Jaringan saraf telah berkembang dari keadaan keingintahuan akademik ke industri besar-besaran

Selama dekade terakhir, komputer telah secara signifikan meningkatkan kemampuan mereka untuk memahami dunia di sekitar mereka. Perangkat lunak untuk peralatan foto secara otomatis mengenali wajah orang. Ponsel cerdas mengkonversi ucapan ke teks. Robomobiles mengenali benda-benda di jalan dan menghindari tabrakan dengannya.
Inti dari semua terobosan ini adalah teknologi kecerdasan buatan (AI) yang disebut deep learning (GO). GO didasarkan pada jaringan saraf (NS), struktur data yang terinspirasi oleh jaringan yang terdiri dari neuron biologis. NS diatur dalam lapisan, dan input dari satu lapisan terhubung ke output dari tetangga.
Ilmuwan komputer telah bereksperimen dengan NS sejak 1950-an. Namun, dasar dari industri GO yang luas saat ini diletakkan oleh dua terobosan besar - satu terjadi pada tahun 1986, yang kedua pada tahun 2012. Terobosan tahun 2012 - revolusi GO - dikaitkan dengan penemuan bahwa penggunaan NS dengan sejumlah besar lapisan akan memungkinkan kami untuk meningkatkan efisiensi secara signifikan. Penemuan ini difasilitasi oleh meningkatnya volume data dan daya komputasi.
Dalam artikel ini kami akan memperkenalkan Anda ke dunia Majelis Nasional. Kami akan menjelaskan apa NS, bagaimana mereka bekerja dan dari mana mereka berasal. Dan kita akan mempelajari mengapa - meskipun telah dilakukan beberapa dekade penelitian sebelumnya - NS menjadi sesuatu yang sangat berguna hanya pada tahun 2012.
Jaringan saraf muncul kembali pada 1950-an
 Frank Rosenblatt sedang mengerjakan perceptronnya - model NS awal
Frank Rosenblatt sedang mengerjakan perceptronnya - model NS awalGagasan Majelis Nasional cukup lama - setidaknya dengan standar ilmu komputer. Kembali pada tahun 1957,
Frank Rosenblatt dari Cornell University menerbitkan
laporan yang menggambarkan konsep NS awal yang disebut perceptron. Pada tahun 1958, dengan dukungan Angkatan Laut AS, ia menciptakan sistem primitif yang mampu menganalisis 20x20 piksel dan mengenali bentuk geometris sederhana.
Tujuan utama Rosenblatt bukanlah menciptakan sistem klasifikasi gambar yang praktis. Dia mencoba memahami bagaimana otak manusia bekerja, menciptakan sistem komputer yang tertata dalam gambarnya. Namun, konsep ini telah menimbulkan antusiasme berlebihan dari pihak ketiga.
"Hari ini, Angkatan Laut AS telah mengungkapkan kepada dunia cikal bakal komputer elektronik yang diharapkan dapat berjalan, berbicara, melihat, menulis, mereproduksi dirinya sendiri dan menyadari keberadaannya," tulis The New York Times.
Faktanya, setiap neuron di NS hanyalah fungsi matematika. Setiap neuron menghitung jumlah data input yang berbobot - semakin besar bobot input, semakin kuat data input ini memengaruhi output neuron. Kemudian, jumlah tertimbang dimasukkan ke fungsi "aktivasi" nonlinier - pada langkah ini, NS dapat mensimulasikan fenomena nonlinier kompleks.
Kemampuan perceptrons awal yang Rosenblatt bereksperimen dengan - dan NS secara umum - berasal dari kemampuan mereka untuk "belajar" dengan contoh-contoh. NS dilatih melalui penyetelan bobot input neuron berdasarkan hasil jaringan dengan data input yang dipilih misalnya. Jika jaringan dengan benar mengklasifikasikan gambar, bobot yang berkontribusi pada peningkatan jawaban yang benar, sementara yang lain berkurang. Jika jaringan salah, bobot akan menyesuaikan ke arah lain.
Prosedur seperti itu memungkinkan NS awal untuk "belajar" dengan cara yang mengingatkan perilaku sistem saraf manusia. Hype seputar pendekatan ini tidak berhenti pada 1960-an. Namun, kemudian
buku 1969 yang
berpengaruh oleh penulis ilmuwan komputer Marvin Minsky dan Seymour Papert menunjukkan bahwa NA awal ini memiliki keterbatasan yang signifikan.
NS Rosenblatt awal hanya memiliki satu atau dua lapisan terlatih. Minsky dan Papert menunjukkan bahwa NSs secara matematis tidak mampu memodelkan fenomena kompleks dari dunia nyata.
Pada prinsipnya, NS yang lebih dalam lebih mampu. Namun, NS seperti itu akan melemahkan sumber daya komputasi yang menyedihkan yang dimiliki komputer pada waktu itu. Algoritma
pencarian ascending paling sederhana yang digunakan di NS pertama tidak mengukur untuk NS lebih dalam.
Akibatnya, Majelis Nasional kehilangan semua dukungan pada tahun 1970-an dan awal 1980-an - itu adalah bagian dari era "musim dingin AI".
Algoritma terobosan
 Jaringan saraf saya sendiri berdasarkan “soft equipment” percaya bahwa kemungkinan memiliki hot dog di foto ini adalah 1. Kita akan menjadi kaya!
Jaringan saraf saya sendiri berdasarkan “soft equipment” percaya bahwa kemungkinan memiliki hot dog di foto ini adalah 1. Kita akan menjadi kaya!Keberuntungan kembali ke NS berkat
karya terkenal
tahun 1986, yang memperkenalkan konsep propagasi balik - metode praktis mengajar NS.
Misalkan Anda bekerja sebagai programmer di perusahaan perangkat lunak imajiner, dan Anda telah diperintahkan untuk membuat aplikasi yang menentukan apakah ada hot dog di dalam gambar. Anda mulai bekerja dengan NS diinisialisasi secara acak, yang mengambil gambar input dan menghasilkan nilai dari 0 hingga 1 - di mana 1 berarti "hot dog" dan 0 berarti "bukan hot dog".
Untuk melatih jaringan, Anda mengumpulkan ribuan gambar, di bawah masing-masing terdapat label yang menunjukkan apakah ada hot dog pada gambar ini. Anda memberinya gambar pertama - dan ada hot dog di dalamnya - di jaringan saraf. Ini memberikan nilai output 0,07, yang berarti "tidak ada hot dog." Ini jawaban yang salah; jaringan seharusnya mengembalikan respons mendekati 1.
Tujuan dari algoritma backpropagation adalah untuk menyempurnakan bobot input sehingga jaringan menghasilkan nilai yang lebih tinggi jika diberikan lagi gambar ini - dan, lebih disukai, gambar lain di mana ada hot dog. Untuk ini, algoritma backpropagation dimulai dengan memeriksa neuron input dari lapisan output. Setiap nilai memiliki variabel bobot. Algoritma backpropagation menyesuaikan setiap bobot sedemikian rupa sehingga NS memberikan nilai yang lebih tinggi. Semakin tinggi nilai input, semakin berat bobotnya.
Sejauh ini, saya menggambarkan pendakian paling sederhana ke puncak yang akrab bagi para peneliti di tahun 1960-an. Terobosan backpropagation adalah langkah berikutnya: algoritma menggunakan turunan parsial untuk mendistribusikan "kesalahan" untuk output yang salah di antara input neuron. Algoritme menghitung bagaimana perubahan kecil dalam setiap nilai input akan mempengaruhi hasil akhir neuron, dan apakah perubahan ini akan memindahkan hasil lebih dekat ke jawaban yang benar, atau sebaliknya.
Hasilnya adalah satu set nilai kesalahan untuk setiap neuron di lapisan sebelumnya - pada kenyataannya, sinyal yang mengevaluasi apakah nilai masing-masing neuron terlalu besar atau terlalu kecil. Kemudian algoritma mengulangi proses tuning untuk neuron baru dari lapisan kedua [dari ujung]. Ini sedikit mengubah bobot input masing-masing neuron untuk mendorong jaringan lebih dekat ke jawaban yang benar.
Kemudian algoritma tersebut kembali menggunakan turunan parsial untuk menghitung bagaimana nilai setiap input dari lapisan sebelumnya memengaruhi kesalahan output dari lapisan ini - dan menyebarkan kesalahan ini kembali ke lapisan pra-sebelumnya, di mana proses berulang lagi.
Ini hanya model backpropagation yang disederhanakan. Jika Anda membutuhkan detail matematika terperinci, saya merekomendasikan buku Michael Nielsen tentang hal ini [
dan kami memiliki terjemahannya / kira-kira. diterjemahkan.]. Untuk tujuan kami, cukup bahwa distribusi terbalik secara radikal mengubah kisaran NS yang terlatih. Orang tidak lagi terbatas pada jaringan sederhana dengan satu atau dua lapisan. Mereka dapat membuat jaringan dengan lima, sepuluh, atau lima puluh lapisan, dan jaringan ini dapat memiliki struktur internal yang rumit.
Penemuan backpropagation meluncurkan boom kedua Majelis Nasional, yang mulai membuahkan hasil praktis. Pada tahun 1998, sekelompok peneliti dari AT&T menunjukkan bagaimana jaringan saraf dapat digunakan untuk mengenali angka tulisan tangan, yang memungkinkan untuk mengotomatisasi pemrosesan cek.
“Pesan utama dari pekerjaan ini adalah bahwa kita dapat menciptakan sistem yang lebih baik untuk mengenali pola, lebih mengandalkan pembelajaran otomatis dan lebih sedikit pada heuristik yang dikembangkan secara manual,” tulis para penulis.
Namun, dalam fase ini, NS hanya salah satu dari banyak teknologi yang tersedia bagi para peneliti pembelajaran mesin. Ketika saya belajar dalam kursus AI di institut pada tahun 2008, jaringan saraf hanya salah satu dari sembilan algoritma MO, dari mana kita bisa memilih opsi yang cocok untuk tugas tersebut. Namun, GO sudah bersiap untuk menaungi sisa teknologi.
Data besar menunjukkan kekuatan pembelajaran yang mendalam
 Relaksasi terdeteksi. Peluang pantai 1.0. Kami memulai prosedur menggunakan Mai Tai.
Relaksasi terdeteksi. Peluang pantai 1.0. Kami memulai prosedur menggunakan Mai Tai.Backpropagation memfasilitasi proses penghitungan NS, tetapi jaringan yang lebih dalam masih membutuhkan lebih banyak sumber daya komputasi daripada yang kecil. Hasil studi yang dilakukan pada 1990-an dan 2000-an sering menunjukkan bahwa adalah mungkin untuk mendapatkan semakin sedikit manfaat dari komplikasi tambahan NS.
Kemudian pemikiran orang-orang diubah oleh karya terkenal 2012, yang menggambarkan NS dengan nama AlexNet, dinamai menurut peneliti terkemuka Alex Krizhevsky. Sama seperti jaringan yang lebih dalam dapat memberikan efisiensi terobosan, tetapi hanya dalam kombinasi dengan banyak daya komputer dan sejumlah besar data.
AlexNet telah mengembangkan trio ilmuwan komputer dari University of Toronto untuk berpartisipasi dalam kompetisi sains ImageNet. Penyelenggara kontes mengumpulkan jutaan gambar di Internet, yang masing-masing diberi label dan ditugaskan ke salah satu dari ribuan kategori objek, misalnya, "ceri", "kapal kontainer" atau "macan tutul". Peneliti AI diminta untuk melatih program MO mereka pada bagian-bagian gambar ini, dan kemudian mencoba untuk menempatkan label yang benar untuk gambar lain yang belum pernah ditemukan oleh perangkat lunak sebelumnya. Perangkat lunak harus memilih lima label yang mungkin untuk setiap gambar, dan upaya itu dianggap berhasil jika salah satu dari mereka bertepatan dengan yang asli.
Ini adalah tugas yang sulit, dan hingga 2012 hasilnya tidak terlalu bagus. Untuk pemenang 2011, tingkat kesalahan adalah 25%.
Pada 2012, tim AlexNet mengungguli semua pesaing dengan memberikan jawaban dengan 15% kesalahan. Untuk pesaing terdekat, angka ini adalah 26%.
Para peneliti dari Toronto menggabungkan beberapa teknik untuk mencapai hasil terobosan. Salah satunya adalah penggunaan
neurosis konvolusional (SNS). Bahkan, SNA, seolah-olah, melatih jaringan saraf kecil - data inputnya adalah bujur sangkar dengan sisi 7-11 piksel - dan kemudian "menempatkannya" pada gambar yang lebih besar.
"Seolah-olah Anda mengambil template kecil atau stensil dan mencoba membandingkannya dengan setiap titik dalam gambar," kata peneliti AI Jie Tan kepada kami tahun lalu. - Anda memiliki stensil anjing, dan Anda menempelkannya pada gambar, dan melihat apakah ada anjing di sana? Jika tidak, pindahkan stensil. Dan untuk seluruh gambar. Dan di mana pun anjing itu muncul dalam gambar. Stensil akan bertepatan dengan itu. Setiap sub-jaringan tidak boleh menjadi penggolong anjing yang terpisah. ”
Faktor kunci kesuksesan lain untuk AlexNet adalah penggunaan kartu grafis untuk mempercepat proses pembelajaran. Kartu grafis memiliki kekuatan pemrosesan paralel, sangat cocok untuk komputasi berulang yang diperlukan untuk melatih jaringan saraf. Mentransfer beban komputasi ke sepasang GPU - Nvidia GTX 580, dengan memori masing-masing 3 GB - para peneliti dapat mengembangkan dan melatih jaringan yang sangat besar dan kompleks. AlexNet memiliki delapan lapisan yang bisa dilatih, 650.000 neuron, dan 60 juta parameter.
Akhirnya, kesuksesan AlexNet juga dipastikan oleh ukuran besar basis data gambar pelatihan dari ImageNet: satu juta lembar. Banyak gambar diperlukan untuk menyempurnakan 60 juta parameter. Untuk mencapai kemenangan yang menentukan, AlexNet dibantu oleh kombinasi jaringan yang kompleks dan kumpulan data yang besar.
Saya bertanya-tanya mengapa terobosan seperti itu tidak terjadi sebelumnya:
- Pasangan GPU kelas konsumen yang digunakan oleh peneliti AlexNet jauh dari perangkat komputasi paling kuat untuk 2012. Lima dan bahkan sepuluh tahun sebelumnya, ada komputer yang lebih kuat. Selain itu, teknologi akselerasi pembelajaran NS menggunakan kartu grafis telah dikenal setidaknya sejak tahun 2004.
- Basis satu juta gambar luar biasa besar untuk pengajaran algoritma MO pada 2012, namun, mengumpulkan data semacam itu bukanlah teknologi baru untuk tahun itu. Tim peneliti yang didanai dengan baik dapat dengan mudah mengumpulkan database dengan ukuran ini lima atau sepuluh tahun sebelumnya.
- Algoritma utama yang digunakan dalam AlexNet bukanlah hal baru. Algoritma backpropagation pada tahun 2012 sudah ada selama sekitar seperempat abad. Gagasan kunci terkait dengan jaringan saraf convolutional dikembangkan pada 1980-an dan 1990-an.
Jadi setiap elemen sukses dari AlexNet ada secara terpisah jauh sebelum terobosan terjadi. Jelas, tidak pernah terpikir oleh siapa pun untuk menggabungkan mereka - sebagian besar karena tidak ada yang tahu seberapa kuat kombinasi ini.
Meningkatkan kedalaman NS secara praktis tidak meningkatkan efisiensi pekerjaan mereka jika mereka tidak menggunakan set data pelatihan yang cukup besar. Dan memperluas set data tidak meningkatkan kinerja jaringan kecil. Untuk melihat peningkatan efisiensi, kami membutuhkan jaringan yang lebih dalam dan kumpulan data yang lebih besar - ditambah daya komputasi yang signifikan yang memungkinkan kami melakukan proses pelatihan dalam jumlah waktu yang wajar. Tim AlexNet adalah yang pertama untuk menyatukan ketiga elemen dalam satu program.
Booming pembelajaran yang mendalam

Demonstrasi dari semua kekuatan NS mendalam, yang disediakan oleh data pelatihan dalam jumlah yang cukup, diperhatikan oleh banyak orang - baik di kalangan ilmuwan, peneliti, dan di antara perwakilan industri.
Kontes ImageNet pertama yang berubah. Hingga 2012, sebagian besar kontestan menggunakan teknologi selain pembelajaran mendalam. Dalam kompetisi 2013, seperti yang ditulis sponsor, “mayoritas” kontestan menggunakan GO.
Persentase kesalahan di antara para pemenang secara bertahap menurun - dari 16% mengesankan di AlexNet pada 2012 menjadi 2,3% pada 2017:
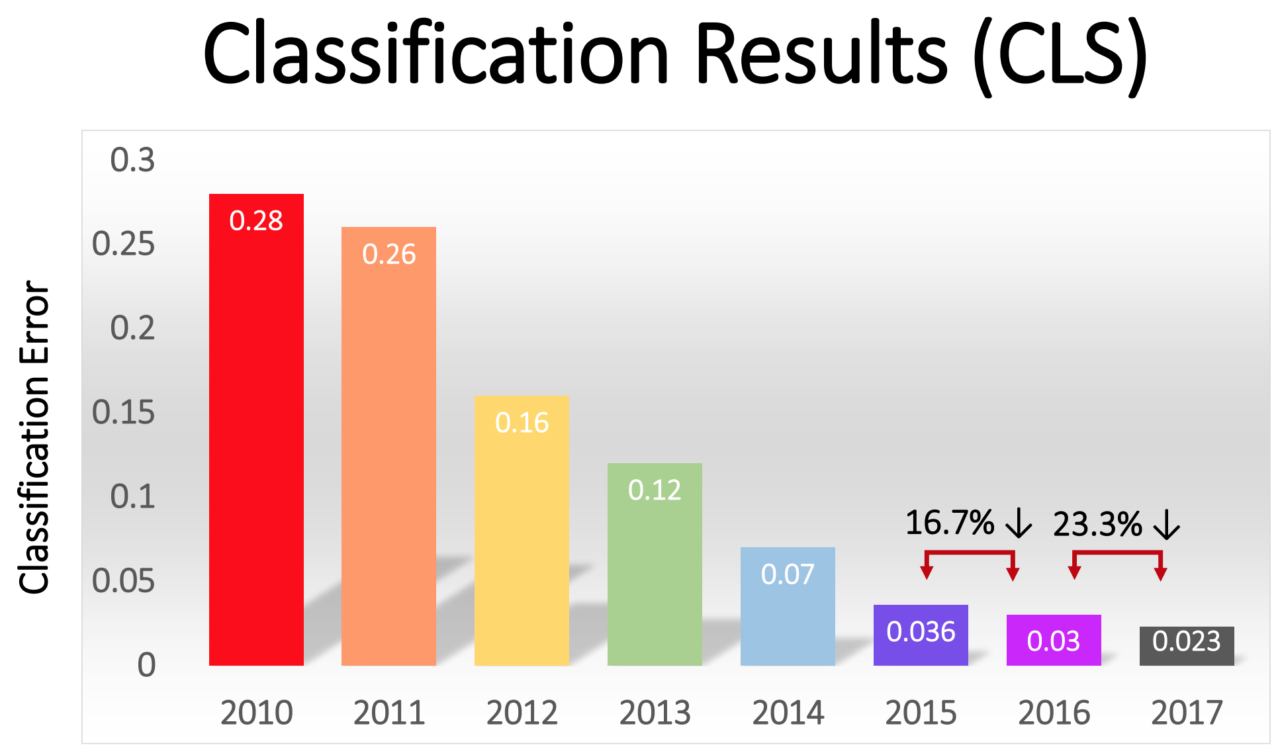
Revolusi GO dengan cepat menyebar ke seluruh industri. Pada 2013, Google mengakuisisi startup yang dibentuk dari penulis AlexNet, dan menggunakan teknologinya sebagai basis untuk fungsi pencarian gambar di Google Photos. Pada 2014, Facebook menggembar-gemborkan perangkat lunaknya sendiri yang mengenali gambar menggunakan GO. Apple telah menggunakan GO untuk pengenalan wajah di iOS sejak setidaknya 2016.
GO juga mendasari peningkatan baru-baru ini dalam teknologi pengenalan suara. Siri dari Apple, Alexa dari Amazon, Cortana dari Microsoft dan asisten Google menggunakan GO - baik untuk memahami kata-kata seseorang, atau untuk menghasilkan suara yang lebih alami, atau keduanya.
Dalam beberapa tahun terakhir, tren mandiri telah muncul di industri, di mana peningkatan daya komputasi, volume data, dan kedalaman jaringan saling mendukung. Tim AlexNet menggunakan GPU karena mereka menawarkan komputasi paralel dengan harga yang wajar. Tetapi selama beberapa tahun terakhir, semakin banyak perusahaan telah mulai mengembangkan chip mereka sendiri, yang dirancang khusus untuk digunakan di bidang MO.
Google mengumumkan rilis chip Tensor Processing Unit yang khusus dirancang untuk NS pada 2016. Pada tahun yang sama, Nvidia mengumumkan rilis GPU baru yang disebut Tesla P100, dioptimalkan untuk NS. Intel menjawab panggilan tersebut dengan chip AI-nya pada 2017. Pada 2018, Amazon mengumumkan rilis chip AI-nya sendiri, yang dapat digunakan sebagai bagian dari layanan cloud perusahaan. Bahkan Microsoft dikatakan bekerja pada chip AI-nya.
Pabrikan smartphone juga bekerja pada chip yang memungkinkan perangkat seluler melakukan lebih banyak komputasi menggunakan NS secara lokal, tanpa harus mengunggah data ke server. Komputasi seperti itu pada perangkat mengurangi latensi dan meningkatkan privasi.
Bahkan Tesla memasuki game ini dengan chip khusus. Tahun ini, Tesla menunjukkan komputer kuat baru, dioptimalkan untuk menghitung NS. Tesla menamakannya Full Self-Driving Computer dan menyajikannya sebagai momen kunci dalam strategi perusahaan untuk mengubah armada Tesla menjadi kendaraan robot.
Ketersediaan kapasitas komputer yang dioptimalkan untuk AI telah menghasilkan permintaan untuk data yang dibutuhkan untuk melatih NS yang semakin kompleks. Dinamika ini paling jelas di sektor robomobile, di mana perusahaan mengumpulkan data jutaan kilometer jalan nyata. Tesla dapat mengumpulkan data ini secara otomatis dari mobil pengguna, dan para pesaingnya, Waymo dan pengemudi berbayar Cruise yang mengendarai mobil mereka di jalan umum.

Permintaan data memberikan keuntungan bagi perusahaan online besar yang sudah memiliki akses ke data pengguna dalam volume besar.
Pembelajaran yang mendalam telah menaklukkan begitu banyak bidang yang berbeda karena fleksibilitasnya yang ekstrem. Dekade percobaan dan kesalahan telah memungkinkan para peneliti untuk mengembangkan blok bangunan dasar untuk tugas-tugas paling umum di bidang MO - seperti jaringan konvolusi untuk pengenalan gambar yang efisien. Namun, jika Anda memiliki jaringan tingkat tinggi yang cocok untuk skema dan data yang cukup, maka proses pelatihannya akan sederhana. Deep NSs mampu mengenali berbagai pola rumit yang luar biasa tanpa bimbingan khusus dari pengembang manusia.
Tentu saja ada batasan. Sebagai contoh, beberapa orang menuruti gagasan melatih robot mobil dengan hanya bantuan GO - yaitu, memberi makan gambar yang diterima dari kamera, jaringan saraf, dan menerima instruksi darinya untuk memutar setir dan pedal. Saya skeptis dengan pendekatan ini.
Majelis Nasional belum menunjukkan kemampuan untuk melakukan penalaran logis kompleks yang diperlukan untuk memahami kondisi tertentu yang muncul di jalan. Selain itu, NS adalah "kotak hitam", alur kerja yang praktis tidak terlihat. Akan sulit untuk mengevaluasi dan mengkonfirmasi keamanan sistem semacam itu.Namun, GO diizinkan untuk membuat lompatan yang sangat luas dalam sejumlah besar aplikasi yang tidak terduga. Di tahun-tahun mendatang, orang dapat mengharapkan kemajuan selanjutnya di bidang ini.