang tidak dapat diterima (misalnya, 502), sebuah insiden dibuat dan kemudian semuanya berjalan di sepanjang rantai yang dijelaskan di atas. StatusCake sendiri memiliki kemampuan untuk memonitor URL internal, berakhirnya sertifikat atau domain SSL.
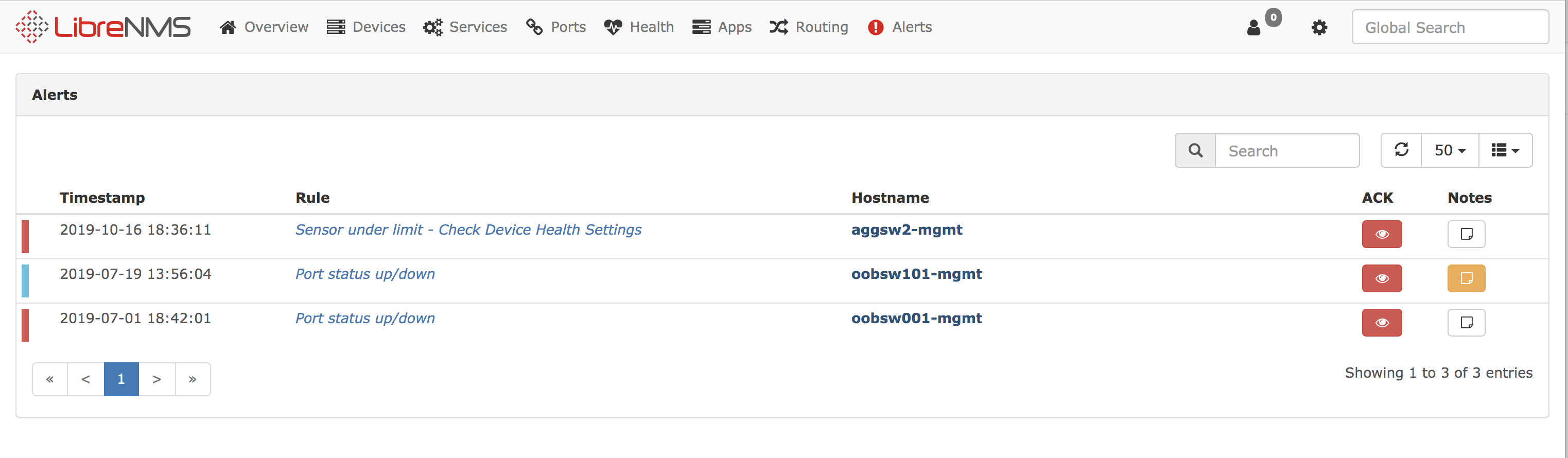
Ini adalah sistem pemantauan lain, lebih lanjut tentang hal itu dapat ditemukan di situs web mereka
https://www.librenms.org/ . Dengan bantuannya, kami memantau antarmuka jaringan dan iDRAC dari server.
Ada juga integrasi seperti Datadog, CloudWatch. Lebih lanjut tentang apa yang terjadi pada mereka dapat ditemukan di
sini .
Visualisasi
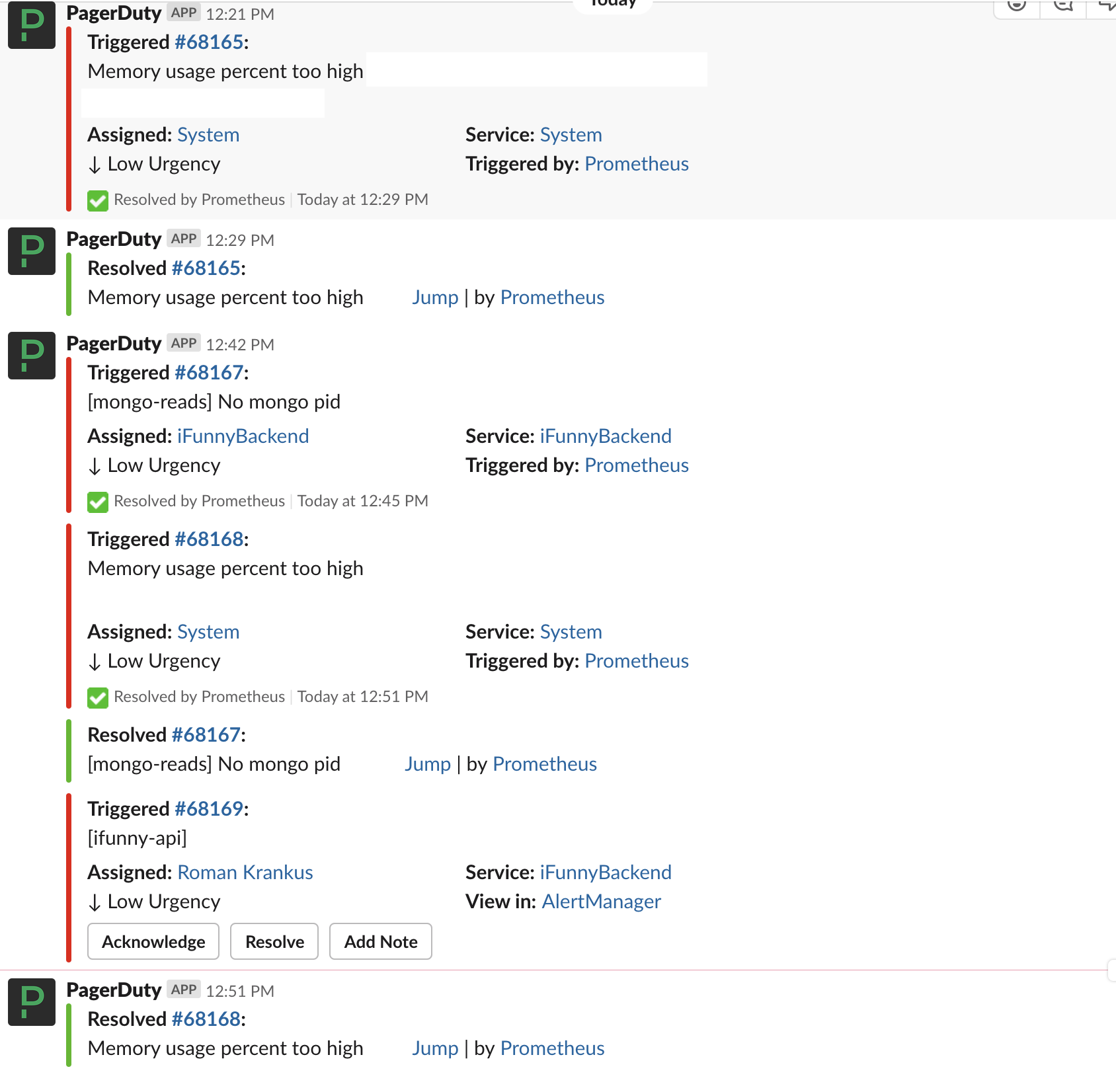
Sistem pelaporan insiden utama adalah Slack. Semua insiden yang datang ke PD ditulis ke obrolan khusus, dan jika statusnya berubah, ini juga ditampilkan dalam obrolan.
Ketika dimungkinkan untuk menampilkan data yang berguna pada layar monitor yang tergantung di bawah langit-langit, kami tiba-tiba menyadari bahwa kami (di bagian devops) tidak memiliki apa pun untuk ditampilkan di sana. Ada Grafana yang luar biasa, tapi tidak bisa ditutupi, dan karyawan merespons peringatan, bukan grafik.
Setelah pencarian menyeluruh dan tidak berhasil pada GitHub untuk "papan" ringkas dan informatif untuk PD, kami memutuskan untuk menulis sendiri - hanya dengan apa yang kami butuhkan. Meskipun pada awalnya ada ide untuk menampilkan antarmuka PD itu sendiri, itu tampak lebih tidak nyaman.
Untuk menulisnya, Anda hanya perlu mendapatkan kunci untuk PD dengan hak baca-saja.
Dan inilah yang kami dapatkan:
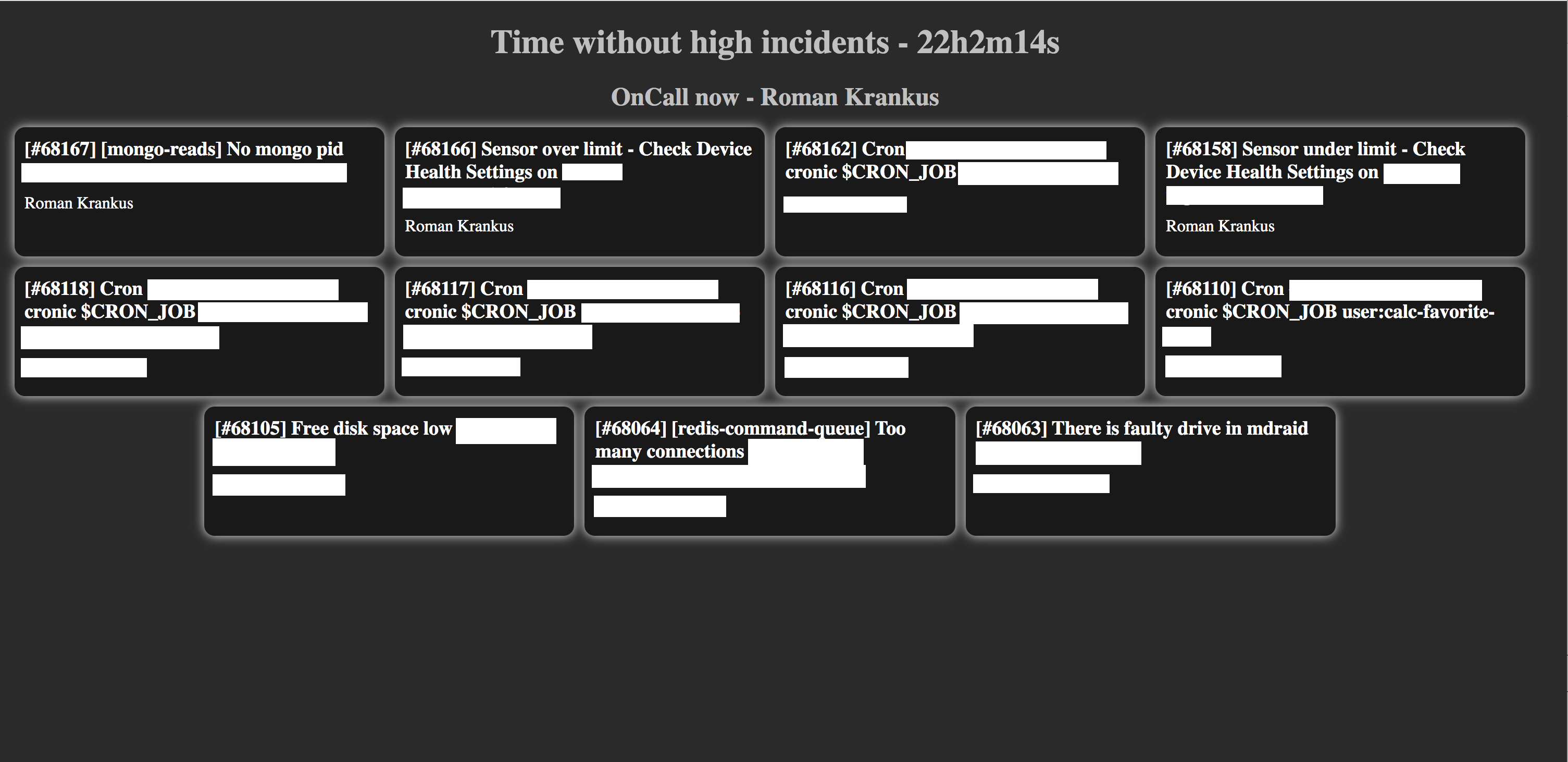
Layar menampilkan insiden terbuka saat ini, nama insinyur tugas saat ini dari jadwal yang dipilih, dan waktu tanpa insiden prioritas tinggi (panel dengan insiden prioritas tinggi akan disorot dengan warna merah).
Lihat kode sumber untuk implementasi ini di sini .
Hasilnya, kami mendapat dasbor yang nyaman untuk melihat semua insiden kami. Saya akan senang jika ada di antara Anda yang akan mendapat manfaat dari pengalaman kami.