 Berikut adalah daftar terbaru dari "barang" Unicode yang paling indah, serta paket dan sumber daya
Berikut adalah daftar terbaru dari "barang" Unicode yang paling indah, serta paket dan sumber dayaUnicode luar biasa! Sebelum kemunculannya, komunikasi internasional melelahkan: masing-masing mendefinisikan karakternya sendiri yang diperluas di bagian atas ASCII (yang disebut halaman kode). Ini menciptakan konflik. Bayangkan saja bahwa Jerman harus bernegosiasi dengan Korea, di mana halaman kode-nya. Untungnya, Unicode muncul dan memperkenalkan standar umum. Unicode 8.0 mencakup lebih dari 120.000 karakter dari lebih dari 129 skrip. Baik modern dan kuno, dan masih belum didekripsi. Unicode mendukung teks dari kiri ke kanan dan dari kanan ke kiri, overlay karakter dan termasuk berbagai simbol budaya, politik, agama dan emoji. Unicode luar biasa manusia, dan kemampuannya sangat diremehkan.
Isi
Pengantar singkat
Karakter apa yang termasuk dalam Unicode Standard?
Standar Unicode mendefinisikan kode untuk karakter dalam bahasa modern utama. Ini adalah skrip alfabet Eropa, skrip Timur Tengah dari kanan ke kiri dan banyak skrip Asia.
Standar ini juga berisi tanda baca, diakritik, simbol matematika, simbol teknis, panah, dingbats, emoji, dll. Ini menyediakan kode untuk diakritik yang mengubah tanda karakter, seperti tildes (~). Mereka digunakan dalam kombinasi dengan yang dasar untuk mewakili karakter beraksen (misalnya, ñ). Secara umum, Unicode versi 9.0 menyediakan kode untuk 128.172 karakter dari huruf dunia, kumpulan ideogram, dan koleksi karakter.
Karakter yang paling umum ditempatkan di titik kode 64K pertama, area ruang kode yang disebut pesawat multibahasa utama, atau singkatnya BMP. Ada enam belas pesawat tambahan lain yang tersedia untuk penyandian karakter lain, dengan lebih dari 850.000 titik kode yang tidak digunakan. Mereka mungkin berguna untuk menambahkan karakter baru ke versi standar masa depan.
Standar Unicode juga menyimpan poin kode untuk penggunaan pribadi. Vendor atau pengguna akhir dapat menunjuk mereka di sistem mereka sendiri untuk karakter mereka atau menggunakannya dengan font khusus. BMP memiliki 6400 titik kode untuk penggunaan pribadi dan 131 poin tambahan 06 06 lainnya untuk penggunaan pribadi, jika 6400 tidak cukup untuk aplikasi tertentu.
Penyandian karakter Unicode
Standar pengkodean karakter tidak hanya menentukan identitas setiap karakter dan nilai numerik atau titik kode, tetapi juga bagaimana nilai ini direpresentasikan dalam bit.
Standar Unicode mendefinisikan tiga bentuk pengkodean yang memungkinkan transmisi data yang sama: byte, kata, dan kata ganda (mis., 8, 16, atau 32 bit per unit kode). Ketiga bentuk menyandikan kumpulan karakter umum yang sama dan dapat secara efektif dikonversi satu sama lain tanpa kehilangan data. Konsorsium Unicode sepenuhnya mendukung penggunaan salah satu bentuk pengodean ini sebagai cara yang disepakati untuk menerapkan Standar Unicode.
UTF-8 populer untuk HTML dan protokol serupa. UTF-8 adalah cara mengubah semua karakter Unicode ke variabel byte-length encoding. Keuntungannya adalah bahwa karakter Unicode yang sesuai dengan set ASCII yang dikenal memiliki nilai byte yang sama dengan ASCII, dan karakter Unicode yang dikonversi ke UTF-8 dapat digunakan dengan banyak perangkat lunak yang ada tanpa modifikasi perangkat lunak utama.
UTF-16 populer di banyak lingkungan di mana diperlukan untuk menyeimbangkan akses efisien ke karakter dengan penyimpanan ekonomis. Ini cukup kompak, dan semua karakter yang sering digunakan ditempatkan dalam satu blok kode 16-bit, sementara semua karakter lain tersedia melalui pasangan blok kode 16-bit.
UTF-32 berguna di mana jumlah memori tidak menjadi masalah, tetapi membutuhkan akses ke karakter dalam kode lebar tetap tunggal. Di sini, setiap karakter Unicode dikodekan dalam blok kode 32-bit tunggal.
Ketiga bentuk pengkodean tidak memerlukan lebih dari 4 byte (atau 32 bit) untuk setiap karakter.
Bicara tentang angka
Set karakter Unicode dibagi menjadi 17 segmen utama (pesawat), yang selanjutnya dibagi menjadi beberapa blok. Di setiap pesawat ada tempat untuk 65.536 (2
16 ) poin kode, yang menciptakan total 1.114.112 poin kode. Ada dua "pesawat penggunaan pribadi" (No. 16 dan No. 17) yang dialokasikan untuk digunakan atas kebijakan perusahaan / pengguna. Mereka memiliki 131.072 poin kode.
Pesawat pertama disebut pesawat multibahasa utama atau BMP. Ini berisi poin kode dari U + 0000 ke U + FFFF, yaitu karakter yang paling umum digunakan. Enam belas pesawat yang tersisa (U + 010000 → U + 10FFFF) disebut tambahan atau astral.
Pasangan pengganti UTF-16
Simbol di luar bidang utama, seperti tetragrammaton yang berarti pusat (U + 1D306), dapat dikodekan dalam UTF-16 dengan hanya dua unit kode 16-bit: 0xD834 0xDF06. Ini disebut pasangan pengganti. Harap dicatat bahwa pasangan pengganti hanya mewakili satu karakter.
Unit kode pertama dari pasangan pengganti selalu dalam kisaran dari 0xD800 ke 0xDBFF dan disebut bagian atas dari pasangan tersebut.
Unit kode kedua dari pasangan pengganti selalu dalam kisaran dari 0xDC00 hingga 0xDFFF dan disebut bagian bawah pasangan.
Matthias Binens
Pasangan pengganti: Representasi satu simbol abstrak, yang terdiri dari urutan dua unit kode 16-bit, di mana nilai pertama pasangan adalah unit kode pengganti atas dan yang kedua adalah unit kode pengganti yang lebih rendah. Pasangan pengganti hanya digunakan dalam UTF-16.
Unicode 8.0 Bab 3.8 - Pengganti
Perhitungan pasangan pengganti
Karakter Unicode "Tumpukan kotoran" (U + 1F4A9) di UTF-16 harus dikodekan sebagai pasangan pengganti, yaitu, dua pengganti. Untuk mengonversi titik kode apa pun menjadi pasangan pengganti, gunakan algoritma ini (dalam JavaScript). Perlu diingat bahwa kami menggunakan notasi heksadesimal.
var High_Surrogate = function(Code_Point){ return Math.floor((Code_Point - 0x10000) / 0x400) + 0xD800 }; var Low_Surrogate = function(Code_Point){ return (Code_Point - 0x10000) % 0x400 + 0xDC00 };
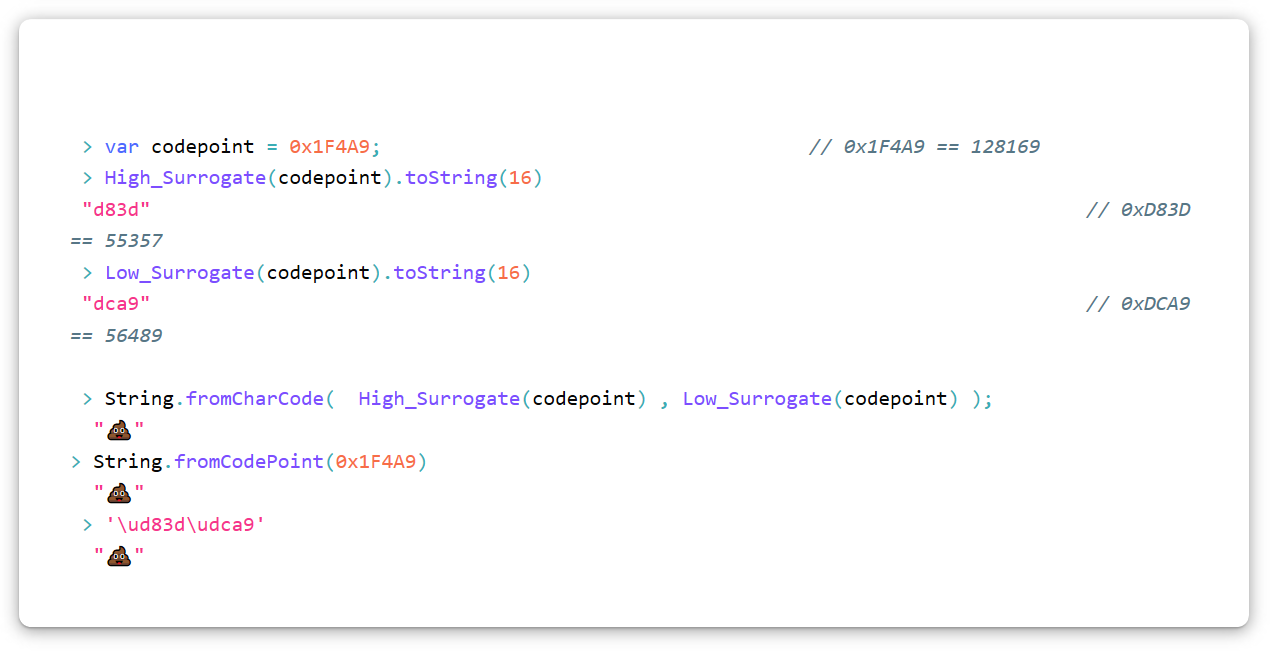
Komposisi dan dekomposisi
Unicode termasuk mekanisme untuk mengubah bentuk karakter, yang sangat memperluas set mesin terbang yang didukung. Ini berlaku untuk diakritik yang dapat dikombinasikan. Mereka dimasukkan setelah karakter utama. Beberapa tanda diakritik dapat diterapkan pada tanda yang sama. Unicode juga berisi versi pra-kompilasi dari sebagian besar kombinasi ini untuk penggunaan normal.
Beberapa urutan karakter juga dapat direpresentasikan sebagai karakter tunggal yang disebut karakter yang dikompilasi sebelumnya, alias karakter gabungan. Misalnya, karakter [ü] dapat dikodekan sebagai satu-satunya titik kode U + 00FC atau sebagai karakter dasar U + 0075 (u), diikuti oleh karakter non-mandiri U + 0308 (¨). Standar Unicode mengkodekan karakter majemuk untuk kompatibilitas dengan standar yang ditetapkan, seperti Latin 1, yang mencakup banyak karakter majemuk, seperti [ü] dan [ñ].
Karakter majemuk dapat diperluas untuk konsistensi atau analisis. Misalnya, ketika mengurutkan menurut abjad, simbol [ü] dapat didekomposisi menjadi [u] diikuti oleh simbol non-independen [¨]. Setelah dekomposisi seperti itu, algoritma lebih mudah untuk bekerja dengan urutan karakter. Ini membuatnya lebih mudah untuk mengurutkan dalam bahasa di mana pengubah karakter tidak mempengaruhi urutan abjad. Standar Unicode menetapkan
urutan penguraian untuk semua karakter komposit. Ini juga mendefinisikan bentuk normalisasi untuk memberikan representasi karakter yang unik.
Unicode Myths
Dari slide presentasi Mark Davis "Myths of Unicode . "- Unicode hanya kode 16-bit . - Beberapa orang secara keliru percaya bahwa Unicode hanya kode 16-bit, di mana setiap karakter menempati 16 bit, dan karenanya ada 65.536 karakter yang mungkin. Sebenarnya, ini tidak sepenuhnya benar. Ini adalah mitos Unicode yang paling umum, jadi jika Anda juga berpikiran seperti itu sebelumnya, jangan berkecil hati.
- Anda dapat mengambil titik kode apa pun yang tidak digunakan untuk kebutuhan Anda . - Tidak. Suatu hari nanti tempat ini akan diganti oleh simbol lain. Sebagai gantinya, gunakan pesawat untuk penggunaan pribadi atau area tanpa karakter di setiap bidang di mana tidak akan ada karakter menurut standar.
- Setiap titik kode Unicode mewakili karakter . - Tidak. Ada banyak titik tanpa karakter (FFFE, FFFF, 1FFFE, dll.) Selain itu, ganti titik kode, titik kode pribadi dan tidak terpakai, serta kontrol / pemformatan "karakter" (RLM, ZWNJ, dll.)
- Unicode kehabisan ruang . - Jika diisi secara linear, itu akan berakhir pada 2140. Tetapi tempat itu tidak mengisi secara linear. Rencana masa depan lihat di sini .
- Semua karakter dicocokkan satu lawan satu . - Tidak. Opsinya adalah:
- Satu ke banyak: (β → SS)
- Mengingat konteksnya: (... Σ ← → ... ς dan pada saat yang sama ... ΣΤ ... ← → ... στ ...)
- Berdasarkan lokal: (I ← → ı dan pada saat yang sama İ ← → i)
Penyandian Aplikasi Unicode
Kode sumber
Daftar karakter luar biasa.
Berbagi dokumen dapat dengan cepat mengubah pengeditan menjadi pertarungan rap tertulis, yang dilakukan oleh pengaturan manajer yang semakin membingungkan dari U + 202a hingga U + 202eKarakter khusus
Konsorsium Unicode telah menerbitkan
diagram tanda baca umum tempat Anda dapat menemukan informasi lebih lanjut.
Tunggu ... apa yang baru saja saya baca?Pengidentifikasi variabel dapat mencakup spasi!
U + 3164 placeholder Hangul ditampilkan sebagai ruang yang luas. Jika karakter jelas tidak
didukung dalam rendering , maka ditampilkan sebagai benar-benar tidak terlihat (dan tidak memakan ruang, yaitu, "lebar nol"). Ini berarti Anda tidak akan pernah melihat karakter pengganti karakter jelek ( ).
Saya belum yakin mengapa U + 3164 diperintahkan untuk berperilaku seperti ini. Menariknya, U + 3164 ditambahkan ke Unicode dalam versi 1.1 (1993) - sehingga spesialis Konsorsium punya banyak waktu untuk memikirkannya. Bagaimanapun, berikut adalah beberapa contoh.
> var ᅟ = 'foo'; undefined > ᅟ 'foo' > var ㅤ= alert; undefined > var foo = 'bar' undefined > if ( foo ===ㅤ`baz` ){}
** Catatan: ** Saya menguji rendering U + 3164 di Ubuntu dan OS X dengan parameter berikut: `node`,` php`, `ruby`,` python3.5`, `scala`,` vim`, `cat` , `chrome` +` github gist '. Atom adalah satu-satunya sistem yang gagal dengan (salah) menampilkan bidang kosong. Saya belum memeriksa kode di Emacs dan Sublime. Seperti yang saya pahami, Konsorsium Unicode tidak akan menetapkan ulang atau mengubah nama karakter atau poin kode, tetapi dapat dibujuk untuk mengubah properti karakter, seperti ID_Start dan ID_Continue.Pengubah
Zero Width Combiner (ZWJ) adalah karakter yang tidak dapat dicetak dalam set komputer dari beberapa font yang kompleks, seperti Arab atau font India. Ketika ditempatkan di antara dua karakter yang seharusnya tidak terhubung, ZWJ memaksa mereka untuk mencetak dalam bentuk gabungan.
Zero Width Disconnector (ZWNJ) adalah karakter yang tidak dapat ditulis dalam set tulisan berbasis komputer dengan ligatur. Ketika ditempatkan di antara dua karakter yang jika tidak akan bergabung ke dalam ligatur, ZWNJ memaksa mereka untuk mencetak dalam bentuk final dan asli masing-masing. Bertindak sebagai ruang, tetapi digunakan ketika diinginkan untuk menjaga kata-kata dekat satu sama lain atau menggabungkan kata dengan morfemnya.
> 'a' "a" > 'a\u{0308}' "ä" > 'a\u{20DE}\u{0308}' "a⃞̈" > 'a\u{20DE}\u{0308}\u{20DD}' "a⃞̈⃝"
Huruf besar mengubah benturan
Tabrakan konversi huruf kecil
Keanehan dan pemecahan masalah
- Panjang garis biasanya ditentukan oleh jumlah titik kode . Ini berarti bahwa pasangan pengganti akan dianggap dua karakter. Beberapa diakritik dapat ditumpangkan pada simbol:
a + ̈ == ̈a . Ini meningkatkan panjang string, hanya menghasilkan satu karakter.
- Demikian pula, inversi string sering menjadi tugas yang tidak sepele . Sekali lagi, pasangan pengganti dan diakritik harus dibalik bersama. ES Reverser menawarkan solusi yang cukup bagus.
- Perbandingan huruf besar dan kecil tidak selalu cocok . Mereka dapat diekspresikan dalam hubungan seperti itu:
- Satu ke banyak: (ß → SS)
- Mengingat konteksnya: (... Σ ← → ... ς dan ... ΣΤ ... ← → ... στ ...)
- Berdasarkan lokal: (I ← → ı dan İ ← → i)
Satu banding banyak
Sebagian besar karakter di bawah ini mengekspresikan pemetaan satu-ke-banyak mereka dalam huruf besar dan lainnya dalam huruf kecil. Pada prinsipnya, daftar ini dapat dibagi menjadi dua bagian.
Paket dan pustaka hebat
- PhantomScript -: ghost :: flashlight: Melaksanakan JavaScript yang tak terlihat dan rekayasa sosial
- ESReverser - Penanganan string JavaScript berbasis Unicode .
- mimic - Penyalahgunaan Unicode
- python-ftfy - Mencoba membuat representasi teks yang benar dan lengkap maksimum yang diterima dalam Unicode.
- vim-troll-stopper - Melindungi kode Anda dari troll unicode.
Emoji
Unicode (diversity), . .
, , . — . :
, .
8.0 ( 2015 ) - . , ( , FitzpatrickSkinType.pdf). .
Unicode
, \u{1F466}\u{1F3FE} .

+

→


JavaScript (ES6)
, ID_START , . , ID_CONTINUE , .
CSS .
<!-- place this within the document head --> <meta charset="UTF-8" /> <div class="ಠ_ಠ">You do not have access to this page.</div> <div class="">Your changes have been saved successfully!</div>
.ಠ_ಠ { border: 1px solid #f00; } . { background: lightgreen; }
HTML
HTML- , , .
, HTML .
:
function testBegin(str){ try{ eval(`document.createElement( '${str}' );`) return true; } catch(e){ return false; } } function testContinue(str){ try{ eval(`document.createElement( 'a${str}' );`) return true; } catch(e){ return false; } }
:
TrueType OpenType UTF-8, 65 535 . 1,1 UTF-8, .
256 .

, () (CJK). , , « ».
. 17- .
:
- — - .
- — , .
- — .
- — , . .
- , — , . , .
- — , . , [Ä] [A] [¨].
- — .
- — , , . .
- — , .
- — .
: c codepoints.net .