Ini bahkan bukan lelucon, sepertinya gambar khusus ini paling akurat mencerminkan esensi dari database ini, dan pada akhirnya akan menjadi jelas mengapa:

Menurut Peringkat DB-Engine, dua basis kolom NoSQL paling populer adalah Cassandra (selanjutnya CS) dan HBase (HB).
Dengan kehendak takdir, tim manajemen pemuatan data kami di Sberbank telah bekerja sama dengan HB
sejak lama . Selama waktu ini, kami mempelajari kekuatan dan kelemahannya dengan cukup baik dan belajar cara memasaknya. Namun, kehadiran alternatif dalam bentuk CS sepanjang waktu membuat saya menyiksa diri sendiri dengan keraguan: apakah kita membuat pilihan yang tepat? Selain itu, hasil
perbandingan yang dilakukan oleh DataStax mengatakan bahwa CS dengan mudah mengalahkan HB dengan skor yang hampir menghancurkan. Di sisi lain, DataStax adalah orang yang tertarik, dan Anda tidak boleh bicara di sini. Juga, sedikit informasi tentang kondisi pengujian itu memalukan, jadi kami memutuskan untuk mencari tahu sendiri siapa raja BigData NoSql, dan hasilnya sangat menarik.
Namun, sebelum beralih ke hasil pengujian yang dilakukan, perlu untuk menggambarkan aspek-aspek penting dari konfigurasi lingkungan. Faktanya adalah bahwa CS dapat digunakan dalam mode toleransi kehilangan data. Yaitu ini adalah ketika hanya satu server (node) yang bertanggung jawab untuk data kunci tertentu, dan jika jatuh karena suatu alasan, nilai kunci ini akan hilang. Untuk banyak tugas ini tidak kritis, tetapi untuk sektor perbankan ini merupakan pengecualian daripada aturan. Dalam kasus kami, penting untuk memiliki beberapa salinan data untuk penyimpanan yang andal.
Oleh karena itu, hanya mode CS dari replikasi tiga yang dipertimbangkan, yaitu pembuatan case dilakukan dengan parameter berikut:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3};
Selanjutnya, ada dua cara untuk memastikan tingkat konsistensi yang diperlukan. Aturan umum:
NW + NR> RF
Ini berarti bahwa jumlah konfirmasi dari node ketika menulis (NW) ditambah jumlah konfirmasi dari node ketika membaca (NR) harus lebih besar daripada faktor replikasi. Dalam kasus kami, RF = 3 sehingga opsi berikut cocok:
2 + 2> 3
3 + 1> 3
Karena sangat penting bagi kami untuk menjaga data seandal mungkin, skema 3 + 1 dipilih. Selain itu, HB bekerja dengan dasar yang sama, yaitu perbandingan seperti itu akan lebih jujur.
Perlu dicatat bahwa DataStax melakukan yang sebaliknya dalam penelitian mereka, mereka menetapkan RF = 1 untuk CS dan HB (untuk yang terakhir dengan mengubah pengaturan HDFS). Ini adalah aspek yang sangat penting, karena dampaknya pada kinerja CS dalam kasus ini sangat besar. Misalnya, gambar di bawah ini menunjukkan peningkatan waktu yang diperlukan untuk memuat data ke dalam CS:
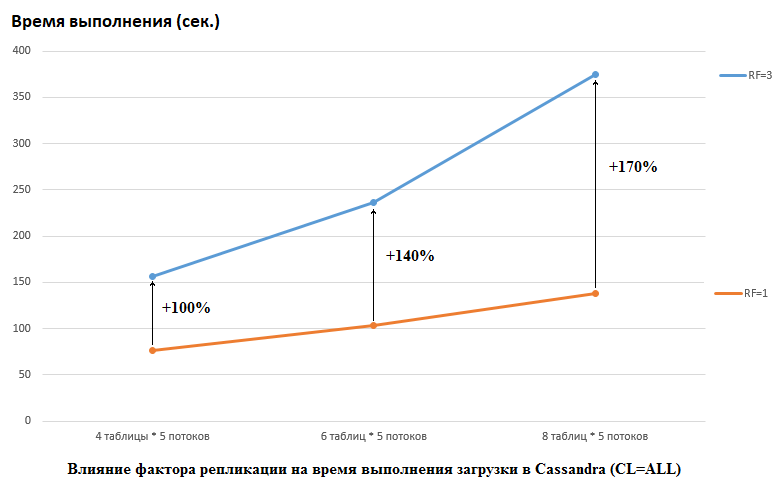
Di sini kita melihat yang berikut, semakin banyak utas bersaing menulis data, semakin lama waktu yang dibutuhkan. Ini wajar, tetapi penting bahwa penurunan kinerja untuk RF = 3 secara signifikan lebih tinggi. Dengan kata lain, jika kita menulis dalam 4 tabel di masing-masing 5 aliran (total 20), maka RF = 3 kehilangan sekitar 2 kali (150 detik RF = 3 berbanding 75 untuk RF = 1). Tetapi jika kita menambah beban dengan memuat data ke dalam 8 tabel di masing-masing 5 aliran (total 40), maka kehilangan RF = 3 sudah 2,7 kali (375 detik berbanding 138).
Mungkin sebagian inilah rahasia keberhasilan pengujian DataStax untuk pengujian beban CS, karena untuk HB di stan kami, mengubah faktor replikasi dari 2 menjadi 3 tidak berpengaruh. Yaitu disk bukanlah hambatan untuk HB untuk konfigurasi kami. Namun, ada banyak jebakan lain, karena harus dicatat bahwa versi HB kami sedikit ditambal dan dikaburkan, lingkungannya sangat berbeda, dll. Perlu juga dicatat bahwa mungkin saya tidak tahu bagaimana mempersiapkan CS dengan benar dan ada beberapa cara yang lebih efektif untuk bekerja dengannya dan saya berharap di komentar kita akan mengetahuinya. Tetapi hal pertama yang pertama.
Semua tes dilakukan pada kluster besi yang terdiri dari 4 server, masing-masing dalam konfigurasi:
CPU: Xeon E5-2680 v4 @ 2.40GHz 64 utas.
Disk: 12 buah HDD SATA
versi java: 1.8.0_111
Versi CS: 3.11.5
Parameter cassandra.ymlnum_tokens: 256
hinted_handoff_enabled: true
hinted_handoff_throttle_in_kb: 1024
max_hints_delivery_threads: 2
hints_directory: / data10 / cassandra / hints
hints_flush_ Period_in_ms: 10000
max_hints_file_size_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
authenticator: AllowAllAuthenticator
authorizer: AllowAllAuthorizer
role_manager: CassandraRoleManager
role_validity_in_ms: 2000
permissions_validity_in_ms: 2000
credentials_validity_in_ms: 2000
partisi: org.apache.cassandra.dht.Murmur3Partitioner
data_file_direktori:
- / data1 / cassandra / data # setiap direktori dataN adalah drive yang terpisah
- / data2 / cassandra / data
- / data3 / cassandra / data
- / data4 / cassandra / data
- / data5 / cassandra / data
- / data6 / cassandra / data
- / data7 / cassandra / data
- / data8 / cassandra / data
commitlog_directory: / data9 / cassandra / commitlog
cdc_enabled: false
disk_failure_policy: stop
commit_failure_policy: berhenti
ready_statements_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
key_cache_size_in_mb:
key_cache_save_ periode: 14400
row_cache_size_in_mb: 0
row_cache_save_ Period: 0
counter_cache_size_in_mb:
counter_cache_save_ periode: 7200
Saved_caches_directory: / data10 / cassandra / Saved_caches
commitlog_sync: periodik
commitlog_sync_ Period_in_ms: 10000
commitlog_segment_size_in_mb: 32
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameter:
- biji: "*, *"
concurrent_reads: 256 # mencoba 64 - tidak ada perbedaan yang diperhatikan
concurrent_writes: 256 # mencoba 64 - tidak ada perbedaan yang diperhatikan
concurrent_counter_writes: 256 # mencoba 64 - tidak ada perbedaan yang diperhatikan
concurrent_materialized_view_writes: 32
memtable_heap_space_in_mb: 2048 # mencoba 16 GB - lebih lambat
memtable_allocation_type: heap_buffers
index_summary_capacity_in_mb:
index_summary_resize_interval_in_minutes: 60
trickle_fsync: false
trickle_fsync_interval_in_kb: 10240
storage_port: 7000
ssl_storage_port: 7001
listen_address: *
broadcast_address: *
listen_on_broadcast_address: true
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: true
native_transport_port: 9042
start_rpc: true
rpc_address: *
rpc_port: 9160
rpc_keepalive: true
rpc_server_type: sync
thrift_framed_transport_size_in_mb: 15
incremental_backups: false
snapshot_before_compaction: false
auto_snapshot: true
column_index_size_in_kb: 64
column_index_cache_size_in_kb: 2
concurrent_compactors: 4
compaction_throughput_mb_per_sec: 1600
sstable_preemptive_open_interval_in_mb: 50
read_request_timeout_in_ms: 100000
range_request_timeout_in_ms: 200000
write_request_timeout_in_ms: 40000
counter_write_request_timeout_in_ms: 100000
cas_contention_timeout_in_ms: 20000
truncate_request_timeout_in_ms: 60000
request_timeout_in_ms: 200000
slow_query_log_timeout_in_ms: 500
cross_node_timeout: false
endpoint_snitch: GossipingPropertyFileSnitch
dynamic_snitch_update_interval_in_ms: 100
dynamic_snitch_reset_interval_in_ms: 600000
dynamic_snitch_badness_threshold: 0.1
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
server_encryption_options:
internode_encryption: tidak ada
client_encryption_options:
diaktifkan: salah
internode_compression: dc
inter_dc_tcp_nodelay: false
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
enable_user_defined_functions: false
enable_scripted_user_defined_functions: false
windows_timer_interval: 1
transparent_data_encryption_options:
diaktifkan: salah
tombstone_warn_threshold: 1000
tombstone_failure_threshold: 100000
batch_size_warn_threshold_in_kb: 200
batch_size_fail_threshold_in_kb: 250
unlogged_batch_across_partitions_warn_threshold: 10
compaction_large_partition_warning_threshold_mb: 100
gc_warn_threshold_in_ms: 1000
back_pressure_enabled: false
enable_materialized_views: true
enable_sasi_indexes: true
Pengaturan GC:
### Pengaturan CMS-XX: + UseParNewGC
-XX: + UseConcMarkSweepGC
-XX: + CMSParallelRemarkEnabled
-XX: SurvivorRatio = 8
-XX: MaxTenuringThreshold = 1
-XX: CMSInitiatingOccupancyFraction = 75
-XX: + UseCMSInitiatingOccupancyOnly
-XX: CMSWaitDuration = 10000
-XX: + CMSParallelInitialMarkEnabled
-XX: + CMSEdenChunksRecordAlways
-XX: + CMSClassUnloadingEnabled
Memori jvm.options dialokasikan 16Gb (masih mencoba 32 Gb, tidak ada perbedaan yang terlihat).
Membuat tabel dilakukan oleh perintah:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};
Versi HB: 1.2.0-cdh5.14.2 (dalam kelas org.apache.hadoop.hbase.regionserver.HRegion kami mengecualikan MetricsRegion yang mengarah ke GC dengan lebih dari 1000 wilayah di RegionServer)
Opsi HBase non-standarzookeeper.session.timeout: 120000
hbase.rpc.timeout: 2 menit
hbase.client.scanner.timeout. Periode: 2 menit
hbase.master.handler.count: 10
hbase.regionserver.lease. Period, hbase.client.scanner.timeout. period: 2 menit
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll. period: 4 jam
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: 1 GiB
hbase.hregion.memstore.block.multiplier: 6
hbase.hstore.compactionThreshold: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.majorcompaction: 1 hari
Potongan Konfigurasi Lanjut Layanan HBase (Katup Pengaman) untuk hbase-site.xml:
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
Opsi Konfigurasi Java untuk HBase RegionServer:
-XX: + UseParNewGC -XX: + UseConcMarkSweepGC -XX: CMSInitiatingOccupancyFraction = 70 -XX: + CMSParallelRemarkEnabled -XX: ReservedCodeCacheSize = 256m
hbase.snapshot.master.timeoutMillis: 2 menit
hbase.snapshot.region.timeout: 2 menit
hbase.snapshot.master.timeout.millis: 2 menit
HBase REST Server Ukuran Log Maks: 100 MiB
HBase REST Server Backup File Log Maksimum: 5
HBase Thrift Server Max Ukuran Log: 100 MiB
HBase Thrift Server Backup File Log Maksimum: 5
Master Max Ukuran Log: 100 MiB
Pencadangan File Log Maksimum Master: 5
RegionServer Max Ukuran Log: 100 MiB
Pencadangan File Log Maksimum RegionServer: 5
Jendela Deteksi Master Aktif HBase: 4 menit
dfs.client.hedged.read.threadpool.size: 40
dfs.client.hedged.read.threshold.millis: 10 milidetik (s)
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
Penjelas File Proses Maksimum: 180.000
hbase.thrift.minWorkerThreads: 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.size: 20
Utas Penggerak Wilayah: 6
Ukuran Java Heap Klien dalam Bytes: 1 GiB
Grup Default Server Rase HBase: 3 GiB
Grup Default Server Hemat HBase: 3 GiB
Java Heap Ukuran Master HBase dalam Bytes: 16 GiB
Ukuran Java Heap dari Region HBaseServer dalam Bytes: 32 GiB
+ ZooKeeper
maxClientCnxns: 601
maxSessionTimeout: 120000
Membuat tabel:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns: t1 UniformSplit -c 64 -f cf
ubah 'ns: t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSION => 'GZ'}Ada satu poin penting - deskripsi DataStax tidak mengatakan berapa banyak daerah yang digunakan untuk membuat tabel HB, meskipun ini sangat penting untuk volume besar. Oleh karena itu, untuk pengujian, angka = 64 dipilih, yang memungkinkan penyimpanan hingga 640 GB, mis. meja ukuran sedang.
Pada saat pengujian, HBase memiliki 22 ribu tabel dan 67 ribu wilayah (ini akan mematikan untuk versi 1.2.0, jika bukan karena tambalan yang disebutkan di atas).
Sekarang untuk kodenya. Karena tidak jelas konfigurasi mana yang lebih menguntungkan untuk database tertentu, pengujian dilakukan dalam berbagai kombinasi. Yaitu dalam beberapa tes, beban berjalan secara bersamaan ke 4 tabel (semua 4 node digunakan untuk koneksi). Dalam tes lain, mereka bekerja dengan 8 tabel berbeda. Dalam beberapa kasus, ukuran bets adalah 100, dalam 200 lainnya (parameter batch - lihat kode di bawah). Ukuran data untuk nilai adalah 10 byte atau 100 byte (dataSize). Secara total, 5 juta catatan ditulis dan dikurangi setiap kali dalam setiap tabel. Pada saat yang sama, 5 aliran ditulis / dibaca ke dalam setiap tabel (nomor aliran adalah angka), masing-masing menggunakan rentang kunci sendiri (jumlah = 1 juta):
if (opType.equals("insert")) { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { StringBuilder sb = new StringBuilder("BEGIN BATCH "); for (int i = 0; i < batch; i++) { String value = RandomStringUtils.random(dataSize, true, true); sb.append("INSERT INTO ") .append(tableName) .append("(id, title) ") .append("VALUES (") .append(key) .append(", '") .append(value) .append("');"); key++; } sb.append("APPLY BATCH;"); final String query = sb.toString(); session.execute(query); } } else { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN ("); for (int i = 0; i < batch; i++) { sb = sb.append(key); if (i+1 < batch) sb.append(","); key++; } sb = sb.append(");"); final String query = sb.toString(); ResultSet rs = session.execute(query); } }
Oleh karena itu, fungsi serupa disediakan untuk HB:
Configuration conf = getConf(); HTable table = new HTable(conf, keyspace + ":" + tableName); table.setAutoFlush(false, false); List<Get> lGet = new ArrayList<>(); List<Put> lPut = new ArrayList<>(); byte[] cf = Bytes.toBytes("cf"); byte[] qf = Bytes.toBytes("value"); if (opType.equals("insert")) { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { lPut.clear(); for (int i = 0; i < batch; i++) { Put p = new Put(makeHbaseRowKey(key)); String value = RandomStringUtils.random(dataSize, true, true); p.addColumn(cf, qf, value.getBytes()); lPut.add(p); key++; } table.put(lPut); table.flushCommits(); } } else { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { lGet.clear(); for (int i = 0; i < batch; i++) { Get g = new Get(makeHbaseRowKey(key)); lGet.add(g); key++; } Result[] rs = table.get(lGet); } }
Karena klien harus menjaga distribusi data yang seragam dalam HB, fungsi pengasinan utama terlihat seperti ini:
public static byte[] makeHbaseRowKey(long key) { byte[] nonSaltedRowKey = Bytes.toBytes(key); CRC32 crc32 = new CRC32(); crc32.update(nonSaltedRowKey); long crc32Value = crc32.getValue(); byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7); return ArrayUtils.addAll(salt, nonSaltedRowKey); }
Sekarang yang paling menarik adalah hasilnya:

Sama seperti grafik:
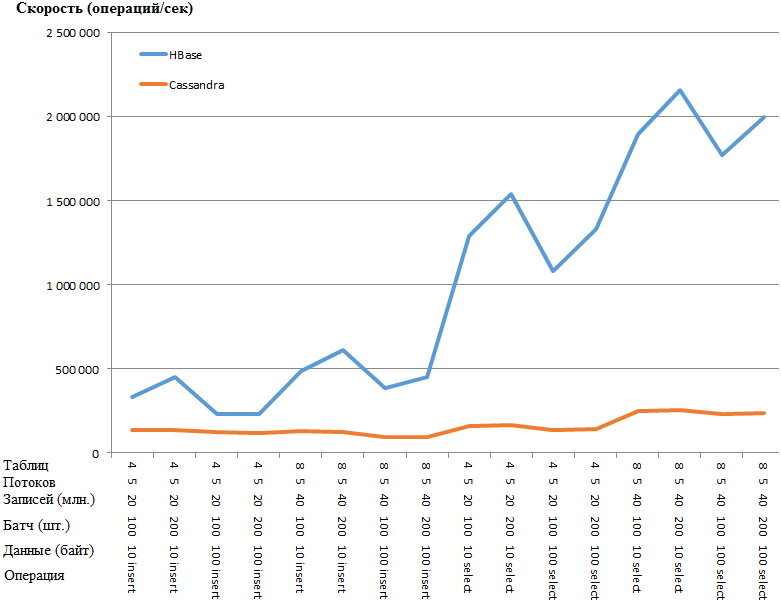
Keuntungan dari HB sangat menakjubkan sehingga ada kecurigaan semacam kemacetan dalam pengaturan CS. Namun, googling dan torsi parameter yang paling jelas (seperti concurrent_writes atau memtable_heap_space_in_mb) tidak memberikan akselerasi. Pada saat yang sama, log bersih, jangan bersumpah apa pun.
Data berbaring secara merata di seluruh node, statistik dari semua node kira-kira sama.
Berikut adalah statistik di atas meja dengan salah satu nodeKeyspace: ks
Baca Hitung: 9383707
Baca Latensi: 0,04287025042448576 ms
Tulis Hitung: 15462012
Tulis Latensi: 0,1350068438699957 ms
Flushes yang tertunda: 0
Tabel: t1
Hitungan SSTable: 16
Ruang yang digunakan (hidup): 148,59 MiB
Ruang yang digunakan (total): 148,59 MiB
Ruang yang digunakan oleh snapshot (total): 0 byte
Memori tumpukan yang digunakan (total): 5,17 MiB
Rasio Kompresi SSTable: 0,5720989576459437
Jumlah partisi (perkiraan): 3970323
Jumlah sel memtable: 0
Ukuran data memtable: 0 byte
Memtable off heap memory yang digunakan: 0 bytes
Hitungan saklar memtable: 5
Hitungan baca lokal: 2346045
Latensi baca lokal: NaN ms
Hitungan tulis lokal: 3865503
Latensi tulis lokal: NaN ms
Flush yang tertunda: 0
Persen diperbaiki: 0,0
Bloom menyaring false positive: 25
Rasio salah filter Bloom: 0,00000
Ruang filter Bloom digunakan: 4,57 MiB
Bloom menyaring memori tumpukan yang digunakan: 4,57 MiB
Ringkasan indeks dari memori tumpukan yang digunakan: 590,02 KiB
Metadata kompresi dari memori tumpukan yang digunakan: 19,45 KiB
Bytes minimum partisi yang dipadatkan: 36
Bytes maksimum partisi yang dipadatkan: 42
Partisi rata-rata byte padat: 42
Rata-rata sel hidup per irisan (lima menit terakhir): NaN
Sel langsung maksimum per irisan (lima menit terakhir): 0
Batu nisan per irisan rata-rata (lima menit terakhir): NaN
Batu nisan maksimum per irisan (lima menit terakhir): 0
Menjatuhkan Mutasi: 0 byte
Upaya untuk mengurangi ukuran bets (hingga mengirim satu per satu) tidak memberikan efek, hanya saja semakin buruk. Ada kemungkinan bahwa sebenarnya ini benar-benar kinerja maksimum untuk CS, karena hasil yang diperoleh pada CS mirip dengan yang diperoleh untuk DataStax - sekitar ratusan ribu operasi per detik. Selain itu, jika Anda melihat pemanfaatan sumber daya, Anda akan melihat bahwa CS menggunakan lebih banyak CPU dan disk:
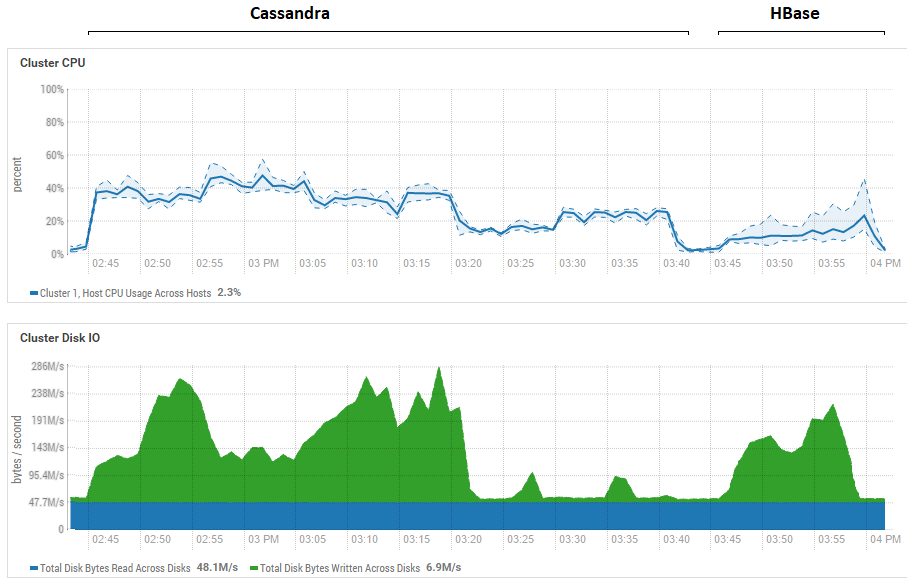 Gambar tersebut menunjukkan pemanfaatan selama menjalankan semua tes berturut-turut untuk kedua basis data.
Gambar tersebut menunjukkan pemanfaatan selama menjalankan semua tes berturut-turut untuk kedua basis data.Mengenai manfaat membaca yang kuat dari HB. Dapat dilihat bahwa untuk kedua basis data, pemanfaatan disk saat membaca sangat rendah (tes baca adalah bagian akhir dari siklus pengujian untuk setiap basis data, misalnya, untuk CS mulai 15:20 hingga 15:40). Dalam kasus HB, alasannya jelas - sebagian besar data hang di memori, di memstore, dan beberapa di-cache di blockcache. Adapun CS, tidak begitu jelas cara kerjanya, namun, pemanfaatan disk juga tidak terlihat, tetapi untuk berjaga-jaga, upaya dilakukan untuk mengaktifkan row_cache_size_in_mb = 2048 cache dan mengatur caching = {'keys': 'ALL', 'rows_per_partition': ' 2.000.000}, tetapi itu membuatnya sedikit lebih buruk.
Sekali lagi perlu dikatakan poin penting tentang jumlah daerah dalam HB. Dalam kasus kami, nilai 64 ditunjukkan. Jika Anda menguranginya dan membuatnya sama dengan misalnya 4, maka ketika membaca kecepatan turun 2 kali. Alasannya adalah bahwa memstore akan tersumbat lebih cepat dan file akan lebih sering memerah dan ketika membacanya perlu memproses lebih banyak file, yang merupakan operasi yang agak rumit untuk HB. Dalam kondisi nyata, ini dapat diatasi dengan memikirkan strategi persiapan dan pemadatan, khususnya, kami menggunakan utilitas buatan sendiri yang mengumpulkan sampah dan memadatkan HFiles secara terus-menerus di latar belakang. Ada kemungkinan bahwa untuk tes DataStax, umumnya 1 wilayah dialokasikan per tabel (yang tidak benar) dan ini akan sedikit menjelaskan mengapa HB kehilangan begitu banyak dalam tes baca mereka.
Kesimpulan awal dari ini adalah sebagai berikut. Dengan asumsi tidak ada kesalahan besar yang dibuat selama pengujian, Cassandra seperti raksasa dengan kaki tanah liat. Lebih tepatnya, ketika dia menyeimbangkan pada satu kaki, seperti pada gambar di awal artikel, dia menunjukkan hasil yang relatif baik, tetapi ketika dia bertarung dalam kondisi yang sama, dia langsung kalah. Pada saat yang sama, dengan mempertimbangkan pemanfaatan CPU yang rendah pada perangkat keras kami, kami belajar untuk menanam dua HB RegionServer per host dan dengan demikian menggandakan produktivitas. Yaitu dengan mempertimbangkan pemanfaatan sumber daya, situasi untuk CS bahkan lebih menyedihkan.
Tentu saja, tes ini cukup sintetik dan jumlah data yang digunakan di sini relatif sederhana. Ada kemungkinan bahwa ketika beralih ke terabyte, situasinya akan berbeda, tetapi jika untuk HB kita dapat memuat terabyte, maka untuk CS ini ternyata bermasalah. Itu sering melempar OperationTimedOutException bahkan dengan volume ini, meskipun parameter harapan respon sudah meningkat beberapa kali dibandingkan dengan yang standar.
Saya berharap bahwa dengan upaya bersama kita akan menemukan kemacetan CS dan jika kita berhasil mempercepatnya, maka saya pasti akan menambahkan informasi tentang hasil akhir di akhir posting.
UPD: Pedoman berikut ini diterapkan pada pengaturan CS:
disk_optimization_strategy: spinning
MAX_HEAP_SIZE = "32G"
HEAP_NEWSIZE = "3200M"
-Xms32G
-Xmx32G
-XX: + UseG1GC
-XX: G1RSetUpdatingPauseTimePercent = 5
-XX: MaxGCPauseMillis = 500
-XX: MemulaiHeapOccupancyPercent = 70
-XX: ParallelGCThreads = 32
-XX: ConcGCThreads = 8Adapun pengaturan OS, ini adalah prosedur yang agak panjang dan rumit (mendapatkan root, me-reboot server, dll), jadi rekomendasi ini tidak diterapkan. Di sisi lain, kedua database berada dalam kondisi yang sama, jadi semuanya adil.
Di bagian kode, satu konektor dibuat untuk semua utas menulis ke tabel:
connector = new CassandraConnector(); connector.connect(node, null, CL); session = connector.getSession(); session.getCluster().getConfiguration().getSocketOptions().setConnectTimeoutMillis(120000); KeyspaceRepository sr = new KeyspaceRepository(session); sr.useKeyspace(keyspace); prepared = session.prepare("insert into " + tableName + " (id, title) values (?, ?)");
Data dikirim melalui pengikatan:
for (Long key = count * thNum; key < count * (thNum + 1); key++) { String value = RandomStringUtils.random(dataSize, true, true); session.execute(prepared.bind(key, value)); }
Ini tidak memiliki dampak signifikan pada kinerja perekaman. Untuk keandalan, saya meluncurkan beban dengan alat YCSB, hasil yang benar-benar sama. Di bawah ini adalah statistik untuk satu utas (dari 4):
2020-01-18 14: 41: 53: 180 315 dt: 10.000.000 operasi; 21589.1 operasi saat ini / detik; [CLEANUP: Hitung = 100, Max = 2236415, Min = 1, Rata-rata = 22356,39, 90 = 4, 99 = 24, 99,9 = 2236415, 99,99 = 2236415] [INSERT: Hitung: 119551, Max = 174463, Min = 273, Rata-rata = 2582,71, 90 = 3491, 99 = 16767, 99,9 = 99711, 99,99 = 171263]
[KESELURUHAN], RunTime (ms), 315539
[KESELURUHAN], Throughput (ops / dtk), 31691.803548848162
[TOTAL_GCS_PS_Scavenge], Hitung, 161
[TOTAL_GC_TIME_PS_Scavenge], Waktu (ms), 2433
[TOTAL_GC_TIME _% _ PS_Scavenge], Waktu (%), 0.7710615803434757
[TOTAL_GCS_PS_MarkSweep], Hitung, 0
[TOTAL_GC_TIME_PS_MarkSweep], Waktu (ms), 0
[TOTAL_GC_TIME _% _ PS_MarkSweep], Waktu (%), 0,0
[TOTAL_GCs], Hitung, 161
[TOTAL_GC_TIME], Waktu (ms), 2433
[TOTAL_GC_TIME_%], Waktu (%), 0.7710615803434757
[INSERT], Operasional, 10.000.000
[INSERT], AverageLatency (us), 3114.2427012
[INSERT], MinLatency (kami), 269
[INSERT], MaxLatency (kami), 609279
[INSERT], 95thPercentileLatency (kami), 5007
[INSERT], 99thPercentileLatency (us), 33439
[INSERT], Return = OK, 10000000
Di sini Anda dapat melihat bahwa kecepatan satu aliran adalah sekitar 32 ribu catatan per detik, 4 aliran bekerja, ternyata 128 ribu. Tampaknya tidak ada lagi yang perlu diperas pada pengaturan saat ini dari subsistem disk.
Tentang membaca lebih menarik. Berkat saran rekan-rekannya, dia berhasil mempercepat secara radikal. Membaca dilakukan bukan di 5 aliran, tetapi di 100. Peningkatan ke 200 tidak menghasilkan efek. Juga ditambahkan ke pembangun:
.withLoadBalancingPolicy (TokenAwarePolicy baru (DCAwareRoundRobinPolicy.builder (). build ()))
Akibatnya, jika sebelumnya tes menunjukkan 159 644 ops (5 stream, 4 tables, 100 batch), sekarang:
100 utas, 4 tabel, kumpulan = 1 (satu per satu): 301 969 ops
100 utas, 4 tabel, kumpulan = 10: 447 608 ops
100 utas, 4 tabel, kumpulan = 100: 625 655 ops
Karena hasilnya lebih baik dengan batch, saya menjalankan tes * serupa dengan HB:
 * Karena ketika bekerja di 400 utas, fungsi RandomStringUtils, yang digunakan sebelumnya, memuat CPU sebesar 100%, itu digantikan oleh generator yang lebih cepat.
* Karena ketika bekerja di 400 utas, fungsi RandomStringUtils, yang digunakan sebelumnya, memuat CPU sebesar 100%, itu digantikan oleh generator yang lebih cepat.Dengan demikian, peningkatan jumlah utas saat memuat data memberi sedikit peningkatan kinerja HB.
Sedangkan untuk membaca, berikut adalah hasil dari beberapa opsi. Atas permintaan
0x62ash , perintah flush dieksekusi sebelum membaca, dan beberapa opsi lain juga diberikan untuk perbandingan:
Memstore - membaca dari memori, mis. sebelum dibilas ke disk.
HFile + zip - membaca dari file yang dikompres oleh algoritma GZ.
HFile + upzip - baca dari file tanpa kompresi.
Fitur yang menarik patut diperhatikan - file kecil (lihat bidang "Data", tempat ditulisnya 10 byte) diproses lebih lambat, terutama jika dikompres. Jelas, ini hanya mungkin sampai ukuran tertentu, jelas file 5 GB tidak akan diproses lebih cepat dari 10 MB, tetapi jelas menunjukkan bahwa dalam semua tes ini masih belum ada bidang bajak untuk meneliti berbagai konfigurasi.
Untuk kepentingan, saya mengoreksi kode YCSB untuk bekerja dengan batch HB 100 buah untuk mengukur latensi dan banyak lagi. Di bawah ini adalah hasil karya 4 salinan yang menulis ke meja mereka, masing-masing dengan 100 utas. Ternyata yang berikut ini:
Satu operasi = 100 catatan[KESELURUHAN], RunTime (ms), 1165415
[KESELURUHAN], Throughput (ops / dtk), 858.06343662987
[TOTAL_GCS_PS_Scavenge], Hitung, 798
[TOTAL_GC_TIME_PS_Scavenge], Waktu (ms), 7346
[TOTAL_GC_TIME _% _ PS_Scavenge], Waktu (%), 0.6303334005483026
[TOTAL_GCS_PS_MarkSweep], Hitung, 1
[TOTAL_GC_TIME_PS_MarkSweep], Waktu (ms), 74
[TOTAL_GC_TIME _% _ PS_MarkSweep], Waktu (%), 0,006349669431061038
[TOTAL_GCs], Hitung, 799
[TOTAL_GC_TIME], Waktu (ms), 7420
[TOTAL_GC_TIME_%], Waktu (%), 0,6366830699793635
[INSERT], Operasional, 1.000.000
[INSERT], AverageLatency (us), 115893.891644
[INSERT], MinLatency (kami), 14528
[INSERT], MaxLatency (kami), 1470463
[INSERT], 95thPercentileLatency (us), 248319
[INSERT], 99thPercentileLatency (us), 445951
[INSERT], Return = OK, 1.000.000
20/01/19 13:19:16 INFO client.ConnectionManager $ HConnectionImplementation: Menutup zookeeper sessionid = 0x36f98ad0a4ad8cc
20/01/19 13:19:16 INFO zookeeper.ZooKeeper: Sesi: 0x36f98ad0a4ad8cc ditutup
20/01/19 13:19:16 INFO zookeeper.ClientCnxn: EventThread dimatikan
[KESELURUHAN], RunTime (ms), 1165806
[KESELURUHAN], Throughput (ops / dtk), 857.7756504941646
[TOTAL_GCS_PS_Scavenge], Hitung, 776
[TOTAL_GC_TIME_PS_Scavenge], Waktu (ms), 7517
[TOTAL_GC_TIME _% _ PS_Scavenge], Waktu (%), 0.6447899564764635
[TOTAL_GCS_PS_MarkSweep], Hitung, 1
[TOTAL_GC_TIME_PS_MarkSweep], Waktu (ms), 63
[TOTAL_GC_TIME _% _ PS_MarkSweep], Waktu (%), 0,005403986598113236
[TOTAL_GCs], Hitung, 777
[TOTAL_GC_TIME], Waktu (ms), 7580
[TOTAL_GC_TIME_%], Waktu (%), 0,6501939430745767
[INSERT], Operasional, 1.000.000
[INSERT], AverageLatency (us), 116042.207936
[INSERT], MinLatency (kami), 14056
[INSERT], MaxLatency (kami), 1462271
[INSERT], 95thPercentileLatency (kami), 250239
[INSERT], 99thPercentileLatency (kami), 446719
[INSERT], Return = OK, 1.000.000
20/01/19 13:19:16 INFO client.ConnectionManager $ HConnectionImplementation: Menutup zookeeper sessionid = 0x26f98ad07b6d67e
20/01/19 13:19:16 INFO zookeeper.ZooKeeper: Sesi: 0x26f98ad07b6d67e ditutup
20/01/19 13:19:16 INFO zookeeper.ClientCnxn: EventThread dimatikan
[KESELURUHAN], RunTime (ms), 1165999
[KESELURUHAN], Throughput (ops / dtk), 857.63366863951
[TOTAL_GCS_PS_Scavenge], Hitung, 818
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7557
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6481137633908777
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 79
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.006775305982252128
[TOTAL_GCs], Count, 819
[TOTAL_GC_TIME], Time(ms), 7636
[TOTAL_GC_TIME_%], Time(%), 0.6548890693731299
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116172.212864
[INSERT], MinLatency(us), 7952
[INSERT], MaxLatency(us), 1458175
[INSERT], 95thPercentileLatency(us), 250879
[INSERT], 99thPercentileLatency(us), 446463
[INSERT], Return=OK, 1000000
20/01/19 13:19:17 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x36f98ad0a4ad8cd
20/01/19 13:19:17 INFO zookeeper.ZooKeeper: Session: 0x36f98ad0a4ad8cd closed
20/01/19 13:19:17 INFO zookeeper.ClientCnxn: EventThread shut down
[OVERALL], RunTime(ms), 1166860
[OVERALL], Throughput(ops/sec), 857.000839860823
[TOTAL_GCS_PS_Scavenge], Count, 707
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7239
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6203829079752499
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 67
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0057419056270675145
[TOTAL_GCs], Count, 708
[TOTAL_GC_TIME], Time(ms), 7306
[TOTAL_GC_TIME_%], Time(%), 0.6261248136023173
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116230.849308
[INSERT], MinLatency(us), 7352
[INSERT], MaxLatency(us), 1443839
[INSERT], 95thPercentileLatency(us), 250623
[INSERT], 99thPercentileLatency(us), 447487
[INSERT], Return=OK, 1000000
Ternyata jika CS AverageLatency (kami) memiliki catatan 3114, maka HB AverageLatency (kami) = 1162 (ingat bahwa 1 operasi = 100 catatan dan karenanya harus dibagi).Secara umum, kesimpulan ini diperoleh - dalam kondisi tertentu, ada keuntungan yang signifikan dari HBase. Namun, tidak dapat disangkal bahwa SSD dan penyempurnaan OS yang hati-hati akan mengubah gambar secara radikal. Anda juga perlu memahami bahwa banyak tergantung pada skenario penggunaan, dapat dengan mudah berubah bahwa jika Anda mengambil bukan 4 tabel, tetapi 400 dan bekerja dengan terabyte, keseimbangan kekuatan akan berkembang dengan cara yang sama sekali berbeda. Seperti yang dikatakan orang klasik: praktik adalah kriteria kebenaran. Anda harus mencoba. Pertama, ScyllaDB sekarang masuk akal untuk diperiksa, jadi untuk dilanjutkan ...