Cube-on-cube, metaclusters, sel, alokasi sumber daya
Fig. 1. ekosistem Kubernetes di Alibaba CloudSejak 2015, Layanan Cloud Container Alibaba untuk Kubernetes (ACK) telah menjadi salah satu layanan cloud yang tumbuh paling cepat di Alibaba Cloud. Ini melayani banyak pelanggan dan juga mendukung infrastruktur internal Alibaba dan layanan cloud lainnya dari perusahaan.
Seperti dalam layanan kontainer serupa dari penyedia cloud kelas dunia, prioritas utama kami adalah keandalan dan ketersediaan. Oleh karena itu, platform yang dapat diskalakan dan dapat diakses secara global telah dibuat untuk puluhan ribu kluster Kubernet.
Dalam artikel ini, kami akan berbagi pengalaman mengelola sejumlah besar kluster Kubernet pada infrastruktur cloud, serta arsitektur platform yang mendasarinya.
Entri
Kubernetes telah menjadi standar de facto untuk berbagai beban kerja cloud. Seperti yang ditunjukkan pada gambar. 1 di bagian atas, semakin banyak aplikasi Cloud Alibaba sekarang bekerja di cluster Kubernetes: ini adalah aplikasi stateful / stateless, serta manajer aplikasi. Mengelola Kubernet selalu menjadi topik diskusi yang menarik dan serius bagi para insinyur yang terlibat dalam membangun dan memelihara infrastruktur. Ketika datang ke penyedia cloud seperti Alibaba Cloud, scaling datang kedepan. Bagaimana cara mengelola kluster Kubernetes pada skala ini? Kami sudah bicara tentang praktik terbaik untuk mengelola 10.000 node Kubernet yang besar. Tentu saja, ini merupakan masalah penskalaan yang menarik. Tetapi ada skala skala lain: jumlah
cluster itu sendiri .
Kami membahas topik ini dengan banyak pengguna ACK. Kebanyakan dari mereka lebih suka menjalankan lusinan, jika bukan ratusan, kluster Kubernet kecil atau menengah. Ada alasan yang masuk akal untuk ini: membatasi kerusakan potensial, mempartisi cluster untuk tim yang berbeda, membuat cluster virtual untuk pengujian. Jika ACK berupaya melayani audiens global dengan model penggunaan ini, ACK harus mengelola sejumlah besar cluster di lebih dari 20 wilayah dengan andal dan efisien.
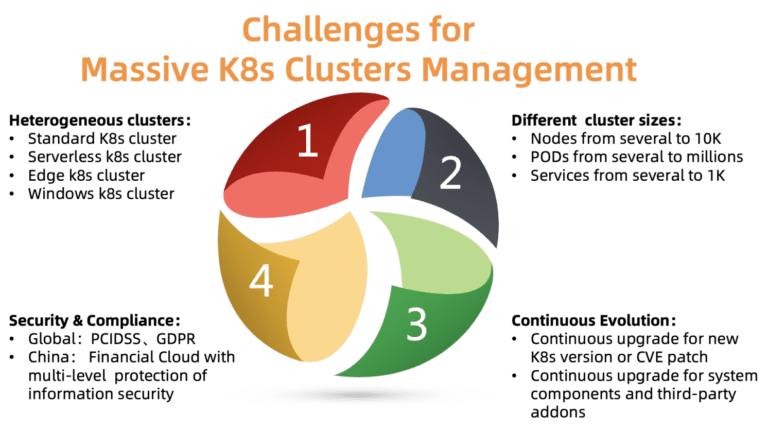 Fig. 2. Tantangan mengelola sejumlah besar kelompok Kubernet
Fig. 2. Tantangan mengelola sejumlah besar kelompok KubernetApa masalah utama manajemen klaster pada skala ini? Seperti yang ditunjukkan pada gambar, ada empat masalah yang harus dihadapi:
ACK harus mendukung berbagai jenis cluster, termasuk standar, serverless, Edge, Windows dan beberapa lainnya. Cluster yang berbeda memerlukan parameter yang berbeda, komponen dan model hosting. Beberapa pelanggan memerlukan bantuan dengan kustomisasi untuk kasus khusus mereka.
- Ukuran cluster yang berbeda
Cluster bervariasi dalam ukuran: dari sepasang node dengan beberapa pod hingga puluhan ribu node dengan ribuan pod. Persyaratan sumber daya juga sangat berbeda. Alokasi sumber daya yang tidak tepat dapat memengaruhi kinerja atau bahkan menyebabkan kegagalan.
Kubernetes berkembang pesat. Versi baru dirilis setiap beberapa bulan. Pelanggan selalu siap untuk mencoba fitur baru. Dengan demikian, mereka ingin menempatkan beban pengujian pada versi baru Kubernetes, dan beban kerja pada yang stabil. Untuk memenuhi persyaratan ini, ACK harus terus memberikan versi baru Kubernet kepada pelanggannya, sambil mempertahankan versi stabil.
Cluster didistribusikan di berbagai daerah. Karena itu, mereka harus mematuhi berbagai persyaratan keselamatan dan peraturan resmi. Sebagai contoh, sebuah cluster di Eropa harus mematuhi GDPR, dan cloud finansial di China harus memiliki tingkat perlindungan tambahan. Persyaratan ini wajib, tidak dapat diabaikan, karena ini menciptakan risiko besar bagi pelanggan platform cloud.
Platform ACK dirancang untuk menyelesaikan sebagian besar masalah di atas. Saat ini, secara andal dan stabil mengelola lebih dari 10 ribu cluster Kubernetes di seluruh dunia. Mari kita lihat bagaimana kita berhasil mencapai ini, termasuk karena beberapa prinsip utama desain / arsitektur.
Desain
Kubus-on-kubus dan sarang lebah
Tidak seperti hierarki terpusat, arsitektur berbasis sel biasanya digunakan untuk skala platform di luar pusat data tunggal atau untuk memperluas cakupan pemulihan bencana.
Setiap wilayah di Alibaba Cloud terdiri dari beberapa zona (AZ) dan biasanya terkait dengan pusat data tertentu. Di wilayah besar (seperti Huangzhou), ribuan kluster klien Kubernet yang menjalankan ACK sering ditemukan.
ACK mengelola kluster Kubernetes ini menggunakan Kubernetes sendiri, yaitu, kami memiliki metacluster Kubernetes untuk mengelola kluster klien Kubernetes. Arsitektur ini juga disebut "cube-on-cube" (kube-on-kube, KoK). Arsitektur KoK menyederhanakan pengelolaan kluster klien karena penyebaran kluster menjadi sederhana dan deterministik. Lebih penting lagi, kita dapat menggunakan kembali fitur Kubernet asli. Misalnya, mengelola server API melalui penggunaan, menggunakan operator etcd untuk mengelola beberapa etcd. Rekursi semacam itu selalu membawa kesenangan khusus.
Dalam wilayah yang sama, beberapa metaclusters Kubernet disebarkan, tergantung pada jumlah klien. Metaclusters ini kita sebut sel. Untuk melindungi dari kegagalan seluruh zona, ACK mendukung penyebaran multi-aktif di satu wilayah: metacluster mendistribusikan komponen wizard kluster klien Kubernetes ke beberapa zona dan mulai secara bersamaan, yaitu dalam mode multi-aktif. Untuk memastikan keandalan dan keefektifan wizard, ACK mengoptimalkan penempatan komponen dan memastikan bahwa server API dan sebagainya dekat satu sama lain.
Model ini memungkinkan Anda untuk mengelola Kubernetes secara efektif, fleksibel, dan andal.
Perencanaan Sumber Daya Metacluster
Seperti yang telah kami sebutkan, jumlah metaclusters di setiap wilayah tergantung pada jumlah pelanggan. Tetapi pada titik apa Anda menambahkan metacluster baru? Ini adalah masalah perencanaan sumber daya yang khas. Sebagai aturan, itu adalah kebiasaan untuk membuat yang baru ketika metaclusters yang ada telah menghabiskan semua sumber dayanya.
Ambil sumber daya jaringan, misalnya. Dalam arsitektur KoK, komponen Kubernetes dari kelompok klien digunakan sebagai pod di metacluster. Kami menggunakan
Terway (Gbr. 3), sebuah plugin berkinerja tinggi yang dikembangkan oleh Alibaba Cloud untuk manajemen jaringan kontainer. Ini memberikan serangkaian kebijakan keamanan yang kaya dan memungkinkan Anda untuk terhubung ke klien virtual private cloud (VPC) melalui Alibaba Cloud Elastic Networking Interface (ENI). Untuk mendistribusikan sumber daya jaringan secara efisien di antara node, pod, dan layanan dalam metacluster, kita harus dengan cermat memantau penggunaannya di dalam metacluster dari cloud pribadi virtual. Ketika sumber daya jaringan berakhir, sel baru dibuat.
Untuk menentukan jumlah cluster klien yang optimal di setiap metacluster, kami juga memperhitungkan biaya, persyaratan kepadatan, kuota sumber daya, persyaratan keandalan, dan statistik kami. Keputusan untuk membuat metacluster baru dibuat berdasarkan semua informasi ini. Harap dicatat bahwa cluster kecil dapat berkembang pesat di masa depan, sehingga konsumsi sumber daya meningkat bahkan dengan jumlah cluster yang sama. Biasanya kami menyisakan ruang kosong yang cukup untuk pertumbuhan setiap cluster.
 Fig. 3. Arsitektur Jaringan Terway
Fig. 3. Arsitektur Jaringan TerwayPenskalaan komponen penyihir dalam kelompok klien
Komponen wizard memiliki persyaratan sumber daya yang berbeda. Mereka bergantung pada jumlah node dan pod di cluster, jumlah pengendali / operator non-standar yang berinteraksi dengan APIServer.
Di ACK, setiap kluster klien Kubernetes berbeda dalam ukuran dan persyaratan runtime. Tidak ada konfigurasi universal untuk komponen panduan hosting. Jika kita keliru menetapkan batas sumber daya yang rendah untuk klien besar, maka klusternya tidak akan mengatasi beban. Jika Anda menetapkan batas tinggi yang konservatif untuk semua cluster, maka sumber daya akan terbuang sia-sia.
Untuk menemukan kompromi halus antara keandalan dan biaya, ACK menggunakan sistem tipe. Yaitu, kami mendefinisikan tiga jenis cluster: kecil, sedang dan besar. Setiap jenis memiliki profil alokasi sumber daya yang terpisah. Jenis ini ditentukan berdasarkan pemuatan komponen penyihir, jumlah node, dan faktor lainnya. Jenis cluster dapat berubah seiring waktu. ACK secara konstan memonitor faktor-faktor ini dan karenanya dapat menambah / mengurangi jenisnya. Setelah mengubah jenis cluster, distribusi sumber daya diperbarui secara otomatis dengan intervensi pengguna minimal.
Kami sedang berupaya meningkatkan sistem ini dalam hal penskalaan yang lebih halus dan pembaruan tipe yang lebih akurat, sehingga perubahan ini terjadi lebih lancar dan lebih masuk akal secara ekonomi.
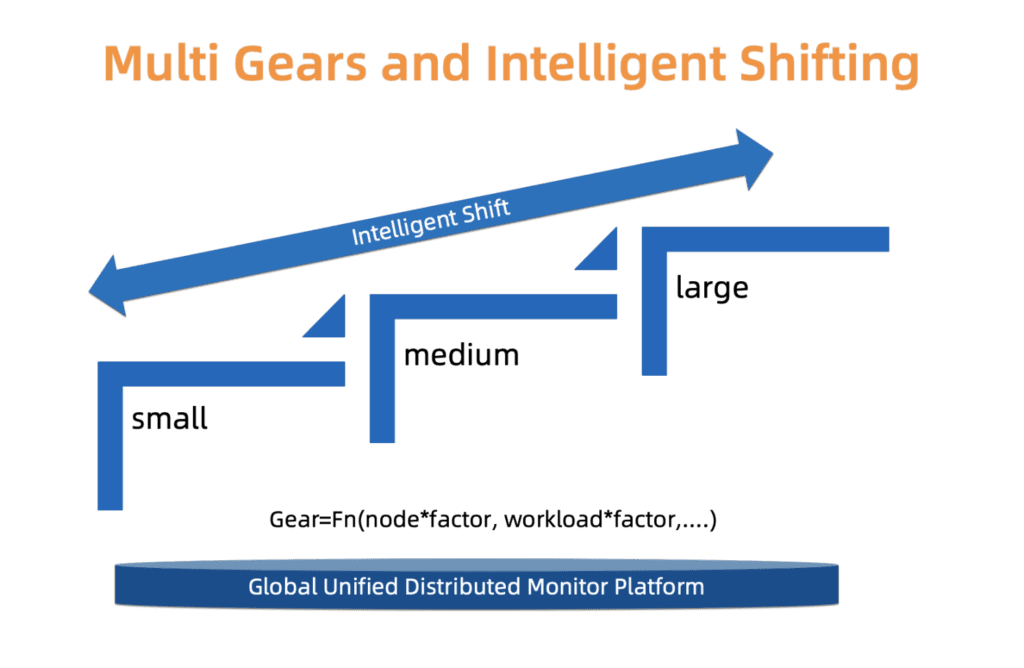 Fig. 4. Peralihan tipe multi-stage yang cerdas
Fig. 4. Peralihan tipe multi-stage yang cerdasEvolusi cluster klien dalam skala
Bagian sebelumnya menjelaskan beberapa aspek pengelolaan sejumlah besar kelompok Kubernet. Namun, ada masalah lain yang perlu diatasi: evolusi klaster.
Kubernetes adalah Linux di dunia cloud. Itu terus diperbarui dan menjadi lebih modular. Kami harus terus menyediakan versi baru kepada pelanggan kami, memperbaiki kerentanan dan memperbarui cluster yang ada, serta mengelola sejumlah besar komponen terkait (CSI, CNI, Plugin Perangkat, Plugin Penjadwal, dan banyak lainnya).
Ambil contoh manajemen komponen Kubernetes. Untuk mulai dengan, kami mengembangkan sistem registrasi dan manajemen terpusat untuk semua komponen plug-in ini.
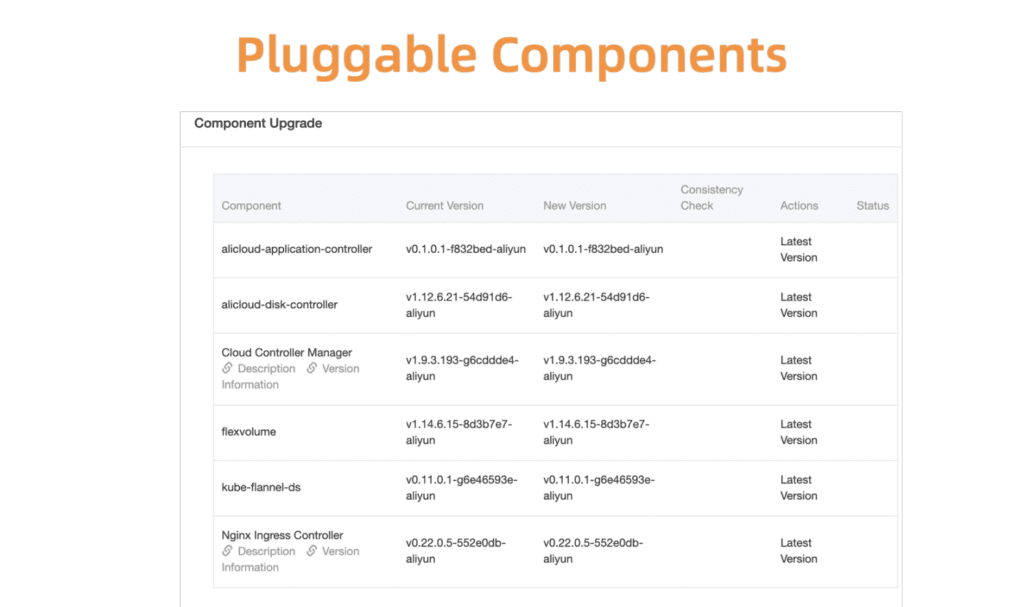 Fig. 5. Komponen fleksibel dan plug-in
Fig. 5. Komponen fleksibel dan plug-inSebelum melanjutkan, Anda harus memastikan pembaruan berhasil. Untuk melakukan ini, kami telah mengembangkan sistem pemeriksaan kesehatan komponen. Validasi dilakukan sebelum dan sesudah peningkatan.
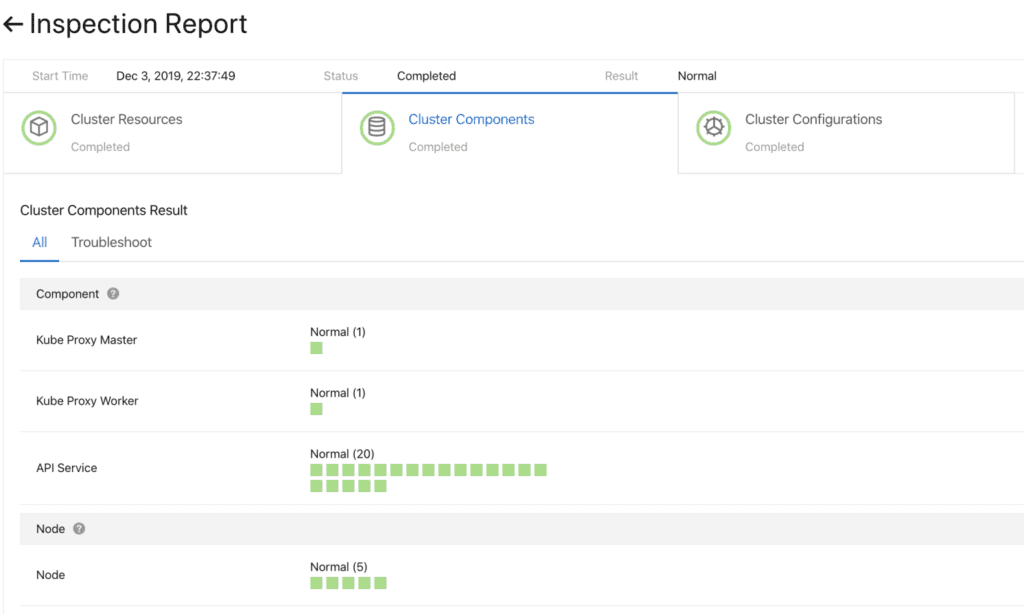 Fig. 6. Pemeriksaan awal komponen kluster
Fig. 6. Pemeriksaan awal komponen klusterUntuk memperbarui komponen ini dengan cepat dan andal, sistem penerapan berkelanjutan bekerja dengan dukungan untuk promosi parsial (skala abu-abu), jeda, dan fungsi lainnya. Kontroler Kubernetes standar tidak cocok untuk penggunaan ini. Oleh karena itu, untuk mengelola komponen cluster, kami telah mengembangkan satu set pengontrol khusus, termasuk plug-in dan modul kontrol tambahan (manajemen sespan).
Misalnya, pengontrol BroadcastJob dirancang untuk memperbarui komponen pada setiap mesin yang bekerja atau untuk memeriksa node pada setiap mesin. Pekerjaan Broadcast menjalankan pod pada setiap node di cluster, seperti DaemonSet. Namun, DaemonSet selalu mendukung operasi kontinu pod, sementara BroadcastJob menguranginya. Pengontrol Broadcast juga memulai pod pada node yang baru terhubung dan menginisialisasi node dengan komponen yang diperlukan. Pada Juni 2019, kami membuka kode sumber untuk mesin otomatisasi OpenKruise, yang kami gunakan di dalam perusahaan.
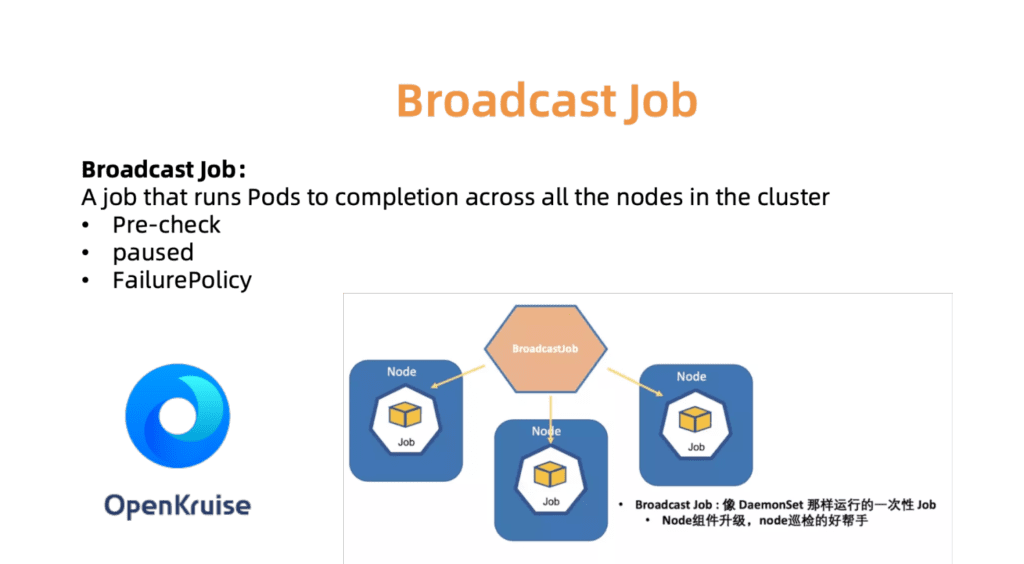 Fig. 7. OpenKurise mengatur tugas Siaran di semua situs.
Fig. 7. OpenKurise mengatur tugas Siaran di semua situs.Untuk membantu pelanggan memilih konfigurasi cluster yang tepat, kami juga menyediakan serangkaian profil yang telah ditentukan sebelumnya, termasuk profil Serverless, Edge, Windows, dan Bare Metal. Saat lanskap meluas dan kebutuhan pelanggan bertambah, kami akan menambahkan lebih banyak profil untuk menyederhanakan proses pengaturan yang membosankan.
 Fig. 8. Profil klaster yang canggih dan fleksibel untuk berbagai skenario
Fig. 8. Profil klaster yang canggih dan fleksibel untuk berbagai skenarioObservabilitas pusat data global
Seperti yang ditunjukkan di bawah ini dalam gambar. 9, Alibaba Cloud Container dikerahkan di dua puluh wilayah di dunia. Mengingat skala ini, salah satu tugas utama ACK adalah dengan mudah memantau status cluster berjalan: jika cluster klien menghadapi masalah, kami dapat dengan cepat menanggapi situasi. Dengan kata lain, Anda perlu menemukan solusi yang akan memungkinkan Anda untuk mengumpulkan statistik waktu-nyata secara efisien dan aman dari kluster klien di semua wilayah - dan menyajikan hasilnya secara visual.
 Fig. 9. Penerapan Global Layanan Cloud Container Alibaba di Dua Puluh Wilayah
Fig. 9. Penerapan Global Layanan Cloud Container Alibaba di Dua Puluh WilayahSeperti banyak sistem pemantauan Kubernetes, kami memiliki Prometheus sebagai alat utama kami. Untuk setiap metacluster, agen Prometheus mengumpulkan metrik berikut:
- Metrik OS, seperti sumber daya host (prosesor, memori, disk, dll.) Dan bandwidth jaringan.
- Metrik untuk metakluster dan sistem manajemen kluster klien, seperti kube-apiserver, kube-controller-manager, dan kube-scheduler.
- Metrik dari kubernetes-state-metrics dan cadvisor.
- Metrik Etcd, seperti waktu penulisan disk, ukuran basis data, throughput antar node, dll.
Statistik global dikumpulkan menggunakan model agregasi multilayer yang khas. Pemantauan data dari setiap metacluster pertama kali dikumpulkan di setiap wilayah, dan kemudian dikirim ke server pusat, yang menunjukkan gambaran besar. Semuanya bekerja melalui mekanisme federasi. Server Prometheus di setiap pusat data mengumpulkan metrik pusat data ini, dan server pusat Prometheus bertanggung jawab untuk menggabungkan data pemantauan. AlertManager terhubung ke Prometheus pusat dan, jika perlu, mengirimkan peringatan melalui DingTalk, email, SMS, dll. Visualisasi - menggunakan Grafana.
Pada Gambar 10, sistem pemantauan dapat dibagi menjadi tiga tingkatan:
Lapisan terjauh dari pusat. Prometheus Edge Server berjalan pada setiap metacluster, mengumpulkan metrik dari kelompok meta dan klien dalam domain jaringan yang sama.
Fungsi lapisan kaskade Prometheus adalah untuk mengumpulkan data pemantauan dari beberapa daerah. Server ini beroperasi pada tingkat unit geografis yang lebih besar seperti Cina, Asia, Eropa, dan Amerika. Ketika cluster tumbuh di suatu wilayah, itu dapat dibagi, dan kemudian server Prometheus tingkat cascading akan muncul di setiap wilayah besar baru. Dengan strategi ini, Anda dapat menskala dengan mulus sesuai kebutuhan.
Server pusat Prometheus terhubung ke semua server kaskade dan melakukan agregasi data akhir. Untuk keandalan, dua instance Prometheus pusat yang terhubung ke server kaskade yang sama dibesarkan di zona yang berbeda.
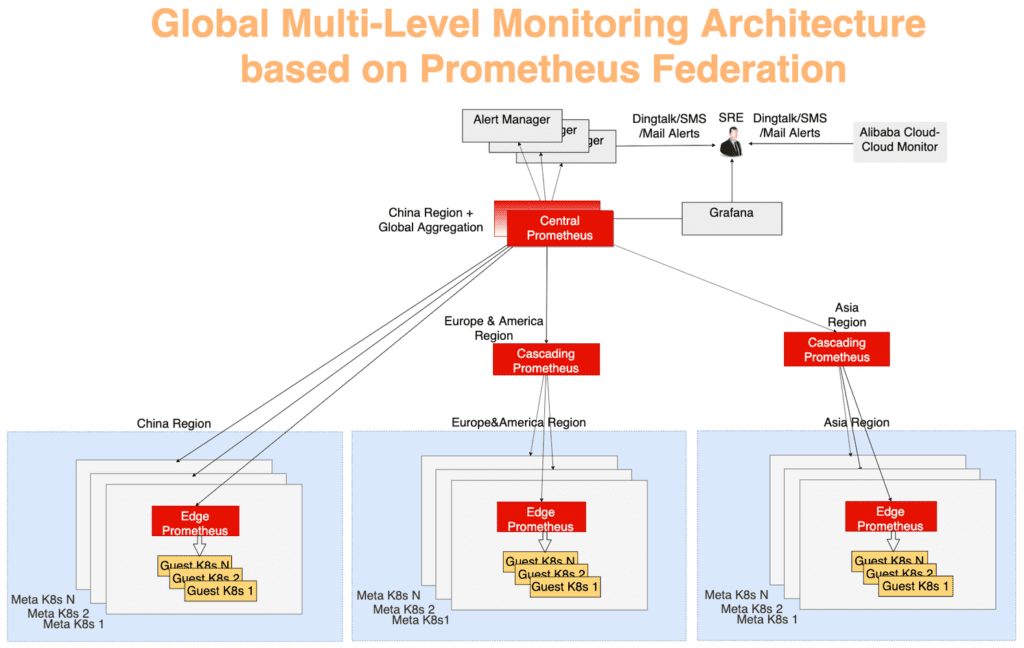 Fig. 10. Arsitektur pemantauan multi-tier global berdasarkan mekanisme federasi Prometheus
Fig. 10. Arsitektur pemantauan multi-tier global berdasarkan mekanisme federasi PrometheusRingkasan
Solusi cloud berbasis Kubernetes terus mengubah industri kami. Alibaba Cloud Container Service menyediakan hosting yang aman, andal, dan berkinerja tinggi - ini adalah salah satu layanan cloud hosting terbaik Kubernetes. Tim Alibaba Cloud sangat percaya pada prinsip-prinsip Open Source dan komunitas open source. Kami pasti akan terus membagikan pengetahuan kami di bidang operasi dan manajemen teknologi cloud.