Artikel ini terdiri dari dua bagian:
- Deskripsi singkat tentang beberapa arsitektur jaringan untuk mendeteksi objek dalam segmentasi gambar dan gambar dengan tautan yang paling dapat dipahami ke sumber daya bagi saya. Saya mencoba memilih penjelasan video dan lebih disukai dalam bahasa Rusia.
- Bagian kedua adalah upaya untuk memahami arah pengembangan arsitektur jaringan saraf. Dan teknologi berdasarkan pada mereka.

Gambar 1 - Memahami arsitektur jaringan saraf tidak mudah
Semuanya dimulai dengan fakta bahwa ia membuat dua aplikasi demo untuk mengklasifikasikan dan mendeteksi objek pada ponsel Android:
- Demo back-end , ketika data diproses di server dan ditransfer ke telepon. Klasifikasi gambar dari tiga jenis beruang: coklat, hitam dan teddy.
- Demo front-end ketika data diproses pada ponsel itu sendiri. Deteksi objek dari tiga jenis: hazelnut, buah ara dan kurma.
Ada perbedaan antara tugas mengklasifikasikan gambar, mendeteksi objek dalam suatu gambar, dan mengelompokkan gambar . Oleh karena itu, ada kebutuhan untuk mengetahui arsitektur jaringan saraf mana yang mendeteksi objek dalam gambar dan mana yang dapat disegmentasi. Saya menemukan contoh arsitektur berikut dengan tautan yang paling dapat dipahami untuk sumber daya bagi saya:
- Serangkaian arsitektur berdasarkan R-CNN ( R egions dengan C onvolution N etural N etworks fitur): R-CNN, Fast R-CNN, R-CNN lebih cepat , R-CNN , Mask R-CNN . Untuk mendeteksi objek dalam gambar menggunakan mekanisme Jaringan Proposal Wilayah (RPN), kotak pembatas dialokasikan. Awalnya, mekanisme Pencarian Selektif lebih lambat digunakan sebagai pengganti RPN. Kemudian, daerah terbatas terpilih diumpankan ke input jaringan saraf normal untuk klasifikasi. Dalam arsitektur R-CNN ada siklus "untuk" enumerasi eksplisit atas wilayah terbatas, total hingga 2000 dijalankan melalui jaringan internal AlexNet. Karena loop "untuk" yang eksplisit, kecepatan pemrosesan gambar melambat. Jumlah siklus eksplisit, berjalan melalui jaringan saraf internal, berkurang dengan setiap versi baru dari arsitektur, dan puluhan perubahan lainnya dilakukan untuk meningkatkan kecepatan dan untuk mengganti tugas mendeteksi objek dengan segmentasi objek di Mask R-CNN.
- YOLO ( Y ou O nly L ook O nce) adalah jaringan saraf pertama yang mengenali objek secara real time pada perangkat seluler. Fitur khas: membedakan objek dalam sekali proses (lihat sekali saja). Artinya, tidak ada loop "untuk" eksplisit dalam arsitektur YOLO, itulah sebabnya jaringannya cepat. Sebagai contoh, ini adalah analogi: di NumPy tidak ada loop "untuk" eksplisit dalam operasi dengan matriks, yang diimplementasikan di NumPy pada tingkat arsitektur yang lebih rendah melalui bahasa pemrograman C. YOLO menggunakan kisi-kisi jendela yang telah ditentukan. Untuk mencegah objek yang sama dari terdeteksi beberapa kali, koefisien tumpang tindih jendela (IoU, Intersection of Union) digunakan. Arsitektur ini bekerja dalam jangkauan luas dan memiliki ketahanan tinggi: model dapat dilatih dalam foto, tetapi pada saat yang sama bekerja dengan baik dalam lukisan yang dilukis.
- SSD ( S ingle S hot MultiBox D etector) - "peretasan" arsitektur YOLO yang paling sukses (misalnya, penindasan non-maksimum) digunakan dan yang baru ditambahkan untuk membuat jaringan saraf lebih cepat dan lebih akurat. Fitur khas: membedakan objek dalam satu kali lari menggunakan kotak jendela yang diberikan (kotak default) pada piramida gambar. Piramida gambar dikodekan dalam tensor konvolusi selama operasi konvolusi dan penyatuan berturut-turut (dengan operasi penyatuan maks, dimensi spasial berkurang). Dengan cara ini, objek besar dan kecil ditentukan dalam satu jaringan yang dijalankan.
- MobileSSD ( Mobile NetV2 + SSD ) adalah kombinasi dari dua arsitektur jaringan saraf. Jaringan MobileNetV2 pertama adalah cepat dan meningkatkan akurasi pengenalan. MobileNetV2 digunakan sebagai pengganti VGG-16, yang awalnya digunakan dalam artikel asli . Jaringan SSD kedua menentukan lokasi objek dalam gambar.
- SqueezeNet adalah jaringan saraf yang sangat kecil namun akurat. Dengan sendirinya, itu tidak memecahkan masalah mendeteksi objek. Namun, dapat digunakan dengan kombinasi berbagai arsitektur. Dan digunakan pada perangkat seluler. Ciri khasnya adalah bahwa pertama-tama data dikompresi menjadi empat filter konvolusional 1 × 1, dan kemudian diperluas menjadi empat filter konvolusional 1 × 1 dan empat 3 × 3. Salah satu iterasi seperti ekspansi kompresi data disebut "Modul Api".
- DeepLab (Segmentasi Gambar Semantik dengan Jaring Konvolusional Dalam) - segmentasi objek dalam gambar. Ciri khas arsitektur ini adalah konvolusi encer, yang menjaga resolusi spasial. Ini diikuti oleh tahap pasca-pemrosesan hasilnya menggunakan bidang acak bersyarat grafis, yang memungkinkan Anda untuk menghilangkan noise kecil dalam segmentasi dan meningkatkan kualitas gambar yang tersegmentasi. Di belakang nama yang tangguh "model probabilistik grafis" adalah filter Gaussian biasa, yang diperkirakan sekitar lima poin.
- Saya mencoba untuk memahami perangkat RefineDet (Single-Shot Refine dan Neural Network for Object Detection), tetapi saya mengerti sangat sedikit.
- Saya juga melihat bagaimana teknologi perhatian bekerja: video1 , video2 , video3 . Ciri khas arsitektur "perhatian" adalah alokasi otomatis wilayah yang semakin meningkat perhatiannya terhadap gambar (RoI, R e sien dari yang lain) menggunakan jaringan saraf yang disebut Unit Perhatian. Daerah dengan perhatian yang meningkat mirip dengan daerah terbatas (kotak pembatas), tetapi tidak seperti mereka, mereka tidak terpaku pada gambar dan mungkin memiliki batas yang buram. Kemudian, dari daerah peningkatan perhatian, fitur (fitur) dibedakan yang "diumpankan" ke jaringan saraf berulang dengan arsitektur LSDM, GRU, atau Vanilla RNN . Jaringan saraf rekursif mampu menganalisis hubungan tanda-tanda secara berurutan. Jaringan saraf rekursif pada awalnya digunakan untuk menerjemahkan teks ke bahasa lain, dan sekarang untuk menerjemahkan gambar menjadi teks dan teks menjadi gambar .
Ketika saya mempelajari arsitektur ini, saya menyadari bahwa saya tidak mengerti apa-apa . Dan intinya bukan bahwa jaringan saraf saya memiliki masalah dengan mekanisme perhatian. Menciptakan semua arsitektur ini tampak seperti semacam hackathon besar di mana penulis bersaing dalam peretasan. Hack adalah solusi cepat untuk tugas perangkat lunak yang sulit. Artinya, tidak ada hubungan logis yang terlihat dan dapat dipahami antara semua arsitektur ini. Semua yang menyatukan mereka adalah seperangkat peretasan paling sukses yang mereka pinjam satu sama lain, ditambah operasi konvolusi umum dengan umpan balik (pembalikan kesalahan, backpropagation). Tidak ada pemikiran sistemik ! Tidak jelas apa yang harus diubah dan bagaimana mengoptimalkan pencapaian yang ada.
Sebagai akibat dari kurangnya koneksi logis antara peretasan, mereka sangat sulit untuk diingat dan dipraktikkan. Ini adalah pengetahuan yang terpecah-pecah. Dalam kasus terbaik, beberapa momen menarik dan tak terduga diingat, tetapi sebagian besar dari apa yang dipahami dan tidak dapat dipahami hilang dari ingatan dalam beberapa hari. Akan lebih baik jika dalam seminggu saya ingat setidaknya nama arsitekturnya. Tetapi butuh beberapa jam dan bahkan berhari-hari waktu kerja untuk membaca artikel dan menonton video ulasan!
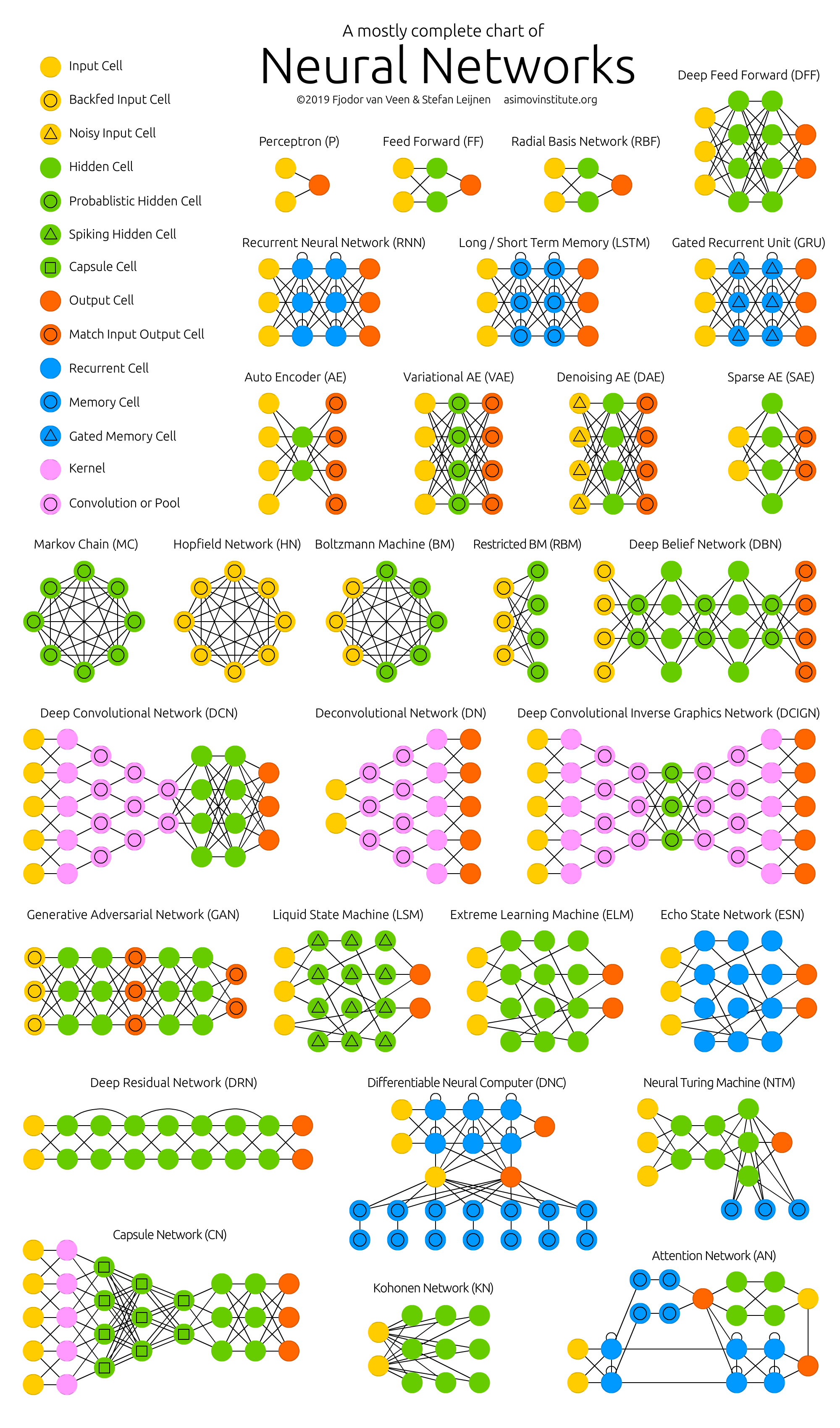
Gambar 2 - Kebun binatang jaringan saraf
Kebanyakan penulis artikel ilmiah, menurut pendapat pribadi saya, melakukan segala yang mungkin sehingga bahkan pengetahuan yang terpecah-pecah ini tidak dipahami oleh pembaca. Tetapi partisipatif dalam sepuluh kalimat kalimat dengan formula yang diambil "dari langit-langit" adalah topik untuk artikel terpisah ( terbitkan atau musnah masalah).
Untuk alasan ini, menjadi perlu untuk mensistematisasikan informasi pada jaringan saraf dan, dengan demikian, meningkatkan kualitas pemahaman dan menghafal. Oleh karena itu, topik utama analisis teknologi individu dan arsitektur jaringan saraf tiruan adalah tugas berikut: untuk mengetahui di mana semua ini bergerak , dan bukan perangkat jaringan saraf tertentu secara terpisah.
Kemana semua ini terjadi? Hasil utama:
- Jumlah startup di bidang pembelajaran mesin telah menurun tajam dalam dua tahun terakhir. Alasan yang mungkin: "jaringan saraf telah berhenti menjadi sesuatu yang baru."
- Setiap orang akan dapat membuat jaringan saraf yang berfungsi untuk memecahkan masalah sederhana. Untuk melakukan ini, ambil model jadi dari "model zoo" dan latih lapisan terakhir dari jaringan saraf ( transfer learning ) pada data jadi dari Google Dataset Search atau dari 25 ribu kumpulan data Kaggle di cloud Jupyter Notebook gratis.
- Produsen besar jaringan saraf mulai menciptakan "kebun binatang model" (model zoo). Dengan menggunakannya, Anda dapat dengan cepat membuat aplikasi komersial: TF Hub untuk TensorFlow, MMDetection untuk PyTorch, Detectron for Caffe2, chainer-modelzoo untuk Chainer dan lainnya .
- Jaringan saraf real-time pada perangkat seluler. 10 hingga 50 frame per detik.
- Penggunaan jaringan saraf di telepon (TF Lite), di peramban (TF.js) dan dalam barang-barang rumah tangga (IoT, Internet dan engsel T ). Terutama pada ponsel yang sudah mendukung jaringan saraf pada tingkat perangkat keras (neuroaccelerators).
- “Setiap perangkat, pakaian, dan bahkan mungkin makanan akan memiliki alamat IP-v6 dan berkomunikasi satu sama lain” - Sebastian Trun .
- Peningkatan publikasi pembelajaran mesin telah mulai melampaui hukum Moore (dua kali lipat setiap dua tahun) sejak 2015. Jelas, artikel analisis jaringan saraf diperlukan.
- Teknologi berikut semakin populer:
- PyTorch - Popularitas tumbuh dengan cepat dan tampaknya menyalip TensorFlow.
- Pilihan otomatis hiperparameter AutoML - popularitas tumbuh dengan lancar.
- Penurunan akurasi dan peningkatan kecepatan komputasi secara bertahap: logika fuzzy , peningkatan algoritma, perhitungan (perkiraan) yang tidak akurat, kuantisasi (ketika bobot jaringan saraf dikonversi menjadi bilangan bulat dan dikuantisasi), neuroaccelerators.
- Terjemahan gambar menjadi teks dan teks menjadi gambar .
- Membuat objek tiga dimensi pada video , sekarang dalam waktu nyata.
- Hal utama dalam DL adalah banyak data, tetapi mengumpulkan dan menandainya tidak mudah. Oleh karena itu, anotasi otomatis untuk jaringan saraf menggunakan jaringan saraf sedang berkembang.
- Dengan jaringan saraf, Ilmu Komputer tiba-tiba menjadi ilmu eksperimental dan krisis reproduktifitas muncul.
- Uang TI dan popularitas jaringan saraf muncul bersamaan ketika komputasi menjadi nilai pasar. Ekonomi emas dan valuta asing menjadi komputasi mata uang emas . Lihat artikel saya tentang ekonofisika dan alasan kemunculan uang IT.
Secara bertahap, metodologi pemrograman ML / DL baru (Machine Learning & Deep Learning) muncul, yang didasarkan pada presentasi program sebagai kumpulan model jaringan saraf terlatih.
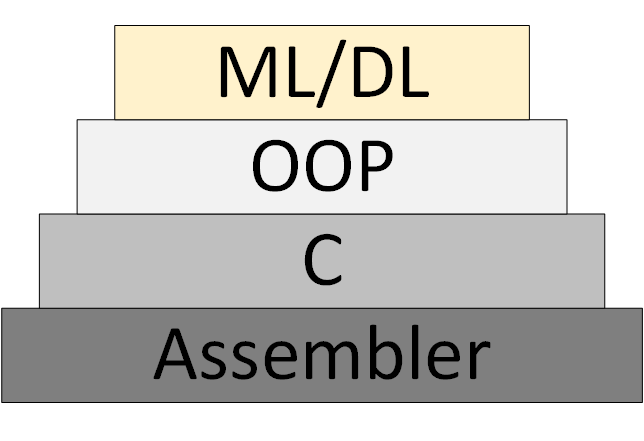
Gambar 3 - ML / DL sebagai metodologi pemrograman baru
Namun, "teori jaringan saraf" tidak muncul, dalam kerangka yang orang dapat berpikir dan bekerja secara sistematis. Apa yang sekarang disebut "teori" sebenarnya adalah eksperimental, algoritma heuristik.
Tautan ke sumber saya dan bukan hanya:
- Buletin Sains Data. Sebagian besar pemrosesan gambar. Siapa yang mau menerima, biarkan dia mengirim e-mail (foobar167 <gaff-gaf> gmail <dot> com). Saya mengirim tautan ke artikel dan video saat materi terkumpul.
- Daftar umum kursus dan artikel yang telah saya ikuti dan ingin saya ikuti.
- Kursus dan video untuk pemula , yang darinya layak untuk mulai mempelajari jaringan saraf. Ditambah brosur "Pengantar pembelajaran mesin dan jaringan saraf tiruan . "
- Alat yang berguna di mana setiap orang akan menemukan sesuatu yang menarik untuk diri mereka sendiri.
- Saluran video untuk analisis artikel ilmiah tentang Ilmu Data ternyata sangat berguna. Temukan, berlangganan, dan kirim tautan ke kolega Anda dan saya juga. Contoh:
Terima kasih atas perhatian anda!