Ini adalah bagian kedua dari artikel tentang numba. Yang pertama adalah pengantar sejarah dan manual instruksi numba singkat. Di sini saya menyajikan kode tugas yang sedikit dimodifikasi dari artikel Haskell “ Lebih cepat daripada C ++; lebih lambat dari PHP ”(membandingkan kinerja implementasi satu algoritma dalam berbagai bahasa / kompiler) dengan benchmark, grafik, dan penjelasan yang lebih rinci. Saya akan segera mengatakan bahwa saya melihat artikel Oh, C / C ini lambat ++ dan, kemungkinan besar, jika Anda membuat perubahan pada kode C, gambar akan berubah sedikit, tetapi bahkan dalam kasus ini, python dapat melebihi kecepatan C bahkan dalam versi ini itu sendiri luar biasa.

Mengganti daftar Python dengan array numpy (dan, karenanya, v0[:] dengan v0.copy() , karena dalam numpy a[:] mengembalikan view alih-alih menyalin).
Untuk memahami sifat perilaku kinerja, saya melakukan "pemindaian" dengan jumlah elemen dalam array.
Dalam kode Python, saya mengganti time.monotonic dengan time.perf_counter , karena lebih akurat (1us berbanding 1ms untuk monotonik).
Karena numba menggunakan kompilasi jit, kompilasi ini harus suatu hari nanti akan terjadi. Secara default, ini terjadi ketika fungsi pertama kali dipanggil dan pasti mempengaruhi hasil tolok ukur (meskipun jika Anda mengambil waktu dari tiga peluncuran, Anda mungkin tidak memperhatikan ini), dan itu juga dirasakan dalam penggunaan praktis. Ada beberapa cara untuk menghadapi fenomena ini:
1) hasil kompilasi cache ke disk:
@njit(cache=True) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:
maka kompilasi akan terjadi pada panggilan pertama program, dan pada panggilan berikutnya akan ditarik dari disk.
2) menunjukkan tanda tangan
Kompilasi akan terjadi pada saat python mem-parsing definisi fungsi, dan start pertama sudah cepat.
String asli ditransmisikan (lebih tepatnya, byte), tetapi dukungan untuk string telah ditambahkan baru-baru ini, sehingga tanda tangannya cukup mengerikan (lihat di bawah). Tanda tangan biasanya ditulis lebih sederhana:
@njit(nb.int64(nb.uint8[:], nb.uint8[:])) def lev_dist(s1, s2):
tetapi kemudian Anda harus mengkonversi byte ke array numpy terlebih dahulu:
s1_py = [int(x) for x in b"a" * 15000] s1 = np.array(s1_py, dtype=np.uint8)
atau
s1 = np.full(15000, ord('a'), dtype=np.uint8)
Dan Anda dapat meninggalkan byte apa adanya dan tentukan tanda tangan di formulir ini:
@njit(nb.int64(nb.bytes(nb.uint8, nb.1d, nb.C), nb.bytes(nb.uint8, nb.1d, nb.C))) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:
Kecepatan eksekusi untuk byte dan array numpy dari uint8 (dalam hal ini) adalah sama.
3) cache pemanasan awal
s1 = b"a" * 15
Kemudian kompilasi akan terjadi pada panggilan pertama, dan yang kedua sudah cepat.
Kode C (dentang -O3 -march = asli) #include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h> static long lev_dist (const char *s1, unsigned long m, const char *s2, unsigned long n) { // unsigned long m, n; unsigned long i, j; long *v0, *v1; long ret, *temp; /* Edge cases. */ if (m == 0) { return n; } else if (n == 0) { return m; } v0 = malloc (sizeof (long) * (n + 1)); v1 = malloc (sizeof (long) * (n + 1)); if (v0 == NULL || v1 == NULL) { fprintf (stderr, "failed to allocate memory\n"); exit (-1); } for (i = 0; i <= n; ++i) { v0[i] = i; } memcpy (v1, v0, sizeof(long) * (n + 1)); for (i = 0; i < m; ++i) { v1[0] = i + 1; for (j = 0; j < n; ++j) { const long subst_cost = (s1[i] == s2[j]) ? v0[j] : (v0[j] + 1); const long del_cost = v0[j + 1] + 1; const long ins_cost = v1[j] + 1; #if !defined(__GNUC__) || defined(__llvm__) if (subst_cost < del_cost) { v1[j + 1] = subst_cost; } else { v1[j + 1] = del_cost; } #else v1[j + 1] = (subst_cost < del_cost) ? subst_cost : del_cost; #endif if (ins_cost < v1[j + 1]) { v1[j + 1] = ins_cost; } } temp = v0; v0 = v1; v1 = temp; } ret = v0[n]; free (v0); free (v1); return ret; } int main () { char s1[25001], s2[25001], s3[25001]; int lengths[] = {1000, 2000, 5000, 10000, 15000, 20000, 25000}; FILE *fout; fopen_s(&fout, "c.txt", "w"); for(int j = 0; j < sizeof(lengths)/sizeof(lengths[0]); j++){ int len = lengths[j]; int i; clock_t start_time, exec_time; for (i = 0; i < len; ++i) { s1[i] = 'a'; s2[i] = 'a'; s3[i] = 'b'; } s1[len] = s2[len] = s3[len] = '\0'; start_time = clock (); printf ("%ld\n", lev_dist (s1, len, s2, len)); printf ("%ld\n", lev_dist (s1, len, s3, len)); exec_time = clock () - start_time; fprintf(fout, "%d %.6f\n", len, ((double) exec_time) / CLOCKS_PER_SEC); fprintf (stderr, "Finished in %.3fs\n", ((double) exec_time) / CLOCKS_PER_SEC); } return 0; }
Perbandingan dilakukan di bawah windows (windows 10 x64, python 3.7.3, numba 0.45.1, clang 9.0.0, intel m5-6y54 skylake): dan di linux (debian 4.9.30, python 3.7.4, numba 0.45.1, dentang 9.0.0).
X adalah ukuran array, y adalah waktu dalam detik.
Skala linear Windows:
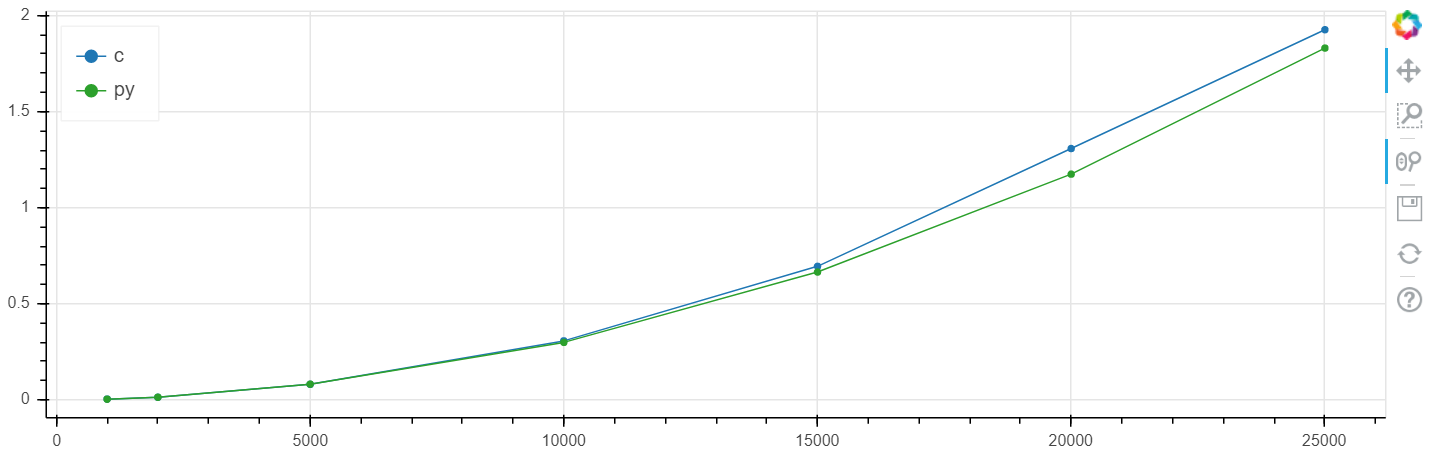
Skala logaritmik Windows:
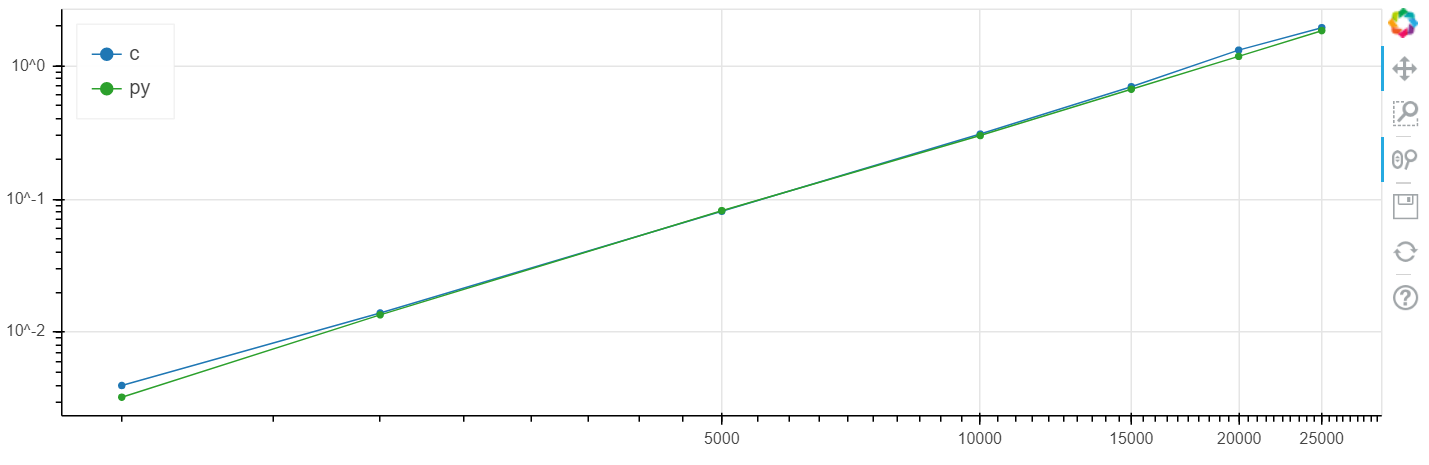
Skala linear Linux:

Skala logaritmik Linux
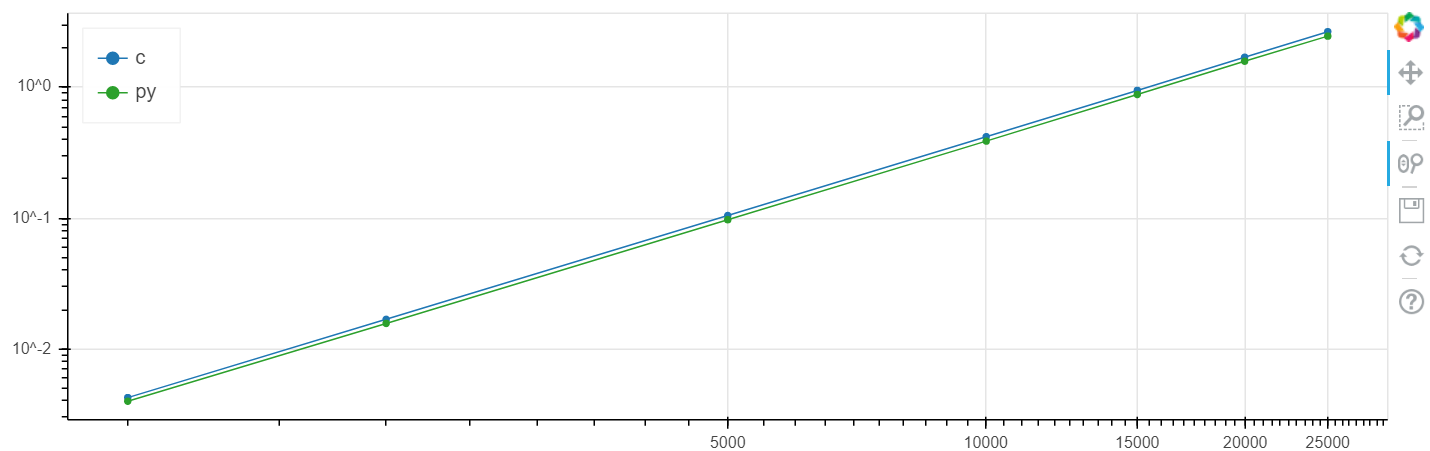
Dalam masalah ini, peningkatan kecepatan diperoleh dibandingkan dengan dentang pada tingkat beberapa persen, yang umumnya lebih tinggi daripada kesalahan statistik.
Saya berulang kali membuat perbandingan ini pada tugas-tugas yang berbeda dan, sebagai suatu peraturan, jika numba dapat mempercepat sesuatu, ia mempercepatnya ke kecepatan dalam margin kesalahan yang bertepatan dengan kecepatan C (tanpa menggunakan insert assembler).
Saya ulangi bahwa jika Anda membuat perubahan pada kode dalam C dari Oh, situasi C / C ++ lambat ini dapat berubah.
Saya akan senang mendengar pertanyaan dan saran di komentar.
PS Saat menentukan tanda tangan array, lebih baik untuk secara eksplisit mengatur cara bolak-balik baris / kolom:
sehingga numba tidak memikirkan 'C' (si) ini atau 'A' (si / fortran auto-recognition) - untuk beberapa alasan ini memengaruhi kinerja bahkan untuk array satu dimensi, untuk ini terdapat sintaksis yang asli: uint8[:,:] this ' A '(deteksi otomatis), nb.uint8[:, ::1] adalah' C '(si), np.uint8[::1, :] adalah' F '(fortran).
@njit(nb.int64(nb.uint8[::1], nb.uint8[::1])) def lev_dist(s1, s2):