Artikel ini adalah terjemahan dari artikel saya di media -
Memulai dengan Danau Data , yang ternyata cukup populer, mungkin karena kesederhanaannya. Oleh karena itu, saya memutuskan untuk menulisnya dalam bahasa Rusia dan menambahkannya sedikit sehingga orang sederhana yang bukan spesialis data dapat memahami apa itu data warehouse (DW) dan apa Data Lake itu dan bagaimana mereka bergaul .
Mengapa saya ingin menulis tentang data lake? Saya telah bekerja dengan data dan analitik selama lebih dari 10 tahun, dan sekarang saya pasti bekerja dengan data besar di Amazon Alexa AI di Cambridge, yang berada di Boston, walaupun saya sendiri tinggal di Victoria di Pulau Vancouver dan sering mengunjungi Boston, Seattle dan Vancouver, dan kadang-kadang bahkan di Moskow, saya berbicara di konferensi. Juga, dari waktu ke waktu saya menulis, tetapi saya menulis terutama dalam bahasa Inggris, dan sudah menulis
beberapa buku , juga saya perlu berbagi tren analitik dari Amerika Utara, dan kadang-kadang saya menulis dalam
telegram .
Saya selalu bekerja dengan gudang data, dan sejak 2015 saya mulai bekerja sama dengan Amazon Web Services, dan secara umum beralih ke cloud analytics (AWS, Azure, GCP). Saya menyaksikan evolusi solusi analitik sejak 2007 dan bahkan bekerja di vendor data warehouse Teradat dan mengimplementasikannya di Sberbank, kemudian Big Data dengan Hadoop muncul. Semua orang mulai mengatakan bahwa era penyimpanan telah berlalu dan sekarang semuanya ada di Hadoop, dan kemudian mereka mulai berbicara tentang Data Lake, lagi, sekarang bahwa gudang data sudah berakhir. Tapi untungnya (mungkin untuk seseorang dan sayangnya, yang mendapat banyak uang dari pengaturan Hadoop), gudang data tidak hilang.
Pada artikel ini, kita akan mempertimbangkan apa itu data lake. Artikel ini ditujukan untuk orang-orang yang memiliki sedikit atau tidak memiliki pengalaman dengan pergudangan data.

Dalam gambar itu, Danau Bled adalah salah satu danau favorit saya, walaupun saya hanya ada di sana sekali, tetapi saya mengingatnya seumur hidup. Tetapi kita akan berbicara tentang jenis danau lain - danau data. Mungkin banyak dari Anda sudah pernah mendengar istilah ini lebih dari sekali, tetapi definisi lain tidak akan merugikan siapa pun.
Pertama-tama, berikut adalah definisi Danau Data yang paling populer:
"Penyimpanan file semua jenis data mentah yang tersedia untuk dianalisis oleh siapa saja di organisasi" - Martin Fowler.
“Jika Anda berpikir bahwa tampilan data adalah sebotol air - dimurnikan, dikemas dan dikemas untuk penggunaan yang mudah, maka danau data adalah reservoir besar air dalam bentuk aslinya. Pengguna, saya dapat mengambil air untuk diri saya sendiri, menyelam ke kedalaman, menjelajahi "- James Dixon.
Sekarang kita tahu pasti bahwa danau data adalah tentang analitik, memungkinkan kita untuk menyimpan sejumlah besar data dalam bentuk aslinya dan kita memiliki akses yang diperlukan dan nyaman ke data.
Saya sering suka menyederhanakan banyak hal, jika saya bisa mengatakan istilah yang kompleks dengan kata-kata sederhana, maka bagi diri saya sendiri saya mengerti cara kerjanya dan untuk apa. Entah bagaimana, saya memilih iPhone saya di galeri foto, dan saya sadar, jadi ini adalah danau data yang nyata, saya bahkan membuat slide untuk konferensi:

Semuanya sangat sederhana. Kami mengambil foto di telepon, foto disimpan di telepon dan dapat disimpan di iCloud (penyimpanan file di cloud). Ponsel ini juga mengumpulkan meta-data foto: apa yang ditampilkan, tag geografis, waktu. Sebagai hasilnya, kita dapat menggunakan antarmuka iPhone yang nyaman untuk menemukan foto kita dan pada saat yang sama kita bahkan melihat indikator, misalnya, ketika saya mencari foto dengan kata api, saya menemukan 3 foto dengan gambar api. Bagi saya, ini seperti alat Intelijen Bisnis yang bekerja sangat cepat dan jelas.
Dan tentu saja, kita tidak boleh melupakan keamanan (otorisasi dan otentikasi), jika tidak, data kita dapat dengan mudah masuk ke akses terbuka. Ada banyak berita tentang perusahaan besar dan perusahaan baru, di mana data masuk ke domain publik karena kelalaian pengembang dan tidak mematuhi aturan sederhana.
Bahkan gambaran sederhana seperti itu membantu kita membayangkan apa itu danau data, perbedaannya dari gudang data tradisional dan elemen utamanya:
- Pemuatan data (Penelanan) adalah komponen kunci dari danau data. Data dapat memasuki gudang data dengan dua cara - batch (pemuatan pada interval) dan streaming (aliran data).
- Penyimpanan File adalah komponen utama Data Lake. Kami membutuhkan penyimpanan agar mudah diukur, sangat andal, dan berbiaya rendah. Misalnya, di AWS, ini S3.
- Katalog dan Penelusuran - untuk menghindari Data Swamp (saat ini kami membuang semua data ke dalam satu tumpukan, dan kemudian mustahil untuk bekerja dengannya), kami perlu membuat lapisan meta-data untuk mengklasifikasikan data sehingga pengguna dapat dengan mudah temukan data yang mereka butuhkan untuk analisis. Selain itu, Anda dapat menggunakan solusi pencarian tambahan, seperti ElasticSearch. Pencarian membantu pengguna mencari data yang diinginkan melalui antarmuka yang nyaman.
- Pemrosesan (Proses) - langkah ini bertanggung jawab untuk pemrosesan dan transformasi data. Kita dapat mengubah data, mengubah strukturnya, menghapus dan banyak lagi.
- Keamanan - penting untuk menghabiskan waktu merancang solusi keamanan. Misalnya, enkripsi data selama penyimpanan, pemrosesan, dan pemuatan. Penting untuk menggunakan metode otentikasi dan otorisasi. Kesimpulannya, alat audit diperlukan.
Dari sudut pandang praktis, kita dapat mencirikan danau data dengan tiga atribut:
- Kumpulkan dan simpan apa pun yang Anda inginkan - danau data berisi semua data, baik data mentah mentah untuk jangka waktu berapa pun, dan data yang diproses / dihapus.
- Analisis mendalam - danau data memungkinkan pengguna untuk mengeksplorasi dan menganalisis data.
- Akses fleksibel - danau data menyediakan akses fleksibel untuk berbagai data dan berbagai skenario.
Sekarang kita bisa bicara tentang perbedaan antara data warehouse dan data lake. Orang biasanya bertanya:
- Tapi bagaimana dengan gudang data?
- Apakah kita mengganti data warehouse dengan data lake atau apakah kita memperluasnya?
- Apakah mungkin dilakukan tanpa data lake?
Singkatnya, tidak ada jawaban yang jelas. Itu semua tergantung pada situasi spesifik, keterampilan tim, dan anggaran. Misalnya, migrasi data warehouse ke Oracle di AWS dan pembuatan danau data oleh anak perusahaan Amazon - Woot -
Kisah data lake kami: Bagaimana Woot.com membangun danau data tanpa server di AWS .
Di sisi lain, vendor Snowflake menyatakan bahwa Anda tidak perlu lagi memikirkan data lake, karena platform data mereka (hingga 2020 itu adalah data warehouse) memungkinkan Anda untuk menggabungkan data lake dan data warehouse. Saya belum banyak bekerja dengan Snowflake, dan ini adalah produk yang benar-benar unik yang dapat melakukan ini. Harga pertanyaan adalah pertanyaan lain.
Sebagai kesimpulan, pendapat pribadi saya adalah bahwa kita masih membutuhkan data warehouse sebagai sumber data utama untuk pelaporan kami, dan kami menyimpan segala sesuatu yang tidak sesuai dengan data lake. Seluruh peran analitik adalah untuk menyediakan akses mudah ke bisnis untuk pengambilan keputusan. Bagaimanapun, pengguna bisnis bekerja lebih efisien dengan data warehouse daripada dengan data lake, misalnya, di Amazon - ada Redshift (gudang data analitik) dan Redshift Spectrum / Athena (antarmuka SQL untuk data lake dalam S3 berdasarkan Hive / Presto). Hal yang sama berlaku untuk gudang data analitik modern lainnya.
Mari kita lihat arsitektur data warehouse yang khas:
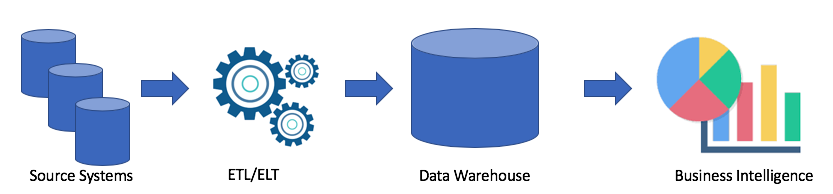
Ini adalah solusi klasik. Kami memiliki sistem sumber, menggunakan ETL / ELT kami menyalin data ke gudang data analitik dan menghubungkan solusi ke solusi Business Intelligence saya (Tableau favorit saya, dan milik Anda?).
Solusi ini memiliki kelemahan berikut:
- Operasi ETL / ELT membutuhkan waktu dan sumber daya.
- Sebagai aturan, memori untuk menyimpan data dalam gudang data analitis tidaklah murah (misalnya, Redshift, BigQuery, Teradata), karena kita perlu membeli seluruh cluster.
- Pengguna bisnis memiliki akses ke data yang dibersihkan dan sering dikumpulkan dan mereka tidak memiliki kemampuan untuk mendapatkan data mentah.
Tentu saja, itu semua tergantung pada kasus Anda. Jika Anda tidak memiliki masalah dengan data warehouse Anda, maka Anda benar-benar tidak memerlukan data lake. Tetapi ketika masalah muncul dengan kurangnya ruang, kapasitas atau harga masalah memiliki peran kunci, maka Anda dapat mempertimbangkan opsi danau data. Itu sebabnya, data lake sangat populer. Berikut adalah contoh arsitektur data lake:

Dengan menggunakan pendekatan data lake, kami memuat data mentah ke data lake kami (batch atau streaming), lalu kami memproses data sesuai kebutuhan. Danau data memungkinkan pengguna bisnis untuk membuat transformasi data mereka sendiri (ETL / ELT) atau menganalisis data dalam solusi Business Intelligence (jika Anda memiliki driver yang tepat).
Tujuan dari setiap solusi analitik adalah untuk melayani pengguna bisnis. Karena itu, kita harus selalu bekerja pada persyaratan bisnis. (Di Amazon, ini adalah salah satu prinsip - bekerja mundur).
Bekerja dengan data warehouse dan data lake, kita dapat membandingkan kedua solusi:
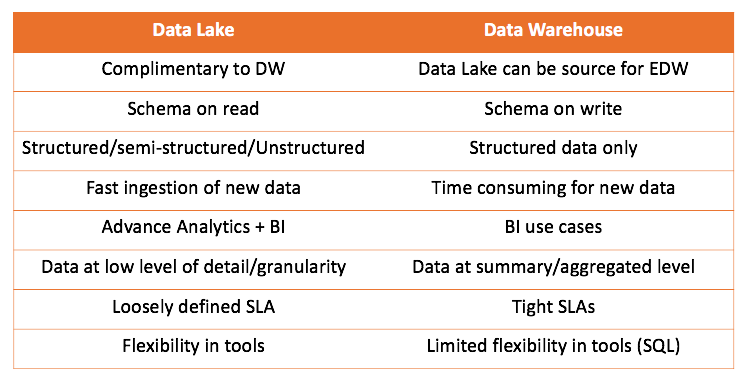
Kesimpulan utama yang dapat ditarik adalah bahwa data warehouse tidak bersaing dengan data lake, tetapi menambahnya lebih. Tetapi terserah Anda apa yang tepat untuk kasus Anda. Selalu menarik untuk mencobanya sendiri dan menarik kesimpulan yang tepat.
Saya juga ingin berbicara tentang salah satu kasus ketika saya mulai menggunakan pendekatan data lake. Semuanya cukup biasa, saya mencoba menggunakan alat ELT (kami punya Matillion ETL) dan Amazon Redshift, solusi saya berhasil, tetapi tidak cocok dengan persyaratan.
Saya perlu mengambil log web, mengubahnya, dan agregat untuk menyediakan data untuk 2 kasus:
- Tim pemasaran ingin menganalisis aktivitas bot untuk SEO
- TI ingin menonton metrik situs
Log sangat sederhana, sangat sederhana. Berikut ini sebuah contoh:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188 192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57 "GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2 arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 "Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012" 1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"
Satu file memiliki berat 1-4 megabyte.
Tetapi ada satu kesulitan. Kami memiliki 7 domain di seluruh dunia, dan dalam satu hari 7.000 ribu file dibuat. Ini bukan volume yang sangat besar, hanya 50 gigabytes. Tetapi ukuran cluster Redshift kami juga kecil (4 node). Mengunduh satu file dengan cara tradisional memerlukan waktu sekitar satu menit. Artinya, tugas itu tidak diselesaikan di dahi. Dan ini adalah kasus ketika saya memutuskan untuk menggunakan pendekatan data lake. Solusinya terlihat seperti ini:
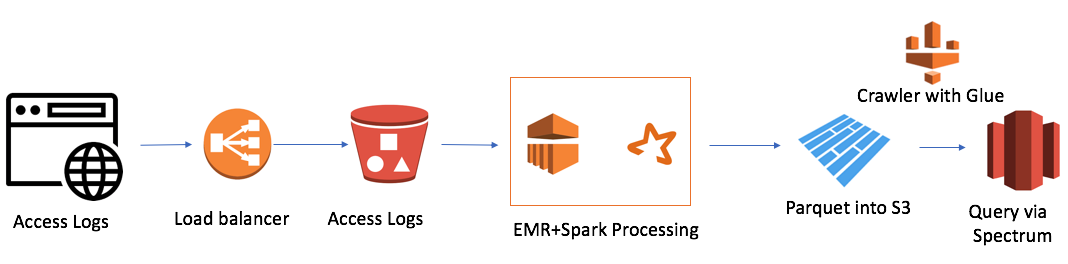
Ini cukup sederhana (saya ingin mencatat bahwa keuntungan bekerja di cloud adalah kesederhanaan). Saya menggunakan:
- AWS Elastic Map Reduce (Hadoop) sebagai Kekuatan Komputasi
- AWS S3 sebagai penyimpanan file dengan kemampuan untuk mengenkripsi data dan membatasi akses
- Spark sebagai InMemory Computing Power dan PySpark untuk Logika dan Transformasi Data
- Parket sebagai hasil dari Spark
- AWS Glue Crawler sebagai kolektor metadata tentang data dan partisi baru
- Redshift Spectrum sebagai antarmuka SQL ke danau data untuk pengguna Redshift yang ada
Gugus EMR + Spark terkecil memproses sejumlah besar file dalam 30 menit. Ada kasus lain untuk AWS, terutama banyak yang terkait dengan Alexa, di mana ada banyak data.
Baru-baru ini, saya menemukan salah satu kelemahan dari data lake adalah GDPR. Masalahnya adalah ketika klien memintanya untuk menghapus, dan data ada di salah satu file, kita tidak bisa menggunakan Bahasa Manipulasi Data dan operasi DELETE seperti dalam database.
Semoga artikel tersebut mengklarifikasi perbedaan antara data warehouse dan data lake. Jika itu menarik, saya masih bisa menerjemahkan artikel saya atau artikel profesional yang saya baca. Dan juga berbicara tentang solusi yang saya gunakan, dan arsitekturnya.