Hari ini saya akan memberitahu Anda bagaimana saya menerapkan penguatan algoritma pembelajaran dalam untuk mengendalikan robot. Singkatnya, saya akan memberi tahu Anda cara membuat "kotak hitam dengan jaringan saraf", yang menerima arsitektur robot pada input dan menghasilkan algoritma yang dapat mengontrolnya pada output.
Inti dari solusi adalah algoritma Advantage Actor Critic (A2C) dengan skor Advantage melalui Generalized Advantage Estimation (GAE).
Di bawah potongan, matematika, implementasi TensorFlow, dan banyak demo dari algoritma berjalan seperti apa.
Konten:
-
tantangan-
Mengapa Belajar Penguatan?-
Pernyataan Pembelajaran Penguatan-
gradien kebijakan-
Kebijakan Gaussian Diagonal-
Kurangi varian dengan menambahkan kritik-
Perangkap- Kesimpulan
Tantangan
Pada artikel ini, kami akan mengajarkan robot untuk berjalan dalam simulasi MuJoCo. Kami akan melewatkan deskripsi langkah dengan membuat model robot dan antarmuka Python ke lingkungan, karena tidak ada yang menarik di sana. Untuk memahami, lihat saja demo di MuJoCo itu sendiri dan sumber-sumber lingkungan MuJoCo di Gym OpenAI .
Pada input, agen akan memiliki banyak angka dari MuJoCo: posisi relatif, sudut rotasi, kecepatan, percepatan bagian-bagian tubuh robot, dll. Secara total, urutan ~ 800 fitur. Kami menggunakan pendekatan Deep Learning dan tidak akan mengerti apa yang sebenarnya mereka maksudkan. Hal utama adalah bahwa dalam rangkaian angka ini akan ada informasi yang cukup sehingga agen dapat memahami apa yang terjadi padanya.
Pada output, kita akan mengharapkan 18 angka - jumlah derajat kebebasan robot, yang berarti sudut rotasi engsel tempat tungkai diperbaiki.
Akhirnya, tujuan agen adalah untuk memaksimalkan total hadiah untuk episode tersebut. Kami akan mengakhiri episode jika robot mogok atau jika 3000 langkah telah berlalu (15 detik). Setiap langkah akan menghargai agen sesuai dengan rumus berikut:
perintahbaru E mathop mathbbE perintahbaru R mathop mathbbRrt= Deltax∗1000+0,5
Yaitu tujuan agen akan meningkatkan koordinasinya x dan jangan jatuh sampai akhir episode.
Jadi, tugasnya diatur: untuk menemukan fungsi pi: R800 to R18 di mana hadiah untuk episode akan menjadi yang terbesar . Kedengarannya itu tidak benar? :) Mari kita lihat bagaimana Deep Reinforcement Learning menangani tugas ini.
Mengapa Belajar Penguatan?
Pendekatan modern untuk memecahkan masalah pergerakan robot berjalan terdiri dari praktik robotika klasik dari bagian kontrol optimal dan optimalisasi lintasan : LQR, QP, optimisasi cembung. Baca selengkapnya: Posting tim Boston Dynamics di Atlas .
Teknik-teknik ini adalah semacam "hardcoding" karena mereka memerlukan pengenalan banyak detail tugas langsung ke dalam algoritma kontrol. Tidak ada sistem pembelajaran di dalamnya - optimasi berlangsung "di tempat".
Di sisi lain, Reinforcement Learning (selanjutnya disebut RL) tidak memerlukan hipotesis dalam algoritma, membuat solusi untuk masalah lebih umum dan terukur.
Pernyataan Pembelajaran Penguatan

Sumber
Dalam masalah RL, kami menganggap interaksi agen dan lingkungan sebagai urutan pasangan (negara, hadiah) dan transisi di antara mereka - tindakan .
(s0) xrightarrowa0(s1,r1) xrightarrowa1... xrightarrowan−1(sn,rn)
Definisikan terminologinya:
- pi(at|st) - kebijakan , strategi perilaku agen, probabilitas bersyarat,
- at sim pi( cdot|st) - Tindakan dianggap sebagai variabel acak dari distribusi pi ,
Kita dapat mempertimbangkan kebijakan sebagai fungsi pi:States toActions , tapi kami ingin membuat aksi agen stochastic, yang memfasilitasi eksplorasi . Yaitu dengan beberapa kemungkinan kami tidak cukup melakukan tindakan yang agen pilih. - tau - lintasan dilacak oleh agen, urutan (s1,s2,...,sn) .
Tugas agen adalah untuk memaksimalkan pengembalian yang diharapkan :
J( pi)= E tau sim pi[R( tau)]= E tau sim pi kiri[ sumnt=0rt kanan]
Sekarang kita dapat merumuskan masalah RL, temukan:
pi∗=arg mathopmax piJ( pi)
dimana pi∗ Apakah kebijakan optimal.
Baca lebih lanjut di materi dari OpenAI: OpenAI Spinning Up .
Gradien kebijakan
Patut dicatat bahwa pernyataan ketat masalah RL sebagai masalah optimisasi memberi kita peluang untuk menggunakan metode optimisasi yang sudah dikenal, misalnya, penurunan gradien . Bayangkan betapa kerennya jika kita bisa mengambil gradien pengembalian yang diharapkan dengan parameter model : nabla thetaJ( pi theta) . Dalam hal ini, aturan untuk memperbarui skala akan menjadi sederhana:
theta= thetaold+ alpha nabla thetaJ( pi theta)
Inilah gagasan semua metode gradien kebijakan . Kesimpulan ketat gradien ini agak hardcore. Kami tidak akan menulisnya di sini, tetapi meninggalkan tautan ke materi indah dari OpenAI . Gradien terlihat seperti ini:
nabla thetaJ( pi theta)= E tau sim pi theta kiri[ sumTt=0 nabla theta log pi theta(at|st)R( tau) kanan]
Dengan demikian, kehilangan model kami akan seperti ini:
loss=− log( pi theta(at|st))R( tau)
Ingat itu R( tau)= sumTt=0rt , dan pi theta(at|st) - ini adalah output dari model kami pada saat dia masuk st . Minus muncul karena kami ingin memaksimalkan J . Selama pelatihan, kami akan mempertimbangkan gradien pada batch dan menambahkannya untuk mengurangi varians (kebisingan data akibat lingkungan stokastik).
Ini adalah algoritma yang bekerja yang disebut REINFORCE . Dan dia tahu bagaimana menemukan solusi untuk beberapa lingkungan sederhana. Misalnya, "CartPole-v1" .
Pertimbangkan kode agen:
class ActorNetworkDiscrete: def __init__(self): self.state_ph = tf.placeholder(tf.float32, shape=[None, observation_space]) l1 = tf.layers.dense(self.state_ph, units=20, activation=tf.nn.relu) output_linear = tf.layers.dense(l1, units=action_space) output = tf.nn.softmax(output_linear) self.action_op = tf.squeeze(tf.multinomial(logits=output_linear,num_samples=1), axis=1)
Kami memiliki perceptron kecil arsitektur ini: (observasi_space, 10, action_space) [untuk CartPole ini adalah (4, 10, 2)]. tf.multinomial memungkinkan Anda memilih tindakan yang ditimbang secara acak. Untuk mendapatkan tindakan, Anda perlu menelepon:
action = sess.run(actor.action_op, feed_dict={actor.state_ph: observation})
Dan jadi kami akan melatihnya:
batch_generator = generate_batch(environments, batch_size=batch_size) for epoch in tqdm_notebook(range(epochs_number)): batch = next(batch_generator)
Generator batch menjalankan agen di lingkungan dan mengumpulkan data untuk pelatihan. Elemen batch adalah tupel dari jenis ini: (st,at,R( tau)) .
Menulis generator yang baik adalah tugas yang terpisah, di mana kesulitan utamanya adalah biaya panggilan sess.run () yang relatif tinggi dibandingkan dengan langkah simulasi tunggal (bahkan MuJoCo). Untuk mempercepat pekerjaan, Anda dapat mengeksploitasi fakta bahwa jaringan saraf berjalan secara batch, dan menggunakan banyak lingkungan paralel. Bahkan meluncurkannya secara berurutan dalam satu utas akan memberikan akselerasi yang signifikan dibandingkan dengan satu lingkungan.
Kode generator menggunakan DummyVecEnv dari baseline OpenAI Agen yang dihasilkan dapat bermain di lingkungan dengan ruang tindakan terbatas . Format ini tidak cocok untuk tugas kita. Agen yang mengendalikan robot harus mengeluarkan vektor dari Rn dimana n - jumlah derajat kebebasan. ( atau Anda dapat membagi ruang tindakan menjadi celah dan mendapatkan tugas dengan output diskrit )
Kebijakan Gaussian Diagonal
Inti dari pendekatan Kebijakan Gaussian Diagonal adalah agar model menghasilkan parameter distribusi normal n-dimensi, yaitu mu theta - mat. menunggu dan sigma theta - standar deviasi. Segera setelah agen perlu mengambil tindakan, kami akan menanyakan parameter ini dari model dan mengambil variabel acak dari distribusi ini. Jadi kami membuat agen keluar Rn dan membuatnya menjadi stokastik. Yang paling penting adalah bahwa setelah memperbaiki kelas distribusi pada output, kita dapat menghitung log( pi theta(at|st)) dan karenanya gradien kebijakan.
Catatan: bisa diperbaiki sigma theta sebagai hyperparameter, sehingga mengurangi dimensi output. Praktek menunjukkan bahwa ini tidak menyebabkan banyak bahaya, tetapi, sebaliknya, menstabilkan pembelajaran.
Baca lebih lanjut tentang kebijakan stokastik .
Kode Agen:
epsilon = 1e-8 def gaussian_loglikelihood(x, mu, log_std): pre_sum = -0.5 * (((x - mu) / (tf.exp(log_std) + epsilon))**2 + 2 * log_std + np.log(2 * np.pi)) return tf.reduce_sum(pre_sum, axis=1) class ActorNetworkContinuous: def __init__(self): self.state_ph = tf.placeholder(tf.float32, shape=[None, observation_space]) l1 = tf.layers.dense(self.state_ph, units=100, activation=tf.nn.tanh) l2 = tf.layers.dense(l1, units=50, activation=tf.nn.tanh) l3 = tf.layers.dense(l2, units=25, activation=tf.nn.tanh) mu = tf.layers.dense(l3, units=action_space) log_std = tf.get_variable(name='log_std', initializer=-0.5 * np.ones(action_space, std = tf.exp(log_std) self.action_op = mu + tf.random.normal(shape=tf.shape(mu)) * std
Bagian pelatihan tidak berbeda.
Sekarang kita akhirnya bisa melihat bagaimana REINFORCE akan mengatasi tugas kita. Selanjutnya, tujuan agen adalah bergerak ke kanan.
Perlahan tapi pasti merangkak menuju tujuannya.
Hadiah-untuk-pergi
Perhatikan bahwa ada anggota tambahan di gradien kami. Yaitu untuk setiap langkah t Saat menimbang gradien logaritma, kami menggunakan total hadiah untuk seluruh lintasan . Dengan demikian, mengevaluasi tindakan agen dengan pencapaiannya dari masa lalu. Kedengarannya salah, bukan? Karena itu
nabla thetaJ( pi theta)= E tau sim pi theta kiri[ sumTt=0 nabla theta log pi theta(at|st) sumTt′=0rt′ kanan]
akan menjadi ini
nabla thetaJ( pi theta)= E tau sim pi theta kiri[ sumTt=0 nabla theta log pi theta(at|st) sumTt′=trt′ kanan]
Temukan 10 perbedaan :)
Meskipun kehadiran anggota ini tidak merusak apa pun secara matematis, itu membuat banyak kebisingan bagi kami. Sekarang, selama pelatihan, agen hanya akan memperhatikan hadiah yang dia terima setelah tindakan tertentu .
Karena peningkatan ini, imbalan rata-rata telah tumbuh. Salah satu agen yang diterima belajar menggunakan forelimbs untuk mencapai tujuannya:
Kurangi varians dengan menambahkan kritik
Inti dari perbaikan lebih lanjut adalah pengurangan noise (varians) yang timbul karena transisi stokastik antara keadaan medium.
Ini akan membantu kami untuk menambahkan model yang akan memprediksi jumlah rata-rata hadiah yang diterima oleh agen, mulai dari negara s ke akhir lintasan, yaitu Fungsi nilai.
V pi(s)= E tau sim pi kiri[R( tau)|s0=s kanan] text−Fungsinilai
Q pi(s,a)= E tau sim pi kiri[R( tau)|s0=s,a0=a kanan] text−FungsiNilaiAksi
A pi(s,a)=Q pi(s,a)−V pi(s) text−Fungsikeuntungan
Fungsi Nilai menunjukkan pengembalian yang diharapkan jika kebijakan kami memulai permainan dari kondisi tertentu. Sama dengan fungsi-Q, perbaiki tindakan pertama saja.
Tambahkan kritik
Beginilah tampilan gradien saat menggunakan hadiah-untuk-pergi:
nabla theta log pi theta(at|st) sumTt′=trt′
Sekarang koefisien untuk gradien logaritma tidak lebih dari sampel fungsi Nilai.
sumTt′=trt′ simV pi(st)
Kami menimbang gradien logaritma dengan satu sampel dari lintasan tertentu, yang tidak baik. Kita dapat memperkirakan nilai-fungsi dengan beberapa model, misalnya, jaringan saraf, dan meminta nilai yang diperlukan dari itu, sehingga mengurangi varians. Kami akan menyebut model ini sebagai kritikus (Kritik) dan kami akan mempelajarinya secara paralel dengan kebijakan. Dengan demikian, rumus gradien dapat ditulis sebagai:
nabla theta log pi theta(at|st) sumTt′=trt′ approx nabla theta log pi theta(at|st)V pi( tau)
Kami mengurangi varians, tetapi pada saat yang sama, kami memperkenalkan bias ke dalam algoritma kami, karena jaringan saraf dapat membuat kesalahan perkiraan. Tetapi kompromi dalam situasi ini bagus. Situasi seperti itu dalam pembelajaran mesin disebut tradeoff varians-bias .
Pengkritik akan mengajarkan nilai-fungsi regresi pada sampel hadiah untuk yang dikumpulkan di lingkungan. Sebagai fungsi kesalahan, kami menggunakan MSE. Yaitu kerugian terlihat seperti ini:
loss=(V pi psi(st)− sumTt′=trt′)2
Kode Kritik:
class CriticNetwork: def __init__(self): self.state_ph = tf.placeholder(tf.float32, shape=[None, observation_space]) l1 = tf.layers.dense(self.state_ph, units=100, activation=tf.nn.tanh) l2 = tf.layers.dense(l1, units=50, activation=tf.nn.tanh) l3 = tf.layers.dense(l2, units=25, activation=tf.nn.tanh) output = tf.layers.dense(l3, units=1) self.value_op = tf.squeeze(output, axis=-1)
Siklus pelatihan sekarang terlihat seperti ini:
batch_generator = generate_batch(envs, batch_size=batch_size) for epoch in tqdm_notebook(range(epochs_number)): batch = next(batch_generator)
Sekarang bets berisi nilai lain, nilai, yang dihitung oleh kritik di generator.
Yaitu jenis batch adalah ini: (st,at,V pi psi(st), sumTt′=trt′) .
Dalam siklus, tidak ada yang membatasi kita dari melatih kritik hingga konvergensi , jadi kita mengambil beberapa langkah penurunan gradien, sehingga meningkatkan perkiraan fungsi Nilai dan mengurangi bias. Namun, pendekatan ini membutuhkan ukuran bets yang besar untuk menghindari pelatihan ulang. Pernyataan serupa tentang kebijakan pembelajaran tidak benar. Seharusnya umpan balik instan dari lingkungan belajar, jika tidak kita dapat menemukan diri kita dalam situasi di mana kita mendenda kebijakan untuk tindakan yang tidak akan diambil. Algoritma dengan properti ini disebut berdasarkan kebijakan .
Dasar-Dasar dalam Gradien Kebijakan
Dapat ditunjukkan bahwa dalam gradien diperbolehkan untuk menempatkan kelas luas dari fungsi-fungsi berguna lainnya t . Fungsi semacam itu disebut garis dasar . ( Kesimpulan dari fakta ini ) Fungsi-fungsi berikut berfungsi dengan baik sebagai baseline:

Sumber: kertas GAE .
Baseline yang berbeda memberikan hasil yang berbeda tergantung pada tugasnya. Sebagai aturan, keuntungan terbesar diberikan oleh fungsi Advantage dan perkiraannya.
Bahkan ada sedikit intuisi di balik ini. Ketika kami menggunakan Advantage, kami mendenda agen secara proporsional dengan seberapa jauh lebih baik atau lebih buruk daripada rata-rata agen mempertimbangkan tindakan yang dilakukannya. Dan semakin baik agen bermain di lingkungan, semakin tinggi standarnya . Agen ideal akan bermain dengan baik dan mengevaluasi semua tindakan mereka sebagai memiliki Keunggulan sama dengan 0 dan, oleh karena itu, memiliki gradien sama dengan 0.
Evaluasi keuntungan melalui fungsi Nilai
Ingat definisi Keuntungan:
A pi(s,a)=Q pi(s,a)−V pi(s) text−Fungsikeuntungan
Tidak jelas bagaimana cara mempelajari fungsi tersebut secara eksplisit. Trik akan datang ke penyelamatan, yang akan mengurangi perhitungan fungsi Advantage menjadi perhitungan fungsi Value.
Tentukan deltaVt=rt+V(st+1)−V(st) - Perbedaan Perbedaan Temporal ( TD-residual ). Tidak sulit untuk menyimpulkan bahwa fungsi seperti itu mendekati Keuntungan:
E kiri[ deltaVt kanan]= E kiri[rt+V(st+1)−V(st) kanan]= E kiri[Q(st,at)−V(st) right]=A(st,at)
Perubahan konseptual yang kompleks seperti itu memicu perubahan kode yang tidak terlalu besar. Sekarang, alih-alih mengevaluasi fungsi Nilai, kritikus akan menyerahkan penilaian Keuntungan untuk pelatihan kebijakan.
Algoritma yang dihasilkan disebut Advantage Actor-Critic .
def estimate_advantage(states, rewards): values = sess.run(critic.value_op, feed_dict={critic.state_ph: states}) deltas = rewards - values deltas = deltas + np.append(values[1:], np.array([0])) return deltas, values
Agen yang diperoleh dapat diamati kiprah percaya diri dan penggunaan tungkai yang sinkron:
Estimasi Keuntungan Umum
Artikel yang relatif baru (2018), " Kontrol terus menerus berdimensi tinggi dengan menggunakan estimasi keuntungan umum ", menawarkan evaluasi Keuntungan yang jauh lebih efisien melalui fungsi Nilai. Ini mengurangi varians bahkan lebih:
AGAE( gamma, lambda)t= sum l=0infty( gamma lambda)l deltaVt+l
dimana:
- deltaVt=rt+V(st+1)−V(st) - TD-residual,
- gamma - faktor diskon (hyperparameter),
- lambda - hiperparameter.
Penafsiran dapat ditemukan dalam publikasi itu sendiri.
Implementasi:
def discount_cumsum(x, coef):
Saat menggunakan ukuran batch kecil, algoritmanya terkonvergensi ke beberapa optima lokal. Di sini, agen menggunakan satu kaki sebagai tongkat, dan sisanya mendorong:
Di sini, agen tidak menggunakan melompat, tetapi hanya cepat meraba anggota badan. Dan Anda juga dapat melihat bagaimana dia berperilaku, jika dia ragu-ragu, dia akan berbalik dan terus berlari:
Agen terbaik, dia berada di bagian paling awal artikel. Melompat stabil, di mana semua anggota badan muncul dari permukaan. Kemampuan yang dikembangkan untuk menyeimbangkan memungkinkan agen untuk memperbaiki lintasan dengan kecepatan penuh jika terjadi kesalahan:
Perangkap
Pembelajaran mesin terkenal dengan dimensi ruang kesalahan yang dapat dibuat dan mendapatkan algoritma yang sama sekali tidak bekerja. Tetapi RL membawa masalah ke tingkat yang sama sekali baru.
Sumber
Berikut adalah beberapa kesulitan yang dihadapi selama pengembangan.
- Algoritma ini sangat sensitif terhadap hiperparameter. Ada perubahan dalam kualitas pembelajaran ketika mengubah tingkat belajar dari 3e-4 ke 1e-4. Dan gambar berubah secara radikal - dari algoritma yang sepenuhnya non-konvergen ke yang terbaik dalam video.
- Ukuran bets sama sekali tidak sama dengan di bidang DL lainnya. Jika dalam klasifikasi gambar Anda dapat membiarkan diri Anda memilih ukuran 32-256 batch dan hasilnya tidak akan berubah dari peningkatannya, maka lebih baik mengambil beberapa ribu, 3000 bekerja untuk tugas kami, dan lagi, dari kurangnya konvergensi ke algoritma yang baik.
- Belajar berjalan lebih baik beberapa kali, terkadang dengan seed acak tidak beruntung.
- Belajar di lingkungan yang agak rumit membutuhkan banyak waktu, dan kemajuan tidak seragam. Misalnya, algoritma terbaik yang dipelajari selama 8 jam, 3 di antaranya menunjukkan hasil yang lebih buruk daripada garis dasar acak. Karena itu, ketika menguji algoritme, lebih baik memulai dengan yang kecil, seperti lingkungan mainan dari gym.
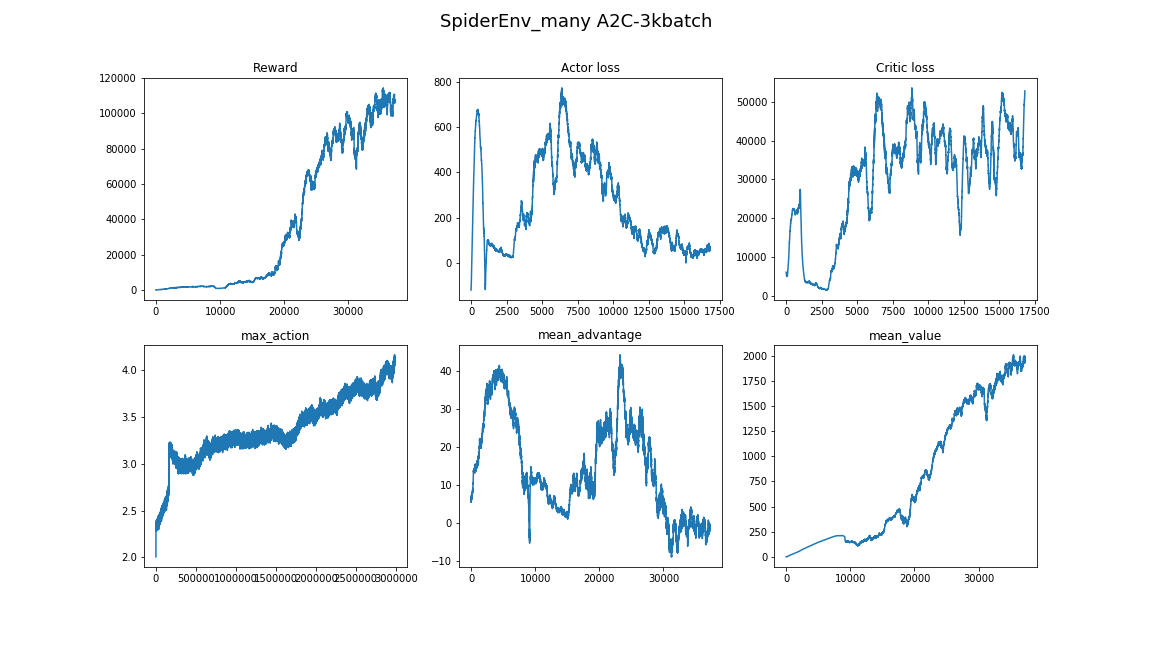
- Pendekatan yang baik untuk menemukan hyperparameter dan arsitektur model adalah dengan mengintip artikel dan implementasi terkait. (Yang utama adalah tidak melatih kembali)
Anda dapat mempelajari lebih lanjut tentang nuansa Deep RL dari artikel ini: Pembelajaran Penguatan Jauh Belum Berfungsi .
Kesimpulan
Algoritma yang dihasilkan meyakinkan memecahkan masalah. Fungsi ditemukan pi: R800 to R18 , mengendalikan robot dengan tangkas dan percaya diri.
Kelanjutan logis akan menjadi studi kerabat dekat dari algoritma A2C, PPO dan TRPO. Mereka meningkatkan efisiensi sampel , mis. waktu konvergensi dari algoritma, dan mereka mampu memecahkan masalah yang lebih kompleks. Itu PPO + Pengacakan Domain Otomatis yang baru-baru ini mengumpulkan Rubik's Cube pada robot .
Di sini Anda dapat menemukan kode dari artikel: repositori .
Saya harap Anda menikmati artikel ini dan terinspirasi oleh apa yang dapat dilakukan Pembelajaran Penguatan Mendalam hari ini.
Terima kasih atas perhatian anda!
Tautan yang bermanfaat:
Terima kasih kepada pinkotter , Vambala , andrey_probochkin , pollyfom , dan suriknik untuk membantu proyek ini.
Secara khusus, Vambala dan andrey_probochkin untuk menciptakan lingkungan MuJoCo yang keren.