Biasanya pada malam Tahun Baru kami memperbarui dataset kami pada semantik Terbuka. Banyak pekerjaan telah dilakukan tahun ini, tetapi belum sampai pada kesimpulan logisnya dan kami akan melanjutkannya tahun depan. Sekarang kami ingin berbicara tentang dataset terbuka yang sama pentingnya yang membangkitkan minat pada sejumlah konferensi linguistik tahun ini, baik pada bagian peneliti dan perwakilan industri. Posting ini akan fokus pada kamus nada terbuka bahasa Rusia.

Mengapa
Nada suara, atau dengan kata sederhana baik / buruk, adalah karakteristik alami dari kata-kata. Alami bagi manusia dan persepsi mereka, tetapi tidak untuk pemahaman komputer. Bahasa diatur sedemikian rupa sehingga mengandung simetri sehubungan dengan polaritas kata-kata dan tidak mungkin untuk memisahkan kata-kata baik dari yang buruk tanpa menggunakan tanda eksternal. Sebenarnya, awalnya tugas membuat kamus nada muncul dari kebutuhan untuk mengelompokkan daftar kata yang diterima secara otomatis oleh algoritma sesuai dengan polaritasnya.
Tentu saja, nada suara hanyalah salah satu aspek dari makna sebuah kata, dan pemahaman sentimen yang sebenarnya membutuhkan analisis semantik penuh, pemahaman tentang peran dalam situasi tertentu, dan pengetahuan tentang posisi yang ditempati oleh pengamat. Jadi, misalnya, "pengurangan harga saham" untuk pihak yang berbeda dapat memiliki nada suara yang berbeda, dan "biaya telah meningkat" dan "laba telah tumbuh" memiliki polaritas yang berbeda, meskipun pertumbuhan kata kerja digunakan dalam kedua frasa, yang memiliki peringkat yang agak positif (menurut dataset kami).
Ada beberapa alasan mengapa kami menghubungkan kata tertentu dengan kunci tertentu. Terkadang ini adalah sensasi langsung kita - sukacita dan kerinduan; terkadang kualitas seseorang - profesionalisme dan kecerobohan: dan terkadang konsep seperti pendidikan atau kewirausahaan terkait dengan lembaga sosial yang kompleks dan memberikan manfaat dalam jangka panjang. Dan penilaian kata-kata tersebut sangat terkait dengan budaya dan kontrak sosial. Dan, karenanya, mungkin tidak memiliki penilaian yang diakui secara universal dan universal.
Namun demikian, bahasa dan komunikasi tidak dapat ada jika sistem koordinat orang yang berbeda dalam budaya yang sama tidak memiliki kesamaan satu sama lain. Dan karena itu, untuk grup kata yang cukup besar, komponen perkiraan mereka kurang lebih konsisten.
Bagaimana?
Ada dua cara utama untuk mengumpulkan sejumlah besar data linguistik - menarik para ahli dan mewawancarai orang-orang (atau versi yang lebih modern dari yang terakhir - crowdsourcing). Kami tidak akan mengulangi tentang perbedaan yang jelas antara pendekatan ini, tetapi lebih memperhatikan mereka yang memiliki dampak langsung pada sifat-sifat dataset yang dihasilkan.
Penandaan pakar menyiratkan orientasi yang jelas untuk penggunaan masa depan, dan karenanya menetapkan metode pengambilan keputusan dalam situasi ambiguitas yang ditentukan oleh aplikasi ini. Untuk dataset final, ini berarti:
- fiksasi area subjek;
- definisi yang jelas tentang posisi pengamat.
Jadi, jika seorang pakar menyusun kamus nada untuk menganalisis berita yang ditargetkan pada khalayak luas, maka ia mengambil posisi sebagai pembaca umum dan mengasumsikan perjanjian tak terucapkan antara media dan pembaca. Katakanlah "pengurangan biaya" dalam instalasi seperti itu akan memiliki penilaian positif, dan "pertumbuhan tarif" - negatif (menurut dataset RusCentiLex-2017).
Crowdsourcing kehilangan kemungkinan menetapkan kerangka kerja seperti itu dan bukan alat yang optimal untuk memecahkan masalah terapan yang sangat terspesialisasi. Tapi itu memungkinkan kita untuk menangkap aspek penting lain dari penilaian nada suara - konsistensi antara responden. Beberapa kata akan dievaluasi secara ambigu sebagai positif atau negatif; beberapa akan membagi penilaian antara opsi netral dan kutub; dan sekelompok kecil kata akan menunjukkan ketidakkonsistenan peringkat.
Distribusi Konsistensi TingkatDi sebelah kiri pada grafik adalah konsistensi maksimum estimasi, di sebelah kanan adalah inkonsistensi maksimum.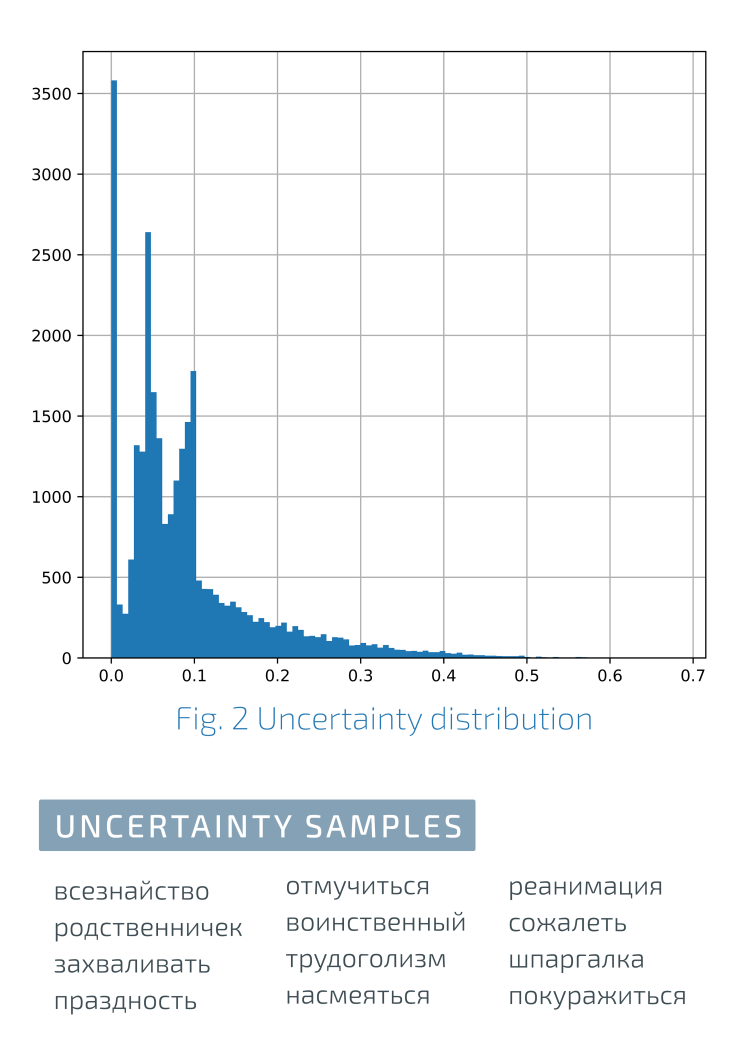
Selain itu, tidak seperti penilaian pakar, crowdsourcing memungkinkan Anda mendapatkan nilai polaritas terus menerus, membatasi kata-kata positif (negatif), agak positif (negatif), dan netral. Distribusi di antara kelompok-kelompok ini tentu saja tergantung pada nilai ambang yang dipilih. Namun, pengambilan sampel sepenuhnya opsional - dimungkinkan bagi sejumlah aplikasi nilai kontinu akan lebih nyaman.
Struktur dataset
Struktur dataset cukup sederhana: ini adalah kamus nada yang mencocokkan kata-kata dengan penilaian mereka dalam kisaran dari -1 (peringkat negatif marjinal) hingga +1 (peringkat positif marjinal). Untuk kenyamanan, tag yang dapat dibaca manusia dari rangkaian "positif", "netral", "negatif" yang dihitung menggunakan nilai ambang ditunjukkan.
Contoh kata-kata positif, netral dan negatif dari dataset- positif: dapat diandalkan, mendamaikan, kebaikan, pengampunan, hati nurani, mengambil inspirasi, fotogenik, untung, berkembang biak dengan baik, reuni, menginspirasi, kepercayaan, antusiasme, anak-anak, mengubah, kesehatan, pindah rumah, kenyamanan, masuk akal, beasiswa, sukarelawan;
- netral: singkatan, rasa, tongkat, tunik, polyhedron, sentuhan, furnitur, penduduk, klik, meleleh, penggunaan, melangkahi, jalan, bahan, mengempis, menekankan, lambang, tidur, berlengan panjang, tujuh, menggambar;
- negatif: bolos, kekek, blab, sandera, redneck, sombong, palsu, polusi, iri hati, mencekik, membekukan, menghambur-hamburkan, menghina, kecanduan, menggigit, masuk angin, menemukan kesalahan, takut, perampok, ignoramus;
Selain itu, dalam versi dataset ini (masih ada versi sebelumnya, pertama), data mentah diberikan - persentase suara yang diberikan untuk masing-masing opsi. Ini memungkinkan Anda untuk menerapkan model khusus untuk menghitung polaritas total dan tingkat konsistensi markup.
Catatan Versi dataset yang disajikan mencakup kata-kata OW yang paling dikenal (kosakata aktif); frasa tidak diberi label. Ketika membandingkan dengan kamus nada suara lainnya, kami menemukan sejumlah kata yang tersedia dalam kosakata aktif, tetapi tidak terwakili dalam kumpulan data kami. Kami akan melakukan markup lebih lanjut dan berencana untuk memasukkan unit bahasa yang hilang selama tahun depan.
Rencana selanjutnya
Menandai sentimen adalah salah satu tugas khusus dalam rangka studi tentang sistem bahasa semantik. Seperti yang kami sebutkan di atas, kegunaan set data yang disajikan secara langsung tergantung pada kemampuan untuk mengaitkan nilai-nilai polaritas yang disajikan di dalamnya dengan informasi semantik lainnya. Dengan kelas kata, misalnya. Kami memulai pekerjaan ini dan berencana untuk mengembangkannya di masa depan.
Bidang penelitian penting lainnya adalah keinginan untuk memahami alasan pewarnaan kata-kata tertentu, perkembangbiakan kata-kata yang berkaitan dengan perasaan, emosi dan penilaian langsung dan kata-kata itu di mana konsep atau situasi yang dijelaskan oleh mereka menjanjikan laba atau rugi yang tertunda. Oleh karena itu, kata-kata seperti itu lebih rentan terhadap pengaruh budaya dan sosial.
Juga direncanakan untuk memperluas markup dengan frasa, termasuk ekspresi stabil dan unit fraseologis. Tetapi di sini kita sudah berbicara tentang volume kosa kata yang sama sekali berbeda, sehingga tugas umumnya adalah memahami bagaimana sentimen bekerja pada tingkat yang lebih umum (lebih banyak di bawah spoiler).
Sentimen dan semantikSetelah meneliti lebih dekat, menjadi jelas bahwa bahasa beroperasi dengan serangkaian konsep yang relatif relatif terhadap jumlah kata dan kombinasinya, yang masing-masing dapat diekspresikan dalam lebih dari satu cara. Pengamatan ini tercermin secara rinci dalam karya-karya ahli bahasa Rusia dan dalam model Sense-Text yang mereka ciptakan.
Misalnya, "penurunan harga", "penurunan harga", "harga jatuh", "harga turun" - ini adalah cara yang berbeda untuk menggambarkan proses yang serupa, tetapi diungkapkan dengan berbagai cara bahasa. Pada saat yang sama, dalam konteks yang sama seseorang dapat memenuhi konsep lain yang memiliki ekspresi kuantitatif - "penurunan tingkat kepercayaan", "peningkatan tingkat pendapatan", dll. Dalam setiap kasus, cukup untuk memahami korespondensi di atas / di bawah ini - baik / buruk (tingkat pengetahuan dan dunia) dan dengan apa arti leksikal gerakan dalam arah yang diberikan diungkapkan (tingkat bahasa).
Umpan balik dan distribusi
Kami menyambut setiap umpan balik dalam komentar - dari kritik terhadap pekerjaan dan pendekatan kami hingga tautan ke studi yang menarik dan artikel terkait.
Jika Anda memiliki kenalan atau kolega yang mungkin tertarik dengan dataset yang diterbitkan, kirimkan tautan ke artikel atau tempat penyimpanan untuk membantu menyebarkan data terbuka.
Tautan ke dataset dan lisensi
Dataset: kamus nada terbuka bahasa RusiaKumpulan data adalah
28197 kata .
Dataset ini dilisensikan di bawah
CC BY-NC-SA 4.0 .
Tautan ke proyek terkait