Kompleksitas interpretasi data seismik disebabkan oleh fakta bahwa untuk setiap tugas perlu dicari pendekatan individual, karena setiap rangkaian data tersebut unik. Pemrosesan manual membutuhkan biaya tenaga kerja yang signifikan, dan hasilnya seringkali mengandung kesalahan yang berkaitan dengan faktor manusia. Penggunaan jaringan saraf untuk interpretasi dapat secara signifikan mengurangi tenaga kerja manual, tetapi keunikan data memaksakan pembatasan pada otomatisasi pekerjaan ini.
Artikel ini menjelaskan percobaan untuk menganalisis penerapan jaringan saraf untuk mengotomatisasi alokasi lapisan geologis dalam gambar 2D menggunakan data berlabel lengkap dari Laut Utara sebagai contoh.
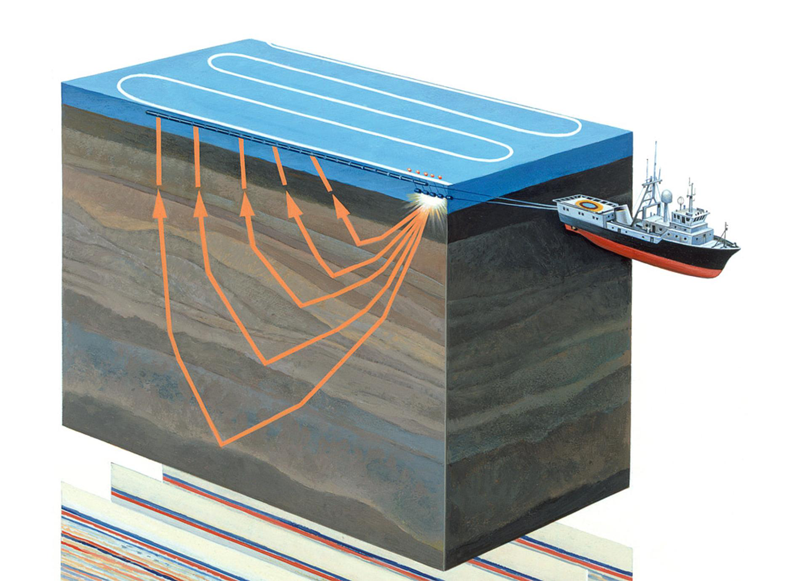
Gambar 1. Survei seismik akuatik (
sumber )
Sedikit tentang bidang subjek
Eksplorasi seismik adalah metode geofisika untuk mempelajari objek geologis menggunakan getaran elastis - gelombang seismik. Metode ini didasarkan pada kenyataan bahwa kecepatan rambat gelombang seismik tergantung pada sifat-sifat lingkungan geologi di mana mereka merambat (komposisi batuan, porositas, fraktur, saturasi kelembaban, dll.) Melewati lapisan geologis dengan sifat yang berbeda, gelombang seismik tercermin dari objek yang berbeda dan kembali ke penerima (lihat Gambar 1). Sifatnya direkam dan setelah pemrosesan memungkinkan Anda untuk membentuk gambar dua dimensi - bagian seismik, atau array data tiga dimensi - kubus seismik.
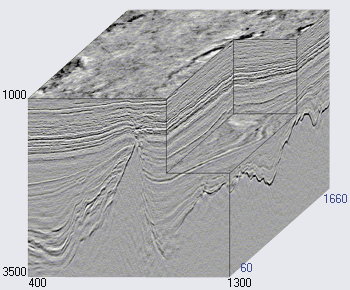
Gambar 2. Contoh kubus seismik (
sumber )
Sumbu horizontal kubus seismik terletak di sepanjang permukaan bumi, dan vertikal mewakili kedalaman atau waktu (lihat Gambar 2). Dalam beberapa kasus, kubus dibagi menjadi beberapa bagian vertikal di sepanjang sumbu geofon (yang disebut inline, inlines) atau lintas (crossline, crosslines, xlines). Setiap kubus vertikal (dan irisan) adalah jejak seismik yang terpisah.
Dengan demikian, inline dan crossline terdiri dari jalur seismik yang sama, hanya dalam urutan yang berbeda. Jalan seismik yang berdekatan sangat mirip satu sama lain. Perubahan yang lebih dramatis terjadi pada titik kesalahan, tetapi masih akan ada kesamaan. Ini berarti irisan tetangga sangat mirip satu sama lain.
Semua pengetahuan ini akan bermanfaat bagi kita saat merencanakan eksperimen.
Tugas interpretasi dan peran jaringan saraf dalam solusinya
Data yang diperoleh diproses secara manual oleh penafsir yang mengidentifikasi secara langsung pada kubus atau pada setiap irisan lapisan geologis masing-masing batuan dan batas-batasnya (cakrawala, cakrawala), endapan garam, sesar dan fitur lain dari struktur geologi daerah penelitian. Penerjemah, yang bekerja dengan kubus atau irisan, memulai pekerjaannya dengan seleksi manual yang melelahkan dari lapisan dan horizon geologis. Setiap cakrawala harus digulung secara manual (dari bahasa Inggris "memilih" - koleksi) dengan mengarahkan kursor dan mengklik mouse.
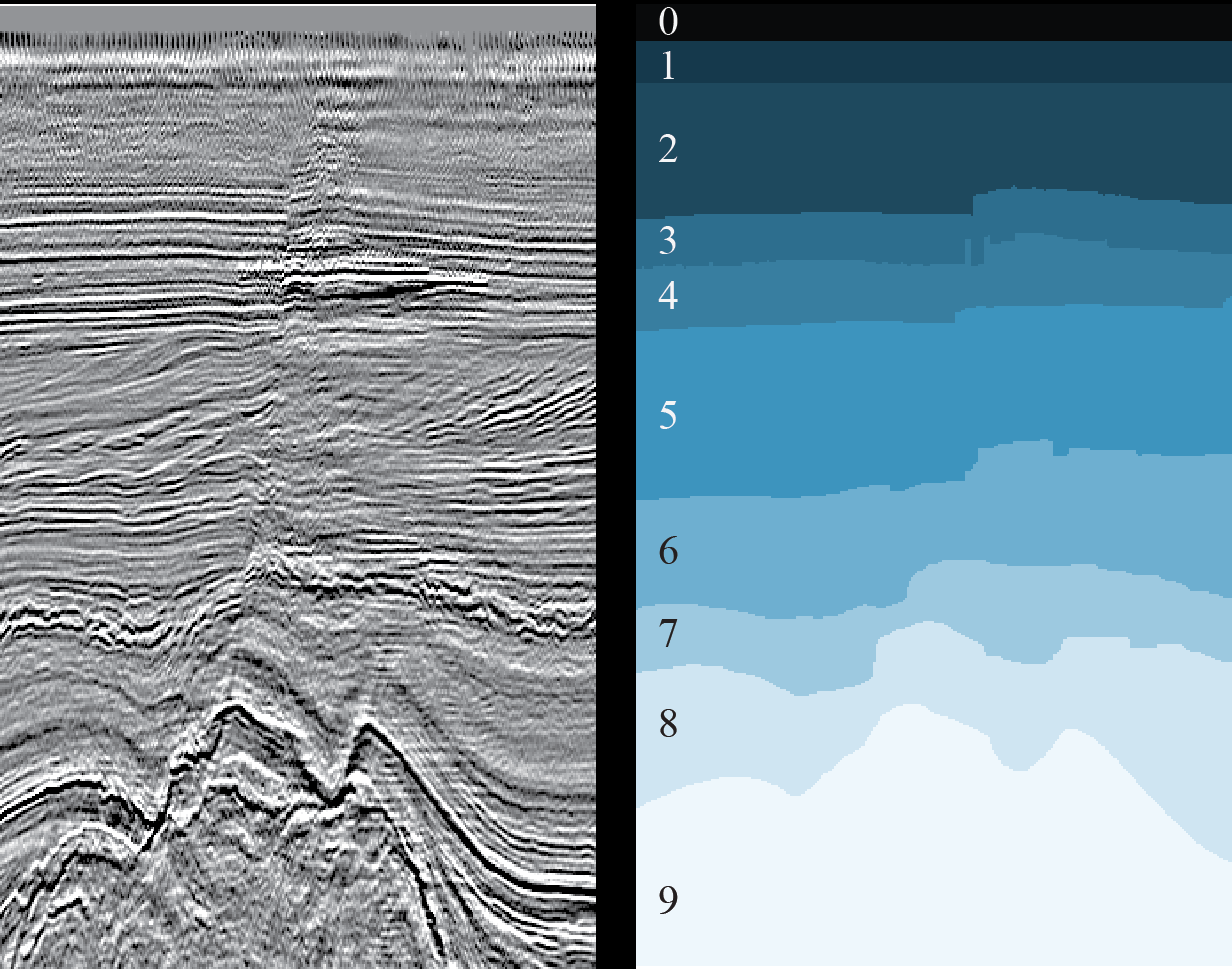
Gambar 3. Contoh irisan 2D (kiri) dan hasil penandaan lapisan geologi yang sesuai (kanan) (
sumber )
Masalah utama terkait dengan meningkatnya volume data seismik yang diperoleh setiap tahun di bawah kondisi geologis yang semakin kompleks (misalnya, bagian bawah laut dengan kedalaman laut yang luar biasa), dan ambiguitas interpretasi data ini. Selain itu, dalam kondisi tenggat waktu yang ketat dan / atau volume yang besar, penerjemah pasti membuat kesalahan, misalnya, kehilangan berbagai fitur dari bagian geologi.
Masalah ini sebagian dapat diselesaikan dengan bantuan jaringan saraf, secara signifikan mengurangi tenaga kerja manual, sehingga mempercepat proses interpretasi dan mengurangi jumlah kesalahan. Untuk pengoperasian jaringan saraf, sejumlah bagian siap pakai, berlabel (bagian dari kubus) diperlukan, dan sebagai hasilnya penandaan lengkap semua bagian (atau seluruh kubus) akan diperoleh, yang idealnya hanya memerlukan perbaikan kecil oleh seseorang untuk menyesuaikan bagian tertentu dari horizon atau menandai kembali area kecil yang jaringan tidak dapat mengenali dengan benar.
Ada banyak solusi untuk masalah interpretasi menggunakan jaringan saraf, berikut adalah beberapa contoh:
satu ,
dua ,
tiga . Kesulitannya terletak pada kenyataan bahwa setiap set data adalah unik - karena kekhasan batuan geologi di wilayah yang diteliti, karena berbagai cara teknis dan metode eksplorasi seismik, karena berbagai metode yang digunakan untuk mengubah data mentah menjadi data yang siap dibaca. Bahkan karena suara-suara eksternal (misalnya, anjing menggonggong dan suara keras lainnya), yang tidak selalu mungkin untuk sepenuhnya dihapus. Oleh karena itu, setiap tugas harus diselesaikan secara individual.
Namun, meskipun demikian, banyak karya memungkinkan untuk meraba-raba pendekatan umum yang terpisah untuk menyelesaikan berbagai masalah interpretasi.
Kami di
MaritimeAI (sebuah proyek yang dikembangkan dari komunitas Machine Learning for Social Goods
ODS ,
sebuah artikel tentang kami ) untuk setiap zona studi bidang minat kami (penelitian laut) telah menerbitkan karya dan melakukan eksperimen kami sendiri, yang memungkinkan kami untuk mengklarifikasi batas dan fitur penerapan tertentu solusi, dan kadang-kadang menemukan pendekatan Anda sendiri.
Hasil dari satu percobaan yang kami jelaskan di artikel ini.
Tujuan Penelitian Bisnis
Cukuplah bagi spesialis Ilmu Data untuk melihat Gambar 3 agar lebih mudah bernapas - tugas umum segmentasi gambar semantik, yang telah banyak diciptakan arsitektur jaringan saraf dan metode pengajaran. Anda hanya perlu memilih yang tepat dan melatih jaringan.
Tapi tidak sesederhana itu.
Untuk mendapatkan hasil yang baik dengan bantuan jaringan saraf, Anda perlu sebanyak mungkin data yang sudah ditandai yang akan dipelajari. Tapi tugas kita justru mengurangi jumlah pekerjaan manual. Dan jarang mungkin untuk menggunakan data yang ditandai dari daerah lain karena perbedaan kuat dalam struktur geologis.
Kami menerjemahkan di atas ke dalam bahasa bisnis.
Agar penggunaan jaringan saraf dapat dibenarkan secara ekonomi, perlu untuk meminimalkan jumlah interpretasi manual primer dan penyempurnaan hasil yang diperoleh. Tetapi mengurangi data untuk pelatihan jaringan akan berdampak negatif pada kualitas hasilnya. Jadi, bisakah jaringan saraf mempercepat dan memfasilitasi pekerjaan penerjemah dan meningkatkan kualitas gambar berlabel? Atau hanya mempersulit proses yang biasa?
Tujuan dari penelitian ini adalah upaya untuk menentukan volume minimum yang cukup dari data kubus seismik mark-up untuk jaringan saraf dan mengevaluasi hasil yang diperoleh. Kami mencoba menemukan jawaban untuk pertanyaan-pertanyaan berikut, yang seharusnya membantu "pemilik" hasil survei seismik dalam memutuskan interpretasi manual atau sebagian otomatis:
- Berapa banyak data yang diperlukan para ahli untuk mengikuti pelatihan jaringan saraf? Dan data apa yang harus dipilih untuk ini?
- Apa yang terjadi pada hasil seperti itu? Akankah penyempurnaan manual prediksi jaringan saraf diperlukan? Jika ya, seberapa rumit dan produktif?
Deskripsi umum percobaan dan data yang digunakan
Untuk percobaan, kami memilih salah satu masalah interpretasi, yaitu, tugas mengisolasi lapisan geologi pada bagian 2D kubus seismik (lihat Gambar 3). Kami telah mencoba untuk menyelesaikan masalah ini (lihat di
sini ) dan, menurut penulis, mendapat hasil yang baik untuk 1% dari irisan yang dipilih secara acak. Mengingat volume kubus, ini adalah 16 gambar. Namun, artikel tersebut tidak memberikan metrik untuk perbandingan dan tidak ada deskripsi metodologi pelatihan (fungsi kehilangan, pengoptimal, skema untuk mengubah kecepatan belajar, dll.), Yang membuat percobaan tidak dapat diproduksi kembali.
Selain itu, hasil yang disajikan di sana, menurut pendapat kami, tidak cukup untuk mendapatkan jawaban lengkap untuk pertanyaan yang diajukan. Apakah nilai ini optimal pada 1%? Atau mungkin untuk sampel irisan lain akan berbeda? Bisakah saya memilih lebih sedikit data? Apakah perlu mengambil lebih banyak? Bagaimana hasilnya akan berubah? Dll
Untuk percobaan, kami mengambil set data berlabel yang sama dari sektor Belanda di Laut Utara. Sumber data seismik tersedia di Open Seismic Repository:
Project Netherlands Offshore F3 Block website. Deskripsi singkat dapat ditemukan di
Silva et al. "Dataset Belanda: Dataset Publik Baru untuk Pembelajaran Mesin dalam Interpretasi Seismik .
"Karena dalam kasus kami, kami berbicara tentang irisan 2D, kami tidak menggunakan kubus 3D asli, tetapi “irisan” yang sudah dibuat, tersedia di sini:
Dataset Interpretasi F3 Belanda .
Selama percobaan, kami menyelesaikan tugas-tugas berikut:
- Kami melihat data sumber dan memilih irisan, yang kualitasnya paling dekat dengan penandaan manual.
- Kami mencatat arsitektur jaringan saraf, metodologi dan parameter pelatihan, dan prinsip pemilihan irisan untuk pelatihan dan validasi.
- Kami melatih 20 jaringan saraf identik pada volume data yang berbeda dari jenis irisan yang sama untuk membandingkan hasilnya.
- Kami melatih 20 jaringan saraf lain pada jumlah data yang berbeda dari berbagai jenis irisan untuk membandingkan hasilnya.
- Diperkirakan jumlah penyempurnaan manual yang diperlukan dari hasil perkiraan.
Hasil percobaan dalam bentuk metrik yang diperkirakan dan diprediksi oleh jaringan topeng irisan disajikan di bawah ini.
Tugas 1. Pemilihan data
Jadi, sebagai data awal, kami menggunakan inline dan garis silang kubus seismik dari sektor Belanda di Laut Utara. Analisis terperinci menunjukkan bahwa semuanya tidak berjalan lancar - ada banyak gambar dan topeng dengan artefak dan bahkan yang sangat terdistorsi (lihat Gambar 4 dan 5).

Gambar 4. Contoh topeng dengan artefak
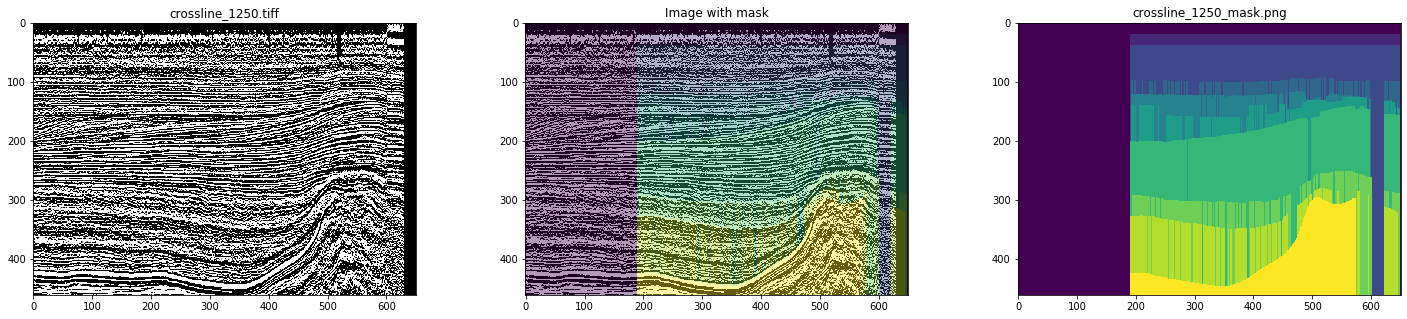
Gambar 5. Contoh topeng yang terdistorsi
Dengan penandaan manual, tidak ada yang akan diamati. Oleh karena itu, mensimulasikan pekerjaan penerjemah, untuk melatih jaringan, kami hanya memilih masker bersih, setelah melihat semua irisan. Akibatnya, 700 garis silang dan 400 inline dipilih.
Tugas 2. Memperbaiki parameter percobaan
Bagian ini menarik, pertama-tama, untuk spesialis dalam Ilmu Data, oleh karena itu, terminologi yang sesuai akan digunakan.
Karena inline dan crossline terdiri dari jejak seismik yang sama, dua hipotesis yang saling eksklusif dapat dikemukakan:
- Pelatihan dapat dilakukan hanya pada satu jenis irisan (misalnya, inline), menggunakan gambar jenis lain sebagai pilihan yang tertunda. Ini akan memberikan penilaian hasil yang lebih memadai, karena irisan yang tersisa dari jenis yang sama yang digunakan dalam pelatihan masih akan serupa dengan yang pelatihan.
- Untuk pelatihan, lebih baik menggunakan campuran irisan berbagai jenis, karena ini merupakan augmentasi siap pakai.
Lihat itu.
Selain itu, kesamaan irisan tetangga dengan jenis yang sama dan keinginan untuk mendapatkan hasil yang dapat direproduksi membawa kami pada strategi untuk memilih irisan untuk pelatihan dan validasi, bukan dengan prinsip yang sewenang-wenang, tetapi secara seragam di seluruh kubus, mis. sehingga irisan terpisah sejauh mungkin, dan karena itu mencakup variasi data maksimum.
Untuk validasi, 2 iris digunakan, juga didistribusikan secara merata antara gambar yang berdekatan dari sampel pelatihan. Sebagai contoh, untuk kasus sampel pelatihan 3 inline, sampel validasi terdiri dari 4 inline, untuk 3 inline dan 3 crossline, masing-masing dari 8 irisan.
Sebagai hasilnya, kami melakukan 2 seri pelatihan:
- Pelatihan sampel inline dari 3 hingga 20 irisan didistribusikan secara merata di atas kubus dengan verifikasi hasil prediksi jaringan pada inline yang tersisa dan pada semua garis silang. Selain itu, pelatihan dilakukan pada 80 dan 160 bagian.
- Pelatihan dalam sampel gabungan dari inline dan crossline 3-10 didistribusikan secara merata di seluruh kubus irisan masing-masing jenis dengan verifikasi hasil prediksi jaringan pada gambar yang tersisa. Selain itu, pelatihan dilakukan pada 40 + 40 dan 80 + 80 bagian.
Dengan pendekatan ini, perlu diperhitungkan bahwa ukuran sampel pelatihan dan validasi bervariasi secara signifikan, yang mempersulit perbandingan, tetapi volume gambar yang tersisa tidak berkurang sedemikian rupa sehingga dapat digunakan untuk menilai perubahan dalam hasil secara memadai.
Untuk mengurangi pelatihan ulang untuk sampel pelatihan, augmentasi digunakan dengan ukuran tanaman sewenang-wenang 448x64 dan gambar cermin di sepanjang sumbu vertikal dengan probabilitas 0,5.
Karena kami tertarik pada ketergantungan kualitas hasil hanya pada jumlah irisan dalam sampel pelatihan, preprocessing gambar dapat diabaikan. Kami menggunakan satu lapisan gambar PNG tanpa perubahan apa pun.
Untuk alasan yang sama, dalam kerangka percobaan ini, tidak perlu mencari arsitektur jaringan yang terbaik - hal yang utama adalah sama di setiap langkah. Kami memilih UNet yang sederhana namun mapan untuk tugas-tugas tersebut:

Gambar 6. Arsitektur jaringan
Fungsi kerugian terdiri dari kombinasi koefisien Jacquard dan entropi silang biner:
def jaccard_loss(y_true, y_pred): smoothing = 1. intersection = tf.reduce_sum(y_true * y_pred, axis = (1, 2)) union = tf.reduce_sum(y_true + y_pred, axis = (1, 2)) jaccard = (intersection + smoothing) / (union - intersection + smoothing) return 1. - tf.reduce_mean(jaccard) def loss(y_true, y_pred): return 0.75 * jaccard_loss(y_true, y_pred) + 0.25 * keras.losses.binary_crossentropy(y_true, y_pred)
Opsi pembelajaran lainnya:
keras.optimizers.SGD(lr = 0.01, momentum = 0.9, nesterov = True) keras.callbacks.EarlyStopping(monitor = 'val_loss', patience = 10), keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', patience = 5)
Untuk mengurangi pengaruh keacakan pilihan bobot awal pada hasil, jaringan dilatih pada 3 inline untuk 1 era. Semua pelatihan lain dimulai dengan bobot yang diterima.
Setiap jaringan dilatih di GeForce GTX 1060 6Gb selama 30-60 zaman. Pelatihan setiap era membutuhkan 10-30 detik tergantung pada ukuran sampel.
Tugas 3. Pelatihan satu jenis irisan (inline)
Seri pertama terdiri dari 18 pelatihan jaringan independen tentang 3-20 inline. Dan, meskipun kami hanya tertarik untuk memperkirakan koefisien Jacquard pada irisan yang tidak digunakan dalam pelatihan dan validasi, menarik untuk mempertimbangkan semua grafik.
Ingatlah bahwa hasil interpretasi untuk setiap irisan adalah 10 kelas (lapisan geologis), yang dalam gambar selanjutnya ditandai dengan angka dari 0 hingga 9.

Gambar 7. Koefisien Jacquard untuk set pelatihan

Gambar 8. Koefisien Jacquard untuk sampel validasi
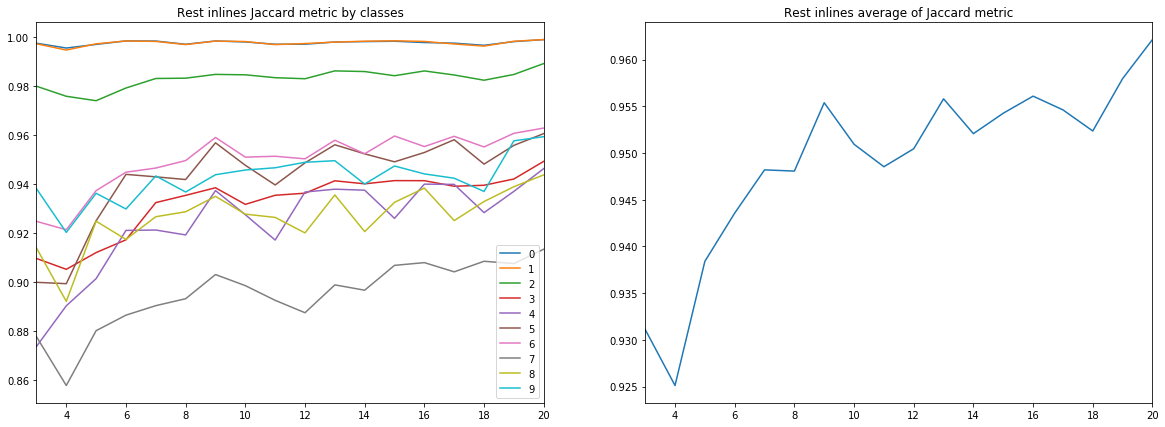
Gambar 9. Koefisien Jacquard untuk inline yang tersisa
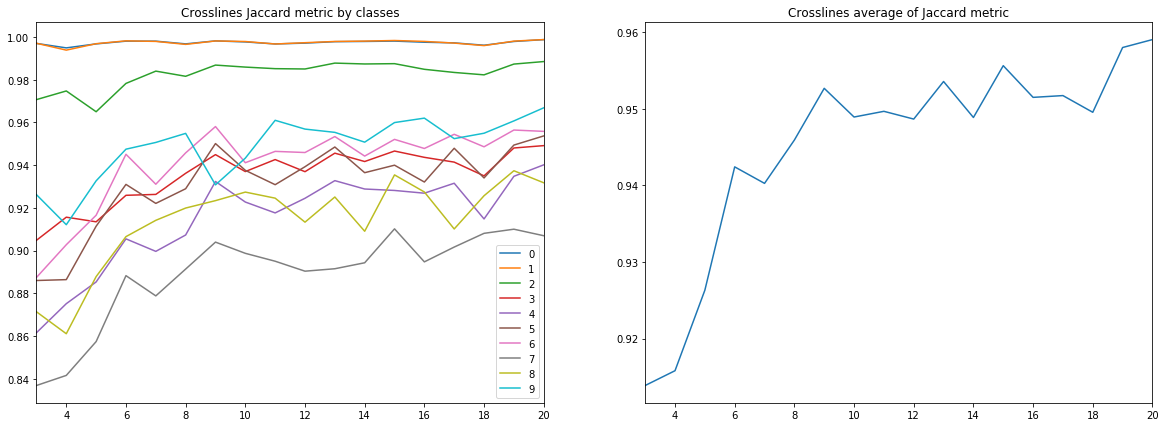
Gambar 10. Koefisien Jacquard untuk garis silang
Sejumlah kesimpulan dapat diambil dari diagram di atas.
Pertama, kualitas prakiraan, diukur dengan koefisien Jacquard, sudah pada 9 inlines mencapai nilai yang sangat tinggi, setelah itu terus tumbuh, tetapi tidak begitu intensif. Yaitu hipotesis kecukupan sejumlah kecil gambar berlabel untuk pelatihan jaringan saraf dikonfirmasi.
Kedua, hasil yang sangat tinggi diperoleh untuk garis silang, meskipun fakta bahwa hanya inline yang digunakan untuk pelatihan dan validasi - hipotesis kecukupan hanya satu jenis irisan juga dikonfirmasi. Namun, untuk kesimpulan akhir, Anda perlu membandingkan hasilnya dengan pelatihan tentang campuran inline dan crossline.
Ketiga, metrik untuk berbagai lapisan, mis. Kualitas pengakuan mereka sangat berbeda. Ini mengarah pada ide untuk memilih strategi pembelajaran yang berbeda, misalnya, menggunakan bobot atau jaringan tambahan untuk kelas yang lemah, atau skema “satu lawan semua”.
Dan akhirnya, perlu dicatat bahwa koefisien Jacquard tidak dapat memberikan deskripsi lengkap tentang kualitas hasilnya. Untuk mengevaluasi prediksi jaringan dalam kasus ini, lebih baik untuk melihat topeng sendiri untuk mengevaluasi kesesuaian mereka untuk revisi oleh penerjemah.
Gambar-gambar berikut menunjukkan markup oleh jaringan yang dilatih pada 10 inline. Kolom kedua, ditandai sebagai "GT mask" (Ground Truth mask), mewakili interpretasi target, yang ketiga adalah prediksi jaringan saraf.


Gambar 11. Contoh perkiraan jaringan untuk inline
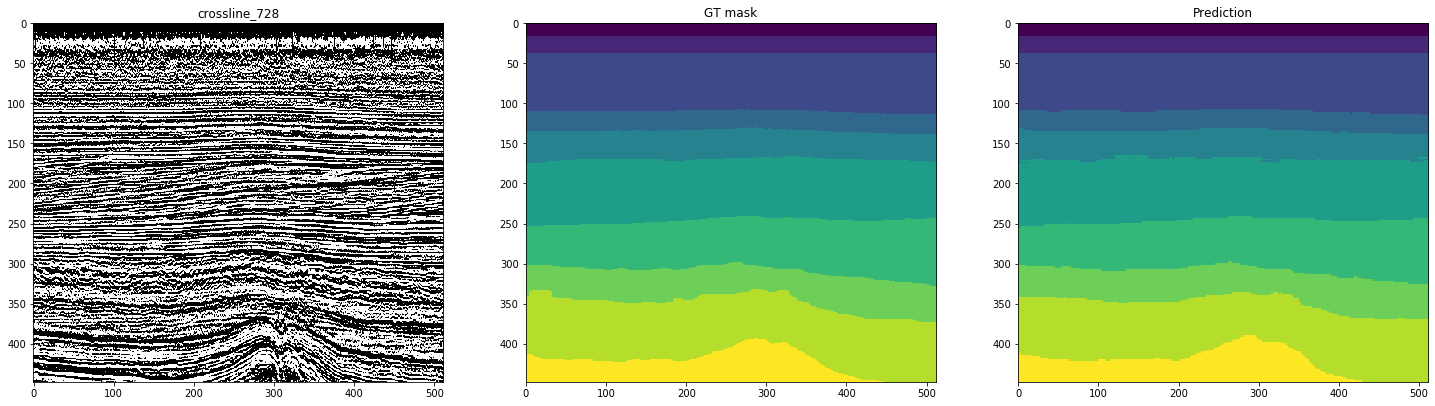

Gambar 12. Contoh perkiraan jaringan untuk garis silang
Dapat dilihat dari angka-angka bahwa, bersama dengan topeng yang cukup bersih, jaringan sulit untuk mengenali kasus-kasus kompleks bahkan pada inline itu sendiri. Dengan demikian, meskipun metrik cukup tinggi untuk 10 irisan, bagian dari hasil akan membutuhkan penyempurnaan yang signifikan.
Ukuran sampel yang kami anggap berfluktuasi sekitar 1% dari total volume data - dan ini sudah memungkinkan untuk menandai bagian dari irisan yang tersisa dengan cukup baik. Haruskah saya menambah jumlah bagian yang ditandai awalnya? Apakah ini akan memberikan peningkatan kualitas yang sebanding?
Mari kita perhatikan dinamika perubahan dalam hasil perkiraan oleh jaringan yang dilatih pada 5, 10, 15, 20, 80 (5% dari total volume kubus) dan 160 (10%) inline menggunakan bagian yang sama sebagai contoh.
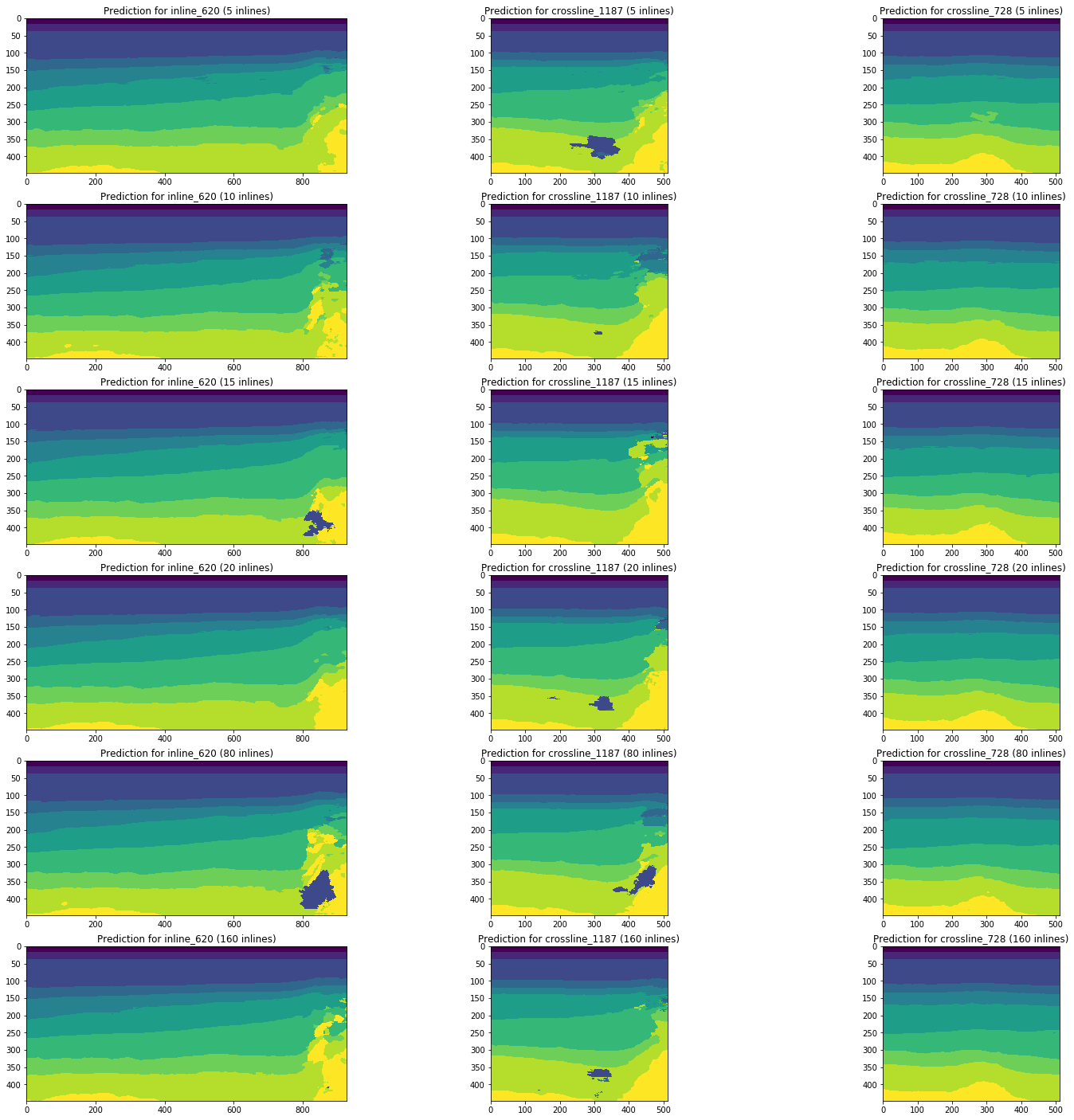
Gambar 13. Contoh prakiraan jaringan yang dilatih pada volume sampel pelatihan yang berbeda
Gambar 13 menunjukkan bahwa peningkatan volume sampel pelatihan sebesar 5 atau bahkan 10 kali tidak menyebabkan peningkatan yang signifikan. Irisan yang sudah dikenal dengan baik dalam 10 gambar pelatihan tidak menjadi lebih buruk.
Dengan demikian, bahkan jaringan sederhana tanpa penyesuaian dan pra-pemrosesan gambar dapat menafsirkan bagian dari irisan dengan kualitas yang cukup tinggi dengan sejumlah kecil gambar yang ditandai secara manual. Kami akan mempertimbangkan pertanyaan tentang pembagian interpretasi tersebut dan kompleksitas penyelesaian irisan yang tidak dikenal.
Pemilihan arsitektur, parameter jaringan dan pelatihan yang hati-hati, preprocessing gambar dapat meningkatkan hasil ini pada volume data tag yang sama. Tapi ini sudah di luar cakupan percobaan saat ini.
Tugas 4. Pelatihan tentang berbagai jenis irisan (inline dan crossline)
Sekarang mari kita bandingkan hasil seri ini dengan prakiraan yang diperoleh dengan melatih campuran inline dan crossline.
Diagram di bawah ini menunjukkan perkiraan koefisien Jacquard untuk sampel yang berbeda, termasuk, dibandingkan dengan hasil seri sebelumnya. Untuk perbandingan (lihat diagram kanan pada gambar), hanya sampel dengan volume yang sama yang diambil, mis. 10 inline vs 5 inline + 5 crosslines, dll.

Gambar 14. Koefisien Jacquard untuk set pelatihan

Gambar 15. Koefisien Jacquard untuk sampel validasi

Gambar 16. Koefisien Jacquard untuk inline yang tersisa

Gambar 17. Koefisien Jacquard untuk garis silang yang tersisa
Diagram dengan jelas menggambarkan bahwa menambahkan irisan dari jenis yang berbeda tidak meningkatkan hasil. Bahkan dalam konteks kelas (lihat Gambar 18), pengaruh garis-silang tidak diamati untuk ukuran sampel yang dipertimbangkan.

Gambar 18. Koefisien Jacquard untuk kelas yang berbeda (sepanjang sumbu X) dan ukuran dan komposisi sampel pelatihan yang berbeda
Untuk melengkapi gambar, kami membandingkan hasil perkiraan jaringan pada irisan yang sama:
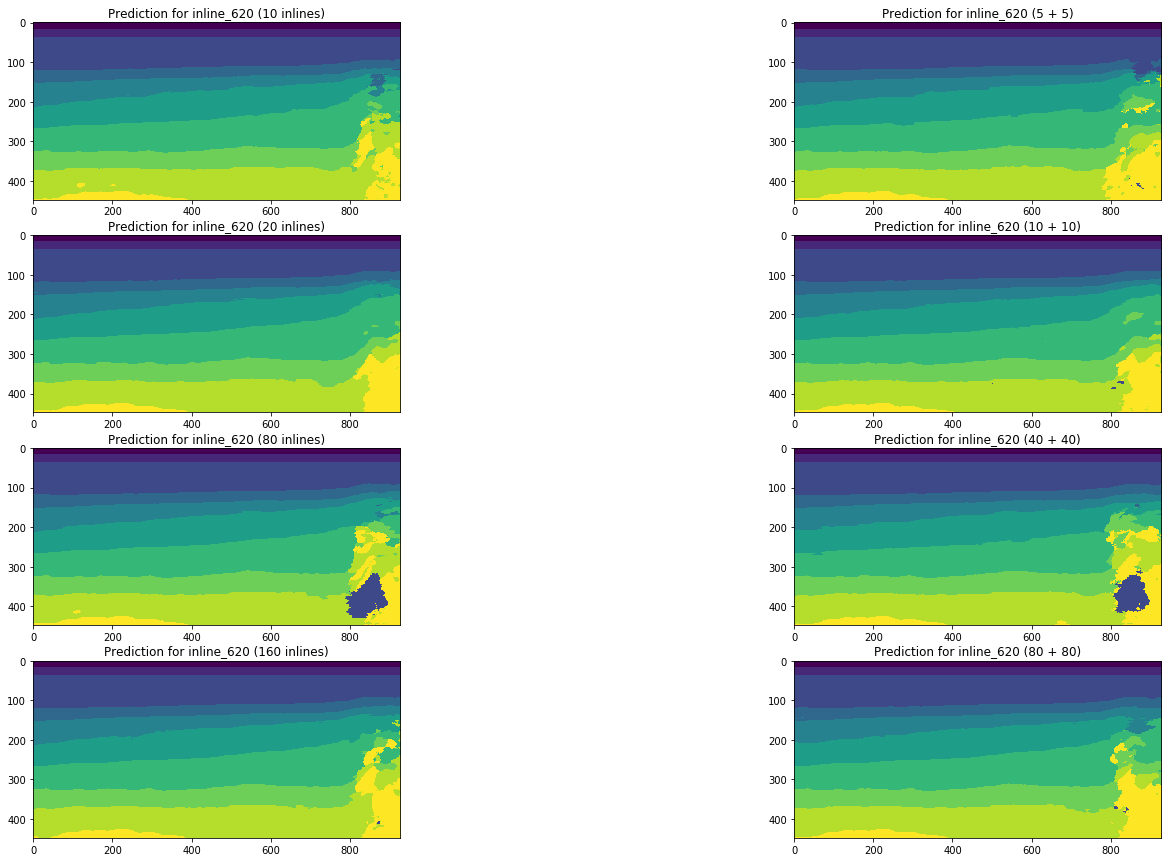
Gambar 19. Perbandingan perkiraan jaringan untuk inline
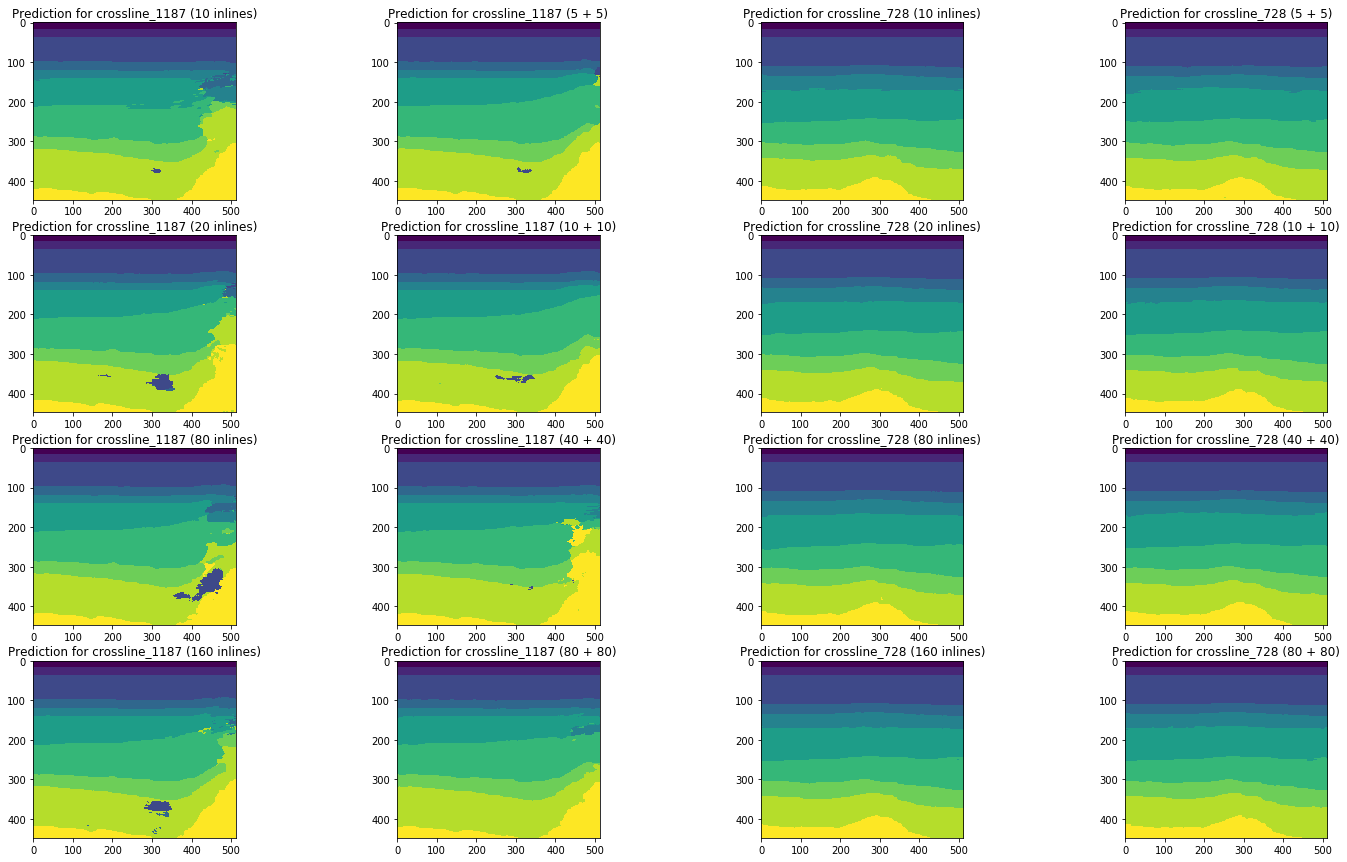
Gambar 20. Perbandingan perkiraan jaringan untuk garis silang
Perbandingan visual menegaskan asumsi bahwa menambahkan berbagai jenis irisan pada pelatihan tidak secara mendasar mengubah situasi. Beberapa perbaikan hanya dapat diamati untuk garis silang kiri, tetapi apakah itu bersifat global? Kami akan mencoba menjawab pertanyaan ini lebih lanjut.
Tugas 5. Penilaian volume penyempurnaan manual
Untuk kesimpulan akhir pada hasil, perlu memperkirakan jumlah penyempurnaan manual perkiraan jaringan yang diperoleh. Untuk melakukan ini, kami menentukan jumlah komponen yang terhubung (mis., Bintik padat dengan warna yang sama) pada setiap perkiraan yang diperoleh. Jika nilai ini 10, maka layer-layer tersebut dipilih dengan benar dan kita berbicara tentang maksimum koreksi horizon minor. Jika tidak banyak lagi, maka Anda hanya perlu "membersihkan" area kecil dari gambar. Jika ada lebih banyak dari mereka, maka semuanya buruk dan bahkan mungkin perlu tata letak yang lengkap.
Untuk pengujian, kami memilih 110 inline dan 360 crossline yang tidak digunakan dalam pelatihan jaringan mana pun yang dipertimbangkan.
Tabel 1. Statistik rata-rata untuk kedua jenis irisan
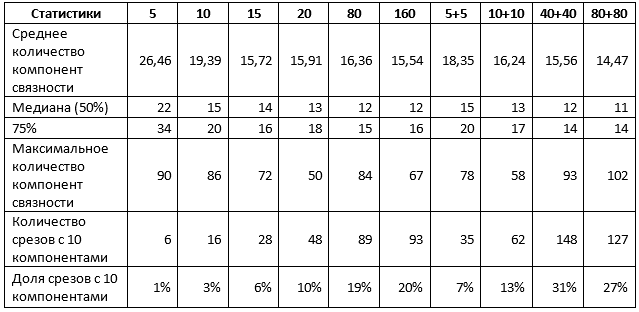
Tabel 1 mengkonfirmasi beberapa hasil sebelumnya. Secara khusus, ketika menggunakan irisan 1% untuk pelatihan, tidak ada perbedaan, gunakan satu jenis irisan atau keduanya, dan hasilnya dapat dikarakterisasi sebagai berikut:
- sekitar 10% dari ramalan mendekati ideal, mis. tidak membutuhkan lebih dari penyesuaian pada setiap bagian dari cakrawala;
- 50% ramalan berisi tidak lebih dari 15 tempat, mis. tidak lebih dari 5 ekstra;
- 75% perkiraan berisi tidak lebih dari 20 tempat, mis. tidak lebih dari 10 ekstra;
- 25% sisanya dari perkiraan membutuhkan penyempurnaan yang lebih substansial, termasuk, mungkin, desain ulang irisan individu yang lengkap.
Peningkatan ukuran sampel hingga 5% mengubah situasi. Secara khusus, jaringan yang dilatih tentang campuran bagian menunjukkan indikator yang jauh lebih tinggi, meskipun nilai maksimum komponen juga meningkat, yang menunjukkan tampilan interpretasi terpisah dengan kualitas yang sangat buruk. Namun, jika Anda menambah sampel sebanyak 5 kali dan menggunakan campuran irisan:
- sekitar 30% dari ramalan mendekati ideal, mis. tidak membutuhkan lebih dari penyesuaian pada setiap bagian dari cakrawala;
- 50% ramalan berisi tidak lebih dari 12 tempat, yaitu tidak lebih dari 2 ekstra;
- 75% perkiraan berisi tidak lebih dari 14 tempat, yaitu tidak lebih dari 4 ekstra;
- 25% sisanya dari perkiraan membutuhkan penyempurnaan yang lebih substansial, termasuk, mungkin, desain ulang irisan individu yang lengkap.
Peningkatan lebih lanjut dalam ukuran sampel tidak mengarah pada hasil yang lebih baik.
Secara umum, untuk kubus data yang kami periksa, kami dapat menarik kesimpulan tentang kecukupan 1-5% dari total volume data untuk mendapatkan hasil yang baik dari jaringan saraf.
Menurut data tersebut, dalam hubungannya dengan metrik dan ilustrasi di atas, sudah dimungkinkan untuk menarik kesimpulan tentang kelayakan menggunakan jaringan saraf untuk membantu penerjemah dan tentang hasil yang akan ditangani oleh spesialis.
Kesimpulan
Jadi, sekarang kita dapat menjawab pertanyaan yang diajukan di awal artikel, menggunakan hasil yang diperoleh pada contoh kubus seismik Laut Utara:
Berapa banyak data yang diperlukan para ahli untuk mengikuti pelatihan jaringan saraf? Dan data apa yang harus saya pilih?Untuk mendapatkan prakiraan jaringan yang bagus, cukup dengan pra-tandai 1-5% dari total jumlah irisan. Peningkatan volume lebih lanjut tidak mengarah pada peningkatan hasil, sebanding dengan peningkatan jumlah data yang ditandai sebelumnya. Untuk mendapatkan markup yang lebih baik pada volume sekecil itu menggunakan jaringan saraf, Anda perlu mencoba pendekatan lain, misalnya, menyempurnakan arsitektur dan strategi pembelajaran, preprocessing gambar, dll.
Untuk penandaan awal, ada baiknya memilih irisan kedua jenis - inline dan crossline.
Apa yang terjadi pada hasil seperti itu? Akankah penyempurnaan manual prediksi jaringan saraf diperlukan? Jika ya, seberapa rumit dan produktif?
Akibatnya, sebagian besar gambar yang diberi label oleh jaringan saraf seperti itu tidak akan memerlukan perbaikan yang paling signifikan, yang terdiri dari koreksi zona individu yang tidak dikenal dengan baik. Di antara mereka akan ada interpretasi seperti itu yang tidak akan membutuhkan koreksi. Dan hanya untuk gambar tunggal, Anda mungkin memerlukan tata letak manual baru.
Tentu saja, ketika mengoptimalkan algoritma pembelajaran dan parameter jaringan, kemampuan prediktifnya dapat ditingkatkan. Dalam percobaan kami, solusi masalah tersebut tidak dimasukkan.
Selain itu, hasil dari satu studi pada satu kubus seismik tidak boleh digeneralisasi tanpa alasan - justru karena keunikan masing-masing kumpulan data. Tetapi hasil ini adalah konfirmasi dari percobaan yang dilakukan oleh penulis lain, dan dasar untuk perbandingan dengan penelitian kami selanjutnya, yang juga akan kami tulis sebentar lagi.
Ucapan Terima Kasih
Dan pada akhirnya, saya ingin mengucapkan terima kasih kepada rekan-rekan saya dari
MaritimeAI (terutama Andrey Kokhan) dan
ODS untuk komentar dan bantuan yang berharga!
Daftar sumber yang digunakan:
- Bas Peters, Eldad Haber, Justin Granek. Jaringan saraf untuk ahli geofisika dan aplikasinya untuk interpretasi data seismik
- Hao Wu, Bo Zhang. Sebuah jaringan neural encoder-decoder convolutional yang mendalam dalam membantu pelacakan horizon seismik
- Thilo Wrona, Indranil Pan, Robert L. Gawthorpe, dan Haakon Fossen. Analisis fasies seismik menggunakan pembelajaran mesin
- Reinaldo Mozart Silva, Lais Baroni, Rodrigo S. Ferreira, Daniel Civitarese, Daniela Szwarcman, Emilio Vital Brazil. Netherlands Dataset: Dataset Publik Baru untuk Pembelajaran Mesin dalam Interpretasi Seismik