Untuk sepenuhnya menguasai Kubernetes, Anda perlu mengetahui berbagai cara untuk skala sumber daya cluster: menurut
pengembang sistem , ini adalah salah satu tugas utama Kubernetes. Kami telah menyiapkan tinjauan tingkat tinggi tentang mekanisme penskalaan otomatis dan pengubahan skala klaster dan horizontal, serta rekomendasi tentang cara menggunakannya secara efektif.
Artikel oleh
Kubernetes Autoscaling 101: Cluster Autoscaler, Horizontal Autoscaler, dan Vertical Pod Autoscaler diterjemahkan oleh tim yang menerapkan
autoscaling di
Kubernet aaS dari Mail.ru.Mengapa penting untuk berpikir tentang penskalaan
Kubernetes adalah alat manajemen sumber daya dan orkestrasi. Tentu saja, menyenangkan untuk bermain-main dengan fungsi penyebaran, pemantauan, dan pengelolaan pod yang keren (modul pod adalah sekelompok kontainer yang diluncurkan sebagai respons terhadap permintaan).
Namun, Anda harus memikirkan masalah-masalah tersebut:
- Bagaimana skala modul dan aplikasi?
- Bagaimana menjaga agar wadah tetap operasional dan efisien?
- Bagaimana menanggapi perubahan kode dan beban kerja yang konstan dari pengguna?
Mengkonfigurasi kluster Kubernetes untuk menyeimbangkan sumber daya dan kinerja bisa jadi sulit, membutuhkan pengetahuan ahli tentang internal Kubernetes. Beban kerja pada aplikasi atau layanan Anda dapat berfluktuasi sepanjang hari atau bahkan satu jam, sehingga penyeimbangan paling baik disajikan sebagai proses berkelanjutan.
Level skala otomatis Kubernetes
Autoscaling yang efektif membutuhkan koordinasi antara dua level:
- Level pod termasuk horisontal (Horizontal Pod Autoscaler, HPA) dan penskalaan otomatis vertikal (Vertical Pod Autoscaler, VPA). Ini adalah penskalaan sumber daya yang tersedia untuk wadah Anda.
- Level cluster, yang dikendalikan oleh Autoscaler Cluster, CA, menambah atau mengurangi jumlah node dalam cluster.
Modul Skala Otomatis Horisontal (HPA)
Seperti namanya, HPA menskala jumlah replika pod. Sebagai pemicu untuk mengubah jumlah replika, kebanyakan pengembang menggunakan CPU dan memori. Namun, Anda dapat mengatur skala sistem berdasarkan
metrik khusus ,
kombinasinya, atau bahkan
metrik eksternal .
Alur kerja HPA tingkat tinggi:
- HPA terus menerus memeriksa nilai metrik yang ditentukan selama instalasi dengan interval default 30 detik.
- HPA mencoba menambah jumlah modul jika ambang yang ditentukan tercapai.
- HPA memperbarui jumlah replika dalam pengontrol penyebaran / replikasi.
- Kontroler penyebaran / replikasi kemudian menyebarkan semua modul tambahan yang diperlukan.
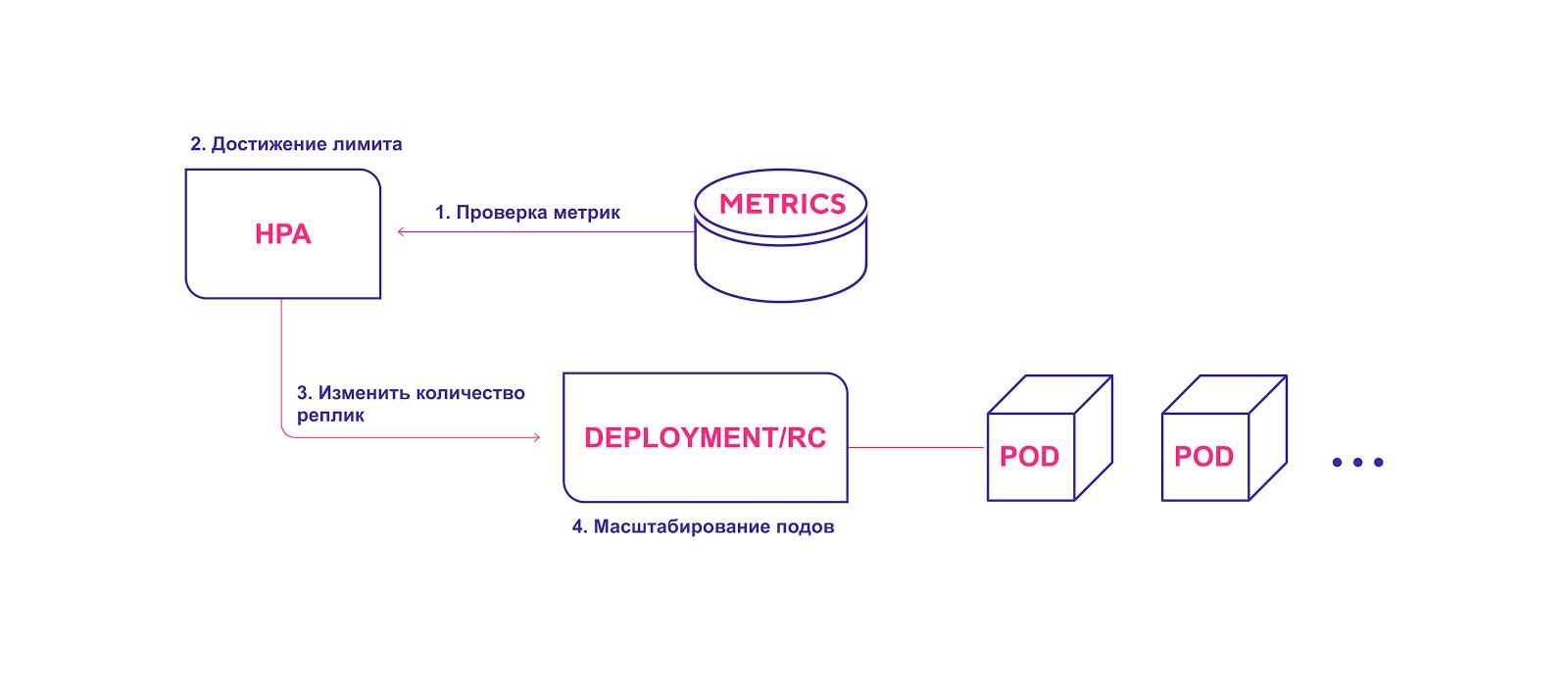 HPA meluncurkan proses penerapan modul saat ambang metrik tercapai
HPA meluncurkan proses penerapan modul saat ambang metrik tercapaiSaat menggunakan HPA, pertimbangkan hal berikut:
- Interval validasi HPA default adalah 30 detik. Ini diatur dengan bendera periode-pod-autoscaler-sinkronisasi-periode di manajer kontroler.
- Kesalahan relatif default adalah 10%.
- Setelah peningkatan terakhir dalam jumlah modul, HPA berharap metrik akan stabil dalam tiga menit. Interval ini diatur oleh flag delay-horisontal-pod-autoscaler-kelas-atas .
- Setelah pengurangan terakhir dalam jumlah modul, HPA berharap untuk stabil selama lima menit. Interval ini diatur oleh flag -delay-pod-autoscaler-downscale-delay .
- HPA bekerja paling baik dengan objek penyebaran, bukan pengontrol replikasi. Autoscaling horizontal tidak kompatibel dengan pembaruan bergulir, yang secara langsung memanipulasi pengontrol replikasi. Saat menggunakan, jumlah replika tergantung langsung pada objek penyebaran.
Autoscaling vertikal pod
Skala Auto Vertikal (VPA) mengalokasikan lebih banyak (atau kurang) waktu prosesor atau memori untuk pod yang ada. Ini cocok untuk polong dengan atau tanpa status negara, tetapi terutama ditujukan untuk layanan negara. Namun, Anda dapat menerapkan VPA untuk modul stateless jika Anda perlu menyesuaikan jumlah sumber daya yang dialokasikan secara otomatis.
VPA juga merespons peristiwa OOM (kehabisan memori, kehabisan memori). Untuk mengubah waktu prosesor dan ukuran memori, restart pod diperlukan. Saat memulai kembali, VPA menghormati
anggaran distribusi polong (PDB ) untuk menjamin jumlah minimum modul.
Anda dapat mengatur jumlah sumber daya minimum dan maksimum untuk setiap modul. Jadi, Anda dapat membatasi jumlah maksimum memori yang dialokasikan hingga batas 8 GB. Ini berguna jika node saat ini tidak dapat mengalokasikan lebih dari 8 GB memori per kontainer. Spesifikasi terperinci dan mekanisme operasi dijelaskan dalam
wiki VPA resmi .
Selain itu, VPA memiliki fungsi rekomendasi yang menarik (VPA Recommender). Ini melacak pemanfaatan sumber daya dan peristiwa OOM dari semua modul untuk menawarkan nilai-nilai baru dari memori dan waktu prosesor berdasarkan algoritma cerdas dengan memperhitungkan metrik historis akun. Ada juga API yang mengambil deskriptor pod dan mengembalikan nilai sumber daya yang diusulkan.
Perlu dicatat bahwa VPA Recommender tidak memonitor "batas" sumber daya. Ini dapat menyebabkan modul memonopoli sumber daya dalam node. Lebih baik untuk menetapkan nilai batas pada tingkat namespace untuk menghindari pemborosan besar memori atau waktu prosesor.
Skema VPA tingkat tinggi:
- VPA terus-menerus memeriksa nilai metrik yang ditentukan selama instalasi dengan interval default 10 detik.
- Jika ambang yang ditentukan tercapai, VPA berupaya mengubah jumlah sumber daya yang dialokasikan.
- VPA memperbarui jumlah sumber daya dalam pengontrol penyebaran / replikasi.
- Saat Anda me-restart modul, semua sumber daya baru diterapkan ke instance yang dibuat.
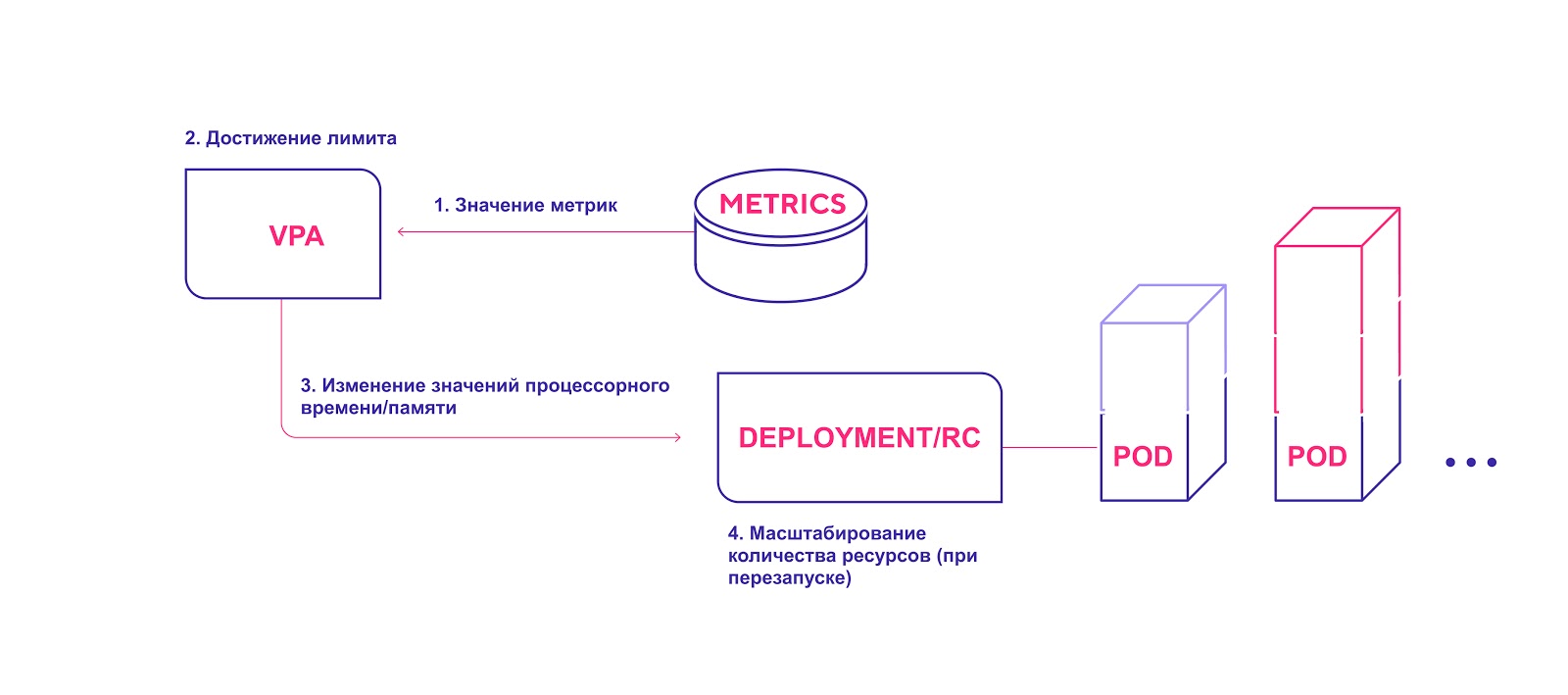 VPA menambahkan jumlah sumber daya yang diperlukan
VPA menambahkan jumlah sumber daya yang diperlukanPertimbangkan hal-hal berikut saat menggunakan VPA:
- Penskalaan membutuhkan restart wajib pod. Ini diperlukan untuk menghindari operasi yang tidak stabil setelah melakukan perubahan. Untuk keandalan, modul-modul dihidupkan ulang dan didistribusikan di antara node berdasarkan sumber daya yang baru dialokasikan.
- VPA dan HPA belum kompatibel satu sama lain dan tidak dapat berfungsi pada pod yang sama. Jika Anda menggunakan kedua mekanisme penskalaan dalam kluster yang sama, pastikan bahwa pengaturan tidak akan memungkinkan mereka diaktifkan pada objek yang sama.
- VPA mengkonfigurasi permintaan kontainer untuk sumber daya hanya berdasarkan penggunaan masa lalu dan saat ini. Itu tidak menetapkan batas pada penggunaan sumber daya. Mungkin ada masalah dengan pengoperasian aplikasi yang salah yang akan mulai mengambil semakin banyak sumber daya, ini akan menyebabkan Kubernet mematikan pod ini.
- VPA masih dalam tahap awal pengembangan. Bersiaplah bahwa dalam waktu dekat sistem dapat mengalami beberapa perubahan. Anda dapat membaca tentang batasan yang diketahui dan rencana pengembangan . Jadi, dalam rencana untuk mengimplementasikan kerja bersama VPA dan HPA, serta penyebaran modul bersama dengan kebijakan penskalaan otomatis vertikal untuk mereka (misalnya, label khusus 'memerlukan VPA').
Kubernetes Cluster Auto-Scaling
Cluster Autoscaler (CA) mengubah jumlah node berdasarkan jumlah pod yang menunggu. Sistem secara berkala memeriksa modul yang tertunda - dan meningkatkan ukuran kluster jika diperlukan lebih banyak sumber daya dan jika klaster tidak melebihi batas yang ditetapkan. CA berinteraksi dengan penyedia layanan cloud, meminta node tambahan darinya, atau membebaskan yang idle. Versi CA yang tersedia untuk umum diperkenalkan di Kubernetes 1.8.
Skema operasi tingkat tinggi CA:
- CA memeriksa modul dalam keadaan siaga dengan interval default 10 detik.
- Jika satu atau beberapa modul dalam keadaan siaga karena sumber daya yang tersedia di gugus tidak mencukupi untuk distribusinya, ia mencoba menyiapkan satu atau beberapa node tambahan.
- Ketika penyedia layanan cloud mengalokasikan node yang diperlukan, ia bergabung dengan cluster dan siap untuk melayani modul pod.
- Penjadwal Kubernetes mendistribusikan modul yang tertunda ke host baru. Jika setelah ini beberapa modul masih tetap dalam keadaan siaga, proses berulang dan node baru ditambahkan ke cluster.
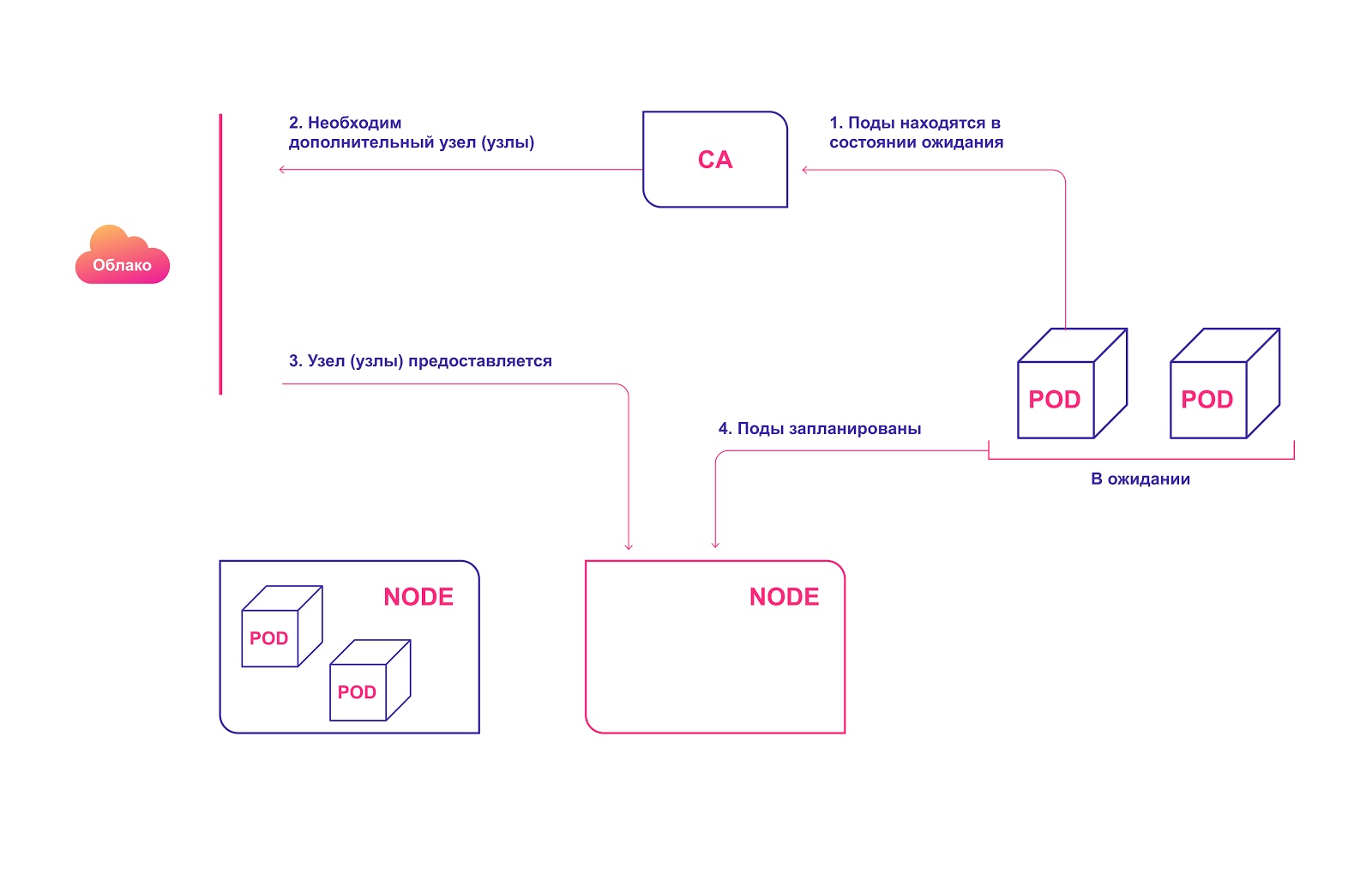 Alokasi node cluster secara otomatis di cloud
Alokasi node cluster secara otomatis di cloudPertimbangkan hal berikut saat menggunakan CA:
- CA memastikan bahwa semua modul di kluster memiliki tempat untuk dijalankan, terlepas dari beban prosesor. Selain itu, ia mencoba memastikan bahwa tidak ada node yang tidak perlu di cluster.
- CA mendaftarkan kebutuhan untuk penskalaan setelah sekitar 30 detik.
- Setelah node menjadi tidak perlu, CA secara default menunggu 10 menit sebelum mengubah skala sistem.
- Dalam sistem autoscale ada konsep ekspander. Ini adalah strategi yang berbeda untuk memilih sekelompok node yang akan ditambahkan node baru.
- Secara bertanggung jawab gunakan opsi cluster-autoscaler.kubernetes.io/safe-to-evict (true) . Jika Anda menginstal banyak pod, atau jika banyak dari mereka tersebar di semua node, Anda akan sangat kehilangan kemampuan untuk memperkecil ukuran cluster.
- Gunakan PodDisruptBudgets untuk mencegah penghapusan pod, karena bagian mana dari aplikasi Anda yang bisa gagal total.
Bagaimana sistem autoscale Kubernet berinteraksi
Untuk keselarasan sempurna, penskalaan otomatis harus diterapkan baik pada level pod (HPA / VPA) dan pada level cluster. Mereka relatif hanya berinteraksi satu sama lain:
- HPA atau VPA memperbarui replika pod atau sumber daya yang dialokasikan untuk pod yang ada.
- Jika tidak ada cukup node untuk penskalaan yang direncanakan, CA akan memperhatikan keberadaan pod dalam keadaan siaga.
- CA mengalokasikan node baru.
- Modul didistribusikan ke node baru.
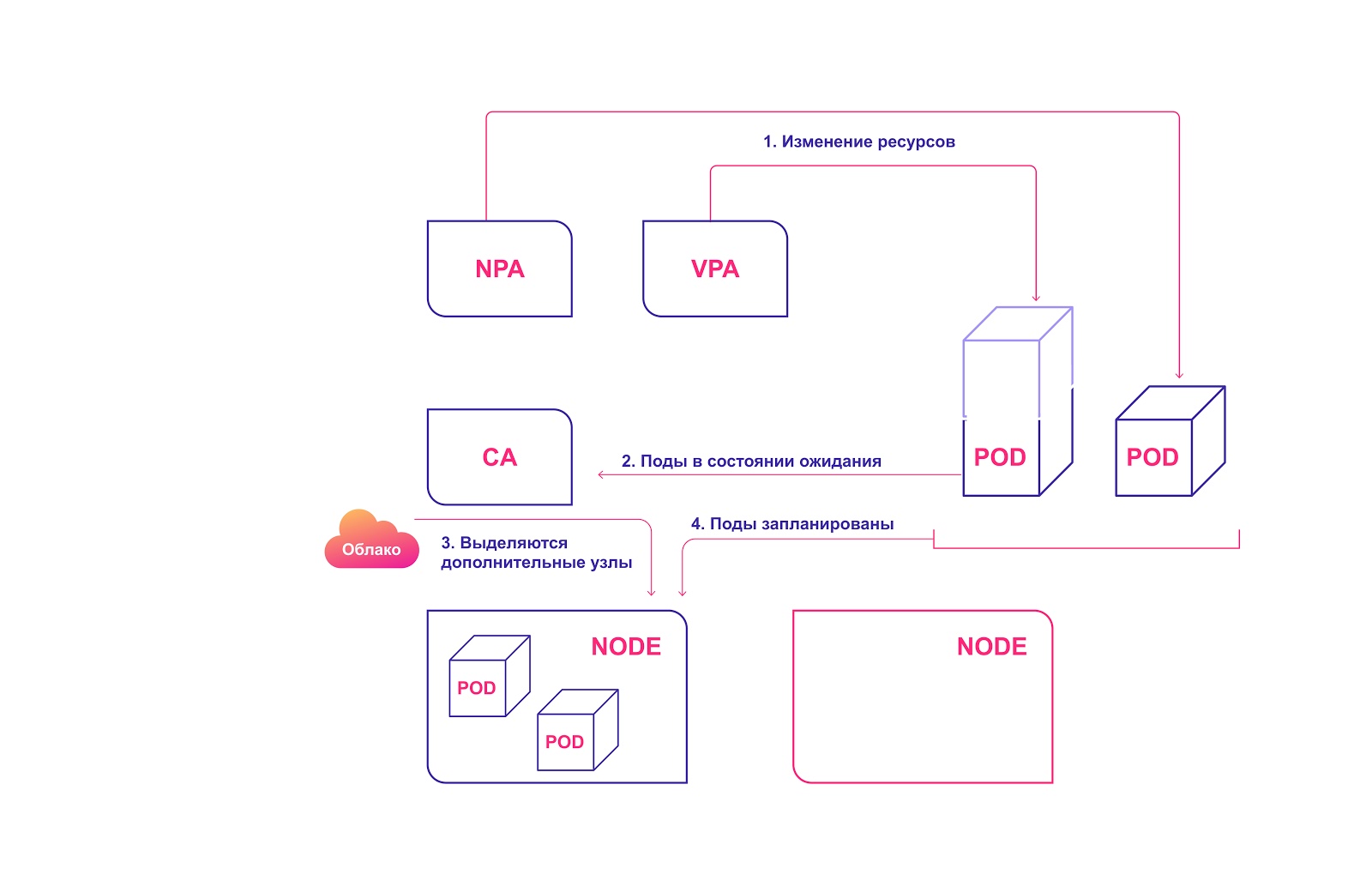 Sistem penskalaan kolaboratif Kubernetes
Sistem penskalaan kolaboratif KubernetesKesalahan autoscaling Kubernetes yang umum
Ada beberapa masalah khas yang dihadapi pengembang ketika mencoba menerapkan autoscaling.
HPA dan VPA bergantung pada metrik dan beberapa data historis. Jika sumber daya tidak memadai dialokasikan, modul akan diciutkan dan tidak akan dapat menghasilkan metrik. Dalam hal ini, autoscaling tidak akan pernah terjadi.
Operasi penskalaan itu sendiri sensitif terhadap waktu. Kami ingin modul dan klaster untuk menskala dengan cepat - sebelum pengguna melihat adanya masalah atau kegagalan. Oleh karena itu, waktu penskalaan rata-rata dari pod dan cluster harus diperhitungkan.
Skenario ideal - 4 menit:
- 30 detik Pembaruan metrik target: 30-60 detik.
- 30 detik HPA memeriksa nilai metrik: 30 detik.
- Kurang dari 2 detik. Modul pod dibuat dan masuk ke kondisi siaga: 1 detik.
- Kurang dari 2 detik. CA melihat modul yang tertunda dan mengirim panggilan untuk menyiapkan node: 1 detik.
- 3 menit Penyedia cloud mengalokasikan node. K8 menunggu hingga siap: hingga 10 menit (tergantung pada beberapa faktor).
Skenario terburuk (lebih realistis) - 12 menit:
- 30 detik Pembaruan metrik target.
- 30 detik HPA memvalidasi nilai metrik.
- Kurang dari 2 detik. Modul pod dibuat dan masuk ke kondisi siaga.
- Kurang dari 2 detik. CA melihat modul yang tertunda dan mengirim panggilan untuk menyiapkan node.
- 10 menit Penyedia cloud mengalokasikan node. K8 menunggu sampai mereka siap. Waktu tunggu tergantung pada beberapa faktor, seperti keterlambatan pemasok, keterlambatan OS, pekerjaan alat bantu.
Jangan bingung mekanisme penskalaan penyedia cloud dengan CA kami. Yang terakhir bekerja di dalam kluster Kubernetes, sementara mekanisme penyedia cloud bekerja berdasarkan alokasi node. Dia tidak tahu apa yang terjadi dengan pod atau aplikasi Anda. Sistem ini bekerja secara paralel.
Bagaimana mengelola penskalaan di Kubernetes
- Kubernetes adalah alat manajemen sumber daya dan orkestrasi. Operasi kluster dan operasi manajemen sumber daya adalah tonggak penting dalam pengembangan Kubernetes.
- Pelajari logika skalabilitas pod untuk HPA dan VPA.
- CA harus digunakan hanya jika Anda memahami kebutuhan pod dan wadah Anda dengan baik.
- Untuk konfigurasi kluster yang optimal, Anda perlu memahami bagaimana berbagai sistem penskalaan bekerja bersama.
- Saat mengevaluasi waktu penskalaan, ingatlah skenario terburuk dan terbaik.