 Itu hanya menyakitkan untuk pertama kalinya!
Itu hanya menyakitkan untuk pertama kalinya!Halo semuanya! Teman-teman yang terkasih, dalam artikel ini saya ingin berbagi pengalaman menggunakan TensorRT, RetinaNet berdasarkan repositori
github.com/aidonchuk/retinanet-examples (ini adalah percabangan turnkey resmi dari
nvidia , yang akan memungkinkan kita untuk mulai menggunakan model yang dioptimalkan dalam produksi sesegera mungkin).
Menggulir melalui saluran komunitas
ods.ai , saya menemukan pertanyaan tentang menggunakan TensorRT, dan sebagian besar pertanyaan diulang, jadi saya memutuskan untuk menulis panduan selengkap
mungkin untuk menggunakan inferensi cepat berdasarkan TensorRT, RetinaNet, Unet, dan docker.
Deskripsi tugasSaya mengusulkan pengaturan tugas dengan cara ini: kita perlu menandai dataset, melatih jaringan RetinaNet / Unet pada Pytorch1.3 + di atasnya, mengonversi bobot yang diterima menjadi ONNX, kemudian mengonversinya ke mesin TensorRT dan menjalankan semua ini di buruh pelabuhan, terutama di Ubuntu 18 dan sangat lebih disukai pada arsitektur ARM (Jetson) *, sehingga meminimalkan penyebaran lingkungan secara manual. Sebagai hasilnya, kita akan mendapatkan wadah yang siap tidak hanya untuk ekspor dan pelatihan RetinaNet / Unet, tetapi juga untuk pengembangan penuh dan pelatihan klasifikasi, segmentasi dengan semua ikatan yang diperlukan.
Tahap 1. Persiapan lingkunganPenting untuk dicatat di sini bahwa baru-baru ini saya benar-benar meninggalkan penggunaan dan penyebaran setidaknya beberapa perpustakaan di mesin desktop, serta pada devbox. Satu-satunya hal yang harus Anda buat dan instal adalah lingkungan virtual python dan cuda 10.2 (Anda dapat membatasi diri pada satu driver nvidia) dari deb.
Misalkan Anda memiliki Ubuntu yang baru diinstal 18. Instal cuda 10.2 (deb), saya tidak akan membahas proses instalasi secara rinci, dokumentasi resmi cukup.
Sekarang kita akan menginstal buruh pelabuhan, panduan pemasangan buruh pelabuhan dapat dengan mudah ditemukan, berikut adalah contoh
www.digitalocean.com/community/tutorials/docker-ubuntu-18-04-1-en , versi 19+ sudah tersedia - taruh saja. Nah, jangan lupa untuk memungkinkan menggunakan buruh pelabuhan tanpa sudo, itu akan lebih nyaman. Setelah semuanya berubah, kami melakukan ini:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.imtqy.com/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.imtqy.com/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit sudo systemctl restart docker
Dan Anda bahkan tidak dapat melihat ke repositori resmi
github.com/NVIDIA/nvidia-docker .
Sekarang lakukan git clone
github.com/aidonchuk/retinanet-examples .
Tetap sedikit, untuk mulai menggunakan buruh pelabuhan dengan nvidia-image, kita perlu mendaftar di NGC Cloud dan masuk. Kami pergi ke sini
ngc.nvidia.com , mendaftar dan setelah kami masuk ke dalam NGC Cloud, tekan SETUP di sudut kiri atas layar atau ikuti tautan ini
ngc.nvidia.com/setup/api-key . Klik "buat kunci." Saya sarankan menyimpannya, jika tidak saat berikutnya Anda mengunjunginya, Anda harus membuat ulang dan, karenanya, menyebarkannya pada mobil baru, jalankan kembali operasi ini.
Jalankan:
docker login nvcr.io Username: $oauthtoken Password: <Your Key> -
Nama pengguna cukup salin. Nah, pertimbangkan, lingkungan sudah dikerahkan!
Tahap 2. Merakit wadah buruh pelabuhanPada tahap kedua dari pekerjaan kami, kami akan mengumpulkan buruh pelabuhan dan berkenalan dengan bagian dalamnya.
Mari kita pergi ke folder root relatif terhadap proyek contoh retina dan jalankan
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Kami mengumpulkan buruh pelabuhan dengan melemparkan pengguna saat ini ke dalamnya - ini sangat berguna jika Anda menulis sesuatu pada VOLUME yang dipasang dengan hak pengguna saat ini, jika tidak akan ada root dan sakit.
Sementara buruh pelabuhan akan pergi, mari kita menjelajahi Dockerfile:
FROM nvcr.io/nvidia/pytorch:19.10-py3 ARG USER=alex ARG UID=1000 ARG GID=1000 ARG PW=alex RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master COPY . retinanet/ RUN pip install --no-cache-dir -e retinanet/ RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl RUN pip install tensorboardx RUN pip install albumentations RUN pip install setproctitle RUN pip install paramiko RUN pip install flask RUN pip install mem_top RUN pip install arrow RUN pip install pycuda RUN pip install torchvision RUN pip install pretrainedmodels RUN pip install efficientnet-pytorch RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch RUN pip install pytorch_toolbelt RUN chown -R ${USER}:${USER} retinanet/ RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping RUN mkdir /var/run/sshd RUN echo 'root:pass' | chpasswd RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd ENV NOTVISIBLE "in users profile" RUN echo "export VISIBLE=now" >> /etc/profile CMD ["/usr/sbin/sshd", "-D"]
Seperti yang Anda lihat dari teks, kami mengambil semua yang favorit kami, mengkompilasi retinanet, mendistribusikan alat-alat dasar untuk kenyamanan bekerja dengan Ubuntu, dan mengkonfigurasi server openssh. Baris pertama hanyalah pewarisan gambar nvidia, yang untuknya kami membuat login di NGC Cloud dan yang berisi Pytorch1.3, TensorRT6.xxx dan sekelompok lib yang memungkinkan kami untuk mengkompilasi kode sumber cpp untuk detektor kami.
Tahap 3. Memulai dan men-debug kontainer buruh pelabuhanMari kita beralih ke kasus utama menggunakan wadah dan lingkungan pengembangan, untuk memulai, jalankan nvidia docker. Jalankan:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latest
Sekarang wadah tersedia di ssh <curr_user_name> @localhost. Setelah peluncuran yang berhasil, buka proyek di PyCharm. Selanjutnya, buka
Settings->Project Interpreter->Add->Ssh Interpreter
Langkah 1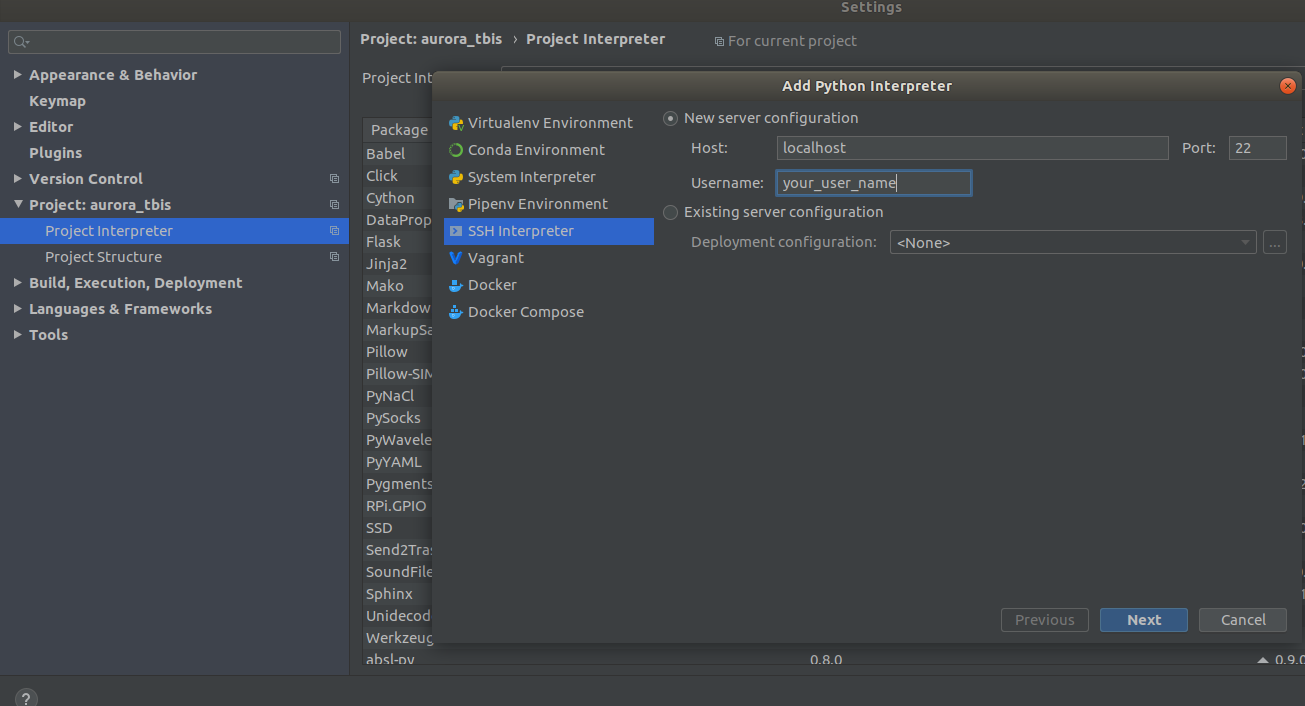 Langkah 2
Langkah 2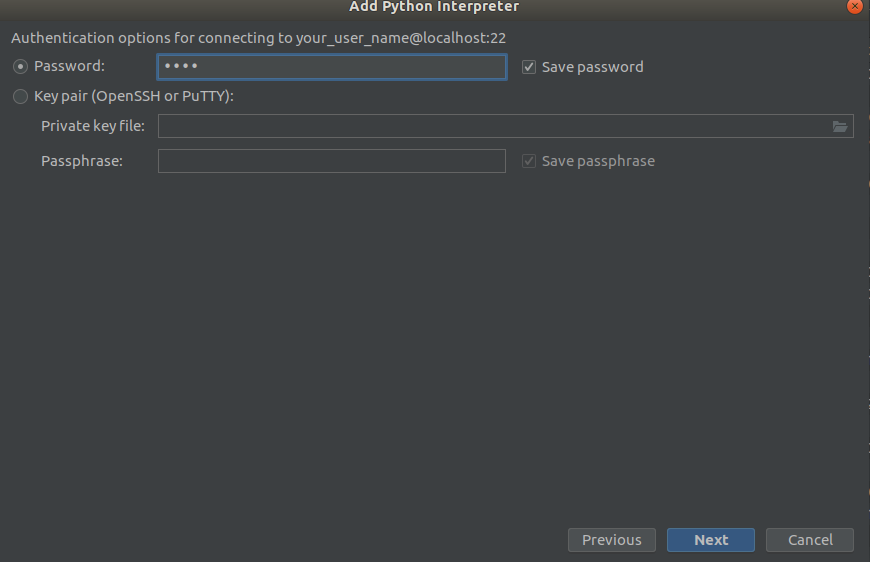 Langkah 3
Langkah 3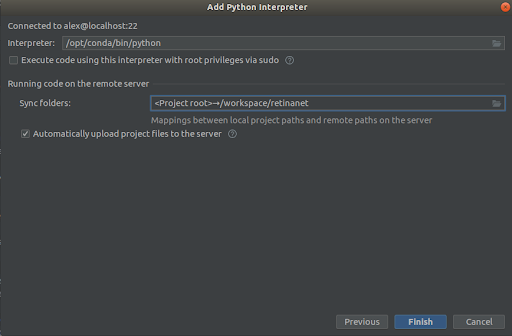
Kami memilih semuanya seperti pada tangkapan layar,
Interpreter -> /opt/conda/bin/python
- ini akan berada di Python3.6 dan
Sync folder -> /workspace/retinanet
Kami menekan garis finish, kami mengharapkan pengindeksan, dan hanya itu, lingkungan siap digunakan!
PENTING !!! Segera setelah pengindeksan, ekstrak file yang dikompilasi untuk Retinanet dari buruh pelabuhan. Di menu konteks di root proyek, pilih
Deployment->Download
Satu file dan dua folder build, retinanet.egg-info dan _so akan muncul
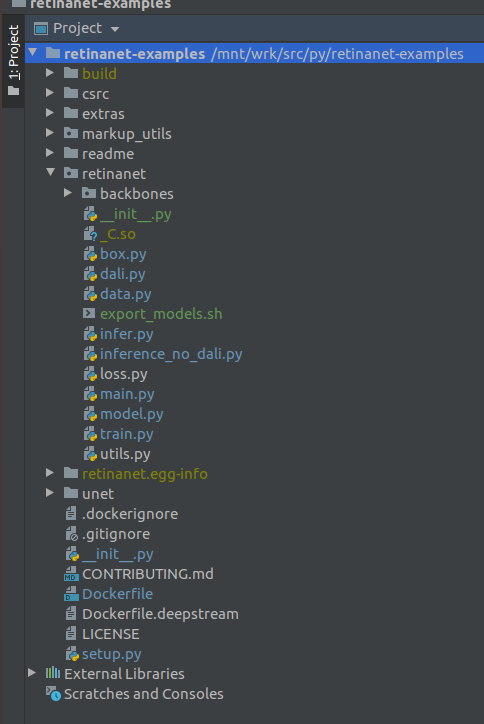
Jika proyek Anda terlihat seperti ini, maka lingkungan melihat semua file yang diperlukan dan kami siap mempelajari RetinaNet.
Tahap 4. Menandai data dan melatih detektorUntuk markup, saya terutama menggunakan
supervise.ly - alat yang bagus dan nyaman, di saat terakhir sekelompok kusen diperbaiki dan menjadi berperilaku lebih baik.
Misalkan Anda menandai dataset dan mengunduhnya, tetapi tidak akan langsung berfungsi untuk memasukkannya ke RetinaNet kami, karena itu dalam formatnya sendiri dan untuk ini kami perlu mengubahnya menjadi COCO. Alat konversi ada di:
markup_utils/supervisly_to_coco.py
Harap perhatikan bahwa Kategori dalam skrip adalah contoh dan Anda harus memasukkannya sendiri (Anda tidak perlu menambahkan kategori latar belakang)
categories = [{'id': 1, 'name': '1'}, {'id': 2, 'name': '2'}, {'id': 3, 'name': '3'}, {'id': 4, 'name': '4'}]
Untuk beberapa alasan, penulis repositori asli memutuskan bahwa Anda tidak akan melatih apa pun kecuali COCO / VOC untuk deteksi, jadi saya harus sedikit memodifikasi file sumber
retinanet/dataset.py
Dengan menambahkan tutda album tambahan augmentasi
Anda.readthedocs.io/en/latest dan hilangkan kategori terprogram dari COCO. Dimungkinkan juga untuk memercikkan area deteksi besar jika Anda mencari objek kecil dalam gambar besar, Anda memiliki dataset kecil =), dan tidak ada yang berhasil, tetapi lebih pada waktu lain.
Secara umum, loop kereta juga lemah, awalnya tidak menyimpan pos-pos pemeriksaan, menggunakan semacam penjadwal yang buruk, dll. Tapi sekarang yang harus Anda lakukan adalah memilih backbone dan mengeksekusi
/opt/conda/bin/python retinanet/main.py
dengan parameter:
train retinanet_rn34fpn.pth --backbone ResNet34FPN --classes 12 --val-iters 10 --images /workspace/mounted_vol/dataset/train/images --annotations /workspace/mounted_vol/dataset/train_12_class.json --val-images /workspace/mounted_vol/dataset/test/images_small --val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json --jitter 256 512 --max-size 512 --batch 32
Di konsol Anda akan melihat:
Initializing model... model: RetinaNet backbone: ResNet18FPN classes: 2, anchors: 9 Selected optimization level O0: Pure FP32 training. Defaults for this optimization level are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 1.0 Processing user overrides (additional kwargs that are not None)... After processing overrides, optimization options are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 128.0 Preparing dataset... loader: pytorch resize: [1024, 1280], max: 1280 device: 4 gpus batch: 4, precision: mixed Training model for 20000 iterations... [ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001 [ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001 [ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001 [ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001 [ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001 [ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001 [ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001 [ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001 [ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001 [ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001 [ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001 [ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001 [ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001 [ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001 Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Saving model: 148
Untuk mempelajari seluruh rangkaian parameter, lihat
retinanet/main.py
Secara umum, mereka standar untuk deteksi, dan mereka memiliki deskripsi. Jalankan pelatihan dan tunggu hasilnya. Contoh inferensi dapat ditemukan di:
retinanet/infer_example.py
atau jalankan perintah:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth --images /workspace/mounted_vol/dataset/test/images --annotations /workspace/mounted_vol/dataset/val.json --output result.json --resize 256 --max-size 512 --batch 32
Kehilangan fokus dan beberapa tulang punggung sudah dibangun ke dalam repositori, dan mereka
retinanet/backbones/*.py
Para penulis memberikan beberapa karakteristik dalam papan nama:
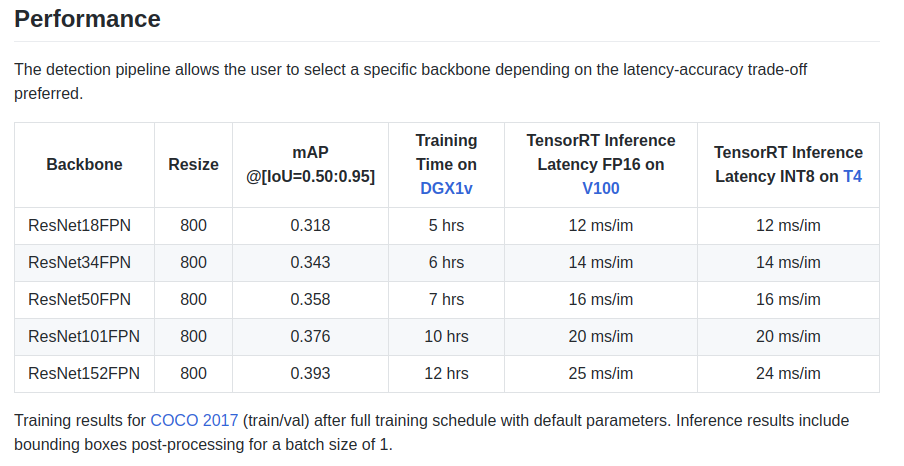
Ada juga tulang punggung ResNeXt50_32x4dFPN dan ResNeXt101_32x8dFPN, yang diambil dari torchvision.
Saya harap kami sedikit mengetahui pendeteksiannya, tetapi Anda harus membaca dokumentasi resmi untuk
memahami mode ekspor dan logging .
Tahap 5. Ekspor dan inferensi model Unet dengan encnet ResnetSeperti yang mungkin Anda perhatikan, pustaka untuk segmentasi dipasang di Dockerfile, dan khususnya pustaka hebat
github.com/qubvel/segmentation_models.pytorch . Dalam paket Yunet, Anda dapat menemukan contoh inferensi dan ekspor pos pemeriksaan pytorch di mesin TensorRT.
Masalah utama ketika mengekspor model Unet-like dari ONNX ke TensoRT adalah kebutuhan untuk menetapkan ukuran Upsample yang tetap atau menggunakan ConvTranspose2D:
import torch.onnx.symbolic_opset9 as onnx_symbolic def upsample_nearest2d(g, input, output_size):
Dengan menggunakan konversi ini, Anda dapat melakukan ini secara otomatis saat mengekspor ke ONNX, tetapi sudah dalam versi 7 dari TensorRT masalah ini diselesaikan, dan kami harus menunggu sangat sedikit.
KesimpulanKetika saya mulai menggunakan buruh pelabuhan, saya ragu tentang kinerjanya untuk tugas-tugas saya. Di salah satu unit saya, sekarang ada cukup banyak lalu lintas jaringan yang dibuat oleh beberapa kamera.
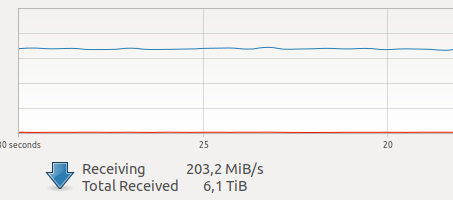
Berbagai tes di Internet mengungkapkan overhead yang relatif besar untuk interaksi dan perekaman jaringan pada VOLUME, ditambah GIL yang tidak diketahui dan mengerikan, dan karena memotret bingkai, operasi driver dan mentransmisikan bingkai melalui jaringan adalah operasi atom dalam mode
waktu-keras yang keras , penundaan. online sangat penting bagi saya.
Tapi tidak ada yang terjadi =)
PS Masih menambahkan loop kereta favorit Anda untuk segmentasi dan produksi!
Terima kasihBerkat komunitas
ods.ai , tidak mungkin berkembang tanpa itu! Terima kasih banyak kepada
n01z3 , DL, yang berharap agar saya menerima DL, atas nasihatnya yang tak ternilai dan profesionalisme yang luar biasa!
Gunakan model yang dioptimalkan dalam produksi!
Aurorai, llc