Semua orang berbicara tentang proses pengembangan dan pengujian, pelatihan staf, peningkatan motivasi, tetapi proses ini hanya sedikit ketika satu menit layanan downtime membutuhkan ruang uang. Apa yang harus dilakukan ketika Anda melakukan transaksi keuangan di bawah SLA yang ketat? Bagaimana cara meningkatkan keandalan dan toleransi kesalahan sistem Anda, menguraikan pengembangan dan pengujian?

Konferensi HighLoad ++ berikutnya akan diadakan pada 6 dan 7 April 2020 di St. Petersburg. Detail dan tiket di
sini . 9 November 18:00. HighLoad ++ Moscow 2018, Delhi + Calcutta Hall. Abstrak dan
presentasi .
Evgeny Kuzovlev (selanjutnya disebut sebagai EC): - Teman-teman, halo! Nama saya Kuzovlev Evgeny. Saya dari EcommPay, divisi khusus adalah EcommPay IT, divisi IT dari sekelompok perusahaan. Dan hari ini kita akan berbicara tentang downtime - bagaimana menghindarinya, bagaimana meminimalkan konsekuensinya, jika Anda tidak bisa menghindarinya. Temanya adalah: "Apa yang harus dilakukan ketika satu menit downtime berharga $ 100.000?" Bagi kami, melihat ke depan, jumlahnya bisa dibandingkan.
Apa yang EcommPay lakukan?
Siapa kita? Kenapa aku berdiri di depanmu? Kenapa aku berhak memberitahumu sesuatu di sini? Dan apa yang akan kita bicarakan secara lebih rinci di sini?

EcommPay Group of Companies adalah perusahaan pengakuisisi internasional. Kami memproses pembayaran di seluruh dunia - di Rusia, Eropa, di Asia Tenggara (All Around the World). Kami memiliki 9 kantor, total 500 karyawan dan sekitar kurang dari setengahnya adalah spesialis IT. Segala sesuatu yang kita lakukan, semua yang kita hasilkan uang, kita lakukan sendiri.
Kami memiliki semua produk kami (dan kami memiliki banyak dari mereka - dalam garis produk TI besar kami memiliki sekitar 16 komponen berbeda) kami menulis sendiri; kita menulis diri kita sendiri, kita mengembangkan diri kita sendiri. Dan saat ini kami sedang melakukan sekitar satu juta transaksi per hari (jutaan - mungkin itu benar untuk mengatakan itu). Kami adalah perusahaan yang cukup muda - kami baru berusia sekitar enam tahun.
6 tahun yang lalu itu adalah startup ketika orang-orang datang dengan bisnis. Mereka disatukan oleh sebuah ide (tidak ada yang lain selain sebuah ide), dan kami berlari. Seperti halnya startup, kami berlari lebih cepat ... Bagi kami, kecepatan lebih penting daripada kualitas.
Pada titik tertentu, kami berhenti: kami menyadari bahwa kami tidak lagi dapat hidup dengan kecepatan dan kualitas itu, dan kami perlu melakukan kualitas sejak awal. Pada titik ini, kami memutuskan untuk menulis platform baru yang tepat, terukur, andal. Mereka mulai menulis platform ini (mereka mulai berinvestasi, mengembangkan pengembangan, menguji), tetapi pada titik tertentu mereka menyadari bahwa pengembangan dan pengujian tidak memungkinkan mencapai tingkat kualitas layanan yang baru.
Anda membuat produk baru, Anda memasangnya untuk produksi, tetapi masih di suatu tempat, ada yang salah. Dan hari ini kita akan berbicara tentang bagaimana mencapai tingkat kualitatif baru (bagaimana kita mendapatkannya, tentang pengalaman kita), mengambil pengembangan dan menguji dari gambar; kami akan berbicara tentang apa yang tersedia untuk eksploitasi - eksploitasi apa yang dapat dilakukan sendiri, apa yang dapat menawarkan pengujian untuk mempengaruhi kualitas.
Waktu henti. Perintah-perintah eksploitasi.
Selalu landasan utama, yang sebenarnya akan kita bicarakan hari ini adalah downtime. Kata menakutkan. Jika kita mengalami downtime, semuanya buruk dengan kita. Kami berlari untuk menaikkan, admin memegang server - Astaga, tidak jatuh, seperti dalam lagu itu. Inilah yang akan kita bicarakan hari ini.

Ketika kami mulai mengubah pendekatan kami, kami membentuk 4 perintah. Mereka disajikan pada slide saya:
Perintah-perintah ini cukup sederhana:

- Identifikasi masalah dengan cepat.
- Singkirkan lebih cepat lagi.
- Bantu memahami alasannya (nanti, untuk pengembang).
- Dan membakukan pendekatan.
Saya menarik perhatian Anda ke poin nomor 2. Kami menyingkirkan masalah, tetapi jangan menyelesaikannya. Untuk memutuskan adalah yang kedua kalinya. Hal utama bagi kami adalah bahwa pengguna terlindungi dari masalah ini. Ini akan ada di lingkungan terisolasi tertentu, tetapi lingkungan ini tidak akan bersentuhan dengannya. Sebenarnya, kita akan membahas empat kelompok masalah ini (untuk beberapa lebih detail, untuk beberapa lebih sedikit detail), saya akan memberi tahu Anda apa yang kami gunakan, pengalaman seperti apa yang kami miliki dalam menyelesaikannya.
Pemecahan masalah: kapan itu terjadi dan apa yang harus dilakukan dengan mereka?
Tapi kita akan mulai dari urutan, kita mulai dengan poin nomor 2 - bagaimana cara cepat menyingkirkan masalah? Ada masalah - kita harus memperbaikinya. "Apa yang harus kita lakukan dengan ini?" Adalah pertanyaan utama. Dan ketika kami mulai berpikir tentang cara memperbaiki masalah, kami mengembangkan sendiri beberapa persyaratan yang harus diikuti pemecahan masalah.

Untuk merumuskan persyaratan ini, kami memutuskan untuk bertanya pada diri sendiri pertanyaan: "Dan kapan kita memiliki masalah"? Dan masalahnya, ternyata, ditemukan dalam empat kasus:

- Kerusakan perangkat keras.
- Kegagalan layanan eksternal.
- Perubahan versi perangkat lunak (penyebaran yang sama).
- Pertumbuhan beban eksplosif.
Kami tidak akan membicarakan dua yang pertama. Kerusakan perangkat keras diselesaikan dengan cukup sederhana: Anda harus menduplikasi semuanya. Jika ini adalah disk - disk harus dirakit dalam RAID, jika itu adalah server - server harus digandakan, jika Anda memiliki infrastruktur jaringan - Anda harus meletakkan salinan kedua dari infrastruktur jaringan, yaitu, Anda ambil dan duplikat. Dan jika sesuatu gagal pada Anda, Anda beralih ke kapasitas cadangan. Sulit untuk mengatakan lebih banyak di sini.
Yang kedua adalah kegagalan layanan eksternal. Bagi sebagian besar, sistem itu tidak masalah sama sekali, tetapi tidak untuk kita. Karena kami memproses pembayaran, kami adalah agregator yang berdiri di antara pengguna (yang memasukkan detail kartunya) dan bank, sistem pembayaran ("Visa", "MasterCard", "World" yang sama). Layanan eksternal kami (sistem pembayaran, bank) cenderung gagal. Kami maupun Anda (jika Anda memiliki layanan semacam itu) tidak dapat memengaruhi ini.
Lalu apa yang harus dilakukan? Ada dua opsi. Pertama, jika Anda bisa, Anda harus menggandakan layanan ini dengan beberapa cara. Misalnya, jika kami bisa, kami mentransfer lalu lintas dari satu layanan ke layanan lain: kami memproses, misalnya, kartu melalui Sberbank, Sberbank memiliki masalah - kami mentransfer lalu lintas [kondisional] ke Raiffeisen. Hal kedua yang dapat kita lakukan adalah dengan cepat memperhatikan kegagalan layanan eksternal, dan oleh karena itu kita akan berbicara tentang kecepatan reaksi di bagian selanjutnya dari laporan ini.
Faktanya, dari keempat ini, kita dapat secara khusus memengaruhi perubahan versi perangkat lunak - untuk mengambil tindakan yang akan mengarah pada peningkatan dalam konteks penyebaran dan dalam konteks pertumbuhan muatan yang eksplosif. Sebenarnya, kita berhasil. Di sini, sekali lagi, sedikit komentar ...
Dari empat masalah ini, beberapa diatasi segera jika Anda memiliki cloud. Jika Anda berada di Microsoft Azhur, Ozon cloud, gunakan cloud kami, dari Yandex atau Mail, maka setidaknya kerusakan perangkat keras menjadi masalah mereka dan semuanya segera menjadi baik dalam konteks kerusakan perangkat keras.
Kami adalah perusahaan kecil non-standar. Di sini semua orang berbicara tentang Kubernet, tentang awan - kita tidak memiliki Kubernet, atau awan. Tetapi kami memiliki rak dengan besi di banyak pusat data, dan kami dipaksa untuk hidup dengan besi ini, kami dipaksa untuk menjawab semuanya. Karena itu, dalam konteks ini kita akan berbicara. Jadi, soal masalahnya. Dua yang pertama keluar dari tanda kurung.
Ubah versi perangkat lunak. Basis
Pengembang kami tidak memiliki akses ke produksi. Kenapa begitu Tapi kami hanya disertifikasi oleh PCI DSS, dan pengembang kami tidak punya hak untuk naik ke "prod." Itu dia, titik. Tentu saja Oleh karena itu, tanggung jawab pengembangan berakhir tepat pada saat pengembangan melewati pembangunan hingga rilis.

Basis kedua kami, yang kami miliki, yang juga banyak membantu kami, adalah kurangnya pengetahuan yang unik dan tidak terdokumentasi. Saya harap Anda melakukan hal yang sama. Karena jika tidak demikian, maka Anda akan mengalami masalah. Masalah akan muncul ketika pengetahuan unik dan tidak berdokumen ini tidak hadir pada waktu yang tepat di tempat yang tepat. Misalkan Anda memiliki satu orang yang tahu cara menggunakan komponen tertentu - tidak ada orang, ia sedang berlibur atau jatuh sakit - itu saja, Anda memiliki masalah.
Dan dasar ketiga yang telah kita miliki. Kami datang kepadanya melalui rasa sakit, darah, air mata - kami sampai pada kesimpulan bahwa salah satu tubuh kami mengandung kesalahan, bahkan jika itu tanpa kesalahan. Kami memutuskan ini untuk diri kami sendiri: ketika kami menyebarkan sesuatu, ketika kami menggulung sesuatu ke dalam prod - kami memiliki build dengan kesalahan. Kami telah membentuk persyaratan yang harus dipenuhi oleh sistem kami.
Persyaratan Perubahan Versi Perangkat Lunak
Ada tiga persyaratan ini:

- Kita harus dengan cepat menghentikan penyebaran.
- Kita harus meminimalkan dampak dari penyebaran yang gagal.
- Dan kita harus dapat dengan cepat terjebak secara paralel.
Dalam urutan itu! Mengapa Karena, pertama-tama, ketika menggunakan versi baru, kecepatan tidak penting, tetapi penting bagi Anda, jika terjadi kesalahan, cepat mundur dan memiliki dampak minimal. Tetapi jika Anda memiliki satu set versi pada produksi, yang ternyata ada kesalahan (seperti salju di kepala Anda, tidak ada penyebaran, tetapi kesalahan terkandung) - kecepatan penyebaran selanjutnya penting bagi Anda. Apa yang telah kami lakukan untuk memenuhi persyaratan ini? Kami menggunakan metodologi seperti itu:
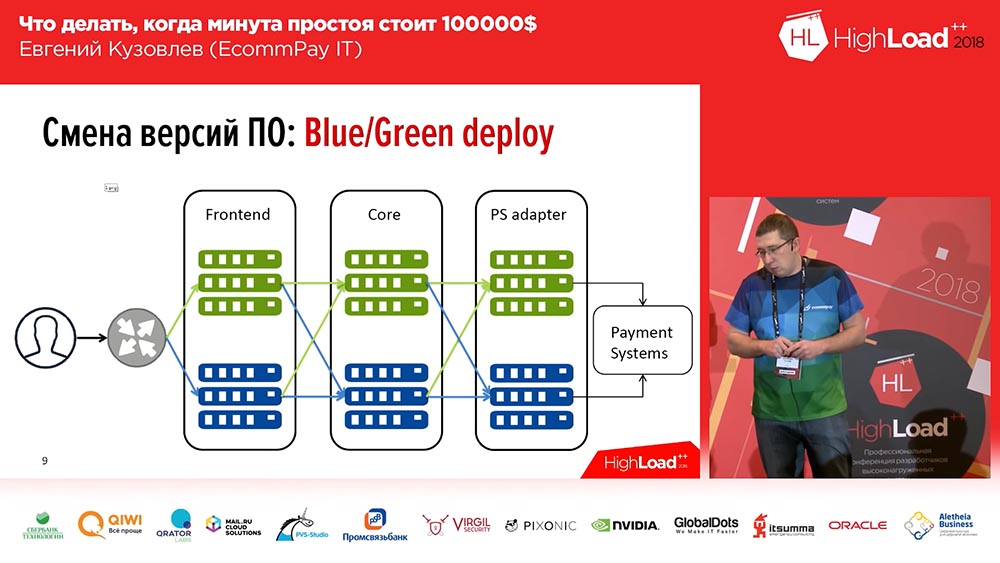
Sudah dikenal, kami belum menemukan sekali pun - ini adalah penyebaran Biru / Hijau. Apa ini Anda harus memiliki salinan untuk setiap kelompok server tempat aplikasi Anda diinstal. Salinan “hangat”: tidak ada lalu lintas di atasnya, tetapi kapan saja lalu lintas ini dapat dikirim ke salinan ini. Salinan ini berisi versi sebelumnya. Dan pada saat penyebaran, Anda meluncurkan kode ke salinan tidak aktif. Kemudian alihkan sebagian lalu lintas (atau semua) ke versi baru. Jadi, untuk mengubah arus lalu lintas dari versi lama ke versi baru, Anda hanya perlu melakukan satu tindakan: Anda perlu mengubah penyeimbang di hulu, mengubah arah - dari satu hulu ke yang lain. Ini sangat mudah dan memecahkan masalah switching cepat, rollback cepat.
Di sini, solusi untuk pertanyaan kedua adalah minimalisasi: Anda dapat menempatkan pada baris baru, pada baris dengan kode baru hanya bagian dari lalu lintas Anda (misalkan, 2%). Dan 2% ini - mereka tidak 100%! Jika Anda kehilangan 100% dari lalu lintas selama penerapan yang gagal - ini menakutkan, jika Anda kehilangan 2% dari lalu lintas - ini tidak menyenangkan, tetapi itu tidak menakutkan. Selain itu, pengguna kemungkinan besar tidak akan memperhatikan hal ini, karena dalam beberapa kasus (tidak semua) pengguna yang sama, dengan menekan F5, ia akan dibawa ke versi lain yang berfungsi.
Biru / Hijau. Routing
Selain itu, tidak semuanya begitu sederhana "Blue / Green Deploy" ... Semua komponen kami dapat dibagi menjadi tiga kelompok:
- Ini adalah frontend (halaman pembayaran yang dilihat pelanggan kami);
- inti pemrosesan;
- adaptor untuk bekerja dengan sistem pembayaran (bank, MasterCard, Visa ...).
Dan ada nuansa - nuansa adalah rute antara garis-garis. Jika Anda hanya beralih 100% dari lalu lintas, Anda tidak memiliki masalah ini. Tetapi jika Anda ingin beralih 2%, pertanyaan dimulai: "Bagaimana melakukan ini?" Hal paling sederhana di dahi: Anda dapat, secara acak, mengkonfigurasi Round Robin di nginx, dan Anda memiliki 2% kiri, 98% - ke kanan. Tapi ini tidak selalu cocok.
Di sini, misalnya, pengguna berinteraksi dengan sistem dalam lebih dari satu permintaan. Ini normal: 2, 3, 4, 5 kueri - sistem Anda mungkin sama. Dan jika penting bagi Anda bahwa semua permintaan pengguna datang ke baris yang sama dengan permintaan pertama datang, atau (saat kedua) semua permintaan pengguna datang ke baris baru setelah beralih (dia bisa mulai bekerja lebih awal dengan sistem, sebelum beralih), - maka distribusi acak ini tidak cocok untuk Anda. Lalu ada opsi berikut:

Opsi pertama, termudah - berdasarkan parameter dasar klien (IP Hash). Anda memiliki IP, dan Anda berbagi kanan-ke-kiri oleh IP. Kemudian kasus kedua yang saya jelaskan akan bekerja untuk Anda ketika ada penyebaran, pengguna sudah bisa mulai bekerja dengan sistem Anda, dan sejak saat penempatan semua permintaan akan masuk ke baris baru (ke yang sama, katakanlah).
Jika karena alasan tertentu ini tidak cocok untuk Anda dan Anda perlu mengirim permintaan ke saluran tempat permintaan intim utama pengguna datang, maka Anda memiliki dua opsi ...
Opsi pertama: Anda dapat mengambil nginx + berbayar. Ada mekanisme sesi Sticky, yang, atas permintaan awal pengguna, mengekspos sesi kepada pengguna dan mengikatnya ke hulu tertentu. Semua permintaan pengguna berikutnya dalam masa hidup sesi akan pergi ke hulu yang sama di mana sesi itu ditetapkan.
Ini tidak cocok untuk kita, karena kita sudah punya nginx normal. Berpindah nginx + bukan berarti itu mahal, itu hanya sedikit menyakitkan bagi kami dan tidak terlalu tepat. Misalnya, "Sesi Tongkat" tidak berfungsi untuk kami karena alasan sederhana bahwa "Sesi Tongkat" tidak memberikan kesempatan untuk melakukan rute berdasarkan "Eli-atau". Di sana Anda dapat menentukan apa yang kami lakukan "Sesi Sticky", misalnya, dengan IP atau IP dan dengan cookie atau dengan parameter posting, tetapi "Eli-atau" sudah lebih rumit di sana.
Karena itu, kami sampai pada pilihan keempat. Kami menggunakan nginx pada "steroid" (ini openresty) - ini adalah nginx yang sama yang juga mendukung dimasukkannya skrip terakhir. Anda dapat menulis skrip terakhir, selipkan "buka" ini, dan skrip terakhir ini akan dieksekusi ketika permintaan pengguna diterima.
Dan kami menulis, pada kenyataannya, skrip seperti itu, mengatur diri kami "openrest" dan dalam skrip ini kami memilah 6 parameter yang berbeda untuk penggabungan "Atau". Bergantung pada ketersediaan parameter ini atau itu, kita tahu bahwa pengguna datang ke satu halaman atau ke yang lain, ke satu baris atau ke yang lain.
Biru / Hijau. Keuntungan dan kerugian
Tentu saja, kami mungkin bisa membuatnya sedikit lebih mudah (menggunakan "Sesi Sticky" yang sama), tetapi kami masih memiliki nuansa sedemikian rupa sehingga tidak hanya pengguna berinteraksi dengan kami dalam kerangka satu pemrosesan satu transaksi ... Tetapi sistem pembayaran juga berinteraksi dengan kami: kami, setelah kami memproses transaksi (dengan mengirimkan permintaan ke sistem pembayaran), kami mendapat panggilan balik.
Dan anggaplah jika di dalam sirkuit kami, kami dapat menjalankan alamat IP pengguna di semua permintaan dan memisahkan pengguna berdasarkan alamat IP, maka kami tidak akan mengatakan "Visa" yang sama: "Dudes, kami adalah perusahaan retro, kami jenis internasional (di situs dan di Dari Rusia) ... Dan tolong beri kami lihat alamat IP pengguna di bidang tambahan, protokol Anda standar! " Bisnis yang jelas, mereka tidak akan setuju.

Karena itu, bagi kami itu tidak cocok - kami melakukan openresty. Dengan demikian, dengan perutean kami mendapat seperti ini:
Blue / Green Deploy memiliki, masing-masing, kelebihan yang saya bicarakan dan kerugiannya.
Kekurangan dua:
- Anda perlu repot dengan routing;
- Kerugian utama kedua adalah biaya.
Anda memerlukan server dua kali lebih banyak, Anda perlu sumber daya operasional dua kali lebih banyak, Anda perlu menghabiskan dua kali lebih banyak upaya untuk memelihara semua kebun binatang ini.
Ngomong-ngomong, di antara kelebihannya adalah hal lain yang belum saya sebutkan sebelumnya: Anda memiliki cadangan jika terjadi peningkatan beban. Jika Anda memiliki pertumbuhan beban yang eksplosif, sejumlah besar pengguna jatuh pada Anda, maka Anda cukup memasukkan baris kedua dalam distribusi 50 hingga 50 - dan Anda segera memiliki 2 server di kluster Anda hingga Anda menyelesaikan masalah memiliki server.
Bagaimana cara membuat penyebaran cepat?
Kami berbicara tentang cara mengatasi masalah minimisasi dan rollback cepat, tetapi pertanyaannya tetap: "Bagaimana cara menyebarkan dengan cepat?"

Ini singkat dan sederhana.
- Anda harus memiliki sistem CD (Pengiriman Berkelanjutan) - tanpanya, tidak ada tempat. Jika Anda memiliki satu server, Anda bisa terjebak dengan pena. Kami memiliki sekitar satu setengah ribu server dan 1.500 pegangan, tentu saja - kami dapat menanam departemen dengan ukuran ruangan ini, hanya untuk disebarkan.
- Menyebarkan harus paralel. Jika Anda memiliki penyebaran yang konsisten, maka semuanya buruk. Satu server normal, Anda akan menggunakan satu setengah ribu server sepanjang hari.
- Sekali lagi, untuk mempercepat, ini tidak lagi diperlukan, mungkin. Ketika desploey biasanya membangun proyek. Apakah Anda memiliki proyek web, ada bagian front-end (Anda membuat paket web di sana, npm mengumpulkan sesuatu seperti itu), dan proses ini pada dasarnya berumur pendek - 5 menit, tetapi 5 menit ini bisa sangat penting. Karena itu, misalnya, kami tidak melakukan ini: kami menghapus 5 menit ini, kami menggunakan artefak.
Apa itu artefak? Artefak adalah bangunan yang dirakit di mana seluruh bagian perakitan telah selesai. Kami menyimpan artefak ini dalam penyimpanan artefak. Kami menggunakan dua penyimpanan seperti itu pada satu waktu - itu adalah Nexus dan sekarang jFrog Artifactory.) Kami awalnya menggunakan Nexus karena kami mulai mempraktikkan pendekatan ini dalam aplikasi java (sangat cocok). Kemudian mereka menempatkan bagian dari aplikasi yang ditulis oleh PHP di sana; dan Nexus tidak lagi cocok, dan oleh karena itu kami memilih jFrog Artefactory, yang dapat artefak hampir semuanya. Kami bahkan sampai pada fakta bahwa dalam penyimpanan artefak ini kami menyimpan paket biner kami sendiri, yang kami kumpulkan untuk server.
Pertumbuhan beban eksplosif
Kami berbicara tentang mengubah versi perangkat lunak. Hal berikutnya yang kita miliki adalah pertumbuhan muatan yang eksplosif. Di sini saya mungkin mengerti bahwa ledakan pertumbuhan muatan bukanlah hal yang benar ...
Kami menulis sistem baru - itu berorientasi layanan, cantik modis, di mana-mana pekerja, di mana-mana antrian, di mana-mana asynchrony. Dan dalam sistem seperti itu, data dapat mengalir berbeda. Untuk transaksi pertama, pekerja ke-1, ke-3, ke-10 dapat terlibat, untuk transaksi kedua - ke-2, ke-4, ke-5. Dan hari ini, katakanlah, di pagi hari Anda memiliki aliran data yang menggunakan tiga pekerja pertama, dan di malam hari itu berubah secara dramatis, dan semuanya menggunakan tiga pekerja lainnya.
Dan di sini ternyata Anda perlu entah bagaimana skala pekerja, Anda perlu entah bagaimana skala layanan Anda, tetapi pada saat yang sama mencegah penggelembungan sumber daya.

Kami telah menentukan persyaratan untuk diri kami sendiri. : Service discovery, – , – . , , . «», «», .
? . 70 . «», «» , , . 100 «», 100 . . , – 24/7 , , , 70 , .
«», IP Scale-Nomad – ScaleNo, : . , : « ?» – , .
, , , , , – , . 3-5 – .

Bagaimana cara kerjanya? ! : : , – , – , – .
, . 45 – . 2 , ( – , ). – , 5-10 , .
«», , «» . , , – . . № 2 – « ».
. ?
– « ?» ! . ?

!
, , . . , . « ». :

«» «», . «» . «» «» , , – «» «», – «» «» Telegraf.
New Relic. , . , . 1,5 , , : « ». , , . «-» , 15 «-». .
, – Debugger. «», , , «». Apa ini , 15-30 , « » , .
, ( ) – , . , «» – , «» . – , , , .
?
? ?

- Response time / RPS – . , - .
- .
- .
- .
– «», «» . , - , . – ( ). - 5-10-15 – , ( ).
– :
– 6 , – . – RPS, RTS. – «». «» , - … , .
, – . OpenTracing – , , , ; . OpenTracing- , . , , . , , .

, 3 – . , , 20-30 .
, – .
, , , , . , .

? , : (, «»); , . , , … – -. , : « »?
… -, ( ) , . : – , , ( ). , - . ! . .
, .
, – , , , , , - . , , .

( – ), ELK Stack – . -, , ELK, , ELK. .
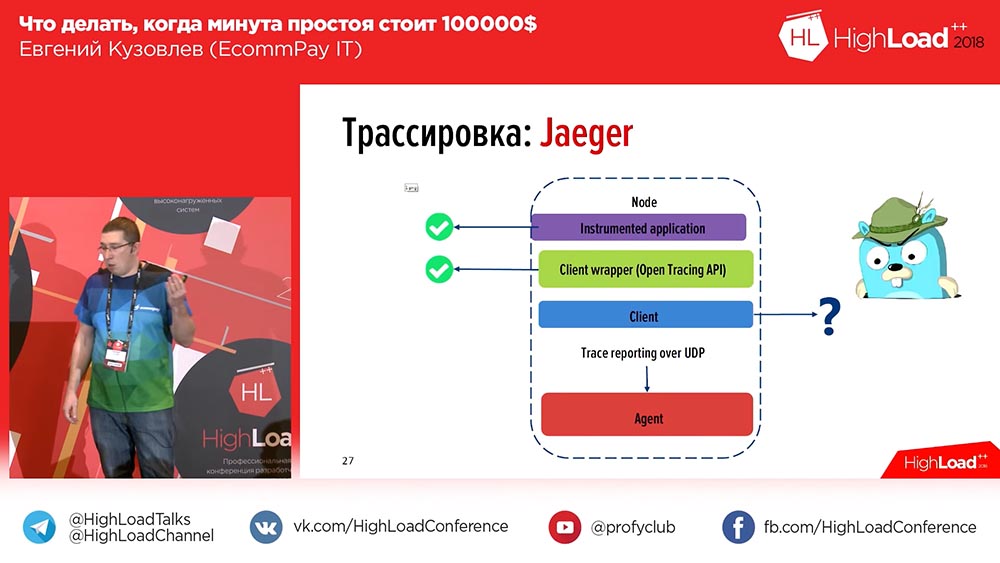
. , , , , «», id- ( ). . Mengapa , , . , – OpenTracing, .
, , – «» (Zipkin) «» (Jaeger). «» – , «». «» , , , , . «» .
«»: , Api ( Api PHP , , – , ), . «», – , . ? :
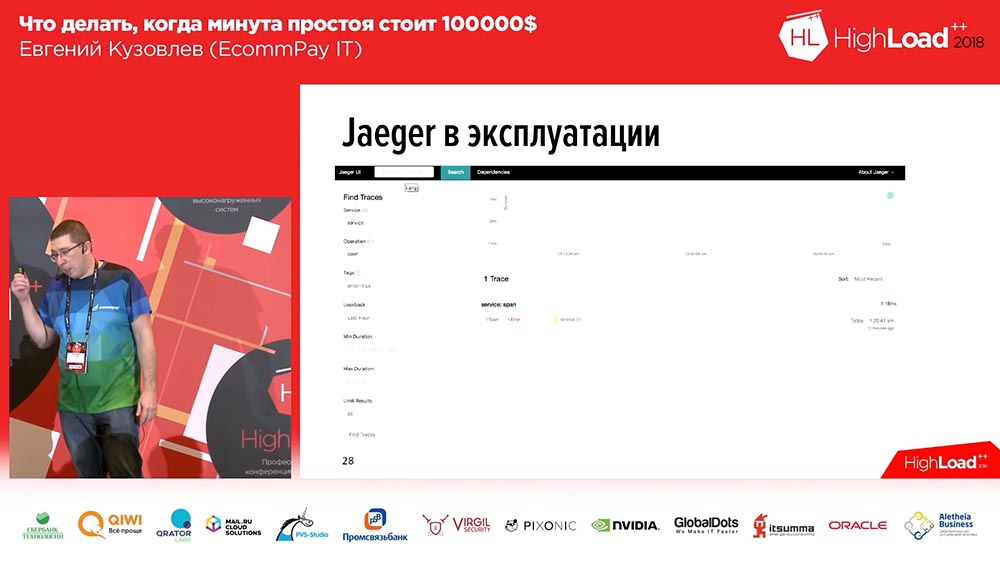
«» span'. , , (1-2-3 – , ). , . , Error. Error , . , span:

. , , . : – , , .
, . , . , «» PHP – , welcome to use, :

– OpenTracing Api, php-extention, . . , . : , extention up to you.
. – . ? :

«»? , ! «» , , , . ?

- . , . 60 , . , , – , .
- . , , RnD-. , (, ) , , .
- , – , . .
- Kami memiliki toleransi. Misalnya, kami tidak mempertimbangkan downtime jika kami kehilangan 2% dari lalu lintas dalam waktu dua menit. Ini, pada prinsipnya, tidak termasuk dalam statistik kami. Jika lebih banyak dalam persentase atau waktu, kami sudah menghitung.
- Dan kami selalu menulis post-mortem. Apa pun yang terjadi pada kami, situasi apa pun ketika berperilaku tidak pantas di lokasi produksi akan tercermin dalam potsortem. Post-mortem adalah dokumen di mana Anda menulis apa yang terjadi pada Anda, waktu terperinci dari apa yang Anda lakukan untuk memperbaikinya dan (ini adalah blok wajib!) Apa yang akan Anda lakukan untuk mencegah hal ini terjadi di masa depan. Ini perlu, perlu untuk analisis selanjutnya.
Apa yang harus dipertimbangkan waktu henti?

Apa yang menyebabkan semua ini?
Ini mengarah pada fakta bahwa (kami memiliki masalah stabilitas tertentu, ini tidak sesuai dengan klien atau kami) selama 6 bulan terakhir, indikator stabilitas kami berjumlah 99,97. Kita dapat mengatakan bahwa ini tidak terlalu banyak. Ya, kami memiliki sesuatu untuk diperjuangkan. Sekitar setengah dari indikator ini adalah stabilitas, bukan milik kami, tetapi firewall aplikasi web kami, yang berdiri di depan kami dan digunakan sebagai layanan, tetapi itu tidak masalah bagi pelanggan.
Kami belajar tidur di malam hari. Akhirnya! Enam bulan lalu, kami tidak tahu caranya. Dan pada catatan ini dengan hasilnya, saya ingin membuat satu komentar. Tadi malam ada laporan bagus tentang sistem kontrol reaktor nuklir. Jika orang yang menulis sistem ini mendengar saya, harap lupakan apa yang saya katakan tentang "2% bukan downtime". Untuk Anda, 2% downtime, bahkan jika selama dua menit "!
Itu saja! Pertanyaan anda

Tentang penyeimbang dan migrasi basis data
Pertanyaan dari hadirin (selanjutnya - B): - Selamat malam. Terima kasih banyak atas laporan admin seperti itu! Pertanyaannya pendek tentang masalah penyeimbang Anda. Anda menyebutkan bahwa Anda memiliki WAF, yaitu, seperti yang saya mengerti, Anda menggunakan semacam penyeimbang eksternal ...
: - Tidak, kami menggunakan layanan kami sebagai penyeimbang. Dalam hal ini, WAF bagi kami semata-mata alat perlindungan DDoS.
T: - Bisakah Anda mengatakan beberapa kata tentang penyeimbang?
EK: - Seperti yang saya katakan, ini adalah sekelompok server di openresty. Kami sekarang memiliki 5 kelompok yang mubazir yang merespons secara eksklusif ... yaitu, server yang berdiri secara eksklusif openresty, hanya proxy lalu lintas. Karenanya, untuk memahami seberapa banyak yang kami miliki: kami sekarang memiliki arus lalu lintas reguler - ini beberapa ratus megabit. Mereka mengelola, mereka merasa baik, mereka bahkan tidak tegang.
T: - Juga pertanyaan sederhana. Ada penyebaran Biru / Hijau. Dan apa yang Anda lakukan, misalnya, dengan migrasi dari database?
EK: - Pertanyaan bagus! Lihat, kami di penyebaran Biru / Hijau memiliki garis terpisah untuk setiap baris. Artinya, jika kita berbicara tentang garis peristiwa yang ditransmisikan dari pekerja ke pekerja, ada garis yang terpisah untuk garis biru dan garis hijau. Jika kita berbicara tentang database itu sendiri, maka kita sengaja mempersempitnya, karena kita bisa, meletakkan semuanya hampir sejalan, kita hanya memiliki setumpuk transaksi dalam database. Dan kami memiliki tumpukan transaksi tunggal untuk semua lini. Dengan basis data dalam konteks ini: kami tidak membaginya dengan biru dan hijau, karena kedua versi kode harus tahu apa yang terjadi dengan transaksi.
Teman-teman, saya masih punya hadiah kecil untuk memacu Anda - sebuah buku. Dan saya harus menyerahkannya untuk pertanyaan terbaik.
T: - Halo. Terima kasih atas laporannya. Pertanyaannya adalah ini. Anda memonitor pembayaran, Anda memantau layanan yang Anda gunakan untuk berkomunikasi ... Tetapi bagaimana Anda memantau sehingga seseorang entah bagaimana datang ke halaman pembayaran Anda, melakukan pembayaran, dan proyek itu memberinya uang? Yaitu, bagaimana Anda memantau marchant tersedia dan menerima panggilan balik Anda?
: - "Pedagang" bagi kami dalam hal ini persis dengan layanan eksternal yang sama dengan sistem pembayaran. Kami memantau kecepatan respons "pedagang".
Tentang enkripsi basis data
T: - Halo. Saya punya sedikit pertanyaan. Anda memiliki data PCI DSS yang sensitif. Saya ingin tahu bagaimana Anda menyimpan PAN dalam antrian yang harus Anda buang? Apakah Anda menggunakan enkripsi apa pun? Dan dari sini muncul pertanyaan kedua: pada PCI DSS, perlu untuk mengenkripsi ulang database secara berkala jika terjadi perubahan (pemberhentian admin, dan sebagainya) - bagaimana hal ini terjadi dengan aksesibilitas?

EK: - Pertanyaan bagus! Pertama, kami tidak menyimpan PAN dalam antrian. Kami tidak memiliki hak untuk menyimpan PAN di tempat yang jelas, pada prinsipnya, oleh karena itu, kami menggunakan layanan khusus (kami menyebutnya "Cademon") - ini adalah layanan yang hanya melakukan satu hal: menerima pesan dan mengirim pesan terenkripsi. Dan kami menyimpan semuanya dengan pesan terenkripsi ini. Karenanya, panjang kunci untuk kami adalah di bawah kilobyte, sehingga langsung dan dapat diandalkan secara langsung.
T: - Apakah Anda memerlukan 2 kilobyte sekarang?
EK: - Sepertinya kemarin itu 256 ... Nah, di mana lagi?!
Dengan demikian, ini yang pertama. Dan kedua, solusi yang ada, mendukung prosedur re-enkripsi - ada dua pasang "kue" (kunci) yang memberikan "deck" yang mengenkripsi (kunci adalah kunci, dek adalah turunan dari kunci yang mengenkripsi). Dan dalam kasus inisiasi prosedur (ini berlangsung secara teratur, dari 3 bulan hingga ± beberapa), kami mengunggah sepasang "kue" baru, dan kami memiliki data yang dienkripsi ulang. Kami memiliki layanan terpisah yang merobek semua data, mengenkripsi dengan cara baru; data disimpan di sebelah pengidentifikasi kunci yang dengannya mereka dienkripsi. Karenanya, segera setelah data kami dienkripsi dengan kunci baru, kami menghapus kunci lama.
Terkadang Anda perlu melakukan pembayaran secara manual ...
T: - Yaitu, jika pengembalian datang untuk beberapa operasi, lalu dekripsi dengan kunci lama?
EC: - Ya.
T: - Lalu satu pertanyaan kecil lagi. Ketika ada beberapa jenis kegagalan, jatuh, insiden, perlu untuk mendorong transaksi dalam mode manual. Ada situasi seperti itu.
EK: - Ya, itu benar.
T: - Di mana Anda mendapatkan data ini? Atau apakah Anda sendiri pergi dengan pena ke toko ini?
EK: - Tidak, tentu saja - kami memiliki semacam sistem back-office yang berisi antarmuka untuk dukungan kami. Jika kami tidak tahu status transaksi itu (misalnya, sementara sistem pembayaran tidak merespons dengan batas waktu), kami tidak tahu apriori, artinya, kami menetapkan status akhir hanya dengan penuh keyakinan. Dalam hal ini, kami membuang transaksi ke status khusus untuk pemrosesan manual. Di pagi hari, hari berikutnya, segera setelah dukungan menerima informasi bahwa transaksi tersebut tetap dalam sistem pembayaran, mereka memprosesnya secara manual di antarmuka ini.

T: - Saya punya beberapa pertanyaan. Salah satunya adalah kelanjutan dari zona PCI DSS: bagaimana Anda mendapatkan loop log mereka? Pertanyaan seperti itu karena pengembang dapat memasukkan apa pun ke dalam log! Pertanyaan kedua: bagaimana Anda meluncurkan perbaikan terbaru? Pena dalam basis data adalah salah satu pilihan, tetapi mungkin ada hot-fix gratis - bagaimana prosedurnya di sana? Dan pertanyaan ketiga mungkin terkait dengan RTO, RPO. Ketersediaan Anda adalah 99,97, hampir empat kali sembilan, tetapi seperti yang saya pahami, Anda memiliki pusat data kedua, pusat data ketiga, dan pusat data kelima ... Bagaimana Anda menangani sinkronisasi, replikasi, semuanya?
EK: - Mari kita mulai dari yang pertama. Pertanyaan pertama tentang log itu? Saat kami menulis log, kami memiliki layer yang menutupi semua data sensitif. Dia melihat topeng dan bidang tambahan. Dengan demikian, log kami keluar dengan data yang sudah di-mask dan loop PCI DSS. Ini adalah salah satu tugas rutin yang ditugaskan ke departemen pengujian. Mereka berkewajiban memeriksa setiap tugas, termasuk log yang mereka tulis, dan ini adalah salah satu tugas rutin dalam tinjauan kode, untuk mengontrol bahwa pengembang tidak menulis sesuatu. Verifikasi selanjutnya dari ini dilakukan secara teratur oleh departemen keamanan informasi sekitar sekali seminggu: log diambil secara selektif untuk hari terakhir, dan mereka dijalankan melalui penganalisa-pemindai khusus dari server uji untuk memeriksa semua ini.
Tentang perbaikan panas. Ini termasuk dalam jadwal penyebaran kami. Kami memiliki item terpisah tentang perbaikan terbaru. Kami percaya bahwa kami menyebarkan perbaikan terbaru sepanjang waktu ketika kami membutuhkannya. Segera setelah versi dirakit, segera setelah dijalankan, segera setelah kami memiliki artefak, kami mendapatkan administrator sistem yang dipanggil dari dukungan, dan dia akan menggunakannya pada saat diperlukan.
Tentang "empat sembilan." Jumlah yang kami miliki sekarang, benar-benar tercapai, dan kami mencarinya di pusat data lain. Sekarang kami memiliki pusat data kedua, dan kami mulai merutekan di antara mereka, dan pertanyaan tentang pusat replikasi data silang adalah pertanyaan yang tidak sepele. Kami mencoba menyelesaikannya pada waktunya dengan cara yang berbeda: kami mencoba menggunakan "Tarantula" yang sama - itu tidak berhasil untuk kami, saya katakan segera. Karena itu, kami sampai pada fakta bahwa kami membuat urutan "sensasi" secara manual. Kami memiliki setiap aplikasi pada kenyataannya dalam mode asinkron dari drive "perubahan yang dilakukan" sinkronisasi yang diperlukan antara pusat data.
T: - Jika Anda memiliki yang kedua, mengapa tidak yang ketiga? Karena belum ada yang memiliki otak terpisah ...
: - Dan kami tidak memiliki otak yang terpisah. Karena setiap aplikasi menggerakkan multimaster, tidak masalah bagi kami pusat permintaan apa yang datang. Kami siap dengan kenyataan bahwa, jika kami memiliki satu pusat data macet (kami sedang meletakkannya) dan di tengah permintaan pengguna yang beralih ke pusat data kedua, kami siap kehilangan pengguna ini, sungguh; tetapi itu akan menjadi unit, unit absolut.
T: - Selamat sore. Terima kasih atas laporannya. Anda berbicara tentang debugger Anda, yang mendorong beberapa transaksi pengujian dalam produksi. Tetapi beri tahu kami tentang transaksi pengujian! Seberapa dalam kerjanya?
EC: - Ini melalui siklus penuh dari seluruh komponen. Tidak ada perbedaan antara transaksi tes dan satu pertempuran untuk komponen. Dan dari sudut pandang logika, ini hanyalah beberapa proyek terpisah dalam sistem, yang hanya menguji transaksi yang dikejar.
T: - Dan di mana Anda memotongnya? Jadi Core mengirim ...
: - Kami berada di belakang "Kor" dalam hal ini untuk pengujian transaksi ... Kami memiliki hal seperti perutean: "Kor" tahu sistem pembayaran mana yang akan dikirim - kami kirim ke sistem pembayaran palsu, yang hanya memberikan tanggapan http dan itu saja .
T: - Katakan, tolong, apakah Anda memiliki aplikasi yang ditulis dalam satu monolith besar, atau apakah Anda memotongnya ke beberapa layanan atau bahkan layanan microser?
: - Kami tidak memiliki monolit, tentu saja, kami memiliki aplikasi yang berorientasi layanan. Kami punya lelucon bahwa kami memiliki layanan monolit - mereka benar-benar cukup besar. Memanggil layanan microser bahasa ini tidak berpaling dari kata sama sekali, tetapi ini adalah layanan di mana pekerja mesin didistribusikan bekerja.
Jika layanan di server terganggu ...
T: - Lalu saya punya pertanyaan berikut. Bahkan jika itu adalah monolith, Anda masih mengatakan bahwa Anda memiliki banyak server instan ini, mereka semua memproses data pada prinsipnya, dan pertanyaannya adalah: "Jika salah satu server instan atau aplikasi, tautan tertentu dikompromikan Apakah mereka memiliki kontrol akses? Yang mana dari mereka yang bisa melakukan apa? Siapa yang harus dihubungi, untuk data apa?

EK: - Ya tentu saja. Persyaratan keamanan cukup serius. Pertama, kami memiliki lalu lintas data terbuka, dan port-port itu hanya yang kami antisipasi lalu lintas sebelumnya. Jika komponen berkomunikasi dengan database (katakanlah, "Muskul") pada 5-4-3-2, hanya 5-4-3-2 dan port lain akan terbuka untuk itu, arah lalu lintas lainnya tidak akan tersedia. Selain itu, kita harus memahami bahwa dalam produksi kami memiliki sekitar 10 loop keamanan yang berbeda. Dan bahkan jika aplikasi itu dikompromikan dalam beberapa cara, Tuhan melarang, seorang penyerang tidak akan dapat mengakses konsol manajemen server, karena ini adalah zona keamanan jaringan lain.
T: - Dan dalam konteks ini, saya lebih tertarik pada saat Anda memiliki beberapa kontrak dengan layanan - apa yang dapat mereka lakukan, melalui mana "tindakan" mereka dapat saling menghubungi ... Dan dalam aliran normal, beberapa layanan tertentu menanyakan seri, daftar "aksi" pada yang lain. Mereka tampaknya tidak beralih ke orang lain dalam situasi normal, dan mereka memiliki bidang tanggung jawab lain. Jika salah satu dari mereka dikompromikan, apakah ia dapat menarik "tindakan" dari layanan itu? ..
EK: - Saya mengerti. Jika dalam situasi normal dengan komunikasi server lain secara umum diizinkan, maka ya. Di bawah kontrak SLA, kami tidak memantau bahwa Anda hanya diizinkan 3 "tindakan" pertama, dan 4 "tindakan" tidak diizinkan untuk Anda. Ini mungkin berlebihan bagi kita, karena kita memiliki sistem perlindungan 4 tingkat, pada prinsipnya, untuk sirkuit. Kami lebih suka bertahan dengan kontur daripada di bagian dalam.
Cara Kerja Visa, MasterCard, dan Sberbank
T: - Saya ingin mengklarifikasi sejenak tentang pengalihan pengguna dari satu pusat data ke yang lain. Sejauh yang saya tahu, "Visa" dan "MasterCard" bekerja pada protokol sinkron biner 8583, ada campuran. Dan saya ingin tahu, sekarang maksud saya beralih - apakah langsung "Visa" dan "MasterCard" atau ke sistem pembayaran, ke pemrosesan?
EK: - Terserah campuran. Campuran yang kami miliki di satu pusat data.
T: - Secara kasar, apakah Anda memiliki satu titik koneksi?
: - “Catok” dan “MasterCard” - ya. Hanya karena "Visa" dan "MasterCard" memerlukan investasi yang cukup serius dalam infrastruktur untuk menyimpulkan kontrak terpisah untuk menerima pasangan campuran kedua, misalnya. Mereka dicadangkan dalam kerangka kerja satu pusat data, tetapi jika, Tuhan melarang, pusat data di mana campuran untuk menghubungkan ke "Visa" dan "MasterCard" sudah mati, maka kita akan memiliki koneksi dengan "Visa" dan "MasterCard" hilang ...
T: - Bagaimana mereka bisa dipesan? Saya tahu bahwa "Visa" hanya memungkinkan satu koneksi tetap pada prinsipnya!
EK: - Mereka sendiri memasok peralatan. Dalam hal apa pun, kami menerima peralatan yang secara internal mubazir.
T: - Yaitu, rak dari Connects Orange mereka? ..
EC: - Ya.
T: - Tetapi seperti dalam kasus ini: jika pusat data Anda hilang, haruskah Anda menggunakannya lebih lanjut? Atau hanya menghentikan lalu lintas?
EC: - Tidak. Dalam hal ini, kami cukup mengalihkan lalu lintas ke saluran lain, yang tentu saja akan lebih mahal bagi kami, lebih mahal bagi pelanggan. Tetapi lalu lintas tidak akan pergi melalui koneksi langsung kami ke Visa, MasterCard, tetapi melalui Sberbank konvensional (sangat berlebihan).
Saya sangat menyesal jika saya melukai karyawan Sberbank. Tetapi menurut statistik kami, Sberbank paling sering jatuh dari bank-bank Rusia. Dalam waktu kurang dari sebulan, sesuatu belum jatuh di Sberbank.

Sedikit iklan :)
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikan kepada teman Anda, VPS berbasis cloud untuk pengembang mulai $ 4,99 , analog unik dari server entry-level yang diciptakan oleh kami untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps mulai dari $ 19 atau cara membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
Dell R730xd 2 kali lebih murah di pusat data Equinix Tier IV di Amsterdam? Hanya kami yang memiliki 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV dari $ 199 di Belanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - mulai dari $ 99! Baca tentang Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?