
Untuk tahun ketiga sekarang, kami telah mengadakan forum RAIF (Russian Artificial Intelligence Forum) di mana para pembicara dari dunia bisnis dan ilmu pengetahuan berbicara tentang pekerjaan mereka. Kami memutuskan untuk membagikan laporan yang paling menarik. Dalam posting ini, Andrey Filchenkov, kepala Lab Pembelajaran Mesin ITMO, menceritakan seluruh kebenaran tentang AutoML.
Dalam kerangka forum RAIF 2019 yang diadakan di Skolkovo, yang diselenggarakan oleh Jet Infosystems, saya membuat presentasi di mana saya berbicara tentang AutoML dan prospek untuk penggunaannya. Karena saya seorang ilmuwan, saya tidak harus sering berbicara di acara-acara seperti itu: biasanya saya berpartisipasi dalam konferensi ilmiah.
Salah satu bidang utama yang kami tangani adalah AutoML. Selain itu, saya adalah CTO dari dua startup kecil. Salah satunya - teknologi Statanly - menciptakan layanan AutoML dan terlibat dalam analisis data. Faktanya, saya adalah orang yang menciptakan algoritma, mengimplementasikannya, dan menggunakannya. Saya kira saya satu-satunya orang yang dapat berbicara tentang AutoML dari ketiga posisi yang memungkinkan.
Apa itu AutoML?
Pada tahun lalu, arah ini sangat menarik, dan sekarang dapat dibandingkan dengan fokus perhatian pada pembelajaran mendalam yang populer pada masanya. Munculnya pembelajaran mesin otomatis sebenarnya dapat tanggal kembali ke tahun 1976. Ada komunitas ML kecil, dan pada 2017, ia mulai mendapatkan popularitas, setelah satu tahun melampaui batas pembelajaran mesin itu sendiri. Sekarang mereka membicarakannya dalam bisnis, industri, dan di berbagai bidang lainnya. Benar, di Rusia, sayangnya, tidak semua orang bahkan dari komunitas ML membayangkan apa pembelajaran mesin otomatis. Mengapa ini terjadi?
Jawabannya sederhana - permintaan akan data ilmuwan tumbuh jauh lebih cepat daripada yang mereka dapat lulus dari universitas dan kursus yang lengkap. Pada saat yang sama, mereka menghabiskan sebagian besar waktu (hingga 80%) memilih model, mengaturnya dan menunggu sampai semuanya dihitung. Ini karena tidak ada algoritma yang sempurna - sayangnya, ada dari mereka yang memiliki ruang lingkup terbatas, dan spesialis analisis data harus memilih algoritma yang optimal untuk setiap tugas tertentu, dan kemudian mengkonfigurasinya. Di sini, banyak yang sudah tergantung pada kualifikasi analis: semakin dia tahu di bidang subjek dan memahami algoritma, semakin optimal solusinya untuk waktu tertentu. Di sinilah AutoML membantu. Sebenarnya, AutoML memungkinkan Anda untuk mengotomatisasi dan mempercepat pemilihan solusi dan tugas pembelajaran mesin.
Mari kita segera memutuskan: ada dua terkait, tetapi berbeda arah satu sama lain.
Pertama: data disajikan dalam tabel, ada label, dan ketika kita perlu mengklasifikasikannya, kita memilih objek dari daftar besar dan mengkonfigurasi parameter hipernya, dan pada saat yang sama kita dapat memproses data.
Skenario kedua lebih kompleks. Sebagai contoh, gambar, urutan, dan area di mana pembelajaran yang mendalam sekarang menjadi standar - di sini tugas menjadi sedikit lebih menarik, karena Anda dapat menemukan arsitektur baru: mereka tidak begitu mudah dipilah. Jadi, "Mencari arsitektur saraf", terlibat dalam kenyataan bahwa ia memilih jaringan yang optimal dan mengatur parameter-hyper yang memungkinkan penyelesaian satu atau masalah lain. Namun, AutoML tidak memperhitungkan semantik data. Ada juga metode yang memungkinkan Anda untuk "mengambil" deskripsi data dan menggunakannya untuk perkiraan, tetapi ini hanya membantu meningkatkan penerapan universal AutoML. Tidak masalah dari mana data berasal: apakah Anda seorang gasman, penjual es krim atau siapa pun - metodenya bersifat universal. Pada saat yang sama, AutoML memungkinkan Anda untuk membangun solusi yang paling efektif di satu sisi, memilih solusi yang kompleks dan bukan yang paling jelas bahkan untuk seorang spesialis dalam analisis data struktural, dan di sisi lain, untuk mencari dan mengoptimalkan solusi tersebut dengan lebih cepat. Dan satu hal lagi yang tidak jelas - AutoML memungkinkan untuk mempercepat penulisan kode. Di sini, misalnya:

Di sebelah kanan, kode ditulis dalam Keras untuk pengakuan MNIST, dan di sebelah kiri adalah kode untuk Auto-Keras di perpustakaan otomasi yang ditulis di bawah Keras. Perbedaannya terlihat, saat waktu penulisan disimpan.
Kelimpahan solusi yang ada (2019)
Saat ini ada sejumlah besar pustaka dan platform yang berbeda untuk analisis data otomatis, saya hanya mengutip beberapa di antaranya (pada kenyataannya, ada lebih banyak lagi).
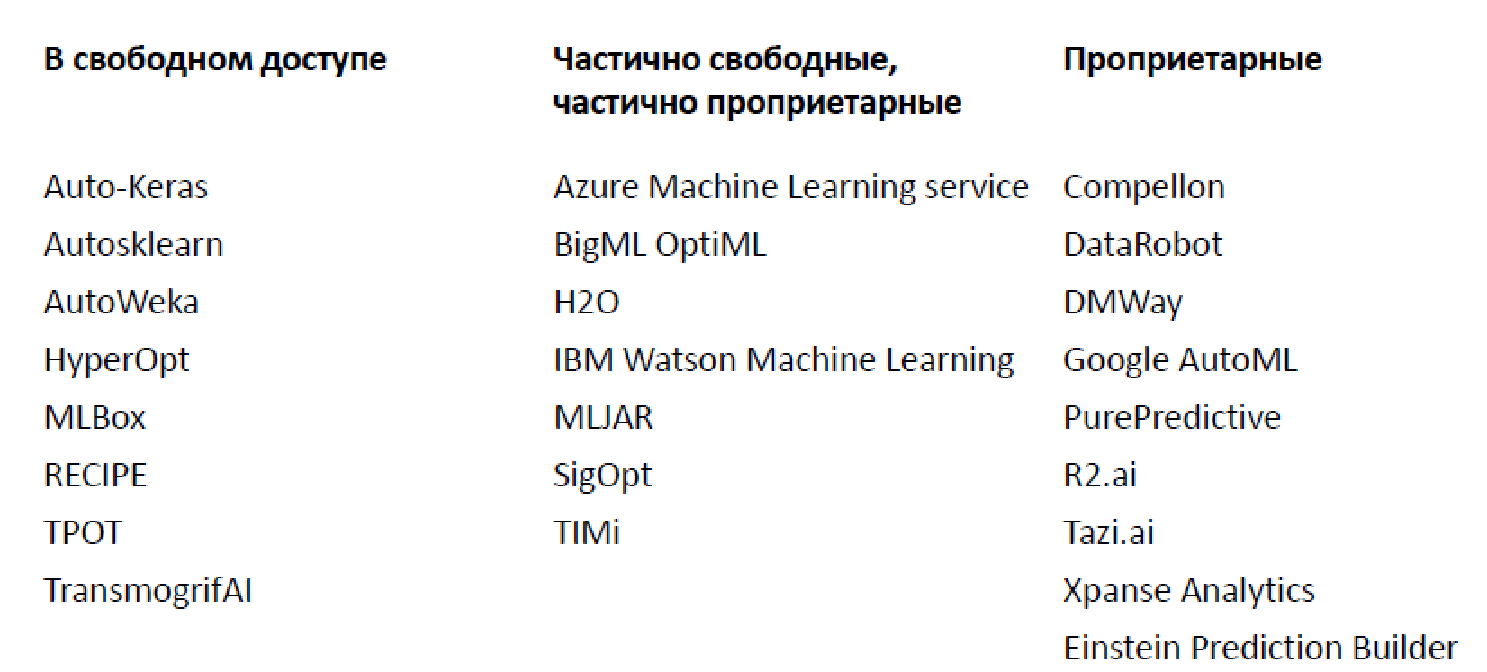
Ada keduanya terbuka, yang menerapkan fungsi terbatas, dan opsi kepemilikan. Yang paling terkenal, mungkin, adalah Google AutoML, yang tidak memberi Anda sebuah model, tetapi melatihnya pada data Anda, memungkinkan Anda untuk menggunakannya seharga $ 20 per jam. Plus, ada sejumlah besar skenario yang layak ketika fungsi dasar diberikan secara gratis, tetapi Anda harus membayar untuk komponen yang lebih maju.
Prakiraan cerah
Komunitas itu sendiri sangat memuji prospek AutoML. Sebagai contoh, Jeff Dean, seorang ilmuwan kecerdasan buatan dan seorang peneliti senior Google, mengatakan kembali pada bulan Maret 2018 bahwa keahlian pembelajaran mesin yang ada dapat digantikan oleh peningkatan seratus kali lipat dalam daya komputasi (hampir semua hal yang dilakukan oleh ilmuwan data -Anda dapat otomatis). Perkiraan yang sedikit lebih tertahan, tetapi masih menakutkan dari Gartner mengatakan bahwa pada tahun 2020, 40% ilmuwan data dapat digantikan oleh AutoML.
Sedikit tar
Seperti inilah metodologi standar CRISP DM:
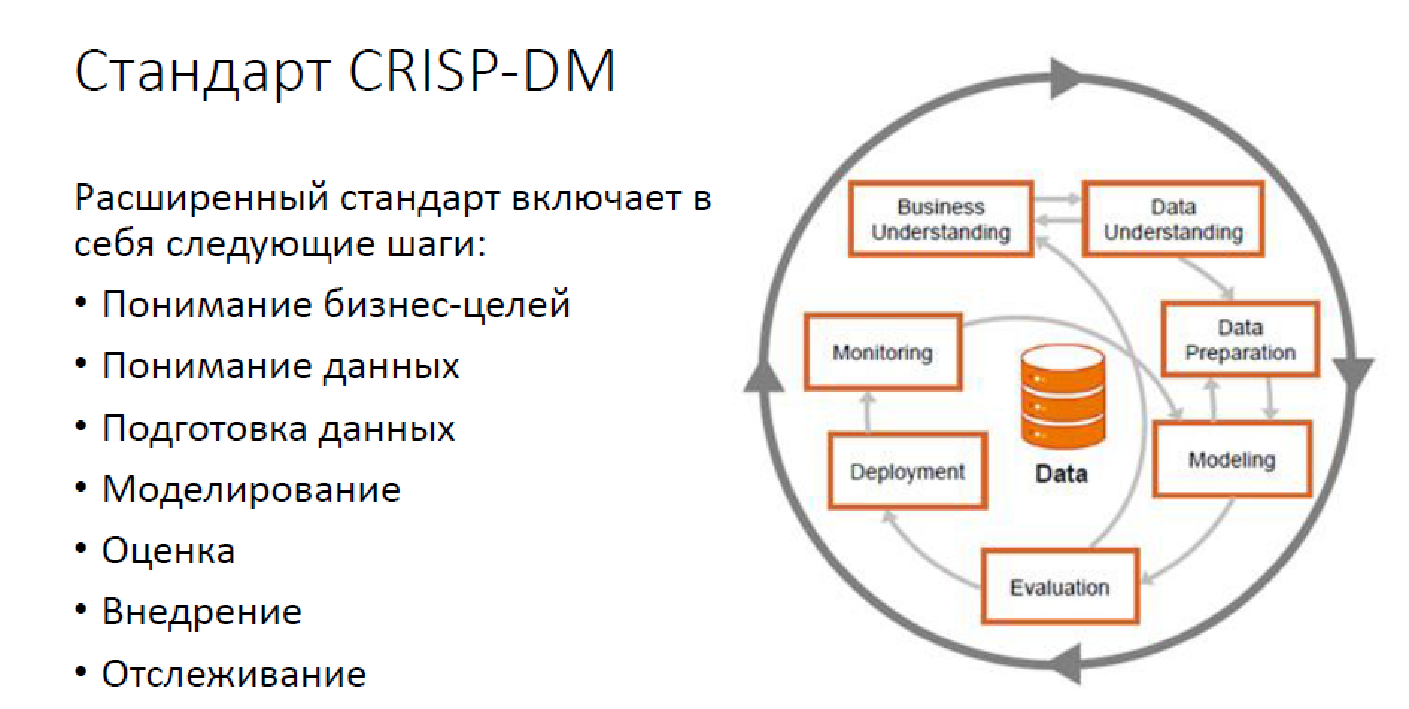
Ini adalah opsi tingkat lanjut, dengan pemantauan, namun demikian. Saat ini, menyelesaikan masalah analisis data tidak hanya menjadi model bangunan saja. Kami memiliki sejumlah besar tugas yang perlu diselesaikan, dan itu perlu diselesaikan dengan tepat oleh orang-orang.
Saat ini, dalam banyak kasus, AutoML hanya berdiri di 2,5 pilar: memilih model, mengaturnya dan kadang-kadang, ketika ternyata, memilih fitur sintesis dan hanya data.
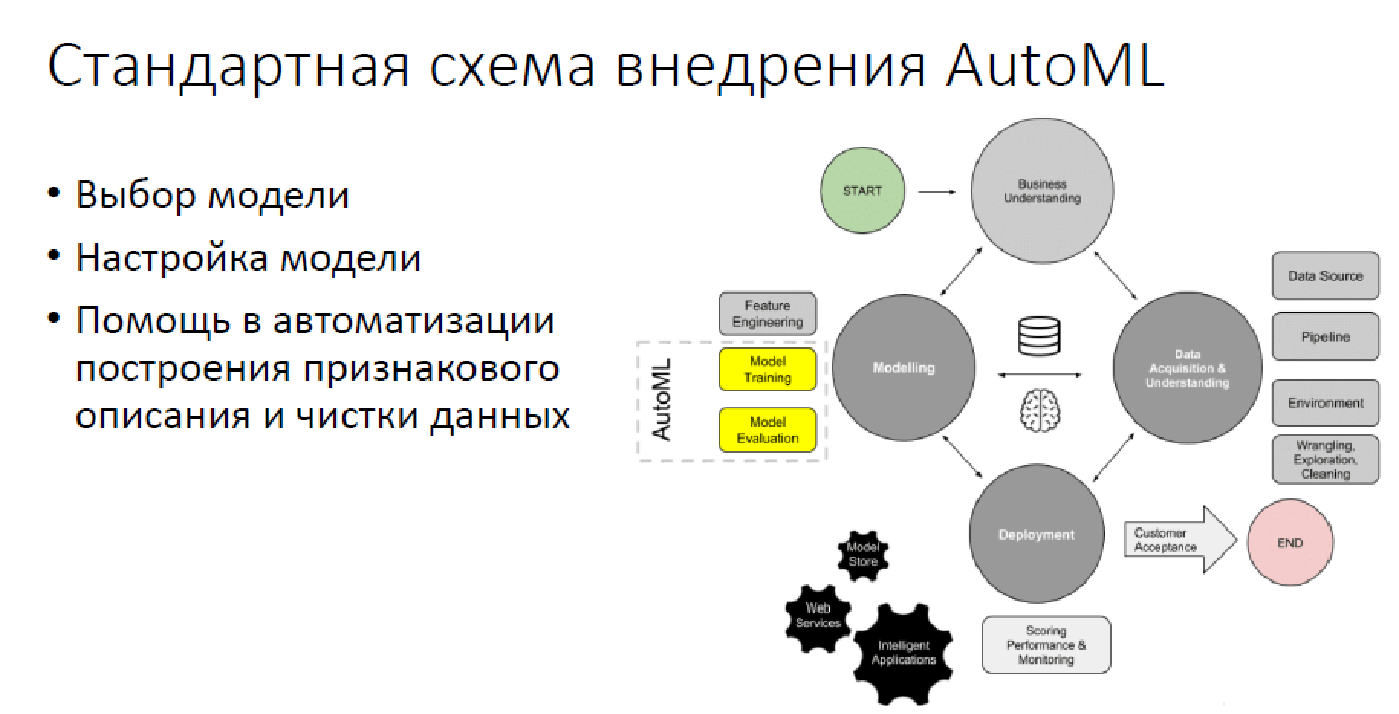
Melampaui AutoML
Sayangnya, sejumlah besar operasi dibiarkan berlebihan, yang AutoML tidak dan tidak akan dapat lakukan di masa depan yang wajar. Secara alami, ini menyiratkan transformasi tugas dari dunia nyata ke dunia analisis data: "Bagaimana memproyeksikan masalah Anda sehingga dapat diselesaikan dengan menggunakan analisis data?" Ini semua jenis pelacakan model, penilaian kualitas, mencari berbagai momen yang tidak menyenangkan - semua sehingga solusinya tidak menjadi, misalnya, terlalu tidak toleran terhadap siapa pun, karena ini sudah terjadi. Secara alami, tidak ada AutoML yang dapat mendukung solusi dan berkomunikasi dengan pelanggan. Plus, penafsiran pada saat ini tidak masuk akal.
Jadi, ini adalah alat yang sangat mudah, tetapi sayangnya, bagi kami itu tidak menyelesaikan jauh dari semua masalah.

Apa yang kita lakukan
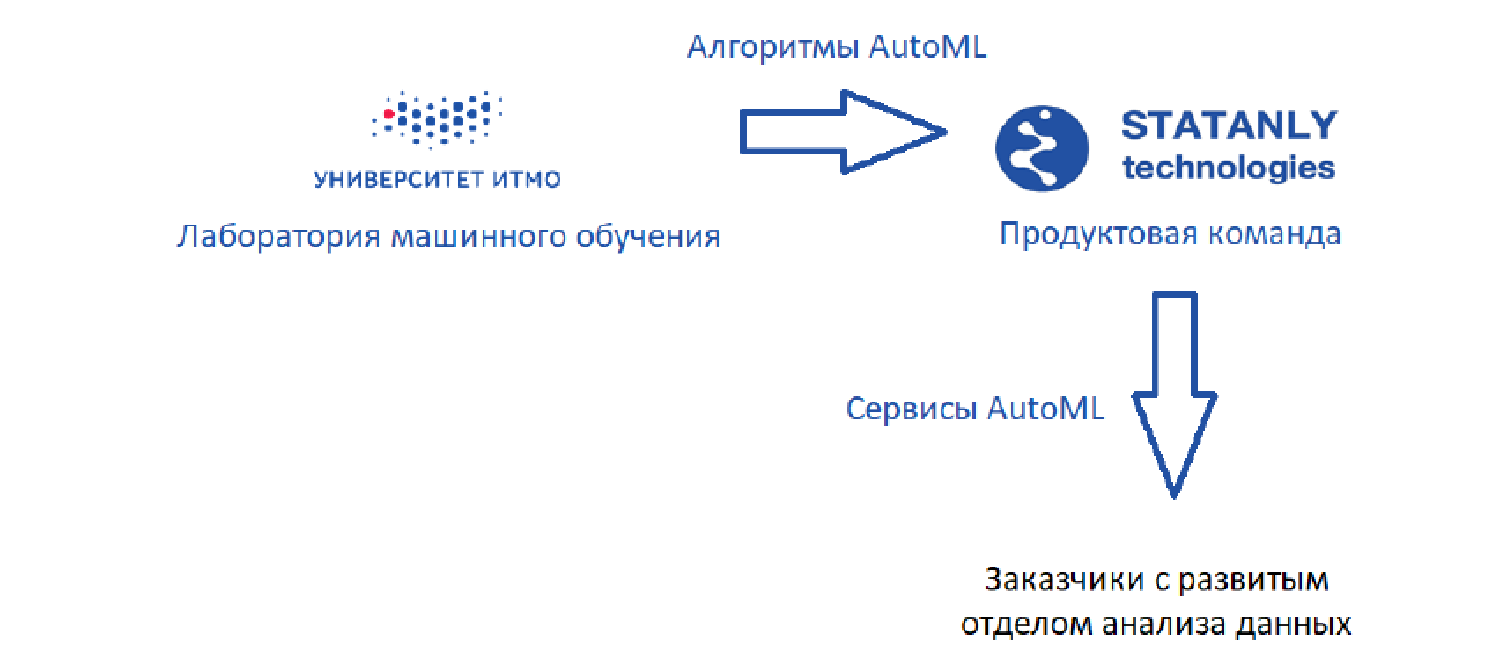
Seperti inilah tampilan sirkuit ideal (seperti yang saya lihat):
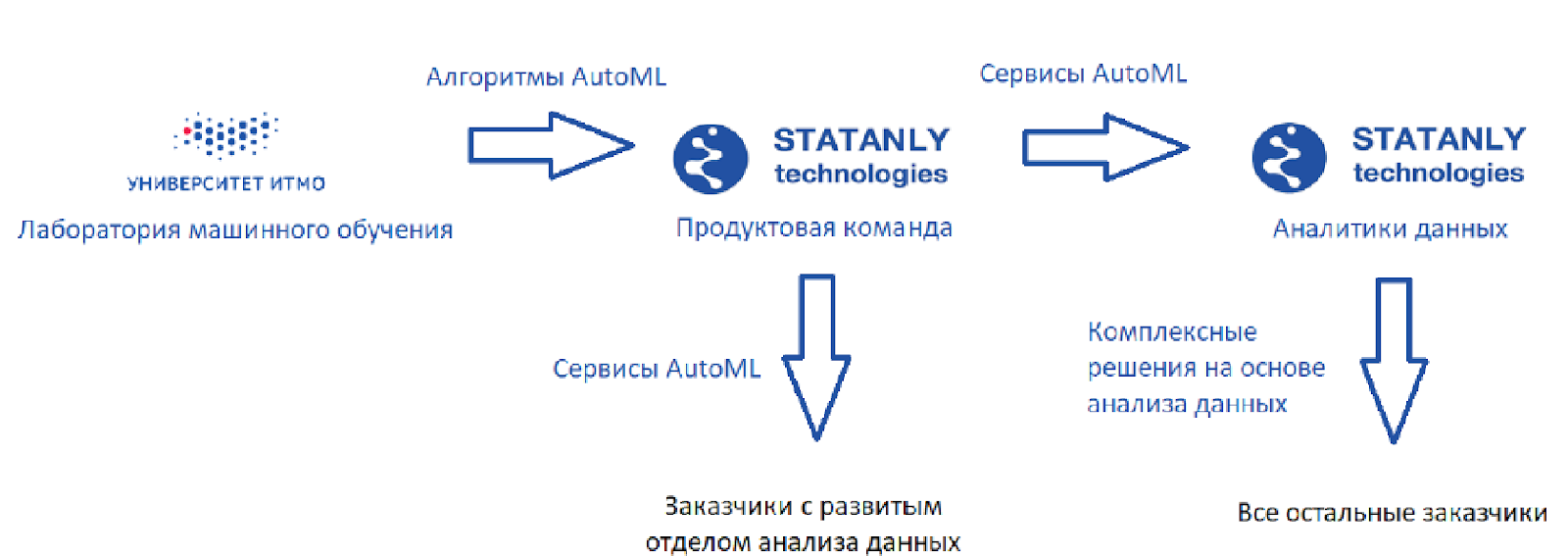
Ada laboratorium pembelajaran mesin yang mengembangkan algoritma, plus ada
Statanly Technologies - tim produk yang mengimplementasikan layanan AutoML berdasarkan pada algoritma kami. Mereka bekerja untuk perusahaan yang memiliki departemen Ilmu Data yang besar. Produk-produk yang sama digunakan oleh tim analis data di
Statanly Technologies itu sendiri dan secara khusus menyelesaikan masalah perusahaan yang belum berkembang atau bahkan membuat departemen analisis data mereka sendiri. Modelnya terlihat hebat, tetapi kenyataannya, tentu saja, sedikit lebih sederhana.
Kami memulai pada 2017 dengan fakta bahwa tidak ada analisis data di sini:
Kami ingin merilis produk yang akan digunakan analis data, tetapi pada 2017, sayangnya, kami tidak dapat menemukan kontak dengan investor - mereka tidak mengerti apa itu AutoML, mengapa itu diperlukan dan siapa yang akan menggunakannya.
Saat ini, kami tidak menjual apa pun, sebagai perusahaan yang mengembangkan solusi AutoML, kami hanya membuat hidup kami lebih mudah, sebagai tim yang menganalisis data:

Sedikit tentang bagaimana kita melakukannya. Secara alami, kami mengatur parameter hiper (tidak ada pencarian jaringan), tetapi selain mengaturnya, kami hampir selalu mencoba untuk membangun beberapa solusi berbasis AutoML dasar, dan kadang-kadang membantu diri kita sendiri dalam langkah-langkah untuk preprocessing data.
Saya memiliki beberapa contoh inspirasional dan beragam - hampir semua yang AutoML dan saya lakukan, dari yang sederhana hingga yang kompleks.
Contoh sederhana adalah tugas di Gazpromneft: ada sumur, Anda perlu memprediksi waktu kegagalan yang potensial. Kami memiliki data dan fitur tabular klasik yang kami miliki. Akibatnya, kami membuat model prediksi menggunakan AutoML, sementara tidak ada satu pun analis yang terluka, tetapi bahkan tidak berpartisipasi dalam proses tersebut. Bahkan, ini ternyata menjadi solusi terbaik:

Kisah kedua: Sinara Technologies. Di sini tugasnya sedikit lebih rumit, karena sebenarnya ada tepat dua kolom: waktu / parameter + bagaimana itu berubah. Itu perlu untuk memprediksi kegagalan mesin. Di sini kami menggunakan AutoML untuk sedikit membantu kami dalam pemrosesan data - kami membuat garis dasar, yang kemudian melampaui kami:

Contoh ketiga: tugas yang pada pandangan pertama tidak ada hubungannya dengan AutoML. Ada situs web untuk saluran TVC - database artikel tempat pencarian, dan pencarian kaya secara semantik. Kami ingin menemukan tidak hanya ekspresi kata yang tepat, tetapi juga sesuai dengan artinya. Ditambah daftar besar persyaratan berbeda yang juga perlu dipertimbangkan.
Bagaimana kita mendekati masalah ini?
Kami memutuskan untuk mengindeks semua dokumen berdasarkan kelompok fleksibel dengan kata-kata yang sama, karena pengindeksan lebih mudah. Selain itu, ada lebih dari 100 ribu dokumen dalam database, dan jika ini tidak dilakukan, pencarian akan menjadi sangat panjang. Selanjutnya, kami membangun representasi vektor (saya harap semua orang mendengarnya) dan mengelompokkan representasi vektor agar kami dapat diindeks.
Masalah kedua: bagaimana kita mengelompokkan data? Kami menerapkan AutoML untuk memilih langkah-langkah untuk menilai kualitas pengelompokan, serta untuk memilih algoritma dan parameter hiper untuk pengelompokan:

Terlebih lagi, paling sering kita tidak menggunakan AutoML. Berikut adalah dua contoh yang sangat terbuka.
Dalam startup kedua kami, Special Video Analytics, produk adalah sistem untuk mengenali tanda-tanda mobil untuk memastikan akses terpusat mereka ke wilayah tertutup. Masalah utama di sini adalah jumlah data yang kecil. Dalam hal ini, cukup sulit untuk menyesuaikan parameter model. Dan kami sangat terbatas, karena AutoML sering digunakan tanpa pertimbangan dan mencoba menyesuaikan model dengan data yang sama dengan yang diuji. Ini tidak dapat dilakukan: menurut klasik pembelajaran mesin, seseorang perlu memilih satu set validasi: semakin besar pencarian, semakin banyak mesin yang seharusnya. Jadi, ketika kita memiliki sedikit data, kita lebih khawatir tentang menemukan dan menandai data ini daripada membangun model yang lebih kompleks.
Contoh lain adalah pengembangan bersama kami dengan Huawei. Kami melakukan proyek agar mereka mengenali teks pada gambar. Tampaknya Anda dapat menggunakan AutoML di sini, karena sudah ada tiga metrik yang dapat dioptimalkan: kualitas pengenalan, waktu pengenalan, dan parameter model (karena semua ini seharusnya diterapkan di perangkat seluler). Tetapi sekarang tidak ada yang memiliki keahlian yang cukup untuk mengimplementasikan ketiga aspek secara optimal.
Akibatnya, tidak ada daya komputasi yang cukup: waktu kami terbatas dan tidak memiliki jumlah server yang memadai. Jika kita memulainya di rumah (dan seharusnya di KURANG), kita tidak akan punya waktu. Karena prosesnya memakan waktu lima jam, kami hanya perlu kompetensi.
Kesimpulan
Secara umum, AutoML adalah hal yang sangat berguna, tetapi aplikasi agak sempit. Secara alami, ia tidak akan dapat menemukan solusi untuk TK. AutoML saat ini hanya berguna untuk analis data. Mungkin suatu hari dia akan menggantinya, tetapi jelas tidak dalam lima tahun ke depan.
Diposting oleh Andrey Filchenkov, Kepala Laboratorium Pembelajaran Mesin, ITMO