Halo semuanya! Saya seorang pengembang backend, menulis microservices di Java + Spring. Saya bekerja di salah satu tim pengembangan produk internal Tinkoff.

Tim kami sering mengajukan pertanyaan tentang optimasi kueri dalam DBMS. Anda selalu ingin sedikit lebih cepat, tetapi Anda tidak selalu bisa bertahan dengan indeks yang dirancang dengan baik - Anda harus mencari beberapa solusi. Dalam salah satu pengembaraan di internet untuk mencari optimasi yang masuk akal ketika bekerja dengan database, saya menemukan blog Marcus Vinand yang sangat berguna , penulis SQL Performance Explained. Ini adalah jenis blog yang sangat langka di mana Anda dapat membaca semua artikel secara berurutan.
Saya ingin menerjemahkan untuk Anda sebuah artikel pendek oleh Marcus. Ini dapat disebut, sampai batas tertentu, sebuah manifesto yang berusaha untuk menarik perhatian pada masalah yang lama tetapi masih relevan dari kinerja operasi offset sesuai dengan standar SQL.
Di beberapa tempat saya akan melengkapi penulis dengan penjelasan dan komentar. Saya akan menunjuk semua tempat seperti "perkiraan" untuk kejelasan.
Pengantar kecil
Saya pikir banyak orang tahu betapa problematis dan penghambatannya untuk bekerja dengan seleksi paginal melalui offset. Tapi tahukah Anda bahwa itu bisa dengan mudah diganti dengan desain yang lebih produktif?
Jadi, kata kunci ofset memberitahu database untuk melewati n entri pertama dalam permintaan. Namun, database masih harus membaca catatan n pertama ini dari disk, dan dalam urutan yang ditentukan (catatan: terapkan pengurutan jika ditentukan), dan hanya setelah itu akan mungkin untuk mengembalikan catatan mulai dari n + 1 dan seterusnya. Hal yang paling menarik adalah bahwa masalahnya bukan pada implementasi konkret dalam DBMS, tetapi dalam definisi awal sesuai dengan standar:
... baris pertama-tama disortir menurut <order by clause> dan kemudian dibatasi dengan menjatuhkan jumlah baris yang ditentukan dalam <result offset clause> dari awal ...
-SQL: 2016, Bagian 2, 4.15.3 Tabel turunan (catatan: sekarang standar yang paling banyak digunakan)
Titik kunci di sini adalah offset mengambil parameter tunggal - jumlah catatan untuk dilewati, dan hanya itu. Mengikuti definisi ini, DBMS hanya bisa mendapatkan semua catatan dan kemudian membuang yang tidak perlu. Jelas, definisi offset semacam itu memaksa Anda untuk melakukan pekerjaan ekstra. Dan bahkan tidak masalah apakah itu SQL atau NoSQL.
Lebih banyak rasa sakit
Masalah offset tidak berakhir di sana, dan inilah sebabnya. Jika operasi lain menyisipkan catatan baru antara membaca dua halaman data dari disk, apa yang akan terjadi dalam kasus ini?
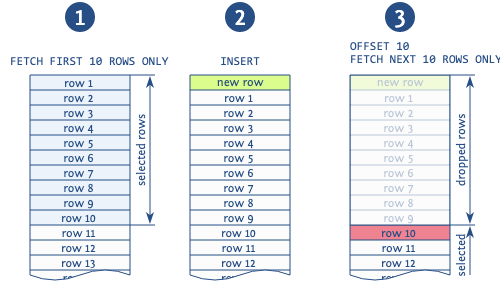
Ketika offset digunakan untuk melewati catatan dari halaman sebelumnya, dalam situasi menambahkan catatan baru antara operasi membaca halaman yang berbeda, kemungkinan besar Anda akan mendapatkan duplikat (catatan: ini dimungkinkan ketika kami membaca halaman demi halaman menggunakan urutan dengan konstruksi, kemudian di tengah output kami mungkin dapatkan catatan baru).
Sosok itu dengan jelas menggambarkan situasi seperti itu. Basis membaca 10 catatan pertama, setelah itu catatan baru dimasukkan, yang menggeser semua catatan yang dibaca oleh 1. Kemudian basis mengambil halaman baru dari 10 catatan berikutnya dan mulai tidak dari tanggal 11 sebagaimana mestinya, tetapi dari tanggal 10, menggandakan catatan ini. Ada anomali lain yang terkait dengan penggunaan ungkapan ini, tetapi ini adalah yang paling umum.
Seperti yang telah kita ketahui, ini bukan masalah DBMS tertentu atau implementasinya. Masalahnya adalah definisi pagination menurut standar SQL. Kami memberi tahu DBMS halaman mana yang akan didapat atau berapa banyak catatan untuk dilewati. Basis sama sekali tidak dapat mengoptimalkan permintaan seperti itu, karena ada terlalu sedikit informasi untuk ini.
Perlu juga diperjelas bahwa ini bukan masalah kata kunci tertentu, melainkan semantik kueri. Ada beberapa sintaksis yang identik dalam hal problematisitas:
- Kata kunci ofset, seperti yang disebutkan sebelumnya.
- Konstruksi dari dua kata kunci membatasi [diimbangi] (meskipun batas itu sendiri tidak begitu buruk).
- Pemfilteran batas bawah berdasarkan penomoran baris (mis. Row_number (), rownum, dll.).
Semua ungkapan ini hanya mengatakan berapa banyak baris untuk dilewati, tidak ada informasi atau konteks tambahan.
Kemudian di artikel ini, kata kunci ofset digunakan sebagai generalisasi dari semua opsi ini.
Hidup tanpa OFFSET
Sekarang bayangkan seperti apa dunia kita tanpa semua masalah ini. Ternyata hidup tanpa offset tidak begitu rumit: Anda dapat memilih hanya garis-garis yang belum kita lihat (perhatikan: yaitu, yang tidak ada di halaman terakhir) menggunakan kondisi di mana.
Dalam hal ini, kami membangun fakta bahwa pemilihan dijalankan pada set yang dipesan (pesanan lama yang baik oleh). Karena kita memiliki set yang dipesan, kita dapat menggunakan filter yang cukup sederhana untuk mendapatkan hanya data yang ada di balik catatan terakhir dari halaman sebelumnya:
SELECT ... FROM ... WHERE ... AND id < ?last_seen_id ORDER BY id DESC FETCH FIRST 10 ROWS ONLY
Itulah keseluruhan prinsip pendekatan ini. Tentu saja, ketika mengurutkan berdasarkan banyak kolom, semuanya menjadi lebih menyenangkan, tetapi idenya sama. Penting untuk dicatat bahwa konstruksi ini berlaku untuk banyak solusi N o S Q L.
Pendekatan ini disebut metode pencarian atau pagination keyset. Ini memecahkan masalah dengan hasil mengambang (catatan: situasi dengan menulis di antara halaman dibaca, dijelaskan sebelumnya) dan, tentu saja, yang kita semua suka, bekerja lebih cepat dan lebih stabil daripada offset klasik. Stabilitas terletak pada kenyataan bahwa waktu pemrosesan kueri tidak meningkat secara proporsional dengan jumlah tabel yang diminta (catatan: jika Anda ingin mempelajari lebih lanjut tentang kerja pendekatan yang berbeda untuk pagination, Anda dapat melihat melalui presentasi penulis . Di sana Anda juga dapat menemukan tolok ukur perbandingan menggunakan metode yang berbeda).
Salah satu slide mengatakan bahwa pagination kunci, tentu saja, tidak mahakuasa - ia memiliki keterbatasan sendiri. Paling signifikan - dia tidak memiliki kemampuan untuk membaca halaman acak (catatan: tidak konsisten). Namun, di era bergulir tanpa akhir (catatan: di ujung depan), ini bukan masalah. Menentukan nomor halaman untuk klik adalah keputusan yang buruk ketika mengembangkan UI (catatan: pendapat penulis artikel).
Bagaimana dengan alatnya?
Pagination kunci sering tidak cocok karena kurangnya dukungan instrumental untuk metode ini. Sebagian besar alat pengembangan, termasuk berbagai kerangka kerja, tidak memberikan pilihan bagaimana pagination akan dilakukan.
Situasi ini diperparah oleh fakta bahwa metode yang diuraikan membutuhkan dukungan ujung ke ujung dalam teknologi yang digunakan - mulai dari DBMS hingga pelaksanaan permintaan AJAX di browser dengan pengguliran tanpa henti. Alih-alih hanya menentukan nomor halaman, sekarang Anda harus menentukan satu set kunci untuk semua halaman sekaligus.
Namun, jumlah kerangka kerja yang mendukung pagination kunci secara bertahap meningkat. Inilah yang saat ini:
(Catatan: beberapa tautan dihapus karena faktanya pada saat penerjemahan beberapa perpustakaan tidak diperbarui dari 2017-2018. Jika tertarik, Anda dapat melihat sumbernya.)
Pada saat inilah bantuan Anda dibutuhkan. Jika Anda sedang mengembangkan atau mendukung kerangka kerja yang entah bagaimana menggunakan pagination, maka saya bertanya, saya mendesak, saya berdoa Anda untuk membuat dukungan asli untuk pagination utama. Jika Anda memiliki pertanyaan atau butuh bantuan, saya akan dengan senang hati membantu ( forum , Twitter , form kontak ) (catatan: dalam pengalaman saya dengan Marcus, saya dapat mengatakan bahwa dia sangat antusias menyebarkan topik ini).
Jika Anda menggunakan solusi siap pakai yang menurut Anda layak dukungan untuk pagination kunci, buat permintaan atau bahkan tawarkan solusi turnkey, jika memungkinkan. Anda juga dapat menentukan artikel ini di tautan.
Kesimpulan
Alasan mengapa pendekatan yang sederhana dan bermanfaat seperti pagination kunci tidak tersebar luas adalah tidak sulit dalam implementasi teknis atau membutuhkan upaya yang besar. Alasan utamanya adalah banyak yang terbiasa melihat dan bekerja dengan offset - pendekatan ini ditentukan oleh standar itu sendiri.
Akibatnya, beberapa orang berpikir tentang mengubah pendekatan ke pagination, dan karena ini, dukungan instrumental dari kerangka kerja dan perpustakaan berkembang dengan buruk. Oleh karena itu, jika Anda dekat dengan ide dan tujuan pagination yang tidak repot, bantu sebarkan!
Sumber: https://use-the-index-luke.com/no-offset
Dikirim oleh: Markus Winand