Hai Habr! Kumpulan data untuk Big Data dan pembelajaran mesin tumbuh secara eksponensial dan perlu diproses. Posting kami tentang teknologi inovatif lain dalam Komputasi Kinerja Tinggi (HPC), ditampilkan di stan Kingston di
Supercomputing 2019 . Ini adalah penggunaan sistem penyimpanan Hi-End (SHD) di server dengan prosesor grafis (GPU) dan teknologi bus Penyimpanan GPUDirect. Berkat pertukaran data langsung antara penyimpanan dan GPU, melewati CPU, pemuatan data ke akselerator GPU dipercepat oleh urutan besarnya, oleh karena itu aplikasi Big Data berjalan pada kinerja maksimum yang disediakan GPU. Pada gilirannya, pengembang sistem HPC tertarik pada pencapaian di bidang penyimpanan dengan kecepatan input / output tertinggi - seperti yang dirilis oleh Kingston.

Kinerja GPU di depan pemuatan data
Sejak penciptaan CUDA, sebuah arsitektur komputasi paralel paralel perangkat keras dan perangkat lunak berbasis GPU untuk mengembangkan aplikasi tujuan umum, pada tahun 2007, kemampuan perangkat keras GPU itu sendiri telah tumbuh dengan luar biasa. Saat ini, GPU semakin banyak digunakan dalam bidang aplikasi HPC seperti Big Data, pembelajaran mesin, dan pembelajaran mendalam.
Perhatikan bahwa meskipun persamaan istilah, dua yang terakhir adalah tugas yang berbeda secara algoritmik. ML mengajarkan komputer berdasarkan data terstruktur, dan DL mengajarkan komputer berdasarkan respons dari jaringan saraf. Contoh yang membantu memahami perbedaannya cukup sederhana. Misalkan komputer harus membedakan foto kucing dan anjing yang diambil dari penyimpanan. Untuk ML, Anda harus mengirim satu set gambar dengan banyak tag, yang masing-masingnya mendefinisikan satu fitur khusus hewan. Untuk DL, cukup mengunggah gambar dalam jumlah yang jauh lebih besar, tetapi hanya dengan satu tag "ini kucing" atau "ini anjing". DL sangat mirip dengan bagaimana anak-anak kecil diajarkan - mereka hanya diperlihatkan gambar anjing dan kucing dalam buku dan dalam kehidupan (paling sering, bahkan tanpa menjelaskan perbedaan terperinci), dan otak anak itu sendiri mulai menentukan jenis hewan setelah sejumlah gambar tertentu untuk perbandingan ( menurut perkiraan, kita berbicara tentang seratus atau dua tayangan untuk semua waktu masa kanak-kanak). Algoritma DL belum begitu sempurna: untuk juga berhasil bekerja pada definisi gambar dari jaringan saraf, jutaan gambar harus diserahkan dan diproses dalam GPU.
Hasil pendahuluan: berdasarkan GPU, Anda dapat membangun aplikasi-HPC di bidang Big Data, ML dan DL, tetapi ada masalah - kumpulan data begitu besar sehingga waktu yang dihabiskan untuk mengunduh data dari sistem penyimpanan ke GPU mulai mengurangi keseluruhan kinerja aplikasi. Dengan kata lain, GPU cepat tetap underload karena lambatnya input / output data dari subsistem lain. Perbedaan dalam kecepatan input / output GPU dan bus ke CPU / SHD dapat menjadi urutan besarnya.
Bagaimana cara kerja teknologi Penyimpanan GPUDirect?
Proses input / output dikendalikan oleh CPU, serta proses memuat data dari penyimpanan ke GPU untuk diproses selanjutnya. Ini mendorong permintaan teknologi yang akan menyediakan akses langsung antara GPU dan drive NVMe untuk interaksi cepat satu sama lain. Teknologi tersebut pertama kali diusulkan oleh NVIDIA dan menyebutnya GPUDirect Storage. Bahkan, ini adalah variasi dari teknologi RDUD GPUDirect (Remote Direct Memory Address) yang sebelumnya mereka kembangkan.
 Jensen Huang, CEO NVIDIA, memperkenalkan Penyimpanan GPUDirect sebagai variasi dari GPUDirect RDMA di SC-19. Sumber: NVIDIA
Jensen Huang, CEO NVIDIA, memperkenalkan Penyimpanan GPUDirect sebagai variasi dari GPUDirect RDMA di SC-19. Sumber: NVIDIAPerbedaan antara GPUDirect RDMA dan GPUDirect Storage ada di perangkat di mana pengalamatan dilakukan. Teknologi RDUD GPUDirect ditugaskan untuk memindahkan data secara langsung antara kartu input antarmuka jaringan (NIC) dan memori GPU, dan Penyimpanan GPUDirect menyediakan jalur transfer data langsung antara penyimpanan lokal atau jarak jauh, seperti NVMe atau NVMe via Fabric (NVMe-oF) dan memori GPU.
Kedua opsi, GPUDirect RDMA dan GPUDirect Storage, menghindari perpindahan data yang tidak perlu melalui buffer dalam memori CPU dan memungkinkan mekanisme Direct Memory Access (DMA) untuk mentransfer data dari kartu jaringan atau penyimpanan langsung ke atau dari memori GPU - semua tanpa beban di pusat prosesor Untuk Penyimpanan GPUDirect, lokasi penyimpanan tidak masalah: itu bisa berupa disk NVME di dalam unit GPU, di dalam rak, atau terhubung melalui jaringan sebagai NVMe-oF.
 Skema operasi Penyimpanan GPUDirect. Sumber: NVIDIA
Skema operasi Penyimpanan GPUDirect. Sumber: NVIDIANVMe Hi-End Storage Diperlukan di Pasar Aplikasi HPC
Memahami bahwa dengan munculnya GPUDirect Storage, minat pelanggan besar akan beralih ke menawarkan sistem penyimpanan dengan kecepatan input / output yang sesuai dengan bandwidth GPU, Kingston menunjukkan sistem demo yang terdiri dari sistem penyimpanan berdasarkan disk NVMe dan unit dengan GPU di SC-19 yang menganalisis ribuan gambar satelit per detik. Kami sudah menulis tentang penyimpanan tersebut berdasarkan 10 drive DC1000M U.2 NVMe
dalam laporan dari pameran superkomputer .
 Penyimpanan berdasarkan 10 drive DC1000M U.2 NVMe secara memadai melengkapi server dengan akselerator grafis. Sumber: Kingston
Penyimpanan berdasarkan 10 drive DC1000M U.2 NVMe secara memadai melengkapi server dengan akselerator grafis. Sumber: KingstonPenyimpanan tersebut dilakukan dalam bentuk unit rak 1U atau lebih dan dapat diskalakan tergantung pada jumlah disk NV1 DC1000M U.2 NVMe, di mana masing-masing memiliki kapasitas 3,84-7,68 TB. DC1000M adalah model NVMe SSD pertama dalam faktor bentuk U.2 di garis drive Kingston untuk pusat data. Ini memiliki peringkat daya tahan (DWPD, Drive menulis per hari), yang memungkinkan Anda untuk menimpa data pada kapasitas penuh sekali sehari untuk masa pakai drive yang terjamin.
Dalam uji fio v3.13 pada sistem operasi Ubuntu 18.04.3 LTS, kernel Linux 5.0.0-31-generik, model penyimpanan pameran menunjukkan kecepatan Baca Berkelanjutan 5,8 juta IOPS dengan bandwidth berkelanjutan 23,8 Gb / s.
Ariel Perez, manajer bisnis SSD Kingston, menggambarkan sistem penyimpanan baru sebagai berikut: “Kami siap untuk memberikan server generasi berikutnya dengan U.2 NVMe SSD untuk mengatasi banyak hambatan transfer data yang secara tradisional dikaitkan dengan penyimpanan. Kombinasi SSD NVMe dan Server Premier DRAM premium kami menjadikan Kingston salah satu penyedia pengolah data end-to-end yang paling komprehensif di industri. "
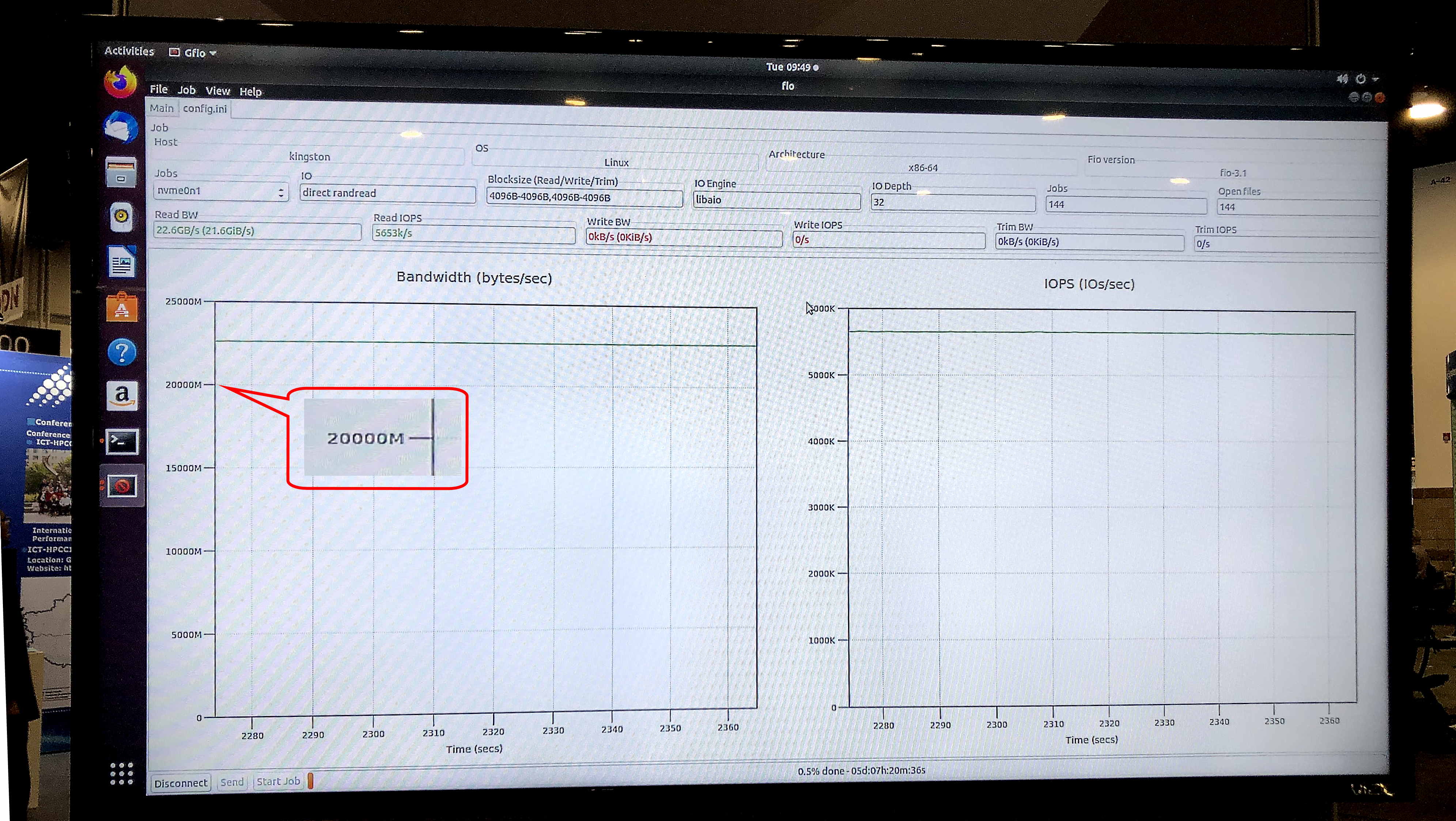 Tes gfio v3.13 menunjukkan bandwidth 23,8 Gb / s untuk penyimpanan demo pada drive DC1000M U.2 NVMe. Sumber: Kingston
Tes gfio v3.13 menunjukkan bandwidth 23,8 Gb / s untuk penyimpanan demo pada drive DC1000M U.2 NVMe. Sumber: KingstonSeperti apa tampilan sistem yang umum untuk aplikasi HPC yang menggunakan teknologi Penyimpanan GPUDirect atau sejenisnya? Ini adalah arsitektur dengan pemisahan fisik blok fungsional dalam rak: satu atau dua unit untuk RAM, beberapa lagi untuk simpul komputasi GPU dan CPU, dan satu atau lebih unit untuk penyimpanan.
Dengan pengumuman Penyimpanan GPUDirect dan kemungkinan munculnya teknologi serupa di vendor GPU lainnya, Kingston memperluas permintaannya untuk sistem penyimpanan yang dirancang untuk digunakan dalam komputasi kinerja tinggi. Penandanya adalah kecepatan membaca data dari sistem penyimpanan, sebanding dengan bandwidth kartu jaringan 40- atau 100-Gbit di pintu masuk ke unit komputasi dengan GPU. Dengan demikian, sistem penyimpanan ultra-cepat, termasuk NVMe eksternal melalui Fabric, dari eksotis akan menjadi mainstream untuk aplikasi HPC. Selain perhitungan sains dan keuangan, mereka akan menemukan aplikasi di banyak bidang praktis lainnya, seperti sistem keselamatan tingkat Kota Aman megalopolis atau pusat pengawasan transportasi, di mana kecepatan pengenalan dan identifikasi pada tingkat jutaan gambar HD per detik diperlukan, ”ceruk pasar atas SHD
Informasi tambahan tentang produk Kingston dapat ditemukan di
situs web resmi perusahaan.