
Pendahuluan
Saya sangat suka pemrograman, saya seorang amatir dan pertama dan terakhir kali saya menghasilkan uang pada pemrograman kembali pada tahun 1996. Tetapi kadang-kadang saya menulis sesuatu untuk mengotomatisasi tugas sehari-hari. Sekitar setahun yang lalu, golang ditemukan. Sebagai alat untuk membuat utilitas, golang ternyata sangat nyaman. Jadi
Ada kebutuhan untuk memproses sejumlah besar (lebih dari seribu, dan saya melihat senyum pro) dari arsip file dengan informasi geofisika khusus. Format file adalah teks, sederhana. Jika Anda tiba-tiba tertarik maka ini adalah format LAS .
File LAS berisi tajuk dan data.
Data ini praktis CSV, hanya pembatas tab atau spasi.
Dan tajuk berisi deskripsi data dan di sini biasanya berisi teks Rusia. Ini mungkin nama bidang, nama studi yang dicatat dalam file, dll.
File-file ini dibuat pada waktu yang berbeda dan dalam program yang berbeda, ia menemukan fakta bahwa dalam satu bagian file dikodekan dalam CP1251, dan bagian dalam CP866. Saya perlu memproses file-file ini, yang berarti mengerti. Jadi itu diperlukan untuk secara otomatis menentukan file encoding.
Akibatnya, ia menciptakan sepeda di golang dan, karenanya, sebuah perpustakaan kecil lahir dengan kemampuan untuk mendeteksi halaman kode.
Tentang penyandian. Belum lama ini di habr ada artikel bagus tentang penyandian Bagaimana penyandian teks berfungsi. Dari mana "buaya" berasal. Prinsip-prinsip pengkodean. Generalisasi dan analisis terperinci. Jika Anda ingin memahami apa itu "tulang" atau "tulang", maka itu layak dibaca.
Pada awalnya saya melemparkan keputusan saya. Kemudian saya mencoba mencari solusi kerja siap pakai untuk golang, tetapi gagal. Ada dua solusi, tetapi keduanya tidak bekerja.
- "Keluar dari kotak" yang pertama - fungsi golang.org/x/net/html/charset DetermineEncoding ()
- Perpustakaan kedua - saintfish / chardet di github
Keduanya pasti salah pada beberapa pengkodean. Standar yang umumnya tidak dapat menentukan apa pun dari file teks, dapat dimengerti, itu dilakukan untuk halaman html.
Saat mencari, saya sering menemukan utilitas yang sudah jadi dari dunia linux - enca . Ditemukan versinya dikompilasi untuk WIN32, versi 1.12. Saya juga akan mempertimbangkannya, ada hal-hal menyenangkan di sana. Saya segera minta maaf atas ketidaktahuan saya tentang linux, yang berarti mungkin ada lebih banyak solusi yang Anda juga dapat mencoba untuk mengacaukan ke kode golang, saya tidak melihat lagi.
Perbandingan solusi yang ditemukan untuk encoding deteksi otomatis
Mempersiapkan katalog data uji softlandia \ cpd dengan file dalam penyandian berbeda. Isi file sangat pendek dan sama. Satu baris "Bahasa Rusia di coding CodePageName". Saya menambahkan file dengan campuran penyandian dan beberapa kasus kompleks dan mencoba untuk menentukan.
Saya pikir itu ternyata lucu.
Pengamatan 1
enca tidak menentukan pengkodean file UTF-16LE tanpa BOM - ini aneh, oke. Saya mencoba menambahkan lebih banyak teks, tetapi tidak mendapatkan hasilnya.
Pengamatan 2. Masalah dengan codings CP1251 dan KOI8-R
Baris 15 dan 16. Perintah enca memiliki masalah.
Di sini saya akan membuat penjelasan, faktanya adalah bahwa pengkodean CP1251 (alias Windows 1251) dan KOI8-R sangat dekat jika kita hanya mempertimbangkan karakter alfabet.
Tabel CP 1251
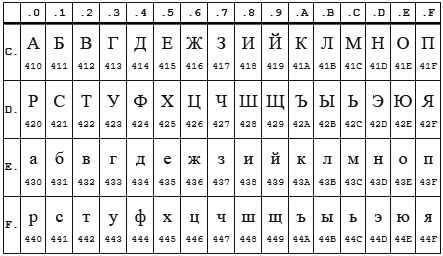
Tabel KOI8-r

Di kedua pengkodean, alfabet terletak dari 0xC0 ke 0xFF , tetapi di mana satu pengkodean memiliki huruf besar, yang lain memiliki huruf kecil. Rupanya enca bekerja dalam huruf kecil. Jadi ternyata, jika Anda mengirim string "STP" yang dikodekan dalam CP1251 ke program enca , maka itu akan memutuskan bahwa itu adalah string "bersemangat" yang dikodekan dalam KOI8-r , yang akan dilaporkan. Terbalik juga bekerja.
Pengamatan 3
Perpustakaan standar html / charset hanya dapat dipercaya dengan definisi UTF-8 , tapi hati-hati! Ini harus digunakan dengan tepat charset.DetermineEncoding () , karena metode utf8.Valid (b [] byte) pada utf-16be file yang disandikan mengembalikan true .
Sepeda sendiri

Deteksi otomatis penyandian hanya dimungkinkan dengan metode heuristik, tidak akurat. Jika kami tidak tahu dalam bahasa apa dan dalam pengkodean apa file teks ditulis, maka dimungkinkan untuk menentukan pengkodean dengan akurasi tinggi, tetapi akan sulit ... dan Anda akan membutuhkan banyak teks.
Bagi saya, tujuan ini tidak ditetapkan. Cukup bagi saya untuk menentukan pengkodean dengan asumsi bahwa ada Rusia. Dan kedua, Anda perlu menentukan dengan sejumlah kecil karakter - 10 karakter harus memiliki definisi yang cukup percaya diri, dan lebih disukai 5-6 karakter secara umum.
Algoritma
Ketika saya menemukan kebetulan encoding KOI8-r dan CP1251 dengan lokasi alfabet, saya sedih selama beberapa hari ... menjadi jelas bahwa saya harus berpikir sedikit. Ternyata begini.
Keputusan kunci:
- Kami akan bekerja dengan sepotong byte, untuk kompatibilitas dengan charset.DetermineEncoding ()
- Pengkodean dan kasus BOM UTF-8 diperiksa secara terpisah
- Data input dilewatkan secara bergantian ke setiap pengkodean. Masing-masing sendiri menghitung dua kriteria bilangan bulat. Jumlah dua kriteria lebih besar, dia menang.
Kriteria kepatuhan
Kriteria pertama
Kriteria pertama adalah jumlah huruf paling populer dari alfabet Rusia.
Huruf yang paling umum adalah: o, e, a, dan, n, t, s, p, b, l, k, m, d, p, y . Surat-surat ini memberikan cakupan 82%. Untuk semua penyandian kecuali KOI8-r dan CP1251, saya hanya menggunakan 9 huruf pertama: o, e, a, dan, n, t, s, p, c. Ini cukup untuk tekad yang dapat diandalkan.
Tetapi untuk KOI8-r dan CP1251 saya harus memodifikasi file. Kode beberapa huruf ini bertepatan, misalnya, huruf o memiliki kode 0xEE di CP1251, sedangkan di KOI8-r kode ini memiliki huruf n . Surat-surat populer berikut diambil untuk pengkodean ini. Untuk CP1251 saya menggunakan a, dan, n, c, p, b, l, k, i. Untuk KOI8-r - o, a, u, t, s, b, l, k, m.
Kriteria kedua
Sayangnya, untuk kasus yang sangat singkat (panjang total teks Rusia adalah 5-6 karakter), kemunculan huruf populer berada pada level 1-3 pcs dan ada tumpang tindih pengkodean KOI8-r dan CP1251. Saya harus memperkenalkan kriteria kedua. Penghitungan konsonan + vokal .
Kombinasi semacam itu diharapkan paling sering terjadi dalam bahasa Rusia dan, karenanya, dalam pengkodean di mana jumlah pasangan demikian lebih besar, pengkodean memiliki kriteria yang lebih besar.
Kedua kriteria dihitung, dijumlahkan, dan jumlah yang diterima adalah kriteria akhir.
Hasilnya ditunjukkan pada tabel di atas.
Fitur yang saya temui
Sedikit sentuhan pada pesona dan masalah yang terkait dengan golang. Bagian ini mungkin menarik hanya bagi pemula untuk menulis di golang.
Masalahnya
Secara pribadi berjalan di sekitar beberapa kerikil bawah laut dari 50 nuansa Go: perangkap, perangkap, dan kesalahan pemula yang umum .
Terlalu khawatir dan mencoba untuk meniup ke dalam air, mendengar dari orang lain tentang luka bakar yang mengerikan dari susu, pergi terlalu jauh dengan memeriksa parameter input dari tipe io.Reader. Saya memeriksa variabel seperti io.Reader dengan refleksi.
Tapi ternyata dalam kasus saya, cukup untuk memeriksa nol. Sekarang semuanya lebih mudah
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
panggilan ke bufio.NewReader (r) .Peek (ReadBufSize) diam-diam melewati tes berikut:
var data *os.File res, err := CodePageDetect(data)
Dalam hal ini, Mengintip () mengembalikan kesalahan.
Setelah menginjak menyapu dengan transfer array dengan nilai. Agak bodoh mencoba mengubah elemen yang disimpan di peta, menjalankannya dalam jangkauan ...
Kesenangan
Sulit untuk mengatakan dengan tepat apakah tangan berjabat tangan konstan dari linter dan compiler atau penggunaan aktif range, atau semuanya bersama-sama, tetapi praktis tidak ada serangan untuk membuat indeks keluar dari batas.
Tentu saja, sangat menyenangkan tinggal bersama pemulung. Saya kira saya masih harus menguasai kekuatan mengotomatiskan alokasi / pelepasan memori, tetapi sejauh ini senyum tolol tidak meninggalkan wajah saya.
Mengetik yang kuat juga merupakan bagian dari kebahagiaan.
Variabel yang memiliki jenis fungsi, dengan demikian, implementasi yang mudah dari berbagai perilaku untuk objek dari jenis yang sama.
Aneh sedikit harus duduk di debugger, membaca ulang kode biasanya memberikan hasil.
Anak anjing senang karena memiliki banyak alat di luar kotak, itu perasaan yang luar biasa ketika kompiler, bahasa, perpustakaan dan IDE Visual Studio Code bekerja untuk Anda bersama-sama, secara harmonis.
Terima kasih Falconandy untuk tips yang konstruktif dan bermanfaat.
Terima kasih padanya
- menerjemahkan tes pada bersaksi dan mereka benar-benar menjadi lebih mudah dibaca
- tes tetap untuk jalur file data untuk kompatibilitas dengan Linux
- berjalan oleh seorang linter - namun ia menemukan satu kesalahan nyata (sialan copy / masa lalu)
Saya terus menambahkan tes, kasus tidak mendefinisikan UTF16 terungkap. Diperbarui. Sekarang UTF16 dan LE dan BE terdeteksi bahkan tanpa adanya huruf Rusia