Pengguna ClickHouse sudah tahu bahwa keuntungan terbesarnya adalah pemrosesan kueri analitik berkecepatan tinggi. Tetapi klaim seperti ini perlu dikonfirmasi dengan pengujian kinerja yang andal. Itulah yang ingin kita bicarakan hari ini.
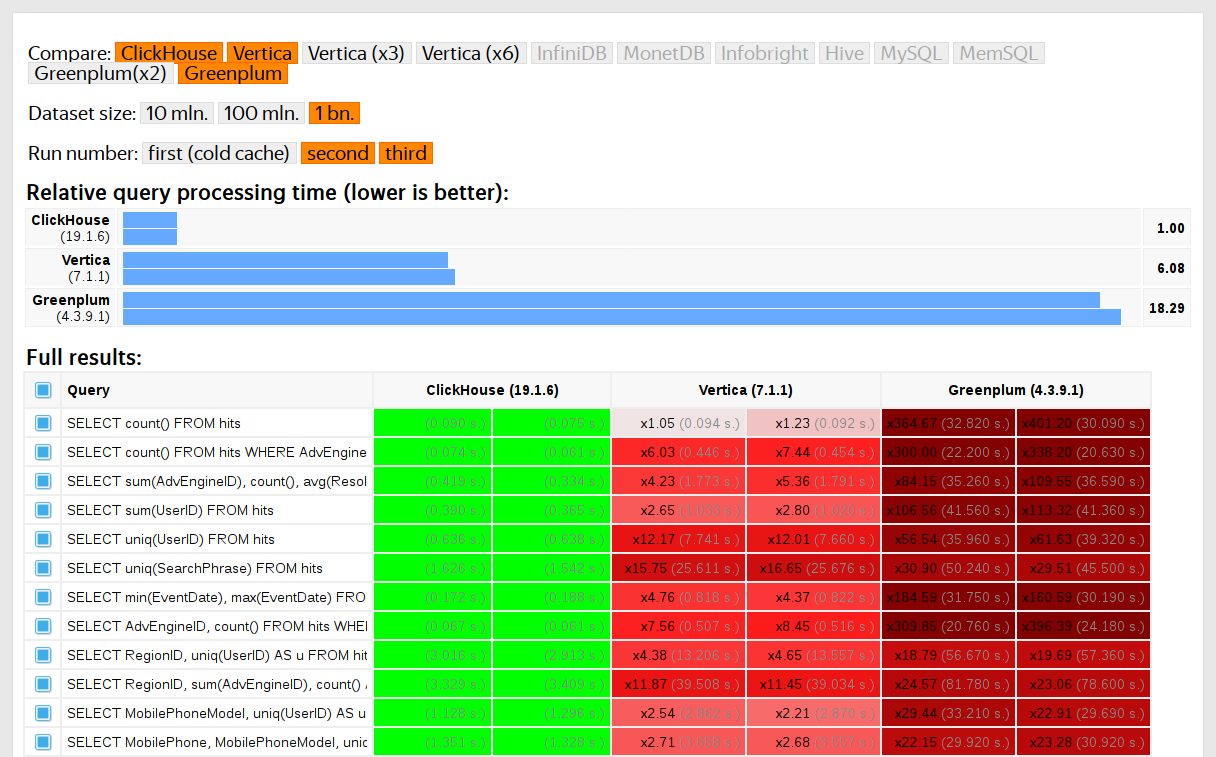
Kami mulai menjalankan tes pada 2013, jauh sebelum produk tersedia sebagai sumber terbuka. Saat itu, sama seperti sekarang, perhatian utama kami adalah kecepatan pemrosesan data di Yandex.Metrica. Kami telah menyimpan data itu di ClickHouse sejak Januari 2009. Sebagian data telah ditulis ke database mulai tahun 2012, dan sebagian dikonversi dari
OLAPServer dan Metrage (struktur data yang sebelumnya digunakan oleh Yandex.Metrica). Untuk pengujian, kami mengambil subset pertama secara acak dari data selama 1 miliar tampilan halaman. Yandex.Metrica tidak memiliki pertanyaan apa pun pada saat itu, jadi kami membuat pertanyaan yang menarik bagi kami, menggunakan semua cara yang mungkin untuk memfilter, menggabungkan, dan mengurutkan data.
Kinerja ClickHouse dibandingkan dengan sistem serupa seperti Vertica dan MonetDB. Untuk menghindari bias, pengujian dilakukan oleh karyawan yang tidak berpartisipasi dalam pengembangan ClickHouse, dan kasus khusus dalam kode tidak dioptimalkan hingga semua hasil diperoleh. Kami menggunakan pendekatan yang sama untuk mendapatkan set data untuk pengujian fungsional.
Setelah ClickHouse dirilis sebagai sumber terbuka pada tahun 2016, orang-orang mulai mempertanyakan tes ini.
Kekurangan tes pada data pribadi
Tes kinerja kami:
- Tidak dapat direproduksi secara independen karena mereka menggunakan data pribadi yang tidak dapat dipublikasikan. Beberapa tes fungsional tidak tersedia untuk pengguna eksternal karena alasan yang sama.
- Perlu pengembangan lebih lanjut. Serangkaian tes perlu diperluas secara substansial untuk mengisolasi perubahan kinerja pada bagian-bagian sistem.
- Jangan dijalankan berdasarkan per-komit atau untuk permintaan penarikan individual. Pengembang eksternal tidak dapat memeriksa kode mereka untuk regresi kinerja.
Kita bisa menyelesaikan masalah ini dengan membuang tes lama dan menulis yang baru berdasarkan data terbuka, seperti
data penerbangan untuk Amerika Serikat dan
naik taksi di New York . Atau kita bisa menggunakan tolok ukur seperti TPC-H, TPC-DS, dan
Star Schema Benchmark . Kerugiannya adalah bahwa data ini sangat berbeda dari data Yandex.Metrica, dan kami lebih suka menyimpan pertanyaan pengujian.
Mengapa penting menggunakan data nyata
Kinerja seharusnya hanya diuji pada data nyata dari lingkungan produksi. Mari kita lihat beberapa contoh.
Contoh 1Katakanlah Anda mengisi basis data dengan nomor pseudorandom yang didistribusikan secara merata. Kompresi data tidak akan berfungsi dalam kasus ini, meskipun kompresi data sangat penting untuk database analitik. Tidak ada solusi peluru perak untuk tantangan memilih algoritma kompresi yang tepat dan cara yang tepat untuk mengintegrasikannya ke dalam sistem, karena kompresi data memerlukan kompromi antara kecepatan kompresi dan dekompresi dan potensi efisiensi kompresi. Tetapi sistem yang tidak bisa mengompres data dijamin kalah. Jika pengujian Anda menggunakan angka acak acak yang didistribusikan secara merata, faktor ini diabaikan, dan hasilnya akan terdistorsi.
Intinya: Data uji harus memiliki rasio kompresi yang realistis.
Saya membahas optimasi algoritma kompresi data ClickHouse di
posting sebelumnya .
Contoh 2Katakanlah kami tertarik pada kecepatan eksekusi query SQL ini:
SELECT RegionID, uniq(UserID) AS visitors FROM test.hits GROUP BY RegionID ORDER BY visitors DESC LIMIT 10
Ini adalah permintaan khas untuk Yandex.Metrica. Apa yang mempengaruhi kecepatan pemrosesan?
- Bagaimana GROUP BY dijalankan.
- Struktur data mana yang digunakan untuk menghitung fungsi agregat uniq.
- Berapa banyak RegionID yang berbeda dan berapa banyak RAM yang diperlukan oleh setiap negara bagian dari fungsi uniq.
Tetapi faktor penting lainnya adalah bahwa jumlah data didistribusikan secara tidak merata antar wilayah. (Ini mungkin mengikuti hukum kekuasaan. Saya meletakkan distribusi pada grafik log-log, tapi saya tidak bisa mengatakannya dengan pasti.) Jika ini masalahnya, penting bahwa keadaan fungsi agregat uniq dengan nilai penggunaan yang lebih sedikit memori yang sangat sedikit. Ketika ada banyak kunci agregasi yang berbeda, setiap byte dihitung. Bagaimana kita bisa mendapatkan data yang dihasilkan yang memiliki semua properti ini? Solusi yang jelas adalah menggunakan data nyata.
Banyak DBMS menerapkan struktur data HyperLogLog untuk perkiraan COUNT (DISTINCT), tetapi tidak ada yang bekerja dengan sangat baik karena struktur data ini menggunakan jumlah memori yang tetap. ClickHouse memiliki fungsi yang menggunakan
kombinasi tiga struktur data yang berbeda , tergantung pada ukuran kumpulan data.
Intinya: Data uji harus mewakili sifat distribusi dari data nyata dengan cukup baik, yang berarti kardinalitas (jumlah nilai berbeda per kolom) dan kardinalitas lintas-kolom (jumlah nilai yang berbeda dihitung di beberapa kolom yang berbeda).
Contoh 3Alih-alih menguji kinerja DBMS ClickHouse, mari kita ambil sesuatu yang lebih sederhana, seperti tabel hash. Untuk tabel hash, penting untuk memilih fungsi hash yang tepat. Ini tidak sepenting std :: unordered_map, karena ini adalah tabel hash berdasarkan chaining dan bilangan prima digunakan sebagai ukuran array. Implementasi pustaka standar dalam GCC dan Dentang menggunakan fungsi hash sepele sebagai fungsi hash default untuk tipe numerik. Namun, std :: unordered_map bukanlah pilihan terbaik saat kami mencari kecepatan maksimum. Dengan tabel hash pengalamatan terbuka, kita tidak bisa hanya menggunakan fungsi hash standar. Memilih fungsi hash yang tepat menjadi faktor penentu.
Sangat mudah untuk menemukan tes kinerja tabel hash menggunakan data acak yang tidak mempertimbangkan fungsi hash yang digunakan. Ada juga banyak tes fungsi hash yang berfokus pada kecepatan perhitungan dan kriteria kualitas tertentu, meskipun mereka mengabaikan struktur data yang digunakan. Tetapi kenyataannya adalah bahwa tabel hash dan HyperLogLog memerlukan kriteria kualitas fungsi hash yang berbeda.
Anda dapat mempelajari lebih lanjut tentang ini di
"Bagaimana tabel hash bekerja di ClickHouse" (presentasi dalam bahasa Rusia). Informasi ini sedikit ketinggalan zaman, karena tidak mencakup
Tabel Swiss .
Tantangan
Tujuan kami adalah untuk memperoleh data untuk menguji kinerja yang memiliki struktur yang sama dengan data Yandex.Metrica dengan semua properti yang penting untuk tolok ukur, tetapi sedemikian rupa sehingga tidak ada jejak pengguna situs web nyata dalam data ini. Dengan kata lain, data harus dianonimkan dan masih dipertahankan:
- Rasio kompresi.
- Kardinalitas (jumlah nilai yang berbeda).
- Kardinalitas timbal balik antara beberapa kolom berbeda.
- Properti distribusi probabilitas yang dapat digunakan untuk pemodelan data (misalnya, jika kami percaya bahwa wilayah didistribusikan menurut hukum daya, maka eksponen - parameter distribusi - harus kira-kira sama untuk data buatan dan untuk data nyata).
Bagaimana kita bisa mendapatkan rasio kompresi yang sama untuk data? Jika LZ4 digunakan, substring dalam data biner harus diulang kira-kira pada jarak yang sama dan pengulangan harus kira-kira sama panjangnya. Untuk ZSTD, entropi per byte juga harus bersamaan.
Tujuan utamanya adalah membuat alat yang tersedia untuk umum yang dapat digunakan siapa saja untuk menganonimkan set data mereka untuk publikasi. Ini akan memungkinkan kami untuk melakukan debug dan menguji kinerja pada data orang lain yang serupa dengan data produksi kami. Kami juga ingin agar data yang dihasilkan menarik.
Namun, ini adalah persyaratan yang sangat longgar dan kami tidak berencana untuk menulis pernyataan masalah formal atau spesifikasi untuk tugas ini.
Kemungkinan solusi
Saya tidak ingin membuatnya terdengar seperti masalah ini sangat penting. Itu tidak pernah benar-benar dimasukkan dalam perencanaan dan tidak ada yang punya niat untuk mengerjakannya. Saya hanya terus berharap bahwa suatu ide akan muncul suatu hari, dan tiba-tiba saya akan berada dalam suasana hati yang baik dan dapat menunda semuanya sampai nanti.
Model probabilistik eksplisit
Gagasan pertama adalah mengambil setiap kolom dalam tabel dan menemukan keluarga distribusi probabilitas yang memodelkannya, kemudian menyesuaikan parameter berdasarkan statistik data (pemasangan model) dan menggunakan distribusi yang dihasilkan untuk menghasilkan data baru. Generator nomor pseudorandom dengan benih yang telah ditentukan dapat digunakan untuk mendapatkan hasil yang dapat direproduksi.
Rantai Markov dapat digunakan untuk bidang teks. Ini adalah model yang akrab yang dapat diimplementasikan secara efektif.
Namun, itu membutuhkan beberapa trik:
- Kami ingin menjaga kesinambungan rangkaian waktu. Ini berarti bahwa untuk beberapa jenis data, kita perlu memodelkan perbedaan antara nilai-nilai tetangga, bukan nilai itu sendiri.
- Untuk memodelkan "kardinalitas bersama" kolom kita juga harus secara eksplisit mencerminkan dependensi antar kolom. Misalnya, biasanya ada sangat sedikit alamat IP per ID pengguna, jadi untuk menghasilkan alamat IP kami akan menggunakan nilai hash ID pengguna sebagai seed dan juga menambahkan sejumlah kecil data pseudorandom lainnya.
- Kami tidak yakin bagaimana mengekspresikan ketergantungan yang sering dikunjungi pengguna yang sama dengan URL domain yang cocok pada waktu yang bersamaan.
Semua ini dapat ditulis dalam "script" C ++ dengan distribusi dan dependensi yang dikodekan dengan keras. Namun, model Markov diperoleh dari kombinasi statistik dengan smoothing dan menambahkan noise. Saya mulai menulis skrip seperti ini, tetapi setelah menulis model eksplisit untuk sepuluh kolom, itu menjadi sangat membosankan - dan tabel "hit" di Yandex.Metrica memiliki lebih dari 100 kolom pada tahun 2012.
EventTime.day(std::discrete_distribution<>({ 0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random)); EventTime.hour(std::discrete_distribution<>({ 13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random)); EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random)); EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random)); UInt64 UserID = hash(4, powerLaw(5000, 1.1)); UserID = UserID / 10000000000ULL * 10000000000ULL + static_cast<time_t>(EventTime) + UserID % 1000000; random_with_seed.seed(powerLaw(5000, 1.1)); auto get_random_with_seed = [&]{ return random_with_seed(); };
Pendekatan ini gagal. Jika saya berusaha lebih keras, mungkin skripnya sudah siap sekarang.
Keuntungan:
- Kesederhanaan konseptual.
Kekurangan:
- Diperlukan banyak pekerjaan.
- Solusinya hanya berlaku untuk satu jenis data.
Dan saya lebih suka solusi yang lebih umum yang dapat digunakan untuk data Yandex.Metrica serta untuk mengaburkan data lainnya.
Bagaimanapun, solusi ini dapat ditingkatkan. Alih-alih memilih model secara manual, kita dapat mengimplementasikan katalog model dan memilih yang terbaik di antara mereka (paling cocok ditambah beberapa bentuk regularisasi). Atau mungkin kita bisa menggunakan model Markov untuk semua jenis bidang, bukan hanya untuk teks. Ketergantungan antara data juga dapat diekstraksi secara otomatis. Ini akan membutuhkan penghitungan
entropi relatif (jumlah relatif informasi) antar kolom. Alternatif yang lebih sederhana adalah menghitung kardinalitas relatif untuk setiap pasangan kolom (sesuatu seperti "berapa banyak nilai A yang berbeda rata-rata untuk nilai tetap B"). Misalnya, ini akan memperjelas bahwa URLDomain sepenuhnya tergantung pada URL, dan bukan sebaliknya.
Tetapi saya juga menolak ide ini, karena ada terlalu banyak faktor untuk dipertimbangkan dan akan terlalu lama untuk ditulis.
Jaringan saraf
Seperti yang telah saya sebutkan, tugas ini tidak tinggi pada daftar prioritas - tidak ada yang berpikir untuk mencoba menyelesaikannya. Tetapi seperti nasib yang beruntung, kolega kami Ivan Puzirevsky mengajar di Sekolah Tinggi Ekonomi. Dia bertanya kepada saya apakah saya memiliki masalah menarik yang akan berfungsi sebagai topik tesis yang cocok untuk murid-muridnya. Ketika saya menawarinya yang satu ini, dia meyakinkan saya bahwa potensinya. Jadi saya memberikan tantangan ini kepada seorang pria baik "di jalan" Sharif (dia memang harus menandatangani NDA untuk mengakses data, meskipun).
Saya membagikan semua ide saya dengannya tetapi menekankan bahwa tidak ada batasan tentang bagaimana masalah itu dapat diselesaikan, dan pilihan yang baik adalah mencoba pendekatan yang tidak saya ketahui, seperti menggunakan LSTM untuk menghasilkan data teks. Ini tampak menjanjikan setelah menemukan artikel
Efektivitas Yang Tidak Beralasan dari Jaringan Syaraf Berulang .
Tantangan pertama adalah kita perlu menghasilkan data terstruktur, bukan hanya teks. Tetapi tidak jelas apakah jaringan saraf berulang dapat menghasilkan data dengan struktur yang diinginkan. Ada dua cara untuk menyelesaikan ini. Solusi pertama adalah menggunakan model terpisah untuk menghasilkan struktur dan "pengisi" dan hanya menggunakan jaringan saraf untuk menghasilkan nilai. Namun pendekatan ini ditunda dan kemudian tidak pernah selesai. Solusi kedua adalah dengan hanya menghasilkan dump TSV sebagai teks. Pengalaman menunjukkan bahwa beberapa baris dalam teks tidak cocok dengan struktur, tetapi baris ini dapat dibuang saat memuat data.
Tantangan kedua adalah bahwa jaringan saraf berulang menghasilkan urutan data, dan dengan demikian ketergantungan pada data harus mengikuti urutan urutan. Tetapi dalam data kami, urutan kolom berpotensi terbalik untuk dependensi di antara mereka.
Kami tidak melakukan apa pun untuk menyelesaikan masalah ini.
Saat musim panas mendekat, kami memiliki skrip Python yang berfungsi pertama yang menghasilkan data. Sekilas kualitas data tampak layak:

Namun, kami mengalami beberapa kesulitan:
- Ukuran model ini sekitar satu gigabyte. Kami mencoba membuat model untuk data yang berukuran beberapa gigabytes (untuk permulaan). Fakta bahwa model yang dihasilkan sangat besar menimbulkan kekhawatiran. Apakah mungkin untuk mengekstraksi data nyata yang dilatihnya? Tidak mungkin. Tapi saya tidak tahu banyak tentang pembelajaran mesin dan jaringan saraf, dan saya belum membaca kode Python pengembang ini, jadi bagaimana saya bisa yakin? Ada beberapa artikel yang diterbitkan pada saat itu tentang cara mengompres jaringan saraf tanpa kehilangan kualitas, tetapi tidak diimplementasikan. Di satu sisi, ini tampaknya tidak menjadi masalah serius, karena kita dapat memilih keluar dari menerbitkan model dan hanya menerbitkan data yang dihasilkan. Di sisi lain, jika terjadi overfitting, data yang dihasilkan dapat berisi beberapa bagian dari data sumber.
- Pada mesin dengan CPU tunggal, kecepatan pembuatan data sekitar 100 baris per detik. Tujuan kami adalah menghasilkan setidaknya satu miliar baris. Perhitungan menunjukkan bahwa ini tidak akan selesai sebelum tanggal pertahanan tesis. Tidak masuk akal untuk menggunakan perangkat keras tambahan, karena tujuannya adalah membuat alat pembuatan data yang dapat digunakan oleh siapa saja.
Sharif mencoba menganalisis kualitas data dengan membandingkan statistik. Antara lain, ia menghitung frekuensi karakter berbeda yang terjadi pada sumber data dan dalam data yang dihasilkan. Hasilnya menakjubkan: karakter yang paling sering adalah Ð dan Ñ.
Tapi jangan khawatir tentang Sharif. Dia berhasil mempertahankan tesisnya dan kemudian kami dengan senang hati melupakan semuanya.
Mutasi data terkompresi
Mari kita asumsikan bahwa pernyataan masalah telah direduksi menjadi satu titik: kita perlu menghasilkan data yang memiliki rasio kompresi yang sama dengan data sumber, dan data harus didekompresi pada kecepatan yang sama. Bagaimana kita bisa mencapai ini? Kita perlu mengedit byte data terkompresi secara langsung! Ini memungkinkan kita untuk mengubah data tanpa mengubah ukuran data yang dikompresi, ditambah semuanya akan bekerja dengan cepat. Saya ingin mencoba ide ini segera, terlepas dari kenyataan bahwa masalah yang dipecahkannya tidak sama dengan yang kami mulai. Tapi begitulah adanya.
Jadi bagaimana kita mengedit file terkompresi? Katakanlah kita hanya tertarik pada LZ4. Data terkompresi LZ4 terdiri dari urutan, yang pada gilirannya adalah string byte tidak dikompresi (literal), diikuti oleh salinan pertandingan:
- Literal (salin N byte berikut apa adanya).
- Cocok dengan panjang pengulangan minimum 4 (ulangi N byte yang ada di file pada jarak M).
Sumber data:
Hello world Hello .
Data terkompresi (contoh sewenang-wenang):
literals 12 "Hello world " match 5 12 .
Dalam file terkompresi, kita membiarkan "cocok" apa adanya, dan mengubah nilai byte dalam "literal". Akibatnya, setelah dekompresi, kami mendapatkan file di mana semua urutan berulang setidaknya 4 byte panjang juga diulang pada jarak yang sama, tetapi mereka terdiri dari set byte yang berbeda (pada dasarnya, file yang dimodifikasi tidak mengandung satu pun byte yang diambil dari file sumber).
Tetapi bagaimana kita mengubah byte? Jawabannya tidak jelas, karena selain jenis kolom, data juga memiliki struktur internal, implisit yang ingin kami pertahankan. Misalnya, teks sering disimpan dalam pengkodean UTF-8, dan kami ingin data yang dihasilkan juga valid UTF-8. Saya mengembangkan heuristik sederhana yang melibatkan memenuhi beberapa kriteria:
- Null byte dan karakter kontrol ASCII disimpan apa adanya.
- Beberapa karakter tanda baca tetap apa adanya.
- ASCII dikonversi ke ASCII dan untuk yang lainnya bit yang paling signifikan dipertahankan (atau set eksplisit pernyataan "jika" ditulis untuk panjang UTF-8 yang berbeda). Dalam kelas satu byte nilai baru diambil secara acak.
- Fragmen seperti
https:// dipelihara, jika tidak terlihat agak konyol.
Satu-satunya peringatan untuk pendekatan ini adalah bahwa model data adalah sumber data itu sendiri, yang berarti tidak dapat dipublikasikan. Model ini hanya cocok untuk menghasilkan jumlah data yang tidak lebih besar dari sumbernya. Sebaliknya, pendekatan sebelumnya menyediakan model yang memungkinkan menghasilkan data dengan ukuran sewenang-wenang.
Contoh untuk URL:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
Hasilnya positif dan datanya menarik, tetapi ada sesuatu yang tidak beres. URL mempertahankan struktur yang sama, tetapi di beberapa di antaranya terlalu mudah untuk mengenali "yandex" atau "avito" (pasar yang populer di Rusia), jadi saya membuat heuristik yang menukar beberapa byte di sekitar.
Ada juga kekhawatiran lain. Misalnya, informasi sensitif mungkin berada di kolom FixedString dalam representasi biner dan berpotensi terdiri dari karakter kontrol ASCII dan tanda baca, yang saya putuskan untuk dipertahankan. Namun, saya tidak mempertimbangkan tipe data.
Masalah lain adalah bahwa jika sebuah kolom menyimpan data dalam format "length, value" (ini adalah bagaimana kolom String disimpan), bagaimana cara memastikan bahwa panjangnya tetap benar setelah mutasi? Ketika saya mencoba untuk memperbaikinya, saya langsung kehilangan minat.
Permutasi acak
Sayangnya, masalahnya tidak terpecahkan. Kami melakukan beberapa percobaan, dan itu menjadi lebih buruk. Satu-satunya yang tersisa adalah duduk dan tidak melakukan apa pun dan menjelajahi web secara acak, karena sihirnya telah hilang. Untungnya, saya menemukan halaman yang
menjelaskan algoritma untuk rendering kematian karakter utama di game Wolfenstein 3D.

Animasi ini dilakukan dengan sangat baik - layar dipenuhi dengan darah. Artikel ini menjelaskan bahwa ini sebenarnya permutasi acak pseudorandom. Permutasi acak dari sekumpulan elemen adalah transformasi bijective (satu-ke-satu) yang dipilih secara acak, atau pemetaan di mana masing-masing dan setiap elemen turunan berhubungan dengan tepat satu elemen asli (dan sebaliknya). Dengan kata lain, ini adalah cara untuk secara acak beralih melalui semua elemen dari kumpulan data. Dan itulah proses yang ditunjukkan dalam gambar: setiap piksel diisi dalam urutan acak, tanpa pengulangan. Jika kita hanya memilih piksel acak pada setiap langkah, itu akan memakan waktu lama untuk sampai ke yang terakhir.
Gim ini menggunakan algoritma yang sangat sederhana untuk permutasi pseudorandom yang disebut linear feedback shift register (
LFSR ). Mirip dengan generator nomor pseudorandom, permutasi acak, atau lebih tepatnya keluarga mereka, dapat secara kriptografis kuat ketika diparetrize oleh kunci. Inilah yang kita butuhkan untuk transformasi data. Namun, detailnya mungkin lebih sulit. Sebagai contoh, enkripsi kriptografis yang kuat dari N byte ke N byte dengan kunci yang ditentukan sebelumnya dan vektor inisialisasi tampaknya akan bekerja untuk permutasi pseudorandom satu set string N-byte. Memang, ini adalah transformasi satu-ke-satu dan tampaknya acak. Tetapi jika kita menggunakan transformasi yang sama untuk semua data kita, hasilnya mungkin rentan terhadap analisis kripto karena vektor inisialisasi dan nilai kunci yang sama digunakan beberapa kali. Ini mirip dengan mode operasi
Codebook Elektronik untuk cipher blok.
Apa cara yang mungkin untuk mendapatkan permutasi pseudorandom? Kita dapat mengambil transformasi satu-ke-satu yang sederhana dan membangun fungsi kompleks yang terlihat acak. Berikut adalah beberapa transformasi satu-ke-satu favorit saya:
- Perkalian dengan bilangan ganjil (seperti bilangan prima yang besar) dalam aritmatika komplemen dua.
- Xorshift:
x ^= x >> N - CRC-N, di mana N adalah jumlah bit dalam argumen.
Sebagai contoh, tiga perkalian dan dua operasi xorshift digunakan untuk finalizer
murmurhash . Operasi ini adalah permutasi pseudorandom. Namun, saya harus menunjukkan bahwa fungsi hash tidak harus satu-ke-satu (bahkan hash dari N bits ke N bits).
Atau inilah
contoh menarik lainnya
dari teori bilangan dasar dari situs web Jeff Preshing.
Bagaimana kita bisa menggunakan permutasi pseudorandom untuk menyelesaikan masalah kita? Kita dapat menggunakannya untuk mengubah semua bidang angka sehingga kita dapat mempertahankan kardinalitas dan kardinalitas bersama dari semua kombinasi bidang. Dengan kata lain, COUNT (DISTINCT) akan mengembalikan nilai yang sama seperti sebelum transformasi, dan selanjutnya, dengan GROUP BY.
Perlu dicatat bahwa menjaga semua kardinalitas agak bertentangan dengan tujuan anonimisasi data kami. Katakanlah seseorang tahu bahwa sumber data untuk sesi situs berisi pengguna yang mengunjungi situs dari 10 negara yang berbeda, dan mereka ingin menemukan pengguna itu dalam data yang diubah. Data yang diubah juga menunjukkan bahwa pengguna mengunjungi situs dari 10 negara yang berbeda, yang memudahkan untuk mempersempit pencarian. Bahkan jika mereka mengetahui apa yang ditransformasikan oleh pengguna, itu tidak akan sangat berguna, karena semua data lain juga telah ditransformasikan, sehingga mereka tidak akan dapat mengetahui situs apa yang dikunjungi oleh pengguna atau hal lainnya. Namun aturan ini bisa diterapkan dalam sebuah rantai. Misalnya, jika seseorang tahu bahwa situs web yang paling sering terjadi dalam data kami adalah Yandex, dengan Google di tempat kedua, mereka hanya dapat menggunakan peringkat untuk menentukan pengidentifikasi situs yang diubah yang sebenarnya berarti Yandex dan Google. Tidak ada yang mengejutkan tentang ini, karena kami bekerja dengan pernyataan masalah informal dan kami hanya mencoba untuk menemukan keseimbangan antara penganoniman data (menyembunyikan informasi) dan menjaga properti data (pengungkapan informasi). Untuk informasi tentang cara mendekati masalah anonimisasi data dengan lebih andal, baca
artikel ini.
Selain menjaga kardinalitas asli dari nilai, saya juga ingin menjaga urutan besarnya nilai. Maksud saya adalah bahwa jika sumber data berisi angka di bawah 10, maka saya ingin angka yang diubah juga kecil. Bagaimana kita bisa mencapai ini?
Sebagai contoh, kita dapat membagi satu set nilai yang mungkin menjadi kelas ukuran dan melakukan permutasi dalam setiap kelas secara terpisah (mempertahankan kelas ukuran). Cara termudah untuk melakukan ini adalah dengan mengambil kekuatan terdekat dari dua atau posisi bit paling signifikan dalam jumlah sebagai kelas ukuran (ini adalah hal yang sama). Angka 0 dan 1 akan selalu tetap apa adanya. Angka 2 dan 3 terkadang akan tetap apa adanya (dengan probabilitas 1/2) dan kadang-kadang akan ditukar (dengan probabilitas 1/2). Himpunan angka 1024. 2047 akan dipetakan ke salah satu dari 1024! varian (faktorial), dan sebagainya. Untuk nomor yang ditandatangani, kami akan menyimpannya.
Juga diragukan apakah kita membutuhkan fungsi satu-ke-satu. Kita mungkin bisa menggunakan fungsi hash yang kuat secara kriptografis. Transformasi tidak akan satu-ke-satu, tetapi kardinalitas akan mendekati sama.
Namun, kita memang membutuhkan permutasi acak yang kuat secara kriptografis sehingga ketika kita mendefinisikan kunci dan memperoleh permutasi dengan kunci itu, akan sulit untuk mengembalikan data asli dari data yang disusun ulang tanpa mengetahui kunci.
Ada satu masalah: selain tidak tahu apa-apa tentang jaringan saraf dan pembelajaran mesin, saya juga tidak tahu apa-apa tentang kriptografi. Itu menyisakan keberanian saya. Saya masih membaca halaman web acak, dan menemukan tautan di
Hackers News untuk diskusi di halaman Fabien Sanglard. Itu memiliki tautan ke
posting blog oleh pengembang Redis Salvatore Sanfilippo yang berbicara tentang menggunakan cara generik yang luar biasa untuk mendapatkan permutasi acak, yang dikenal sebagai
jaringan Feistel .
Jaringan Feistel bersifat iteratif, terdiri dari putaran. Setiap putaran adalah transformasi luar biasa yang memungkinkan Anda untuk mendapatkan fungsi satu-ke-satu dari fungsi apa pun. Mari kita lihat cara kerjanya.
- Bit argumen dibagi menjadi dua bagian:
arg: xxxxyyyy
arg_l : xxxx
arg_r : yyyy - Setengah kanan menggantikan kiri. Sebagai gantinya kami menempatkan hasil XOR pada nilai awal setengah kiri dan hasil fungsi yang diterapkan pada nilai awal setengah kanan, seperti ini:
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F( arg_r )
Ada juga klaim bahwa jika kita menggunakan fungsi pseudorandom kriptografi yang kuat untuk F dan menerapkan putaran Feistel setidaknya 4 kali, kita akan mendapatkan permutasi pseudorandom kuat secara kriptografis.
Ini seperti keajaiban: kami mengambil fungsi yang menghasilkan sampah acak berdasarkan data, memasukkannya ke jaringan Feistel, dan kami sekarang memiliki fungsi yang menghasilkan sampah acak berdasarkan data, tetapi belum dapat dibalik!
Jaringan Feistel adalah jantung dari beberapa algoritma enkripsi data. Apa yang akan kita lakukan adalah enkripsi, hanya saja itu sangat buruk. Ada dua alasan untuk ini:
- Kami mengenkripsi nilai individual secara independen dan dengan cara yang sama, mirip dengan mode operasi Codebook Elektronik.
- Kami menyimpan informasi tentang urutan besarnya (kekuatan terdekat dua) dan tanda nilai, yang berarti bahwa beberapa nilai tidak berubah sama sekali.
Dengan cara ini kita dapat mengaburkan bidang angka sambil mempertahankan properti yang kita butuhkan. Misalnya, setelah menggunakan LZ4, rasio kompresi harus tetap kira-kira sama, karena nilai duplikat dalam data sumber akan diulang dalam data yang dikonversi, dan pada jarak yang sama satu sama lain.
Model Markov
Model teks digunakan untuk kompresi data, input prediksi, pengenalan ucapan, dan pembuatan string acak. Model teks adalah distribusi probabilitas dari semua string yang mungkin. Katakanlah kita memiliki distribusi probabilitas khayalan dari semua buku yang bisa ditulis manusia. Untuk menghasilkan string, kami hanya mengambil nilai acak dengan distribusi ini dan mengembalikan string yang dihasilkan (buku acak yang bisa ditulis manusia). Tetapi bagaimana kita mengetahui distribusi probabilitas dari semua string yang mungkin?
Pertama, ini membutuhkan terlalu banyak informasi. Ada 256 ^ 10 string yang mungkin yang panjangnya 10 byte, dan akan membutuhkan cukup banyak memori untuk secara eksplisit menulis tabel dengan probabilitas setiap string. Kedua, kami tidak memiliki statistik yang cukup untuk menilai distribusi secara akurat.
Inilah sebabnya kami menggunakan distribusi probabilitas yang diperoleh dari statistik kasar sebagai model teks. Sebagai contoh, kita bisa menghitung probabilitas setiap huruf yang terjadi dalam teks, dan kemudian menghasilkan string dengan memilih setiap huruf berikutnya dengan probabilitas yang sama. Model primitif ini berfungsi, tetapi senarnya masih sangat tidak alami.
Untuk sedikit memperbaiki model, kita juga dapat menggunakan probabilitas bersyarat dari kemunculan huruf jika didahului oleh huruf N tertentu. N adalah konstanta yang ditentukan sebelumnya. Katakanlah N = 5 dan kami menghitung probabilitas huruf "e" yang muncul setelah huruf "compr". Model teks ini disebut model Orde-N Markov.
P(cat a | cat) = 0.8
P(cat b | cat) = 0.05
P(cat c | cat) = 0.1
...Mari kita lihat bagaimana model Markov bekerja di situs web
Hay Kranen . Tidak seperti jaringan saraf LSTM, model hanya memiliki memori yang cukup untuk konteks kecil fixed-length N, sehingga mereka menghasilkan teks yang lucu dan tidak masuk akal. Model Markov juga digunakan dalam metode primitif untuk menghasilkan spam, dan teks yang dihasilkan dapat dengan mudah dibedakan dari yang asli dengan menghitung statistik yang tidak sesuai dengan model. Ada satu keuntungan: model Markov bekerja jauh lebih cepat daripada jaringan saraf, yang memang kita butuhkan.
Contoh untuk Judul (contoh kami dalam bahasa Turki karena data yang digunakan):
Hyunday Butter'dan anket shluha - Politika head manşetleri | STALKER BOXER Çiftede book - Yanudistkarışmanlı Mı Kanal | League el Digitalika Haberler Haberleri - Haberlerisi - Hotel dengan Centry'ler Neden babah.com
Kami dapat menghitung statistik dari sumber data, membuat model Markov, dan menghasilkan data baru dengannya. Perhatikan bahwa model ini perlu diperhalus untuk menghindari pengungkapan informasi tentang kombinasi langka dalam data sumber, tetapi ini bukan masalah. Saya menggunakan kombinasi model dari 0 hingga N. Jika statistik tidak mencukupi untuk model pesanan N, model N - 1 digunakan sebagai gantinya.
Tetapi kami masih ingin mempertahankan kardinalitas data. Dengan kata lain, jika data sumber memiliki 123456 nilai URL unik, hasilnya akan memiliki jumlah nilai unik yang kira-kira sama. Kita dapat menggunakan generator nomor acak yang diinisialisasi secara deterministik untuk mencapai hal ini. Cara termudah untuk melakukan ini adalah dengan menggunakan fungsi hash dan menerapkannya ke nilai asli. Dengan kata lain, kita mendapatkan hasil pseudorandom yang secara eksplisit ditentukan oleh nilai asli.
Persyaratan lain adalah bahwa data sumber mungkin memiliki banyak URL berbeda yang dimulai dengan awalan yang sama tetapi tidak identik. Misalnya:
https://www.yandex.ru/images/cats/?id=xxxxxx . Kami ingin hasilnya juga memiliki URL yang semuanya dimulai dengan awalan yang sama, tetapi berbeda. Misalnya:
http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx . Sebagai generator angka acak untuk menghasilkan karakter berikutnya menggunakan model Markov, kami akan mengambil fungsi hash dari jendela bergerak 8 byte pada posisi yang ditentukan (alih-alih mengambilnya dari seluruh string).
https://www.yandex.ru/ images/c ats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][g g ggg][h]...
hash(" images/c ") % total_count: ^
http://ftp.google.kz/c g ...Ternyata persis seperti yang kita butuhkan. Inilah contoh judul halaman:
PhotoFunia - Haber7 - Hava mükemment.net Oynamak içinde şaşıracak haber, Oyunu Oynanılmaz • apród.hu kínálatában - RT Bahasa Arab
PhotoFunia - Kinobar.Net - apród: Ingyenes | Posti
PhotoFunia - Peg Perfeo - Castika, Sıradışı Deniz Lokoning Your Code, Sire Eminema.tv/
PhotoFunia - TUT.BY - Anak Anda Ayakkanın Son Dakika Spor,
PhotoFunia - film besar, Del Meireles offilim, Samsung DealeXtreme Değerler NEWSru.com.tv, Smotri.com Mobile yapmak Okey
PhotoFunia 5 | Galaksi, gt, duplikat anal bilgi yarak Ceza RE050A V-Stranç
PhotoFunia :: Miami olacaksını yerel Haberler Oyun Young video
PhotoFunia Monstelli'nin En İyi kisa.com.tr –Star Thunder Ekranı
PhotoFunia Seks - Politika, Ekonomi, Spor GTA SANAYİ VE
PhotoFunia Taker-Rating Bintang TV Resmi Söylenen Yatağa każdy dzież wierzchnie
PhotoFunia TourIndex.Marketime Oyunu Oyna Geldolları Mynet Spor, Magazin, Haberler dan Habereri, Solvia, korkusuz Ev SahneTv
PhotoFunia todo di Gratis Perky Parti'nin yapıyı bu fotogram
PhotoFunian Dünyasın takımız halles en kulları - TEZ
Hasil
Setelah mencoba empat metode, saya bosan dengan masalah ini sehingga tiba saatnya untuk memilih sesuatu, menjadikannya alat yang dapat digunakan, dan mengumumkan solusinya. Saya memilih solusi yang menggunakan permutasi acak dan model Markov parametrized oleh kunci. Ini diimplementasikan sebagai program
clickhouse-obfuscator , yang sangat mudah digunakan. Input adalah dump tabel dalam
format yang didukung (seperti CSV atau JSONEachRow), dan parameter baris perintah menentukan struktur tabel (nama dan tipe kolom) dan kunci rahasia (string apa pun, yang dapat Anda lupakan segera setelah digunakan). Outputnya adalah jumlah baris yang sama dari data yang dikaburkan.
Program ini diinstal dengan clickhouse-client, tidak memiliki dependensi, dan bekerja pada hampir semua rasa Linux. Anda bisa menerapkannya pada sembarang database dump, bukan hanya ClickHouse. Misalnya, Anda dapat menghasilkan data uji dari database MySQL atau PostgreSQL atau membuat database pengembangan yang mirip dengan database produksi Anda.
clickhouse-obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse-obfuscator --help
Tentu saja, semuanya tidak begitu dipotong dan dikeringkan, karena data yang diubah oleh program ini hampir sepenuhnya reversibel. Pertanyaannya adalah apakah mungkin untuk melakukan transformasi terbalik tanpa mengetahui kuncinya. Jika transformasi menggunakan algoritma kriptografi, operasi ini akan sesulit pencarian kasar. Meskipun transformasi menggunakan beberapa primitif kriptografi, mereka tidak digunakan dengan cara yang benar, dan data rentan terhadap metode analisis tertentu. Untuk menghindari masalah, masalah ini dicakup dalam dokumentasi untuk program (akses menggunakan
--help ).
Pada akhirnya, kami mengubah set data yang kami butuhkan
untuk pengujian fungsional dan kinerja serta Yandex VP publikasi keamanan data yang disetujui.
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xzclickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xzPengembang non-Yandex menggunakan data ini untuk pengujian kinerja nyata ketika mengoptimalkan algoritma di dalam ClickHouse. Pengguna pihak ketiga dapat memberi kami data yang dikaburkan sehingga kami dapat membuat ClickHouse lebih cepat bagi mereka. Kami juga merilis patokan terbuka independen untuk penyedia perangkat keras dan cloud di atas data ini:
clickhouse.yandex/benchmark_hardware.html