Tahun Baru semakin dekat, tahun 2010 akan segera berakhir, memberikan dunia kebangkitan sensasional dari jaringan saraf. Saya terganggu
dan dilarang tidur oleh pikiran sederhana: "Bagaimana seseorang dapat secara retrospektif memperkirakan kecepatan pengembangan jaringan saraf?" Karena "Dia yang tahu masa lalu tahu masa depan". Seberapa cepat algoritma yang berbeda lepas landas? Bagaimana seseorang dapat mengevaluasi kecepatan kemajuan di bidang ini dan memperkirakan kecepatan kemajuan dalam dekade berikutnya?

Jelas bahwa Anda dapat secara kasar menghitung jumlah artikel di berbagai area. Metode ini tidak ideal, Anda perlu mempertimbangkan subdomain akun, tetapi secara umum Anda dapat mencoba. Saya memberikan ide, di
Google Cendekia (BatchNorm) itu cukup nyata! Anda dapat mempertimbangkan kumpulan data baru, Anda dapat kursus baru. Hamba Anda yang rendah hati, setelah
disortir melalui beberapa opsi, menetap di
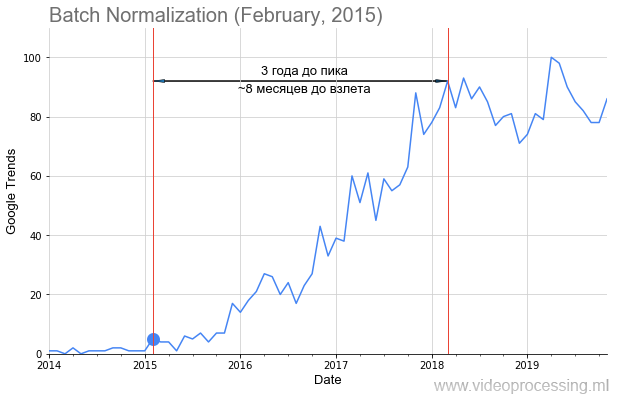
Google Trends (BatchNorm) .
Rekan-rekan saya dan saya menerima permintaan dari teknologi ML / DL utama, misalnya,
Normalisasi Batch , seperti pada gambar di atas, menambahkan tanggal publikasi artikel dengan sebuah titik, dan mendapat cukup waktu untuk menghapus popularitas topik. Tapi tidak untuk semua itu,
jalan setapaknya dipenuhi mawar, lepas landas begitu jelas dan indah, seperti batnorm. Beberapa istilah, seperti regularisasi atau lewati koneksi, tidak dapat dibangun sama sekali karena kebisingan data. Namun secara umum, kami berhasil mengumpulkan tren.
Siapa yang peduli dengan apa yang terjadi - selamat datang di luka!
Alih-alih memperkenalkan atau tentang pengenalan gambar
Jadi! Data awal cukup berisik, kadang-kadang ada puncak yang tajam.
 Sumber: Andrei Karpaty twitter - siswa berdiri di gang audiensi yang besar untuk mendengarkan ceramah tentang jaringan saraf convolutional
Sumber: Andrei Karpaty twitter - siswa berdiri di gang audiensi yang besar untuk mendengarkan ceramah tentang jaringan saraf convolutionalSecara konvensional, cukup bagi
Andrey Karpaty untuk memberikan ceramah tentang
CS231n yang legendaris
: Jaringan Syaraf Konvolusional untuk Pengakuan Visual untuk 750 orang dengan mempopulerkan konsep bagaimana puncak yang tajam terjadi. Oleh karena itu, data dihaluskan dengan
kotak-filter sederhana (semua penghalusan ditandai sebagai Smoothed pada sumbu). Karena kami tertarik untuk membandingkan tingkat pertumbuhan popularitas - setelah perataan, semua data dinormalisasi. Ternyata cukup lucu. Berikut adalah grafik arsitektur utama yang bersaing di ImageNet:
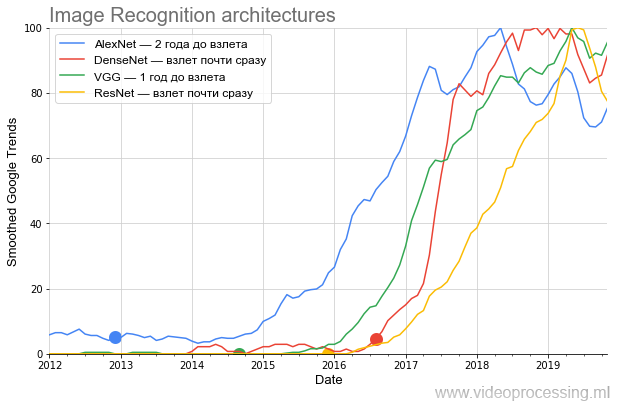 Sumber: Selanjutnya - perhitungan penulis menurut Google Trends
Sumber: Selanjutnya - perhitungan penulis menurut Google TrendsGrafik tersebut menunjukkan dengan sangat jelas bahwa setelah publikasi sensasional oleh
AlexNet , yang menyeduh bubur dari sensasi jaringan saraf saat ini pada akhir 2012, selama hampir dua tahun itu bergolak
meskipun ada anggapan tumpukan bahwa hanya sekelompok spesialis yang relatif sempit
bergabung . Topik tersebut pergi ke masyarakat umum hanya di musim dingin 2014-2015. Perhatikan bagaimana jadual jadwal menjadi dari 2017: puncak lebih lanjut setiap musim semi.
Dalam psikiatri, ini disebut eksaserbasi musim semi ... Ini adalah tanda yang pasti bahwa sekarang istilah ini paling banyak digunakan oleh siswa, dan rata-rata, minat terhadap AlexNet menurun dibandingkan dengan puncak popularitas.
Selanjutnya, pada paruh kedua 2014,
VGG muncul. Ngomong-ngomong,
VGG ikut menulis bersama pengawas
studi , mantan murid saya,
Karen Simonyan , sekarang bekerja di Google DeepMind (
AlphaGo ,
AlphaZero , dll.). Saat belajar di Universitas Negeri Moskow pada tahun ke-3, Karen menerapkan
algoritma Estimasi Gerakan yang baik, yang telah berfungsi sebagai referensi bagi siswa 2 tahun selama 12 tahun. Selain itu, tugas-tugas di sana agak mirip secara sukarela. Bandingkan:
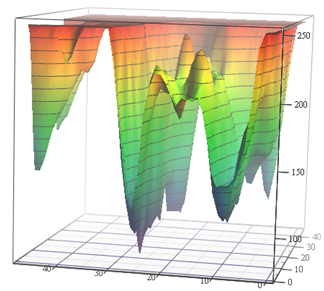
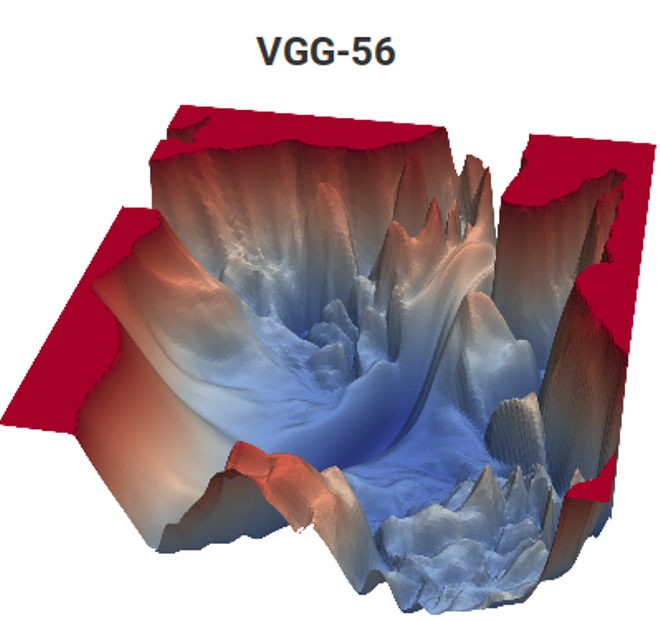 Sumber: Fungsi kerugian untuk tugas Estimasi Gerak (bahan penulis) dan VGG-56
Sumber: Fungsi kerugian untuk tugas Estimasi Gerak (bahan penulis) dan VGG-56Di sebelah kiri Anda perlu menemukan titik terdalam di permukaan nontrivial tergantung pada data input untuk jumlah minimum pengukuran (banyak minimum lokal yang mungkin), dan di sebelah kanan Anda perlu menemukan titik yang lebih rendah dengan perhitungan minimal (dan juga sekelompok minimum lokal, dan permukaan juga tergantung pada data) . Di sebelah kiri, kita mendapatkan vektor gerakan yang diprediksi, dan di sebelah kanan, jaringan terlatih. Dan perbedaannya adalah bahwa di sebelah kiri hanya ada pengukuran implisit ruang warna, dan di sebelah kanan adalah sepasang pengukuran dari ratusan juta. Nah, kompleksitas komputasi di sebelah kanan adalah sekitar 12 orde magnitude (!) Lebih tinggi. Sedikit seperti itu ... Tapi tahun kedua, bahkan dengan tugas yang sederhana, bergoyang seperti ... [dihentikan karena sensor]. Dan tingkat pemrograman anak sekolah kemarin untuk alasan yang tidak diketahui selama 15 tahun terakhir telah menurun tajam. Mereka harus mengatakan: "Kamu akan melakukannya dengan baik, mereka akan membawamu ke DeepMind!" Orang bisa mengatakan "menciptakan VGG", tetapi "mereka akan membawa ke DeepMind" karena alasan tertentu memotivasi lebih baik. Ini, jelas, adalah analog modern maju klasik "Anda akan makan semolina, Anda akan menjadi astronot!". Namun, dalam kasus kami, jika kami menghitung jumlah anak di negara ini dan ukuran korps kosmonot, kemungkinannya jutaan kali lebih tinggi, karena kami berdua sudah bekerja di DeepMind dari laboratorium kami.
Berikutnya adalah
ResNet , melanggar standar jumlah lapisan dan mulai lepas landas setelah enam bulan. Dan akhirnya, DenseNet, yang muncul di awal hype
, lepas landas dengan segera, bahkan lebih keren dari ResNet.
Jika kita berbicara tentang popularitas, saya ingin menambahkan beberapa kata tentang karakteristik jaringan dan kinerja, yang juga bergantung pada popularitas. Jika Anda melihat bagaimana kelas
ImageNet diprediksi tergantung pada jumlah operasi di jaringan, tata letak akan seperti ini (lebih tinggi dan ke kiri - lebih baik):
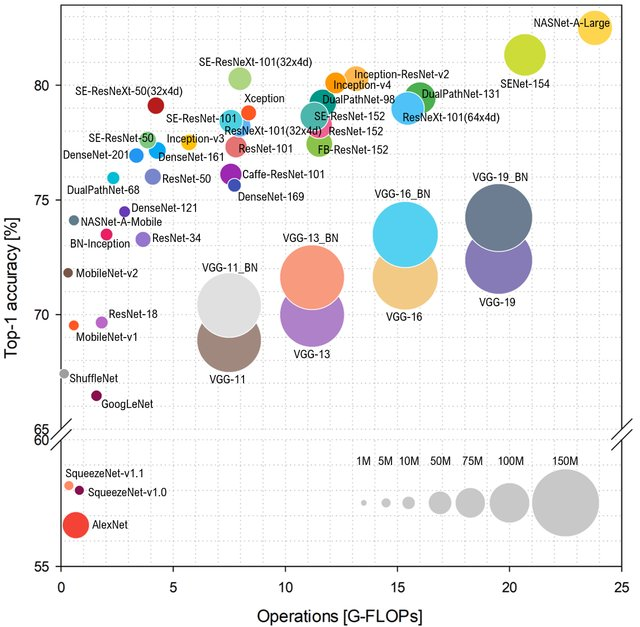 Sumber: Analisis Benchmark Arsitektur Perwakilan Deep Neural Network
Sumber: Analisis Benchmark Arsitektur Perwakilan Deep Neural NetworkJenis AlexNet tidak lagi kue, dan mereka memerintah jaringan berdasarkan ResNet. Namun, jika Anda melihat evaluasi praktis
FPS lebih dekat ke hati saya, Anda dapat dengan jelas melihat bahwa VGG lebih dekat ke optimal di sini, dan secara umum, keberpihakannya berubah. Termasuk AlexNet secara tak terduga pada amplop Pareto-optimal (skala horizontal adalah logaritmik, lebih baik di atas dan di kanan):
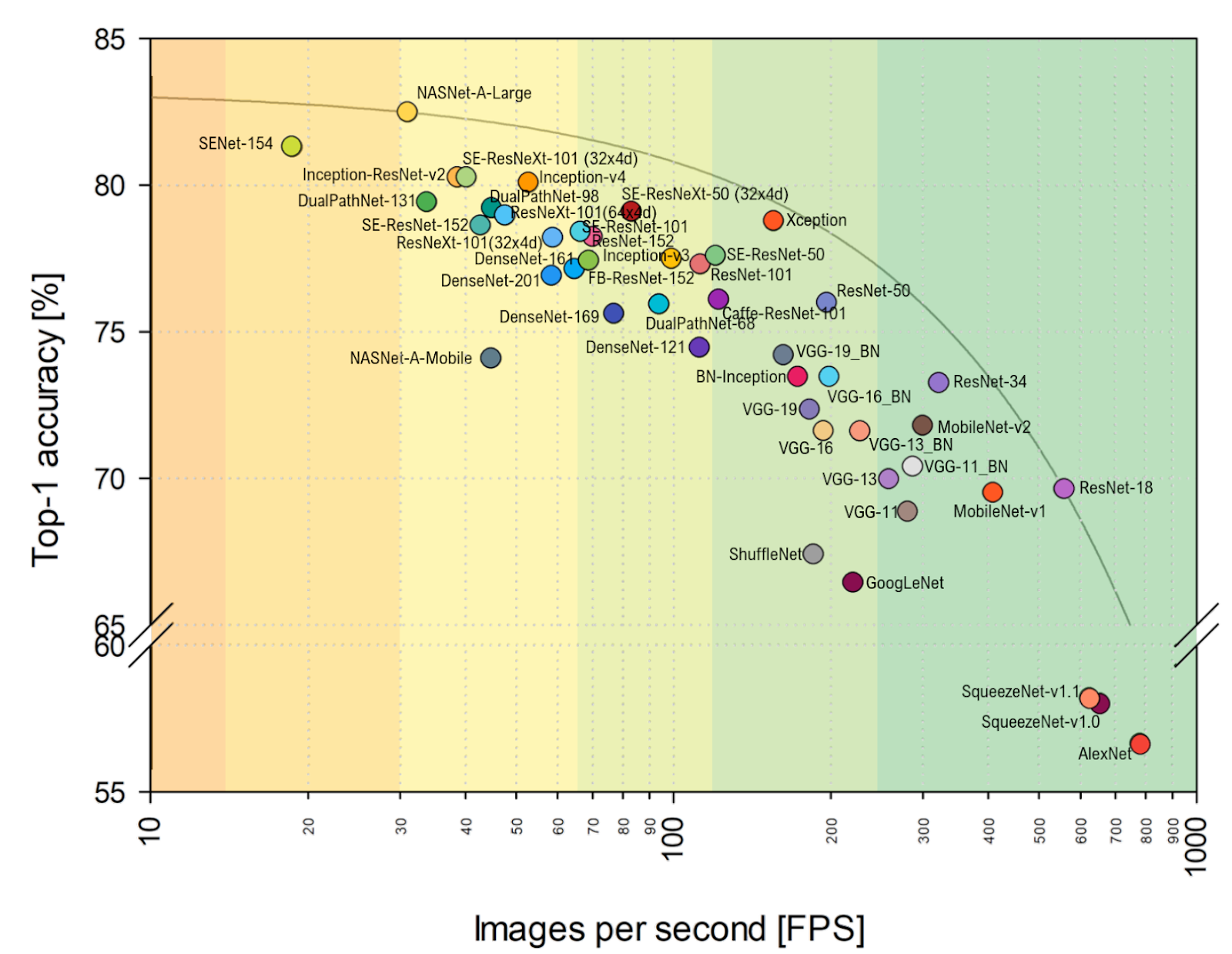 Sumber: Analisis Benchmark Arsitektur Perwakilan Deep Neural NetworkTotal:
Sumber: Analisis Benchmark Arsitektur Perwakilan Deep Neural NetworkTotal:
- Di tahun-tahun mendatang, penyelarasan arsitektur dengan probabilitas tinggi akan berubah sangat signifikan karena kemajuan akselerator jaringan saraf , ketika beberapa arsitektur pergi ke keranjang dan beberapa tiba-tiba lepas landas, hanya karena lebih baik meletakkan pada perangkat keras baru. Misalnya, dalam artikel yang disebutkan , perbandingan dibuat pada NVIDIA Titan X Pascal dan papan NVIDIA Jetson TX1, dan tata letak berubah secara nyata. Apalagi kemajuan TPU, NPU dan lainnya baru saja dimulai.
- Sebagai seorang praktisi, saya tidak dapat tidak melihat bahwa perbandingan pada ImageNet dilakukan secara default pada ImageNet-1k, dan bukan pada ImageNet-22k, hanya karena sebagian besar melatih jaringan mereka di ImageNet-1k, di mana ada 22 kali lebih sedikit kelas (ini keduanya lebih mudah dan lebih cepat). Beralih ke ImageNet-22k, yang lebih relevan untuk banyak aplikasi praktis, juga akan mengubah perataan (bagi mereka yang diasah oleh 1k - banyak).
Lebih dalam dalam Teknologi dan Arsitektur
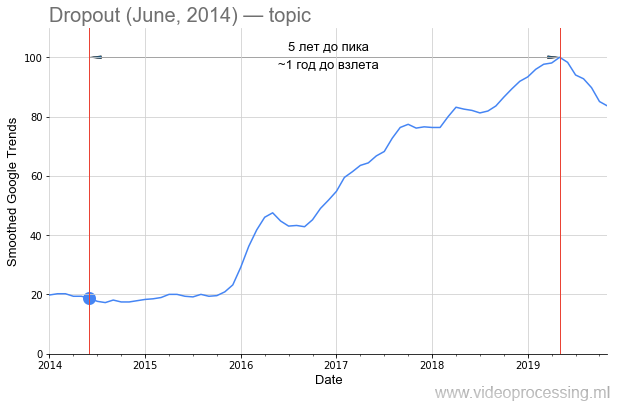
Namun, kembali ke teknologinya. Istilah
Dropout sebagai kata pencarian cukup berisik, tetapi pertumbuhan 5 kali lipat jelas terkait dengan jaringan saraf. Dan penurunan minat di dalamnya kemungkinan besar dengan
paten Google dan munculnya metode baru. Harap dicatat bahwa sekitar satu setengah tahun telah berlalu dari publikasi
artikel asli ke lonjakan minat dalam metode ini:
Namun, jika kita berbicara tentang periode sebelum kenaikan popularitas, maka di DL salah satu tempat pertama jelas diambil oleh
jaringan berulang dan
LSTM :
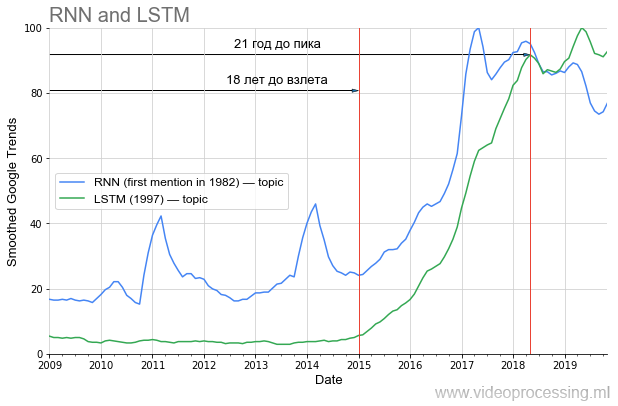
Jauh 20 tahun sebelum puncak popularitas saat ini, dan sekarang, dengan penggunaannya, terjemahan mesin, analisis genom telah ditingkatkan secara radikal, dan dalam waktu dekat (jika Anda mengambil dari daerah saya), YouTube, lalu lintas Netflix akan turun dua kali dengan kualitas visual yang sama. Jika Anda dengan benar mempelajari pelajaran sejarah, jelas bahwa sebagian gagasan dari poros artikel saat ini akan "lepas landas" hanya setelah 20 tahun. Pimpin gaya hidup sehat, jaga dirimu, dan kamu akan melihatnya secara pribadi!
Sekarang lebih dekat dengan sensasi yang dijanjikan.
GAN lepas landas seperti ini:
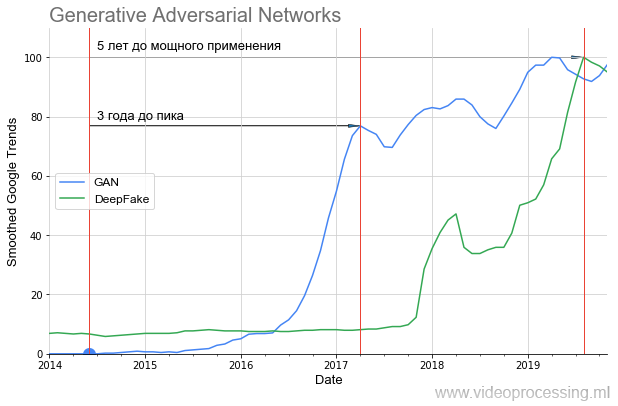
Dapat dilihat dengan jelas bahwa selama hampir satu tahun ada keheningan sama sekali dan hanya pada tahun 2016, setelah 2 tahun, peningkatan yang tajam dimulai (hasilnya terlihat membaik). Lepas landas ini setahun kemudian memberi DeepFake sensasional, yang, bagaimanapun, juga lepas landas 1,5 tahun. Artinya, bahkan teknologi yang sangat menjanjikan memerlukan sejumlah besar waktu untuk beralih dari sebuah ide ke aplikasi yang dapat digunakan semua orang.
Jika Anda melihat gambar apa yang dihasilkan oleh GAN di
artikel asli dan apa yang bisa dibuat dengan
StyleGAN , menjadi sangat jelas mengapa ada keheningan seperti itu. Pada tahun 2014, hanya spesialis yang dapat mengevaluasi betapa kerennya itu - untuk membuat, pada dasarnya, jaringan lain sebagai fungsi yang hilang dan melatih mereka bersama. Dan pada tahun 2019, setiap anak sekolah dapat menghargai betapa kerennya hal ini (tanpa sepenuhnya memahami bagaimana hal ini dilakukan):

Ada
banyak masalah berbeda yang berhasil diselesaikan oleh jaringan saraf hari ini, Anda dapat mengambil jaringan terbaik dan membangun grafik popularitas untuk setiap arah, menangani kebisingan dan puncak permintaan pencarian, dll. Agar tidak menyebarkan pemikiran saya pada pohon, kami akan mengakhiri seleksi ini dengan topik algoritma segmentasi, di mana ide-ide dari
konvolusi yang meluas / melebar dan
ASPP dalam satu setengah tahun terakhir telah cukup
untuk diri mereka sendiri
dalam tolok ukur algoritma :
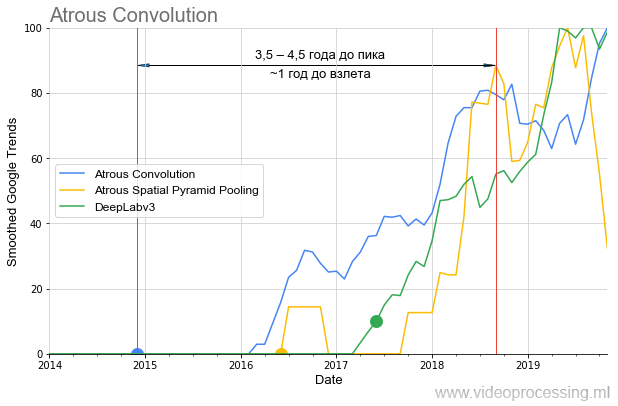
Perlu juga dicatat bahwa jika
DeepLabv1 lebih dari satu tahun "menunggu" untuk kenaikan popularitas, maka
DeepLabv2 lepas landas dalam setahun, dan
DeepLabv3 segera. Yaitu secara umum, kita dapat berbicara tentang mempercepat pertumbuhan minat dari waktu ke waktu (baik, atau mempercepat pertumbuhan minat pada teknologi penulis terkemuka).
Semua ini bersama-sama menyebabkan terciptanya masalah global berikut - peningkatan eksplosif dalam jumlah publikasi pada topik:
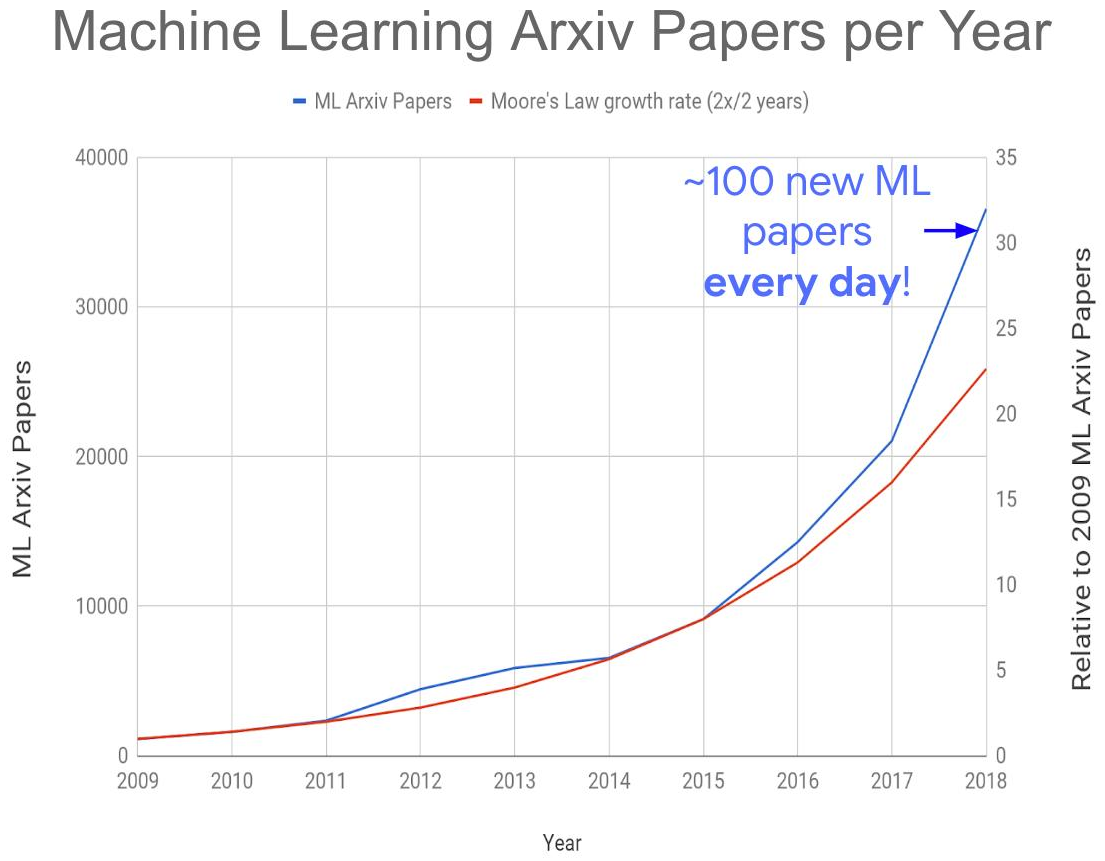 Sumber: Terlalu banyak makalah pembelajaran mesin?
Sumber: Terlalu banyak makalah pembelajaran mesin?Tahun ini kami mendapatkan sekitar 150-200 artikel per hari, mengingat tidak semua dipublikasikan di arXiv-e. Membaca artikel bahkan di sub-area mereka sendiri saat ini sama sekali tidak mungkin. Akibatnya, banyak ide menarik pasti akan terkubur di bawah puing-puing publikasi baru, yang akan mempengaruhi waktu "take-off" mereka. Namun, juga peningkatan
eksplosif dalam jumlah spesialis kompeten yang dipekerjakan di wilayah tersebut memberikan
sedikit harapan untuk mengatasi masalah tersebut.
Total:
- Selain ImageNet dan kisah di balik layar tentang kesuksesan gaming DeepMind, GAN memunculkan gelombang baru popularisasi jaringan saraf. Dengan mereka, sangat mungkin untuk "menembak" aktor tanpa menggunakan kamera . Dan apakah akan ada lebih banyak! Di bawah kebisingan informasional ini, teknologi pemrosesan dan pengenalan yang kurang nyaring, namun cukup bekerja akan dibiayai.
- Karena ada terlalu banyak publikasi, kami menantikan munculnya metode jaringan saraf baru untuk analisis cepat artikel, karena hanya mereka yang akan menyelamatkan kita (lelucon dengan sebagian kecil dari lelucon!).
Robot kerja, sobat
Selama 2 tahun sekarang, AutoML telah mendapatkan popularitas
dari halaman surat kabar . Semuanya dimulai secara tradisional dengan ImageNet, di mana, dalam Top-1 Accuracy, ia mulai dengan kuat mengambil tempat pertama:
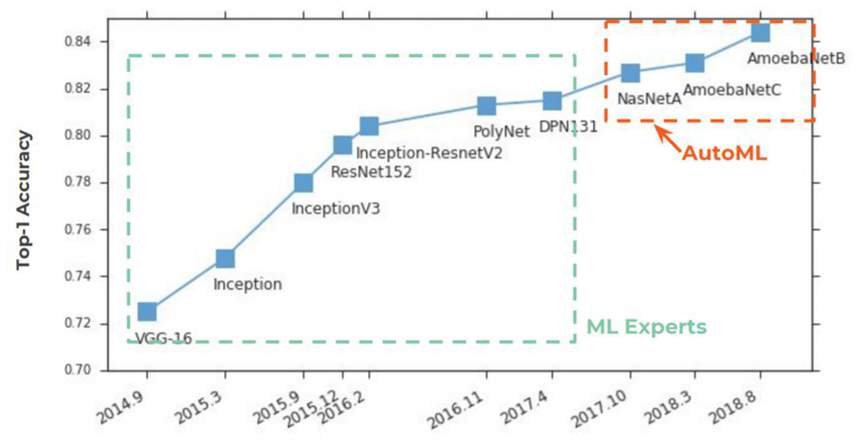
Inti dari AutoML sangat sederhana, impian para ilmuwan data yang telah berusia seabad telah terwujud di dalamnya - untuk jaringan saraf untuk memilih parameter hiper. Idenya disambut dengan keras:
Di bawah ini pada grafik kita melihat situasi yang agak langka ketika, setelah publikasi artikel awal di
NASNet dan
AmoebaNet , mereka mulai mendapatkan popularitas dengan standar gagasan sebelumnya hampir secara instan (minat besar pada topik terpengaruh):
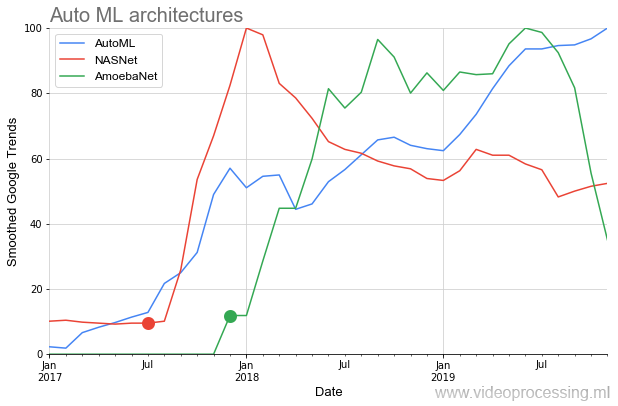
Gambaran idilis agak dimanjakan oleh dua poin. Pertama, setiap percakapan tentang AutoML dimulai dengan frasa: "Jika Anda memiliki dofigalion GPU ...". Dan itu masalahnya. Google, tentu saja, mengklaim bahwa dengan
Cloud AutoML mereka ini mudah diselesaikan, yang
utama adalah Anda punya cukup uang , tetapi tidak semua orang setuju dengan pendekatan ini. Kedua, itu bekerja sejauh ini
tidak sempurna . Di sisi lain, mengingat GAN, lima tahun belum berlalu, dan idenya sendiri terlihat sangat menjanjikan.
Bagaimanapun, lepas landas utama AutoML akan dimulai dengan akselerator perangkat keras generasi berikutnya untuk jaringan saraf dan, pada kenyataannya, dengan peningkatan algoritma.
 Sumber: Gambar oleh Dmitry Konovalchuk, bahan penulisTotal: Faktanya, para ilmuwan data tidak akan memiliki liburan abadi, tentu saja, karena untuk waktu yang sangat lama akan tetap ada sakit kepala besar dengan data. Tetapi sebelum Tahun Baru dan awal tahun 2020-an, mengapa tidak bermimpi?
Sumber: Gambar oleh Dmitry Konovalchuk, bahan penulisTotal: Faktanya, para ilmuwan data tidak akan memiliki liburan abadi, tentu saja, karena untuk waktu yang sangat lama akan tetap ada sakit kepala besar dengan data. Tetapi sebelum Tahun Baru dan awal tahun 2020-an, mengapa tidak bermimpi?Beberapa kata tentang alat
Efektivitas penelitian sangat tergantung pada alat. Jika untuk memprogram AlexNet, Anda memerlukan pemrograman non-sepele, hari ini jaringan seperti itu dapat dikumpulkan dalam beberapa baris dalam kerangka kerja baru.
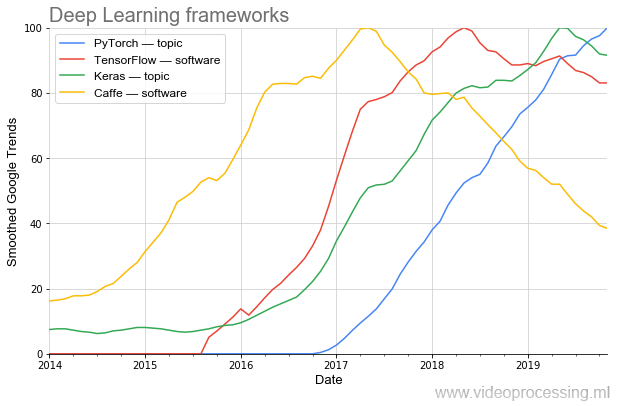
Terlihat jelas bagaimana popularitas berubah dalam gelombang. Saat ini, yang paling populer (termasuk
menurut PapersWithCode ) adalah
PyTorch . Dan begitu
Caffe populer dengan indah meninggalkannya dengan sangat lancar. (Catatan: topik dan perangkat lunak berarti bahwa pemfilteran topik Google digunakan saat merencanakan.)
Nah, karena kami menyentuh alat pengembangan, perlu disebutkan perpustakaan untuk mempercepat eksekusi jaringan:
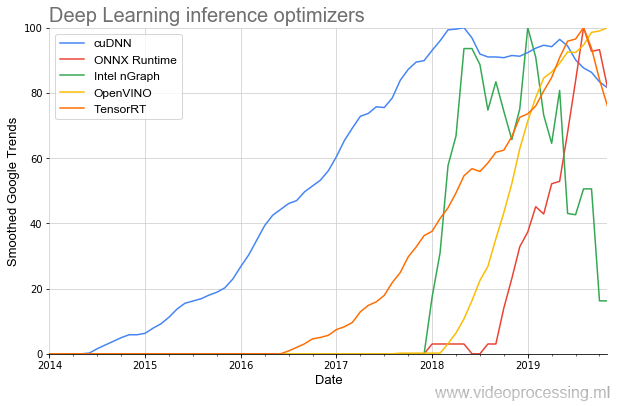
Yang tertua dalam topik ini adalah (menghormati NVIDIA)
cuDNN , dan, untungnya bagi pengembang, selama beberapa tahun terakhir jumlah perpustakaan telah meningkat beberapa kali, dan awal popularitas mereka telah menjadi lebih curam. Dan tampaknya semua ini hanyalah permulaan.
Total: Bahkan selama 3 tahun terakhir, alat telah berubah secara serius menjadi lebih baik. Dan 3 tahun yang lalu, menurut standar hari ini, mereka sama sekali tidak. Kemajuannya sangat bagus!Prospek Neural Network yang Dijanjikan
Tapi kesenangan dimulai kemudian. Musim panas ini, dalam sebuah
artikel besar yang terpisah, saya menjelaskan secara terperinci mengapa CPU dan bahkan GPU tidak cukup efisien untuk bekerja dengan jaringan saraf, mengapa miliaran dolar mengalir ke pengembangan chip baru, dan bagaimana prospeknya. Saya tidak akan mengulangi lagi. Di bawah ini adalah generalisasi dan penambahan teks sebelumnya.
Untuk memulainya, Anda perlu memahami perbedaan antara perhitungan jaringan saraf dan perhitungan dalam arsitektur von Neumann yang sudah dikenal (di mana mereka tentu saja dapat dihitung, tetapi kurang efisien):
 Sumber: Gambar oleh Dmitry Konovalchuk, bahan penulis
Sumber: Gambar oleh Dmitry Konovalchuk, bahan penulisWaktu sebelumnya, diskusi utama berlangsung di sekitar FPGA / ASIC, dan perhitungan yang tidak akurat hampir tidak diperhatikan, jadi mari kita membahasnya lebih detail. Prospek besar untuk mengurangi chip generasi berikutnya adalah tepatnya dalam kemampuan membaca yang tidak akurat (dan menyimpan data koefisien secara lokal). Pengerasan, pada kenyataannya, juga digunakan dalam aritmatika yang tepat, ketika bobot jaringan dikonversi menjadi bilangan bulat dan dikuantisasi, tetapi pada tingkat yang baru. Sebagai contoh, pertimbangkan penambah bit tunggal (contohnya cukup abstrak):
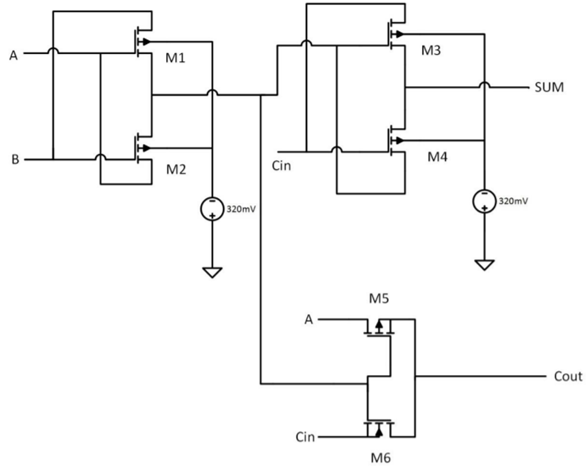 Sumber: Desain Kecepatan Tinggi dan Daya Rendah 8 Bit x 8 Bit Pengganda menggunakan Novel Two Transistor (2T) XOR Gates
Sumber: Desain Kecepatan Tinggi dan Daya Rendah 8 Bit x 8 Bit Pengganda menggunakan Novel Two Transistor (2T) XOR GatesIa membutuhkan 6 transistor (ada pendekatan yang berbeda, jumlah transistor yang dibutuhkan bisa semakin banyak, tetapi secara umum, sesuatu seperti ini). Untuk 8 bit, diperlukan sekitar
48 transistor . Dalam hal ini, penambah analog hanya membutuhkan 2 (dua!) Transistor, yaitu 24 kali lebih sedikit:
 Sumber: Pengganda Analog (Analisis dan Desain Sirkuit Terpadu Analog)
Sumber: Pengganda Analog (Analisis dan Desain Sirkuit Terpadu Analog)Jika akurasinya lebih tinggi (misalnya, setara dengan digital 10 atau 16 bit), perbedaannya akan lebih besar. Yang lebih menarik adalah situasi dengan multiplikasi! Jika multiplexer 8-bit digital membutuhkan sekitar
400 transistor , maka analog 6, yaitu 67 kali (!) Lebih sedikit. Tentu saja, transistor "analog" dan "digital" secara signifikan berbeda dari sudut pandang sirkuit, tetapi idenya jelas - jika kita berhasil meningkatkan keakuratan perhitungan analog, maka kita dengan mudah mencapai situasi ketika kita membutuhkan dua kali lipat transistor kurang besar. Dan intinya tidak begitu banyak dalam mengurangi ukuran (yang penting sehubungan dengan "perlambatan hukum Moore"), tetapi dalam mengurangi konsumsi listrik, yang sangat penting untuk platform seluler. Dan untuk pusat data itu tidak akan berlebihan.
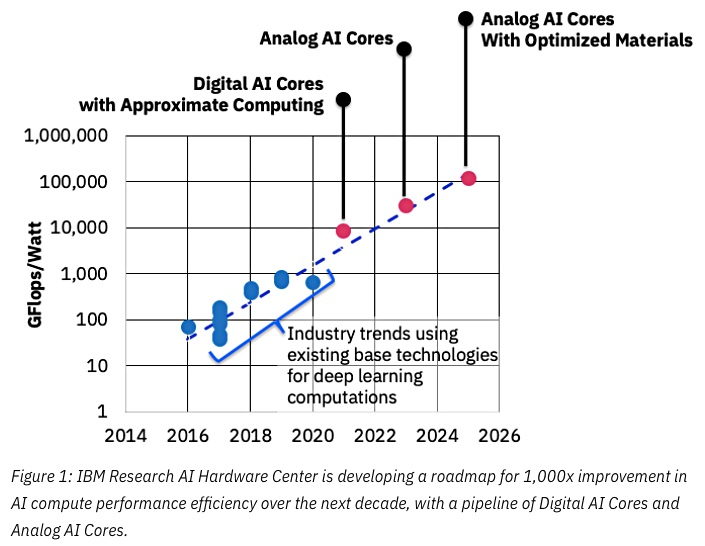 Sumber: IBM berpikir chip analog untuk mempercepat pembelajaran mesin
Sumber: IBM berpikir chip analog untuk mempercepat pembelajaran mesinKunci keberhasilan di sini adalah pengurangan akurasi, dan sekali lagi di sini IBM berada di garis depan:
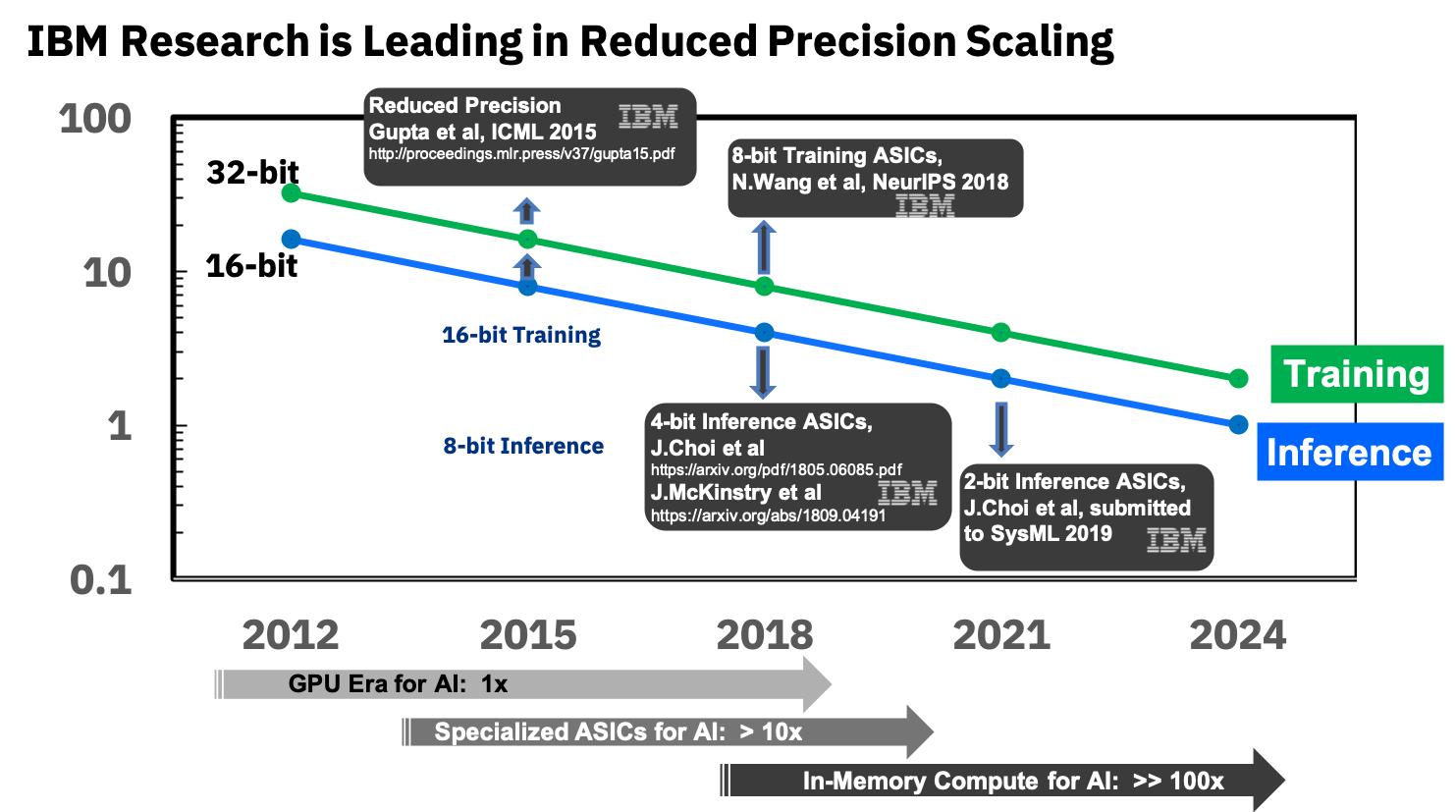 Sumber: IBM Research Blog: Presisi 8-Bit untuk Pelatihan Sistem Pembelajaran Mendalam
Sumber: IBM Research Blog: Presisi 8-Bit untuk Pelatihan Sistem Pembelajaran MendalamMereka sudah terlibat dalam ASIC khusus untuk jaringan saraf, yang menunjukkan keunggulan lebih dari 10 kali lipat dari GPU, dan berencana untuk mencapai keunggulan 100 kali lipat di tahun-tahun mendatang. Terlihat sangat menggembirakan, kami sangat menantikannya, karena, saya ulangi, ini akan menjadi terobosan untuk perangkat seluler.
Sementara itu, situasinya tidak begitu ajaib, meskipun ada keberhasilan yang serius. Berikut ini adalah tes menarik dari akselerator perangkat keras mobile saat ini dari jaringan saraf (gambar dapat diklik, dan itu lagi menghangatkan jiwa penulis, juga dalam gambar per detik):
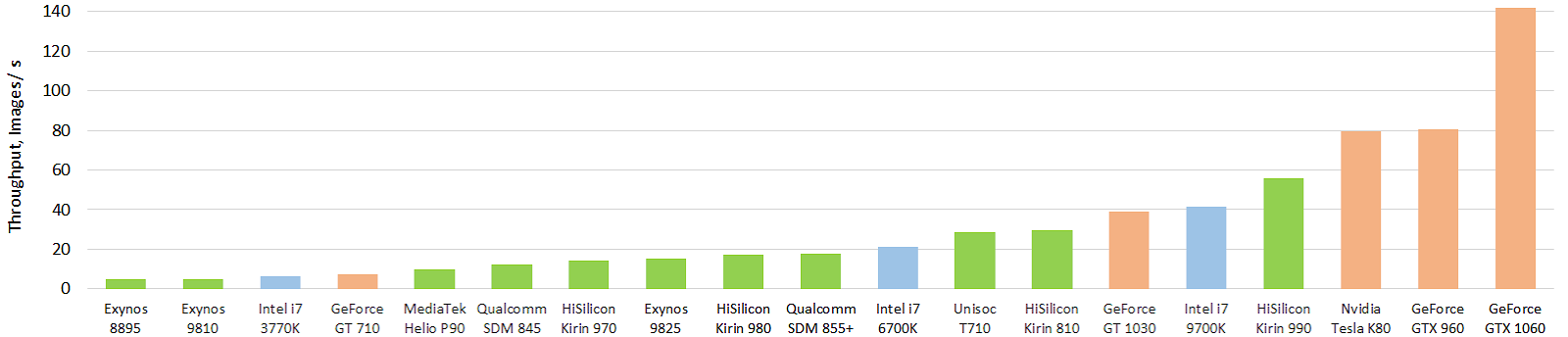 Sumber: Evolusi kinerja akselerator AI seluler: throughput gambar untuk model float Inception-V3 (model FP16 menggunakan TensorFlow Lite dan NNAPI)
Sumber: Evolusi kinerja akselerator AI seluler: throughput gambar untuk model float Inception-V3 (model FP16 menggunakan TensorFlow Lite dan NNAPI)Hijau menunjukkan chip ponsel, biru menunjukkan CPU, oranye menunjukkan GPU. Jelas terlihat bahwa chip mobile saat ini, dan pertama-tama, chip top-end dari Huawei, sudah menyalip CPU puluhan kali lebih besar dalam ukuran (dan konsumsi daya). Dan itu kuat! Dengan GPU, sejauh ini semuanya tidak begitu ajaib, tetapi akan ada sesuatu yang lain. Anda dapat melihat hasilnya secara lebih rinci di situs web terpisah
http://ai-benchmark.com/ , perhatikan bagian tes di sana, mereka memilih serangkaian algoritma yang baik untuk perbandingan.
Total: Kemajuan akselerator analog saat ini cukup sulit untuk dievaluasi. Ada sebuah perlombaan. Tapi produknya belum keluar, jadi ada relatif sedikit publikasi. Anda dapat memantau paten yang muncul dengan penundaan (misalnya, aliran padat dari IBM ) atau menangkap paten langka dari produsen lain. Tampaknya ini akan menjadi revolusi yang sangat serius, terutama di smartphone dan server TPU.Alih-alih sebuah kesimpulan
ML / DL hari ini disebut teknologi pemrograman baru, ketika kita tidak menulis suatu program, tetapi menyisipkan blok dan melatihnya. Yaitu Seperti pada awalnya ada assembler, lalu C, lalu C ++, dan sekarang, setelah menunggu selama 30 tahun, langkah selanjutnya adalah ML / DL:
Itu masuk akal. Baru-baru ini, di perusahaan maju, tempat pengambilan keputusan dalam program digantikan oleh jaringan saraf. Yaitu « IF-» (!) , 3-5 . , , . ,
, , , , , . -!
, . , - , : « , !»
, , , , (, !) . : « , !» , . «» « !» ( ). . !
, ML/DL — , . :
- — ,
- — ,
- — ,
- 8K 2K — ,
- , — ,
- 10 ,
- — ,
- — - — ,
- — ! )

Hanya 4 tahun telah berlalu sejak orang belajar untuk melatih jaringan saraf yang sangat dalam dalam banyak hal berkat BatchNorm (2015) dan melewatkan koneksi (2015), dan 3 tahun telah berlalu sejak mereka "lepas landas", dan kami benar-benar membaca hasil pekerjaan mereka tidak melihat. Dan sekarang mereka akan mencapai produk. Sesuatu memberi tahu kita bahwa di tahun-tahun mendatang banyak hal menarik menunggu kita. Terutama ketika akselerator "lepas landas" ...

Sekali waktu, jika ada yang ingat, Prometheus mencuri api dari Olympus dan menyerahkannya kepada orang-orang. Marah Zeus dengan dewa-dewa lain menciptakan keindahan pertama seorang wanita-pria bernama Pandora, yang diberkahi dengan banyak kualitas wanita yang luar biasa
(tiba-tiba saya menyadari bahwa menceritakan kembali secara benar beberapa mitos Yunani Kuno sangat sulit) . Pandora dikirim ke orang-orang, tetapi Prometheus, yang curiga ada yang salah, menolak mantranya, dan saudaranya Epimetheus tidak. Sebagai hadiah untuk pernikahan, Zeus mengirim peti mati yang indah bersama Merkurius dan Merkurius, jiwa yang baik hati, memenuhi perintah - ia memberikan peti mati itu ke Epimetheus, tetapi memperingatkannya untuk tidak membukanya dalam hal apa pun. Penasaran Pandora mencuri peti mati dari suaminya, membukanya, tetapi hanya ada dosa, penyakit, perang dan masalah umat manusia lainnya. Dia mencoba menutup peti mati, tetapi sudah terlambat:
 Sumber: Gereja Artis Frederick Stuart, Kotak Terbuka Pandora
Sumber: Gereja Artis Frederick Stuart, Kotak Terbuka PandoraSejak saat itu, frasa "buka kotak Pandora" telah hilang, yaitu,
karena ingin tahu merupakan tindakan yang tidak dapat diubah, konsekuensinya mungkin tidak seindah dekorasi peti mati di luar.
Anda tahu, semakin dalam saya menyelam ke dalam jaringan saraf, yang lebih berbeda adalah perasaan bahwa ini adalah kotak Pandora yang lain. Namun, umat manusia memiliki pengalaman terkaya dalam membuka kotak seperti itu! Dari baru-baru ini - ini adalah energi nuklir dan Internet. Jadi, saya pikir kita bisa mengatasi bersama. Tidak heran jika sekelompok pria
berjanggut kasar di antara para pembuka. Nah, peti mati itu indah, setuju! Dan itu tidak benar bahwa hanya ada masalah, mereka sudah punya banyak hal baik. Karena itu, mereka berkumpul dan ... kita buka lebih jauh!
Total:
- Artikel itu tidak memasukkan banyak topik menarik, misalnya, algoritma ML klasik, transfer pembelajaran, pembelajaran penguatan, popularitas dataset, dll. (Tuan-tuan, Anda dapat melanjutkan topik!)
- Untuk pertanyaan tentang peti mati: Saya pribadi berpikir bahwa programmer Google yang memungkinkan Google untuk meninggalkan kontrak $ 10 miliar dengan Pentagon adalah hebat dan tampan. Mereka menghormati dan menghormati. Namun, perhatikan bahwa seseorang memenangkan tender besar ini.
Baca juga:
- Akselerasi perangkat keras jaringan saraf dalam: GPU, FPGA, ASIC, TPU, VPU, IPU, DPU, NPU, RPU, NNP, dan surat lainnya - teks penulis tentang keadaan saat ini dan prospek akselerasi perangkat keras jaringan saraf dibandingkan dengan pendekatan saat ini.
- Deep Fake Science, krisis reproduktifitas dan dari mana repositori kosong berasal - tentang masalah dalam sains yang dihasilkan oleh ML / DL.
- Perbandingan codec jalan ajaib. Kami mengungkapkan rahasia - contoh palsu yang didasarkan pada jaringan saraf.
Semua banyak penemuan baru yang menarik di tahun 2020 secara umum dan di Tahun Baru, khususnya!
Ucapan Terima Kasih
Saya ingin mengucapkan terima kasih:
- Laboratorium Grafik Komputer dan Multimedia VMK Moscow State University M.V. Lomonosov atas kontribusinya pada pengembangan pembelajaran mendalam di Rusia dan tidak hanya
- secara pribadi Konstantin Kozhemyakov dan Dmitry Konovalchuk, yang melakukan banyak hal untuk membuat artikel ini lebih baik dan lebih visual,
- dan akhirnya, terima kasih banyak kepada Kirill Malyshev, Yegor Sklyarov, Nikolai Oplachko, Andrey Moskalenko, Ivan Molodetsky, Evgeny Lyapustin, Roman Kazantsev, Alexander Yakovenko, dan Dmitry Klepikov atas banyak komentar dan koreksi bermanfaat yang membuat teks ini jauh lebih baik!