
Saat kami berhenti mengontrol ukuran tabel, mempertahankan dan menyediakan data menjadi tugas yang tidak sepele. Saya sudah mengalami masalah seperti itu dalam produksi, ada lebih banyak data setiap hari, tabel tidak sesuai dengan memori, server merespons untuk waktu yang lama, tetapi sebuah solusi ditemukan.
Halo, Habr! Nama saya Diamond dan sekarang saya ingin berbagi metode yang membantu saya mengimplementasikan partisi.
Partisi dalam PostgreSql
Partisi (atau, demikian mereka menyebutnya, mempartisi) adalah proses pemisahan satu tabel logis besar menjadi beberapa bagian fisik yang lebih kecil. Inilah yang membantu kami mengelola data kami.
Contoh: kami memiliki tabel "penjualan", yang dipartisi dengan selang waktu satu bulan, dan bagian ini dapat dibagi menjadi sub-bagian yang lebih kecil berdasarkan wilayah.
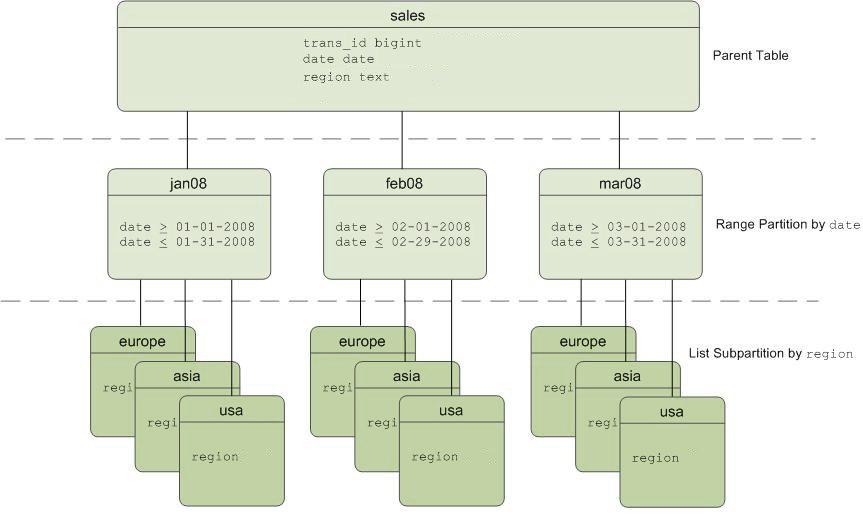 Skema “penjualan” tabel yang dipartisi
Skema “penjualan” tabel yang dipartisiKekurangan dari pendekatan ini:
- Struktur database yang rumit. Setiap bagian dalam definisi basis data adalah sebuah tabel, walaupun itu adalah bagian dari satu entitas logis.
- Anda tidak dapat mengonversi tabel yang ada ke yang dipartisi dan sebaliknya.
- Tidak ada dukungan penuh di Postgres versi 11.
Pro:
+ Performa. Dalam kasus tertentu, kita dapat bekerja dengan kumpulan bagian terbatas tanpa melalui seluruh tabel, bahkan pencarian indeks untuk tabel besar akan lebih lambat. Meningkatkan ketersediaan data.
+ Unggah massal dan hapus data dengan perintah ATTACH / DETACH. Ini menyelamatkan kita dari overhead dalam bentuk VACUUM. yang memungkinkan Anda untuk lebih efektif memelihara basis data.
+ Kemampuan untuk menentukan TABLESPACE untuk bagian tersebut. Ini memberi kita peluang untuk mentransfer data ke bagian lain, tetapi kami masih bekerja dalam instance yang sama dan metadata dari direktori utama akan berisi informasi tentang bagian-bagian. (Jangan bingung dengan sharding)
2 cara untuk mengimplementasikan partisi di PostgreSql:
1. Warisan tabel (Warisan)Saat membuat tabel, kita mengatakan "mewarisi dari tabel (induk) lain". Pada saat yang sama, kami menambahkan batasan untuk manajemen data dalam tabel. Dengan ini kami mendukung logika pemisahan data, tetapi ini adalah tabel yang berbeda secara logis.
Di sini perlu dicatat ekstensi yang dikembangkan oleh Postgres Professional pg_pathman, yang mengimplementasikan partisi, juga melalui pewarisan tabel.
CREATE TABLE orders_y2010 ( CHECK (log_date >= DATE '2010-01-01) ) INHERITS (orders);
2. Pendekatan deklaratif (PARTISI)Tabel didefinisikan sebagai dipartisi secara deklaratif. Solusi ini muncul dalam versi 10 dari PostgreSql.
CREATE TABLE orders (log_date date not null, …) PARTITION BY RANGE(log_date);
Saya telah memilih pendekatan deklaratif. Ini memberikan keuntungan besar - kekerabatan, lebih banyak fitur yang didukung oleh kernel. Pertimbangkan pengembangan PostgreSQL ke arah ini:
 Sumber
SumberTetapi PostgreSql terus berkembang, dan versi 12 memiliki dukungan untuk menautkan ke tabel yang dipartisi. Ini adalah terobosan besar.
Cara saya
Diberikan di atas,
skrip ditulis dalam PL / pgSQL, yang membuat tabel dipartisi berdasarkan yang sudah ada dan "melempar" semua tautan ke tabel baru. Jadi, kita mendapatkan tabel dipartisi berdasarkan yang sudah ada dan terus bekerja dengannya seperti dengan tabel biasa.
Script tidak memerlukan dependensi tambahan dan berjalan dalam sirkuit terpisah yang dibuatnya sendiri. Juga log ulang dan kembalikan tindakan. Script ini memecahkan dua tugas utama: membuat tabel dipartisi dan mengimplementasikan tautan eksternal ke sana melalui pemicu.
Persyaratan skrip: PostgreSql v.:11 dan lebih tinggi.
Sekarang mari kita telusuri skripnya dengan lebih detail. Antarmukanya sangat sederhana:
Ada dua prosedur yang melakukan semua pekerjaan.
1. Tantangan utama - pada tahap ini kami tidak mengubah tabel utama, tetapi semua yang diperlukan untuk bagian akan dibuat dalam skema terpisah:
call partition_run();
2. Panggil tugas yang ditangguhkan yang direncanakan selama pekerjaan utama:
call partition_run_jobs();
Pekerjaan dapat diluncurkan di beberapa utas. Jumlah utas optimal mendekati jumlah tabel yang dipartisi.
Parameter input untuk skrip (catatan _pt)

Script dari dalam, tindakan utama:
- Buat tabel yang dipartisi
perform _partition_create_parent_table(_pt);
- Buat bagian
perform _partition_create_child_tables(_pt);
- Salin data di bagian
perform _partition_copy_data(_pt);
- Tambahkan batasan (pekerjaan)
perform _partition_add_constraints(_pt);
- Kembalikan tautan ke tabel eksternal
perform _partition_restore_referrences(_pt);
- Kembalikan pemicu
perform _partition_restore_triggers(_pt);
- Buat pemicu acara
perform _partition_def_tr_on_delete(_pt);
- Buat indeks (pekerjaan)
perform _partition_create_index(_pt);
- Ganti tampilan, tautan bagian (pekerjaan)
perform _partition_replace_view(_pt);
Waktu berjalan skrip tergantung pada banyak faktor, tetapi yang utama adalah ukuran tabel target, jumlah hubungan, indeks dan karakteristik server. Dalam kasus saya, tabel 300Gb dipartisi dalam waktu kurang dari satu jam.
Hasil
Apa yang kita dapatkan? Mari kita lihat rencana permintaan:
EXPLAIN ANALYZE select * from “sales” where dt BETWEEN '01.01.2019'::date and '14.01.2019'::date

Kami mendapat hasil dari tabel dipartisi lebih cepat dan menggunakan lebih sedikit sumber daya server kami dibandingkan dengan kueri ke tabel biasa.
Dalam contoh ini, tabel reguler dan dipartisi berada di pangkalan yang sama dan memiliki sekitar 200 juta catatan. Ini adalah hasil yang baik, mengingat bahwa kami, tanpa menulis ulang kode aplikasi, mendapat akselerasi. Kueri pada indeks lain juga berfungsi dengan baik, tetapi ingat: setiap kali kita dapat menentukan bagian, hasilnya akan beberapa kali lebih cepat, karena PostgreSql dapat membuang bagian tambahan pada tahap perencanaan permintaan (
atur enable_partition_pruning ke on ).
Ringkasan
Saya berhasil menerapkan partisi pada tabel yang memiliki banyak hubungan dan memastikan integritas basis data. Script tidak tergantung pada struktur data tertentu dan dapat digunakan kembali.
PostgreSQL adalah basis data relasional open source paling canggih di dunia!Terima kasih semuanya!
Tautan ke sumber