Halo semuanya. Di bawah ini adalah transkrip laporan dengan Pertemuan Besar Pengawasan 4 .
Prometheus adalah sistem pemantauan untuk berbagai sistem dan layanan, di mana administrator sistem dapat mengumpulkan informasi tentang parameter sistem saat ini dan mengonfigurasi peringatan untuk menerima pemberitahuan penyimpangan dalam pengoperasian sistem.
Laporan ini akan membandingkan Thanos dan VictoriaMetrics , proyek untuk penyimpanan jangka panjang metrik Prometheus.


Pertama, saya akan berbicara tentang Prometheus. Ini adalah sistem pemantauan yang mengumpulkan metrik dari target yang diberikan dan menyimpannya di penyimpanan lokal. Prometheus dapat menulis metrik ke repositori jarak jauh, dapat menghasilkan peringatan dan aturan perekaman.

Keterbatasan Prometheus:
- Itu tidak memiliki tampilan permintaan global. Ini terjadi ketika Anda memiliki beberapa contoh prometheus yang independen. Mereka mengumpulkan metrik. Dan Anda ingin mengajukan permintaan di atas semua metrik yang dikumpulkan dari berbagai contoh prometheus. Prometheus tidak mengizinkan ini.
- Dengan prometheus, kinerja dibatasi hanya untuk satu server. Prometheus tidak dapat secara otomatis mengukur ke beberapa server. Anda hanya dapat membagi target secara manual di antara banyak Prometheus.
- Volume metrik di Prometheus terbatas hanya untuk satu server karena alasan yang sama sehingga tidak dapat secara otomatis skala ke beberapa server.
- Di Prometheus, tidak mudah mengatur keamanan data.

Memecahkan masalah / tantangan ini?
Solusinya adalah:
Semua solusi penyimpanan jarak jauh ini dikumpulkan oleh Prometheus. Mereka memecahkan masalah penyimpanan jarak jauh dari slide sebelumnya dengan berbagai cara. Dalam presentasi ini, saya hanya akan berbicara tentang dua solusi pertama: Thanos dan VictoriaMetrics .
Untuk pertama kalinya, informasi tentang Thanos muncul di tautan ini . Ini menggambarkan arsitektur Thanos dan cara kerjanya.

Thanos mengambil data yang disimpan Prometheus ke disk lokal dan menyalinnya ke S3, ke GCS, atau ke penyimpanan objek lain.

Dengan cara ini, Thanos memberikan tampilan permintaan global. Anda dapat meminta data yang disimpan dalam penyimpanan objek dari beberapa instance Prometheus.

Thanos mendukung PromQL dan API permintaan Prometheus .

Thanos menggunakan kode Prometheus untuk menyimpan data.

Thanos sedang dikembangkan oleh pengembang yang sama dengan Prometheus.
Tentang VictoriaMetrics . Inilah tautan tempat kami pertama kali berbicara tentang VictoriaMetrics .

VictoriaMetrics menerima data dari beberapa prometheus melalui protokol API tulis jarak jauh yang didukung oleh Prometheus.
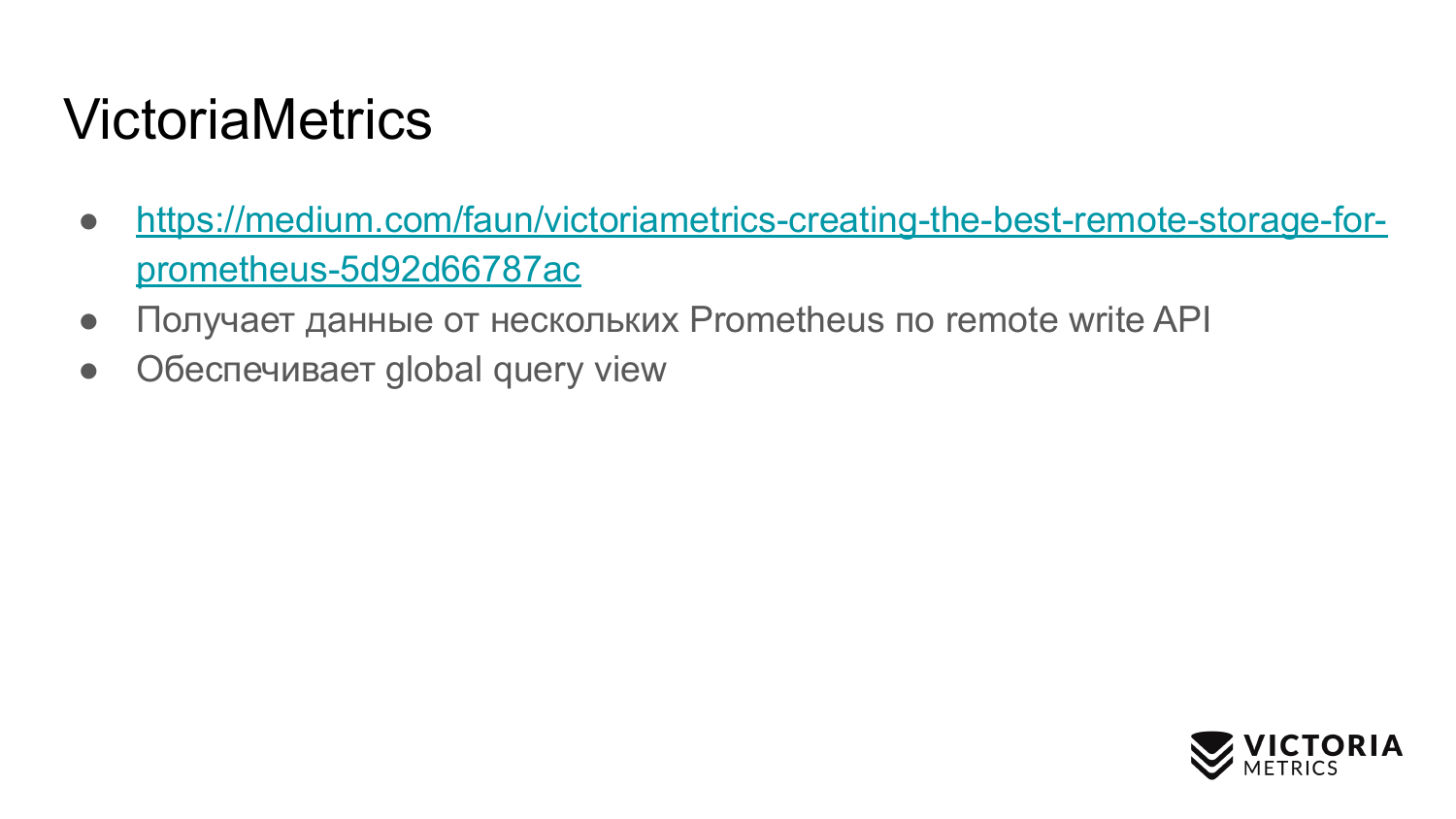
VictoriaMetrics menyediakan tampilan permintaan global, karena beberapa instance Prometheus dapat menulis data ke satu VictoriaMetrics. Dengan demikian, Anda dapat membuat permintaan untuk semua data ini.

VictoriaMetrics juga mendukung, seperti Thanos, PromQL, dan API kueri Prometheus.

Tidak seperti Thanos, kode sumber VictoriaMetrics ditulis dari awal dan dioptimalkan untuk kecepatan dan sumber daya.

VictoriaMetrics, tidak seperti Thanos, berskala secara vertikal dan horizontal. Ada versi Single-node yang skala secara vertikal. Anda dapat mulai dengan satu prosesor dan 1 GB memori dan secara bertahap tumbuh hingga ratusan prosesor dan 1TB memori. VictoriaMetrics dapat menggunakan semua sumber daya ini. Kinerjanya akan meningkat sekitar 100 kali dibandingkan dengan sistem single-core.

Sejarah Thanos dimulai pada November 2017, ketika komit publik pertama kali muncul. Sebelum ini, Thanos dikembangkan secara internal oleh improbable.io .

Pada Juni 2019, ada rilis penting 0,5.0, di mana protokol gosip dihapus . Dia dikeluarkan dari Thanos karena dia tidak melakukan yang terbaik. Seringkali cluster Thanos tidak berfungsi dengan benar, node terhubung dengan tidak benar karena protokol gosip. Karena itu, mereka memutuskan untuk menghapusnya dari sana. Saya pikir ini adalah keputusan yang tepat.

Juga pada Juni 2019, mereka mengirim nomor aplikasi 256 ke Cloud Native Computing Foundation .

Dan setelah beberapa bulan, Thanos bergabung dengan Cloud Native Computing Foundation , yang meliputi Prometheus, Kubernetes, dan proyek populer lainnya.

Pada Januari 2018, pengembangan VictoriaMetrics dimulai.

Pada bulan September 2018, saya pertama kali menyebutkan VictoriaMetrics di depan umum.

Pada bulan Desember 2018, versi Single-node diterbitkan.

Pada Mei 2019 , sumber - sumber Single-node dan versi cluster diterbitkan .

Pada Juni 2019, seperti halnya Thanos, kami mendaftar ke yayasan CNCF di nomor 255 . Kami melamar satu hari sebelum Thanos melamar.

Namun, sayangnya, kami masih belum diterima di sana. Butuh bantuan dari komunitas.

Pertimbangkan slide paling penting yang menunjukkan arsitektur Thanos dan VictoriaMetrics.

Mari kita mulai dengan Thanos. Komponen kuning adalah komponen Prometheus. Yang lainnya adalah komponen Thanos. Mari kita mulai dengan komponen yang paling penting. Thanos Sidecar adalah komponen yang dipasang di sebelah setiap Prometheus. Dia berkomitmen untuk memuat data Prometheus dari penyimpanan lokal ke S3 atau ke Penyimpanan Objek lain.
Ada juga komponen seperti Thanos Store Gateway, yang dapat membaca data ini dari Object Storage atas permintaan masuk dari Thanos Query. Kueri Thanos mengimplementasikan PromQL dan API Prometheus. Artinya, dari luar terlihat seperti Prometheus. Ia menerima permintaan PromQL, mengirimkannya ke Thanos Store Gateway, Thanos Store Gateway mengambil data yang diperlukan dari Object Storage, mengirimkannya kembali.
Tetapi kami telah menyimpan data di Object Storage tanpa dua jam terakhir karena kekhasan implementasi Thanos Sidecar, yang tidak dapat mengunggah dua jam terakhir ke Object Storage S3, karena selama dua jam ini Prometheus belum membuat file di penyimpanan lokal.
Bagaimana mereka memutuskan untuk mengatasi ini? Thanos Query, di samping permintaan dari Thanos Store Gateway, mengirimkan permintaan paralel ke setiap Thanos Sidecar yang terletak di sebelah Prometheus.
Dan Thanos Sidecar, pada gilirannya, proksi permintaan lebih lanjut di Prometheus, dan mendapatkan data selama dua jam terakhir.
Selain komponen-komponen ini, ada juga komponen opsional yang tanpanya Thanos tidak akan merasa sehat. Ini adalah Thanos Compact, yang menggabungkan file kecil di Object Storage menjadi file yang lebih besar yang telah diunggah di sini oleh Thanos Sidecar. Thanos Sidecar mengunggah file data di sana dalam dua jam. File-file ini, jika Anda tidak menggabungkannya menjadi file yang lebih besar, maka jumlahnya dapat tumbuh sangat signifikan. Semakin banyak file seperti itu, semakin banyak memori yang diperlukan untuk Thanos Store Gateway, semakin banyak sumber daya yang diperlukan untuk mentransfer data melalui jaringan, metadata. Gateway Thanos Store menjadi tidak efisien. Oleh karena itu, Anda harus menjalankan Thanos Compact, yang menggabungkan file kecil menjadi yang lebih besar sehingga ada lebih sedikit file seperti itu dan untuk mengurangi overhead pada Thanos Store Gateway.
Ada juga komponen seperti Thanos Ruler. Ini mengikuti aturan peringatan Prometheus dan dapat menghitung aturan rekaman Prometheus untuk menulis data kembali ke Object Storage. Tetapi komponen ini tidak direkomendasikan, karena dia cenderung mengembalikan data yang tidak lengkap .
Ini adalah skema sederhana untuk Thanos.
Sekarang bandingkan dengan skema VictoriaMetrics.
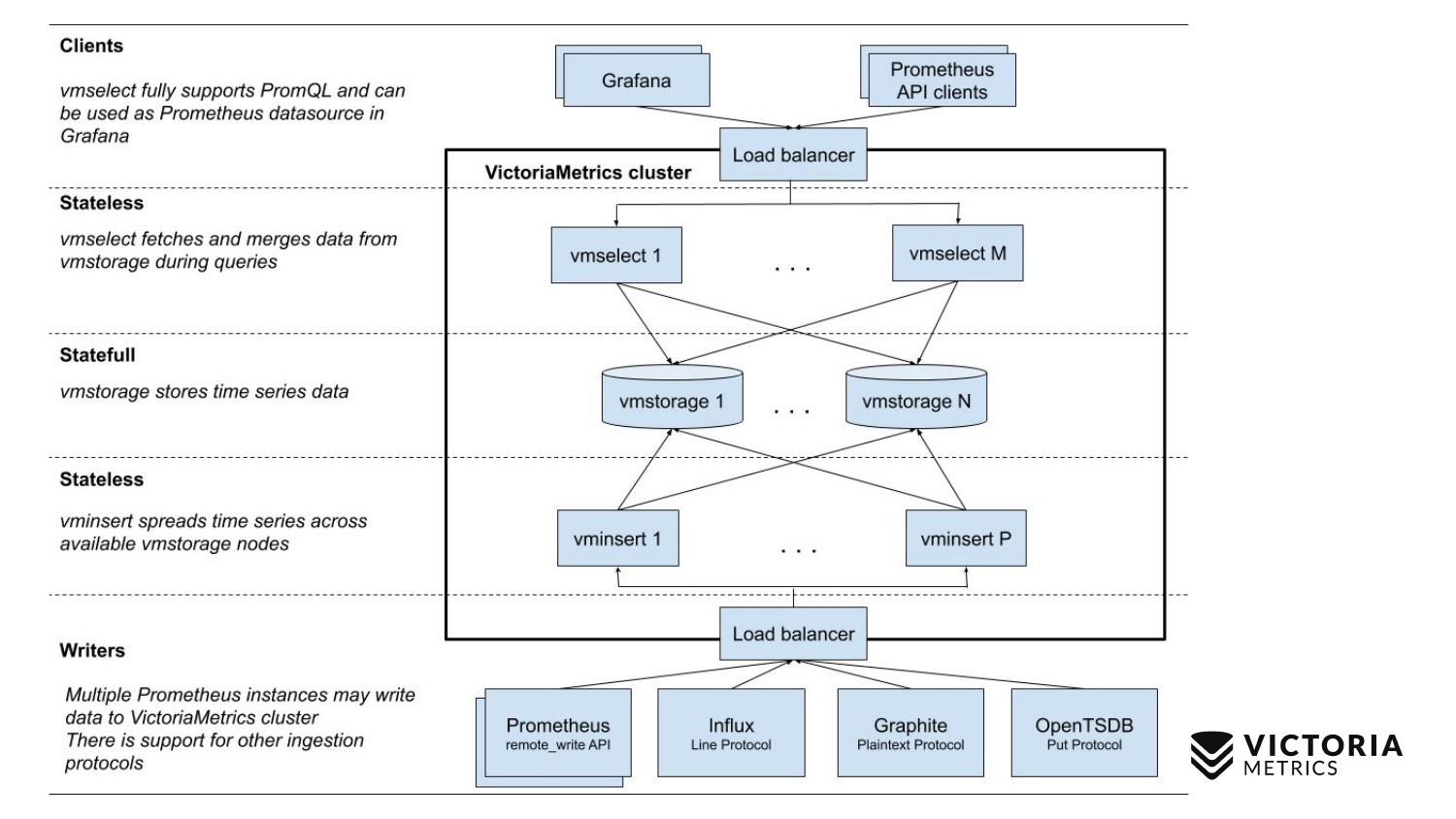
VictoriaMetrics memiliki 2 versi: Single-node dan versi cluster. Single-node berjalan di satu komputer. Single-node tidak memiliki komponen-komponen ini, hanya satu biner. Biner pada slide ini terlihat seperti kotak ini. Semua yang ada di dalam kotak adalah konten dari file biner untuk versi Single-node. Anda tidak perlu tahu tentang dia. Mulai saja biner - dan semuanya bekerja untuk kita.
Versi cluster lebih rumit. Di dalamnya ada tiga komponen yang berbeda: vmselect, vminsert dan vmstorage. Dari nama mereka harus jelas apa yang mereka lakukan. Komponen Sisipan menerima data dalam format yang berbeda: dari API penulisan jarak jauh Prometheus, protokol garis Influx, protokol Graphite, dan protokol OpenTSDB. Komponen Sisip menerima mereka, mem-parsing dan mendistribusikannya di antara komponen penyimpanan yang ada, di mana data sudah disimpan. Komponen Select, pada gilirannya, menerima permintaan PromQL. Ini mengimplementasikan PromQL serta API kueri Prometheus, dan itu dapat digunakan sebagai pengganti Prometheus di Grafana atau klien API Prometheus lainnya. Pilih menerima permintaan promql, mem-parsingnya, membaca data yang diperlukan untuk mengeksekusi permintaan ini dari node penyimpanan, memproses data ini dan mengembalikan respons.

Bandingkan kesulitan memasang Thanos dan VictoriaMetrics.

Mari kita mulai dengan Thanos. Sebelum Anda mulai bekerja dengan Thanos, Anda perlu membuat ember di Object Storage, seperti S3 atau GCS, sehingga Thanos Sidecar dapat menulis data di sana.

Kemudian untuk setiap Prometheus Anda perlu menginstal Thanos Sidecar. Sebelum itu, Anda harus ingat untuk menonaktifkan pemadatan data di Prometheus. Pemadatan data secara berkala mengompresi data dalam penyimpanan lokal Prometheus untuk mengurangi konsumsi sumber daya.
Ketika Anda menginstal Thanos Sidecar ke Prometheus Anda, Anda harus menonaktifkan pemadatan data ini, karena Thanos Sidecar tidak dapat bekerja secara normal ketika pemadatan data diaktifkan. Ini berarti bahwa Prometheus Anda mulai menyimpan data dalam blok dua jam dan berhenti menggabungkan blok ini menjadi yang lebih besar. Dengan demikian, jika Anda membuat permintaan yang lebih lama dari dua jam terakhir, mereka tidak akan bekerja seefisien mungkin jika pemadatan data diaktifkan.

Oleh karena itu, Thanos merekomendasikan untuk mengurangi waktu penyimpanan data di penyimpanan lokal menjadi 6-8 jam untuk mengurangi overhead ini dari sejumlah besar blok kecil.
Setelah Anda menginstal Thanos Sidecar, Anda harus menginstal dua komponen untuk setiap Bucket Penyimpanan Objek. Ini adalah Thanos Compactor dan Thanos Store Gateway.

Setelah itu, Anda perlu menginstal Thanos Query dan mengkonfigurasinya sehingga ia tahu cara menyambungkan ke semua Thanos Store Gateway yang Anda miliki, dan juga tahu cara menghubungkan ke semua Thanos Sidecar.
Mungkin ada masalah kecil.

Anda perlu mengonfigurasi koneksi yang andal dan aman dari Thanos Query ke komponen ini. Dan jika Prometheus Anda berada di pusat data yang berbeda, atau di VPC berbeda, maka koneksi eksternal ke mereka dilarang. Tetapi agar Thanos Query berfungsi, Anda perlu mengkonfigurasi koneksi di sana, dan Anda harus menemukan cara.
Jika Anda memiliki banyak pusat data seperti itu, maka, keandalan seluruh sistem menurun. Karena Thanos Query harus terus terhubung ke semua Thanos Sidecar yang terletak di pusat data yang berbeda. Dengan setiap permintaan yang masuk, ia akan meneruskan permintaan ke semua Thanos Sidecar. Jika koneksi terputus, Anda akan menerima set data yang tidak lengkap, atau Anda akan mendapatkan jawaban "cluster tidak berfungsi."

Di VictoriaMetrics, segalanya sedikit lebih mudah. Untuk versi Single-node, cukup menjalankan satu biner dan semuanya berfungsi.

Dalam versi berkerumun, cukup menjalankan semua tiga jenis komponen di atas dalam jumlah apa pun yang Anda butuhkan, atau menggunakan bagan kemudi untuk mengotomatiskan peluncuran komponen di Kubernetes. Kami masih berencana untuk membuat operator Kubernetes. Helm chart tidak mencakup beberapa kasus, dan memungkinkan Anda untuk menembak kaki Anda. Misalnya, ini memungkinkan Anda untuk mengurangi jumlah node penyimpanan, yang akan menyebabkan hilangnya data.

Setelah Anda meluncurkan satu versi biner atau cluster, Anda hanya perlu menambahkan pengaturan untuk url tulis jarak jauh ke konfigurasi Prometheus sehingga mulai menulis data secara paralel ke penyimpanan lokal dan penyimpanan jarak jauh. Seperti yang Anda perhatikan, konfigurasi ini harus bekerja jauh lebih andal dibandingkan dengan konfigurasi Thanos. Kami tidak perlu membuat VictoriaMetrics terhubung dengan semua Prometheus, karena Prometheus sendiri terhubung ke VictoriaMetrics dan mengirimkan data.

Pertimbangkan pengawalan Thanos dan VictoriaMetrics.

Thanos perlu mengawasi Sidecar agar tidak berhenti memuat data ke dalam Object Storage. Mereka dapat menghentikan pemuatan data ini karena kesalahan pemuatan, misalnya, koneksi jaringan Anda dengan Object Storage sementara waktu terputus, atau Object Storage sementara tidak tersedia. Thanos Sidecar pada saat ini akan melihat ini, melaporkan kesalahan, mungkin jatuh dan kemudian berhenti bekerja. Jika Anda tidak memantaunya, maka data Anda tidak akan lagi ditransfer ke Object Storage. Jika waktu retensi berlalu (disarankan 6-8 jam), maka Anda akan kehilangan data yang tidak termasuk dalam Object Storage.

Pemadat Thanos dapat berhenti bekerja karena balapan dengan Sidecar . Compactor mengambil data dari Object Storage dan menggabungkannya menjadi potongan data yang lebih besar. Karena compactor tidak disinkronkan dengan Sidecar, ini mungkin terjadi: Sidecar belum selesai menulis blok, Compactor memutuskan bahwa blok ini sepenuhnya direkam. Compactor mulai membacanya. Itu tidak membaca blok secara keseluruhan dan berhenti bekerja. Lihat detailnya di sini .

Store Gateway dapat memberikan data yang tidak konsisten karena perlombaan antara Compactor dan Sidecar. Ini adalah hal yang sama, karena Store Gateway sama sekali tidak sinkron dengan Compactor dan Sidecar. Dengan demikian, kondisi balapan dapat terjadi ketika Store Gateway tidak melihat bagian dari data atau melihat kelebihan data.

Komponen Query di Thanos default ke hasil parsial jika beberapa Sidecar atau Store Gateway saat ini tidak tersedia. Anda akan menerima bagian dari data, dan bahkan tidak akan tahu bahwa tidak semua data diterima. Itu berfungsi seperti ini secara default. Dalam situasi yang serupa, VictoriaMetrics mengembalikan data yang ditandai sebagai parsial.

Tidak seperti Thanos, VictoriaMetrics jarang kehilangan data. Bahkan jika koneksi dari Prometheus ke VictoriaMetrics terputus, maka ini bukan masalah, karena Prometheus terus merekam data baru yang masuk dalam Write Ahead Log, yang berukuran 2 jam. Jika Anda terhubung kembali ke VictoriaMetrics dalam dua jam, maka data tidak akan hilang. Prometheus dapat menambahkan data setelah tersambung kembali ke VictoriaMetrics .

Tidak seperti Thanos, yang hanya menulis data ke penyimpanan objek setelah dua jam, Prometheus secara otomatis mereplikasi data melalui protokol tulis jarak jauh ke penyimpanan jarak jauh, seperti VictoriaMetrics. Anda tidak takut kehilangan penyimpanan lokal di Prometheus. Jika dia tiba-tiba kehilangan penyimpanan lokal, maka dalam kasus terburuk Anda akan kehilangan detik-detik terakhir data yang tidak punya waktu untuk menulis ke penyimpanan jauh.

Kubernetes secara otomatis mengelola cluster, tidak seperti Thanos. Semua komponen Thanos sulit untuk dimasukkan ke dalam satu cluster Kubernetes, tidak seperti komponen cluster VictoriaMetrics.

VictoriaMetrics memiliki peningkatan yang sangat sederhana ke versi baru. Hentikan VictoriaMetrics, perbarui binari dan jalankan. Ketika berhenti melalui sinyal SIGINT, semua binari VictoriaMetrics melakukan shutdown yang anggun. Mereka dengan benar menyimpan data yang diperlukan, menutup koneksi masuk dengan benar agar tidak kehilangan apa pun. Karena itu, Anda tidak akan kehilangan apa pun saat meningkatkan.

VictoriaMetrics memiliki cara yang sangat sederhana untuk memperluas cluster. Cukup tambahkan komponen yang diperlukan dan terus bekerja.

Tentang perangkap di Thanos dan Victoria Metrics.

Thanos memiliki perangkap berikut. Prometheus harus menyimpan data selama dua jam terakhir. Jika hilang, Anda akan benar-benar kehilangannya, karena mereka belum berhasil mendaftar di Object Storage, seperti S3.

Komponen Store Gateway dan komponen pemadat mungkin memerlukan banyak memori untuk bekerja dengan Penyimpanan Objek besar jika banyak file kecil disimpan di sana. Semakin besar jumlah dan volume file, semakin banyak Store Gateway dan memori pemadat diperlukan untuk menyimpan informasi meta. Thanos memiliki banyak masalah tentang Store Gateway dan penurunan compactor dengan data rata-rata yang direkam .

Thanos disebut-sebut dapat mengukur skala dengan jumlah Prometheus Anda tanpa batas. Ini sebenarnya tidak benar. Karena semua permintaan melalui komponen Query, yang harus secara bersamaan melakukan polling semua komponen Store Gateway dan semua komponen Sidecar, tarik data dari sana dan kemudian preprocess mereka. Jelas, kecepatan kueri dibatasi oleh tautan lemah paling lambat, Gerbang Store paling lambat, atau Sidecar paling lambat.
Komponen-komponen ini mungkin dimuat tidak merata. Misalnya, Anda memiliki Prometheus yang mengumpulkan jutaan metrik per detik. Dan ada Prometheus, yang mengumpulkan ribuan metrik per detik. Prometheus, yang mengumpulkan jutaan metrik per detik, memuat server yang dijalankannya lebih banyak. Dengan demikian, Sidecar lebih lambat di sana. Secara umum, semuanya berjalan lambat di sana. Dan komponen Query akan menarik data dengan sangat lambat dari sana. Dengan demikian, kinerja seluruh cluster Anda akan dibatasi oleh Sidecar yang lambat ini.

Secara default, Thanos mengembalikan data sebagian jika beberapa Sidecar dan Store Gateway tidak tersedia. Misalnya, jika Anda memiliki Sidecar yang tersebar di seluruh dunia di pusat data yang berbeda, maka kemungkinan pemutusan dan tidak tersedianya komponen meningkat sangat besar. Karenanya, dalam kebanyakan kasus Anda akan menerima data sebagian tanpa menyadarinya.

VictoriaMetrics juga memiliki jebakan. Jebakan pertama adalah opsi yang membatasi jumlah RAM yang digunakan untuk cache VictoriaMetrics. Secara default, ini sama dengan 60% RAM pada mesin tempat VictoriaMetrics berjalan, atau 60% dari VictoriaMetrics pod RAM di Kubernetes.
Jika Anda salah mengubah nilai ini, maka Anda dapat merusak kinerja VictoriaMetrics. Misalnya, jika Anda menetapkan nilai terlalu rendah, data mungkin tidak lagi sesuai dengan cache VictoriaMetrics. Karena itu, ia harus melakukan pekerjaan ekstra dan memuat prosesor dengan disk. Jika Anda membuat opsi ini terlalu besar, itu meningkatkan, pertama, kemungkinan bahwa VictoriaMetrics akan crash karena kehabisan memori kesalahan, dan, kedua, ini akan menyebabkan sangat sedikit memori operasional yang tersisa di sistem operasi memori untuk cache file. Dan VictoriaMetrics mengandalkan cache file untuk kinerja. Jika itu tidak cukup, maka beban pada disk bisa sangat meningkat. Karenanya, tip: jangan ubah parameter kecuali benar-benar diperlukan.
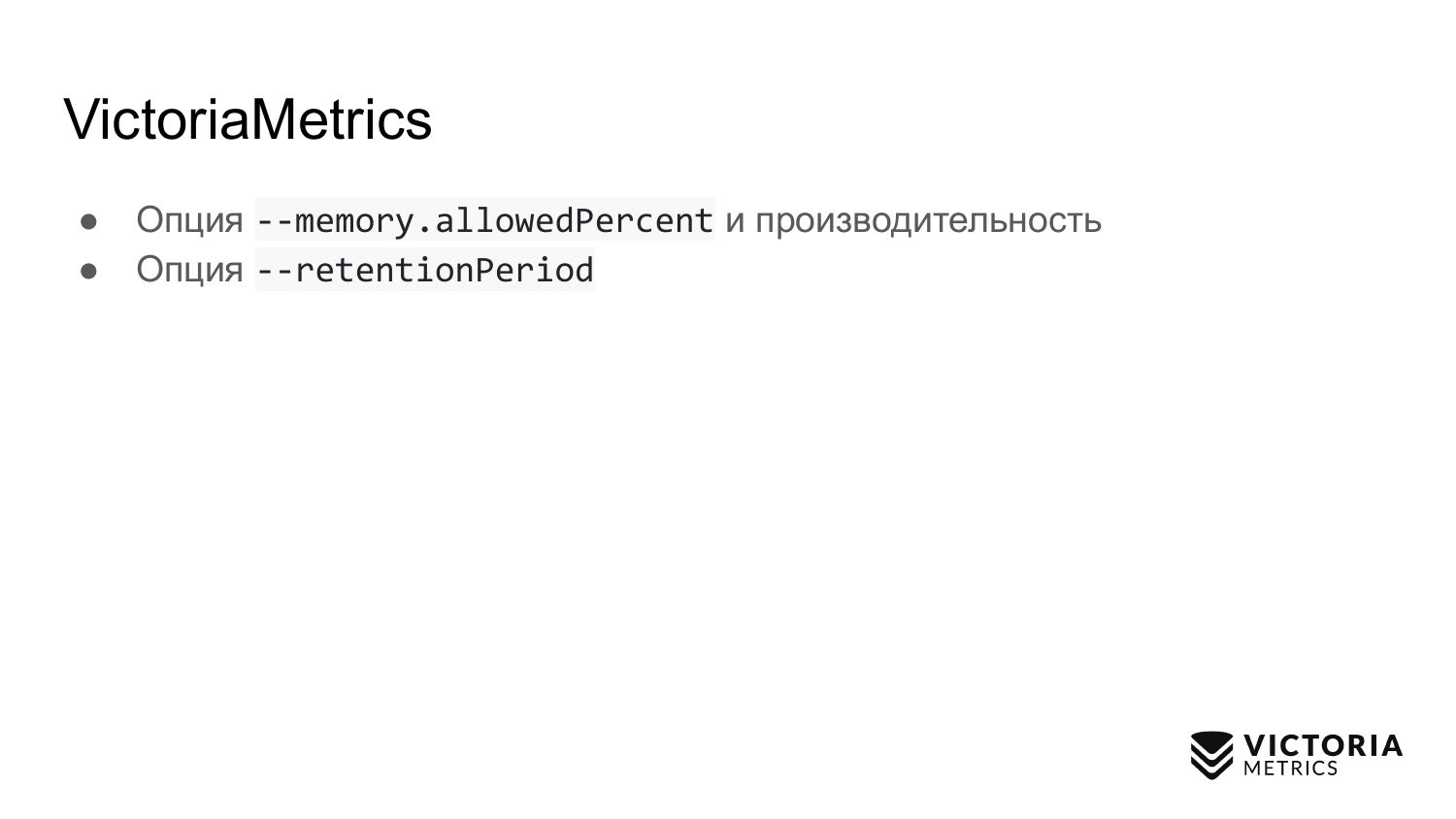
Opsi kedua. Ini adalah retentionPeriod - periode yang ditetapkan ke 1 bulan secara default. Ini adalah waktu VictoriaMetrics menyimpan data. Setelah periode ini, VictoriaMetrics menghapus data.
Banyak yang menjalankan VictoriaMetrics tanpa parameter ini, mereka merekam data selama sebulan. Dan kemudian mereka bertanya: mengapa data hilang untuk bulan sebelumnya? Karena retentionPeriod adalah 1 bulan secara default. Oleh karena itu, Anda perlu mengetahui dan mengatur retensiPeriode yang benar.

Mari kita berjalan melalui peluang unik.

Thanos memiliki fitur seperti downsampling: interval 5 menit dan jam, yang sering tidak berfungsi dengan benar . Jika Anda Google dan melihat masalah mereka di github, ada banyak masalah yang terkait dengan downsampling ini, bahwa kadang-kadang tidak berfungsi dengan benar, atau tidak berfungsi seperti yang diharapkan pengguna.

Thanos memiliki deduplikasi data untuk pasangan HA Prometheus. Ketika dua Prometheus'a mengumpulkan metrik yang sama dari target yang sama'dan Thanos menempatkan mereka di Object Storage. Thanos , VictoriaMetrics.

Thanos alert , Thanos. production .

Thanos , Thanos Prometheus — . Thanos Prometheus . Thanos Prometheus .

VictoriaMetrics — MetricsQL. VictoriaMetrics PromQL, big monitoring metup.

VictoriaMetrics . VictoriaMetrics Prometheus, Influx, OpenTSDB Graphite.

VictoriaMetrics Thanos Prometheus.
, 2-5 Prometheus Thanos.

VictoriaMetrics — .

.

Thanos , object storage, .
object storage, ($10 ). object storage, , AWS — . , $10 $230 1. , Thanos .

Thanos Compact, Store Gateway, Query , , .

VictoriaMetrics . GCE HDD , $40 1. VictoriaMetrics HDD , SSD, . VictoriaMetrics HDD.

VictoriaMetrics membutuhkan server untuk komponen: baik Single-nod atau untuk komponen cluster, yang, tidak seperti komponen Thanos, membutuhkan CPU yang lebih sedikit, RAM - itu akan lebih murah sesuai itu.

Contoh implementasi.

Contoh implementasi Thanos adalah Gitlab. Gitlab sepenuhnya didukung oleh Thanos. Tapi tidak begitu mulus. Jika Anda melihat masalah mereka, Anda dapat melihat bahwa mereka terus-menerus memiliki semacam masalah operasional dengan Thanos : tidak ada cukup memori untuk Store Gateway atau komponen Permintaan. Mereka terus-menerus harus meningkatkan jumlah memori.
Karena itu, biaya untuk menyelesaikan masalah ini meningkat.
Implementasi kedua, yang mungkin lebih sukses, adalah perusahaan Improbable, yang memulai pengembangan Thanos. Mereka menerbitkan sumber Thanos. Improbable adalah perusahaan yang mengembangkan mesin game.

Contoh implementasi publik VictoriaMetrics adalah:
- pembuat situs wix.com
- Adidas memperkenalkan VictoriaMetrics dan bahkan membuat presentasi di PromCon 2019 terbaru
- TrafficStars - jaringan iklan
- Seznam.cz adalah mesin pencari populer di Ceko.
Dan kemudian pergi ke nama perusahaan, yang saya tidak dapat nama sekarang. Mereka tidak setuju.
- Salah satu pengembang game utama. Lebih besar dari mereka Tidak mungkin.
- Pengembang perangkat lunak grafis utama.
- Bank besar Rusia.
- Pabrikan turbin angin Eropa yang telah berhasil menguji VictoriaMetrics. Pabrikan ini mengimplementasikan VictoriaMetrics untuk memantau data dari turbin angin dengan kecepatan 50 sampel per detik per sensor. Setiap turbin angin memiliki beberapa ratus sensor. Mereka memiliki beberapa ratus turbin angin.
- Maskapai penerbangan Rusia yang ingin memperkenalkan VictoriaMetrics, tetapi masih belum bisa. Kami berada pada tahap kontrak dengan mereka.
 Kesimpulan
Kesimpulan
VictoriaMetrics dan Thanos memecahkan masalah serupa, tetapi dengan cara yang berbeda:
- Tampilan permintaan global
- skala horizontal
- retensi sewenang-wenang

Terima kasih
Kami menunggu Anda di saluran telegram kami.
