Jika Anda menulis
kueri SQL tanpa menganalisis algoritme yang harus mereka implementasikan, ini biasanya tidak menghasilkan sesuatu yang baik dalam hal kinerja.
Permintaan
seperti itu
seperti "memakan" waktu prosesor dan secara aktif membaca data hampir tiba-tiba. Selain itu, ini belum tentu semacam pertanyaan kompleks, sebaliknya - semakin sederhana ditulis, semakin besar peluang mendapatkan masalah. Dan jika operator BERGABUNG berperan ...
Dengan sendirinya, bergabung dengan tabel tidak berbahaya atau berguna - itu hanya alat, tetapi Anda harus dapat menggunakannya.
Pengelompokan Pengawasan
Pertama, ambil contoh yang sangat sederhana.
Ada "kamus" dari 100 entri (misalnya, ini adalah wilayah Federasi Rusia):
CREATE TABLE tbl_dict AS SELECT generate_series(0, 100) k; ALTER TABLE tbl_dict ADD PRIMARY KEY(k);
... dan terlampir padanya adalah tabel "fakta" terkait per 100 ribu entri:
CREATE TABLE tbl_fact AS SELECT (random() * 100)::integer k , (random() * 1000)::integer v FROM generate_series(1, 100000); CREATE INDEX ON tbl_fact(k);
Sekarang mari kita coba menghitung jumlah nilai untuk setiap "wilayah".
Seperti yang didengar, ada tertulis
SELECT dk , sum(fv) FROM tbl_fact f NATURAL JOIN tbl_dict d GROUP BY 1;
Membaca data itu sendiri hanya membutuhkan waktu 18%, sisanya sedang memproses:
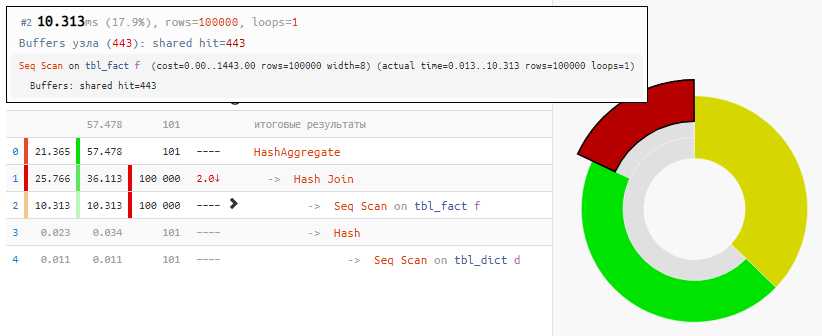 [lihat menjelaskan.tensor.ru]
[lihat menjelaskan.tensor.ru]Dan semua karena Hash Join dan Hash Aggregate harus memproses 100 ribu catatan masing-masing karena keinginan kami untuk
mengelompokkan berdasarkan bidang tabel tertaut .
Kami menggunakan kecerdikan
Namun nilai bidang ini sama dengan nilai bidang dalam tabel gabungan! Artinya, tidak ada yang mengganggu kita untuk
mengelompokkan "fakta" terlebih dahulu, dan baru kemudian membuat koneksi :
SELECT dk , f.sum FROM ( SELECT k , sum(v) FROM tbl_fact GROUP BY 1 ) f NATURAL JOIN tbl_dict d;
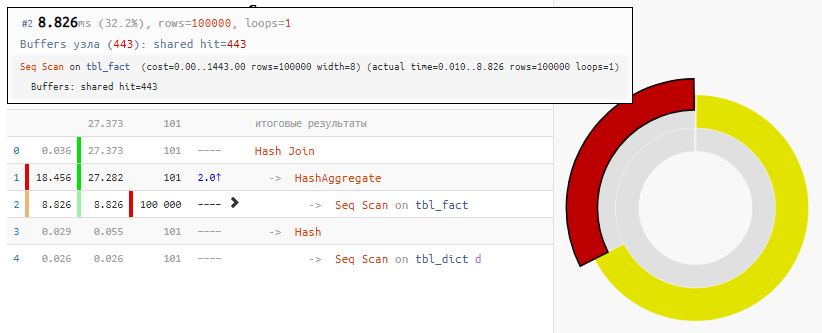 [lihat menjelaskan.tensor.ru]
[lihat menjelaskan.tensor.ru]Tentu saja, metode ini tidak universal, tetapi untuk kasus kami "GABUNG biasa"
, penambahan waktu adalah 2 kali dengan modifikasi minimal dari permintaan - hanya karena "Hash" Hash Join, yang menerima hanya 100 entri, bukan 100K entri.
Kondisi yang Tidak Sama
Sekarang mari kita rumit tugasnya: kita memiliki 3 tabel yang terhubung oleh satu pengidentifikasi - tabel utama dan dua tambahan dengan beberapa data aplikasi, yang dengannya kita akan memfilter.
Pernyataan kecil tapi sangat penting: meskipun berdasarkan pengetahuan "terapan" dari tugas target, kita sudah tahu bahwa kondisi akan terpenuhi
pada tabel pertama - hampir selalu (untuk kepastian - 3: 4), dan
pada yang kedua - sangat jarang (1: 8 )
Kami ingin memilih dari tabel bantu utama dan pertama
100 rekaman pertama oleh id dengan nilai pengidentifikasi genap yang
kondisi semua tabel terpenuhi . Semua catatan dalam tabel, mari kita kembali pada 100K.
Generator skrip CREATE TABLE base( id integer PRIMARY KEY , val integer ); INSERT INTO base SELECT id , (random() * 1000)::integer FROM generate_series(1, 100000) id; CREATE TABLE ext1( id integer PRIMARY KEY , conda boolean ); INSERT INTO ext1 SELECT id , (random() * 4)::integer <> 0
Seperti yang didengar, ada tertulis
SELECT base.* , ext1.* FROM base NATURAL JOIN ext1 NATURAL JOIN ext2 WHERE id % 2 = 0 AND conda AND condb ORDER BY base.id LIMIT 100;
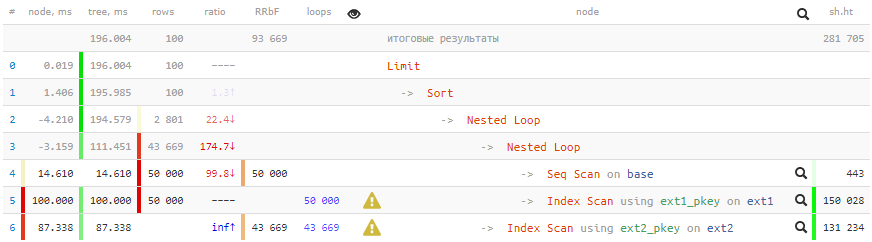 [lihat menjelaskan.tensor.ru]
[lihat menjelaskan.tensor.ru]Waktu negatif dalam hal iniBegitu banyak siklus yang telah melalui beberapa node sehingga kesalahan pembulatan dari beberapa bahkan telah didorong menjadi minus. Hampir artefak serupa dalam rencana saya akan berbicara di
PGConf.Russia .
200ms dan lebih banyak data 2GB dipompa - tidak terlalu bagus untuk 100 catatan!
Kami menggunakan kecerdikan
Kami menggunakan pendekatan berikut untuk mencapai akselerasi:
- Untuk memulainya, kami memahami bahwa masuk akal bagi kami untuk memeriksa semua kondisi untuk tabel tertaut hanya ketika kondisi untuk tabel utama dipenuhi (bahkan untuk id).
- Outputnya harus diurutkan berdasarkan base.id, dan untuk ini, kunci utama tabel ini sangat cocok untuk kita!
- Kami tidak memerlukan data dari ext2, dan hanya digunakan untuk memverifikasi kondisi. Ini berarti bahwa semua pekerjaan dengan tabel ini dapat dihapus dengan aman dari GABUNG ke bagian WHERE . Dan gunakan EXIS untuk memeriksa, jika tidak, bagaimana jika tidak ada catatan seperti itu sama sekali?
- Kita perlu mengambil setidaknya beberapa data dari ext1 hanya jika sisa pemeriksaan di pangkalan dan ext2 berhasil diteruskan . Artinya, koneksi dengan ext1 harus pergi setelah semua tindakan dengan basis / ext2, yang dapat dicapai menggunakan LATERAL.
- Sehingga perencana kueri tidak mencoba mengubah verifikasi bersarang pada ext2 menjadi BERGABUNG, subquery "sembunyikan di bawah KASUS" .
SELECT base.* , ext1.* FROM base , LATERAL(
 [lihat menjelaskan.tensor.ru]
[lihat menjelaskan.tensor.ru]Permintaan, tentu saja, menjadi lebih rumit, tetapi
memenangkan 13 kali dalam waktu dan 350 dalam "kerakusan" tidak sia-sia!
Biarkan saya mengingatkan Anda lagi bahwa tidak semua metode digunakan dan tidak selalu, tetapi mengetahui tidak akan berlebihan.Ini juga akan menarik: