Dalam artikel ini saya ingin berbagi pengalaman saya dalam menggunakan pustaka sumber terbuka ini pada contoh mengimplementasikan satu tugas dengan parsing file
PDF / DOC / DOCX yang berisi resume spesialis.
Di sini saya juga akan menjelaskan tahapan penerapan alat untuk menyiapkan dataset. Maka akan mungkin untuk melatih model
BERT pada dataset yang diterima sebagai bagian dari tugas mengenali entitas dari teks (
Named Entity Recognition - selanjutnya
NER ).
Jadi, dari mana harus memulai. Secara alami, pertama-tama Anda perlu menginstal dan mengkonfigurasi lingkungan untuk menjalankan alat kami. Saya akan menginstal pada
Windows 10 .
Di Habré sudah ada beberapa artikel dari pengembang perpustakaan ini, di mana hanya ada panduan instalasi terperinci. Dan dalam artikel ini saya ingin menggabungkan semuanya, mulai dari peluncuran hingga pelatihan model. Saya juga akan menunjukkan solusi untuk beberapa masalah yang saya temui saat bekerja dengan perpustakaan ini.
PENTING: saat memasang, penting untuk mematuhi versi semua produk dan komponen, karena sering kali ada masalah dengan versi yang tidak kompatibel. Ini terutama berlaku pada perpustakaan TensorFlow . Bahkan untuk beberapa tugas, hingga komitmen yang diperlukan pada GitHub, Anda harus menggunakannya. Dalam kasus DeepPavlov , kepatuhan dengan hanya versi yang didukung sudah cukup.
Saya akan menunjukkan versi produk dari konfigurasi yang berfungsi, dan spesifikasi laptop saya di mana saya memulai proses pelatihan jaringan saraf. Saya akan memberikan beberapa tautan yang juga menjelaskan instalasi dan konfigurasi perpustakaan
DeepPavlov open-source.
Tautan yang bermanfaat dari pengembang DeepPavlov
Versi Komponen untuk Instalasi
- Python 3.6.6 - 3.7
- Komunitas Visual Studio 2017 (opsional)
- Visual C ++ Build Tools 14.0.25420.1
- nVIDIA CUDA 10.0.130_411.31_win10
- cuDNN-10.0-windows10-x64-v7.6.5.32
Pengaturan lingkungan untuk dukungan GPU
- Instal Python atau Visual Studio Community 2017 yang disertakan dengan Python . Dalam instalasi saya, saya menggunakan metode kedua, menginstal Visual Studio Community dengan dukungan Python .
Tentu saja, Anda harus menambahkan path ke folder secara manualC:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64
ke variabel sistem PATH , di mana Python diinstal dari Visual Studio, tetapi ini bukan masalah bagi saya, penting bagi saya untuk mengetahui bahwa saya menginstal satu versi untuk Python .
Tapi ini kasus saya, Anda dapat menginstal semuanya secara terpisah. - Langkah selanjutnya adalah menginstal Visual C ++ Build Tools .
- Selanjutnya, instal nVIDIA CUDA .
PENTING: jika pustaka nVIDIA CUDA sebelumnya diinstal, maka Anda harus menghapus semua komponen yang sebelumnya diinstal dari nVIDIA, hingga driver video. Dan hanya pada saat itu, pada instalasi driver video yang bersih, instal nVIDIA CUDA .
- Sekarang instal cuDNN untuk nVIDIA CUDA .
Untuk melakukan ini, Anda harus mendaftar untuk keanggotaan Program Pengembang NVIDIA (gratis).

- Unduh versi cuDNN untuk CUDA 10.0

- Buka paket arsip ke dalam folder
C:\Users\<_>\Downloads\cuDNN
- Salin seluruh isi folder .. \ cuDNN ke folder tempat kita menginstal CUDA
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
- Nyalakan kembali komputer. Opsional, tapi saya sarankan.
Instal DeepPavlov
- Buat dan aktifkan lingkungan Python virtual.
PENTING: Saya melakukan ini melalui Visual Studio.
- Untuk melakukan ini, saya membuat proyek baru untuk Dari kode Python Dari Yang Ada .

- Kami menekan lebih jauh ke jendela terakhir, tetapi pada Selesai kami belum mengklik. Anda harus menghapus centang pada " Deteksi Lingkungan Virtual "

- Klik Selesai .
- Sekarang Anda perlu membuat lingkungan virtual.

- Kami meninggalkan semuanya secara default.

- Buka folder proyek pada baris perintah. Dan jalankan perintah:
.\env\Scripts\activate.bat

- Sekarang semuanya siap untuk menginstal DeepPavlov . Kami menjalankan perintah:
pip install deeppavlov
- Selanjutnya, Anda perlu menginstal TensorFlow 1.14.0 dengan dukungan GPU . Untuk melakukan ini, jalankan perintah:
pip install tensorflow-gpu==1.14.0
- Hampir semuanya siap. Anda hanya perlu memastikan bahwa TensorFlow akan menggunakan kartu grafis untuk perhitungan. Untuk melakukan ini, kami menulis skrip sederhana devices.py , konten berikut:
from tensorflow.python.client import device_lib print(device_lib.list_local_devices())
atau tensorflow_test.py :
import tensorflow as tf tf.test.is_built_with_cuda() tf.test.is_gpu_available(cuda_only=False, min_cuda_compute_capability=None)
- Setelah menjalankan devices.py , kita akan melihat sesuatu seperti berikut:
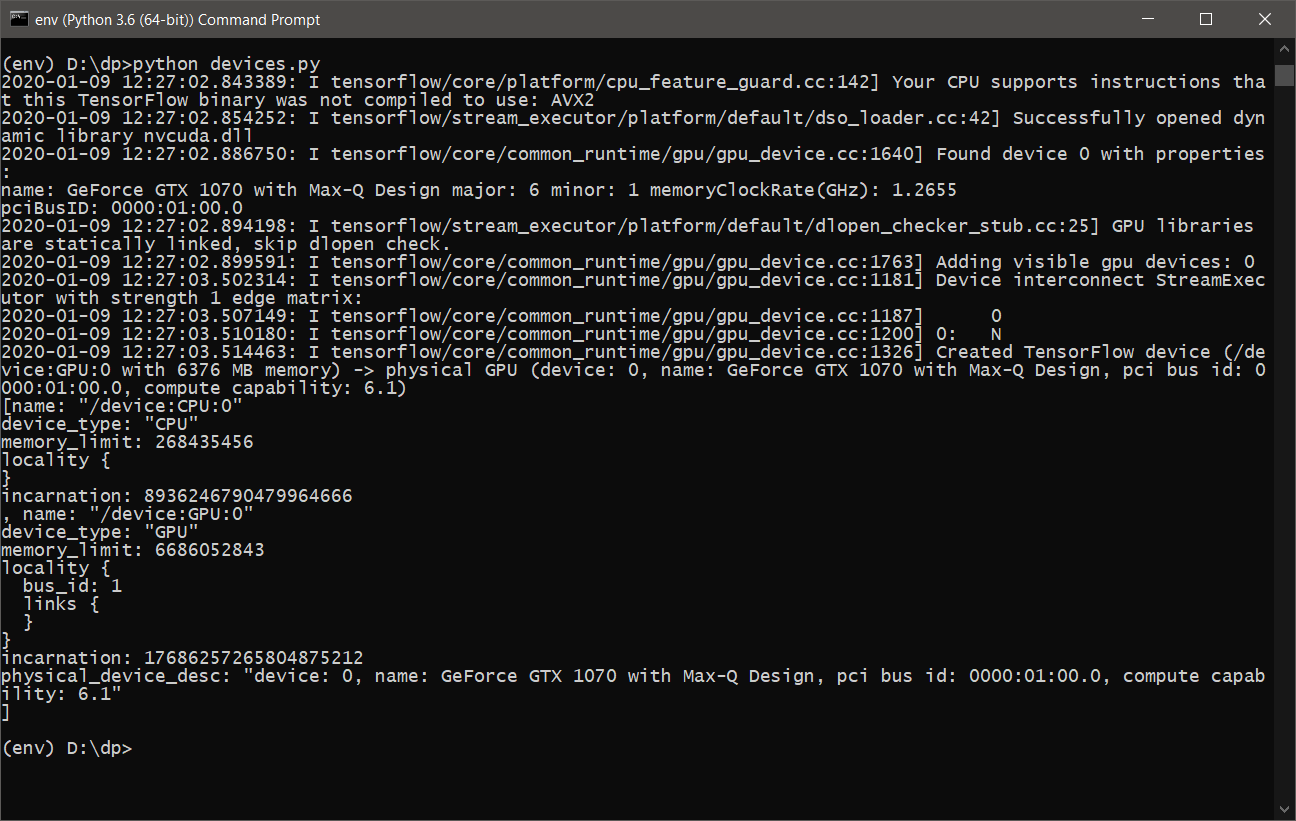
- Sekarang Anda siap belajar dan menggunakan DeepPavlov dengan dukungan GPU .
DeepPavlov di REST API
Untuk memulai dan menginstal layanan untuk REST API, Anda harus menjalankan perintah berikut:
- Instal di lingkungan virtual yang aktif
python -m deeppavlov install ner_ontonotes_bert_mult
- Unduh model ner_ontonotes_bert_mult dari server DeepPavlov
python -m deeppavlov download ner_ontonotes_bert_mult
- Jalankan REST API
python -m deeppavlov riseapi ner_ontonotes_bert_mult -p 5005
Model ini akan tersedia di
http: // localhost: 5005 . Anda dapat menentukan porta Anda.
Semua model akan diunduh secara default di sepanjang jalan.
C:\Users\<_>\.deeppavlov
Menyiapkan DeepPavlov untuk pelatihan
Sebelum memulai proses pembelajaran, kita perlu mengonfigurasi
DeepPavlov agar proses pembelajaran tidak "macet" dengan kesalahan bahwa memori pada kartu video kita penuh. Untuk ini, kami memiliki file konfigurasi untuk setiap model.
Seperti dalam contoh dari pengembang, saya juga akan menggunakan model
ner_ontonotes_bert_mult . Semua konfigurasi default untuk
DeepPavlov terletak di sepanjang jalan:
<_>\env\Lib\site-packages\deeppavlov\configs\ner
Dalam kasus saya, file tersebut akan dinamai seperti model
ner_ontonotes_bert_mult.json .
Untuk konfigurasi laptop saya, saya harus mengubah nilai
batch_size di blok
kereta menjadi 4.

Kalau tidak, kartu video saya "tersedak" setelah beberapa menit, dan proses belajarnya gagal.
Konfigurasi Nobook
- Model: MSI GS-65
- Prosesor: Core i7 8750H 2200 MHz
- Jumlah memori yang dipasang: 32 GB DDR-4
- Hard Drive: SSD 512 GB
- Kartu video: GeForce GTX 1070 8192 Mb
Alat persiapan dataset
Untuk melatih model, Anda perlu menyiapkan dataset. Dataset terdiri dari tiga file
train.txt ,
valid.txt ,
test.txt . Dengan perincian data dalam persentase kereta berikut - 80%, valid dan uji 10%.
Dataset untuk model BERT adalah sebagai berikut:
Ivan B-PERSON Ivanov I-PERSON Senior B-WORK_OF_ART Java I-WORK_OF_ART Developer I-WORK_OF_ART IT B-ORG - I-ORG Company I-ORG Key O duties O : 0 Java B-WORK_OF_ART Python B-WORK_OF_ART CSS B-WORK_OF_ART JavaScript B-WORK_OF_ART Russian B-LOC Federation I-LOC . O Petr B-PERSON Petrov I-PERSON Junior B-WORK_OF_ART Web I-WORK_OF_ART Developer I-WORK_OF_ART Boogle B-ORG IO ' O ve O developed O Web B-WORK_OF_ART - O Application O . Skills O : O ReactJS B-WORK_OF_ART Vue B-WORK_OF_ART - I-WORK_OF_ART JS I-WORK_OF_ART HTML B-WORK_OF_ART CSS B-WORK_OF_ART Russian B-LOC Federation I-LOC . O ...
Format dataset adalah sebagai berikut:
<_><><_>
PENTING: setelah akhir kalimat harus ada jeda baris. Jika penawaran berisi lebih dari 75 token, maka perlu juga untuk membuat garis istirahat, jika tidak ketika mempelajari model proses akan gagal.
Untuk menyiapkan dataset, saya menulis antarmuka web di mana dimungkinkan untuk mengunggah file
DOC / PDF / DOCX ke server, mem-parsingnya menjadi teks biasa, dan kemudian menjalankan teks ini melalui model aktif dengan akses REST API sambil menyimpan hasilnya dalam database perantara. Untuk ini saya menggunakan
MongoDB .
Setelah tindakan di atas selesai, Anda dapat melanjutkan ke pembentukan dataset untuk kebutuhan kita.
Untuk melakukan ini, di antarmuka web tertulis saya, saya membuat panel terpisah di mana dimungkinkan untuk mencari berdasarkan token dataset dan kemudian mengubah jenis token dan teks token itu sendiri.
Alat ini juga tahu cara otomatis, berdasarkan daftar kata, memperbarui jenis token yang ditentukan oleh pengguna berdasarkan permintaan.
Secara umum, alat ini membantu mengotomatiskan bagian dari pekerjaan, tetapi Anda masih harus melakukan banyak pekerjaan manual.
Antarmuka untuk memeriksa hasil dan membagi dataset menjadi tiga file juga diimplementasikan.
Pelatihan DeepPavlov
Jadi kami sampai pada bagian yang paling menarik. Untuk proses pembelajaran, pertama-tama Anda harus mengunduh model
ner_ontonotes_bert_mult , jika Anda belum melakukannya, Anda harus menyelesaikan dua langkah pertama dari bagian
DeepPavlov ke REST API di atas.
Sebelum memulai proses pembelajaran, Anda harus menyelesaikan dua langkah:
- Hapus sepenuhnya folder dengan model yang terlatih:
C:\Users\<_>\.deeppavlov\models\ner_ontonotes_bert_mult
Karena model ini dilatih pada dataset yang berbeda. - Salin file dataset yang sudah disiapkan train.txt, valid.txt, test.txt ke folder
C:\Users\<_>\.deeppavlov\downloads\ontonotes
Sekarang Anda dapat memulai proses pembelajaran.
Untuk memulai pelatihan, Anda dapat menulis skrip
train.py sederhana dari formulir berikut:
from deeppavlov import configs, train_model ner_model = train_model(configs.ner.ner_ontonotes_bert_mult, download=False)
atau gunakan baris perintah:
python -m deeppavlov train <_>\env\Lib\site-packages\deeppavlov\configs\ner\ner_ontonotes_bert_mult.json
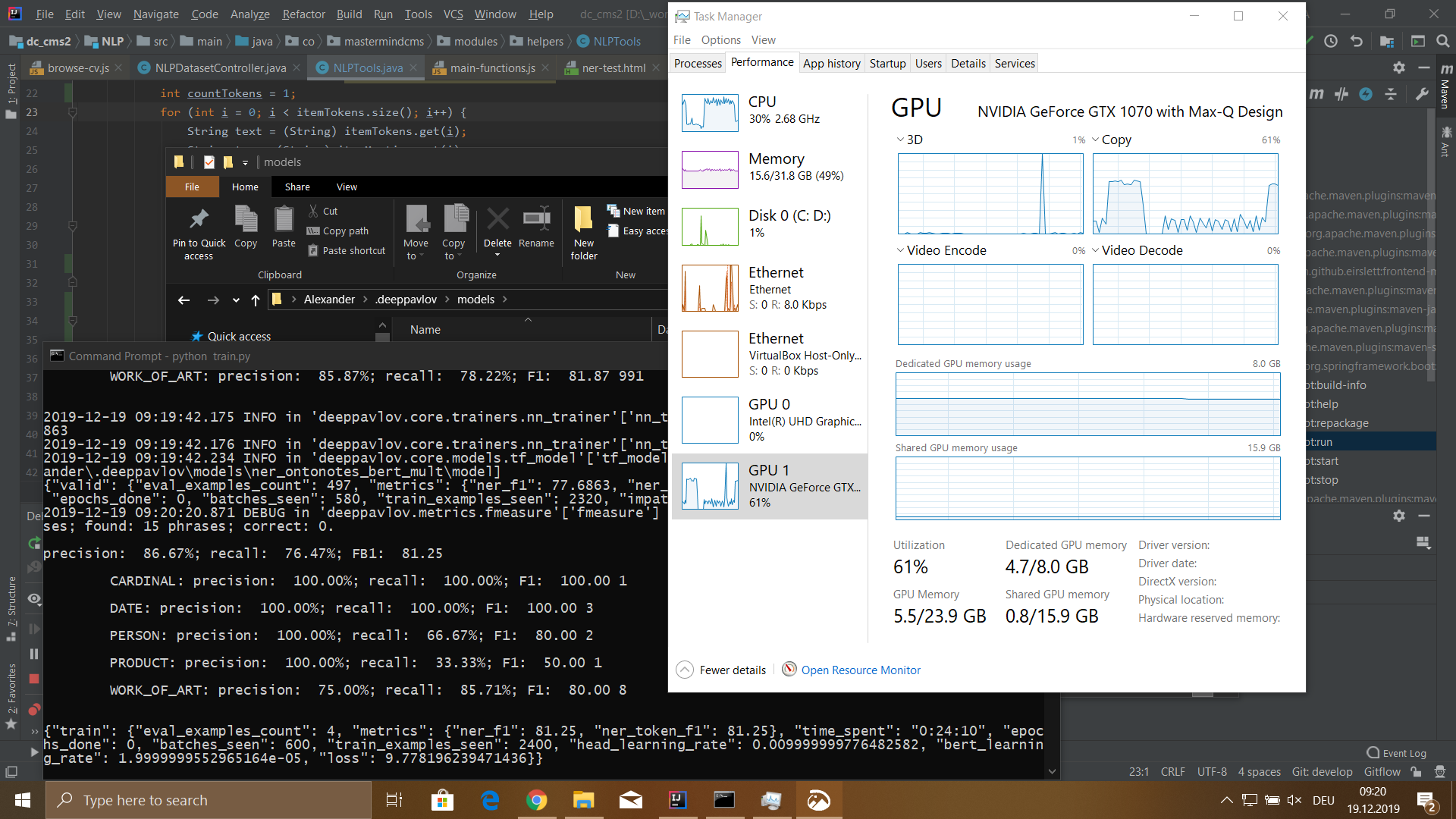
Hasil
Saya melatih model pada dataset 115.540 token. Dataset ini dihasilkan dari 100 file resume karyawan. Proses belajar saya membutuhkan waktu 5 jam 18 menit.
Model memiliki arti sebagai berikut:
- presisi: 76,32%;
- ingat: 72,32%;
- FB1: 74.27;
- kerugian: 5.4907482981681826;
Setelah mengedit beberapa masalah dalam pembuatan data secara otomatis, saya menerima
kerugian di bawah ini. Tetapi secara umum, saya senang dengan hasilnya. Tentu saja, saya masih memiliki banyak pertanyaan tentang penggunaan perpustakaan ini, dan apa yang saya jelaskan di sini hanyalah setetes saja.
Saya sangat menyukai perpustakaan karena kesederhanaan dan kemudahan penggunaannya. Setidaknya untuk tugas
NER . Saya akan sangat senang mendiskusikan fitur-fitur lain dari perpustakaan ini dan saya harap seseorang akan menemukan bahan dari artikel ini bermanfaat.