NeurIPS (
Neural Information Processing Systems ) adalah konferensi terbesar di dunia tentang pembelajaran mesin dan kecerdasan buatan dan acara utama dalam dunia pembelajaran yang mendalam.
Pada dekade baru, akankah para insinyur DS kita juga menguasai biologi, linguistik, dan psikologi? Kami akan memberi tahu dalam ulasan kami.

Tahun ini, konferensi menyatukan lebih dari 13.500 orang dari 80 negara di Vancouver (Kanada). Ini bukan tahun pertama Sberbank mewakili Rusia di konferensi - tim DS berbicara tentang pengenalan ML dalam proses perbankan, kompetisi ML, dan kemampuan platform DS Sberbank. Apa tren utama 2019 di komunitas ML? Para peserta konferensi mengatakan:
Andrey Chertok dan
Tatyana Shavrina .
Tahun ini, lebih dari 1.400 artikel diterima di NeurIPS - algoritma, model baru, dan aplikasi baru untuk data baru.
Tautan ke semua materiKonten:
- Tren
- Interpretabilitas model
- Multidisiplin
- Alasan
- RL
- Gan
- Kunci Pembicaraan yang Diundang
- “Kecerdasan Sosial”, Blaise Aguera y Arcas (Google)
- "Ilmu Data Veridis", Bin Yu (Berkeley)
- "Pemodelan Perilaku Manusia dengan Pembelajaran Mesin: Peluang dan Tantangan", Nuria M Oliver, Albert Ali Salah
- "Dari System 1 ke System 2 Deep Learning", Yoshua Bengio
Tren 2019
1. Model Interpretabilitas dan Metodologi ML BaruTopik utama konferensi adalah interpretasi dan bukti mengapa kita mendapatkan hasil ini atau itu. Anda dapat berbicara lama tentang pentingnya filosofis menafsirkan "kotak hitam", tetapi ada lebih banyak metode nyata dan perkembangan teknis di bidang ini.
Metodologi reproduksibilitas model dan ekstraksi pengetahuan dari mereka adalah alat baru ilmu pengetahuan. Model dapat berfungsi sebagai alat untuk memperoleh pengetahuan baru dan mengujinya, dan setiap tahap preprocessing, pelatihan, dan penerapan model harus direproduksi.
Proporsi publikasi yang signifikan ditujukan bukan untuk membangun model dan alat, tetapi untuk masalah memastikan keamanan, transparansi, dan verifikasi hasil. Secara khusus, aliran terpisah muncul tentang serangan pada model (serangan permusuhan), dan opsi untuk serangan pada pelatihan dan serangan pada aplikasi dipertimbangkan.
Artikel:
- Ilmu Data Veridis adalah artikel fitur tentang metodologi verifikasi model. Ini mencakup tinjauan umum alat-alat modern untuk menafsirkan model, khususnya, penggunaan perhatian dan memperoleh fitur penting karena "distilasi" jaringan saraf oleh model linier.
- Ini Tampak Seperti Itu: Pembelajaran yang Dalam untuk Pengenalan Gambar yang Dapat Diartikan Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, Jonathan K. Su
- Sebuah Tolok Ukur untuk Metode Interpretabilitas dalam Jaringan Saraf Tiruan Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, Sudah Kim
- Menuju Pembelajaran Penguatan yang Dapat Diartikan Menggunakan Agen Augmented Perhatian Alexander Mott, Daniel Zoran, Mike Chrzanowski, Daan Wierstra, Danilo Jimenez Rezende
- Pentingnya Pengukuran MDI Fitur Debiased untuk Hutan Acak Xiao Li, Yu Wang, Sumanta Basu, Karl Kumbier, Bin Yu
- Ekstraksi Pengetahuan tanpa Data yang Dapat Diobservasi Jaemin Yoo, Minyong Cho, Taebum Kim, U Kang
- Sebuah Langkah Menuju Mengukur Penelitian Pembelajaran Mesin Reproducible Secara Mandiri Edward Raff
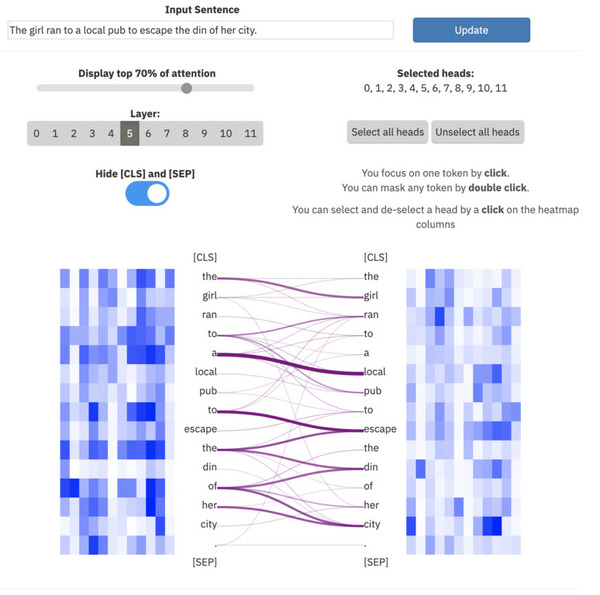 ExBert.net menunjukkan interpretasi model untuk tugas pengolah kata
ExBert.net menunjukkan interpretasi model untuk tugas pengolah kata
2. MultidisiplinUntuk memastikan verifikasi yang andal dan mengembangkan mekanisme untuk menguji dan menambah pengetahuan, diperlukan spesialis dari bidang terkait, yang secara bersamaan memiliki kompetensi dalam ML dan dalam bidang subjek (kedokteran, linguistik, neurobiologi, pendidikan, dll.). Dari catatan khusus adalah kehadiran yang lebih signifikan dari karya dan presentasi tentang ilmu saraf dan ilmu kognitif - ada pemulihan hubungan spesialis dan ide-ide pinjaman.
Selain pemulihan hubungan ini, multidisiplin direncanakan dalam pemrosesan bersama informasi dari berbagai sumber: teks dan foto, teks dan permainan, basis data grafik + teks dan foto.
Artikel:
 Dua model - ahli strategi dan pemain - berdasarkan RL dan NLP memainkan strategi online3. Penalaran
Dua model - ahli strategi dan pemain - berdasarkan RL dan NLP memainkan strategi online3. PenalaranMemperkuat kecerdasan buatan - gerakan menuju sistem belajar mandiri, "sadar", bernalar, dan berdebat (reasoning). Secara khusus, inferensi kausal dan akal sehat berkembang. Bagian dari laporan dikhususkan untuk meta-learning (cara belajar belajar) dan kombinasi teknologi-DL dengan logika orde 1 dan 2 - istilah Inteligensi Buatan Buatan (AGI) menjadi istilah umum dalam pidato pembicara.
Artikel:
- Pembelajaran Heterogen untuk Penalaran Visual Commonsense, Weijiang Yu, Jingwen Zhou, Weihao Yu, Xiaodan Liang, Nong Xiao
- Pembelajaran Mesin Bridging dan Penalaran Logis dengan Pembelajaran Abductive Wang-Zhou Dai, Qiuling Xu, Yang Yu, Zhi-Hua Zhou
- Secara implisit belajar bernalar dalam logika tingkat pertama Vaishak Belle, Brendan Juba
- PHYRE: Tolok Ukur Baru untuk Penalaran Fisik Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, Ross Girshick
- Penyisipan Kuantum Pengetahuan untuk Penalaran Dinesh Garg, Shajith Ikbal, Santosh K. Srivastava, Harit Vishwakarma, Hima Karanam, L Venkata Subramaniam
4.Penguatan PembelajaranSebagian besar pekerjaan terus mengembangkan area tradisional RL - DOTA2, Starcraft, menggabungkan arsitektur dengan visi komputer, NLP, basis data grafik.
Hari yang terpisah dari konferensi ini didedikasikan untuk lokakarya RL, yang mempresentasikan arsitektur Model Kritik Aktor Optimis, melampaui semua yang sebelumnya, khususnya Kritik Aktor Lembut.
Artikel:
 Pemain StarCraft bertarung dengan Alphastar (DeepMind)5. GAN
Pemain StarCraft bertarung dengan Alphastar (DeepMind)5. GANJaringan generatif masih menjadi fokus perhatian: banyak karya menggunakan vanilla GAN untuk bukti matematis, dan juga menerapkannya dalam versi baru dan tidak biasa (grafik model generatif, bekerja dengan seri, aplikasi untuk menyebabkan dan mempengaruhi hubungan dalam data, dll.).
Artikel:
Karena pekerjaan telah diambil lebih dari
1.400 di bawah ini, kami akan berbicara tentang pertunjukan yang paling penting.
Pembicaraan yang Diundang
“Kecerdasan Sosial”, Blaise Aguera y Arcas (Google)
TautanSlide dan videoLaporan ini didedikasikan untuk metodologi pembelajaran mesin umum dan prospek yang mengubah industri saat ini - persimpangan jalan apa yang kita hadapi? Bagaimana cara kerja otak dan evolusi, dan mengapa kita menggunakan begitu sedikit sehingga kita sudah mengetahui dengan baik tentang pengembangan sistem alami?
Pengembangan industri ML sebagian besar bertepatan dengan tonggak perkembangan Google, yang menerbitkan penelitiannya tentang NeurIPS dari tahun ke tahun:
- 1997 - peluncuran kapasitas pencarian, server pertama, daya komputasi kecil
- 2010 - Jeff Dean meluncurkan proyek Google Brain, ledakan jaringan saraf di awal
- 2015 - implementasi industri jaringan saraf, pengenalan wajah cepat langsung pada perangkat lokal, prosesor tingkat rendah dipertajam oleh komputasi tensor - TPU. Google meluncurkan Coral ai - analog dari raspberry pi, komputer mini untuk memperkenalkan jaringan saraf ke dalam instalasi eksperimental
- 2017 - Google memulai pengembangan pelatihan terdesentralisasi dan menggabungkan hasil pelatihan jaringan saraf dari berbagai perangkat menjadi satu model - di android
Saat ini, seluruh industri memperhatikan keamanan data, menggabungkan dan mereproduksi hasil pembelajaran pada perangkat lokal.
Pembelajaran federasi - Arah ML, di mana masing-masing model belajar secara mandiri, dan kemudian digabungkan menjadi model tunggal (tanpa memusatkan sumber data), disesuaikan untuk peristiwa langka, anomali, personalisasi, dll Semua perangkat Android pada dasarnya adalah komputer super komputasi tunggal untuk Google.
Model generatif berdasarkan pembelajaran federasi adalah bidang yang menjanjikan di masa depan, menurut Google, yang "berada pada tahap awal pertumbuhan eksponensial." GAN, menurut dosen, dapat belajar bagaimana mereproduksi perilaku massa populasi organisme hidup, dengan algoritma pemikiran.
Dengan menggunakan dua arsitektur GAN sederhana sebagai contoh, ditunjukkan bahwa di dalamnya pencarian untuk jalur pengoptimalan mengembara dalam lingkaran, yang berarti bahwa pengoptimalan tidak terjadi seperti itu. Selain itu, model-model ini sangat berhasil memodelkan percobaan yang dilakukan para ahli biologi pada populasi bakteri, memaksa mereka untuk mempelajari strategi baru untuk perilaku dalam mencari makanan. Kita dapat menyimpulkan bahwa kehidupan bekerja secara berbeda dari fungsi optimisasi.
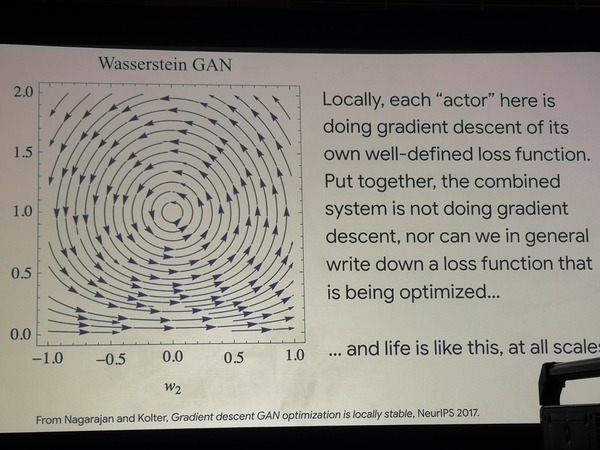 Mengembara Optimalisasi GAN
Mengembara Optimalisasi GANSemua yang kami lakukan dalam kerangka pembelajaran mesin sekarang adalah tugas yang sempit dan sangat formal, sementara formalisme ini kurang digeneralisasikan dan tidak sesuai dengan pengetahuan subjek kami di bidang-bidang seperti neurofisiologi dan biologi.
Apa yang benar-benar layak dipinjam dari bidang neurofisiologi dalam waktu dekat adalah arsitektur baru neuron dan sedikit revisi mekanisme back propagation of error.
Otak manusia sendiri tidak belajar bagaimana menggunakan jaringan saraf:
- Dia tidak memiliki pengantar primer acak, termasuk yang diletakkan melalui indera dan di masa kecil
- Dia memiliki arah perkembangan naluriah yang mapan (keinginan untuk belajar bahasa dari bayi, postur tegak)
Mempelajari otak individu adalah tugas tingkat rendah, mungkin kita harus mempertimbangkan "koloni" individu yang berubah dengan cepat, mentransmisikan pengetahuan satu sama lain untuk mereproduksi mekanisme evolusi kelompok.
Apa yang dapat kita ambil ke dalam algoritma ML sekarang:
- Menerapkan model garis keturunan sel yang memberikan pelatihan bagi populasi, tetapi umur pendek individu ("otak individu")
- Beberapa hasil belajar pada beberapa contoh
- Struktur neuron yang lebih kompleks, fungsi aktivasi yang sedikit berbeda
- Melewati "genom" ke generasi mendatang - algoritma propagasi balik
- Segera setelah kita menghubungkan neurofisiologi dan jaringan saraf, kita akan belajar bagaimana membangun otak multifungsi dari banyak komponen.
Dari sudut pandang ini, praktik solusi SOTA merugikan dan harus ditinjau untuk mengembangkan tugas umum (tolok ukur).
"Ilmu Data Veridis", Bin Yu (Berkeley)
Video dan slideLaporan ini dikhususkan untuk masalah interpretasi model pembelajaran mesin dan metodologi verifikasi dan verifikasi langsung mereka. Model ML apa pun yang terlatih dapat dianggap sebagai sumber pengetahuan yang perlu diekstraksi darinya.
Di banyak bidang, terutama dalam kedokteran, penerapan model tidak mungkin tanpa mengekstraksi pengetahuan tersembunyi ini dan menafsirkan hasil model - jika tidak kita tidak akan yakin bahwa hasilnya akan stabil, nonrandom, dapat diandalkan, dan tidak akan membunuh pasien. Seluruh arah metodologi kerja berkembang di dalam paradigma pembelajaran yang mendalam dan melampaui batas-batasnya - ilmu data yang benar. Apa ini
Kami ingin mencapai kualitas publikasi ilmiah dan reproduksi model sehingga:
- bisa ditebak
- dapat dihitung
- stabil
Ketiga prinsip ini membentuk dasar metodologi baru. Bagaimana model ML diuji terhadap kriteria ini? Cara termudah adalah membangun model yang dapat langsung ditafsirkan (regresi, pohon keputusan). Namun, kami ingin mendapatkan manfaat langsung dari pembelajaran yang mendalam.
Beberapa cara yang ada untuk menangani masalah:
- menafsirkan model;
- Gunakan metode berbasis perhatian
- menggunakan ensemble algoritma untuk pelatihan, dan memastikan bahwa model yang dapat ditafsirkan linier belajar untuk memprediksi jawaban yang sama dengan jaringan saraf, menafsirkan fitur dari model linier;
- Ubah dan tambah data pelatihan. Ini termasuk penambahan noise, interferensi, dan augmentasi data;
- metode apa pun yang memastikan bahwa hasil model tidak acak dan tidak bergantung pada gangguan kecil yang tidak diinginkan (serangan permusuhan);
- menafsirkan model post factum setelah pelatihan;
- bobot tanda belajar dengan berbagai cara;
- mempelajari probabilitas semua hipotesis, distribusi kelas.
 Serangan musuh pada babi
Serangan musuh pada babiKesalahan pemodelan mahal untuk semua orang: contoh nyata - karya Reinhart dan Rogov "
Pertumbuhan dalam masa utang " memengaruhi kebijakan ekonomi banyak negara Eropa dan memaksa mereka untuk mengejar kebijakan tabungan, tetapi pemeriksaan silang data yang cermat dan pengolahannya bertahun-tahun kemudian menunjukkan hasil yang berlawanan!
Setiap teknologi ML memiliki siklus hidup sendiri dari implementasi ke implementasi. Tugas metodologi baru adalah melakukan pemeriksaan pada tiga prinsip dasar pada setiap tahap kehidupan model.
Ringkasan:
- Beberapa proyek sedang dikembangkan untuk membantu model ML menjadi lebih andal. Ini, misalnya, deeptune (tautan ke: github.com/ChrisCummins/paper-end2end-dl );
- Untuk pengembangan metodologi lebih lanjut, perlu untuk secara signifikan meningkatkan kualitas publikasi di bidang ML;
- Pembelajaran dengan mesin membutuhkan pemimpin dengan pelatihan multidisiplin dan keahlian di bidang teknis dan kemanusiaan.
“Pemodelan Perilaku Manusia dengan Pembelajaran Mesin: Peluang dan Tantangan” Nuria M Oliver, Albert Ali Salah
Ceramah tentang pemodelan perilaku manusia, fondasi teknologinya, dan prospek aplikasinya.
Pemodelan perilaku manusia dapat dibagi menjadi:
- perilaku individu
- perilaku kelompok kecil
- perilaku massa
Masing-masing tipe ini dapat dimodelkan menggunakan ML, tetapi dengan informasi dan fitur input yang sangat berbeda. Setiap jenis juga memiliki masalah etika masing-masing yang dilalui oleh setiap proyek:
- perilaku individu - pencurian identitas, deepfake;
- perilaku kelompok orang - deanonimisasi, memperoleh informasi tentang gerakan, panggilan telepon, dll.
Perilaku individuUntuk tingkat yang lebih besar, tema Computer Vision - pengakuan emosi manusia, reaksinya. Itu hanya mungkin dalam konteks, dalam waktu atau dengan skala relatif dari variabilitas emosinya sendiri. Pada slide adalah pengakuan emosi Mona Lisa menggunakan konteks dari spektrum emosional wanita Mediterania. Hasil: senyum sukacita, tetapi dengan jijik dan jijik. Alasannya kemungkinan besar secara teknis menentukan emosi "netral".
Perilaku kelompok kecilSejauh ini, yang terburuk dimodelkan karena kurangnya informasi. Karya-karya tahun 2018 - 2019 ditampilkan sebagai contoh. pada lusinan orang, X lusinan video (lih. dataset gambar 100k ++). Untuk simulasi terbaik dalam tugas ini, diperlukan informasi multimodal, terutama dari sensor ke tele-altimeter, termometer, rekaman mikrofon, dll.
Perilaku massalArea yang paling maju, karena pelanggannya adalah PBB dan banyak negara bagian. Kamera pengintai luar ruangan, data dari menara telepon - penagihan, SMS, panggilan, data tentang pergerakan antar batas negara - semua ini memberikan gagasan yang sangat andal tentang pergerakan arus orang, ketidakstabilan sosial. Aplikasi potensial dari teknologi: optimalisasi operasi penyelamatan, bantuan dan evakuasi populasi yang tepat waktu jika terjadi keadaan darurat. Model yang digunakan sebagian besar masih diinterpretasikan dengan buruk - ini adalah berbagai LSTM dan jaringan konvolusional. Ada komentar singkat bahwa PBB melobi undang-undang baru yang akan mewajibkan perusahaan-perusahaan Eropa untuk berbagi data anonim yang diperlukan untuk penelitian apa pun.
"Dari System 1 ke System 2 Deep Learning", Yoshua Bengio
SlideDalam sebuah ceramah oleh Joshua, pembelajaran mendalam Benjio bertemu dengan ilmu saraf di tingkat penetapan tujuan.
Benjio mengidentifikasi dua jenis tugas utama menurut metodologi peraih Nobel Daniel Kahneman (buku "
Berpikir perlahan, selesaikan dengan cepat ")
tipe 1 - Sistem 1, tindakan tidak sadar yang kita lakukan "pada mesin" (otak kuno): mengendarai mobil di tempat yang akrab, berjalan, mengenali wajah.
tipe 2 - Sistem 2, tindakan sadar (korteks serebral), penetapan tujuan, analisis, berpikir, tugas gabungan.
AI sejauh ini mencapai ketinggian yang cukup hanya dalam tugas-tugas dari tipe pertama - sementara tugas kami adalah membawanya ke yang kedua, setelah belajar bagaimana melakukan operasi multidisiplin dan beroperasi dengan logika, keterampilan kognitif tingkat tinggi.
Untuk mencapai tujuan ini, diusulkan:
- menggunakan perhatian sebagai mekanisme utama untuk memodelkan pemikiran dalam tugas-tugas NLP
- menggunakan meta-learning dan representasi pembelajaran untuk pemodelan tanda-tanda yang lebih baik yang mempengaruhi kesadaran, dan lokalisasi mereka - dan berdasarkan mereka beralih ke operasi dengan konsep tingkat yang lebih tinggi.
Alih-alih kesimpulan, kami meninggalkan entri bicara yang diundang: Benjio adalah salah satu dari banyak ilmuwan yang mencoba memperluas bidang ML di luar masalah optimasi, SOTA dan arsitektur baru.
Pertanyaannya tetap terbuka sampai sejauh mana kombinasi masalah kesadaran, pengaruh bahasa pada pemikiran, neurobiologi dan algoritma adalah apa yang menanti kita di masa depan dan akan memungkinkan kita untuk beralih ke mesin yang “berpikir” seperti orang.
Terima kasih