Pendahuluan
Memahami bagaimana classifier memecah ruang multidimensi awal atribut menjadi banyak kelas target adalah langkah penting untuk menganalisis masalah klasifikasi dan mengevaluasi solusi yang diperoleh dengan menggunakan pembelajaran mesin.
Pendekatan modern untuk memvisualisasikan keputusan pengklasifikasi terutama menggunakan sebar plot yang hanya dapat menampilkan proyeksi sampel pelatihan asli, tetapi tidak secara eksplisit menunjukkan batas-batas pengambilan keputusan yang sebenarnya, atau menggunakan struktur internal pengklasifikasi (misalnya, kNN, SVM, Regresi Logistik) yang mudah untuk membangun geometri interpretasi. Metode ini tidak cocok untuk visualisasi, misalnya, dari pengklasifikasi jaringan saraf.
Artikel "Visualisasi Berbasis Batas Batas Keputusan" (Rodrigues et al., 2018) mengusulkan metode alternatif yang efektif, indah dan cukup sederhana untuk memvisualisasikan solusi pengklasifikasi, yang tanpa kekurangan di atas. Yaitu, metode ini cocok untuk pengklasifikasi dalam bentuk apa pun dan membangun batas pengambilan keputusan menggunakan gambar dengan laju pengambilan sampel yang sewenang-wenang.
Posting ini adalah ikhtisar singkat tentang ide-ide utama dan hasil dari artikel asli.
Deskripsi Metode
Dasar dari metode ini adalah pengambilan sampel terbalik (eng. Upsampling) dari bidang gambar  yang diwakili oleh satu set piksel ke dalam ruang fitur
yang diwakili oleh satu set piksel ke dalam ruang fitur  .
.
Metode ini membutuhkan dua pemetaan  - Proyeksi langsung dari ruang fitur ke bidang gambar dan kebalikannya
- Proyeksi langsung dari ruang fitur ke bidang gambar dan kebalikannya  . Seperti pemetaan tersebut, LAMP (Joia et al. 2011) dan iLAMP (Amorim et al. 2012) , masing-masing, digunakan.
. Seperti pemetaan tersebut, LAMP (Joia et al. 2011) dan iLAMP (Amorim et al. 2012) , masing-masing, digunakan.
Membangun
Untuk membangun gambar, Anda perlu menetapkan warna untuk setiap piksel. Untuk ini, untuk setiap piksel  akan menemukan
akan menemukan  poin dari sumber hyperspace mana
poin dari sumber hyperspace mana  - parameter yang ditentukan oleh pengguna. Biarkan pikselnya sudah
- parameter yang ditentukan oleh pengguna. Biarkan pikselnya sudah  prototipe nyata dari set pelatihan. Maka pilihlah secara merata
prototipe nyata dari set pelatihan. Maka pilihlah secara merata  titik yang tersisa dari permukaan piksel dan temukan prototipe untuk mereka melalui proyeksi belakang
titik yang tersisa dari permukaan piksel dan temukan prototipe untuk mereka melalui proyeksi belakang  . Jadi, warna masing-masing piksel akan ditentukan setidaknya titik ruang sumber, dan seluruh gambar akan dilukis.
. Jadi, warna masing-masing piksel akan ditentukan setidaknya titik ruang sumber, dan seluruh gambar akan dilukis.
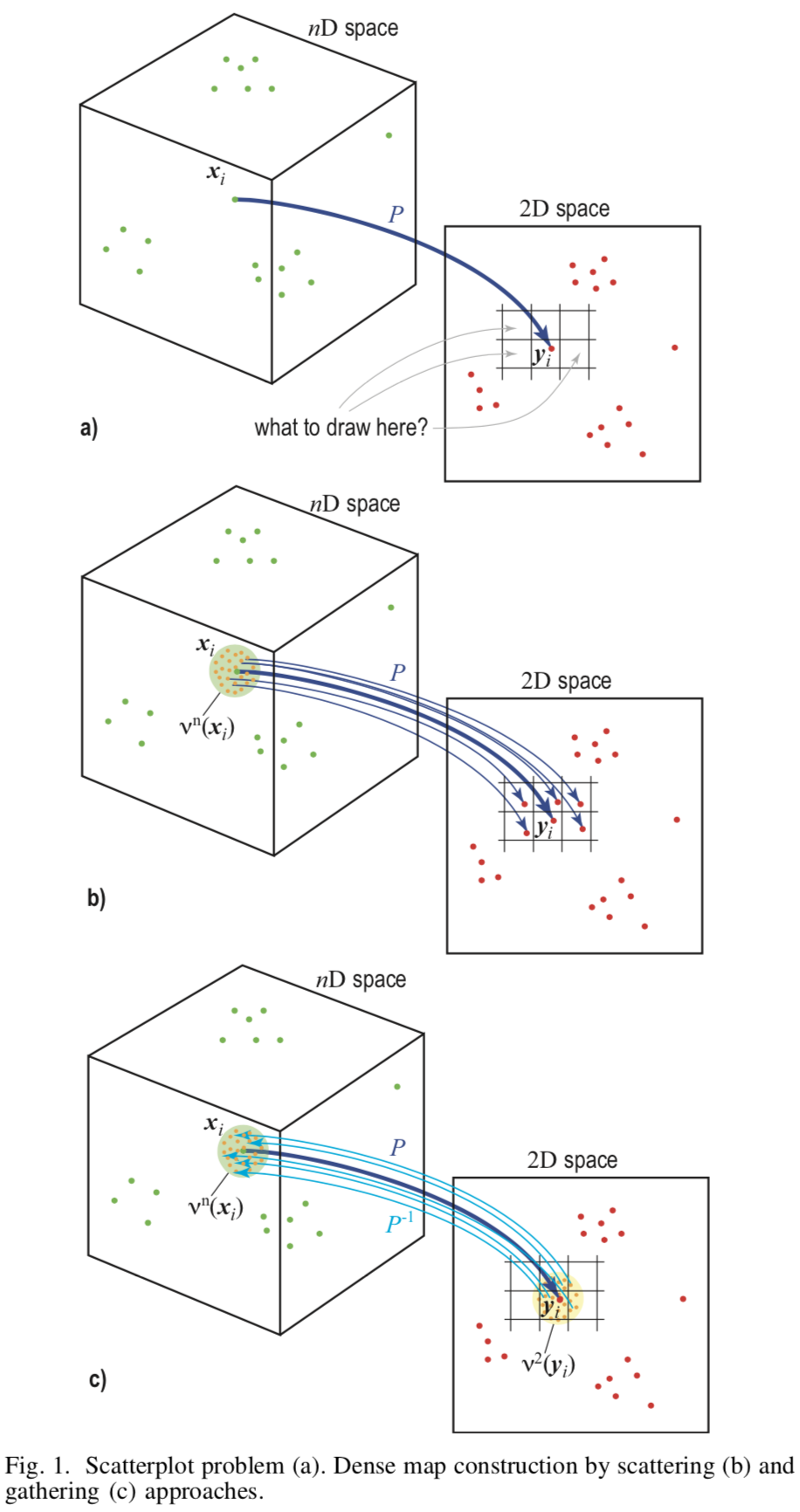
[Gbr.1] Ilustrasi skematis dari berbagai pendekatan
Definisi warna
Warna  setiap piksel ditentukan oleh suara mayoritas untuk label kelas dari preimage yang sesuai.
setiap piksel ditentukan oleh suara mayoritas untuk label kelas dari preimage yang sesuai.
![d (y) = \ text {argmax} _ {k \ dalam C} \ sum_ {y_i \ in y} [f (P ^ {- 1} (y_i)) = k]](https://habrastorage.org/getpro/habr/post_images/469/c8d/c50/469c8dc5021ee22be2190d80d4a8f9bd.svg)
dimana  - Banyak dari semua kelas,
- Banyak dari semua kelas,  - penggolong.
- penggolong.
Setiap kelas akan diberi nada (eng. Hue)  - jika proyeksi memiliki poin dari sampel nyata, dan nada sedikit berubah
- jika proyeksi memiliki poin dari sampel nyata, dan nada sedikit berubah  untuk piksel yang hanya memiliki titik-titik sintetis.
untuk piksel yang hanya memiliki titik-titik sintetis.
Kebingungan
Tentukan pencampuran piksel (dari kebingungan bahasa Inggris)  - sebagai perbandingan jumlah label dari kelas yang ada dengan jumlah total gambar terbalik piksel :
- sebagai perbandingan jumlah label dari kelas yang ada dengan jumlah total gambar terbalik piksel :
![c (y) = \ frac {\ max_ {k \ dalam C} \ sum_ {y_i \ in y} [f (P ^ {- 1} (y_i)) = k]} {| y |}](https://habrastorage.org/getpro/habr/post_images/62d/5e7/47f/62d5e747f958e587200665af682cbae9.svg)
Nilai tinggi menunjukkan konsistensi classifier, sementara nilai yang rendah menandakan pendekatan untuk batas pemisah. Blend informasi yang dikodekan dalam saturasi piksel  - semakin tinggi konsistensi, semakin tinggi saturasi.
- semakin tinggi konsistensi, semakin tinggi saturasi.
Kepadatan
Meskipun minimum telah dihasilkan poin preimage untuk setiap piksel, mungkin ada piksel yang ada lebih banyak poin nyata dari set pelatihan. Pixel semacam itu harus dipertimbangkan saat rendering. Untuk melakukan ini, masukkan kerapatan piksel  sebagai jumlah titik gambar terbalik dari . Orang dapat menggunakan kerapatan ini secara langsung untuk menentukan kecerahan piksel sebagai
sebagai jumlah titik gambar terbalik dari . Orang dapat menggunakan kerapatan ini secara langsung untuk menentukan kecerahan piksel sebagai  , tetapi penulis artikel menunjukkan bahwa ini tidak memberikan hasil yang diinginkan, karena beberapa nada jelas lebih gelap dari yang lain. Oleh karena itu, pengaturan yang lebih canggih digunakan pada saat yang sama saturasi dan kecerahan melalui parameter kepadatan yang dinormalisasi.
, tetapi penulis artikel menunjukkan bahwa ini tidak memberikan hasil yang diinginkan, karena beberapa nada jelas lebih gelap dari yang lain. Oleh karena itu, pengaturan yang lebih canggih digunakan pada saat yang sama saturasi dan kecerahan melalui parameter kepadatan yang dinormalisasi.

Lalu jika ![\ hat {\ rho} \ dalam [0, 0,5]](https://habrastorage.org/getpro/habr/post_images/5f3/8f9/0c5/5f38f90c57fe8c26092278e6a36b55c7.svg) - Kecerahan secara linear tergantung pada parameter di dalamnya
- Kecerahan secara linear tergantung pada parameter di dalamnya ![[V_ {min} = 0,1, V_ {max} = 1]](https://habrastorage.org/getpro/habr/post_images/b1e/ef5/e22/b1eef5e220c553d3c437ee6ddb9f4f08.svg) . Di
. Di ![\ hat {\ rho} \ dalam [0,5, 1]](https://habrastorage.org/getpro/habr/post_images/4cc/04d/a79/4cc04da7997da643ef6671babba1ec57.svg) mulai tumbuh saturasi linear dari
mulai tumbuh saturasi linear dari  sebelumnya
sebelumnya  .
.
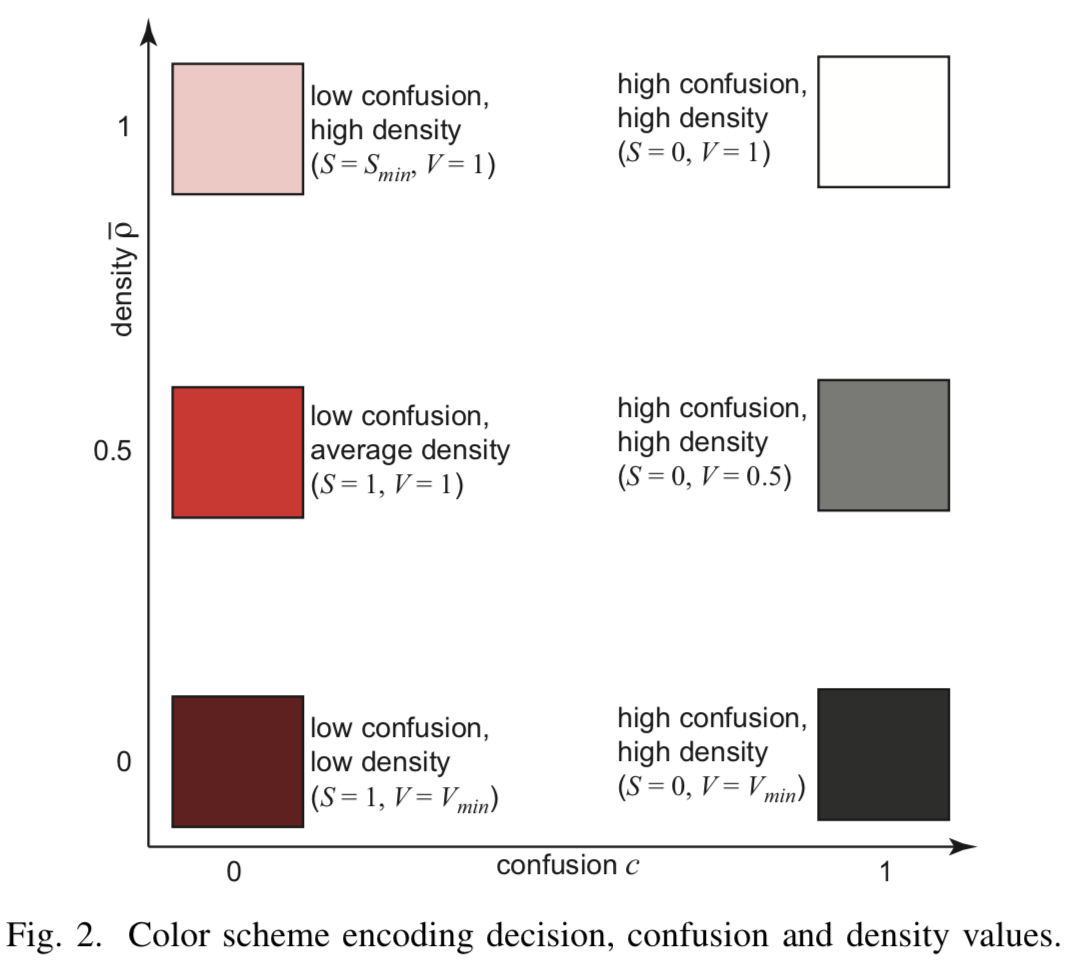
[Gbr.2] Pengodean warna
Eksperimen dan Hasil
Untuk percobaan, masalah klasifikasi biner pada set gambar digital MNIST dan klasifikasi multi-kelas pada Dataset Segmentasi Gambar , yang berisi 2.310 gambar dibagi menjadi 7 kelas, diselesaikan. Ada 19 atribut untuk setiap gambar.
Hasil pencitraan dengan berbagai pengaturan resolusi  dan jumlah minimum prototipe untuk binary classifier LogisticRegression pada MNIST ditunjukkan pada gambar [3]. Kelas dipisahkan oleh garis lurus dengan akurasi tinggi dan algoritma visualisasi melakukan pekerjaan yang sangat baik. Dengan resolusi yang meningkat, awan titik sumber hampir sepenuhnya larut di antara banyak titik yang dihasilkan.
dan jumlah minimum prototipe untuk binary classifier LogisticRegression pada MNIST ditunjukkan pada gambar [3]. Kelas dipisahkan oleh garis lurus dengan akurasi tinggi dan algoritma visualisasi melakukan pekerjaan yang sangat baik. Dengan resolusi yang meningkat, awan titik sumber hampir sepenuhnya larut di antara banyak titik yang dihasilkan.
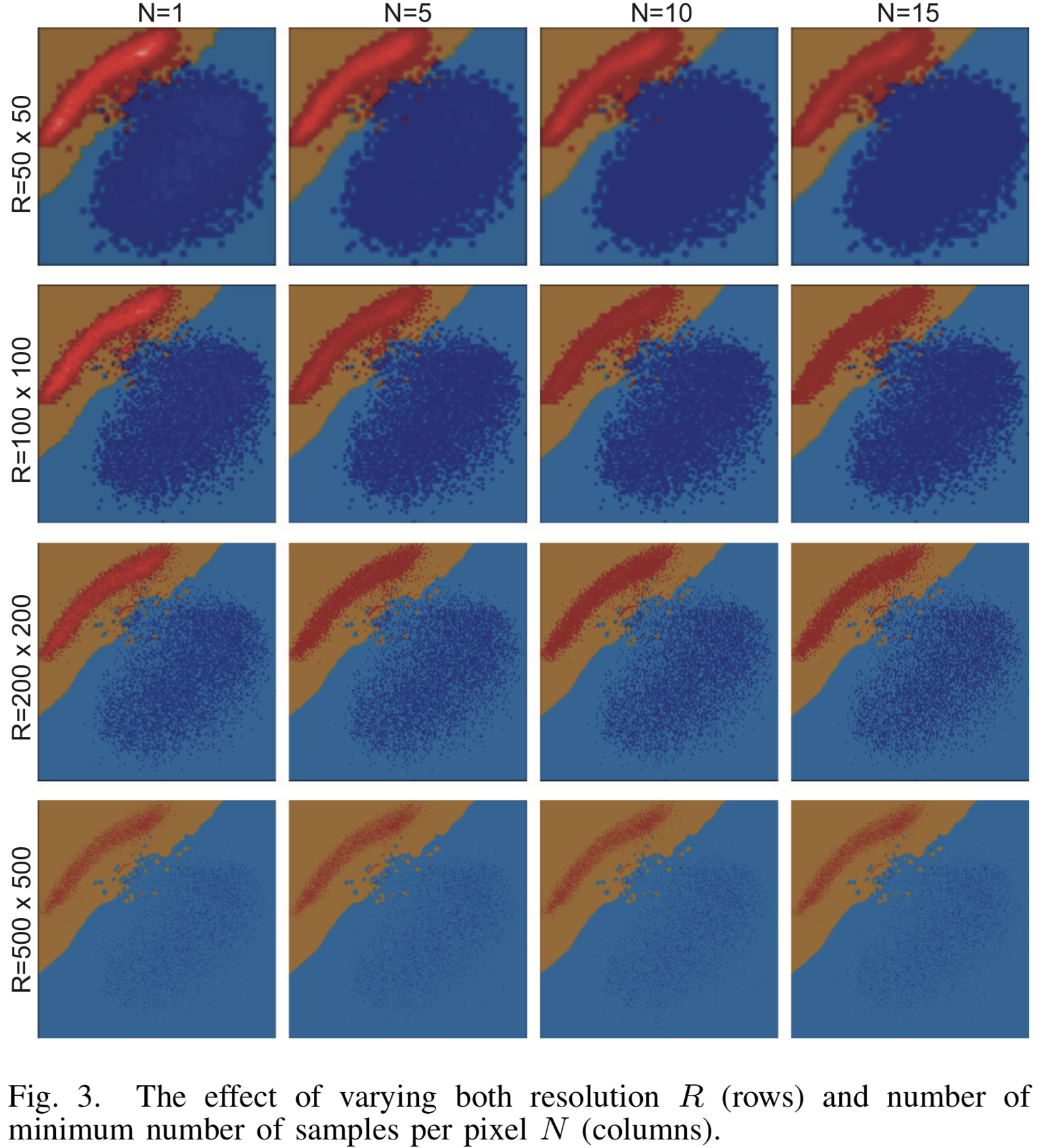
[Gambar. 3] Hasil visualisasi untuk berbagai parameter resolusi dan jumlah sampel minimum N untuk classifier LogisticRegression
Visualisasi kapan  untuk tiga pengklasifikasi yang berbeda untuk multi-klasifikasi pada gambar [4]. Proyeksi titik awal sangat beragam, dan tidak mungkin untuk membangun batas pemisah eksplisit di tempat-tempat di mana proyeksi dari kasus uji diakumulasikan. Namun, selain dari cluster utama, batas kelas eksplisit diperoleh, informasi tentang yang tidak ditampilkan pada proyeksi biasa, tetapi diperoleh hanya dengan bantuan titik sintetik.
untuk tiga pengklasifikasi yang berbeda untuk multi-klasifikasi pada gambar [4]. Proyeksi titik awal sangat beragam, dan tidak mungkin untuk membangun batas pemisah eksplisit di tempat-tempat di mana proyeksi dari kasus uji diakumulasikan. Namun, selain dari cluster utama, batas kelas eksplisit diperoleh, informasi tentang yang tidak ditampilkan pada proyeksi biasa, tetapi diperoleh hanya dengan bantuan titik sintetik.
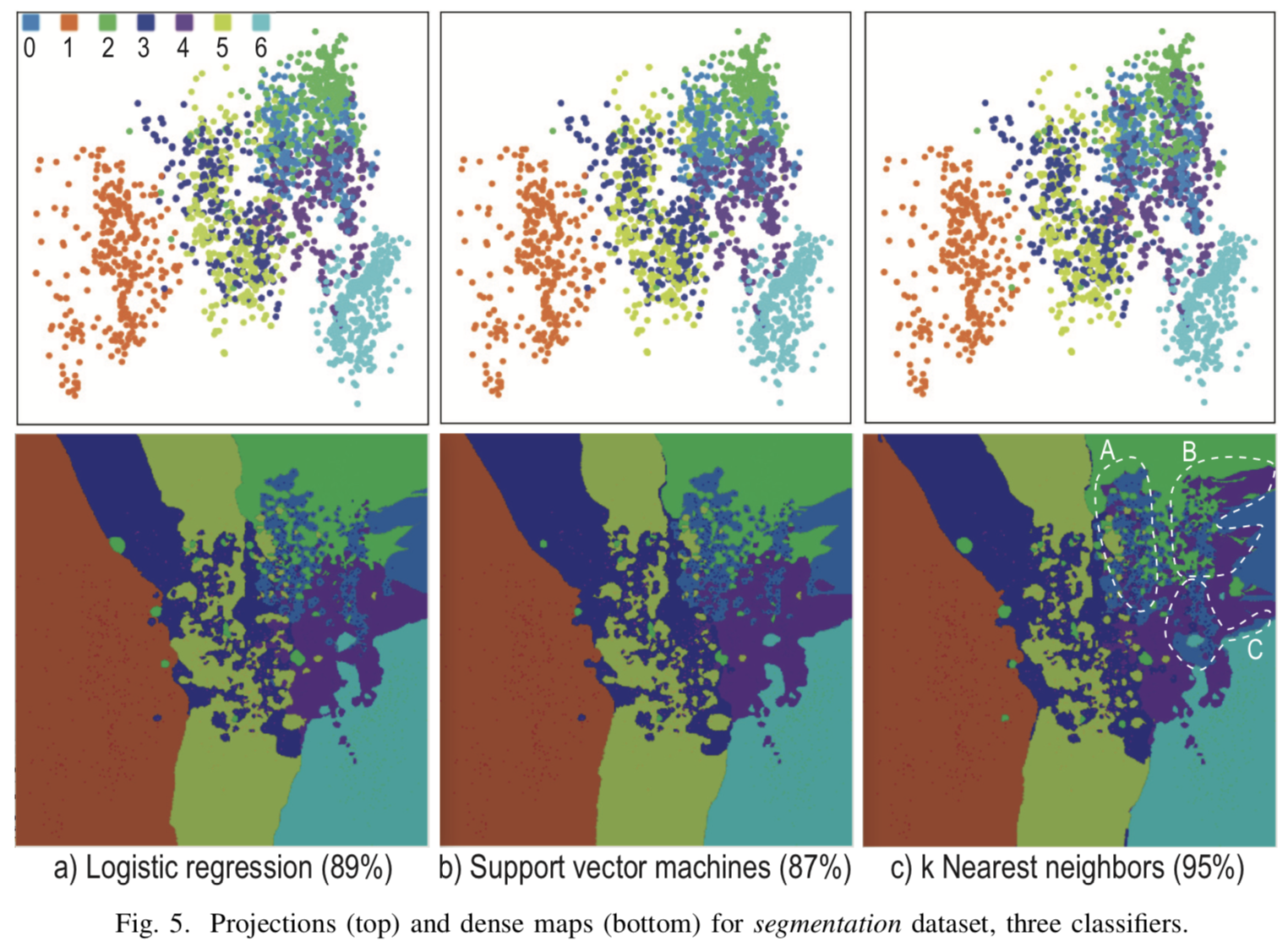
[Gambar. 4] Hasil dari visualisasi tiga pengklasifikasi yang berbeda untuk k = 7, R = 500x500, N = 5
Kesimpulan
Visualisasi batas kelas dapat digunakan dalam konstruksi dan debugging algoritma yang menentukan, dalam pemilihan hyperparameters, dalam perang melawan pelatihan ulang, untuk mempresentasikan dan menganalisis hasilnya.
Metode yang dideskripsikan oleh penulis artikel asli dapat digunakan untuk masalah klasifikasi di mana data direpresentasikan sebagai seperangkat tanda-tanda dimensi tetap. Tidak seperti algoritma visualisasi lainnya, pendekatan ini dapat digunakan untuk pengklasifikasi kompleks yang sewenang-wenang dan untuk kumpulan data dengan sejumlah contoh acak, bahkan dengan yang sangat kecil, karena bahkan dengan yang kecil Algoritma bekerja secara stabil, tanpa kehilangan banyak kualitas.