Clickhouse adalah mesin basis data sistem manajemen basis data kueri analitik open source (OLAP) yang dibuat oleh Yandex. Ini digunakan oleh Yandex, CloudFlare, VK.com, Badoo dan layanan lainnya di seluruh dunia untuk menyimpan data dalam jumlah sangat besar (masukkan ribuan baris per detik atau petabyte data yang disimpan dalam disk).
Dalam DBMS "string" yang biasa, contohnya adalah MySQL, Postgres, MS SQL Server, data disimpan dalam urutan ini:
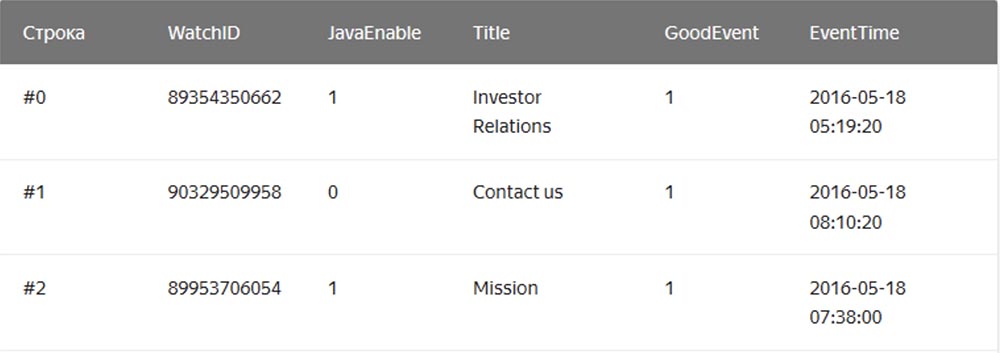
Dalam hal ini, nilai yang terkait dengan satu baris disimpan secara fisik berdampingan. Dalam DBMS berbentuk kolom, nilai-nilai dari berbagai kolom disimpan secara terpisah, dan data satu kolom disimpan bersama:
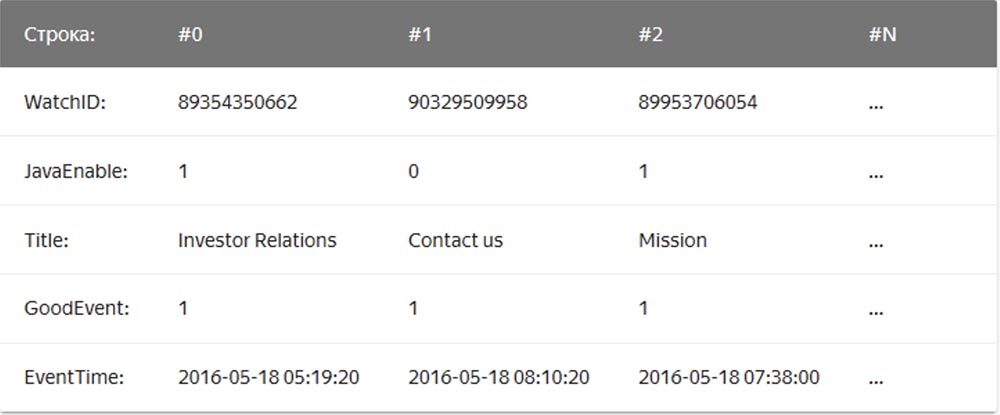
Contoh DBMS berbentuk kolom adalah Vertica, Paraccel (Actian Matrix, Amazon Redshift), Sybase IQ, Exasol, Infobright, InfiniDB, MonetDB (VectorWise, Vector Actian), LucidDB, SAP HANA, Google Dremel, Google PowerDrill, Druid, kdb +.
Perusahaan
penerusan surat
Qwintry mulai menggunakan Clickhouse pada tahun 2018 untuk pelaporan dan sangat terkesan dengan kesederhanaan, skalabilitas, dukungan dan kecepatan SQL. Kecepatan DBMS ini dibatasi oleh sihir.
Kesederhanaan
Clickhouse menginstal di Ubuntu dengan satu perintah tunggal. Jika Anda tahu SQL, Anda dapat segera mulai menggunakan Clickhouse untuk kebutuhan Anda. Namun, ini tidak berarti bahwa Anda dapat menjalankan "show create table" di MySQL dan salin-tempel SQL di Clickhouse.
Dibandingkan dengan MySQL, dalam DBMS ini ada perbedaan penting tipe data dalam definisi skema tabel, jadi untuk pekerjaan yang nyaman Anda masih perlu waktu untuk mengubah definisi skema tabel dan mempelajari mesin tabel.
Clickhouse berfungsi dengan baik tanpa perangkat lunak tambahan, tetapi jika Anda ingin menggunakan replikasi, Anda harus menginstal ZooKeeper. Analisis kinerja kueri menunjukkan hasil yang sangat baik - tabel sistem berisi semua informasi, dan semua data dapat diperoleh dengan menggunakan SQL yang lama dan membosankan.
Performa
- Benchmark membandingkan Clickhouse dengan Vertica dan MySQL pada server konfigurasi: dua soket Intel® Xeon® E5-2650 v2 @ 2.60GHz; 128 GiB RAM; md RAID-5 pada 8 6TB SATA HDD, ext4.
- Benchmark membandingkan Clickhouse dengan penyimpanan data cloud Amazon RedShift.
- Kutipan dari Cloudflare Clickhouse Performance Blog :

Basis data ClickHouse memiliki desain yang sangat sederhana - semua node di cluster memiliki fungsi yang sama dan hanya menggunakan ZooKeeper untuk koordinasi. Kami membangun sekelompok kecil beberapa node dan melakukan pengujian, di mana kami menemukan bahwa sistem memiliki kinerja yang cukup mengesankan, yang sesuai dengan keuntungan yang dinyatakan dalam tolok ukur DBMS analitik. Kami memutuskan untuk melihat lebih dekat konsep di balik ClickHouse. Rintangan pertama untuk penelitian adalah kurangnya alat dan ukuran kecil komunitas ClickHouse, jadi kami menyelidiki desain sistem manajemen basis data ini untuk memahami cara kerjanya.
ClickHouse tidak mendukung penerimaan data langsung dari Kafka (saat ini sudah tahu caranya), karena ini hanya database, jadi kami menulis layanan adaptor kami sendiri di Go. Dia membaca pesan yang disandikan Cap'n Proto dari Kafka, mengubahnya menjadi TSV, dan menyisipkannya ke dalam ClickHouse dalam batch melalui antarmuka HTTP. Kemudian, kami menulis ulang layanan ini untuk menggunakan Go library bersama dengan antarmuka ClickHouse kami sendiri untuk meningkatkan kinerja. Ketika mengevaluasi kinerja paket penerima, kami menemukan hal penting - ternyata di ClickHouse kinerja ini sangat tergantung pada ukuran paket, yaitu jumlah baris yang dimasukkan secara bersamaan. Untuk memahami mengapa ini terjadi, kami memeriksa bagaimana ClickHouse menyimpan data.
Mesin utama, atau lebih tepatnya, keluarga mesin meja yang digunakan oleh ClickHouse untuk menyimpan data, adalah MergeTree. Mesin ini secara konseptual mirip dengan algoritma LSM yang digunakan oleh Google BigTable atau Apache Cassandra, tetapi menghindari membangun tabel memori antara dan menulis data langsung ke disk. Ini memberikan throughput penulisan yang sangat baik, karena setiap paket yang dimasukkan hanya diurutkan berdasarkan kunci primer "primary key", dikompres dan ditulis ke disk untuk membentuk segmen.
Tidak adanya tabel memori atau konsep "kesegaran" data juga berarti bahwa mereka hanya dapat ditambahkan, sistem tidak mendukung mengubah atau menghapusnya. Saat ini, satu-satunya cara untuk menghapus data adalah dengan menghapusnya berdasarkan bulan kalender, karena segmen tidak pernah melewati batas bulan. Tim ClickHouse secara aktif bekerja untuk membuat fitur ini dapat dikustomisasi. Di sisi lain, ini membuat segmen perekaman dan penggabungan menjadi mulus, sehingga bandwidth yang diterima berskala linier dengan jumlah sisipan paralel hingga I / O atau core jenuh.
Namun, fakta ini juga berarti bahwa sistem tidak cocok untuk paket kecil, oleh karena itu layanan dan sisipan Kafka digunakan untuk buffering. Selanjutnya, ClickHouse di latar belakang terus melakukan penggabungan segmen, sehingga banyak informasi kecil akan digabungkan dan direkam lebih banyak kali, sehingga meningkatkan intensitas perekaman. Dalam hal ini, terlalu banyak bagian yang tidak terkait akan menyebabkan pelemparan agresif dari insert selama penggabungan berlanjut. Kami menemukan bahwa kompromi terbaik antara penerimaan data real-time dan kinerja penerimaan adalah menerima sejumlah sisipan per detik ke dalam tabel.
Kunci kinerja tabel membaca adalah pengindeksan dan pemosisian data pada disk. Terlepas dari seberapa cepat pemrosesan, ketika mesin perlu memindai terabyte data dari disk dan hanya menggunakan sebagian dari mereka, itu akan memakan waktu. ClickHouse adalah toko kolom, sehingga setiap segmen berisi file untuk setiap kolom (kolom) dengan nilai yang diurutkan untuk setiap baris. Dengan demikian, seluruh kolom yang tidak ada dalam kueri dapat dilewati terlebih dahulu, dan kemudian beberapa sel dapat diproses secara paralel dengan eksekusi vektor. Untuk menghindari pemindaian penuh, setiap segmen memiliki file indeks kecil.
Mengingat bahwa semua kolom diurutkan berdasarkan "kunci utama", file indeks hanya berisi label (baris yang diambil) dari setiap baris ke-N untuk dapat menyimpannya dalam memori bahkan untuk tabel yang sangat besar. Misalnya, Anda dapat mengatur pengaturan default "tandai setiap baris 8192", kemudian indeks "sedikit" dari tabel dengan 1 triliun. baris, yang mudah masuk ke memori, hanya akan menempati 122.070 karakter.
Pengembangan sistem
Pengembangan dan peningkatan Clickhouse dapat ditelusuri ke
repo Github dan memastikan bahwa proses "tumbuh" berjalan dengan kecepatan yang mengesankan.
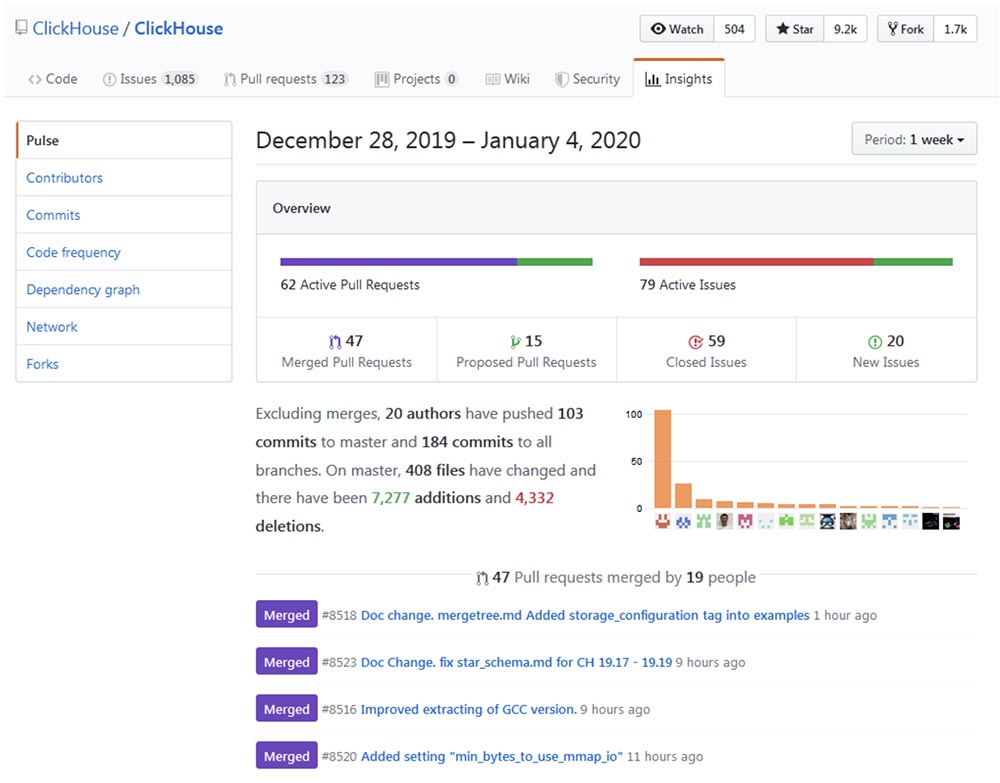
Popularitas
Clickhouse tampaknya tumbuh secara eksponensial, terutama di komunitas berbahasa Rusia. Konferensi tahun lalu High load 2018 (Moscow, 8-9 November, 2018) menunjukkan bahwa monster seperti vk.com dan Badoo menggunakan Clickhouse, yang dengannya mereka menempelkan data (misalnya, log) dari puluhan ribu server pada saat yang bersamaan. Dalam video 40 menit,
Yuri Nasretdinov dari tim VKontakte berbicara tentang bagaimana hal ini dilakukan . Segera kami akan memposting transkrip pada Habr untuk kenyamanan bekerja dengan materi.
Area aplikasi
Setelah saya menghabiskan beberapa waktu meneliti, saya pikir ada area di mana ClickHouse dapat bermanfaat atau dapat sepenuhnya menggantikan solusi lain yang lebih tradisional dan populer, seperti MySQL, PostgreSQL, ELK, Google Big Query, Amazon RedShift, TimescaleDB, Hadoop, MapReduce, Pinot, dan Druid. Berikut ini adalah detail penggunaan ClickHouse untuk memutakhirkan atau sepenuhnya menggantikan DBMSs di atas.
Memperluas MySQL dan PostgreSQL
Baru-baru ini, kami mengganti sebagian MySQL dengan ClickHouse untuk platform
buletin buletin Mautic . Masalahnya adalah MySQL, karena desainnya yang salah, mencatat setiap email yang dikirim dan setiap tautan dalam email ini dengan hash base64, menciptakan tabel MySQL yang sangat besar (email_stats). Setelah mengirim hanya 10 juta surat ke pelanggan layanan, tabel ini menempati 150 GB ruang file, dan MySQL mulai "membosankan" pada pertanyaan sederhana. Untuk memperbaiki masalah ruang file, kami berhasil menggunakan kompresi tabel InnoDB, yang menguranginya sebanyak 4 kali. Namun, masih tidak masuk akal untuk menyimpan lebih dari 20-30 juta email di MySQL hanya untuk membaca cerita, karena setiap permintaan sederhana yang karena alasan tertentu perlu melakukan pemindaian penuh mengarah ke swap dan beban besar pada I / O, untuk tentang itu kami secara teratur menerima peringatan Zabbix.

Clickhouse menggunakan dua algoritma kompresi yang mengurangi jumlah data sekitar
3-4 kali , tetapi dalam kasus khusus ini data itu terutama "kompresibel".

Penggantian RUSA
Berdasarkan pengalaman kami sendiri, tumpukan ELK (ElasticSearch, Logstash dan Kibana, dalam kasus khusus ini, ElasticSearch) membutuhkan lebih banyak sumber daya untuk dijalankan daripada yang diperlukan untuk menyimpan log. ElasticSearch adalah mesin yang hebat jika Anda membutuhkan pencarian log teks lengkap yang bagus (dan saya rasa Anda tidak benar-benar membutuhkannya), tetapi saya heran mengapa, faktanya, itu telah menjadi mesin logging standar. Kinerja penerimaannya dikombinasikan dengan Logstash menciptakan masalah bagi kami bahkan dengan beban yang agak kecil dan membutuhkan penambahan jumlah RAM dan ruang disk yang semakin meningkat. Sebagai basis data, Clickhouse lebih baik daripada ElasticSearch karena alasan berikut:
- Dukungan dialek SQL;
- Rasio kompresi terbaik dari data yang disimpan;
- Mendukung regex pencarian ekspresi reguler, bukan pencarian teks lengkap;
- Perencanaan kueri yang ditingkatkan dan kinerja keseluruhan yang lebih tinggi.
Saat ini, masalah terbesar yang muncul ketika membandingkan ClickHouse dengan ELK adalah kurangnya solusi untuk pengiriman log, serta kurangnya dokumentasi dan manual pelatihan tentang topik ini. Pada saat yang sama, setiap pengguna dapat mengkonfigurasi ELK menggunakan Digital Ocean Guide, yang sangat penting untuk implementasi cepat dari teknologi tersebut. Ada mesin basis data di sini, tetapi belum ada Filebeat untuk ClickHouse. Ya, ada
fluentd dan sistem untuk bekerja dengan
loghouse log, ada alat
clicktail untuk memasukkan data dari file log ke ClickHouse, tetapi semua ini membutuhkan waktu lebih lama. Namun, ClickHouse masih mengarah karena kesederhanaannya, jadi bahkan pemula menginstalnya secara mendasar dan mulai menggunakannya sepenuhnya hanya dalam 10 menit.
Memilih solusi minimalis, saya mencoba menggunakan FluentBit, alat untuk mengirim log dengan jumlah memori yang sangat kecil, bersama dengan ClickHouse, sambil mencoba menghindari penggunaan Kafka. Namun, ketidakcocokan kecil, seperti
masalah format tanggal , harus diperbaiki sebelum ini dapat dilakukan tanpa lapisan proxy yang mengubah data dari FluentBit ke ClickHouse.
Sebagai alternatif untuk Kibana, Anda dapat menggunakan
Grafana sebagai
backend ClickHouse. Seperti yang saya pahami, ini dapat menyebabkan masalah kinerja saat memberikan sejumlah besar titik data, terutama dengan versi Grafana yang lebih lama. Di Qwintry, kami belum mencoba ini, tetapi keluhan tentang ini dari waktu ke waktu muncul di saluran dukungan ClickHouse di Telegram.
Mengganti Google Big Query dan Amazon RedShift (solusi untuk perusahaan besar)
Kasus penggunaan ideal untuk BigQuery adalah untuk mengunduh 1 TB data JSON dan melakukan kueri analitik. Big Query adalah produk hebat yang skalabilitasnya sulit ditaksir terlalu tinggi. Ini adalah perangkat lunak yang jauh lebih kompleks daripada ClickHouse, berjalan pada cluster internal, tetapi dari sudut pandang klien, ia memiliki banyak kesamaan dengan ClickHouse. BigQuery dapat dengan cepat naik harga segera setelah Anda membayar untuk setiap PILIH, jadi ini adalah solusi SaaS nyata dengan semua pro dan kontra.
ClickHouse adalah pilihan terbaik ketika Anda melakukan banyak pertanyaan komputasi mahal. Semakin banyak kueri SELECT yang Anda jalankan setiap hari, semakin masuk akal untuk mengganti Kueri Besar dengan ClickHouse, karena penggantian seperti itu akan menghemat ribuan dolar ketika Anda berhadapan dengan banyak terabyte data yang diproses. Ini tidak berlaku untuk data yang disimpan, yang cukup murah untuk diproses di Big Query.
Artikel oleh pendiri Altinity, Alexander Zaitsev,
"Switching to ClickHouse," berbicara tentang manfaat migrasi DBMS.
Mengganti TimescaleDB
TimescaleDB adalah ekstensi PostgreSQL yang mengoptimalkan pekerjaan dengan deret waktu deret waktu dalam database reguler (
https://docs.timescale.com/v1.0/introduction ,
https://habr.com/en/company/zabbix/blog/458530 / ).
Meskipun ClickHouse bukan pesaing serius dalam seri time series, tetapi struktur kolom dan eksekusi vektor dari query, dalam kebanyakan kasus pemrosesan query analitis, ini jauh lebih cepat daripada TimescaleDB. Pada saat yang sama, kinerja menerima data paket ClickHouse adalah sekitar 3 kali lebih tinggi, di samping itu, menggunakan ruang disk 20 kali lebih sedikit, yang sangat penting untuk memproses sejumlah besar data historis:
https://www.altinity.com/blog/ClickHouse-for -waktu-seri .
Tidak seperti ClickHouse, satu-satunya cara untuk menghemat ruang disk di TimescaleDB adalah menggunakan ZFS atau sistem file serupa.
Pembaruan ClickHouse yang akan datang cenderung memperkenalkan kompresi delta, yang akan membuatnya lebih cocok untuk memproses dan menyimpan data deret waktu. TimescaleDB mungkin merupakan pilihan yang lebih baik daripada ClickHouse telanjang dalam kasus berikut:
- instalasi kecil dengan jumlah RAM yang sangat kecil (<3 GB);
- sejumlah besar INSERT kecil yang tidak ingin Anda buffer menjadi fragmen besar;
- konsistensi, keseragaman, dan persyaratan ACID yang lebih baik;
- Dukungan PostGIS;
- bergabung dengan tabel PostgreSQL yang ada, karena Timescale DB pada dasarnya adalah PostgreSQL.
Persaingan dengan Hadoop dan Sistem MapReduce
Hadoop dan produk MapReduce lainnya dapat melakukan banyak perhitungan rumit, tetapi mereka biasanya bekerja dengan penundaan besar. ClickHouse memperbaiki masalah ini dengan memproses terabyte data dan memberikan hasil hampir secara instan. Dengan demikian, ClickHouse jauh lebih efisien untuk melakukan penelitian analitik interaktif yang cepat, yang seharusnya menarik bagi spesialis pemrosesan data.
Persaingan dengan Pinot dan Druid
Pesaing terdekat ClickHouse adalah Pinot dan Druid, produk open source yang dapat diukur secara linear. Pekerjaan yang sangat baik membandingkan sistem ini diterbitkan dalam sebuah artikel oleh
Roman Leventov tanggal 1 Februari 2018.
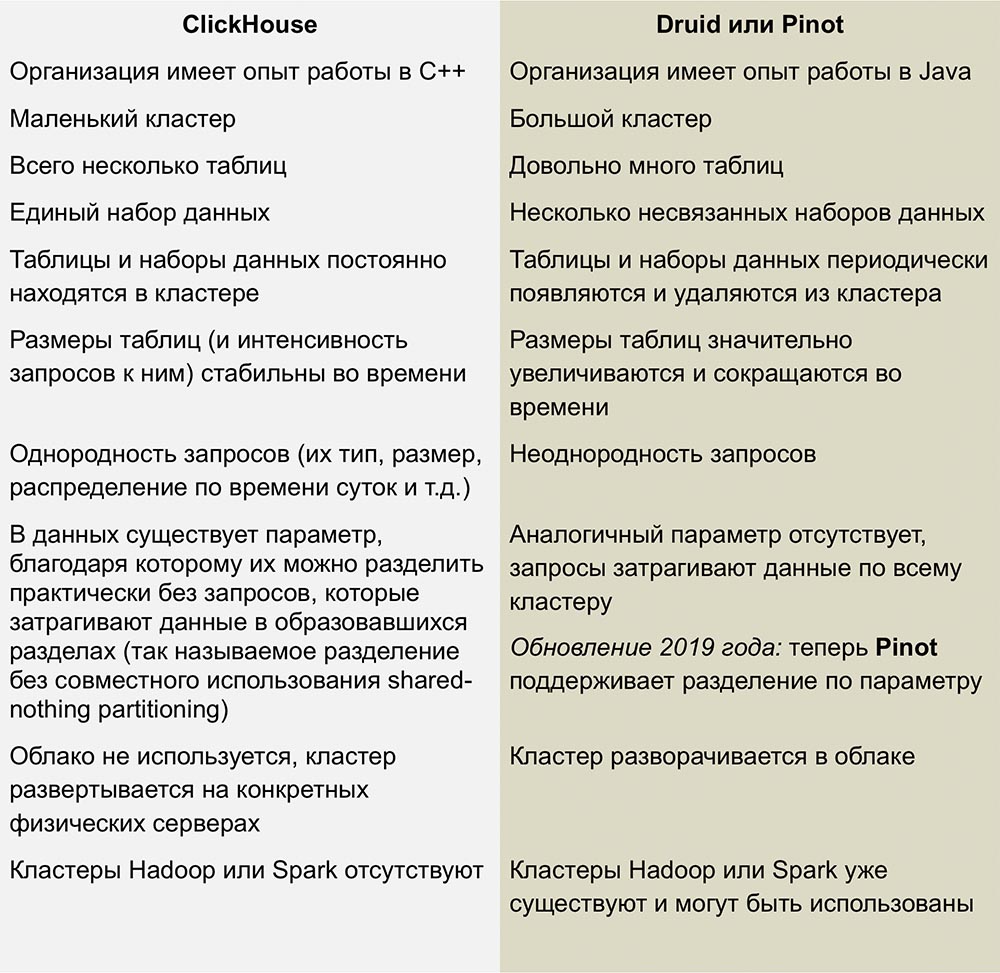
Artikel ini memerlukan pembaruan - menyatakan bahwa ClickHouse tidak mendukung operasi UPDATE dan DELETE, yang tidak sepenuhnya benar untuk versi terbaru.
Kami tidak memiliki pengalaman yang cukup dengan DBMS ini, tetapi saya tidak suka kompleksitas infrastruktur yang digunakan untuk menjalankan Druid dan Pinot - ini adalah sejumlah "bagian bergerak" yang dikelilingi oleh Jawa dari semua sisi.
Druid dan Pinot adalah proyek inkubator Apache, progres pengembangannya dibahas secara rinci oleh Apache di halaman proyek GitHub-nya. Pinot muncul di inkubator pada Oktober 2018, dan Druid lahir 8 bulan sebelumnya - pada bulan Februari.
Kurangnya informasi tentang cara kerja AFS memberi saya beberapa, dan mungkin pertanyaan konyol. Saya bertanya-tanya apakah penulis Pinot memperhatikan bahwa Yayasan Apache lebih cenderung pada Druid, dan apakah sikap terhadap pesaing ini membuat iri? Akankah pengembangan Druid melambat dan Pinot akan meningkat jika sponsor yang mendukung Druid tiba-tiba tertarik pada yang terakhir?
Kerugian ClickHouse
Ketidakdewasaan: Jelas, ini masih bukan teknologi yang membosankan, tetapi dalam hal apa pun, tidak ada yang serupa yang diamati dalam DBMS kolumnis lainnya.
Sisipan kecil tidak berfungsi dengan baik pada kecepatan tinggi: sisipan harus dibagi menjadi beberapa bagian besar, karena kinerja sisipan kecil menurun secara proporsional dengan jumlah kolom di setiap baris. Ini adalah cara ClickHouse menyimpan data pada disk - setiap kolom berarti 1 file atau lebih, sehingga untuk memasukkan 1 baris yang berisi 100 kolom, Anda harus membuka dan menulis setidaknya 100 file. Inilah sebabnya mengapa perantara diperlukan untuk menyangga sisipan (kecuali klien itu sendiri menyediakan penyangga) - biasanya ini adalah Kafka atau semacam sistem manajemen antrian. Anda juga dapat menggunakan mesin tabel Buffer untuk nanti menyalin potongan besar data ke tabel MergeTree.
Gabungan tabel dibatasi oleh RAM server, tetapi setidaknya mereka ada di sana! Misalnya, Druid dan Pinot sama sekali tidak memiliki koneksi seperti itu, karena mereka sulit untuk diimplementasikan secara langsung dalam sistem terdistribusi yang tidak mendukung pergerakan data dalam jumlah besar di antara node.
Kesimpulan
Di tahun-tahun mendatang, kami berencana untuk menggunakan ClickHouse secara ekstensif di Qwintry, karena DBMS ini memberikan keseimbangan kinerja yang sangat baik, overhead yang rendah, skalabilitas, dan kesederhanaan. Saya cukup yakin bahwa itu akan mulai menyebar dengan cepat segera setelah komunitas ClickHouse menghasilkan lebih banyak cara untuk menggunakannya pada instalasi kecil dan menengah.
Sedikit iklan :)
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikan kepada teman Anda
VPS berbasis cloud untuk pengembang mulai $ 4,99 ,
analog unik dari server entry-level yang diciptakan oleh kami untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps mulai dari $ 19 atau cara membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
Dell R730xd 2 kali lebih murah di pusat data Equinix Tier IV di Amsterdam? Hanya kami yang memiliki
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV dari $ 199 di Belanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - mulai dari $ 99! Baca tentang
Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?