
Sebelum Anda lagi, tugas mendeteksi objek. Prioritas - kecepatan dengan akurasi yang dapat diterima. Anda mengambil arsitektur YOLOv3 dan melatihnya. Akurasi (mAp75) lebih besar dari 0,95. Namun kecepatan lari masih rendah. Neraka
Hari ini kita akan melewati kuantisasi. Dan di bawah potongan, pertimbangkan Model Pruning - memangkas bagian jaringan yang berlebihan untuk mempercepat Inferensi tanpa kehilangan keakuratan. Secara visual - di mana, berapa banyak dan cara memotong. Mari kita cari tahu cara melakukannya secara manual dan di mana Anda dapat mengotomatisasi. Pada akhirnya adalah repositori di keras.
Pendahuluan
Di tempat kerja terakhir, Perm Macroscop, saya punya satu kebiasaan - selalu memantau waktu eksekusi algoritma. Dan waktu menjalankan jaringan harus selalu diperiksa melalui filter kecukupan. Biasanya state-of-the-art di prod tidak lulus filter ini, yang membuat saya ke Pruning.
Pemangkasan adalah tema lama yang dibicarakan di kuliah Stanford 2017. Gagasan utamanya adalah mengurangi ukuran jaringan terlatih tanpa kehilangan keakuratan dengan menghapus berbagai node. Kedengarannya keren, tapi saya jarang mendengar tentang penggunaannya. Mungkin, tidak ada implementasi yang cukup, tidak ada artikel berbahasa Rusia, atau hanya semua orang menganggap pemangkasan pengetahuan dan diam.
Tapi pergi bongkar
Pandangan tentang biologi
Saya suka ketika di Deep Learning ide-ide berasal dari biologi. Mereka, seperti evolusi, dapat dipercaya (tahukah Anda bahwa ReLU sangat mirip dengan fungsi mengaktifkan neuron di otak ?)
Proses Pemangkasan Model juga dekat dengan biologi. Respons jaringan di sini dapat dibandingkan dengan plastisitas otak. Beberapa contoh menarik ada dalam buku Norman Dodge :
- Otak seorang wanita yang hanya memiliki separuh dari kelahiran memprogram ulang dirinya untuk melakukan fungsi-fungsi setengah yang hilang
- Pria itu menembak dirinya sendiri bagian otak yang bertanggung jawab untuk penglihatan. Seiring waktu, bagian otak lain mengambil alih fungsi-fungsi ini. (jangan coba lagi)
Jadi dari model Anda, Anda dapat memotong beberapa bundel yang lemah. Dalam kasus ekstrim, bundel yang tersisa akan membantu menggantikan yang dipotong.
Apakah Anda suka Transfer Learning atau belajar dari awal?
Opsi nomor satu. Anda menggunakan Transfer Learning di Yolov3. Retina, Mask-RCNN atau U-Net. Tetapi lebih sering daripada tidak, kita tidak perlu mengenali 80 kelas objek, seperti pada COCO. Dalam latihan saya, semuanya terbatas pada 1-2 kelas. Dapat diasumsikan bahwa arsitektur untuk 80 kelas berlebihan di sini. Ini memunculkan pemikiran bahwa arsitektur perlu dikurangi. Selain itu, saya ingin melakukan ini tanpa kehilangan bobot pra-pelatihan yang ada.
Opsi nomor dua. Mungkin Anda memiliki banyak data dan sumber daya komputasi, atau Anda hanya perlu arsitektur super-kustom. Itu tidak masalah. Tetapi Anda mempelajari jaringan dari awal. Urutan yang biasa adalah untuk melihat struktur data, pilih arsitektur yang MENGURANGI kekuatan dan mendorong dropout dari pelatihan ulang. Saya melihat putus 0,6, Carl.
Dalam kedua kasus, jaringan dapat dikurangi. Dipromosikan. Sekarang mari kita cari tahu seperti apa sunat pemangkasan
Algoritma umum
Kami memutuskan bahwa kami dapat menghapus konvolusi. Ini terlihat sangat sederhana:
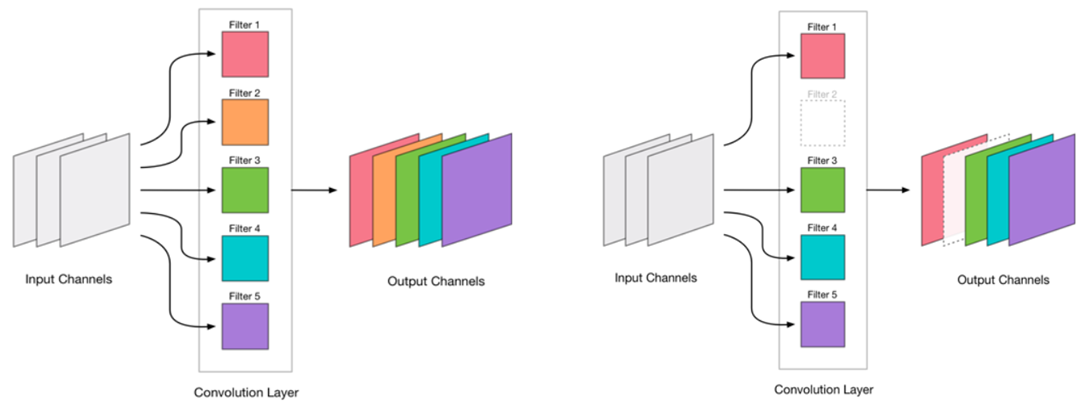
Menghapus konvolusi adalah tekanan untuk jaringan, yang biasanya menyebabkan peningkatan kesalahan. Di satu sisi, pertumbuhan kesalahan ini merupakan indikator seberapa benar kita menghapus konvolusi (misalnya, pertumbuhan besar menunjukkan bahwa kita melakukan sesuatu yang salah). Tetapi pertumbuhan kecil cukup dapat diterima dan sering dihilangkan dengan pelatihan selanjutnya yang mudah dengan LR kecil. Kami menambahkan langkah pelatihan ulang:
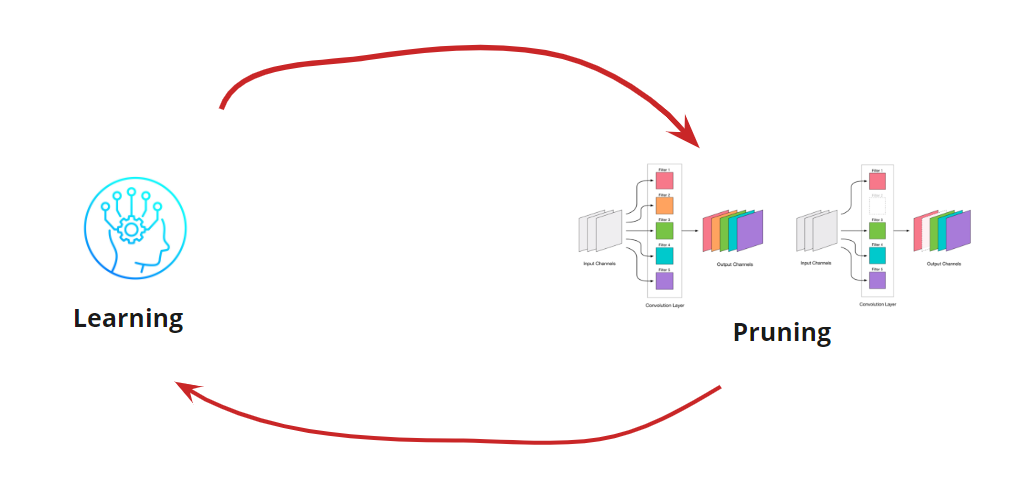
Sekarang kita perlu memahami kapan kita ingin menghentikan Pembelajaran kita <-> Siklus Pemangkasan. Mungkin ada opsi eksotis ketika kita perlu mengurangi jaringan ke ukuran dan kecepatan tertentu (misalnya, untuk perangkat seluler). Namun, opsi yang paling umum adalah melanjutkan siklus sampai kesalahan menjadi lebih tinggi dari yang diizinkan. Tambahkan kondisi:
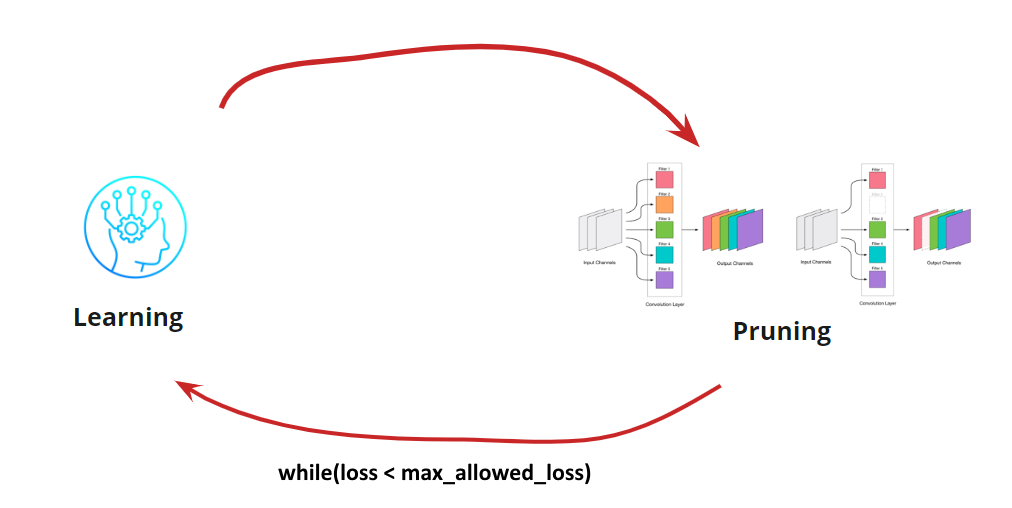
Jadi, algoritma menjadi jelas. Masih harus dibongkar cara menentukan konvolusi yang dihapus.
Cari konvolusi untuk dihapus
Kami perlu menghapus beberapa konvolusi. Merobek ke depan dan "menembak mati" adalah ide yang buruk, meskipun itu akan berhasil. Tetapi jika Anda memiliki kepala, Anda dapat berpikir dan mencoba memilih konvolusi “lemah” untuk dihapus. Ada beberapa opsi:
- Ukuran L1 terkecil atau low_magnitude_pruning . Gagasan bahwa konvolusi dengan bobot kecil memberikan kontribusi kecil pada keputusan akhir
- Pengukuran L1 terkecil dengan memperhitungkan simpangan rata-rata dan standar. Kami melengkapi penilaian sifat distribusi.
- Masking convolutions dan menghilangkan yang paling sedikit mempengaruhi akurasi yang dihasilkan . Definisi yang lebih akurat tentang konvolusi tidak signifikan, tetapi sangat memakan waktu dan sumber daya intensif.
- Lainnya
Setiap opsi memiliki hak untuk hidup dan fitur implementasinya sendiri. Di sini kami mempertimbangkan varian dengan ukuran L1 terkecil
Proses manual untuk YOLOv3
Arsitektur asli berisi blok residu. Tetapi tidak peduli seberapa kerennya mereka untuk jaringan yang dalam, mereka akan agak menghalangi kita. Kesulitannya adalah Anda tidak dapat menghapus rekonsiliasi dengan indeks berbeda di lapisan ini:

Oleh karena itu, kami memilih lapisan dari mana kami dapat dengan bebas menghapus rekonsiliasi:
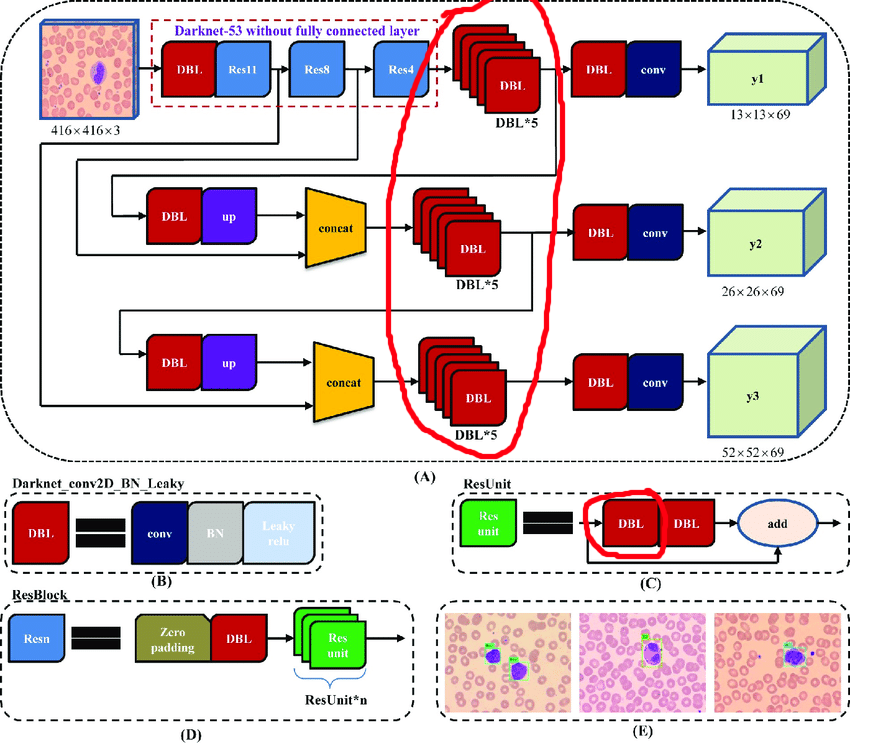
Sekarang mari kita membangun siklus kerja:
- Bongkar aktivasi
- Kami bertanya-tanya berapa banyak yang harus dipotong
- Hentikan
- Pelajari 10 era dengan LR = 1e-4
- Pengujian
Membongkar konvolusi berguna untuk mengevaluasi bagian mana yang dapat kita hapus pada langkah tertentu. Bongkar contoh:

Kami melihat bahwa hampir di mana-mana 5% konvolusi memiliki norma L1 yang sangat rendah dan kami dapat menghapusnya. Pada setiap langkah, pembongkaran seperti itu diulangi dan dilakukan penilaian lapisan mana dan berapa banyak yang bisa dipotong.
Seluruh proses diselesaikan dalam 4 langkah (di sini dan di mana-mana nomor untuk RTX 2060 Super):
Untuk langkah 2, satu efek positif ditambahkan - patch-size 4 masuk ke memori, yang sangat mempercepat proses pelatihan ulang.
Pada langkah 4, proses dihentikan, karena bahkan pendidikan lanjutan yang berkepanjangan tidak meningkatkan nilai mAp75 ke nilai lama.
Hasilnya, kami berhasil mempercepat inferensi sebesar 15% , mengurangi ukuran sebesar 35% dan tidak kehilangan keakuratannya.
Otomatisasi untuk arsitektur yang lebih sederhana
Untuk arsitektur jaringan yang lebih sederhana (tanpa blok tambahan bersyarat, konaternat, dan residual), sangat mungkin untuk fokus pada pemrosesan semua lapisan konvolusional dan mengotomatiskan proses pemotongan konvolusi.
Saya telah menerapkan opsi ini di sini .
Sederhana: Anda hanya memiliki fungsi kehilangan, pengoptimal, dan generator kumpulan:
import pruning from keras.optimizers import Adam from keras.utils import Sequence train_batch_generator = BatchGenerator... score_batch_generator = BatchGenerator... opt = Adam(lr=1e-4) pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt) pruner.prune(train_batch, valid_batch)
Jika perlu, Anda dapat mengubah parameter konfigurasi:
{ "input_model_path": "model.h5", "output_model_path": "model_pruned.h5", "finetuning_epochs": 10, # the number of epochs for train between pruning steps "stop_loss": 0.1, # loss for stopping process "pruning_percent_step": 0.05, # part of convs for delete on every pruning step "pruning_standart_deviation_part": 0.2 # shift for limit pruning part }
Selain itu, pembatasan berdasarkan standar deviasi diterapkan. Tujuannya adalah membatasi sebagian yang dihapus, tidak termasuk konvolusi dengan ukuran L1 yang sudah "cukup":
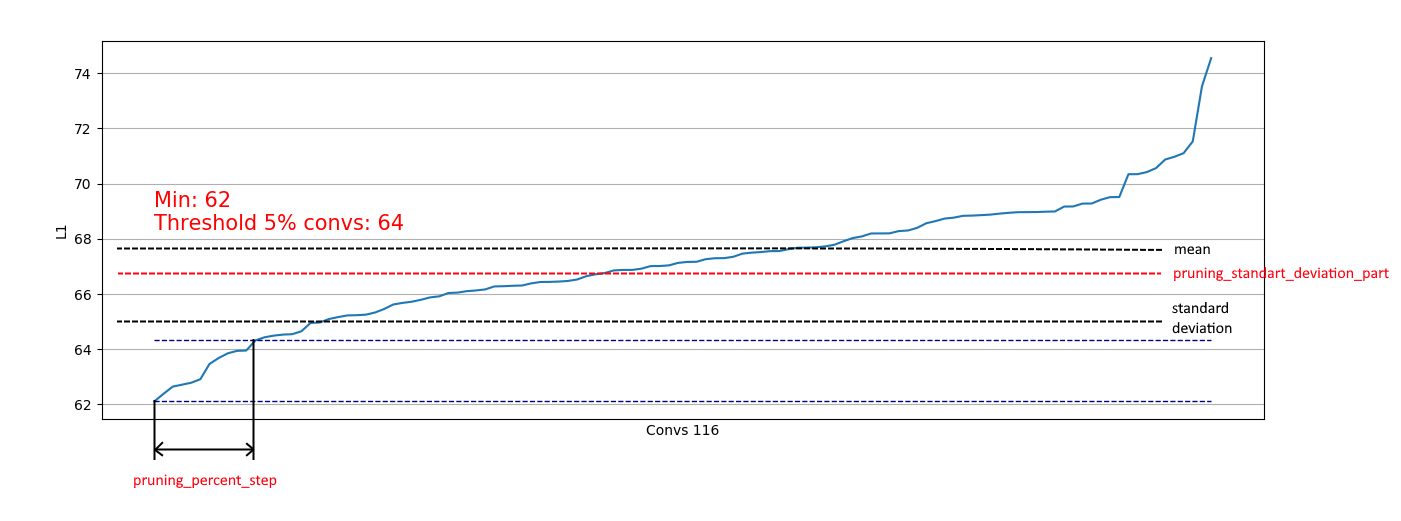
Dengan demikian, kami hanya dapat menghapus konvolusi lemah dari distribusi yang mirip dengan kanan dan tidak memengaruhi penghapusan dari distribusi seperti kiri:

Ketika distribusi mendekati normal, koefisien pruning_standart_deviation_part dapat dipilih dari:

Saya merekomendasikan asumsi 2 sigma. Atau Anda tidak dapat fokus pada fitur ini, meninggalkan nilai <1.0.
Outputnya adalah grafik ukuran jaringan, kehilangan dan waktu menjalankan jaringan untuk seluruh tes, dinormalisasi ke 1.0. Misalnya, di sini ukuran jaringan berkurang hampir 2 kali tanpa kehilangan kualitas (jaringan konvolusi kecil untuk bobot 100rb):
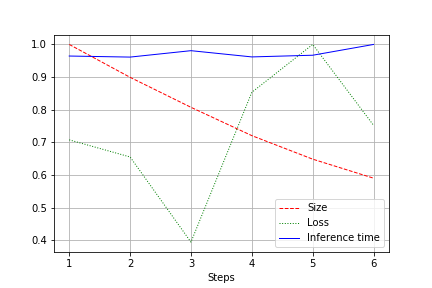
Kecepatan lari tunduk pada fluktuasi normal dan tidak banyak berubah. Ada penjelasan untuk ini:
- Jumlah konvolusi berubah dari nyaman (32, 64, 128) menjadi tidak nyaman untuk kartu video - 27, 51, dll. Di sini saya bisa salah, tetapi kemungkinan besar itu mempengaruhi.
- Arsitekturnya tidak luas, tetapi konsisten. Mengurangi lebar, kita tidak menyentuh kedalaman. Jadi, kami mengurangi beban, tetapi tidak mengubah kecepatan.
Oleh karena itu, peningkatan dinyatakan dalam penurunan beban CUDA selama menjalankan oleh 20-30%, tetapi tidak dalam penurunan dalam waktu berjalan
Ringkasan
Renungkan. Kami menganggap 2 opsi pemangkasan - untuk YOLOv3 (ketika Anda harus bekerja dengan tangan Anda) dan untuk jaringan dengan arsitektur lebih mudah. Dapat dilihat bahwa dalam kedua kasus ini dimungkinkan untuk mencapai pengurangan ukuran jaringan dan akselerasi tanpa kehilangan keakuratan. Hasil:
- Perampingan
- Jalankan akselerasi
- Pengurangan beban CUDA
- Akibatnya, ramah lingkungan (Kami mengoptimalkan penggunaan sumber daya komputasi di masa depan. Di suatu tempat Greta Tunberg bersukacita sendirian)
Lampiran
- Setelah langkah pemangkasan, Anda juga dapat memutar kuantisasi (misalnya, dengan TensorRT)
- Tensorflow menyediakan fitur untuk low_magnitude_pruning . Itu bekerja.
- Saya ingin mengembangkan repositori dan saya akan dengan senang hati membantu