Jika Anda tertarik pada pembelajaran mesin, Anda mungkin pernah mendengar tentang BERT dan transformer.
BERT adalah model bahasa dari Google, menunjukkan hasil-hasil canggih dengan selisih yang lebar pada sejumlah tugas. BERT, dan umumnya transformer, telah menjadi langkah yang benar-benar baru dalam pengembangan algoritma pemrosesan bahasa alami (NLP). Artikel tentang mereka dan "kedudukan" untuk berbagai tolok ukur dapat ditemukan di situs web Papers With Code .
Ada satu masalah dengan BERT: bermasalah untuk digunakan dalam sistem industri. BERT-base berisi parameter 110M, BERT-besar - 340M. Karena sejumlah besar parameter, model ini sulit untuk diunduh ke perangkat dengan sumber daya terbatas, seperti ponsel. Selain itu, inferensi waktu yang lama membuat model ini tidak cocok di mana kecepatan respons sangat penting. Oleh karena itu, menemukan cara untuk mempercepat BERT adalah topik yang sangat panas.
Kami di Avito sering harus menyelesaikan masalah klasifikasi teks. Ini adalah tugas pembelajaran mesin terapan yang khas yang telah dipelajari dengan baik. Tetapi selalu ada godaan untuk mencoba sesuatu yang baru. Artikel ini lahir dari upaya untuk menerapkan BERT dalam tugas pembelajaran mesin setiap hari. Di dalamnya, saya akan menunjukkan bagaimana Anda dapat secara signifikan meningkatkan kualitas model yang ada menggunakan BERT tanpa menambahkan data baru dan tanpa menyulitkan model.

Distilasi pengetahuan sebagai metode percepatan jaringan saraf
Ada beberapa cara untuk mempercepat / meringankan jaringan saraf. Ulasan terinci yang saya temui dipublikasikan di blog Intento on the Medium .
Metode dapat secara kasar dibagi menjadi tiga kelompok:
- Arsitektur jaringan berubah.
- Kompresi model (kuantisasi, pemangkasan).
- Distilasi pengetahuan.
Jika dua metode pertama relatif terkenal dan dapat dipahami, maka yang ketiga kurang umum. Untuk pertama kalinya, ide penyulingan diusulkan oleh Rich Caruana dalam artikel "Model Compression" . Esensinya sederhana: Anda dapat melatih model yang ringan yang akan meniru perilaku model guru atau bahkan ansambel model. Dalam kasus kami, guru akan BERT, dan siswa akan menjadi model ringan.
Tantangan
Mari kita analisis distilasi menggunakan klasifikasi biner sebagai contoh. Ambil dataset SST-2 yang terbuka dari serangkaian tugas standar yang menguji model untuk NLP.
Dataset ini adalah kumpulan ulasan film dengan IMDb yang dipecah berdasarkan warna emosional - positif atau negatif. Metrik pada dataset ini adalah akurasi.
Pelatihan model berbasis BERT atau "guru"
Pertama-tama, Anda perlu melatih model BERT berbasis “besar”, yang akan menjadi guru. Cara termudah untuk melakukan ini adalah mengambil embeddings dari BERT dan melatih classifier di atasnya, menambahkan satu layer ke jaringan.
Berkat pustaka tranformers, melakukan ini cukup mudah, karena ada kelas yang sudah jadi untuk model BertForSequenceClassification. Menurut pendapat saya, tutorial yang paling rinci dan dapat dipahami untuk mengajar model ini diterbitkan oleh Menuju Ilmu Data .
Mari kita bayangkan bahwa kita mendapatkan model BertForSequenceClassification yang terlatih. Dalam kasus kami, num_labels = 2, karena kami memiliki klasifikasi biner. Kami akan menggunakan model ini sebagai "guru."
Belajar "murid"
Anda dapat mengambil arsitektur apa pun sebagai siswa: jaringan saraf, model linier, pohon keputusan. Mari kita coba mengajarkan BiLSTM untuk visualisasi yang lebih baik. Untuk memulai, kami akan mengajar BiLSTM tanpa BERT.
Untuk mengirimkan teks ke input jaringan saraf, Anda harus menyajikannya sebagai vektor. Salah satu cara termudah adalah memetakan setiap kata ke indeksnya dalam kamus. Kamus akan terdiri dari kata-kata top-n paling populer dalam dataset kami ditambah dua kata layanan: "pad" - "dummy word" sehingga semua urutan memiliki panjang yang sama, dan "unk" - untuk kata-kata di luar kamus. Kami akan membangun kamus menggunakan seperangkat alat standar dari torchtext. Untuk kesederhanaan, saya tidak menggunakan embeddings kata pra-terlatih.
import torch from torchtext import data def get_vocab(X): X_split = [t.split() for t in X] text_field = data.Field() text_field.build_vocab(X_split, max_size=10000) return text_field def pad(seq, max_len): if len(seq) < max_len: seq = seq + ['<pad>'] * (max_len - len(seq)) return seq[0:max_len] def to_indexes(vocab, words): return [vocab.stoi[w] for w in words] def to_dataset(x, y, y_real): torch_x = torch.tensor(x, dtype=torch.long) torch_y = torch.tensor(y, dtype=torch.float) torch_real_y = torch.tensor(y_real, dtype=torch.long) return TensorDataset(torch_x, torch_y, torch_real_y)
Model BiLSTM
Kode untuk model akan terlihat seperti ini:
import torch from torch import nn from torch.autograd import Variable class SimpleLSTM(nn.Module): def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout, batch_size, device=None): super(SimpleLSTM, self).__init__() self.batch_size = batch_size self.hidden_dim = hidden_dim self.n_layers = n_layers self.embedding = nn.Embedding(input_dim, embedding_dim) self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout) self.fc = nn.Linear(hidden_dim * 2, output_dim) self.dropout = nn.Dropout(dropout) self.device = self.init_device(device) self.hidden = self.init_hidden() @staticmethod def init_device(device): if device is None: return torch.device('cuda') return device def init_hidden(self): return (Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device)), Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device))) def forward(self, text, text_lengths=None): self.hidden = self.init_hidden() x = self.embedding(text) x, self.hidden = self.rnn(x, self.hidden) hidden, cell = self.hidden hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1)) x = self.fc(hidden) return x
Pelatihan
Untuk model ini, dimensi vektor keluaran akan menjadi (batch_size, output_dim). Dalam pelatihan, kita akan menggunakan logloss yang biasa. PyTorch memiliki kelas BCEWithLogitsLoss yang menggabungkan sigmoid dan cross entropy. Apa yang kamu butuhkan
def loss(self, output, bert_prob, real_label): criterion = torch.nn.BCEWithLogitsLoss() return criterion(output, real_label.float())
Kode untuk satu era pembelajaran:
def get_optimizer(model): optimizer = torch.optim.Adam(model.parameters()) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 2, gamma=0.9) return optimizer, scheduler def epoch_train_func(model, dataset, loss_func, batch_size): train_loss = 0 train_sampler = RandomSampler(dataset) data_loader = DataLoader(dataset, sampler=train_sampler, batch_size=batch_size, drop_last=True) model.train() optimizer, scheduler = get_optimizer(model) for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Train')): text, bert_prob, real_label = to_device(text, bert_prob, real_label) model.zero_grad() output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) loss.backward() optimizer.step() train_loss += loss.item() scheduler.step() return train_loss / len(data_loader)
Kode untuk verifikasi setelah era:
def epoch_evaluate_func(model, eval_dataset, loss_func, batch_size): eval_sampler = SequentialSampler(eval_dataset) data_loader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=batch_size, drop_last=True) eval_loss = 0.0 model.eval() for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Val')): text, bert_prob, real_label = to_device(text, bert_prob, real_label) output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) eval_loss += loss.item() return eval_loss / len(data_loader)
Jika semua ini disatukan, maka kita mendapatkan kode berikut untuk melatih model:
import os import torch from torch.utils.data import (TensorDataset, random_split, RandomSampler, DataLoader, SequentialSampler) from torchtext import data from tqdm import tqdm def device(): return torch.device("cuda" if torch.cuda.is_available() else "cpu") def to_device(text, bert_prob, real_label): text = text.to(device()) bert_prob = bert_prob.to(device()) real_label = real_label.to(device()) return text, bert_prob, real_label class LSTMBaseline(object): vocab_name = 'text_vocab.pt' weights_name = 'simple_lstm.pt' def __init__(self, settings): self.settings = settings self.criterion = torch.nn.BCEWithLogitsLoss().to(device()) def loss(self, output, bert_prob, real_label): return self.criterion(output, real_label.float()) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=1, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings['train_batch_size']) return model def train(self, X, y, y_real, output_dir): max_len = self.settings['max_seq_length'] text_field = get_vocab(X) X_split = [t.split() for t in X] X_pad = [pad(s, max_len) for s in tqdm(X_split, desc='pad')] X_index = [to_indexes(text_field.vocab, s) for s in tqdm(X_pad, desc='to index')] dataset = to_dataset(X_index, y, y_real) val_len = int(len(dataset) * 0.1) train_dataset, val_dataset = random_split(dataset, (len(dataset) - val_len, val_len)) model = self.model(text_field) model.to(device()) self.full_train(model, train_dataset, val_dataset, output_dir) torch.save(text_field, os.path.join(output_dir, self.vocab_name)) def full_train(self, model, train_dataset, val_dataset, output_dir): train_settings = self.settings num_train_epochs = train_settings['num_train_epochs'] best_eval_loss = 100000 for epoch in range(num_train_epochs): train_loss = epoch_train_func(model, train_dataset, self.loss, self.settings['train_batch_size']) eval_loss = epoch_evaluate_func(model, val_dataset, self.loss, self.settings['eval_batch_size']) if eval_loss < best_eval_loss: best_eval_loss = eval_loss torch.save(model.state_dict(), os.path.join(output_dir, self.weights_name))
Distilasi
Gagasan metode distilasi ini diambil dari sebuah artikel oleh para peneliti dari University of Waterloo . Seperti yang saya katakan di atas, "siswa" harus belajar meniru perilaku "guru". Apa sebenarnya perilaku itu? Dalam kasus kami, ini adalah prediksi model guru pada set pelatihan. Dan ide kuncinya adalah menggunakan output jaringan sebelum menerapkan fungsi aktivasi. Diasumsikan bahwa dengan cara ini model akan dapat lebih baik mempelajari representasi internal daripada dalam kasus probabilitas akhir.
Artikel asli mengusulkan untuk menambahkan istilah ke fungsi kerugian, yang akan bertanggung jawab atas kesalahan "imitasi" - MSE antara model log.

Untuk tujuan ini, kami membuat dua perubahan kecil: mengubah jumlah output jaringan dari 1 menjadi 2 dan memperbaiki fungsi kehilangan.
def loss(self, output, bert_prob, real_label): a = 0.5 criterion_mse = torch.nn.MSELoss() criterion_ce = torch.nn.CrossEntropyLoss() return a*criterion_ce(output, real_label) + (1-a)*criterion_mse(output, bert_prob)
Anda dapat menggunakan kembali semua kode yang kami tulis dengan mendefinisikan ulang hanya model dan kehilangan:
class LSTMDistilled(LSTMBaseline): vocab_name = 'distil_text_vocab.pt' weights_name = 'distil_lstm.pt' def __init__(self, settings): super(LSTMDistilled, self).__init__(settings) self.criterion_mse = torch.nn.MSELoss() self.criterion_ce = torch.nn.CrossEntropyLoss() self.a = 0.5 def loss(self, output, bert_prob, real_label): return self.a * self.criterion_ce(output, real_label) + (1 - self.a) * self.criterion_mse(output, bert_prob) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=2, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings['train_batch_size']) return model
Itu saja, sekarang model kita sedang belajar untuk "meniru".
Perbandingan Model
Dalam artikel asli, hasil klasifikasi terbaik untuk SST-2 diperoleh pada a = 0, ketika model hanya belajar meniru, tidak memperhitungkan label nyata. Akurasi masih kurang dari BERT, tetapi secara signifikan lebih baik daripada BiLSTM biasa.

Saya mencoba mengulangi hasil dari artikel, tetapi dalam percobaan saya hasil terbaik diperoleh pada a = 0,5.
Beginilah tampilan grafik kehilangan dan keakuratan saat mempelajari LSTM dengan cara biasa. Menilai dari perilaku kehilangan, model itu dengan cepat belajar, dan di suatu tempat setelah era keenam, pelatihan ulang dimulai.
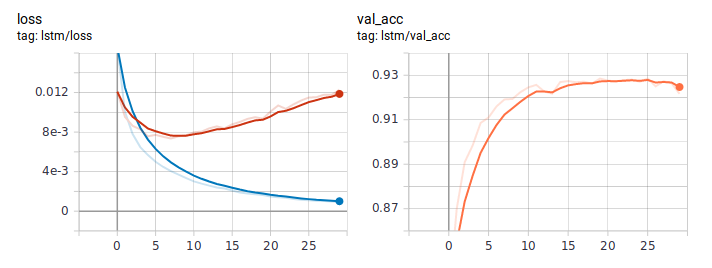
Grafik distilasi:
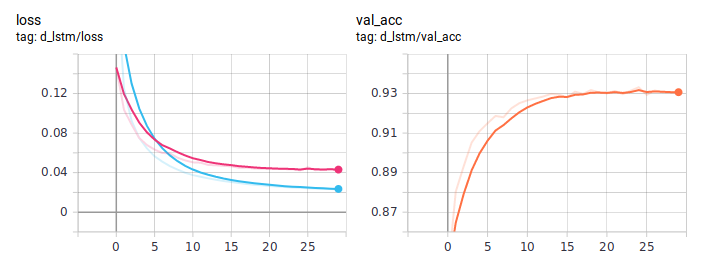
BiLSTM yang disuling secara konsisten lebih baik dari biasanya. Penting bahwa mereka benar-benar identik dalam arsitektur, satu-satunya perbedaan adalah dalam cara mengajar. Saya memposting kode pelatihan lengkap di GitHub .
Kesimpulan
Dalam panduan ini, saya mencoba menjelaskan ide dasar pendekatan distilasi. Arsitektur spesifik siswa akan tergantung pada tugas yang dihadapi. Tetapi secara umum, pendekatan ini berlaku dalam tugas praktis apa pun. Karena kerumitan pada tahap pelatihan model, Anda bisa mendapatkan peningkatan yang signifikan dalam kualitasnya, sambil mempertahankan kesederhanaan asli arsitektur.