Kita akan melihat bagaimana Zabbix bekerja dengan database TimescaleDB sebagai backend. Kami menunjukkan cara memulai dari awal dan cara bermigrasi dengan PostgreSQL. Kami juga memberikan uji kinerja komparatif dari kedua konfigurasi tersebut.

HighLoad ++ Siberia 2019. Tomsk Hall. 24 Juni 16:00. Abstrak dan
presentasi . Konferensi HighLoad ++ berikutnya akan diadakan pada 6 dan 7 April 2020 di St. Petersburg. Detail dan tiket di
sini .
Andrey Gushchin (selanjutnya disebut sebagai
AG): - Saya seorang insinyur dukungan teknis ZABBIX (selanjutnya disebut sebagai Zabbix), seorang pelatih. Saya telah bekerja dalam dukungan teknis selama lebih dari 6 tahun dan telah berhadapan langsung dengan kinerja. Hari ini saya akan berbicara tentang kinerja yang TimescaleDB dapat berikan bila dibandingkan dengan PostgreSQL biasa 10. Juga, beberapa bagian pengantar - tentang cara kerjanya.
Tantangan Kinerja Utama: Dari Akuisisi Data
Untuk memulainya, ada tantangan kinerja tertentu yang dihadapi oleh setiap sistem pemantauan. Tantangan kinerja pertama adalah pengumpulan dan pemrosesan data secara cepat.

Sistem pemantauan yang baik harus segera, tepat waktu menerima semua data, memprosesnya sesuai dengan pemicu ekspresi, yaitu, memprosesnya sesuai dengan beberapa kriteria (dalam sistem yang berbeda berbeda) dan menyimpannya ke database untuk menggunakan data ini di masa depan.

Tantangan kinerja kedua adalah menjaga sejarah. Simpan dalam database sering dan memiliki akses cepat dan mudah ke metrik ini yang dikumpulkan selama periode waktu tertentu. Yang paling penting adalah nyaman untuk mendapatkan data ini, menggunakannya dalam laporan, grafik, pemicu, dalam beberapa nilai ambang, untuk peringatan, dll.

Tantangan kinerja ketiga adalah membersihkan sejarah, yaitu, ketika hari Anda sedemikian rupa sehingga Anda tidak perlu menyimpan metrik terperinci yang telah dikumpulkan selama 5 tahun (bahkan berbulan-bulan atau dua bulan). Beberapa node jaringan telah dihapus, atau beberapa host, metrik tidak lagi diperlukan karena mereka sudah usang dan tidak lagi dikumpulkan. Semua ini perlu dibersihkan agar basis data Anda tidak bertambah besar. Secara umum, membersihkan sejarah paling sering merupakan ujian serius untuk penyimpanan - sangat sering mempengaruhi kinerja.
Bagaimana cara mengatasi masalah caching?
Sekarang saya akan berbicara secara khusus tentang Zabbix. Di Zabbix, panggilan pertama dan kedua diselesaikan menggunakan caching.

Pengumpulan dan pemrosesan data - kami menggunakan RAM untuk menyimpan semua data ini. Sekarang data ini akan dibahas secara lebih rinci.
Juga di sisi database ada caching tertentu untuk sampel utama - untuk grafik, hal-hal lain.
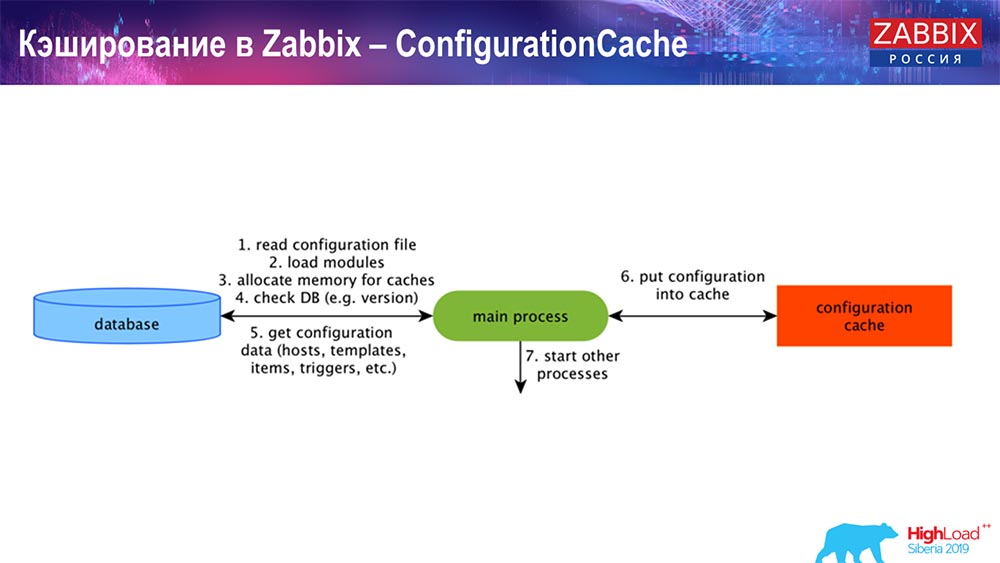
Caching di sisi server Zabbix itu sendiri: kami memiliki ConfigurationCache, ValueCache, HistoryCache, TrendsCache. Apa ini

ConfigurationCache adalah cache utama tempat kami menyimpan metrik, host, item data, pemicu; semua yang Anda butuhkan untuk memproses preprocessing, mengumpulkan data, dari host mana yang dikumpulkan, dengan frekuensi berapa. Semua ini disimpan dalam ConfigurationCache, agar tidak pergi ke database, bukan untuk membuat permintaan yang tidak perlu. Setelah server dimulai, kami memperbarui cache ini (buat) dan memperbarui secara berkala (tergantung pada pengaturan konfigurasi).
Caching di Zabbix. Pengumpulan data
Di sini skemanya cukup besar:

Yang utama dalam skema ini adalah para kolektor ini:
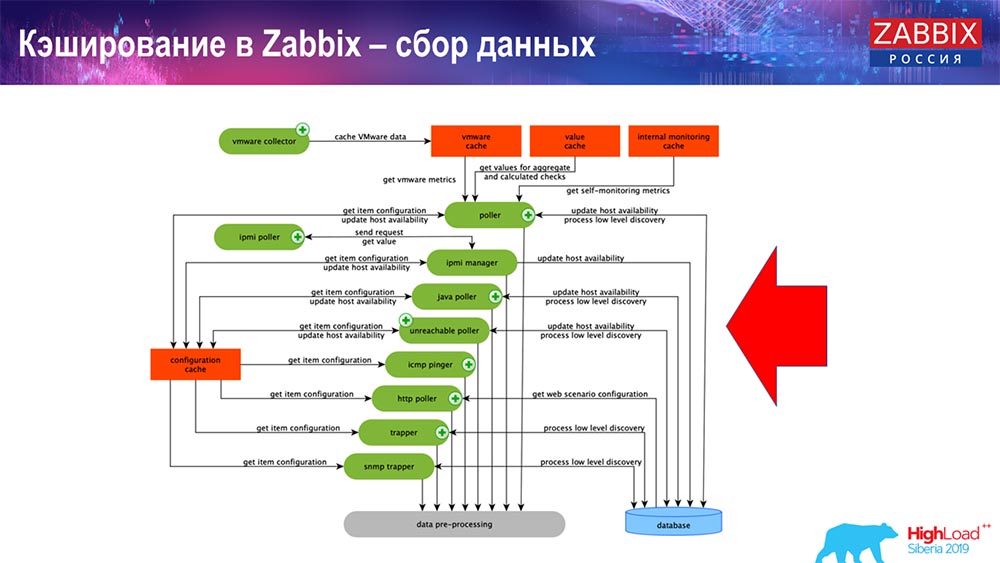
Ini adalah proses perakitan itu sendiri, berbagai "jajak pendapat" yang bertanggung jawab untuk berbagai jenis majelis. Mereka mengumpulkan data melalui icmp, ipmi, sesuai dengan protokol yang berbeda dan mentransfer semuanya ke preprocessing.
PreCiproses HistoryCache
Selain itu, jika kami telah menghitung elemen data (siapa yang tahu Zabbix - tahu), yaitu elemen data yang dihitung, dikumpulkan, kami membawanya langsung dari ValueCache. Tentang bagaimana itu diisi, saya akan katakan nanti. Semua kolektor ini menggunakan ConfigurationCache untuk mendapatkan pekerjaan mereka dan kemudian meneruskannya ke preprocessing.
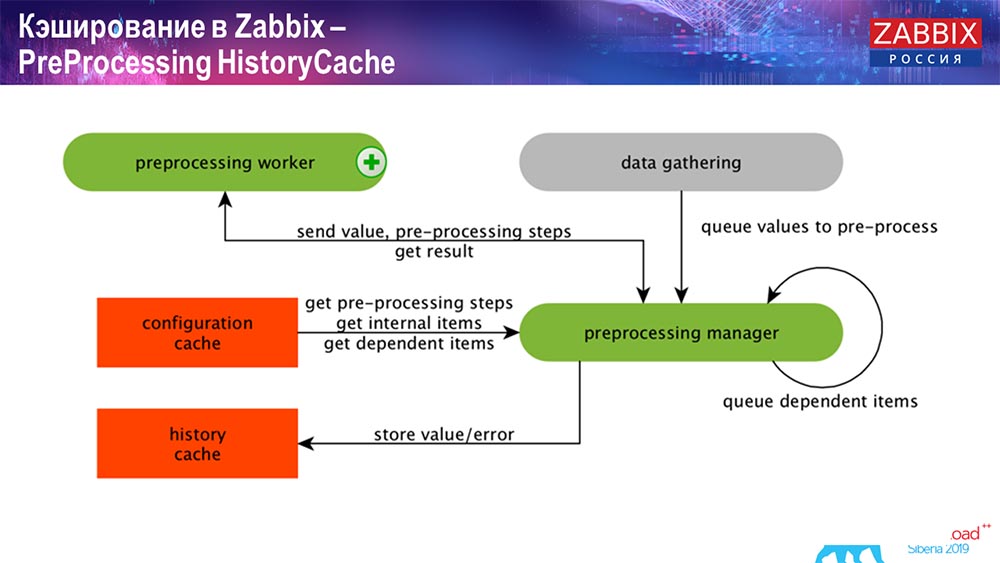
Preprocessing juga menggunakan ConfigurationCache untuk mendapatkan langkah preprocessing, ia memproses data ini dengan berbagai cara. Dimulai dengan versi 4.2, kami menyerahkannya ke proxy. Ini sangat mudah, karena preprocessing itu sendiri adalah operasi yang agak sulit. Dan jika Anda memiliki "Zabbix" yang sangat besar, dengan sejumlah besar elemen data dan koleksi frekuensi tinggi, ini sangat memudahkan pekerjaan.
Karenanya, setelah kami memproses data ini dengan beberapa cara menggunakan preprocessing, kami menyimpannya di HistoryCache untuk memprosesnya lebih lanjut. Ini mengakhiri pengumpulan data. Kami beralih ke proses utama.
Operasi syncer sejarah
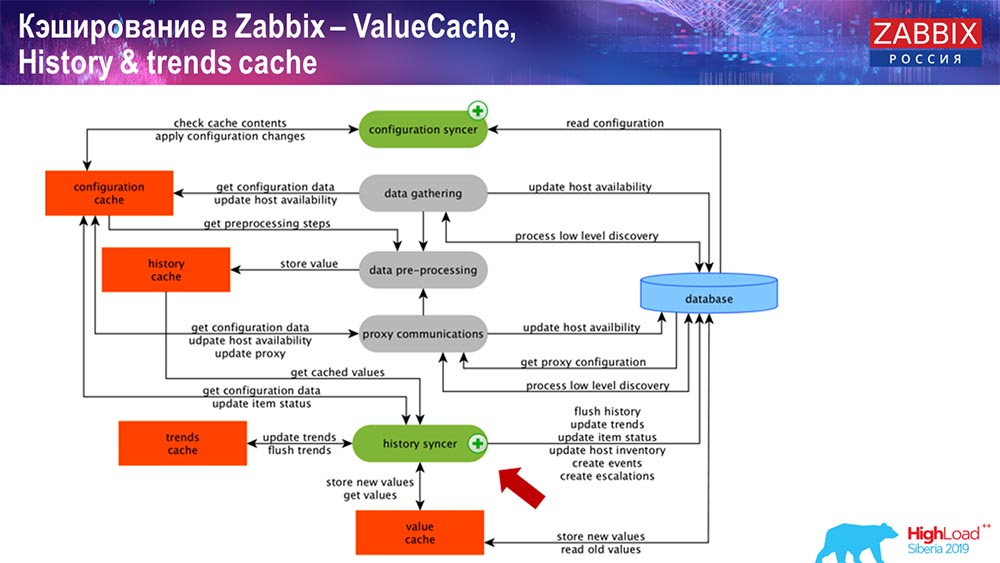
Proses utama dalam Zabbix (karena merupakan arsitektur monolitik) adalah History syncer. Ini adalah proses utama yang berkaitan secara khusus dengan pemrosesan atom dari setiap elemen data, yaitu dari setiap nilai:
- nilai datang (dibutuhkan dari HistoryCache);
- check in Configuration syncer: apakah ada pemicu untuk perhitungan? menghitungnya;
jika ada, itu menciptakan peristiwa, menciptakan eskalasi untuk membuat peringatan, jika perlu oleh konfigurasi; - catatan pemicu untuk pemrosesan selanjutnya, agregasi; jika Anda mengumpulkan dalam satu jam terakhir dan seterusnya, nilai ini mengingat ValueCache, agar tidak masuk ke tabel sejarah; Dengan demikian, ValueCache diisi dengan data yang diperlukan yang diperlukan untuk menghitung pemicu, elemen yang dihitung, dll.
- kemudian syncer sejarah menulis semua data ke database;
- database menulisnya ke disk - disinilah proses pemrosesan berakhir.
Basis data Caching
Di sisi DB, ketika Anda ingin melihat grafik atau semacam laporan acara, ada berbagai cache. Tetapi sebagai bagian dari laporan ini, saya tidak akan membicarakannya.
Untuk MySQL, ada Innodb_buffer_pool, sekelompok cache yang berbeda yang juga dapat dikonfigurasi.
Tapi ini yang utama:
- shared_buffers;
- ukuran efektif_cache_;
- shared_pool.

Saya telah mengutip untuk semua database bahwa ada cache tertentu yang memungkinkan Anda untuk menyimpan dalam memori data yang sering diperlukan untuk permintaan. Di sana mereka memiliki teknologi sendiri untuk ini.
Tentang kinerja basis data
Karenanya, ada lingkungan kompetitif, yaitu, server Zabbix mengumpulkan data dan mencatatnya. Saat memulai ulang, itu juga membaca dari sejarah untuk mengisi ValueCache dan sebagainya. Di sini Anda dapat memiliki skrip dan laporan yang menggunakan Zabbix-API, yang dibangun berdasarkan antarmuka web. "Zabbiks" -API termasuk dalam database dan menerima data yang diperlukan untuk mendapatkan grafik, laporan atau daftar peristiwa, masalah terkini.

Juga solusi visualisasi yang sangat populer adalah Grafana, yang digunakan oleh pengguna kami. Mampu langsung memasukkan keduanya melalui "Zabbiks" -API, dan melalui database. Hal ini juga menciptakan persaingan tertentu untuk mendapatkan data: penyempurnaan yang lebih baik, penyempurnaan yang lebih baik dari basis data diperlukan agar sesuai dengan pengiriman hasil dan pengujian yang cepat.

Bersihkan riwayat. Zabbix memiliki Pengurus Rumah Tangga
Tantangan ketiga yang digunakan oleh Zabbix adalah untuk membersihkan cerita dengan Housekeeper. Hauskiper mematuhi semua pengaturan, yaitu, dalam elemen data kami ditunjukkan berapa banyak untuk menyimpan (dalam hari), berapa banyak untuk menyimpan tren, dinamika perubahan.
Saya tidak berbicara tentang TrendCache, yang kami hitung dengan cepat: data tiba, kami menjumlahkannya dalam satu jam (pada dasarnya ini adalah angka dalam jam terakhir), jumlahnya rata-rata / minimum dan menuliskannya sekali per jam di tabel perubahan dinamika (Tren) . Hauskiper memulai dan menghapus data dari database menggunakan pilihan reguler, yang tidak selalu efektif.
Bagaimana memahami bahwa itu tidak efisien? Anda dapat melihat gambar berikut pada grafik kinerja proses internal:
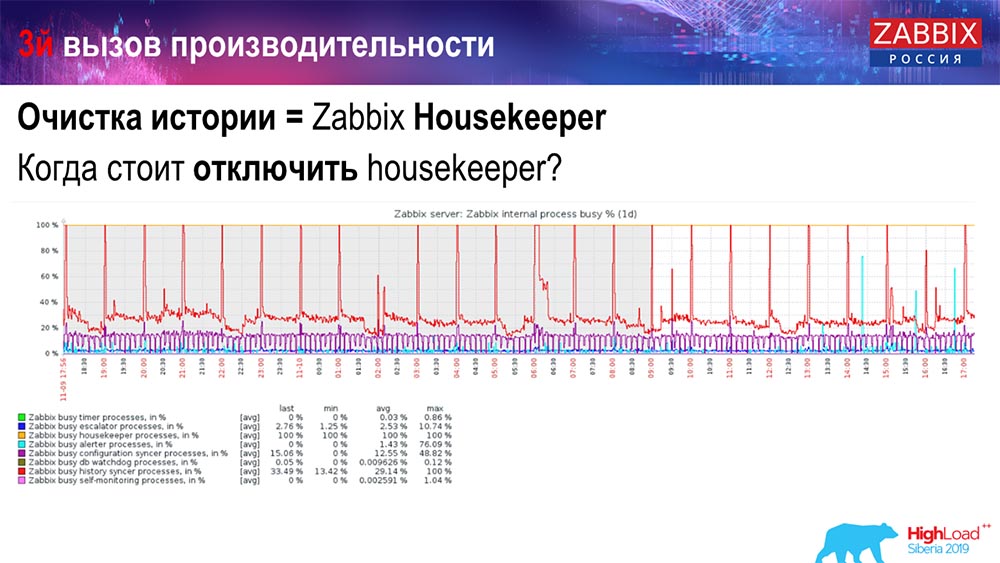
Syncer History Anda selalu sibuk (grafik merah). Dan grafik "merah" yang berada di atas. Ini adalah Hauskiper, yang memulai dan menunggu untuk database ketika menghapus semua baris yang ditentukan.
Ambil beberapa ID Item: Anda harus menghapus 5 ribu terakhir; Tentu saja dengan indeks. Tetapi biasanya dataset cukup besar - database masih membaca ini dari disk dan menaikkannya ke cache, dan ini adalah operasi yang sangat mahal untuk database. Tergantung pada ukurannya, ini dapat menyebabkan masalah kinerja tertentu.
Anda dapat menonaktifkan Hauskiper dengan cara sederhana - kami memiliki antarmuka web yang umum untuk semua orang. Pengaturan dalam Administrasi umum (pengaturan untuk "Housekeeper") kami menonaktifkan housekeeping internal untuk sejarah dan tren internal. Karenanya, Hauskiper tidak lagi mengontrol ini:

Apa yang bisa saya lakukan selanjutnya? Anda terputus, jadwal Anda naik level ... Masalah apa yang bisa lebih jauh dalam kasus ini? Apa yang bisa membantu?
Partisi (partisi)
Ini biasanya dikonfigurasi pada setiap basis data relasional yang telah saya daftarkan dengan cara yang berbeda. MySQL memiliki teknologinya sendiri. Tetapi secara keseluruhan mereka sangat mirip ketika datang ke PostgreSQL 10 dan MySQL. Tentu saja, ada banyak perbedaan internal dalam bagaimana semua itu diterapkan dan bagaimana semuanya mempengaruhi kinerja. Namun secara umum, pembuatan partisi baru seringkali juga mengarah pada masalah tertentu.

Tergantung pada pengaturan Anda (berapa banyak data yang Anda buat dalam satu hari), mereka biasanya menetapkan minimal satu - 1 hari / partisi, dan untuk tren, dinamika perubahan - 1 bulan / partisi baru. Ini dapat berubah jika Anda memiliki pengaturan yang sangat besar.
Katakan langsung tentang ukuran pengaturan: hingga 5 ribu nilai baru per detik (disebut nvps) - ini akan dianggap sebagai "pengaturan" kecil. Rata-rata - dari 5 hingga 25 ribu nilai per detik. Semua yang ada di atas sudah instalasi besar dan sangat besar yang membutuhkan konfigurasi database yang sangat hati-hati.
Pada instalasi yang sangat besar, 1 hari - ini mungkin tidak optimal. Saya pribadi melihat partisi MySQL sebesar 40 gigabyte per hari (dan mungkin ada lebih banyak). Ini adalah jumlah data yang sangat besar, yang dapat menyebabkan beberapa masalah. Itu perlu dikurangi.
Mengapa harus dipartisi?
Apa yang Partitioning berikan, saya pikir semua orang tahu, adalah tabel partisi. Seringkali ini adalah file terpisah pada permintaan disk dan span. Dia lebih optimal memilih satu partisi, jika ini adalah bagian dari partisi yang biasa.
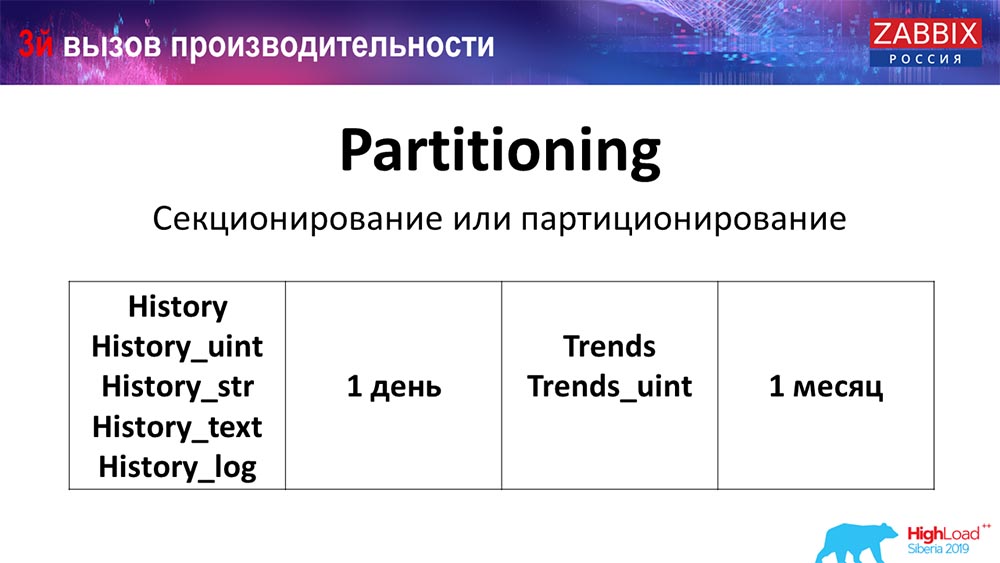
Untuk Zabbix, khususnya, digunakan oleh rentang, oleh rentang, yaitu, kami menggunakan timestamp (jumlahnya biasa, waktu dari awal era). Anda menentukan awal hari / akhir hari, dan ini adalah partisi. Dengan demikian, jika Anda melamar data dua hari yang lalu, ini semua dipilih dari database lebih cepat, karena Anda hanya perlu mengunggah satu file ke cache dan mengeluarkan (bukan tabel besar).

Banyak basis data juga mempercepat penyisipan (penyisipan ke tabel satu anak). Meskipun saya berbicara secara abstrak, tetapi itu juga mungkin. Berpartisi sering membantu.
Elasticsearch untuk NoSQL
Baru-baru ini, dalam 3.4, kami menerapkan solusi untuk NoSQL. Menambahkan kemampuan untuk menulis di Elasticsearch. Anda dapat menulis beberapa jenis terpisah: pilih - baik tuliskan nomor atau beberapa tanda; kami memiliki teks string, Anda dapat menulis log di Elasticsearch ... Dengan demikian, antarmuka web juga akan mengakses Elasticsearch. Ini berfungsi dengan baik dalam beberapa kasus, tetapi saat ini dapat digunakan.
TimescaleDB. Hipertabel
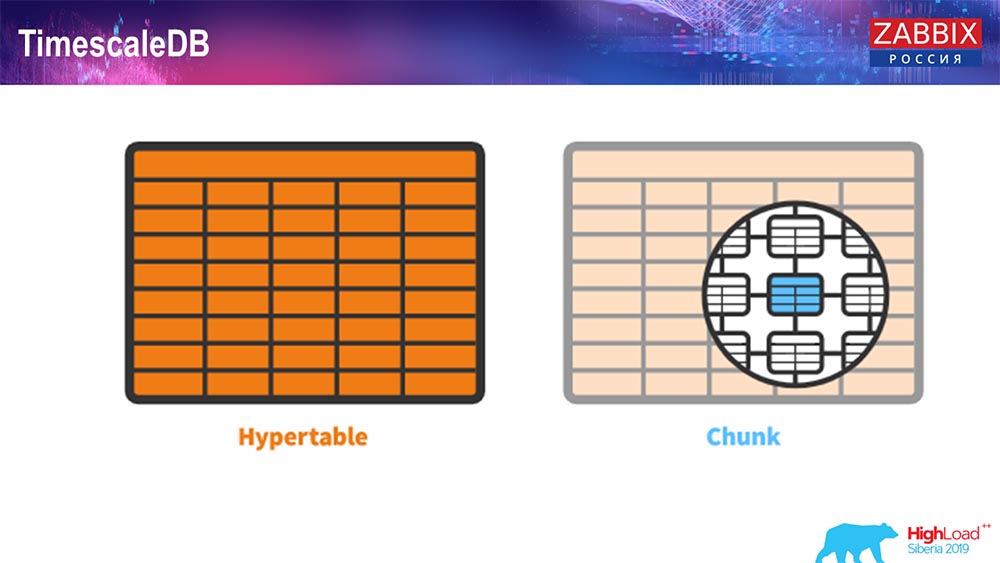
Untuk 4.4.2, kami memperhatikan satu hal seperti TimescaleDB. Apa ini Ini adalah ekstensi untuk Postgres, yaitu, ia memiliki antarmuka asli PostgreSQL. Plus, ekstensi ini memungkinkan Anda untuk bekerja dengan data deret waktu jauh lebih efisien dan memiliki partisi otomatis. Seperti apa tampilannya:

Ini hipertensi - ada konsep seperti itu di Timescale. Ini adalah hipertensi yang Anda buat, dan berisi potongan. Bongkahan adalah partisi, ini adalah meja anak-anak, jika saya tidak salah. Ini sangat efektif.
TimescaleDB dan PostgreSQL
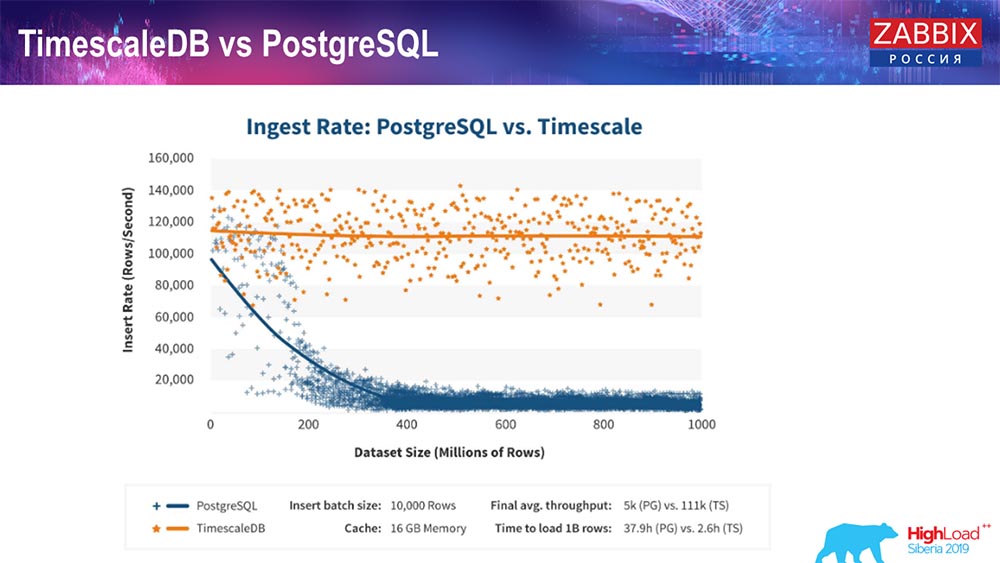
Seperti yang dipastikan oleh produsen TimescaleDB, mereka menggunakan algoritma pemrosesan permintaan yang lebih benar, khususnya insert'ov, yang memungkinkan Anda memiliki kinerja yang hampir konstan dengan ukuran insert data yang meningkat. Yaitu, setelah 200 juta baris "Postgres", yang biasa mulai melorot sangat banyak dan kehilangan kinerja secara harfiah menjadi nol, sedangkan "Timescale" memungkinkan Anda untuk memasukkan sisipan seefisien mungkin dengan sejumlah data.
Bagaimana cara menginstal TimescaleDB? Semuanya sederhana!
Dia memilikinya dalam dokumentasi, dijelaskan - itu dapat dikirim dari paket untuk ... Itu tergantung pada paket resmi Postgres. Itu dapat dikompilasi secara manual. Kebetulan saya harus mengkompilasi untuk database.
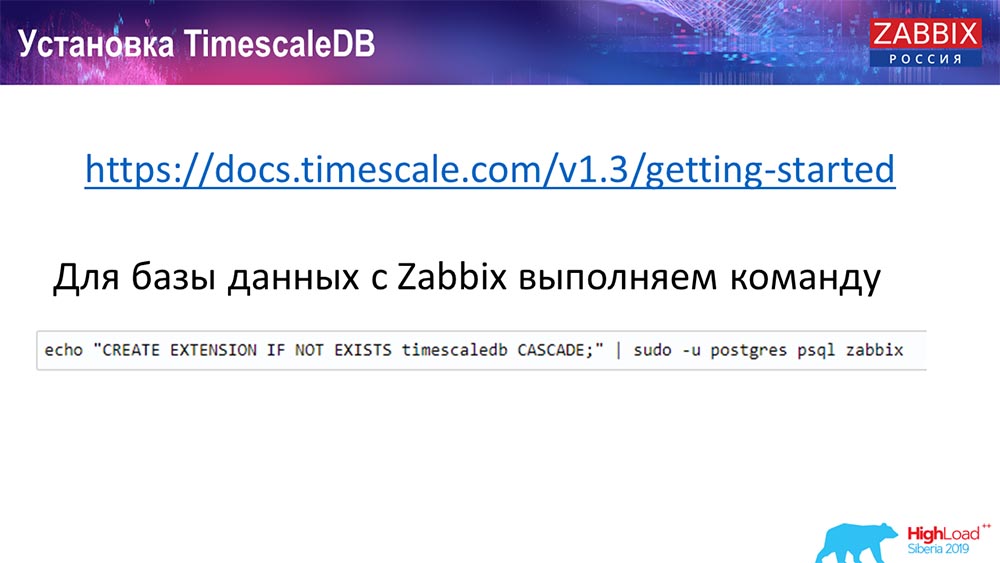
Di Zabbix, kami hanya mengaktifkan Extention. Saya pikir mereka yang menggunakan Extention di Postgres ... Anda cukup mengaktifkan Extention, buat untuk database Zabbix yang Anda gunakan.
Dan langkah terakhir ...
TimescaleDB. Tabel riwayat migrasi
Anda harus membuat hipertensi. Ada fungsi khusus untuk ini - Buat hipertensi. Di dalamnya, parameter pertama menunjukkan tabel yang diperlukan dalam database ini (yang Anda perlu buat hipertensi).

Bidang yang ingin Anda buat, dan chunk_time_interval (ini adalah interval chunks (partisi yang akan digunakan). 86.400 adalah satu hari.
Parameter migrate_data: jika Anda memasukkan true, maka ini mentransfer semua data saat ini ke potongan yang dibuat sebelumnya.
Saya sendiri menggunakan migrate_data - butuh waktu yang layak, tergantung seberapa besar basis data Anda. Saya memiliki lebih dari satu terabyte - pembuatannya membutuhkan waktu lebih dari satu jam. Dalam beberapa kasus, saat pengujian, saya menghapus data historis untuk teks (history_text) dan string (history_str), agar tidak mentransfernya - mereka tidak benar-benar menarik bagi saya.
Dan kami melakukan pembaruan terakhir di db_extention kami: kami menetapkan timescaledb sehingga database dan, khususnya, Zabbix kami memahami apa itu db_extention. Ini mengaktifkannya dan menggunakan sintaksis yang benar dan query database, menggunakan "fitur" yang diperlukan untuk TimescaleDB.
Konfigurasi server
Saya menggunakan dua server. Server pertama adalah mesin virtual yang cukup kecil, 20 prosesor, 16 gigabytes RAM. Siapkan Postgres 10.8 di atasnya:

Sistem operasi adalah Debian, sistem file adalah xfs. Saya membuat pengaturan minimal untuk menggunakan database khusus ini, minus apa yang akan digunakan Zabbix. Pada mesin yang sama adalah server Zabbix, PostgreSQL, dan agen beban.

Saya menggunakan 50 agen aktif yang menggunakan LoadableModule untuk dengan cepat menghasilkan berbagai hasil. Mereka menghasilkan garis, angka, dan sebagainya. Saya menyumbat DB dengan banyak data. Awalnya, konfigurasi berisi 5 ribu elemen data per host, dan kira-kira setiap elemen data berisi pemicu - sehingga itu merupakan pengaturan nyata. Terkadang bahkan dibutuhkan lebih dari satu pemicu untuk digunakan.

Saya mengatur interval pembaruan, beban itu sendiri sehingga saya tidak hanya menggunakan 50 agen (ditambahkan lebih banyak), tetapi juga dengan bantuan elemen data dinamis dan mengurangi interval pembaruan menjadi 4 detik.
Tes kinerja. PostgreSQL: 36 ribu NVP
Peluncuran pertama, pengaturan pertama saya pada PostreSQL 10 murni pada perangkat keras ini (35 ribu nilai per detik). Secara umum, seperti yang dapat Anda lihat di layar, memasukkan data membutuhkan sepersekian detik - semuanya baik-baik saja dan cepat, SSD (200 gigabyte). Satu-satunya hal adalah bahwa 20 GB dengan cepat terisi.
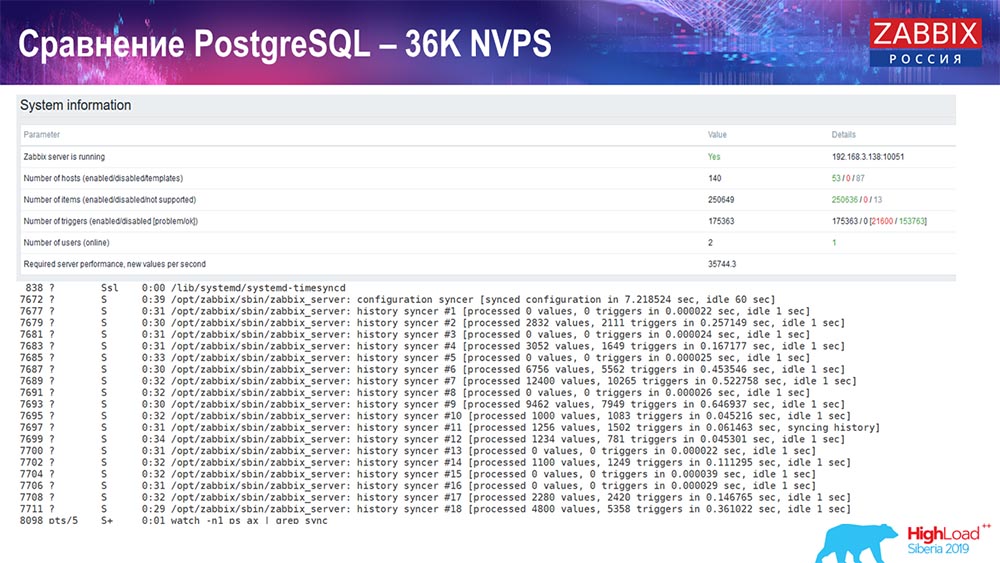
Akan ada lebih banyak grafik seperti itu. Ini adalah dasbor kinerja standar server Zabbix.
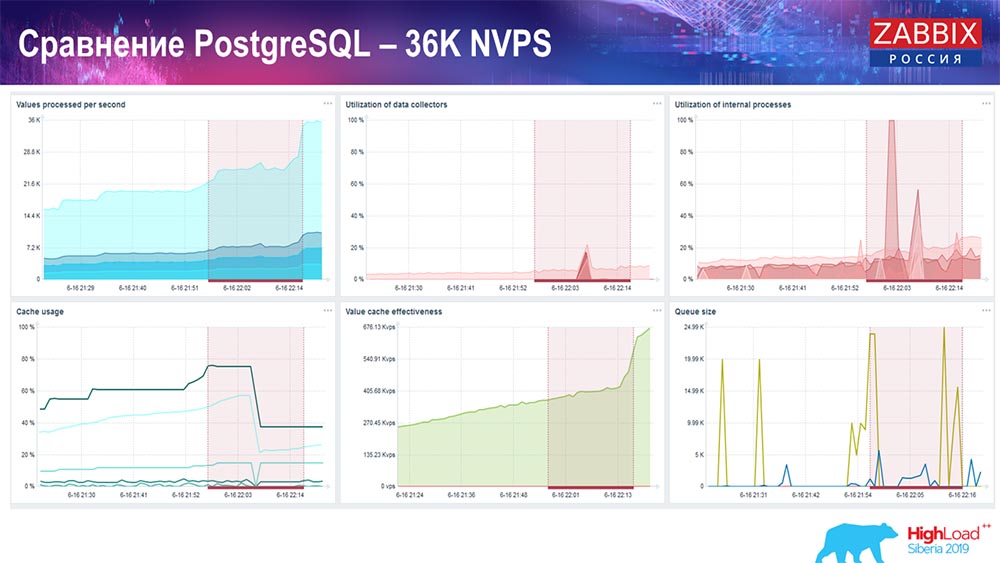
Grafik pertama adalah jumlah nilai per detik (biru, kiri atas), 35 ribu nilai dalam kasus ini. Ini (pusat pemuatan) adalah pemuatan proses perakitan, dan ini (kanan atas) memuat proses internal: penyelaraskan riwayat dan pembantu rumah tangga, yang telah berjalan di sini untuk waktu yang cukup.
Grafik ini (tengah bawah) menunjukkan penggunaan ValueCache - berapa banyak hit ValueCache untuk pemicu (beberapa ribu nilai per detik). Grafik penting lainnya adalah yang keempat (kiri bawah), yang menunjukkan penggunaan HistoryCache, yang saya bicarakan, yang merupakan buffer sebelum memasukkan ke dalam database.
Tes kinerja. PostgreSQL: 50 ribu NVP
Selanjutnya, saya menambah beban menjadi 50 ribu nilai per detik pada perangkat keras yang sama. Saat memuat dengan Hauskiper, 10 ribu nilai tercatat sudah dalam 2-3 detik dengan perhitungan. Faktanya, yang ditunjukkan pada tangkapan layar berikut:
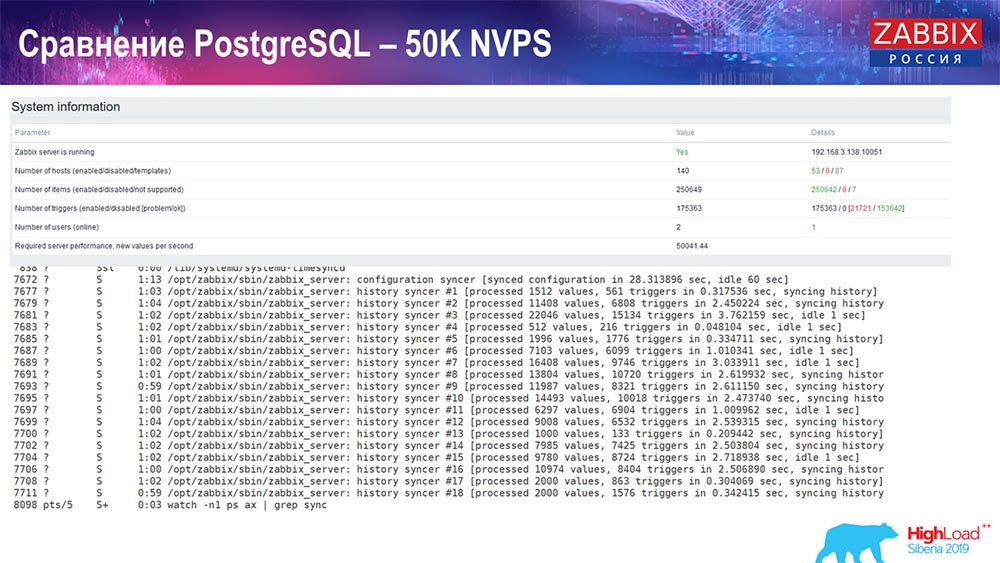
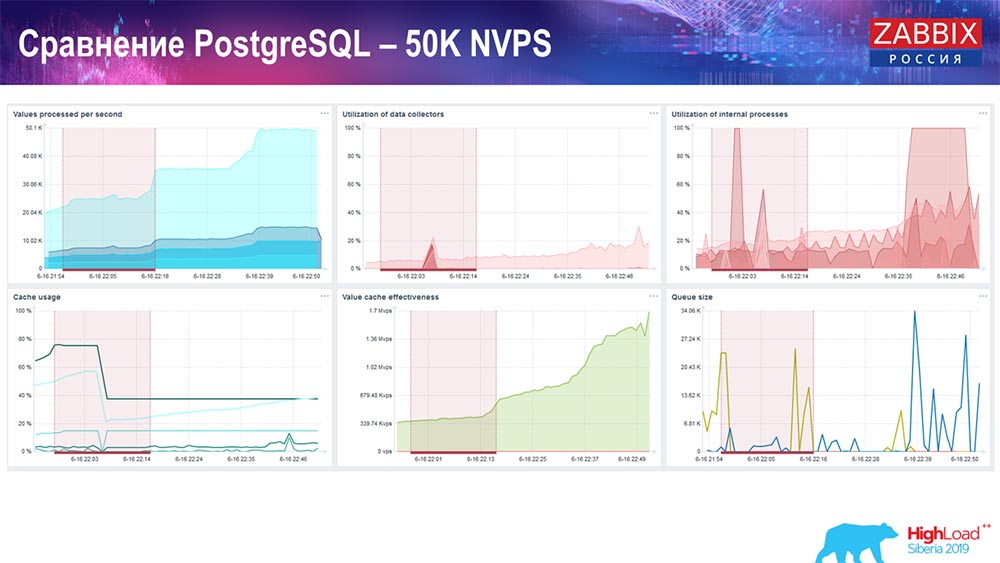
Hauskiper sudah mulai mengganggu pekerjaan, tetapi pemuatan keseluruhan penjebak sejarah-sinker masih di 60% (grafik ketiga, kanan atas). HistoryCache sudah selama karya "Hauskiper" mulai aktif mengisi (kiri bawah). Itu sekitar setengah gigabyte, terisi 20%.
Tes kinerja. PostgreSQL: 80 ribu NVP
Selanjutnya meningkat menjadi 80 ribu nilai per detik:
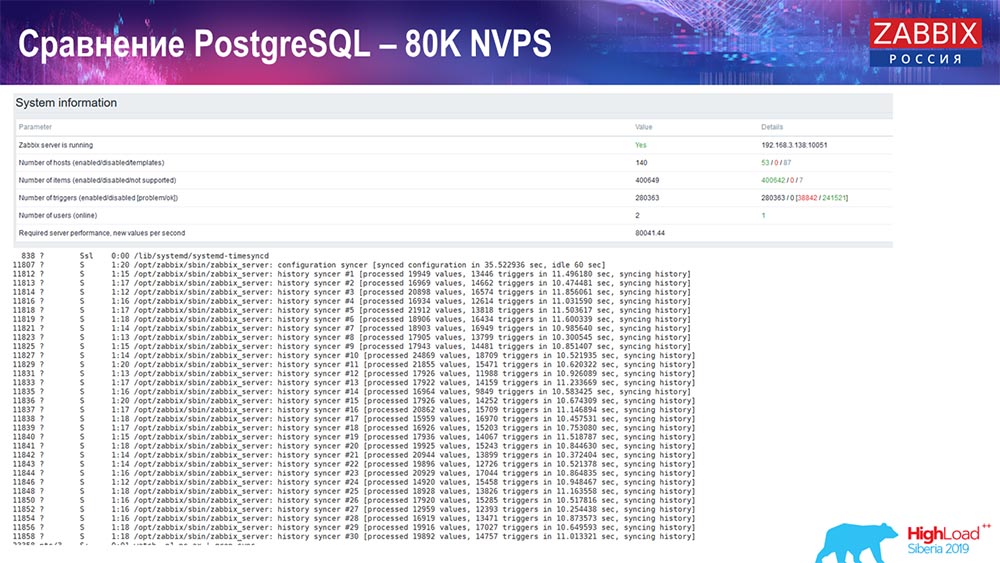
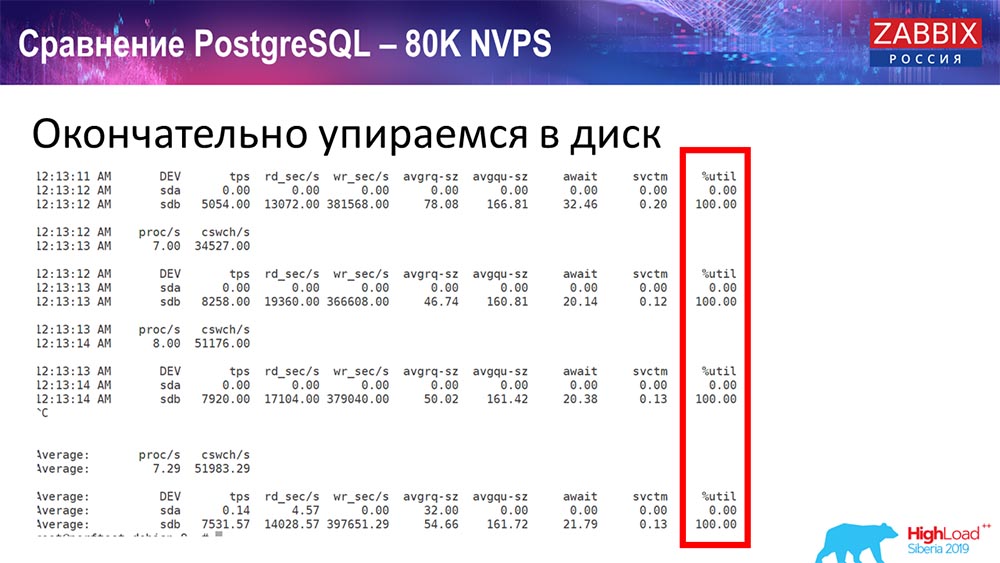
Itu sekitar 400 ribu elemen data, 280 ribu pemicu. Sisipan, seperti yang Anda lihat, untuk memuat sinker historis (ada 30 dari mereka) sudah cukup tinggi. Selanjutnya, saya meningkatkan berbagai parameter: history-sinkers, cache ... Pada hardware ini, memuat history-sinkers mulai meningkat secara maksimal, hampir "ke rak" - karena itu, HistoryCache pergi ke beban yang sangat tinggi:
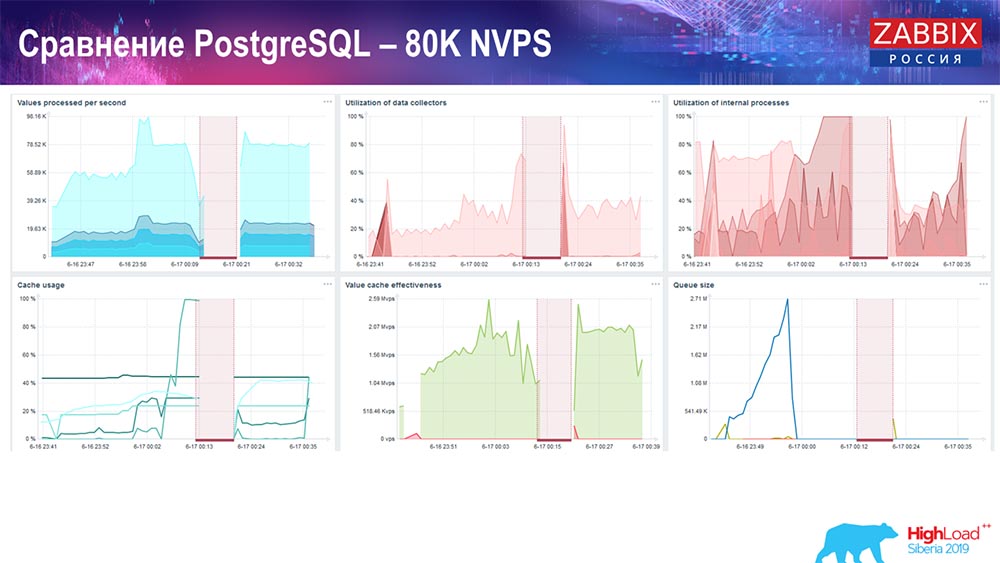
Selama ini saya memperhatikan semua parameter sistem (bagaimana prosesor digunakan, RAM) dan menemukan bahwa pemanfaatan disk maksimum - saya mencapai kapasitas maksimum disk ini pada perangkat keras ini, pada mesin virtual ini. "Postgres" dimulai pada intensitas untuk membuang data dengan cukup aktif, dan disk tidak lagi punya waktu untuk menulis, membaca ...
Saya mengambil server lain yang sudah memiliki 48 prosesor dengan 128 gigabytes RAM:
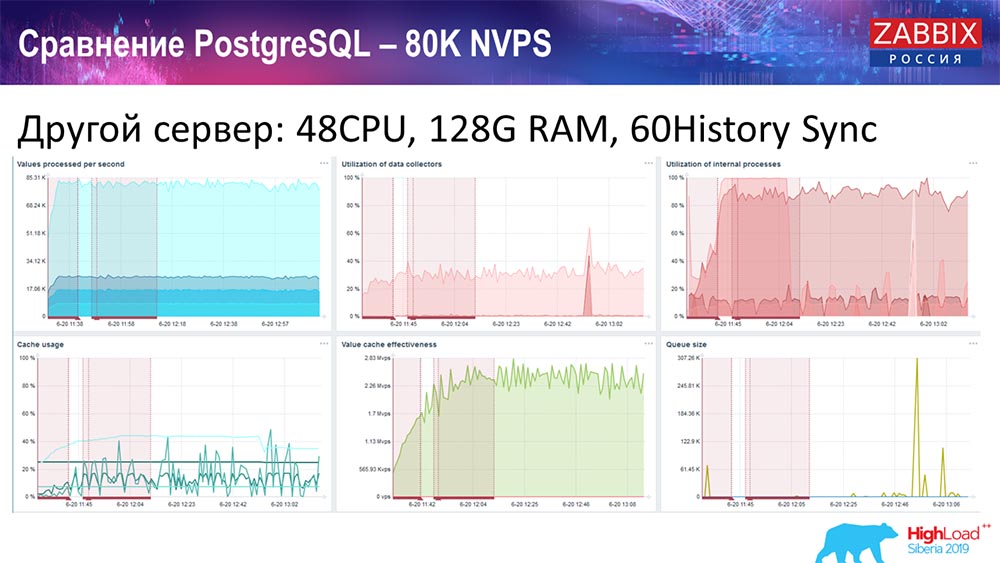
Juga, saya "menodai" itu - saya menginstal syncer Sejarah (60 buah) dan mencapai kinerja yang dapat diterima. Faktanya, kita tidak "berada di rak", tetapi ini mungkin adalah batas produktivitas, di mana kita perlu melakukan sesuatu untuk itu.
Tes kinerja. TimescaleDB: 80 ribu NVP
Tugas utama saya adalah menggunakan TimescaleDB. Kegagalan terlihat di setiap grafik:
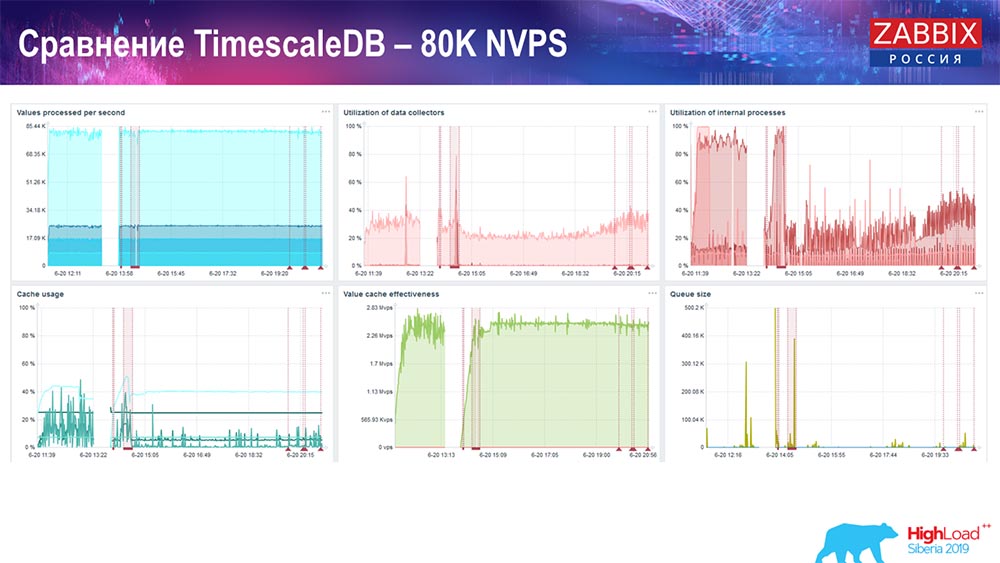
Penurunan ini hanya migrasi data. Setelah itu, di server "Zabbix", profil pemuatan sejarah-sinker, seperti yang Anda lihat, telah banyak berubah.
Ini hampir 3 kali lebih cepat yang memungkinkan Anda untuk memasukkan data dan menggunakan lebih sedikit HistoryCache - karena itu, Anda akan menerima data tepat waktu. Sekali lagi, 80 ribu nilai per detik adalah tingkat yang cukup tinggi (tentu saja, bukan untuk Yandex). Secara umum, ini adalah pengaturan yang cukup besar, dengan satu server.Tes kinerja PostgreSQL: 120 ribu NVP
Selanjutnya, saya meningkatkan nilai jumlah elemen data menjadi setengah juta dan mendapatkan nilai perkiraan 125 ribu per detik: Dan saya mendapatkan grafik ini:
Dan saya mendapatkan grafik ini: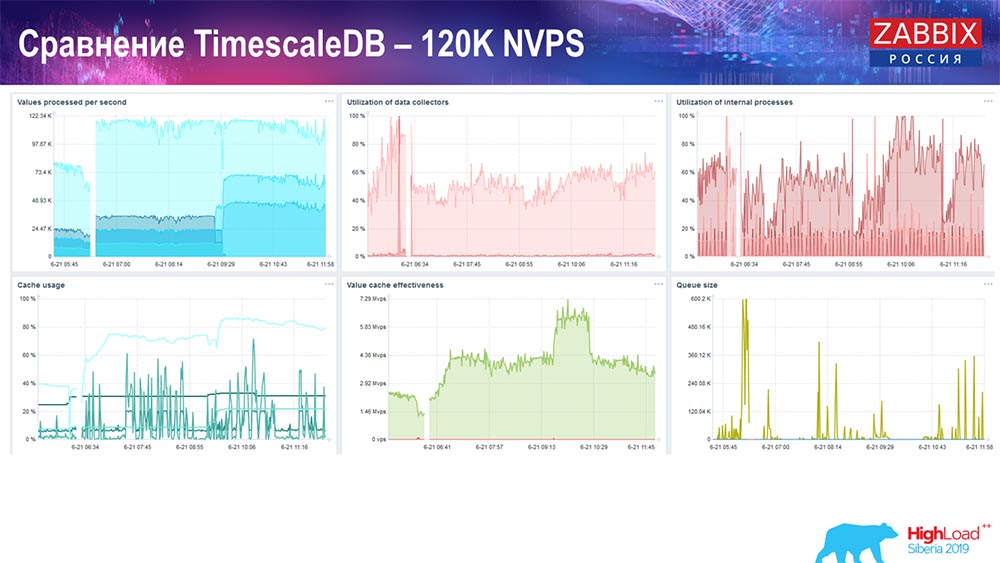 Pada prinsipnya, ini adalah pengaturan yang berfungsi, ia dapat bekerja untuk waktu yang agak lama. Tetapi karena saya hanya memiliki 1,5 terabyte disk, saya menghabiskannya dalam beberapa hari. Yang paling penting, pada saat yang sama, partisi TimescaleDB baru dibuat, dan ini benar-benar tidak diperhatikan untuk kinerja, yang tidak dapat dikatakan tentang MySQL.Partisi biasanya dibuat pada malam hari, karena memblokir penyisipan umum dan operasi tabel, dan dapat menyebabkan degradasi layanan. Dalam hal ini, ini bukan! Tugas utama adalah menguji kemampuan TimescaleDB. Hasilnya adalah angka seperti itu: 120 ribu nilai per detik.Ada juga contoh di komunitas:
Pada prinsipnya, ini adalah pengaturan yang berfungsi, ia dapat bekerja untuk waktu yang agak lama. Tetapi karena saya hanya memiliki 1,5 terabyte disk, saya menghabiskannya dalam beberapa hari. Yang paling penting, pada saat yang sama, partisi TimescaleDB baru dibuat, dan ini benar-benar tidak diperhatikan untuk kinerja, yang tidak dapat dikatakan tentang MySQL.Partisi biasanya dibuat pada malam hari, karena memblokir penyisipan umum dan operasi tabel, dan dapat menyebabkan degradasi layanan. Dalam hal ini, ini bukan! Tugas utama adalah menguji kemampuan TimescaleDB. Hasilnya adalah angka seperti itu: 120 ribu nilai per detik.Ada juga contoh di komunitas: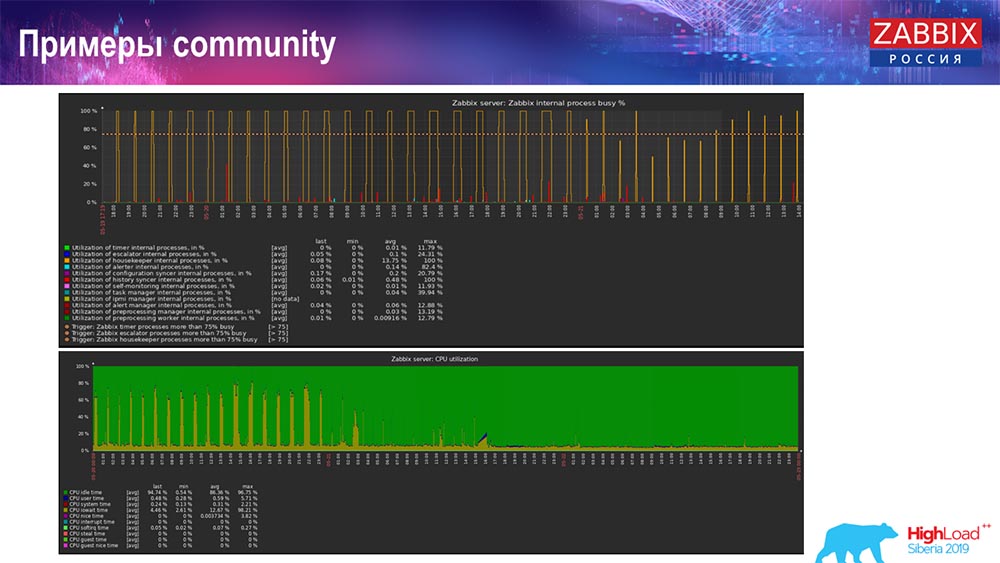 Pria itu juga menyalakan TimescaleDB dan beban untuk menggunakan io.weight jatuh pada prosesor; dan penggunaan elemen proses internal juga menurun berkat dimasukkannya TimescaleDB. Dan ini adalah disk pancake biasa, yaitu, mesin virtual biasa pada disk biasa (bukan SSD)!Untuk beberapa pengaturan kecil yang mengandalkan kinerja disk, TimescaleDB, menurut saya, adalah solusi yang sangat bagus. Ini akan memungkinkan Anda untuk terus bekerja dengan baik sebelum bermigrasi ke perangkat keras yang lebih cepat untuk basis data.Saya mengundang Anda semua ke acara kami: Konferensi - di Moskow, KTT - di Riga. Gunakan saluran kami - Telegram, forum, IRC. Jika Anda memiliki pertanyaan - datang ke konter kami, kami dapat membicarakan semuanya.
Pria itu juga menyalakan TimescaleDB dan beban untuk menggunakan io.weight jatuh pada prosesor; dan penggunaan elemen proses internal juga menurun berkat dimasukkannya TimescaleDB. Dan ini adalah disk pancake biasa, yaitu, mesin virtual biasa pada disk biasa (bukan SSD)!Untuk beberapa pengaturan kecil yang mengandalkan kinerja disk, TimescaleDB, menurut saya, adalah solusi yang sangat bagus. Ini akan memungkinkan Anda untuk terus bekerja dengan baik sebelum bermigrasi ke perangkat keras yang lebih cepat untuk basis data.Saya mengundang Anda semua ke acara kami: Konferensi - di Moskow, KTT - di Riga. Gunakan saluran kami - Telegram, forum, IRC. Jika Anda memiliki pertanyaan - datang ke konter kami, kami dapat membicarakan semuanya.Pertanyaan pemirsa
Pertanyaan dari hadirin (selanjutnya - A): - Jika TimescaleDB sangat mudah dikonfigurasi, dan memberikan peningkatan kinerja seperti itu, maka mungkin itu harus digunakan sebagai praktik terbaik untuk mengatur Zabbix dengan Postgres? Dan apakah ada kekurangan dan kekurangan dari keputusan ini, atau masih, jika saya memutuskan untuk membuat Zabbix sendiri, saya dapat dengan aman mengambil Postgres, langsung menempatkan Timescale di sana, menggunakannya dan tidak memikirkan masalah apa pun ? AH:- Ya, saya akan mengatakan bahwa ini adalah rekomendasi yang bagus: segera gunakan Postgres dengan ekstensi TimescaleDB. Seperti yang saya katakan, banyak ulasan bagus, meskipun faktanya "fitur" ini bersifat eksperimental. Tetapi pada kenyataannya, tes menunjukkan bahwa ini adalah solusi hebat (dengan TimescaleDB), dan saya pikir itu akan berkembang! Kami mengamati bagaimana ekspansi ini berkembang dan akan memperbaiki apa yang dibutuhkan.Bahkan selama pengembangan, kami mengandalkan salah satu "fitur" terkenal mereka: di sana Anda dapat bekerja dengan potongan sedikit berbeda. Tapi kemudian mereka melihatnya di rilis berikutnya, dan kami tidak lagi bergantung pada kode ini. Saya akan merekomendasikan menggunakan solusi ini pada banyak pengaturan. Jika Anda menggunakan MySQL ... Untuk pengaturan menengah, solusi apa pun berfungsi dengan baik.A:- Pada grafik terbaru, yang berasal dari komunitas, ada grafik dengan "Housekeeper":
AH:- Ya, saya akan mengatakan bahwa ini adalah rekomendasi yang bagus: segera gunakan Postgres dengan ekstensi TimescaleDB. Seperti yang saya katakan, banyak ulasan bagus, meskipun faktanya "fitur" ini bersifat eksperimental. Tetapi pada kenyataannya, tes menunjukkan bahwa ini adalah solusi hebat (dengan TimescaleDB), dan saya pikir itu akan berkembang! Kami mengamati bagaimana ekspansi ini berkembang dan akan memperbaiki apa yang dibutuhkan.Bahkan selama pengembangan, kami mengandalkan salah satu "fitur" terkenal mereka: di sana Anda dapat bekerja dengan potongan sedikit berbeda. Tapi kemudian mereka melihatnya di rilis berikutnya, dan kami tidak lagi bergantung pada kode ini. Saya akan merekomendasikan menggunakan solusi ini pada banyak pengaturan. Jika Anda menggunakan MySQL ... Untuk pengaturan menengah, solusi apa pun berfungsi dengan baik.A:- Pada grafik terbaru, yang berasal dari komunitas, ada grafik dengan "Housekeeper":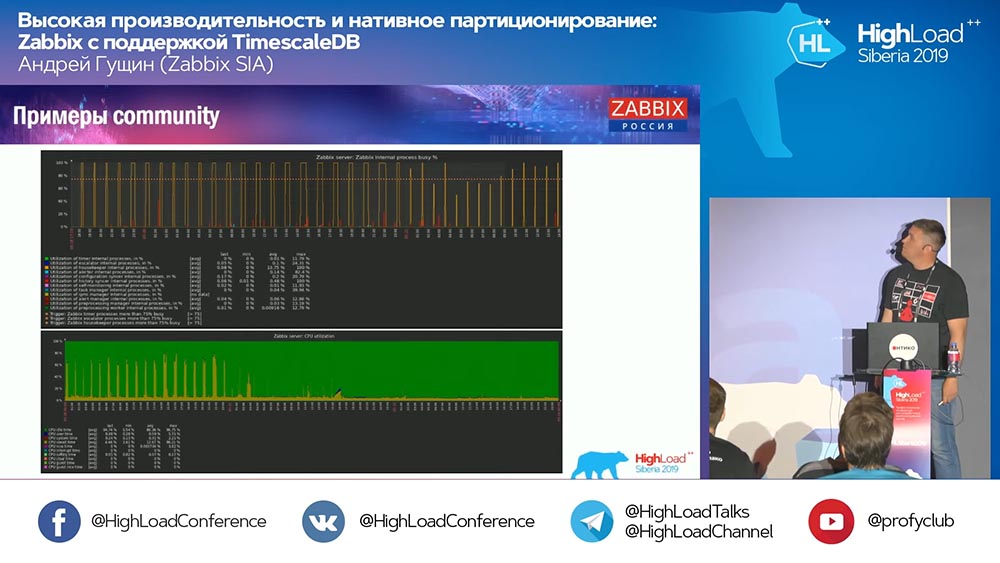 Itu terus bekerja. Apa yang dilakukan Hauskiper dengan TimescaleDB?AG: - Sekarang saya tidak bisa mengatakan dengan pasti - Saya akan melihat kode dan mengatakan lebih detail. Itu tidak menggunakan kueri TimescaleDB untuk menghapus potongan, tapi entah bagaimana menggabungkannya. Meskipun saya belum siap untuk menjawab pertanyaan teknis ini. Kami akan mengklarifikasi di stand hari ini atau besok.A: - Saya punya pertanyaan serupa - tentang kinerja operasi hapus di Timescale.A (respons dari audiens): - Ketika Anda menghapus data dari tabel, jika Anda melakukannya melalui delete, maka Anda harus melalui tabel - hapus, bersih, tandai semua untuk vakum di masa mendatang. Di Timescale, karena Anda memiliki bongkahan, Anda bisa jatuh. Secara kasar, Anda hanya mengatakan pada file yang ada dalam data besar: "Hapus!""Skala waktu" hanya memahami bahwa tidak ada potongan seperti itu lagi. Dan karena ia terintegrasi ke dalam perencana kueri, ia menangkap kondisi Anda pada hook di operasi tertentu atau lainnya dan segera memahami bahwa bidak ini tidak ada lagi - “Saya tidak akan pergi ke sana lagi!” (Data tidak tersedia). Itu saja! Artinya, pemindaian tabel digantikan oleh penghapusan file biner, jadi itu cepat.A:- Sudah menyentuh topik bukan SQL. Sejauh yang saya mengerti, Zabbix tidak benar-benar perlu memodifikasi data, tetapi semua ini seperti log. Apakah mungkin untuk menggunakan basis data khusus yang tidak dapat mengubah data mereka, tetapi pada saat yang sama menyimpan, mengakumulasi, memberikan - Clickhouse, katakanlah sesuatu seperti kafka? .. Kafka juga merupakan log! Apakah mungkin untuk mengintegrasikannya?AH:- Bongkar dapat dilakukan. Kami memiliki "fitur" tertentu dari versi 3.4: Anda dapat menulis semua file historis, acara, semua lainnya ke file; dan kemudian mengirimkannya oleh penangan mana saja ke basis data lain. Bahkan, banyak yang mengulang dan menulis langsung ke database. Saat itu juga, sinkronisasi sejarah menulis semua ini ke file, memutar file-file ini, dan seterusnya, dan Anda dapat membuang ini ke Clickhouse. Saya tidak bisa mengatakan tentang rencana tersebut, tetapi, mungkin, dukungan lebih lanjut untuk solusi NoSQL (seperti "Clickhouse") akan terus berlanjut.A: - Secara umum, ternyata Anda benar-benar dapat menyingkirkan postgres?AH:- Tentu saja, bagian yang paling sulit di Zabbix adalah tabel sejarah, yang menciptakan banyak masalah, dan peristiwa. Dalam hal ini, jika Anda tidak menyimpan acara untuk waktu yang lama dan menyimpan sejarah dengan tren di beberapa penyimpanan cepat lainnya, maka, secara umum, tidak akan ada masalah.A: - Bisakah Anda menilai seberapa cepat semuanya akan bekerja jika Anda pergi ke Clickhouse, misalnya?AG: - Saya tidak menguji. Saya pikir setidaknya angka yang sama dapat dicapai dengan cukup sederhana, mengingat "Clickhouse" memiliki antarmuka sendiri, tetapi saya tidak bisa mengatakannya dengan pasti. Lebih baik diuji. Itu semua tergantung pada konfigurasi: berapa banyak host yang Anda miliki dan sebagainya. Sisipan adalah satu hal, tetapi Anda masih perlu mengambil data ini - Grafana atau yang lainnya.A:- Artinya, kita berbicara tentang pertarungan yang setara, dan bukan tentang keuntungan besar dari database cepat ini?AG: - Saya pikir ketika kami berintegrasi, akan ada tes yang lebih akurat.A: - Kemana perginya RRD tua yang baik? Apa yang membuat Anda beralih ke database SQL? Awalnya, pada RRD, semua metrik dikumpulkan.AG: - Dalam RRD "Zabbix", mungkin itu dalam versi yang sangat kuno. Selalu ada database SQL - pendekatan klasik. Pendekatan klasiknya adalah MySQL, PostgreSQL (sudah ada sejak lama). Kami memiliki antarmuka umum untuk database SQL dan RRD, kami hampir tidak pernah menggunakannya.
Itu terus bekerja. Apa yang dilakukan Hauskiper dengan TimescaleDB?AG: - Sekarang saya tidak bisa mengatakan dengan pasti - Saya akan melihat kode dan mengatakan lebih detail. Itu tidak menggunakan kueri TimescaleDB untuk menghapus potongan, tapi entah bagaimana menggabungkannya. Meskipun saya belum siap untuk menjawab pertanyaan teknis ini. Kami akan mengklarifikasi di stand hari ini atau besok.A: - Saya punya pertanyaan serupa - tentang kinerja operasi hapus di Timescale.A (respons dari audiens): - Ketika Anda menghapus data dari tabel, jika Anda melakukannya melalui delete, maka Anda harus melalui tabel - hapus, bersih, tandai semua untuk vakum di masa mendatang. Di Timescale, karena Anda memiliki bongkahan, Anda bisa jatuh. Secara kasar, Anda hanya mengatakan pada file yang ada dalam data besar: "Hapus!""Skala waktu" hanya memahami bahwa tidak ada potongan seperti itu lagi. Dan karena ia terintegrasi ke dalam perencana kueri, ia menangkap kondisi Anda pada hook di operasi tertentu atau lainnya dan segera memahami bahwa bidak ini tidak ada lagi - “Saya tidak akan pergi ke sana lagi!” (Data tidak tersedia). Itu saja! Artinya, pemindaian tabel digantikan oleh penghapusan file biner, jadi itu cepat.A:- Sudah menyentuh topik bukan SQL. Sejauh yang saya mengerti, Zabbix tidak benar-benar perlu memodifikasi data, tetapi semua ini seperti log. Apakah mungkin untuk menggunakan basis data khusus yang tidak dapat mengubah data mereka, tetapi pada saat yang sama menyimpan, mengakumulasi, memberikan - Clickhouse, katakanlah sesuatu seperti kafka? .. Kafka juga merupakan log! Apakah mungkin untuk mengintegrasikannya?AH:- Bongkar dapat dilakukan. Kami memiliki "fitur" tertentu dari versi 3.4: Anda dapat menulis semua file historis, acara, semua lainnya ke file; dan kemudian mengirimkannya oleh penangan mana saja ke basis data lain. Bahkan, banyak yang mengulang dan menulis langsung ke database. Saat itu juga, sinkronisasi sejarah menulis semua ini ke file, memutar file-file ini, dan seterusnya, dan Anda dapat membuang ini ke Clickhouse. Saya tidak bisa mengatakan tentang rencana tersebut, tetapi, mungkin, dukungan lebih lanjut untuk solusi NoSQL (seperti "Clickhouse") akan terus berlanjut.A: - Secara umum, ternyata Anda benar-benar dapat menyingkirkan postgres?AH:- Tentu saja, bagian yang paling sulit di Zabbix adalah tabel sejarah, yang menciptakan banyak masalah, dan peristiwa. Dalam hal ini, jika Anda tidak menyimpan acara untuk waktu yang lama dan menyimpan sejarah dengan tren di beberapa penyimpanan cepat lainnya, maka, secara umum, tidak akan ada masalah.A: - Bisakah Anda menilai seberapa cepat semuanya akan bekerja jika Anda pergi ke Clickhouse, misalnya?AG: - Saya tidak menguji. Saya pikir setidaknya angka yang sama dapat dicapai dengan cukup sederhana, mengingat "Clickhouse" memiliki antarmuka sendiri, tetapi saya tidak bisa mengatakannya dengan pasti. Lebih baik diuji. Itu semua tergantung pada konfigurasi: berapa banyak host yang Anda miliki dan sebagainya. Sisipan adalah satu hal, tetapi Anda masih perlu mengambil data ini - Grafana atau yang lainnya.A:- Artinya, kita berbicara tentang pertarungan yang setara, dan bukan tentang keuntungan besar dari database cepat ini?AG: - Saya pikir ketika kami berintegrasi, akan ada tes yang lebih akurat.A: - Kemana perginya RRD tua yang baik? Apa yang membuat Anda beralih ke database SQL? Awalnya, pada RRD, semua metrik dikumpulkan.AG: - Dalam RRD "Zabbix", mungkin itu dalam versi yang sangat kuno. Selalu ada database SQL - pendekatan klasik. Pendekatan klasiknya adalah MySQL, PostgreSQL (sudah ada sejak lama). Kami memiliki antarmuka umum untuk database SQL dan RRD, kami hampir tidak pernah menggunakannya.
Sedikit iklan :)
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikan kepada teman Anda,
VPS berbasis cloud untuk pengembang mulai $ 4,99 ,
analog unik dari server entry-level yang diciptakan oleh kami untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps mulai dari $ 19 atau cara membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
Dell R730xd 2 kali lebih murah di pusat data Equinix Tier IV di Amsterdam? Hanya kami yang memiliki
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV dari $ 199 di Belanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - mulai dari $ 99! Baca tentang
Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?