Ada kalanya Anda perlu membatasi akses pengguna ke beberapa data dalam kubus. Tampaknya tidak ada yang rumit: instal filter garis dalam peran dan Anda selesai, tetapi ada satu masalah - filter memotong data dalam tabel dan ternyata Anda dapat melihat kecepatan hanya dengan jalur yang tersedia, dan kami membutuhkan semua kecepatan, tetapi detailnya hanya tersedia untuk beberapa dari mereka.
Misalnya, pengguna harus melihat pergantian untuk semua produk, dengan kemungkinan perincian lengkap tentang mereka, tetapi pada saat yang sama, pelanggan tidak boleh menampilkan semua, tetapi hanya beberapa, atau semua pelanggan, tetapi dengan data yang sebagian tersembunyi di beberapa atribut (bidang).
Untuk mencegah pengguna melihat pergantian oleh pelanggan, Anda bisa mengalahkan ini melalui rumus dalam ukuran dan menampilkan nilai kosong jika pengguna mencoba untuk melihat pergantian klien tertentu, salah satu opsi ini dijelaskan di
sini . Namun, ini bukan masalahnya. Ketika beberapa lusin mengukur, lalu tulis formula di masing-masing ... dan jika Anda lupa? Tapi Anda pasti akan melupakannya suatu hari nanti ... Dan jika pengguna membutuhkan data dari kartu klien tertentu, maka tidak ada yang akan mencegahnya melihat ini tanpa memilih ukuran penyaringan. Apa yang harus dilakukan
Kami perlu mencapai tampilan ini:
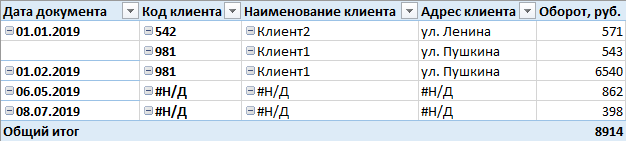
Seluruh prinsip yang memungkinkan Anda untuk mendapatkan hasil yang serupa didasarkan pada sedikit trik, dan itu terdiri dari menambahkan baris sintetis ke tabel (klien, dalam hal ini) sehingga catatan tentang entitas yang sama digandakan setidaknya satu kali - yang pertama akan berisi informasi lengkap, dan yang kedua di sebagian besar kolom diisi dengan potongan tulisan
# N / A , tetapi pengidentifikasi sama untuk kedua catatan. Selanjutnya, dengan bantuan filter dalam peran dan kolom khusus yang digunakan untuk menyaring, kami membiarkan garis-garis tertentu tersedia bagi pengguna - baik garis dengan bidang yang diisi penuh atau dengan stub. Dan sejak itu Karena kubus memiliki fitur pengulangan "collapsing" data dan tidak ada atribut lain yang memberikan nilai unik yang dapat diakses oleh pengguna, maka dalam tabel yang dihasilkan semua klien dengan kode
# N / A akan berubah menjadi satu baris. Saya pikir pada tahap ini semuanya sudah sangat jelas, Anda tidak bisa lagi membaca. Hasilnya dalam judul artikel.
Tetapi jika seseorang membutuhkan detail - saya memilikinya.
Model tabular hingga versi 1400 (termasuk SQL 2017) tidak memungkinkan membuat hubungan banyak ke banyak, tetapi dalam kasus duplikat, kita membutuhkan hubungan seperti itu, jadi kami akan membuatnya melalui tabel perantara yang hanya berisi satu kolom dengan pengidentifikasi pelanggan yang unik. Tabel ini awalnya tidak bisa dimampatkan sejak itu hanya berisi nilai unik, sehingga Anda dapat membuatnya dihitung, karena dalam hal ini kami tidak akan mendapatkan apa pun jika kami mengisinya melalui t-sql (ingat prinsip pemrosesan dan urutan kompresi tabel?). Hanya karena kemampuan mesin untuk mengompresi data duplikat, jumlah data dalam kubus akan sedikit meningkat, dan karena penyaringan melalui peran, sesi pengguna memiliki serangkaian catatan yang berkurang, mis. jumlah akhir catatan setelah memfilter set akan tetap seperti tanpa duplikat. Oleh karena itu, jangan khawatir, bahkan jika tabel awalnya cukup besar, menambahkan duplikat tidak akan mempengaruhi kinerja dan volume secara signifikan (tentu saja, kasus berbeda, tetapi kebanyakan dari mereka semuanya hanya akan seperti itu).
Gambar berikut menunjukkan model kubus dan isi tabel:
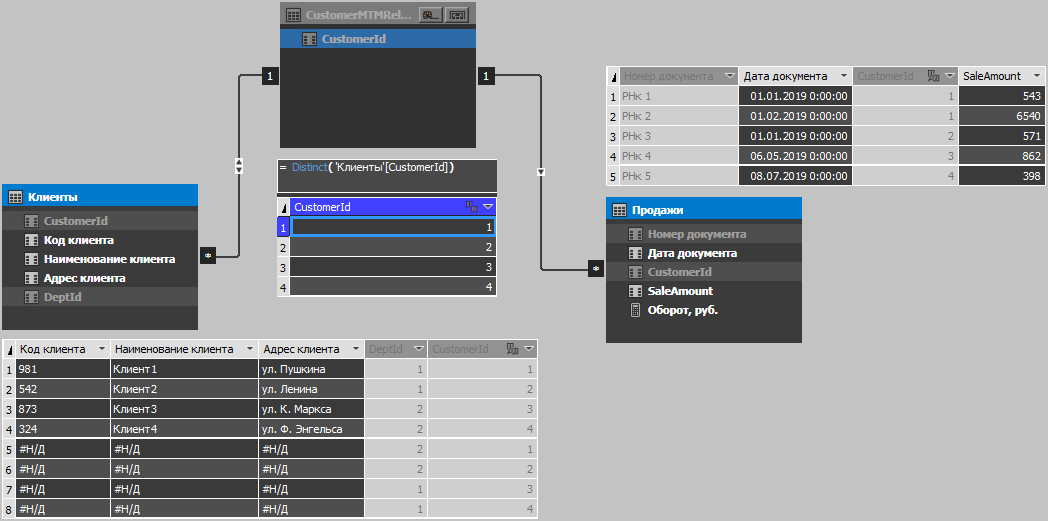
Misalnya, tambahkan filter sederhana:

Itu saja.
Saya ingin memperingatkan tentang satu fitur menggunakan pendekatan ini. Pengguna yang adalah administrator di server SSAS, secara default, masuk ke kubus melewati semua jenis peran, bahkan jika nama mereka ditentukan dalam peran ini. Ini mengarah pada fakta bahwa filter peran tidak berfungsi dan di bawah administrator semua duplikat terlihat. Tapi jangan putus asa, itu cukup untuk secara eksplisit menunjukkan peran yang digunakan dalam string koneksi dan semuanya jatuh pada tempatnya, apalagi, saat pengujian, Anda harus beralih di antara peran lebih dari sekali.
Seperti yang Anda pahami, Anda dapat membuat beberapa kombinasi dari catatan yang sama dengan derajat kepenuhan kolom yang berbeda dengan data nyata. Anda juga dapat membuat tabel tersembunyi terpisah di kubus, yang akan diisi dengan akun melalui ADSI, dan mendistribusikan pengguna ke grup domain yang berbeda, dan mengisi tabel ini tergantung pada kombinasi keanggotaan pengguna dalam grup tertentu. Kami menulis tautan dalam filter peran baris demi baris ke tabel ini, yang akan memungkinkan kami mengontrol pengukuran dan kami juga dapat merujuknya dalam ukuran, sehingga, jika perlu, beberapa tindakan menunjukkan kekosongan. Dengan organisasi seperti itu, fine-tuning hak akses ke data diperoleh dan semuanya disimpan di satu tempat. Tetapi ada nuansa dengan ukuran: jika pengguna mahir menulis kueri ke kubus sendiri, maka tidak ada yang mencegahnya menggunakan ukurannya, tanpa bookmark, asalkan dia tahu nama-nama kolom dasar dan formula ... Meskipun, jika diinginkan, Anda bisa melakukannya di sini pembatasan, tapi itu topik lain.