Sistem kontrol versi telah lama menjadi alat harian bagi pengembang. Dalam monorepositori besar, persyaratan untuk mereka sangat spesifik. Karena itu, perusahaan dapat mengadaptasi solusi yang ada, seperti yang dilakukan Facebook dengan Mercurial dan Microsoft dengan Git, atau mengembangkan sistem mereka sendiri: Piper dan CitC di Google dan Arc VCS di Yandex.
Dalam laporan tersebut, pengembang Vladimir Kikhtenko
kikht memberi tahu mengapa Yandex membutuhkan sistem kontrol versinya sendiri dan cara kerjanya. Pertimbangkan dari sisi pengembang biasa: cara mengakses kode sumber, sisihkan cabang untuk pengembangan, dan mengintegrasikan perubahan ke dalam basis kode umum. Kami melihat di bawah tenda - kami belajar tentang representasi internal data dan tampilannya dalam sistem file virtual dengan salinan yang berfungsi. Kami akan membahas kesulitan dalam mengimplementasikan fungsi VCS dalam sistem file virtual dan ketika memuat data dengan malas. Mari kita bicara tentang cara memastikan keandalan infrastruktur server repositori.
Pada akhirnya, Anda dapat melihat catatan laporan tidak resmi.
- Selamat siang semuanya, namaku Vladimir. Anda semua mendengar pidato tentang tidak menulis sepeda. Laporan saya akan berada di sisi lain dari barikade.
Memang, Yandex memiliki monorepositori di mana ada banyak kode. Dan kami sampai pada kesimpulan bahwa kami sedang mengembangkan sistem kontrol versi kami sendiri.

Bagaimana kita bisa hidup seperti itu? Secara historis, monorepositori ini tinggal bersama kami di SVN. Ini praktik pengembangan berbasis trunk. Tidak ada cabang dengan sedikit pengecualian. Semua kode harus terlebih dahulu masuk ke bagasi, dan kemudian menjadi penuh.
Dengan pertumbuhan repositori, satu-satunya cara yang mungkin untuk bekerja dengannya adalah checkout selektif, karena didukung dalam SVN. Mengunggah seluruh repositori ke diri Anda sendiri tidak sepenuhnya mustahil, tetapi bekerja dengannya sangat sulit.

Apa skala masalah kita? Berikut adalah beberapa angka: 6 juta komit, hampir 2 juta file individual. Ukuran total dengan seluruh riwayat repositori adalah 2 TB. Untuk memperjelas apa arti angka-angka ini dibandingkan dengan repositori tipikal lainnya, inilah grafik. Median GitHub adalah ukuran repositori median pada GitHub, 1 MB. Persentil ke-90 di GitHub adalah apa yang oleh rekan-rekan saya disebut sebagai "gudang putra pacar ibu saya." Dan yang lainnya adalah gudang besar yang terkenal.
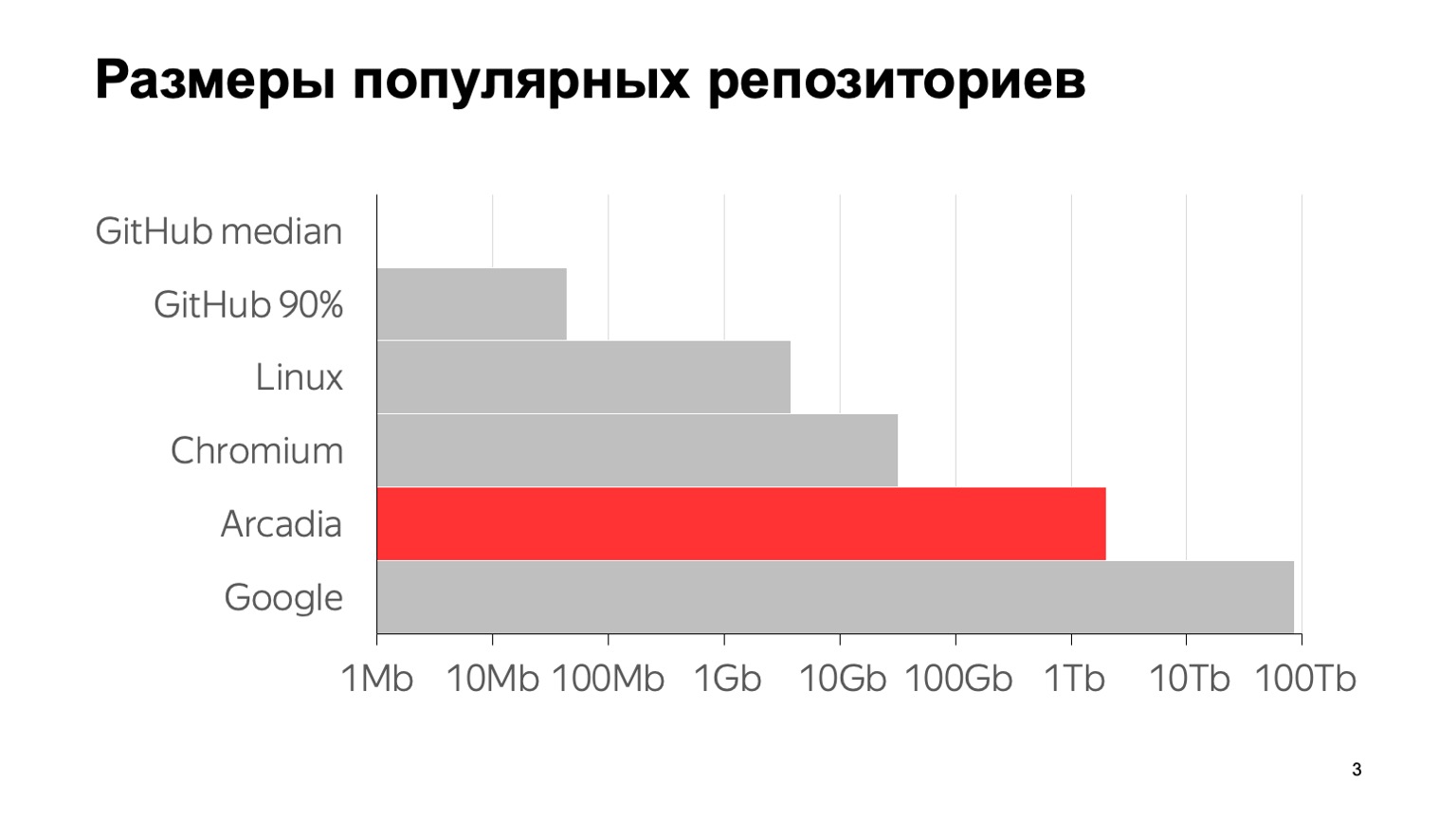
Sejauh yang saya tahu, repositori terbesar di dunia adalah dengan Google. Perkiraan ukurannya diberikan dari sebuah artikel di 2015 - mungkin sejak itu mereka telah tumbuh. Seperti yang Anda lihat, skalanya adalah logaritmik. Dapat dilihat bahwa kita juga cukup besar.
Bagaimana cara kerja berbagai sistem kontrol versi ketika mencoba mengunduh seluruh repositori ini? Secara alami, kami tidak segera mulai mengembangkan sistem kontrol versi kami. Kami mencoba mengonversi repositori kami ke sistem yang berbeda. Upaya paling serius dilakukan dengan Mercurial. Dan hasil dari waktu operasi khas masih tidak cocok untuk kita.
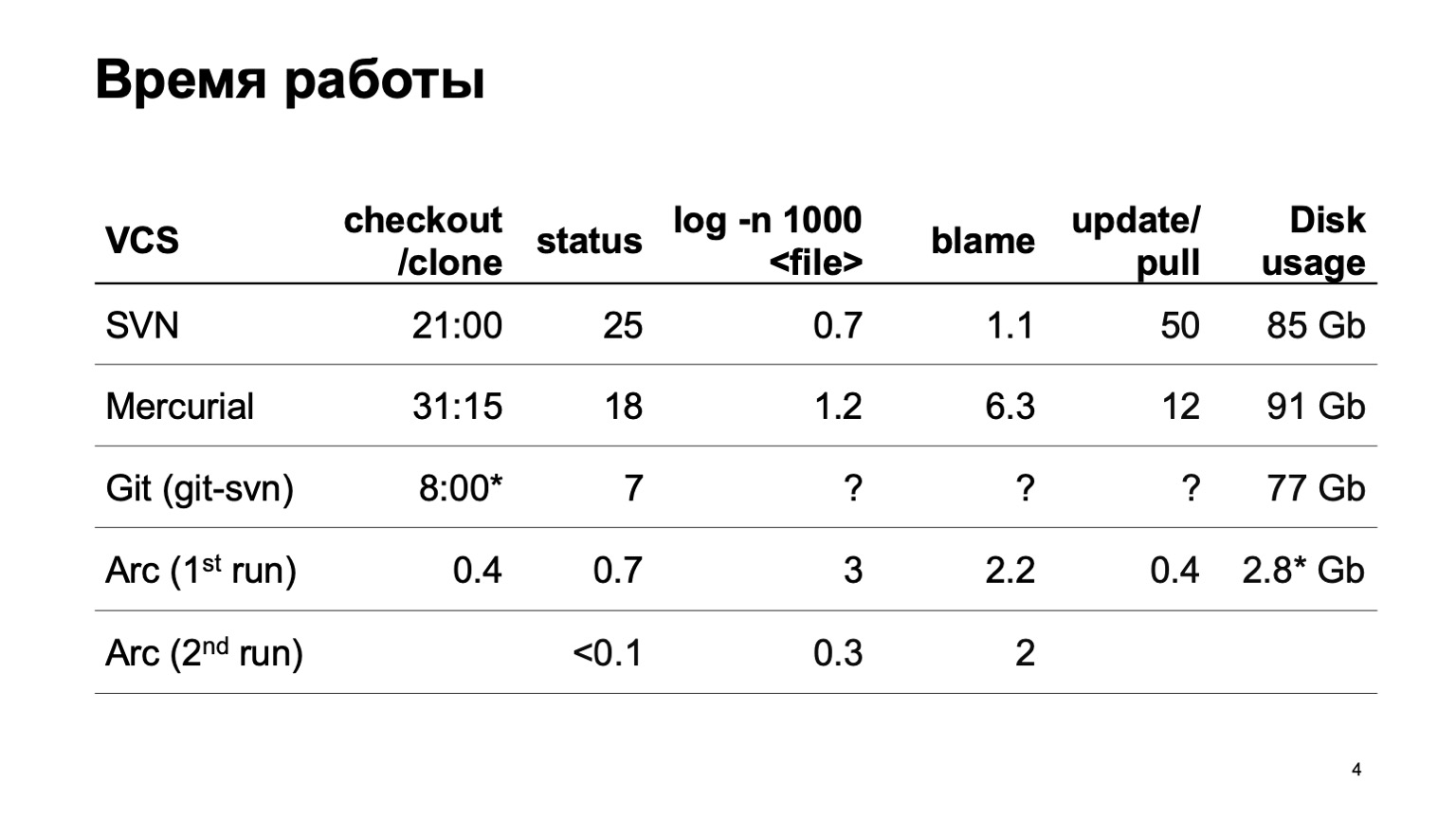
Sayangnya, selama persiapan laporan, git-svn tidak dapat mengonversi seluruh gudang kami. Mengonversi beberapa iris dari sejumlah kecil komitmen, jadi saya tidak dapat memperkirakan berapa banyak operasi yang terkait dengan pekerjaan sejarah. Dalam satu segmen mereka cepat, dan bagaimana untuk 6 juta komit tidak terlalu jelas.
Pada akhirnya adalah angka untuk sistem kontrol versi kami. Anda dapat langsung mendapatkan salinan yang berfungsi. Pada awal pertama, operasi log sedikit melambat, pada awal kedua, semuanya bekerja dengan cepat.
Dan digit terakhir. Karena sistem kontrol versi kami memuat semua data dengan malas, hanya kode sumber yang benar-benar kami kerjakan, yang benar-benar kami gunakan, yang ada di disk. Ini jauh lebih sedikit daripada mengunduh keseluruhan.

Bagaimana kita mencapai ini? Fitur utama: copy pekerjaan yang kita buat bukanlah file asli pada disk. Ini adalah sistem file virtual. Di Linux dan Mac, ini dilakukan dengan sekering, pada Windows dengan ProjFS. Kami memuat semua data dengan malas, sehingga ruang disk yang digunakan sebanyak yang kami butuhkan, kami tidak mencoba memuat semuanya terlebih dahulu. Dan kami melakukan segala macam operasi berat ke server. Secara khusus - pengoperasian log dan beberapa lagi.

Antarmuka sistem kontrol versi kami, pada umumnya, mengulangi Git, jadi saya tidak akan menunjukkan seperti apa alur kerja yang khas. Bayangkan Git. Semuanya sama: checkout untuk mendapatkan revisi yang diinginkan, cabang untuk membuat cabang, komit untuk komit, simpanan juga didukung dengan cara yang sama. Apa yang diberikan pendekatan ini? Kami secara signifikan mengurangi ambang entri. Sebagian besar pengembang di dalam dan di luar Yandex dapat bekerja dengan Git. Mereka tidak harus belajar sesuatu yang baru.
Di sisi lain, kami tidak memiliki tujuan melakukan penggantian pengganti untuk Git. Saya akan membicarakan ini nanti dengan lebih rinci. Untuk mendukung semua variasi tim git tampaknya gila, kita hampir tidak membutuhkan semuanya.

Saya akan ceritakan sedikit tentang bagian dalam, tentang cara kerjanya. Mari kita mulai dengan model data. Model data kami sangat mirip dengan yang geografis, dengan beberapa perbedaan. Dengan cara yang sama, semua objek yang kita buat di dalamnya tidak dapat diubah, mereka dialamatkan oleh hash dari konten mereka, dan di dalamnya mereka disimpan dalam flatbuffer.

Seperti apa strukturnya? Ada objek komit, masing-masing komit memiliki leluhur yang terpisah atau beberapa. Dan dengan cara ini mereka membangun beberapa cerita DAG (grafik asiklik terarah).
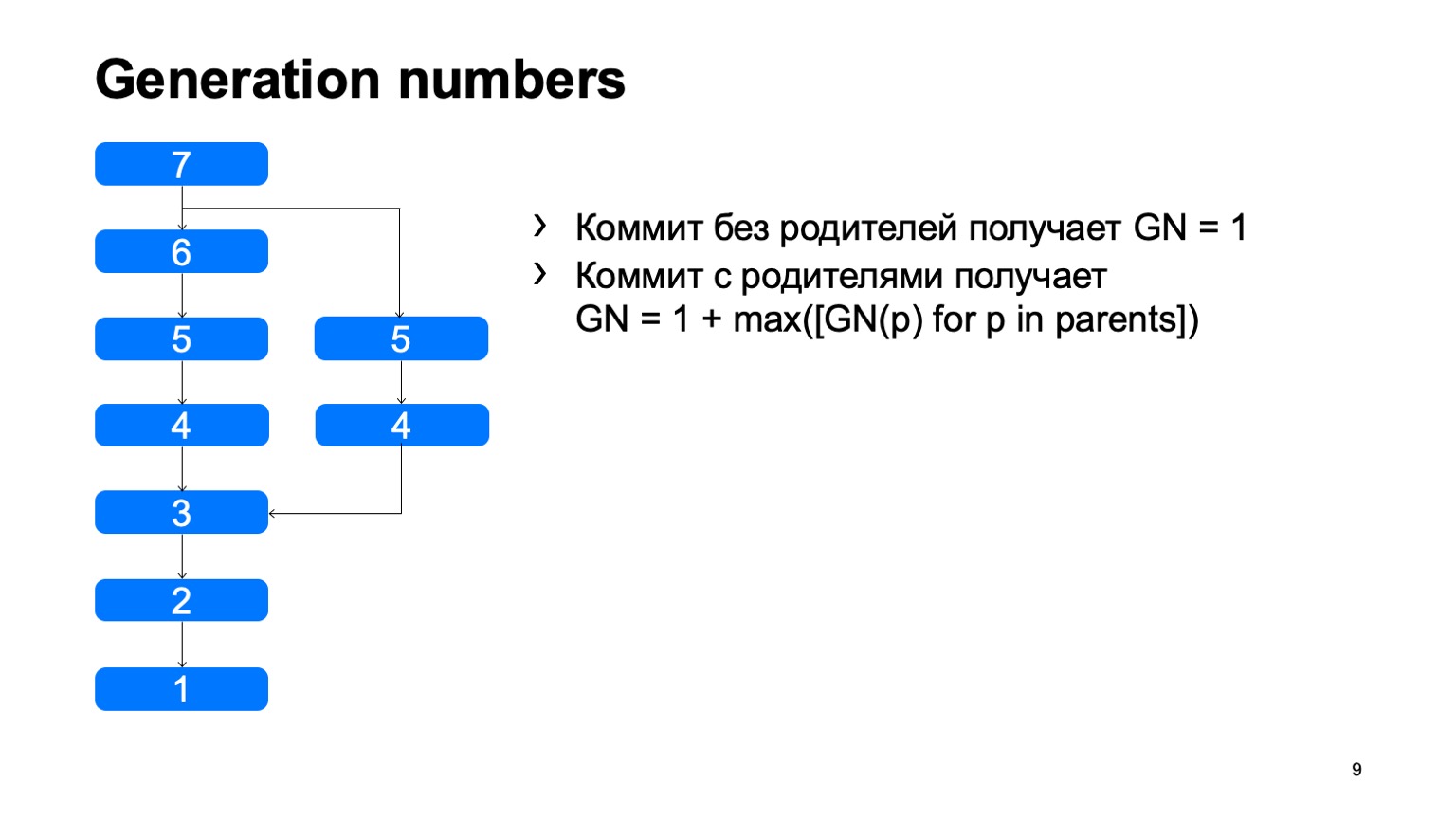
Apa yang kita miliki dan yang tidak segera muncul di Git adalah nomor generasi. Dengan menggunakan algoritma sederhana, kami mempertimbangkan jarak tertentu dari akar pohon. Mengapa kita membutuhkan ini? Ini semua dijahit ke dalam struktur objek, setelah diperbaiki, dan tidak pernah berubah lagi.
Operasi yang cukup penting untuk sistem kontrol versi adalah menemukan leluhur bersama terkecil untuk kedua komit. Dalam versi dasar, itu dapat diimplementasikan hanya dengan melintasi lebar, mulai dari dua titik, menandai semua komit yang dicapai di sana dengan satu atau beberapa tanda lain, segera setelah mereka menemukan komit yang memiliki kedua tanda-tanda ini, ada leluhur yang paling tidak umum.
Bagaimana ini akan bekerja dalam implementasi yang naif? Sesuatu seperti ini: berkeliling dan temukan komit yang diinginkan.
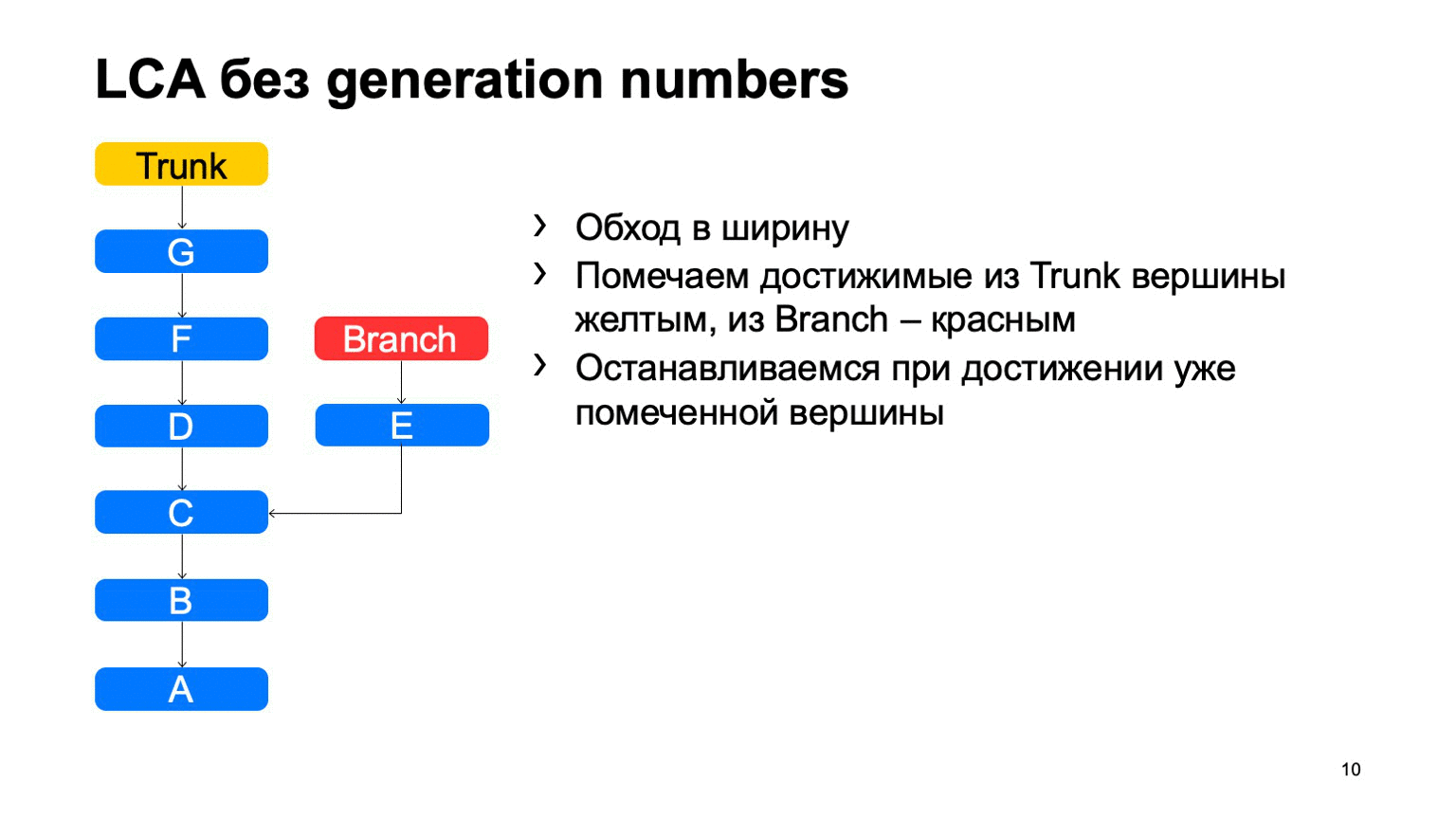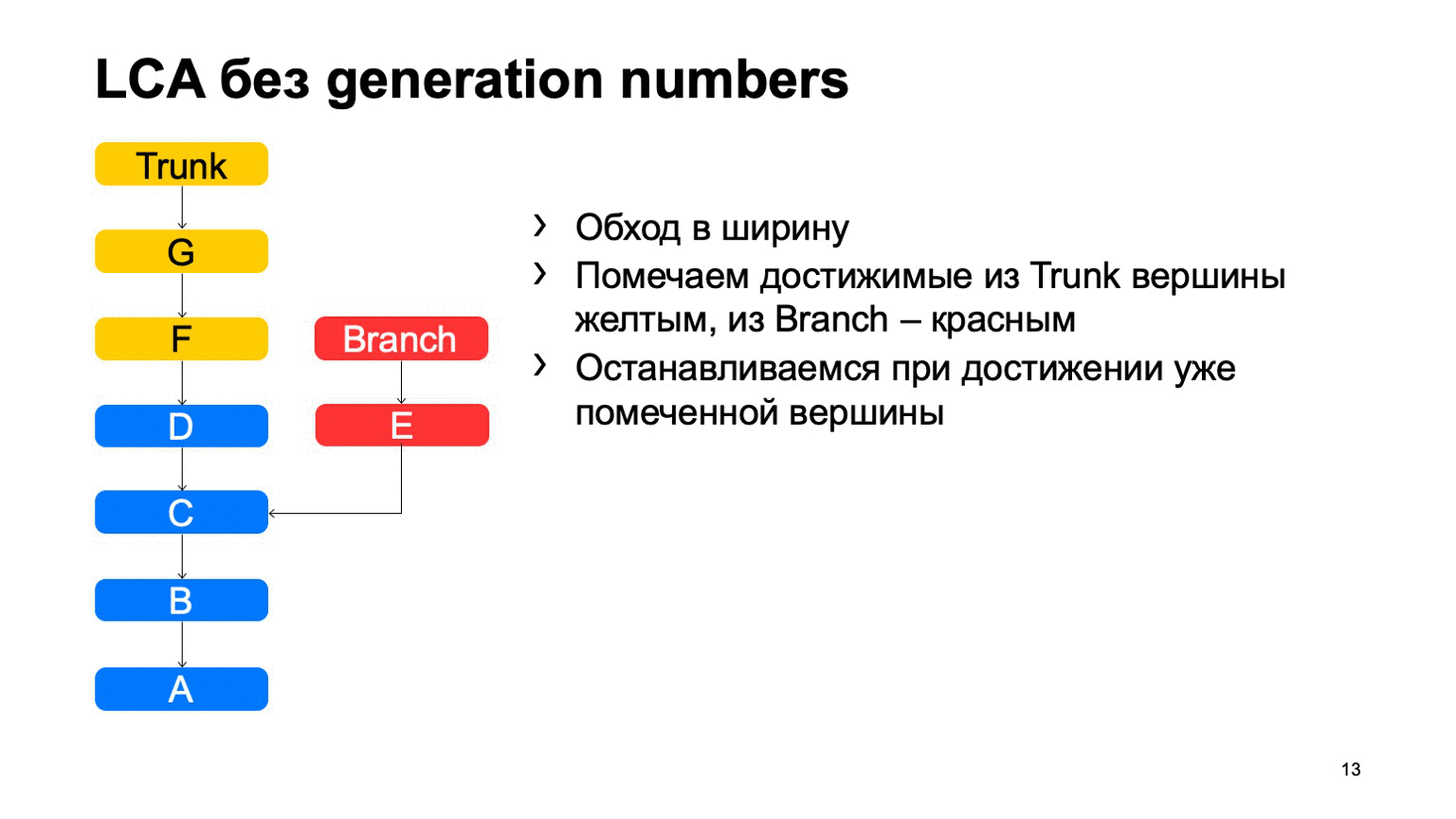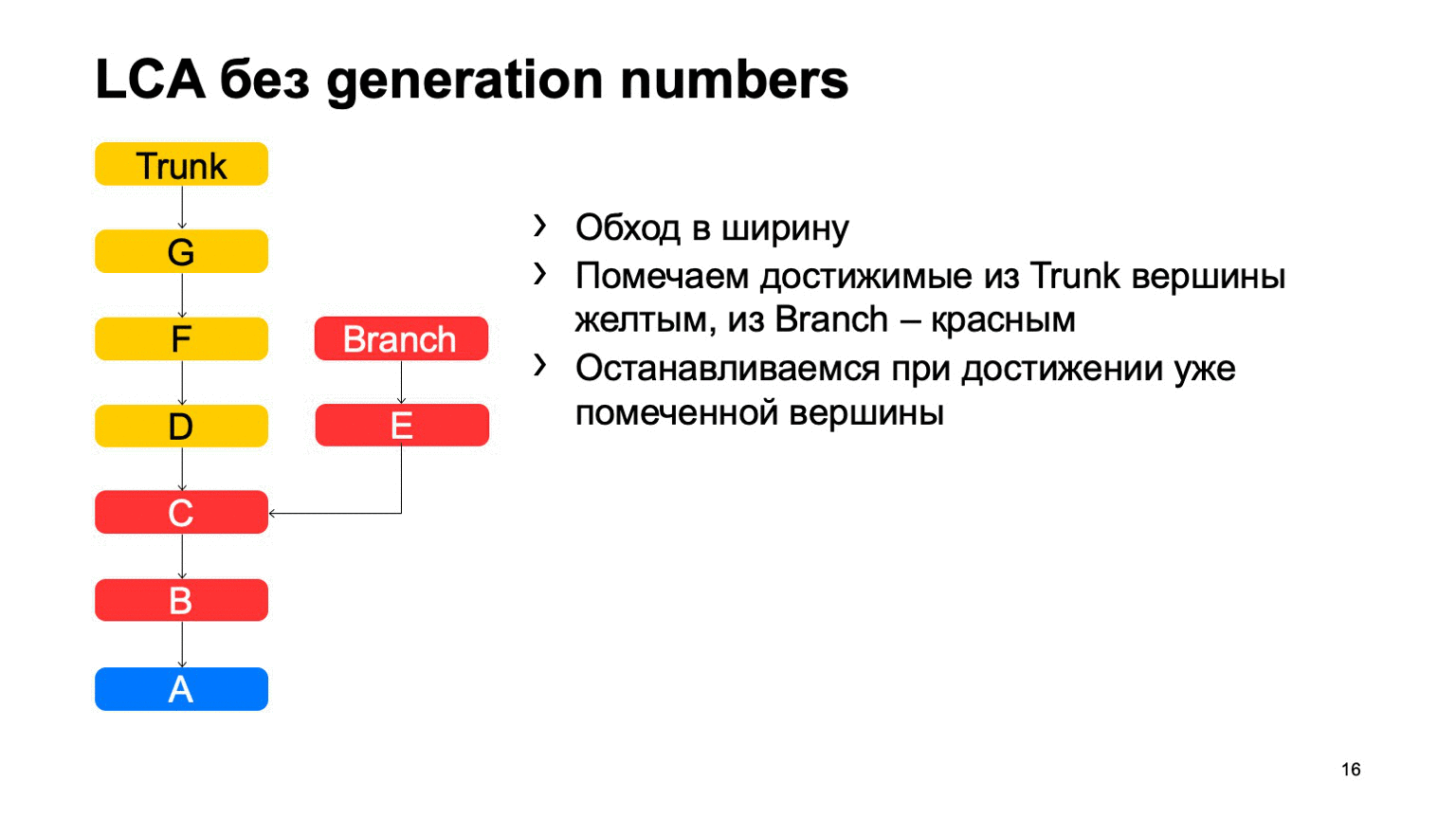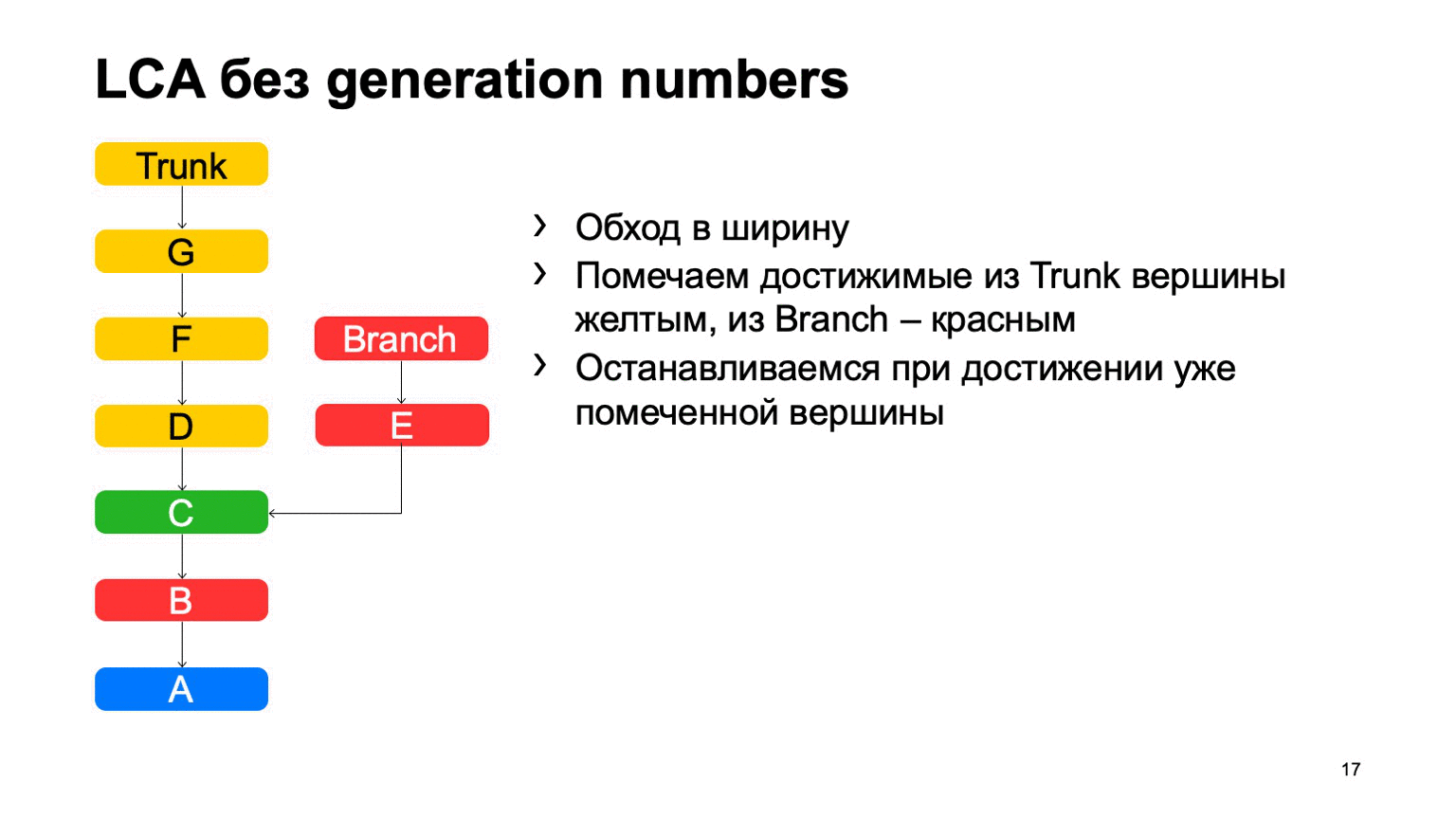
Masalahnya adalah dengan B, yang berlebihan. Tampaknya kami tidak bisa membahasnya, tetapi kami melihatnya. Dan semakin kita memiliki perbedaan antara cabang dan batang menggunakan contoh, semakin banyak komitmen tambahan yang akan kita temukan. Dalam kasus monorepositori, ketika tingkat komit ke bagasi cukup tinggi, jarak ini bisa sangat besar. Dan akan ada puluhan ribu komitmen ekstra semacam itu.


Jika ada nomor generasi, kita dapat menggunakan antrian prioritas saat merayapi, dan perayapan akan terlihat seperti ini: sekali - dan segera temukan yang Anda butuhkan.

Ini adalah salah satu contoh perbedaan antara model kami. Di Git, hal ini sebelumnya didukung, mereka menggunakan stempel waktu nomor generasi, tetapi ini hanya akan berfungsi jika waktu untuk membuat komit konsisten dengan grafik komit.
Sayangnya, ini bukan kasus untuk sejarah repositori kami. Ada komit yang dihasilkan dari migrasi repositori lain, dan waktu mulai mundur di dalamnya. Di Git, hal ini didukung di beberapa titik, tetapi tidak selalu berlaku di sana, karena di Git Anda dapat mengganti objek komit dengan yang lain secara lokal. Kekebalan model menderita dari ini, oleh karena itu nomor-nomor generasi yang tidak mencatat, mereka kadang-kadang tidak berlaku untuk apa yang tertulis di dalamnya, ini tidak benar. Kami tidak punya masalah seperti itu.
Kelebihan lain dari pengoptimalan ini adalah bahwa itu sepenuhnya lokal. Untuk menggunakan angka-angka ini, kita tidak perlu memiliki seluruh grafik komit. Dan kami biasanya tidak memilikinya sama sekali, bersama kami itu dimuat dengan malas. Semakin sedikit kita malas memuat, semakin baik kita hidup.
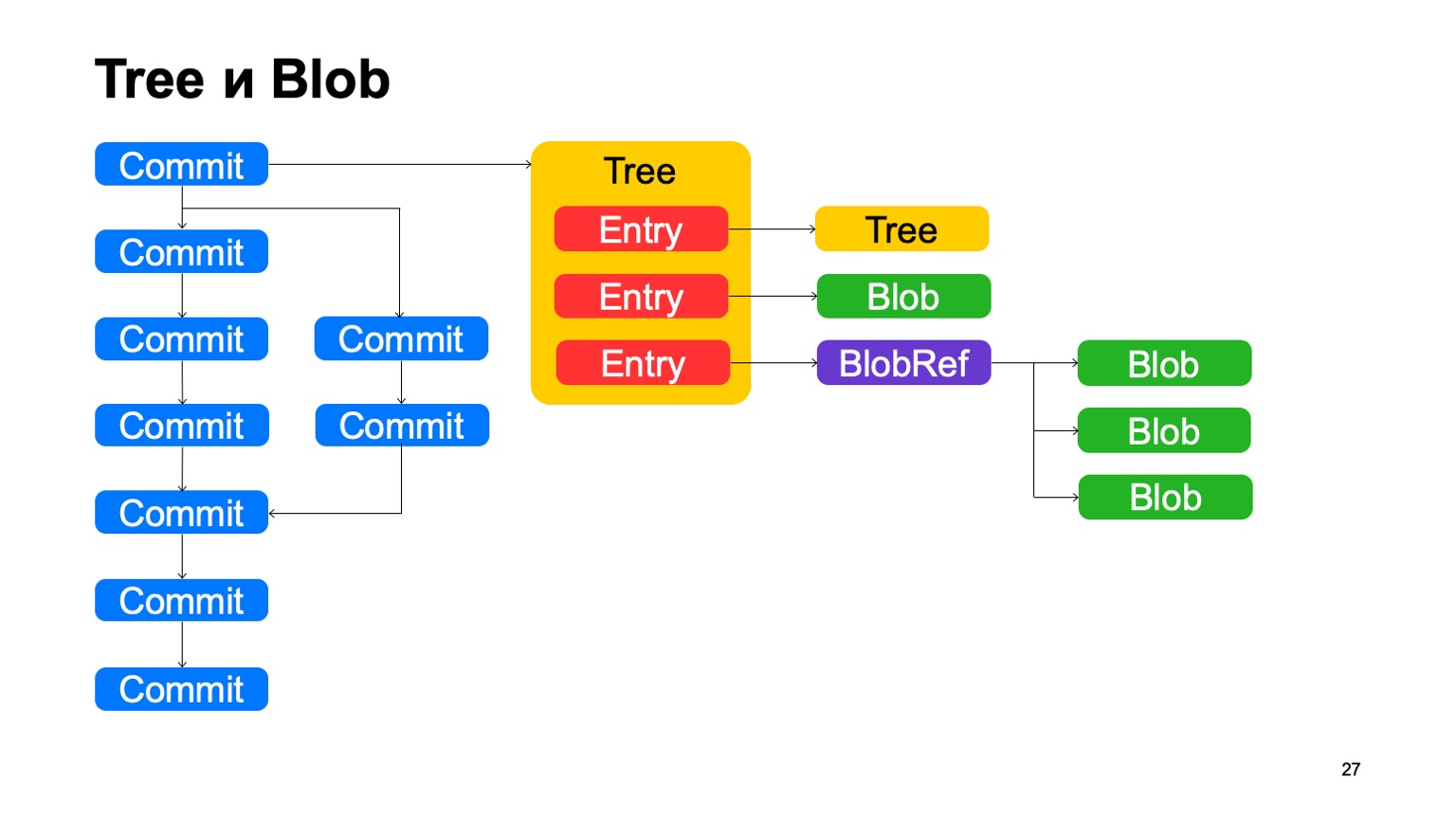
Selain berkomitmen, modelnya sangat mirip dengan Git. Setiap komit menunjuk ke objek pohon tertentu, pohon terdiri dari catatan, setiap catatan adalah pohon lain, dan ini adalah bagaimana hierarki direktori ditampilkan pada kita, atau ini adalah gumpalan, beberapa file. Ditambah lagi kita memiliki hal seperti BlobRef, ketika file sangat besar, kita membaginya menjadi beberapa bagian dan menyajikannya dalam objek khusus. Itu saja, seperti di Git.

Apa yang tidak kita sukai di Git? Kami menyebut hal ini sebagai salinan-info. Jika file itu disalin dalam beberapa jenis komit, maka Git tidak menyimpan informasi ini dengan cara apa pun, dan kemudian mencoba mengembalikannya dengan heuristik ketika menunjukkan Anda berbeda dan status. Kami menyimpan informasi ini dalam grafik. Catatan mungkin memiliki beberapa tautan info salinan ke komit lain, ke jalur di dalam repositori di komit ini, yang dengannya kami tahu bahwa file ini disalin dalam komit ini.
Ada juga deduplikasi, seperti di samping, gumpalan ini disimpan sekali. Tetapi deduplikasi akan tetap sama, karena isi file tidak berubah, itu akan dideduplikasi oleh hash.
Bagaimana pengaturan backend? Jika Git memiliki sistem kontrol versi terdistribusi, Git tidak memerlukan backend. Kami merasakan ini terutama ketika GitHub sedang down. Kami jelas memahami bahwa Git tidak membutuhkan backend. Sistem kami adalah client-server, ia menyimpan semua data di server, dan ketersediaan server diperlukan untuk mengunduh objek-objek yang belum pada klien.

Semua data kami simpan di Yandex Database. Ini adalah basis data yang sangat keren yang menyediakan transaksi, tingkat keandalan yang diperlukan. Ia memiliki semua yang kita butuhkan, dan hal ini menyelamatkan kita dari banyak masalah.
Berkat ini, backend itu sendiri benar-benar tanpa kewarganegaraan, seluruh negara bagian ada di dalam basis data, dan backend kita dapat dengan mudah skala sebanyak yang kita butuhkan.
Dan untuk interaksi yang dengan klien, interserver, kami menggunakan gRPC, ada laporan terperinci tentang hal itu hari ini.
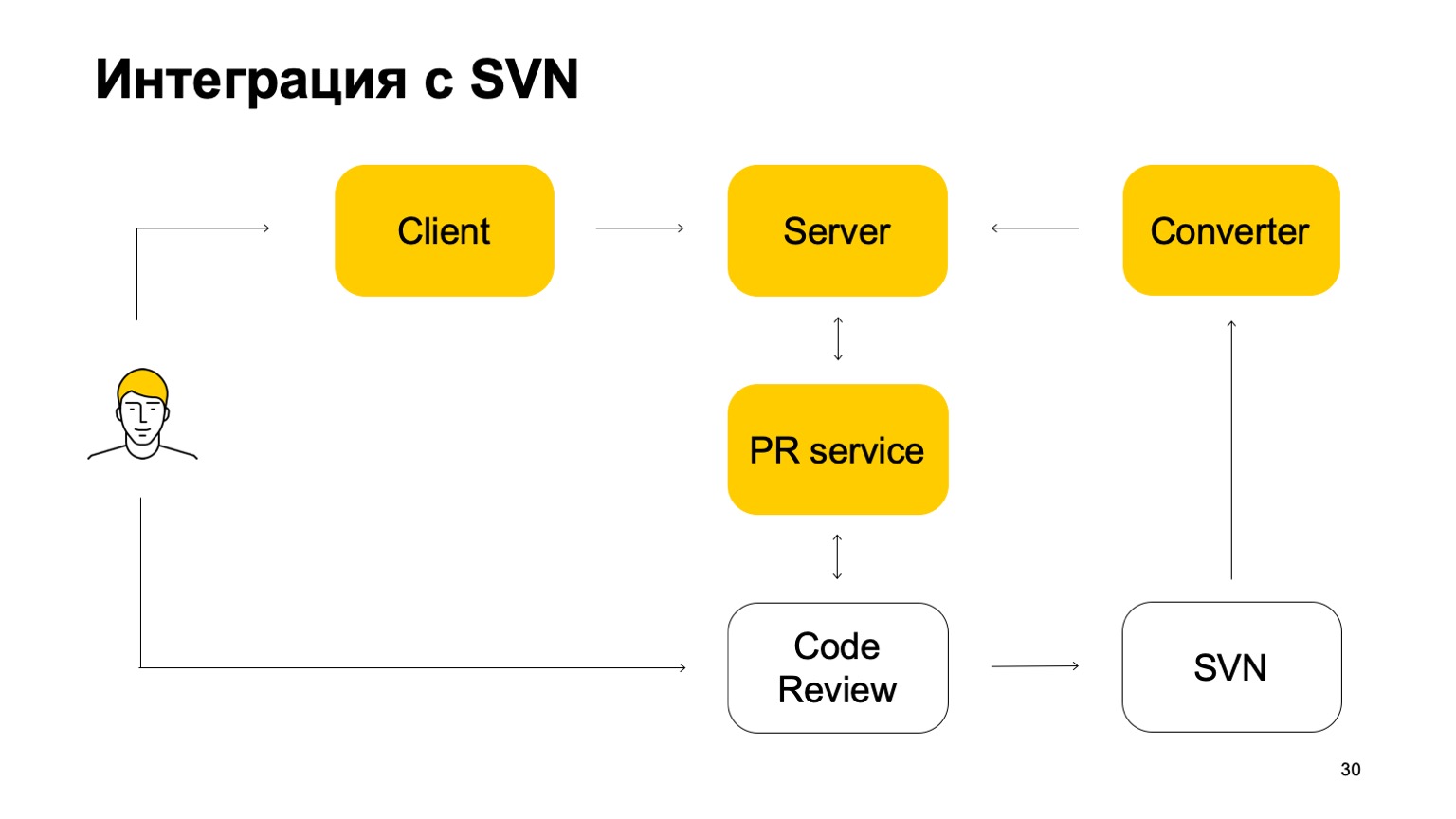
Bagaimana sistem kami terintegrasi dengan SVN? Repositori SVN terus hidup. Selain itu, sistem kontrol versi kami belum mandiri. Bagaimana dia bekerja di bagian ini? Awalnya, ada beberapa komponen Konverter yang memantau status repositori SVN dan mengubah SVN menjadi komit Arc - sistem kontrol versi kami.
Selanjutnya, ada klien yang memasang salinan yang berfungsi dan pergi ke server untuk data. Ketika seorang pengembang melakukan sesuatu, itu dikirim terlebih dahulu ke server Arc, tetapi untuk perubahan ini pergi ke trunk, cabang utama kami, mereka harus pergi melalui sistem permintaan kumpulan dan sistem tinjauan kode. Di sinilah layanan lain yang memantau cabang-cabang Arc, dan jika mereka diperbarui, mengirimkan permintaan kumpulan ke ulasan kode sistem kami. Berikutnya adalah sistem peninjauan kode, ketika diputuskan bahwa tambalan ini perlu digabungkan, komit ke SVN. Tidak cukup sederhana: ia menambahkan sejumlah metadata di sana bahwa komit ini sebenarnya merupakan gabungan dari cabang ini dan itu dari Arc. Dan komit ini sudah melihat konverter, menemukan meta-data di dalamnya dan membuat komit di server Arc. Ini adalah siklus komitmen. Karena itu, sementara kita tidak dapat hidup tanpa SVN, karena kita memiliki trunk di SVN.
Cabang utama terus disinkronkan dengan server kami, tetapi kami tidak mengizinkan untuk melakukan komit langsung padanya.

Tentang keandalan backend. Tentu saja, kami berencana bahwa semua pengembang Yandex akan menggunakan hal ini, jadi penting bagi kami agar tidak rusak. Ini adalah standar intra-indeks: layanan kami harus selamat dari kegagalan pusat data apa pun. Sistem kontrol versi tidak terkecuali. Di sini, kami sangat diselamatkan oleh fakta bahwa YDB mendukung ini. Dan backend kita tanpa kewarganegaraan, ada bagian yang berbeda diimplementasikan dalam cara yang sedikit berbeda. Server yang beroperasi pada objek Arc beroperasi pada cabang, mereka stateless, direplikasi. Konverter yang secara konstan mengkonversi dari SVN direplikasi sesuai dengan skema aktif-aktif. Ada beberapa konverter yang bekerja secara bersamaan, mereka mengonversi pada saat yang sama, dan saat mereka mencoba memperbarui cabang Arc, mereka menyelesaikan konflik. Satu berhasil, yang lain gagal. Dia mencoba untuk mengubah sesuatu lebih jauh.
Layanan permintaan kumpulan direplikasi oleh master-slave. Ada yang utama yang berfungsi. Jika gagal, yang baru dipilih melalui YDB. Ada hal yang luar biasa seperti semaphore, yang memiliki jaminan serius untuk aksesibilitas, keandalan. Akses ke semaphores sepenuhnya serial. Kami menggunakan semafor untuk layanan pencarian permintaan kumpulan dan untuk memilih pemimpin.
Sedikit tentang cara kerja klien. Ini adalah bagian paling sulit dari sistem kontrol versi kami, karena ada sistem file virtual. Faktanya, kita dipaksa untuk mengimplementasikan semua operasi pada file kita sendiri. Saya akan membahas beberapa operasi dasar, dengan kasar menggambarkan dengan jari apa yang terjadi di dalam ketika kita melakukannya.

Sebagai contoh, kami membuka file untuk direkam. Ketika kami membuka file untuk menulis, kami menemukan gumpalan yang sesuai dari model objek kami. Jika perlu, unggah sesuatu dari server. Jika kami secara fisik membuat file di toko khusus, maka semua permintaan lebih lanjut yang masuk ke file ini akan diproksi di sana. Jadi, sampai perubahan yang dilokalkan dilakukan (dalam Git disebut unstaged) mereka masuk ke penyimpanan sementara. Kami menyebut file tersebut terwujud.

Jika kita membuka file untuk dibaca, maka kita tidak bisa mematerialisasikan apa pun, tetapi cukup memberikan data langsung dari gumpalan kita.

Inilah saatnya ketika kita menambahkan file ke indeks. Pada titik ini, Anda perlu melihat apakah kami memiliki sesuatu yang terwujud. Apakah ada file yang sudah berubah. Jika ya, buat gumpalan untuk itu dan simpan di indeks.

Operasi selanjutnya adalah status busur. Sangat menarik karena itu adalah hal yang dalam sistem kontrol versi konvensional pada ukuran seperti itu lambat, karena harus melintasi seluruh pohon file. Kami tidak harus berkeliling seluruh pohon file, karena semua permintaan untuk mengubah file melalui driver sekering kami, dan kami segera tahu file mana yang layak diperiksa untuk perubahan. Kami memeriksa apa yang berhasil kami tulis ke indeks, dan mencetak jawabannya.

Waktu komitmen. Segalanya tampak jelas. Ada indeks, kami telah membuat gumpalan untuk objek-objek ini, membuat objek pohon yang sesuai dengan keadaan ini, membuat objek komit baru, menulisnya ke penyimpanan objek.

Selanjutnya, kami mengalihkan copy pekerjaan ke komit baru. Ini adalah operasi yang sulit, ini jelas dapat dilakukan dengan perintah checkout. Dan di sini Anda mungkin berpikir bahwa semua perubahan lokal kami tampaknya telah terwujud, kami dapat berasumsi bahwa kami harus mengembalikan file yang tidak terwujud dari komitmen baru. Dan itu dia. Semua operasi selanjutnya hanya dikirim ke pohon lain dan gumpalan.

Mengapa ini tidak berhasil? Versi pertama adalah tentang ini. Masalahnya adalah dalam semua jenis operasi rumit seperti arc reset –soft. Mereka mengganti kami dengan tree switch, tetapi tidak mematerialisasi file. Mereka terus ada di suatu tempat yang sakral. Kami juga memiliki file yang tidak bisa dilacak dan diabaikan, yang juga perlu diproses dengan cara khusus. Di tempat ini, kami mengumpulkan banyak garu dan akhirnya sampai pada kesimpulan bahwa, sama saja, selama checkout kita harus mengambil pohon (sekarang satu copy pekerjaan), ambil pohon komit yang akan kita gunakan, ambil indeks, dan ace rapi. tunggu sebentar
Tetapi dalam hal kompleksitas algoritma, kami tidak kehilangan apa pun di sini: semua pohon perubahan lokal ini sebanding dengan perubahan yang kami buat. Oleh karena itu, kita tidak harus berkeliling seluruh repositori dengan operasi ini, mereka masih bekerja dengan cukup cepat.
Pada saat yang sama, kami melakukan beberapa sihir sehingga cap waktu yang kami berikan ke file lebih atau kurang benar. Jika kita hanya menyimpan file dalam sistem file, ia memonitor ini, dan waktu selalu berjalan. Di sini kita sendiri entah bagaimana harus mengingat file apa yang dilihat pengguna pada saat apa. Dan jika dia beralih ke komitmen sebelumnya, jangan mulai memberinya waktu sebelumnya. Karena sistem perakitan, semua IDE tidak siap untuk ini, mereka mengambil banyak hal.

Dalam sistem kontrol versi kami, dukungan untuk pengembangan berbasis trunk dipaku. Pertama, apa yang telah saya katakan: semua perubahan harus melalui permintaan pool dan trunk. Ada beberapa poin lagi. Kami tidak memiliki dukungan cabang grup. Cabang yang dibuat di Arc terikat dengan pengguna tertentu, dan hanya dia yang bisa melakukan di sana. Ini memungkinkan kita untuk menghindari cabang yang berumur panjang. Di SVN, ini tidak terlalu khusus, karena tidak nyaman untuk membuat cabang. Dan nyaman untuk melakukannya di Arc, dan jika ini tidak dikontrol, kami takut bahwa beberapa bagian dari repositori tunggal kami akan berangkat ke cabang mereka dan akan melakukan pengembangan mereka di sana. Ini bertentangan dengan model yang ingin kita lakukan.

Kedua, kami tidak memiliki perintah penggabungan. Semua merger cabang terjadi di bawah kendali ketat kami. Kami sekarang sedang mengembangkan cabang untuk rilis, di mana juga dimungkinkan untuk bergabung. Ini juga akan dilakukan bukan oleh beberapa tim pengguna, tetapi oleh mesin server, kemungkinan besar.

Apa rencana kita? 20% pengembang monorepositori sudah menggunakan sistem kontrol versi kami. Kami telah muncul dari semacam keadaan kekanak-kanakan, ini adalah sistem yang digunakan secara serius, tidak mungkin untuk membuangnya begitu saja. Tujuan utamanya adalah menjadi sistem kontrol versi utama di Yandex. Kami harus meyakinkan 80% sisa pengembang bahwa kami cukup stabil, dapat diandalkan, dan dapat digunakan. Jelas bahwa untuk ini Anda harus memperbaiki semua bug dan menyelesaikan fitur-fitur yang ada di Git.
Tentu saja, dalam beberapa perspektif, kami berencana untuk menjadi mandiri, meninggalkan konverter atau menyebarkannya ke arah yang berlawanan, sehingga pertama semua perubahan pergi ke Arc, dan kemudian ke SVN untuk programmer yang paling gigih.
Sekarang kami memiliki tantangan besar - integrasi sistem kontrol versi dalam perakitan otomatis kami, dalam CI kami dan saluran pipa lainnya. Tantangannya adalah bahwa orang lemah dalam roh, mereka perlahan mengetik kode dan perlahan-lahan melakukan. Dan mereka mengunduh kodenya terlalu lambat. Dan robot dirampas dari kekurangan ini.
— , CI Arc, - . , . . , ++- , , . .
. « Git». : Git. , , .
. Git . , . - . , checkout reset, . , , . : Git. « , ». Git .
. Git, git begin-wave-stash?
:
— .
— , Git ? — , , , . , . Git . , . Terima kasih