HighLoad ++ Moscow 2018, Gedung Kongres. 9 November 15:00
Abstrak dan presentasi:
http://www.highload.ru/moscow/2018/abstracts/4066Yuri Nasretdinov (VKontakte): laporan tersebut akan berbicara tentang pengalaman menerapkan ClickHouse di perusahaan kami - mengapa kami membutuhkannya, berapa banyak data yang kami simpan, bagaimana kami menulisnya dan sebagainya.

Sumber Tambahan:
Menggunakan Clickhouse sebagai Pengganti untuk ELK, Pertanyaan Besar, dan TimescaleDB Yuri Nasretdinov: - Halo semuanya! Nama saya Yuri Nasretdinov, karena mereka sudah memperkenalkan saya. Saya bekerja di VKontakte. Saya akan berbicara tentang bagaimana kita memasukkan data ke "ClickHouse" dari armada server kami (puluhan ribu).
Apa itu log dan mengapa mengumpulkannya?
Apa yang akan kita bicarakan: apa yang kita lakukan, mengapa kita membutuhkan "ClickHouse", masing-masing - mengapa kita memilihnya, kinerja seperti apa yang bisa kamu dapatkan secara kasar tanpa mengkonfigurasi apapun secara spesifik. Saya akan memberi tahu Anda lebih banyak tentang tabel buffer, tentang masalah yang kami alami dengan mereka, dan tentang solusi kami yang kami kembangkan dari sumber terbuka - KittenHouse dan Lighthouse.
Mengapa kita perlu melakukan apa saja (pada VKontakte semuanya selalu baik-baik saja, kan?). Kami ingin mengumpulkan log debug (dan ada ratusan terabyte data di sana), mungkin, entah bagaimana, lebih nyaman untuk membaca statistik; dan kami memiliki puluhan ribu server tempat semua ini perlu dilakukan.
Mengapa kami memutuskan? Kami mungkin punya solusi untuk menyimpan log. Di sini - ada "Backend VK" publik. Saya sangat menyarankan untuk berlangganan.

Apa itu log? Ini adalah mesin yang mengembalikan array kosong. Mesin di "VK" adalah apa yang orang lain sebut layanan microser. Dan stiker seperti itu sedang tersenyum (cukup banyak suka). Bagaimana bisa begitu? Baiklah, dengarkan!

Apa yang bisa digunakan untuk menyimpan log secara umum? Mustahil untuk tidak menyebutkan Khadup. Kemudian, misalnya, Rsyslog (penyimpanan dalam file-file log ini). LSD Siapa yang tahu apa itu LSD? Tidak, bukan LSD ini. File disimpan, masing-masing juga. Yah, ClickHouse adalah versi yang aneh.
Clickhouse dan pesaing: persyaratan dan peluang
Apa yang kita inginkan? Kami ingin agar kami tidak perlu mandi uap khusus dengan operasinya, sehingga ia bekerja di luar kotak lebih disukai, dengan pengaturan minimal. Kami ingin banyak menulis, dan menulis cepat. Dan kami ingin menyimpannya berbulan-bulan, bertahun-tahun, untuk waktu yang lama. Kami mungkin ingin menyelesaikan beberapa masalah yang mereka hadapi, kata mereka - “Sesuatu tidak bekerja di sini untuk kami”, - ini 3 bulan lalu), dan kami ingin dapat melihatnya 3 bulan lalu ". Kompresi data - dapat dimengerti mengapa ini akan menjadi nilai tambah - karena jumlah ruang yang ditempati berkurang.

Dan kami memiliki persyaratan yang menarik: kadang-kadang kami menulis output dari beberapa perintah (misalnya, log), bisa lebih dari 4 kilobyte dengan cukup tenang. Dan jika hal ini berfungsi pada UDP, maka tidak perlu mengeluarkan ... itu tidak akan memiliki "overhead" untuk koneksi, dan untuk sejumlah besar server ini akan menjadi nilai tambah.

Mari kita lihat apa yang ditawarkan open source kepada kami. Pertama, kami memiliki Mesin Log - ini adalah mesin kami; dia pada dasarnya tahu segalanya, bahkan antrean panjang bisa menulis. Ya, itu tidak memampatkan data secara transparan - kita dapat mengkompresi kolom besar sendiri jika kita ingin ... kita, tentu saja, tidak mau (jika mungkin). Satu-satunya masalah adalah dia hanya bisa memberikan apa yang ditempatkan dalam ingatannya; sisanya, untuk membaca, Anda perlu mendapatkan binlog dari mesin ini dan, oleh karena itu, butuh waktu cukup lama.

Apa pilihan lainnya? Misalnya, Khadup. Kemudahan penggunaan ... Siapa yang percaya Hadoup mudah untuk dikonfigurasi? Dengan rekaman itu, tentu saja, tidak ada masalah. Dengan membaca, terkadang muncul pertanyaan. Pada prinsipnya, saya akan mengatakan bahwa kemungkinan besar tidak, terutama untuk log. Penyimpanan jangka panjang - tentu saja, ya, kompresi data - ya, antrean panjang - jelas Anda dapat menulis. Tetapi untuk merekam dari sejumlah besar server ... Bagaimanapun, kita harus melakukan sesuatu sendiri!
Rsyslog. Faktanya, kami menggunakannya sebagai fallback, sehingga akan mungkin untuk membaca binlog tanpa dump, tetapi itu tidak dapat menulis ke garis panjang, pada prinsipnya, ia tidak dapat menulis lebih dari 4 kilobyte. Kompresi data harus dilakukan dengan cara yang sama. Membaca akan pergi dari file.

Lalu ada perkembangan "buruk" LSD. Hal yang sama pada dasarnya sama dengan "Rsyslog": mendukung garis panjang, tetapi tidak tahu cara menggunakan UDP dan, pada kenyataannya, karena ini, sayangnya, ada banyak hal untuk ditulis ulang. LSD perlu diulang agar Anda dapat merekam dari puluhan ribu server.

Oh, ini! Pilihan yang lucu adalah ElasticSearch. Bagaimana mengatakannya? Semuanya baik-baik saja dengan membaca, yaitu, ia membaca dengan cepat, tetapi tidak begitu baik dengan menulis. Pertama, jika kompres data, itu sangat lemah. Kemungkinan besar, pencarian lengkap membutuhkan lebih banyak struktur data daripada volume aslinya. Sulit dieksploitasi, seringkali timbul masalah. Dan, sekali lagi, sebuah entri dalam "Elastis" - kita semua harus melakukannya sendiri.

Di sini ClickHouse - opsi ideal, tentu saja. Satu-satunya hal adalah, rekaman dari puluhan ribu server adalah masalah. Tapi dia setidaknya satu, kita bisa mencoba menyelesaikannya entah bagaimana. Dan sisa laporan adalah tentang masalah ini. Kinerja keseluruhan apa dari ClickHouse yang dapat Anda harapkan?
Bagaimana kita menanamkan? MergeTree
Berapa banyak dari Anda belum pernah mendengar tentang ClickHouse, tidak tahu? Perlu diceritakan, tidak perlu? Sangat cepat. Sisipan ada 1-2 gigabit per detik, semburan hingga 10 gigabit per detik sebenarnya dapat menahan konfigurasi ini - ada dua Xeon 6-inti (yaitu, bahkan bukan yang paling kuat), 256 gigabytes RAM, 20 terabyte per RAID (tidak ada yang dikonfigurasi, pengaturan standar). Alexey Milovidov, pengembang ClickHouse, mungkin menangis, bahwa kami tidak mengonfigurasi apa pun (semuanya bekerja untuk kami seperti itu). Karenanya, kecepatan pindai, misalnya, sekitar 6 miliar baris per detik dapat diperoleh jika data dikompresi dengan baik. Jika Anda suka% pada baris teks - 100 juta baris per detik, itu sepertinya sangat cepat.

Bagaimana kita menanamkan? Nah, Anda tahu itu di "VK" - dalam PHP. Kami dari setiap pekerja PHP akan menempel HTTP ke "ClickHouse", ke dalam plat MergeTree untuk setiap entri. Siapa yang melihat masalah di sirkuit ini? Untuk beberapa alasan, tidak semua orang mengangkat tangan. Mari kita beri tahu.
Pertama, ada banyak server - karenanya, akan ada banyak koneksi (buruk). Kemudian di MergeTree lebih baik memasukkan data tidak lebih dari sekali per detik. Dan siapa yang tahu mengapa? Oke, bagus. Saya akan bercerita sedikit tentang ini. Pertanyaan menarik lainnya adalah kita, seolah-olah, tidak melakukan analitik, kita tidak perlu memperkaya data, kita tidak perlu server perantara, kita ingin menyematkan langsung dalam "ClickHouse" (lebih disukai - lebih lurus, lebih baik).

Dengan demikian, bagaimana penyisipan diterapkan di MergeTree? Mengapa lebih baik memasukkannya tidak lebih dari sekali per detik atau kurang? Faktanya adalah bahwa "ClickHouse" adalah database kolom dan mengurutkan data dalam urutan kunci primer, dan ketika Anda memasukkan, jumlah file dibuat oleh setidaknya jumlah kolom di mana data diurutkan dalam urutan kunci primer (direktori terpisah dibuat, satu set file pada disk untuk setiap sisipan). Kemudian sisipan selanjutnya berjalan, dan di latar belakang mereka bergabung menjadi "partisi" yang lebih besar. Karena data diurutkan, Anda dapat "menyulap" dua file yang diurutkan tanpa banyak konsumsi memori.
Tetapi, seperti yang Anda bayangkan, jika Anda menulis 10 file untuk setiap sisipan, maka "ClickHouse" akan berakhir dengan cepat (atau server Anda), oleh karena itu disarankan untuk memasukkan dalam bundel besar. Karenanya, kami tidak pernah meluncurkan skema pertama dalam produksi. Kami segera meluncurkan yang memiliki nomor 2 di sini:

Bayangkan di sini bahwa ada sekitar seribu server yang kami luncurkan, hanya ada PHP. Dan di setiap server ada agen lokal kami, yang kami sebut "Kittenhouse", yang memegang satu koneksi ke "ClickHouse" dan memasukkan data setiap beberapa detik. Itu tidak memasukkan data ke MergeTree, tetapi ke tabel spooler, yang berfungsi untuk tidak langsung memasukkan ke MergeTree segera.
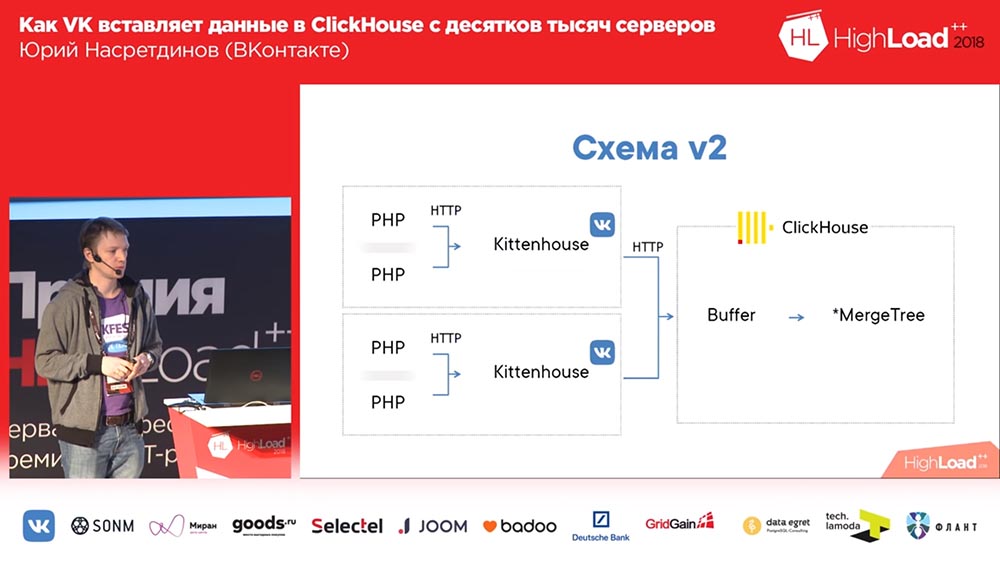
Bekerja dengan tabel buffer
Apa ini Tabel penyangga adalah sepotong memori yang dikocok (artinya, Anda sering dapat memasukkannya ke dalamnya). Mereka terdiri dari beberapa bagian, dan masing-masing bagian berfungsi sebagai penyangga independen, dan mereka menyiram secara independen (jika Anda memiliki banyak bagian dalam buffer, maka akan ada banyak sisipan per detik). Anda dapat membaca dari tabel ini - lalu Anda membaca gabungan dari konten buffer dan tabel induk, tetapi pada saat itu catatan diblokir, jadi lebih baik tidak membaca dari sana. Dan QPS yang sangat bagus ditunjukkan oleh tabel buffer, yaitu hingga 3 ribu QPS Anda tidak akan memiliki masalah sama sekali saat memasukkan. Jelas bahwa jika daya hilang di server, maka data dapat hilang, karena mereka hanya disimpan dalam memori.

Pada saat yang sama, skema dengan buffer diperumit oleh ALTER, karena Anda harus terlebih dahulu menjatuhkan tabel buffer yang lama dengan skema yang lama (data tidak akan hilang pada saat yang sama, karena akan disiram sebelum tabel dihapus). Kemudian Anda "mengubah" tabel yang Anda butuhkan dan membuat tabel buffer lagi. Dengan demikian, meskipun tidak ada tabel buffer, data Anda tidak mengalir di mana saja, tetapi Anda bahkan dapat secara lokal pada disk.

Apa itu Kittenhouse dan bagaimana cara kerjanya?
Apa itu KittenHouse? Ini adalah proxy. Tebak bahasa apa? Saya mengumpulkan topik paling hype dalam laporan saya - ini adalah "Clickhouse", Go, mungkin saya bisa mengingat hal lain. Ya, ini ditulis dalam Go, karena saya tidak benar-benar tahu cara menulis dalam C, saya tidak mau.

Dengan demikian, itu membuat koneksi dengan setiap server, dapat menulis ke memori. Misalnya, jika kita menulis log kesalahan di "Clickhouse", maka jika "Clickhouse" tidak punya waktu untuk memasukkan data (setelah semua, jika terlalu banyak yang ditulis), maka kita tidak membengkak dari memori - kita cukup membuang sisanya. Karena, jika kita menulis beberapa gigabit per detik dari kesalahan, maka, mungkin, kita dapat membuang beberapa. Kittenhouse tahu caranya. Selain itu, ia tahu cara mengirim secara andal, yaitu, ia menulis ke disk di mesin lokal dan sesekali (di sana, sekali dalam beberapa detik) ia mencoba mengirimkan data dari file ini. Dan pada awalnya kami menggunakan format Nilai biasa - bukan format biner, format teks (seperti dalam SQL biasa).

Tapi kemudian ini terjadi. Kami menggunakan pengiriman yang andal, menulis log, lalu memutuskan (itu adalah gugus uji bersyarat) ... Mereka memadamkannya selama beberapa jam dan mengangkatnya kembali, dan penyisipan dimulai dari ribuan server - ternyata Klickhouse masih memiliki "Utas pada" koneksi ”- dengan demikian, dalam seribu koneksi, insert aktif mengarah ke rata-rata beban server sekitar satu setengah ribu. Anehnya, server menerima permintaan, tetapi data tersebut tetap dimasukkan setelah beberapa waktu; tapi itu sangat sulit bagi server untuk melayani itu ...
Tambahkan nginx
Solusi semacam itu untuk model Thread per koneksi adalah nginx. Kami menempatkan nginx di depan Clickhouse, pada saat yang sama mengatur balancing menjadi dua replika (kami telah meningkatkan kecepatan penyisipan sebanyak 2 kali, meskipun bukan fakta bahwa seharusnya demikian) dan membatasi jumlah koneksi ke Clickhouse, ke hulu dan, karenanya, lebih banyak daripada di 50 senyawa, tampaknya tidak masuk akal untuk disisipkan.

Kemudian kami menyadari bahwa secara umum skema ini memiliki kekurangan, karena kami punya satu nginx di sini. Dengan demikian, jika nginx ini diletakkan, meskipun ada replika, kami kehilangan data atau, setidaknya, tidak menulis di mana pun. Karena itu, kami melakukan penyeimbangan muatan. Kami juga memahami bahwa "Clickhouse" masih cocok untuk log, dan "iblis" juga mulai menulis log sendiri di "Clickhouse" - sangat mudah, jujur saja. Kami masih menggunakannya untuk "setan" lainnya.

Kemudian mereka menemukan masalah yang menarik: jika Anda menggunakan cara yang tidak cukup standar untuk memasukkan dalam mode SQL, maka AST parser SQL berbasis lengkap dipaksa, yang agak lambat. Karenanya, kami menambahkan pengaturan agar ini tidak pernah terjadi. Kami melakukan penyeimbangan muatan, pemeriksaan kesehatan, sehingga jika ada yang mati, kami masih meninggalkan data. Kami telah mendapatkan cukup tabel sehingga kami harus memiliki kluster “Clickhouse” yang berbeda. Dan kami mulai memikirkan kegunaan lain - misalnya, kami ingin menulis log dari modul nginx, dan mereka tidak dapat berkomunikasi menggunakan RPC kami. Yah, saya ingin mengajar mereka bagaimana cara mengirim - misalnya, melalui UDP untuk menerima acara di localhost dan kemudian mengirimkannya ke "Clickhouse".
Satu langkah dari keputusan
Skema terakhir mulai terlihat seperti ini (versi keempat dari skema ini): pada setiap server di depan Clickhouse ada nginx (di server yang sama, apalagi) dan itu hanya proksi permintaan ke localhost dengan batas jumlah koneksi 50 buah. Dan sekarang skema ini sudah berfungsi, cukup bagus.

Kami hidup seperti ini sekitar sebulan. Semua orang senang, menambahkan tabel, menambahkan, menambahkan ... Secara umum, ternyata cara kami menambahkan tabel buffer tidak terlalu optimal (katakanlah begitu). Kami membuat 16 buah di setiap meja dan interval lampu kilat selama beberapa detik; kami memiliki 20 tabel dan 8 sisipan per detik pergi ke setiap tabel - dan pada saat itu "Clickhouse" dimulai ... catatan mulai kosong. Mereka bahkan tidak lulus ... Nginx memiliki hal yang menarik secara default sehingga jika koneksi berakhir di hulu, maka itu hanya memberikan "502" untuk semua permintaan baru.

Dan di sini di kami (saya hanya melihat log di "Clickhouse" saya melihat) di suatu tempat sekitar setengah persen dari permintaan gagal. Dengan demikian, pemanfaatan disk tinggi, ada banyak penggabungan. Apa yang telah saya lakukan? Secara alami, saya tidak mulai mengerti mengapa koneksi dan upstream berakhir.
Mengganti nginx dengan proxy terbalik
Saya memutuskan bahwa kita perlu mengelola ini sendiri, jangan memberikannya ke nginx - nginx tidak tahu tabel apa yang ada di "Clickhouse", dan mengganti nginx dengan proxy terbalik, yang juga saya tulis.
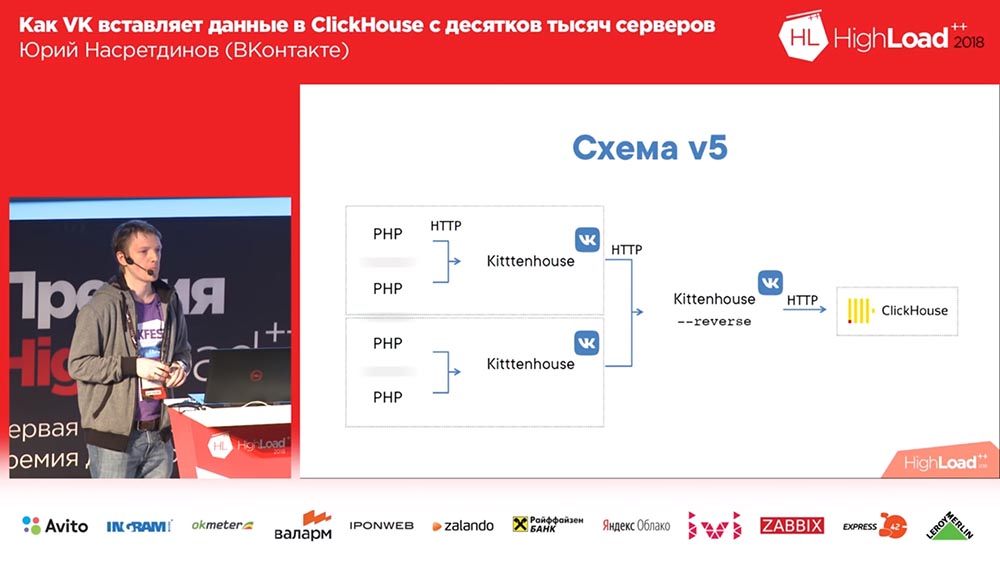
Apa yang dia lakukan Ia bekerja atas dasar pustaka fasthttp "goosh", yaitu, cepat, hampir secepat nginx. Maaf, Igor, jika Anda di sini (catatan: Igor Sysoev adalah seorang programmer Rusia yang menciptakan server web nginx). Dia dapat memahami pertanyaan apa itu - INSERT atau SELECT - masing-masing, ia menyimpan kumpulan koneksi yang berbeda untuk berbagai jenis pertanyaan.

Karenanya, bahkan jika kami tidak punya waktu untuk menyelesaikan permintaan, "pilihan" akan berlalu, dan sebaliknya. Dan itu mengelompokkan data ke dalam tabel buffer - dengan buffer kecil: jika ada kesalahan, kesalahan sintaks, dan sebagainya - sehingga mereka sedikit mempengaruhi sisa data, karena ketika kami hanya memasukkan ke dalam tabel buffer, kami memiliki kecil “ bachi ”, dan semua kesalahan kesalahan sintaks hanya mempengaruhi bagian kecil ini; dan di sini mereka sudah akan mempengaruhi buffer besar. Kecil adalah 1 megabyte, artinya, tidak terlalu kecil.

Memasukkan sinkronisasi dan pada dasarnya mengganti nginx pada dasarnya sama dengan yang dilakukan nginx sebelumnya - Kittenhouse tidak perlu diubah secara lokal untuk ini. Dan karena menggunakan fasthttp, itu sangat cepat - Anda dapat membuat lebih dari 100 ribu permintaan per detik dari satu sisipan melalui proksi terbalik. Secara teoritis, Anda dapat memasukkan satu baris ke proksi terbalik kittenhouse, tetapi kami tentu saja tidak.

Skema mulai terlihat seperti ini: Kittenhouse, proxy terbalik membalikkan banyak permintaan ke dalam tabel, dan pada gilirannya, tabel buffer memasukkannya ke dalam yang utama.
Pembunuh - solusi sementara, Kitten - permanen
Ada masalah yang sangat menarik ... Apakah ada di antara Anda yang menggunakan fasthttp? Siapa yang menggunakan fasthttp dengan permintaan POST? Mungkin, sebenarnya tidak layak melakukan ini, karena secara default buffer body permintaan, dan kami telah menetapkan ukuran buffer 16 megabyte. Penyisipan berhenti pada waktu di beberapa titik, dan dari semua puluhan ribu server 16-megabyte bongkahan mulai masuk, dan mereka semua buffered dalam memori sebelum diberikan ke Clickhouse. Dengan demikian, kehabisan memori, Pembunuh Kehabisan Memori datang, membunuh proxy terbalik (atau "Clickhouse", yang secara teoritis bisa "makan" lebih banyak dari proxy terbalik). Siklus itu berulang. Bukan masalah yang sangat bagus. Meskipun kami menemukan ini hanya setelah beberapa bulan beroperasi.
Apa yang saya lakukan? Sekali lagi, saya tidak terlalu suka mengerti apa yang sebenarnya terjadi. Sepertinya saya cukup jelas bahwa tidak perlu buffer ke memori. Saya tidak dapat menambal fasthttp, walaupun saya sudah mencoba. Tapi saya menemukan cara untuk membuatnya sehingga tidak perlu menambal apa pun, dan muncul dengan metode saya sendiri dalam HTTP - menyebutnya KITTEN. Yah, ini logis - "VK", "Kitten" ... Bagaimana lagi? ..

Jika permintaan datang ke server dengan metode Kitten, maka server harus menjawab "meow" - secara logis. Jika dia menjawab ini, maka diyakini bahwa dia memahami protokol ini, dan kemudian saya mencegat koneksi (ada metode seperti itu di fasthttp), dan koneksi masuk ke mode "mentah". Mengapa saya membutuhkan ini? Saya ingin mengontrol bagaimana membaca dari koneksi TCP terjadi. TCP memiliki properti yang luar biasa: jika tidak ada yang membaca dari sisi itu, maka catatan mulai menunggu, dan memori tidak secara khusus dihabiskan untuk ini.
Jadi saya membaca di suatu tempat dari 50 klien sekaligus (dari lima puluh karena lima puluh pasti sudah cukup, bahkan jika itu berasal dari DC lain) ... Konsumsi telah menurun dengan pendekatan ini setidaknya 20 kali, tapi saya jujur , Saya tidak bisa mengukur berapa tepatnya, karena sudah tidak ada gunanya (sudah menjadi tingkat kesalahan). Protokolnya adalah biner, yaitu ada nama tabel dan data; tidak ada header http, jadi saya tidak menggunakan soket web (saya tidak perlu berkomunikasi dengan browser - saya membuat protokol yang sesuai dengan kebutuhan kita). Dan bersamanya semuanya baik-baik saja.
Meja penyangga sedih
Baru-baru ini, kami menemukan fitur lain yang menarik dari tabel buffer. Dan masalah ini sudah jauh lebih menyakitkan daripada yang lain.
Bayangkan situasi ini: Anda telah secara aktif menggunakan Clickhouse, Anda memiliki puluhan server Clickhouse, dan Anda memiliki beberapa permintaan yang membaca untuk waktu yang sangat lama (misalnya, lebih dari 60 detik); dan Anda datang dan membuat Alter seperti itu pada saat ini ... Dan sampai "select" yang dimulai sebelum "Alter" tidak termasuk dalam tabel ini, "Alter" tidak memulai - mungkin beberapa fitur bagaimana "Clickhouse" bekerja tempat ini. Mungkin ini bisa diperbaiki? Atau tidak?
, , , . , , , «» ( – , , ), … , «» ( - «» ) – , - : ( , ), «» , - , . , «», – .

(, ) – «» query_thread_log. , - . 840 (100 ). , (, , , ) «» (inserts). , «» – «» . , – , . Mengapa , ! .

, ? «». .
«KitttenHouse»
, ? . ! : , , - . , .

, «», – , (, - ) , , – .

? . , , 10 , – -, , . , , , , – , «», 100 - – , , , . , . , .
, , . : , - , , , read only . ? . – - , - … ( , «», ClickHouse) ? ? , . . : , . , . .
. . , - ?.. «»? - … «»? , , . , . , .

– . , . , : , , ( ), – , .

Sequel Pro, «», . : «, -?» ? 2018-? , «» (MySQL) , «», ! «», – , .
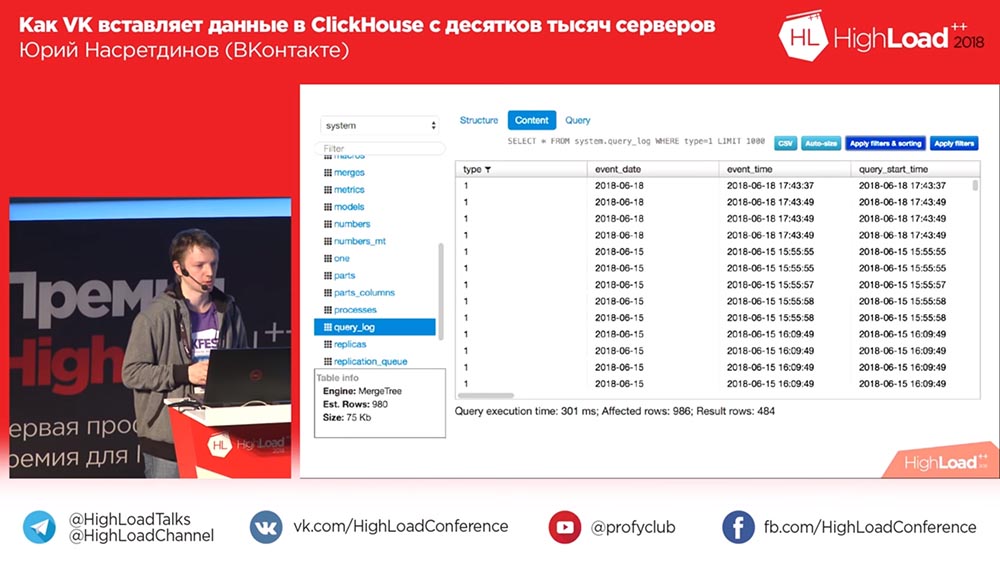
, , , , , , , , affected rows ( ), . .
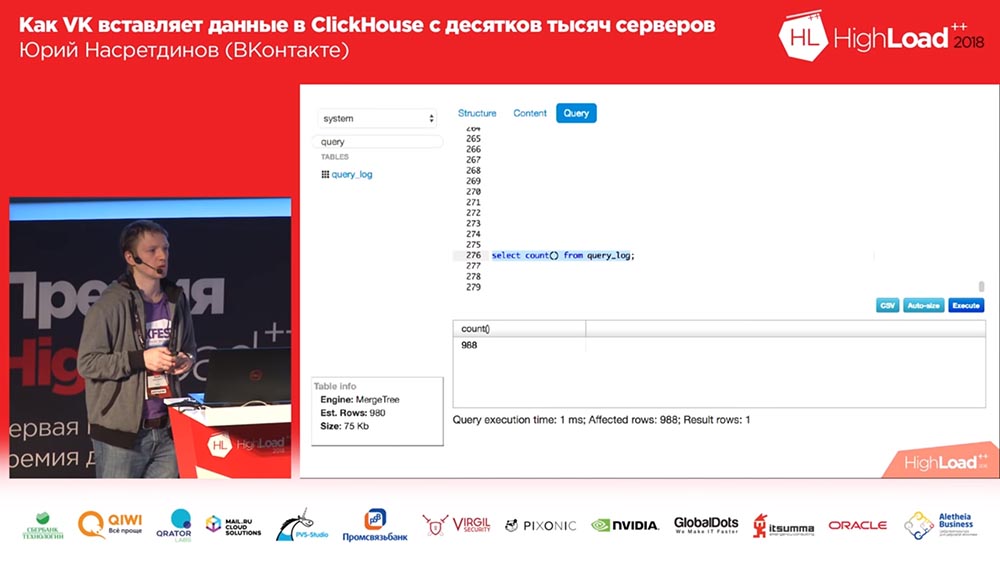
. «», . - - . .
«»
, «», , . , , – . , … , , .

TCP? , «» UDP. TCP… , , : «, ! , UDP». , TCP . , , – - ; , .
«» «» HighLoad Siberia, « »… , … , , . - , - , – , ( , , ).
. ! Github
. «» .
 :
: – , . , VHS.
( – ): – VHS, ?
 :"Kamu juga tidak bisa sepenuhnya menentukan bagaimana Clickhouse akan bekerja atau tidak!" Teman, 5 menit untuk pertanyaan!
:"Kamu juga tidak bisa sepenuhnya menentukan bagaimana Clickhouse akan bekerja atau tidak!" Teman, 5 menit untuk pertanyaan!Pertanyaan
Pertanyaan dari hadirin (selanjutnya - H): - Selamat siang. Terima kasih banyak atas laporannya. Saya punya dua pertanyaan. Saya akan mulai dengan yang sembrono: apakah jumlah huruf t dalam nama "Kittenhouse" pada skema (3, 4, 7 ...) memengaruhi kepuasan kucing?
UN: - Jumlah apa?
Z: - Huruf t. Ada tiga t, di suatu tempat tiga t.
UN: - Apakah saya benar-benar memperbaiki ini? Ya tentu saja! Ini adalah produk yang berbeda - saya baru saja berbohong kepada Anda selama ini. Oke, saya bercanda - tidak. Ah, ini! Tidak, itu hal yang sama, saya disegel.
 Z:
Z: - Terima kasih. Pertanyaan kedua adalah serius. Sejauh yang saya mengerti, di "Clickhouse" tabel buffer hidup secara eksklusif dalam memori, mereka tidak buffer ke disk dan, karenanya, tidak persisten.
UN: - Ya.
Z: - Dan pada saat yang sama, pada buffering klien Anda ke disk dilakukan, yang menyiratkan beberapa jaminan pengiriman log yang sama ini. Tetapi di Clickhouse, ini tidak dijamin. Jelaskan bagaimana jaminan dilakukan, karena apa? .. Mekanisme ini lebih rinci
UN: - Ya, secara teoritis tidak ada kontradiksi, karena Anda dapat mendeteksi jutaan cara yang berbeda dalam kenyataan ketika "Clickhouse" jatuh. Jika "Clickhouse" mogok (jika tidak selesai dengan benar), Anda dapat, secara kasar, mundur log yang Anda tulis sedikit dan mulai dari saat semuanya baik-baik saja. Mari kita memundurkannya satu menit yang lalu, yaitu, diyakini bahwa itu mem-flash semuanya dalam satu menit.
Z: - Yaitu, Kittenhouse menjaga jendela lebih lama dan seandainya jatuh dapat mengenali dan melepasnya?
PBB: - Tapi ini secara teori. Dalam praktiknya, kami tidak melakukan ini, dan pengiriman yang andal adalah dari nol hingga waktu tak terbatas. Tapi rata-rata satu. Kami puas bahwa jika "Clickhouse" macet karena suatu alasan atau server "reboot", maka kami kehilangan sedikit. Dalam semua kasus lain, tidak ada yang akan terjadi.
Z: - Halo. Sejak awal, menurut saya Anda akan benar-benar menggunakan UDP sejak awal laporan. Anda memiliki http, semua itu ... Dan sebagian besar masalah yang Anda uraikan, seperti yang saya pahami, disebabkan oleh solusi khusus ini ...
UN: - Apa yang kita gunakan TCP?
Z: - Sebenarnya, ya.
UN: - Tidak.
Z: - Itu dengan fasthttp bahwa Anda punya masalah, dengan koneksi Anda punya masalah. Jika Anda hanya menggunakan UDP, Anda akan menghemat waktu. Yah, akan ada masalah dengan pesan panjang atau sesuatu yang lain ...
UN: - Dengan apa?
 Z:
Z: - Dengan pesan panjang, karena mungkin tidak cocok dengan MTU, sesuatu yang lain ... Nah, di sana masalah Anda mungkin muncul. Pertanyaannya adalah: mengapa bukan UDP?
UN: - Saya percaya bahwa penulis yang mengembangkan TCP / IP jauh lebih pintar daripada saya dan tahu bagaimana membuat serialisasi paket lebih baik (jadi mereka pergi), pada saat yang sama menyesuaikan jendela pengiriman, jangan membebani jaringan, dan memberikan umpan balik tentang apa berbunyi, tidak dihitung dari sisi lain ... Semua masalah ini, menurut pendapat saya, juga akan di UDP, hanya saja saya harus menulis lebih banyak kode daripada yang sudah saya tulis untuk mengimplementasikan hal yang sama sendiri dan kemungkinan besar itu akan menjadi buruk. Saya bahkan tidak suka menulis dalam bahasa C, tidak seperti di sana ...
Z: - Mudah saja! Terkirim ok dan jangan mengharapkan apa pun - Anda benar-benar tidak sinkron. Sebuah pemberitahuan kembali bahwa semuanya baik-baik saja - itu berarti telah datang; tidak datang - itu berarti buruk.
UN: - Saya perlu keduanya dan yang lain - Saya harus dapat mengirim keduanya dengan jaminan pengiriman, dan tanpa jaminan pengiriman. Ini adalah dua skenario yang berbeda. Beberapa log saya tidak perlu kehilangan atau tidak kehilangan masuk akal.
Z: - Saya tidak akan makan waktu. Ini harus dibahas lebih lama. Terima kasih
Presenter: - Siapa yang punya pertanyaan - pena di langit!
 Z:
Z: - Hai, saya Sasha. Di suatu tempat di tengah-tengah laporan ada perasaan bahwa mungkin, selain TCP, untuk menggunakan solusi yang sudah jadi - semacam "Kafka".
UN: "Ya ... Sudah saya katakan, saya tidak ingin menggunakan server perantara, karena ... untuk Kafka - ternyata kami memiliki sepuluh ribu host; sebenarnya, kami memiliki lebih dari - puluhan ribu host. Dengan Kafka, tanpa proxy, itu juga bisa menyakitkan. Selain itu, yang paling penting, masih memberikan "latensi", memberikan host tambahan yang perlu Anda miliki. Dan saya tidak ingin memilikinya - saya ingin ...
Z: - Tapi pada akhirnya ternyata.
UN: - Tidak, tidak ada tuan rumah! Semuanya bekerja di host Clickhouse.
Z: - Tapi bagaimana dengan Kittenhouse, kebalikannya - di mana dia tinggal?
 UN:
UN: - Di tuan rumah Klickhouse, dia tidak menulis apa pun ke disk.
Z: - Baiklah, katakan saja.
Presenter: - Memuaskan Anda? Bisakah kita memberi gaji?
Z: - Ya, ya. Bahkan, ada banyak kruk untuk mendapatkan hal yang sama, dan sekarang - jawaban sebelumnya tentang topik TCP bertentangan, menurut pendapat saya, situasi ini. Rasanya seperti Anda bisa melakukan semua hal di lutut Anda dalam waktu yang jauh lebih singkat.
UN: - Dan mengapa saya tidak ingin menggunakan "Kafka", karena ada cukup banyak keluhan di telegram "Clickhouse" di Telegram yang, misalnya, pesan dari "Kafka" hilang. Bukan dari Kafka sendiri, tetapi dalam integrasi Kafka dan Klikhaus; atau sesuatu yang tidak terhubung di sana. Secara kasar, maka perlu bagi klien untuk Kafka untuk menulis kemudian. Saya tidak berpikir bahwa solusi yang lebih sederhana dan lebih dapat diandalkan akan diperoleh.
Z: - Katakan, mengapa Anda tidak mencoba beberapa jalur atau bus umum semacam itu? Karena Anda mengatakan bahwa itu mungkin dengan Anda secara tidak sinkron untuk melewati antrian log itu sendiri dan juga mendapatkan secara tidak sinkron melalui antrian sebagai tanggapan?
 UN:
UN: - Harap sarankan antrian mana yang dapat digunakan?
Z: - Apa pun, bahkan tanpa jaminan bahwa mereka akan melakukan pemesanan. Redis Apa Saja, RMQ ...
UN: - Saya merasa bahwa Redis kemungkinan besar tidak akan dapat menarik volume penyisipan seperti itu bahkan pada satu host (dalam arti beberapa server) yang menarik keluar Clickhouse. Saya tidak dapat mengkonfirmasi ini dengan bukti apa pun (saya tidak membandingkannya), tetapi bagi saya Redis bukanlah solusi terbaik di sini. Pada prinsipnya, Anda dapat menganggap sistem ini sebagai antrian pesan dadakan, tetapi hanya untuk "Clickhouse"
Presenter: - Yuri, terima kasih banyak. Saya mengusulkan untuk mengakhiri pertanyaan dan jawaban tentang ini dan mengatakan yang mana dari orang-orang yang mengajukan pertanyaan akan memberi kami sebuah buku.
UN: - Saya ingin memberikan buku kepada orang pertama yang mengajukan pertanyaan.
Presenter: - Hebat! Hebat! Hebat! Terima kasih banyak!
Sedikit iklan :)
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikan kepada teman Anda
VPS berbasis cloud untuk pengembang mulai $ 4,99 ,
analog unik dari server entry-level yang diciptakan oleh kami untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps mulai dari $ 19 atau cara membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
Dell R730xd 2 kali lebih murah di pusat data Equinix Tier IV di Amsterdam? Hanya kami yang memiliki
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV dari $ 199 di Belanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - mulai dari $ 99! Baca tentang
Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?