Halo semuanya!
Anda mungkin sudah tahu tentang inisiatif Machine Learning for Social Good (# ml4sg) komunitas Open Data Science. Dalam kerangka kerjanya, penggemar menggunakan metode pembelajaran mesin untuk memecahkan masalah yang signifikan secara sosial secara gratis. Kami, tim proyek Lacmus (#proj_rescuer_la), terlibat dalam implementasi solusi Deep Learning modern untuk menemukan orang-orang yang tersesat di luar wilayah padat penduduk: di hutan, lapangan, dll.

Menurut perkiraan kasar, di Rusia lebih dari seratus ribu orang menghilang setiap tahun. Bagian nyata dari mereka adalah orang-orang yang tersesat jauh dari tempat tinggal manusia. Untungnya, beberapa dari mereka yang tersesat dipilih sendiri, tim pencarian dan penyelamatan sukarela dimobilisasi untuk membantu orang lain. Detasemen yang paling terkenal adalah, mungkin, Lisa Alert, tetapi saya ingin mencatat bahwa dia bukan satu-satunya.
Metode pencarian utama saat ini, di abad ke-21, menyisir sekeliling dengan berjalan kaki menggunakan cara teknis, yang sering kali tidak lebih rumit daripada sirene atau mercusuar yang berdengung. Topiknya, tentu saja, relevan dan panas, memunculkan banyak ide untuk menggunakan kemajuan ilmiah dan teknologi dalam pencarian pencapaian; beberapa dari mereka bahkan diwujudkan dalam bentuk prototipe dan diuji di kompetisi yang diselenggarakan khusus. Tetapi hutan adalah hutan, dan kondisi sebenarnya dari pencarian, ditambah dengan sumber daya material yang terbatas, membuat masalah ini sulit dan masih sangat jauh dari solusi yang lengkap.
Baru-baru ini, penyelamat semakin menggunakan kendaraan udara tak berawak (UAV) untuk mensurvei wilayah yang luas di wilayah itu, memotret medan dari ketinggian 40-50m. Dengan satu operasi pencarian dan penyelamatan, beberapa ribu foto diperoleh, yang hingga saat ini, sukarelawan melihat secara manual. Jelas bahwa pemrosesan seperti itu lama dan tidak efisien. Setelah dua jam bekerja, para relawan menjadi lelah dan tidak dapat melanjutkan pencarian, dan bagaimanapun, kesehatan dan kehidupan orang tergantung pada kecepatannya.
Bersama dengan tim pencarian dan penyelamatan, kami mengembangkan sebuah program untuk mencari orang hilang dalam gambar yang diambil dengan UAV. Sebagai spesialis pembelajaran mesin, kami berupaya membuat pencarian otomatis dan cepat.

Perbedaan dari solusi serupa
Tidak adil mengatakan bahwa Lacmus adalah satu-satunya proyek yang dikembangkan ke arah ini. Namun, tampaknya hanya sedikit orang yang berkembang dalam kerjasama erat dengan tim penyelamat, dengan fokus pada kebutuhan dan kemampuan mereka yang mendesak. Beberapa waktu lalu, kompetisi Odyssey diadakan, di mana berbagai tim berlomba dalam pembentukan solusi terbaik untuk mencari dan menyelamatkan orang, termasuk menggunakan UAV. Menjadi pada tahap awal pengembangan, kami menghadiri kompetisi ini bukan sebagai peserta, tetapi sebagai pengamat. Membandingkan hasil kompetisi, informasi tentang proyek serupa dan pengalaman kami dalam berkomunikasi dengan tim seperti Lisa Alert, Owl, Extreme, saya ingin mencatat masalah yang melekat pada banyak analog:
- Biaya implementasi. Beberapa tim dari kontes Odyssey mengembangkan drone dan UAV inovatif mereka sendiri. Tetapi Anda perlu memahami bahwa PSO di Rusia biasanya beroperasi dengan basis nirlaba, dan memperlengkapi operator drone dengan mesin bernilai lebih dari 1.000.000 rubel terlalu mahal. Selain itu, tidak cukup hanya untuk memproduksi pesawat terbang, perlu pemeliharaannya. Sulit bagi perusahaan kecil untuk menawarkan solusi dengan uang yang sama dengan pesaing Cina yang tangguh.
- Fokus komersial dari banyak solusi. Tidak ada yang salah dengan proyek bisnis, tetapi menemukan orang yang hilang di hutan adalah tugas yang agak spesifik, tidak setiap pengembangan komersial dapat diintegrasikan ke dalamnya. Anda dapat membuat drone yang luar biasa dan menempelkan neuron yang mengenali tanaman di sana, tetapi proyek seperti itu tidak akan berguna untuk menemukan orang di hutan melalui tim pencarian sukarela: di sini Anda memerlukan solusi termurah, tetapi efektif. Kamera multi-saluran yang mahal tidak cocok di sini. Hanya RGB, hanya hardcore. Untuk alasan yang sama, pencitraan termal juga hilang, model murah yang memiliki resolusi sangat rendah. (Dan secara umum, pencitraan panas tidak efektif di sini, karena seseorang yang membeku di hutan mengeluarkan terlalu sedikit panas).
- Arsitektur jaringan saraf populer yang digunakan dalam solusi yang dikenal - YOLO, SSD, VGG - memiliki metrik kualitas yang baik pada kumpulan data publik seperti ImageNet, tetapi tidak berfungsi dengan baik pada gambar di area domain kami yang agak spesifik. (Tentang pilihan arsitektur jaringan saraf, opsi yang dicoba dan diuji dan fitur yang digunakan di akhir - bawah).
- Hampir tidak ada yang menggunakan peluang untuk mengoptimalkan model untuk inferensi. Di area pencarian, seringkali tidak ada koneksi internet, jadi Anda perlu memproses gambar yang diterima secara lokal. Sebagian besar penyelamat menggunakan laptop dengan GPU berdaya rendah, atau tanpa mereka sama sekali, menjalankan jaringan saraf pada CPU konvensional. Mudah untuk menghitung bahwa jika rata-rata 10 detik dihabiskan untuk memproses satu gambar, 1000 gambar akan diproses dalam waktu sekitar 3 jam. Di sini, kita dapat mengatakan bahwa setiap detik itu penting.
- Tertutupnya perkembangan yang ada. Semua solusi yang kami tahu tertutup dan eksklusif. Tetapi masalahnya terlalu rumit untuk diselesaikan oleh kekuatan segelintir orang, dan tidak semua yang siap membantu. Oleh karena itu, kami sedang mengembangkan solusi Open Source sepenuhnya: aneh untuk berpikir bahwa topik yang menarik begitu banyak sukarelawan yang bekerja "di ladang" tidak akan sama menariknya dengan spesialis TI.
- Kurangnya kebebasan distribusi. PSO sukarela seringkali tidak terpusat, pendekatan kerja dan aplikasi ditransfer dari tangan ke tangan, perangkat lunak dengan salinan berlisensi tidak akan berfungsi di sini. Itulah sebabnya kami, antara lain, telah memilih sumber terbuka dan strategi distribusi terbuka sehingga siapa pun dapat mengunduh solusi kami dan menggunakannya. Kami untuk sains terbuka dan sumber terbuka!
Persiapan data
Tampaknya jika setiap operasi pencarian menggunakan UAV membawa ribuan foto, susunan data yang terakumulasi harus sangat besar dan latih. Tidak semuanya ternyata sangat sederhana, karena:
- Tidak ada penyimpanan terpusat untuk data yang ditandai. Gambar yang diambil selama operasi pencarian tidak digunakan atau diproses di masa depan.
- Data yang diperoleh sangat tidak seimbang. Dalam satu pemotretan dengan orang yang ditemukan, ada beberapa ribu foto "kosong". Karena informasi tentang gambar yang dipindai tidak direkam di mana pun, untuk menemukan yang diperlukan di antara mereka, sejumlah besar pekerjaan perlu dilakukan untuk kedua kalinya - oleh upaya tim kecil yang tidak memiliki "mata terlatih".
- Setiap gambar, dalam dirinya sendiri, juga "tidak seimbang": orang yang diinginkan menempati sebagian kecil dari seluruh area gambar di atasnya. Jelas, jaringan saraf yang baik seharusnya tidak hanya dapat mengatakan bahwa, menurut pendapatnya, seseorang hadir dalam gambar - itu harus melingkari tempat tertentu (mis., Melakukan tugas mendeteksi objek, bukan mengklasifikasikan gambar). Jika tidak, operator akan menghabiskan waktu dan energi ekstra untuk melihatnya, dan mungkin juga keliru menolak foto yang diinginkan. Tetapi untuk ini, jaringan saraf harus belajar dari data mark-up, dalam foto, di mana objek yang diinginkan ditandai menggunakan perangkat lunak khusus. Tidak ada yang akan melakukan ini selama operasi pencarian - tidak sebelumnya.
- Statistik pada pose di mana orang-orang ditemukan, waktu tahun, jenis medan dan fitur lain dari gambar tidak diperhitungkan. Data tersebut akan sangat berguna untuk membuat gambar pelatihan "sintetis" menggunakan fotografi bertahap, editor foto atau model generatif - tetapi untuk menggunakan semua ini, Anda perlu memahami bagaimana sebuah foto terlihat dengan orang yang benar-benar hilang. Sekarang, ketika merekonstruksi foto-foto seperti itu, seseorang harus mengandalkan pengalaman subyektif para ahli penyelamat.
- Selain kesulitan teknis, hambatan hukum dimungkinkan yang memaksakan pembatasan kepemilikan gambar yang diperoleh. Seringkali, permintaan kami untuk bantuan dalam mengumpulkan data tetap tidak terjawab sama sekali. Karena kurangnya data seperti itu, masalah hukum atau kemalasan biasa - tidak jelas.
Dengan demikian, informasi berharga tidak digunakan dengan cara apa pun untuk melatih jaringan saraf, hilang atau mati di suatu tempat pada disk dan penyimpanan cloud, alih-alih meningkatkan volume dan kualitas sampel pelatihan. Kami sedang menulis layanan yang memungkinkan, antara lain, mengunggah foto-foto berharga kepada kami (tentang hal itu juga di bawah), tetapi, seperti biasa, lebih banyak tugas daripada orang.
Terlebih lagi, hingga saat ini, jaringan memiliki sangat sedikit dataset (terbuka) yang bagus dengan gambar dari UAV. Yang paling cocok yang kami temukan adalah
Stanford Drone Dataset (SDD) . Ini adalah foto dari ketinggian di atas kampus universitas, dengan benda bertanda kelas "Pedestrian" (pejalan kaki), bersama dengan pengendara sepeda, bus, dan mobil. Terlepas dari sudut pemotretan yang serupa, pejalan kaki yang difoto dan lingkungan memiliki sedikit kesamaan dengan apa yang terjadi dalam gambar kami. Eksperimen yang dilakukan pada dataset ini menunjukkan bahwa metrik kualitas detektor yang dilatih tentang itu pada data kami menunjukkan hasil yang rendah. Akibatnya, kami sekarang menggunakan SDD untuk melatih apa yang disebut tulang punggung, yang mengekstraksi atribut tingkat atas, dan lapisan ekstrem harus diselesaikan pada gambar area domain kami.
Itulah mengapa kami pertama kali berkomunikasi dengan berbagai mesin pencari dan penyelamat untuk waktu yang lama, mencoba memahami bagaimana orang yang hilang di hutan terlihat seperti dalam gambar dari atas. Sebagai hasilnya, kami mengumpulkan statistik unik pada 24 pose, di mana orang hilang paling sering ditemukan. Kami memfilmkan dan menandai kumpulan data kami sendiri - Lacmus Drone Dataset (LaDD), yang dalam versi pertama menyertakan lebih dari 400 gambar. Penembakan itu dilakukan terutama dengan bantuan DJI Mavic Pro dan Phantom dari ketinggian 50 - 100 meter, resolusi gambar adalah 3000x4000, ukuran orang rata-rata adalah 50x100 px. Saat ini, kami sudah memiliki versi keempat dataset dengan 2 ribu gambar, baik nyata maupun “disimulasikan”. Kami terus bekerja untuk mengisi ulang set data dan versi kelima sudah dekat.
Saat kami mengisi ulang dataset kami, kami sampai pada kebutuhan untuk memisahkan gambar berdasarkan musim. Faktanya adalah bahwa model yang dilatih dalam foto musim dingin menunjukkan hasil yang lebih baik daripada model yang dilatih pada seluruh dataset, baik di musim panas atau musim semi secara terpisah. Mungkin tanda-tanda pada latar belakang bersalju lebih baik diekstraksi daripada di rumput yang bising.

Pada saat yang sama, ketika berlatih hanya dalam gambar musim dingin, jumlah positif palsu (false positive) meningkat. Rupanya, gambar-gambar dari musim yang berbeda adalah pemandangan yang sangat berbeda (domain) dan jaringan saraf tidak dapat menyamaratakannya. Ini masih harus dilihat, dan sejauh ini kita melihat dua cara:
- Buat banyak kisi "kecil" dan pelajari untuk domain berbeda secara terpisah (satu untuk musim dingin, yang lain untuk musim panas ... Selain musim, Anda juga dapat memecah berdasarkan wilayah: misalnya, satu model untuk strip tengah dan dataran, yang lain untuk selatan, dan seterusnya) .
- Tingkatkan data kami berulang kali dan coba latih model itu sekaligus di semua domain. Berdasarkan solusi dari masalah serupa di artikel dari Yandex, kami cenderung mencoba opsi khusus ini. Sulit untuk mengumpulkan sejumlah besar foto nyata dengan orang hilang karena alasan yang telah dijelaskan, jadi, mungkin, kami akan mencoba membuat kembali contoh pendidikan realistis berdasarkan gambar "kosong" (ada banyak dari mereka). Jadi kita mungkin akan segera memiliki GAN.
Proses belajar
Sifat gambar kami sangat berbeda dari gambar kumpulan data populer seperti ImageNet, COCO, dll. Karena jaringan saraf yang dikembangkan untuk perangkat semacam itu mungkin kurang cocok untuk tugas kita, maka perlu dilakukan studi tentang penerapan berbagai arsitektur. Untuk melakukan ini, kami mengambil model pra-dilatih di ImageNet, melatihnya kembali di Stanford Drone Dataset, setelah itu kami "membekukan" tulang punggung, dan bagian-bagian detektor yang tersisa dilatih langsung pada gambar kami. Metrik terbaik disajikan dalam tabel:
Selain angka-angka dalam tabel di atas, Anda harus memperhatikan fitur seperti gambar Lacmus Drone Dataset sebagai ketidakseimbangan kelas besar: rasio area latar belakang dengan luas persegi panjang (jangkar) dengan objek yang diinginkan adalah beberapa ribu. Saat melatih detektor, ini mencakup dua masalah:
- Sebagian besar wilayah dengan latar belakang tidak membawa informasi yang berguna.
- Daerah dengan benda-benda karena jumlahnya yang kecil juga tidak memberikan kontribusi yang signifikan terhadap pelatihan bobot.
Untuk mengatasi masalah ini, berbagai skema pelatihan, pengaturan jaringan, dan sampel pelatihan digunakan. Salah satu arsitektur jaringan saraf yang kami uji, RetinaNet, ditujukan tepat untuk mengurangi efek negatif dari ketidakseimbangan kelas besar. Pencipta RetinaNet mendesainnya untuk meningkatkan keakuratan detektor satu tahap (menutupi gambar dengan jaringan padat jangkar-persegi yang telah ditentukan dan kemudian menyaring yang terbaik untuk menutupi objek) dibandingkan dengan detektor dua tahap yang berkualitas lebih baik, tetapi lebih lambat (siswa belajar menemukan kandidat daerah terlebih dahulu) , kemudian tentukan posisi mereka). Dari sudut pandang penulis artikel tentang RetinaNet, detektor satu tahap kehilangan justru karena ketidakseimbangan yang disebabkan oleh sejumlah besar jangkar kosong. Terhadap latar belakang keunggulan ini, pilihan kami dibuat untuk mendukung RetinaNet dengan tulang punggung ResNet50.
Arsitektur jaringan
ini diperkenalkan pada tahun 2017. Fitur utama dari RetinaNet, yang memungkinkan Anda untuk menangani efek negatif dari ketidakseimbangan kelas dalam pelatihan, adalah fungsi kehilangan
Focal Loss asli:
Di mana
p adalah probabilitas probabilitas konten di wilayah objek yang diinginkan diestimasi oleh model (dengan kata lain, output dari jaringan saraf, jika direduksi menjadi interval [0, 1]).
Dalam domain domain lain, fungsi kerugian harus, sebagai suatu peraturan, tahan terhadap contoh atipikal (contoh keras), yang kemungkinan besar outlier; dampaknya pada latihan beban harus dikurangi. Dalam Focal Loss, sebaliknya, pengaruh latar belakang yang sering terjadi (inliers, contoh mudah) berkurang, dan objek yang jarang terlihat memiliki pengaruh terbesar ketika melatih bobot RetinaNet. Ini dilakukan karena bagian formula ini:
Koefisien
dalam eksponen menentukan "berat" contoh keras dalam fungsi total loss.
Selama proses pelatihan RetinaNet, fungsi kerugian dihitung untuk semua orientasi yang dipertimbangkan dari area kandidat (jangkar), dari semua level penskalaan gambar. Secara total, ada sekitar 100k area untuk satu gambar, yang sangat berbeda dari heuristic sampling (RPN) atau pencarian untuk instance langka (OHEM, SSD) dengan sejumlah kecil area (sekitar 256) untuk setiap minibatch. Nilai kehilangan fokus dihitung sebagai jumlah dari nilai fungsi untuk semua jangkar, dinormalisasi dengan jumlah jangkar yang berisi objek yang diinginkan. Normalisasi hanya dilakukan pada mereka, dan bukan pada jumlah total, karena sebagian besar jangkar adalah latar belakang yang mudah diidentifikasi, dengan sedikit kontribusi pada fungsi kerugian keseluruhan.
Secara struktural, RetinaNet terdiri dari tulang punggung dan dua definisi Subnet Klasifikasi dan Regresi Kotak tambahan.
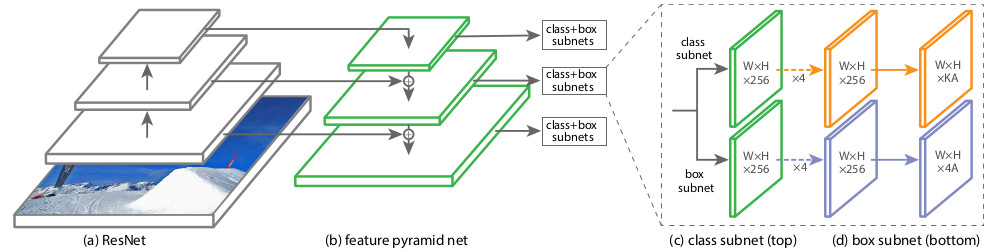
Sebagai tulang punggung, yang disebut
Feature Pyramid Network , FPN, yang bekerja di atas salah satu jaringan saraf convolutional yang umum digunakan (misalnya, ResNet50), digunakan. FPN memiliki output lateral tambahan dari lapisan tersembunyi dari jaringan konvolusi, membentuk tingkat piramida dengan skala yang berbeda. Setiap tingkat dilengkapi dengan "jalur top-down", yaitu informasi dari level yang lebih tinggi yang lebih kecil, tetapi berisi informasi tentang area area yang lebih besar. Itu terlihat seperti peningkatan buatan (misalnya, dengan hanya mengulangi elemen) dari peta fitur yang lebih "diminimalkan" ke ukuran peta saat ini, menambahkannya elemen demi elemen dan memindahkan keduanya ke level piramida yang lebih rendah dan ke input subnet lainnya (mis., Ke dalam Subnet Klasifikasi dan Kotak Regresi Subnet). Ini memungkinkan Anda untuk memilih dari gambar asli piramida tanda pada skala yang berbeda, di mana benda besar dan kecil dapat dideteksi. FPN digunakan di banyak arsitektur, meningkatkan deteksi objek dari berbagai ukuran: RPN, DeepMask, Fast R-CNN, Mask R-CNN, dll.
Anda dapat membaca lebih lanjut tentang FPN di
artikel aslinya.
Di jaringan kami, seperti pada aslinya, FPN dengan 5 level diberi nomor
oleh
. Level
memiliki izin untuk
kali lebih kecil dari gambar input (kami tidak akan masuk ke detail dari mana titik ResNet mereka berasal - ini akan mematahkan kaki). Semua tingkat piramida memiliki jumlah saluran yang sama C = 256 dan jumlah jangkar A sekitar 1000 (tergantung pada ukuran gambar).
Jangkar memiliki area dari [16 x 16] hingga [256 x 256] untuk setiap tingkat piramida
sebelumnya
sesuai, dengan langkah perpindahan (langkah) [8 - 128] px. Ukuran ini memungkinkan Anda untuk menganalisis benda-benda kecil dan beberapa lingkungan di sekitarnya. Misalnya, cabang, jika Anda tidak memperhitungkan realitas di sekitarnya, sangat mirip dengan orang yang berbohong.
FPN asli menggunakan tiga aspek rasio jangkar (1: 2, 1: 1, 2: 1); RetinaNet aspect ratio [
]. 9- , / 16 400 px.
Classification Subnet . (Fully ConvNet, FCN), FPN. , :
- (W x H x C)
- 33
- ReLU
- 33 ( ) ,
- -
x A, K — . — Pedestrian.
Box Regression Subnet 4- . , FPN, Classification Subnet. , , (4 ) — :
, , IoU (Intersection over Union) > 0.5.
1, 0. .
( ) forward . 1k , 0,05. , threshold = 0,5.
RetinaNet
towardsdatascience .
, . OpenSource-, Github fizyr:
keras-retinanet , .
, , 20-30 . , :
Dan juga ...
- Nvidia Jetson
- Corral Edge TPU
tensoflow 1.14 CPU AVX Intel nndl. AVX ( 2012 ) , Core 2 Duo!
Albumentations .
:
Produksi
docker
desktop- c , . Nvidia Cuda CuDNN TensorFlow — . , Python . - , . — Docker. web- . , docker-. GUI . GUI , , , , . Docker API, GUI, . , Docker , .
#
. 3 :
dotnext . «! - ! - ? », — ! GUI # AvaloniaUI, 64- Win10, Linux Mac.
AvaloniaUI — , . WPF, , . , 2D- , WPF. , WPF.
, SkiaSharp GTK ( Unix ). X11 . , , (!). .Net Core Bios', AvaloniaUI .
AvaloniaUI , , . , 2019 , . WPF C# — . ( electron), , .
 ...
..., , issue. , ,
,
.
.Untuk pemahaman lengkap tentang konsep ini, ada baiknya melihat presentasi oleh Nikita Tsukanov @kekekeks . Dia adalah pengembang kerangka kerja ini, berpengalaman dalam hal itu dan. NET secara umum.Backend
Selain aplikasi desktop, kami sedang mengembangkan infrastruktur mlOps untuk melakukan percobaan dan menemukan arsitektur jaringan saraf terbaik di cloud. Menggunakan sisi server, kami ingin:- mengumpulkan data dan menyimpannya secara terpusat;
- mengotomatiskan proses pembelajaran jaringan saraf, menciptakan lingkungan untuk penelitian dan menyediakan akses untuk itu bagi orang lain;
- menyediakan akses ke cloud untuk tim pencarian dan penyelamatan sehingga mereka juga dapat menggunakan data akumulasi jika perlu;
Arsitektur sistem secara keseluruhan terlihat seperti ini:
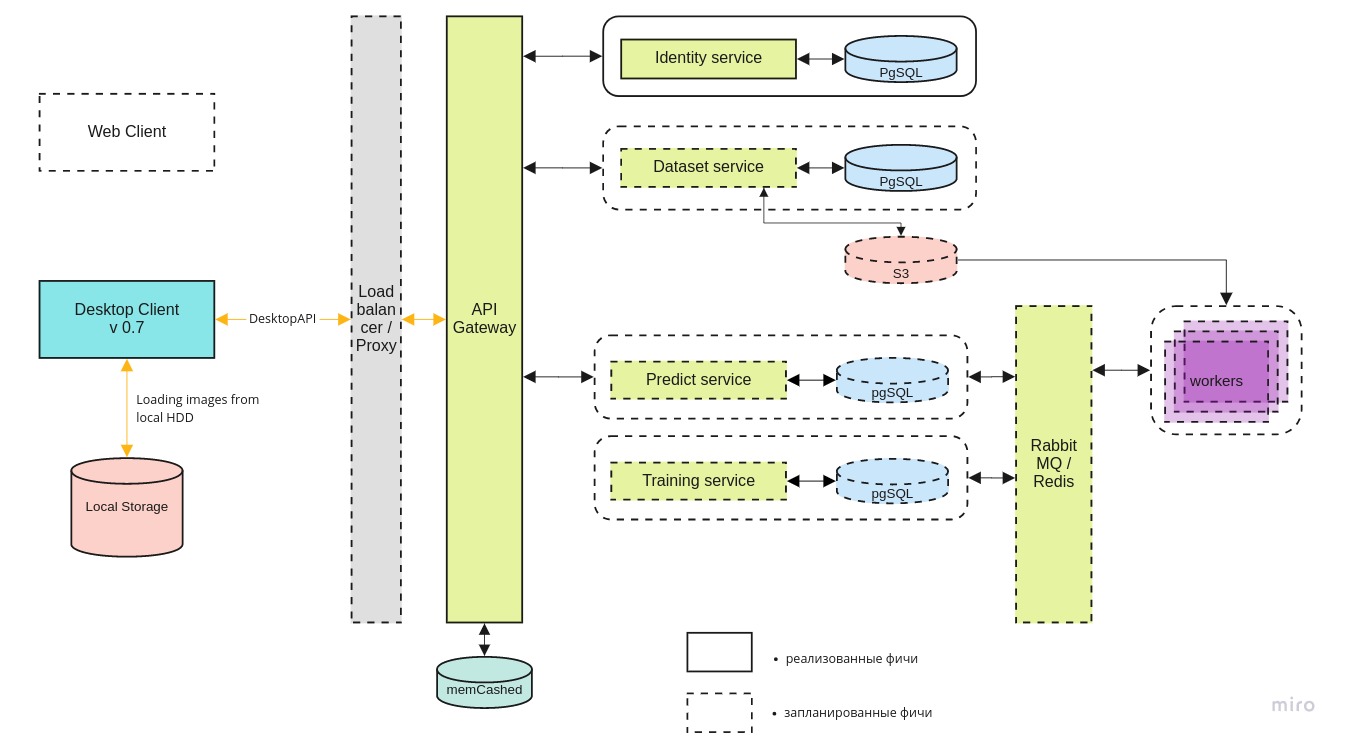 Desktop-klien
Desktop-klien dapat bekerja dengan versi lokal dari wadah buruh pelabuhan dan versi terbaru di server pusat, melalui REST API.
Layanan microsoft
identitas menyediakan akses ke server hanya untuk pengguna yang berwenang.
Layanan
dataset digunakan untuk menyimpan gambar itu sendiri dan markup mereka.
Layanan
prediksi memungkinkan Anda memproses dengan cepat sejumlah besar gambar di hadapan saluran lebar untuk pilot.
Layanan
pelatihan diperlukan untuk menguji model-model baru dan melatih yang sudah ada saat data baru tiba.
Antrian tugas dikelola menggunakan RabbitMQ / Redis.
Pencarian Kemampuan GPU
Terlepas dari kenyataan bahwa kesimpulan dari jaringan saraf dapat bekerja bahkan pada laptop sederhana, GPU diperlukan untuk melatih model. Secara teknis, Anda dapat melatihnya pada CPU, tetapi dalam praktiknya itu membutuhkan terlalu banyak waktu. Tidak semua orang yang datang ke tim memiliki komputer yang cocok untuk Deep Learning, jadi kami mencari kemampuan GPU terpusat.
Saat ini kami sedang bernegosiasi dengan
DTL dan kami berharap kerjasama akan berkembang. Keunikan server GPU DTL adalah penggunaan pendinginan perendaman: perendaman rak dalam cairan dielektrik khusus. Ini terlihat seperti ini:

 (Catatan fotografer: Biru bukan cahaya Cherenkov. Itu sorotan yang sangat bagus di dalamnya).
(Catatan fotografer: Biru bukan cahaya Cherenkov. Itu sorotan yang sangat bagus di dalamnya).Penyimpangan liris. "Apakah kamu tahu tentang jaringan saraf dari Beeline?"
Jujur, saya tidak benar-benar ingin menyentuh topik (licin) ini, tetapi terus menyentuh kita, jadi tidak mungkin untuk berpura-pura bahwa kita berada di dalam tangki. Ya, kami tahu tentang jaringan saraf dari Beeline. Menurut umpan balik dari pilot yang bekerja sama dengan kami, ini bekerja lebih buruk daripada versi kami dan hanya pada platform kelas atas. Menurut pengembang dari Beeline - proyek ini dibekukan dan tidak berkembang sekarang. Dari sudut pandang akal sehat, berita dalam semangat Beeline adalah yang pertama di Rusia untuk mengembangkan jaringan saraf seperti itu hampir tidak benar. Beberapa orang bahkan menerapkan arsitektur yang dirancang oleh laboratorium seperti Penelitian Facebook atau Google Brain, apalagi membuat sendiri. Paling sering, ini hanya tentang mengadaptasi perpustakaan OpenSource publik dengan kebutuhan area subjek Anda. Seberapa sering perpustakaan terbuka digunakan dalam perangkat lunak komersial Rusia, semua orang yang mengembangkan perangkat lunak ini tahu. Sebagian besar, bahkan tidak ada pelanggaran terhadap lisensi; tetapi membiarkan pencapaian OpenSource internasional secara keseluruhan perkembangannya dan melakukan PR keras di atasnya setidaknya jelek. Tampaknya pencapaian kami juga digunakan: khususnya, dalam
gamifikasi kami foto kami
dinyalakan. Bandingkan dengan foto "musim dingin" dari bagian tentang dataset Lacmus:

Ada alasan lain untuk meyakini bahwa masalahnya tidak terbatas pada data di sini.
Apa yang buruk bagi kita di tempat pertama adalah bahwa jaringan saraf Beeline sekarang terputus menjadi mustahil. Ketika disebutkan, tidak mungkin untuk memahami apakah itu benar-benar tentang dia, atau tentang aplikasi kita, atau secara umum tentang opsi orang lain. Dalam kondisi desentralisasi, pengendalian JI yang buruk dan sejumlah kecil saluran umpan balik, informasi apa pun tentang prevalensi dan kualitas pekerjaan Lacmus akan bermanfaat, juga tentang perkembangan serupa - tetapi hype seputar Beeline menaungi segalanya.
Kami berencana untuk terus memantau situasi untuk saat ini, tetapi permintaan kami kepada masyarakat adalah, pertama, untuk mengatakan "Beeline neural network" hanya ketika mereka 100% yakin bahwa ini dia, dan kedua, untuk membaca lisensi open source dan dengan jujur menunjukkan kepengarangan.
Ringkasan
Selama 2019 terakhir, anggota Yayasan Lacmus:
- Kami mengambil dan menandai dataset unik, versi terbaru yang mencakup lebih dari 2000 gambar;
- mencoba sejumlah arsitektur jaringan saraf yang berbeda dan memilih yang paling cocok;
- Kami memilih hyperparameter terbaik dari jaringan saraf dan melatihnya pada data unik kami sendiri untuk pengakuan yang paling akurat;
- mengembangkan aplikasi lintas platform untuk operator UAV dengan kemampuan untuk digunakan saat bekerja offline;
- mengoptimalkan kerja jaringan saraf kami untuk bekerja dengan anggaran dan komputer laptop berdaya rendah;
Saat ini, indikator terbaik dari metrik mAP jaringan saraf LAPMUS adalah 94%. Program kami siap untuk digunakan dalam operasi pencarian dan penyelamatan nyata dan telah diuji pada menjalankan umum. Di daerah terbuka dari jenis "bidang" dan "penahan angin" semua tes "hilang" ditemukan. Sekarang Lakmus digunakan oleh tim penyelamat dan membantu menemukan orang.
Dan kami juga menerima penghargaan Project of the Year dari Open Data Science:

Tahun ini kami merencanakan:
- temukan mitra untuk infrastruktur hosting yang andal;
- mengimplementasikan antarmuka web dan mlOps;
- membentuk dataset sintetis besar pada mesin UE4 atau dengan bantuan GAN;
- meluncurkan kompetisi InClass di Kaggle untuk semua orang yang ingin meningkatkan keterampilan DL / CV mereka dan mencari solusi SOTA terbaik;
- menambah retinanet kami bahkan lebih banyak implementasi tulang punggung dan variasi arsitektur ini;
Kami benar-benar kekurangan pekerja untuk mengimplementasikan rencana ini, jadi kami akan senang untuk semua orang terlepas dari tingkat dan arah pelatihan.
Jika bersama kita bisa menyelamatkan setidaknya satu orang lagi, maka semua upaya tidak akan sia-sia.
Bagaimana cara membantu proyek
Kami adalah proyek OpenSource, dan kami dengan senang hati akan menerima semua orang! Berikut ini tautan ke repositori github kami:
Jika Anda seorang pengembang dan ingin bergabung dengan proyek ini, Anda dapat menulis ke Perevozchikov Georgy Pavlovich,
gosha20777 di semua jejaring sosial,
gosha20777@live.ru atau bergabung dengan proyek melalui saluran
# ml4sg dalam slack ODS (jika Anda ada di sana).
Kami membutuhkan:
- Pengembang ML
- Pengembang C # / go / python;
- Pekerja garis depan;
- Beckers;
- Hanya orang yang aktif dari segala arah! Kami akan selalu senang melihat Anda!
Jika Anda tidak terlibat dalam pengembangan, Anda juga dapat membantu proyek:
- Anda dapat membantu kami menulis artikel;
- Anda dapat membantu kami menulis dokumentasi pengguna dan wiki (dan memperbaiki kesalahan tata bahasa di sana))))
- Anda dapat tetap berperan sebagai manajer produk dan menyelesaikan tugas di trello;
- Anda bisa memberi kami ide;
- Anda dapat mendistribusikan pos ini;
Tentang tim
Manajer proyek: Georgy Pavlovich Perevozchikov,
gosha20777 .
Daftar yang tidak lengkap dari mereka yang terlibat (sebenarnya, itu jauh lebih besar, jika Anda telah dilupakan secara tidak adil, beri tahu saya dan kami akan menambahkan):
- Peserta ODS yang paling aktif di saluran #proj_rescuer_la : Kseniia, balezz, ei-grad, Palladdiumm, sharov_am, dartov
- Peserta proyek di luar ODS: Martynova Viktoriya Viktorovna (organisasi proyek, pengumpulan dan pelabelan data), Denis Petrovich Shurankov (organisasi pengumpulan data), Daria Pavlovna Perevozchikova (ditandai sekitar 30% dari semua foto).
- Operator UAV dari pasukan Liza Alert, yang membantu dengan gambar dan pembentukan kumpulan data: Partyzan, Vanteyich, Sevych, California, Tarekon, Evgen, GB.
Terima kasih khusus:
- Untuk programmer dari AvaloniaUI - .NET framework terbaik: worldbeater , kekekeks , Larymar
- Admin ODS untuk mengatur komunitas paling keren: natekin, Sasha, mephistopheies.
Artikel ini ditulis bersama dengan
balezz dan
habrozhitelami gosha20777 .
Semua orang memiliki akal dan tidak pernah tersesat!
 Video demonstrasi pekerjaan untuk pencuci mulut. Versi pra-awal-alfa. Bagi mereka yang membaca sampai akhir. Februari 2019.
Video demonstrasi pekerjaan untuk pencuci mulut. Versi pra-awal-alfa. Bagi mereka yang membaca sampai akhir. Februari 2019.