Zabbix adalah sistem pemantauan terbuka populer yang digunakan oleh sejumlah besar perusahaan. Saya akan berbicara tentang pengalaman membuat cluster pemantauan.
Dalam laporan itu, saya secara singkat menyebutkan perubahan yang dibuat sebelumnya (tambalan), yang secara signifikan memperluas kemampuan sistem dan menyiapkan dasar untuk klaster (mengunggah riwayat ke "Clickhouse", polling asinkron). Dan saya akan mempertimbangkan secara rinci masalah yang muncul selama pengelompokan sistem - menyelesaikan konflik identitas dalam database, sedikit tentang teorema CAP dan pemantauan dengan database terdistribusi, tentang nuansa Zabbix yang bekerja dalam mode cluster: cadangan dan koordinasi server dan proksi, tentang "domain pemantauan" dan tampilan baru pada arsitektur sistem.
Saya akan berbicara singkat tentang cara memulai sebuah cluster di rumah, di mana mendapatkan sumber, dan apa yang tambahan. pengaturan akan diperlukan untuk cluster.

HighLoad ++ Siberia 2019. Tomsk Hall. 24 Juni, jam 5 malam Abstrak dan
presentasi . Konferensi HighLoad ++ berikutnya akan diadakan pada 6 dan 7 April 2020 di St. Petersburg. Detail dan tiket di
sini .
Mikhaili Makurov (selanjutnya - MM): - Saya bekerja untuk perusahaan penyedia. Penyedia disebut Intersvyaz, ia bekerja di kota Chelyabinsk. Kami memiliki sekitar 1,5 juta orang. Dan agar penyedia dapat bekerja, ada infrastruktur yang sangat besar. Kami memiliki sekitar 70 ribu peralatan: sakelar, perangkat IoT ... - banyak hal yang perlu dipantau. Secara khusus, laporan ini adalah tentang penggunaan Zabbix, tentang membangun sebuah cluster berdasarkan Zabbix untuk pemantauan infrastruktur.
Saya 12 tahun di penyedia. Sekarang saya tidak melakukan hal-hal teknis sama sekali, ini lebih tentang mengelola orang. Dan ini (hal-hal teknis) sebenarnya adalah hobi saya. Saya akan mengembangkan topik ini sedikit.
Memantau masalah
Saya pikir saya beruntung. Sekitar satu setengah tahun yang lalu, saya berakhir di sebuah proyek yang terdengar seperti ini: "Kita perlu menyelesaikan beberapa masalah dengan pemantauan kita." Saya mewarisi zona tanggung jawab (pemantauan), yang terdiri dari sekelompok server, khususnya 21 server:

Ada 4 server yang kuat dan 15 proxy - semuanya perangkat keras. Ada beberapa keluhan tentang pemantauan ini. Yang pertama adalah banyak. Kami belum memiliki satu server dengan penyedia yang menghabiskan begitu banyak ruang. Ini adalah uang, listrik ... Sebenarnya, ini bukan masalah besar.

Masalah besar adalah bahwa pemantauan tidak sesuai dengan berapa banyak yang kami inginkan darinya. Bagi mereka yang belum secara aktif menggunakan Zabbix, ini adalah dasbor yang menunjukkan keterlambatan pada pemeriksaan:

Sebagian besar cek kami berada di zona merah. Mereka berlari lebih dari 10 menit lebih lambat dari yang kita inginkan, yaitu, mereka terlambat 10 menit. Itu tidak terlalu menyenangkan, tetapi masih mungkin untuk hidup lebih atau kurang. Masalah terbesar adalah ini:

Itu adalah sistem pemantauan jaringan kerja. Ketika pekerjaan yang direncanakan dilakukan, segmen ribuan jatuh pada lima sakelar. Bersama-sama dengan sakelar ini, sakelar dan pemantauan dilupakan. Ketika semuanya dipulihkan, dua jam kemudian dan pemantauan dipulihkan. Itu sangat tidak menyenangkan, dan frasa ini harus ada di setiap laporan:

"Kita harus melakukan sesuatu dengan proyek ini!"
Dan di sini saya akan menceritakan dua kisah. Kemudian kami mencoba untuk pergi secara bersamaan dalam dua cara. Kami memiliki grup integrasi - ia memilih cara untuk membangun sistem modular (ada laporan yang sangat keren dari Avito ke Highload pada November tahun lalu di Moskow - mereka membicarakan hal ini):

Zabbix = orang + API + efisiensi
Orang-orang dari potongan-potongan kecil mulai membangun sistem. Dan dengan beberapa peminat, saya terus mengerjakan Zabbix. Ada alasan untuk itu. Apa alasannya?
- Pertama, ada API keren. Dan ketika Anda memiliki 60-70 ribu elemen pemantauan, jelas bahwa ini semua hanya berfungsi secara otomatis - Anda tidak dapat menambahkan begitu banyak tangan tanpa kesalahan.
- Personil. Ada shift pemantauan bertugas yang berlangsung 24/7. Ini bukan spesialis IT, ini adalah orang-orang yang bertugas. Kami menunjukkan "Grafan" beberapa sistem lain - sulit bagi mereka. Ada admin yang terbiasa dengan keanekaragaman, kenyamanan pemantauan di Zabbix itu sendiri: template, deteksi otomatis - dan itu semua keren!
- Zabbix bisa efektif.
Apakah database SQL melambat? Satu jawaban - Clickhouse
Alasan pertama jelas. Kami kemudian bekerja pada MySQL, dan kami berlari ke sekitar 6-7 ribu metrik per detik, kami melihat penundaan yang konstan pada disk.

Hari ini sudah 100 kali terdengar: satu-satunya jawaban adalah Clickhouse:
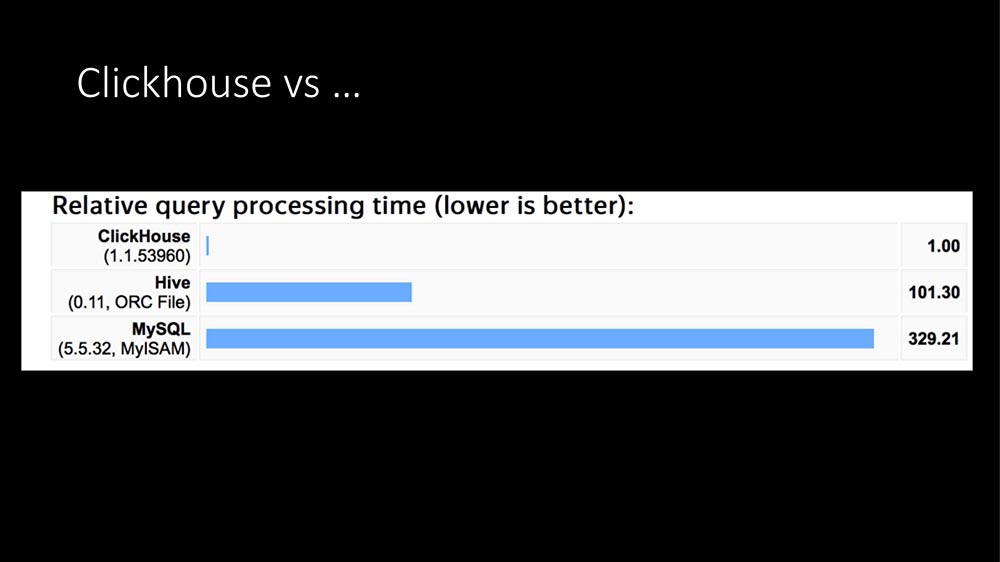
Dalam struktur kueri, sebagian besar kueri (profil kami dalam beberapa jam) adalah catatan metrik. Menulis metrik ke database SQL sangat mahal. Di sini TimeScaleDB muncul ... Kemudian kami memiliki "Clickhouse" yang beroperasi selama sekitar satu tahun untuk tugas-tugas lain (kami mengerjakan data besar, kami memiliki aplikasi besar - secara umum, penyedia sekarang merupakan bisnis TI keseluruhan).
Setelah melihat grafik yang indah dari Internet (bahwa "Clickhouse" ratusan kali lebih cepat, yang membutuhkan ruang sangat sedikit) dan memiliki pengalaman saat ini, kami menulis modul HistoryStorage kami untuk "Zabbix" sehingga dapat menyimpan data "Clickhouse" secara langsung (yaitu, bukan dari ekspor file, tetapi langsung on the fly).

Selain itu, kami menulis modul untuk "depan". Semua gambar indah ini di panel admin Zabbix dapat dibangun dari Clickhouse. Jelas bahwa API juga berfungsi.
Efeknya kira-kira sama - SQL server sebagai entitas yang berdedikasi tidak menjadi sepenuhnya, yaitu beban turun menjadi nol. Apa yang paling luar biasa, kami sudah memiliki cluster "Clickhouse" khusus: ketika kami memberikan semua beban kami di sana, itu meningkat dari 6 menjadi 10 ribu metrik. Orang-orang yang mengelola berkata: "Tapi kami tidak melihat sesuatu yang telah datang. Tidak! ”
Bagaimana kami memperluas Clickhouse
Saya akan mengatakan lebih jauh: untuk pengujian kami mencoba memuat hingga 140-150 ribu metrik per detik (kami tidak bisa lagi memeras dari Zabbix, nanti saya akan mengatakan alasannya), dan Clickhouse juga tidak melihat beban ini. Artinya, sangat nyaman, beban dingin. Secara umum, ada modul seperti itu.
Selain itu, kami sedikit mengembangkannya:

Dalam versi kami, Anda dapat mematikan nanodetik. Anda mungkin tahu: Zabbix menulis detik dan nanodetik dalam dua bidang. Di bidang "Clickhouse" di mana variabilitasnya sangat besar, membutuhkan banyak ruang.
Ngomong-ngomong, tentang tempat itu. Satu metrik di Clickhouse (saat ini kami memiliki sekitar 700 miliar metrik yang tercatat) membutuhkan 2,9 byte. Menurut dokumentasi Zabbix, satu metrik dalam database SQL memakan waktu dari 40 hingga 100 byte. Mematikan nanodetik menghemat 40% lagi, yaitu sekitar 1,5 byte per metrik. Artinya, "Clickhouse" sangat efektif dalam hal lokasi.
Atas permintaan orang-orang kami yang terlibat dalam pembelajaran mesin, kami membuat pilihan sehingga kami dapat menulis host dan nama metrik. Karena variabilitas data besar, ini tidak memakan banyak ruang tambahan, meskipun fakta bahwa data teks bisa signifikan (belum diverifikasi dengan tes panjang).
Plus, kami membuat dua tambahan, karena kami mengembangkan Zabbix dan seringkali harus menariknya. Tambahan yang sangat keren: di awal, karena "Clickhouse" memungkinkan Anda membaca jutaan catatan, kami dapat mengisi cache riwayat. Pada awalnya, kami ditunda selama 30-40 detik tambahan, tetapi kami mendapatkan layanan segera diluncurkan dengan cache yang hangat.
Dalam kasus di mana lebih mudah untuk mengumpulkan dari infrastruktur, masih ada opsi seperti itu: untuk melarang membaca dari cache untuk beberapa waktu. Lebih baik bekerja cepat selama 5 menit, tidak menghitung pemicu, dan kemudian cache akan terisi - jika Anda tidak melakukan ini, stagnasi para penyelesai sejarah dimulai.
Secara umum, ada modul "Clickhouse". Itu bisa digunakan.
Efisiensi pemungutan suara
Terlepas dari kenyataan bahwa kami kemudian memecahkan masalah dengan pangkalan, rem dan masalah dengan lima belas proxy masih tetap ada. Mereka terhubung dengan ini:

Ini adalah pipa pemrosesan data utama di Zabbix. Ada tahap pengumpulan data, ada preprocessing, dan ada sinkronisasi sejarah yang melakukan semua pekerjaan (perhitungan pemicu, peringatan, menyimpan riwayat). Hambatan cache ternyata adalah:

Mengapa pemungutan suara lambat? Karena utas yang membuat permintaan masuk ke antrian dalam konfigurasi cache untuk metrik unit dan memblokirnya. Ada tempat lain, tetapi mereka tidak begitu sempit. Misalnya, ada preprocessing sendiri dan ada History Cache. Pada SQL kami, kami mendapatkan batasan berikut:

Mungkin ini disebabkan oleh fakta bahwa dalam kasus kami, basisnya sekitar 5 juta metrik, yang kami hapus. Dengan semua optimasi yang kami lakukan, kami dapat memperoleh 70 ribu metrik dalam bottleneck (pada Cache Konfigurasi), tetapi hanya dalam kasus ketika kami memprosesnya secara massal.
Apa itu pemrosesan massal? Poller pergi ke Konfigurasi Cache dan mengambil tugas bukan untuk satu metrik, tetapi untuk 4 atau 8 ribu. Pada saat yang sama, ia mendapat kesempatan luar biasa: ia sekarang dapat melakukan polling secara tidak sinkron, karena ia mendapatkan 4 ribu metrik ... Mengapa mereka melakukan satu demi satu? Anda bisa langsung menanyakan semuanya!
Polling asinkron lebih efisien daripada proxy!
Untuk jenis utama yang digunakan oleh penyedia - ini adalah SNMP dan AGEN, kami menulis ulang polling ke mode asinkron, dan secara agregat ini memberikan peningkatan kecepatan dari 100 menjadi 200 kali. Kami memiliki 15 proxy, kami membaginya menjadi 150 - mereka benar-benar hilang. Akibatnya, semuanya berubah menjadi dua bank, yang hanya diperlukan untuk cadangan:

Bank Uniprocessor (satu biaya Xeon 1280). Inilah saatnya saya:

Sekitar 60% gratis, tetapi dering dari 60% hingga 40% ini menjalankan skrip periodik pada mesin itu sendiri (skrip eksternal). Mereka dapat dioptimalkan sampai masalah dibuat.
Skala adalah sesuatu seperti ini:

Ini adalah 62 ribu host, sekitar 5 juta metrik. Kebutuhan kita saat ini adalah sekitar 20 ribu metrik per detik.
Ya, seperti semuanya? Kami memecahkan masalah kinerja, Riwayat diperluas, Polling luar biasa. Apakah masalah teratasi? Tidak juga ... Semuanya akan terlalu sederhana.
Saya memainkan trik pada grafik sebelumnya (tidak semua ditampilkan):

Ada dua masalah. Saya ingin mengatakan: "Bodoh, jalan." Ada faktor manusia, ada peralatan.
Satu server masih belum cukup. Dalam sekitar satu tahun operasi, ada dua kasus dengan masalah perangkat keras - drive SSD dan yang lainnya. Sebagian besar masalah adalah faktor manusia ketika orang melakukan semacam pengujian. Di perusahaan kami, Zabbix digunakan sebagai layanan: semua departemen dapat menulis sesuatu sendiri di sana.
Saya ingin berkembang. Saya ingin tidak bergantung pada satu kaleng. Saya ingin kami bisa tetap lebih kuat. Dan saya ingin meningkatkan skala sesuai dengan prinsip Scale-out. Bahkan tidak ada yang perlu dibicarakan di sini: untuk tumbuh, meningkatkan kapasitas satu kaleng, sudah tidak relevan selama 20 tahun.

Cluster meminta ...
Di suatu tempat di bulan Desember, versi pertama muncul. Unit gugus atom adalah apa yang diproses pada host yang terpisah. Tuan rumah telah dipilih.

Faktanya adalah bahwa di Zabbix ada koneksi yang cukup kuat antara item yang dapat berada di host yang sama, yaitu, pemicu dapat dihubungkan, mereka dapat diproses bersama dalam preprocessing. Tetapi di antara host-host konektivitasnya tidak terlalu tinggi, jadi itu normal untuk menggunakan cluster ini antara node-node dari cluster - akan ada banyak lalu lintas di sana. Tugas utama cluster adalah untuk menyetujui di antara mereka sendiri yang terlibat dalam host.
Saya ingin mencapai batas maksimum 60-70 ribu metrik kami, karena selera makan datang bersama. Kami memiliki orang yang terlibat dalam QoE ... Quality of Experience - sebuah analisis tentang bagaimana Internet bekerja untuk pelanggan berdasarkan metrik transit, yaitu, Anda memasok semua metrik TCP ke 1,5 juta orang, menuangkannya ke dalam pemantauan - ada banyak data.
Dan saya menginginkan keandalan. Saya menginginkannya jika sesuatu terjadi ... Petugas jaga shift menelepon, berkata, "Kami memiliki masalah dengan server," mematikannya, kami akan mencari tahu besok.
Cluster pertama
Versi pertama diimplementasikan berdasarkan etcd:

Etcd adalah penyimpanan nilai kunci terdistribusi yang digunakan dalam banyak proyek progresif (sejauh yang saya mengerti, di Kubernetes). Semuanya luar biasa. Etcd menyediakan alat yang sangat menarik - misalnya, itu memecahkan masalah memilih server utama. Tapi masalah seperti itu ...
Kami memiliki tiga tautan klasik "Zabbix": "web" - basis - server itu sendiri. Dan kami menambahkan "Clickhouse" di sana, dan sekarang kami menambahkan etcd juga. Admin mulai menggaruk di belakang kepala mereka: ada terlalu banyak dependensi di sini - mungkin tidak akan dapat diandalkan. Dalam proses pengembangan, satu hal lagi menjadi jelas: di Zabbix sendiri sudah ada cara interserver komunikasi, itu hanya digunakan antara server dan proxy, yang disebut proses poller proxy:

Ini cukup keren untuk komunikasi interserver dengan perubahan minimal. Ini memungkinkan etcd untuk tidak menggunakan (setidaknya sementara), sangat menyederhanakan kode, dan yang paling penting, bekerja pada kode yang telah diverifikasi (sepertinya 5 atau 7 tahun untuk kode ini).
Bagaimana server terkoordinasi dalam sebuah cluster?
Koordinasi dilakukan berdasarkan jenis, seperti protokol IGP. Agar server mendapat prioritas (sekarang saya akan mengatakan mengapa ini perlu) dan untuk menghindari konflik dalam database SQL saat menulis log, setiap server diberi pengenal (sejauh ini secara manual) - ini adalah angka dari 0 hingga 63 (63 - itu hanya sebuah konstanta, mungkin lebih):

Server dengan pengidentifikasi maksimum menjadi "master". Ketika kami meluncurkan kelompok uji pertama kami, hal pertama yang dikatakan admin kami adalah: “Wow! Dan mari kita letakkan mereka di situs yang berbeda. Baiklah, bagus! ”(Kami akan kembali ke sini). Dan ketika seseorang telah mendistribusikan cluster, akan dimungkinkan untuk mengontrol bagaimana topologi didistribusikan kembali: ke mana peran "master" pergi jika terjadi penurunan pada server "Zabbix" utama:

Dalam hal ini, seperti ini:

Melangkah
Dalam Zabbix asli, ini dilakukan seperti ini: server itu sendiri bertanggung jawab untuk menghasilkan indeks kenaikan otomatis. Untuk mencegah banyak kejadian menginjak tumit satu sama lain (agar tidak membuat log dengan indeks yang sama), melangkah digunakan: "Zabbix" dengan pengidentifikasi "1" akan menghasilkan kelipatan satu - 1, 11, 21; dengan pengidentifikasi "7" - 7, 17, 27 (dengan nuansa).
Kami melaju dengan pengubah.

Bagaimana server berinteraksi satu sama lain?
Ini adalah warisan Paket Hello IGP setiap 5 detik. Jadi server tahu bahwa mereka memiliki tetangga. Jadi "master" tahu bahwa ada tetangga di dekatnya, dan atas dasar ini, "master" memutuskan host mana yang dapat didistribusikan ke server mana.

Dengan demikian, ada konfigurasi. Menurut ingatan lama, saya menyebutnya topologi. Topologi pada dasarnya adalah daftar server dan host milik mereka.
Protokolnya sederhana - ini JSON:

Ini juga merupakan warisan dari Zabbix proxy dan komunikasi server Zabbix. Secara umum, tidak masuk akal untuk menggunakan sesuatu yang lain. Satu-satunya hal adalah bahwa dalam kasus Zabbix ada 4 byte (ZBXD), tetapi ini bukan intinya.
Dalam paket halo, pengidentifikasi server ditransmisikan: ketika server mengirim paket, ia mengatakan pengidentifikasi dan versi topologinya - dengan cara ini server dengan cepat mengetahui bahwa ada versi baru dari topologi dan diperbarui dengan sangat cepat.
Sebenarnya, topologi itu sendiri hanyalah sebuah pohon, daftar server. Untuk setiap server, daftar host yang didukungnya:

Dan kemudian muncul masalah yang menarik.
Ada frase ajaib - domain pemantauan
Apa gunanya Dalam Zabbix klasik, semuanya sederhana - sikap yang tidak ambigu: host ini dimonitor oleh proxy ini, proxy ini memberikan data ke server. Jika proxy belum diinstal (atau tidak diperlukan), maka server ini memonitor semua host:

Ketika kami memiliki banyak server, apa yang harus dilakukan? Selain itu, mungkin ada masalah dengan fakta bahwa kami memiliki server yang didistribusikan secara geografis, dan server di beberapa kantor yang lambat bekerja di Kemerovo akan mulai mencoba memantau seluruh infrastruktur Novosibirsk.

Kami tidak menginginkan ini. Kami ingin memiliki semacam mekanisme sehingga tidak semua server, tetapi yang kami pilih (mungkin berdasarkan geografi) dapat memonitor host tertentu. Pada saat yang sama, kami ingin mengelola ini, dan kami ingin itu sederhana. Untuk ini, ide pemantauan domain diciptakan. Faktanya, ini adalah grup sederhana - hanya sudah ada grup dalam catatan.
Dan ketika saya melakukan ini, orang-orang dari operasi berbicara dengan saya - mereka berkata: “Kelompok-kelompok itu sangat membingungkan kami. Kami selalu mulai berpikir tentang kelompok normal. ” Oleh karena itu, nama ini: domain pemantauan.
Host secara jelas berhubungan: satu host - satu domain:

Domain host dapat menyertakan sejumlah server. Server dapat berada di sejumlah domain. Ini adalah hal yang sangat fleksibel. Untuk memperluas fleksibilitas dan menghancurkan otak sepenuhnya, ada juga domain default:

Server yang menjadi anggota domain default dipantau oleh semua host yang tidak memiliki server langsung atau yang tidak memiliki domain pemantauan.
Ini hanya memungkinkan kita untuk mengikat host secara topologis ke beberapa server dan mengontrol bagaimana host didistribusikan jika satu server jatuh:

Masalah berikutnya yang kami temui ...
Cluster: Berpikir Berbeda
Ketika kami memiliki banyak server, ada peluang baru untuk membangun sebuah cluster, untuk membangun topologi. Ini sangat klasik ketika kami memiliki semacam situs pusat dan ada yang jauh; atau, katakanlah, proksi tempat beban didelegasikan:

Dalam kasus cluster Zabbix, ini dapat diimplementasikan dalam dua cara. Anda dapat menggunakan cara klasik: cukup gandakan infrastruktur. Di pusat, kami memiliki dua server yang membentuk sebuah cluster, dapat mengatur ulang host atau mengambil beban pada diri mereka sendiri jika tetangga jatuh. Dengan demikian, Anda dapat meningkatkan proxy tambahan di server yang sama - kami mendapatkan cadangan ganda:

Anda dapat menggunakan "fitur" baru dan melakukan ini:

Hal utama adalah tidak pergi ke situasi di mana server yang secara geografis jauh sedang memantau beberapa infrastruktur besar di tempat lain. Ini lebih merupakan masalah administrasi (saya menyebutnya bisnis) karena ini adalah masalah konfigurasi.
Cluster: membagi otak dan sudut pandang
, :
- split brain;
- point of view ( ).
. Split brain – , . , - – ? , , ( ).
point of view : , , , . . , RTT , .
:

, . , , . , – . , , , .
SQL-
, , , . . , , … . .
-, , , - – . , Galera MySQL.
PostgreSQL. «» : , , – . «», , .
?
, :


– . :
- - (Logs), . problems, events events recovery. , – , .
- 15 (State). – ( – – «» ). . , ; – …
- - (Configuration update).
«. «», SQL-:

-, :

. -, , … – , 2 ! : « , ». - , , .
. , :

, . SQL- . , SQL-. ( - ), «» ( ). …
.
, , «» . . , ?

«»- (. . «» daemon). ( ): ( 1 63, «») ( , ).
ServerIP IP-. , , IP- . - , proxy poller, trapper hello-, proxy poller .
. , , « »:

:

, default. . – , IP-, , ( ). «» – default.
-, .
- .
- , : « , ». .
- - , .
- , hello-time, : « »; .
- .
, , , . 30-40 . , , , .
, . - : « , !» -!

– : - , - , , GitLab, CI/CD, . , , – .
, , – 4.0.9 (4.2 ). Roadmap – -. -, «»; , RPM'.

( ) «» «»-. . , . – : , - … ? !.. «», .
SQL- , , . History Storage.
Referensi
5 . .
-, , , , . . -.

, ? ! , , , . - - , . , , . , :

. «»- , .
- , , , .
- «» : , Configuration Cache, .
- , , . , , .
- - , . , , . 200 , – .
Catatan: proksi pasif belum didukung!Saya menghapus kode. Ini disebabkan oleh kenyataan bahwa sulit bagi orang untuk membuat mekanisme lain, server mana yang masih akan bertanggung jawab untuk proxy ini.Proxy aktif sendiri masuk ke server. Ada opsi Server untuk ini (proxy standar). Proxy yang dimodifikasi memiliki opsi Server: Dan apa yang dilakukan oleh server yang dimodifikasi tersebut? Itu membuat koneksi KPI dengan semua server yang ditentukan untuk itu; meminta konfigurasi, mengirim data ke server pertama yang tersedia dari daftar. Ini menyelesaikan masalah. Misalkan jika Anda memiliki proxy yang dikonfigurasi pada server Zabbix dan server Zabbix telah jatuh, ada satu lagi di cluster sehingga tidak dibiarkan tanpa proxy; maka proxy hanya kait ke yang lain.
Dan apa yang dilakukan oleh server yang dimodifikasi tersebut? Itu membuat koneksi KPI dengan semua server yang ditentukan untuk itu; meminta konfigurasi, mengirim data ke server pertama yang tersedia dari daftar. Ini menyelesaikan masalah. Misalkan jika Anda memiliki proxy yang dikonfigurasi pada server Zabbix dan server Zabbix telah jatuh, ada satu lagi di cluster sehingga tidak dibiarkan tanpa proxy; maka proxy hanya kait ke yang lain.Pertanyaan
Pertanyaan dari audiens (selanjutnya - A): - Saya ingin mengklarifikasi keadaan di antara server? Protokol apa yang mereka gunakan untuk berkomunikasi? Apakah ada keamanan? Karena tidak terlalu "aman" untuk membawa komunikasi antar server ke Internet ... Bagaimana kabarnya?
MM: - Saya pikir ini adalah penantang untuk pertanyaan terbaik - to the point! Bahkan, ketika kami beralih ke komunikasi standar, server untuk komunikasi interserver mereka mewarisi semua token protokol komunikasi yang ada antara server dan proksi. Saya akan mengklarifikasi: ada enkripsi, kompresi data. Tolong - dengan cara yang sama semuanya dikonfigurasikan melalui web, karena dikonfigurasi secara standar untuk server dan proksi; semuanya akan bekerja.
A: - Bagaimana cara kerja Hauskiper untuk Anda dalam kasus Clickhouse?
MM: - Dalam standar "Zabbix" tidak ada antarmuka dari "Housekeeper" ke History Interface, yaitu, History Interface tidak mendukung rotasi data (ElasticSearch, misalnya, tidak mendukung). Mungkin di 4.2 itu (saya tidak melihat), tetapi sejauh ini pada 4.0.9.
Buat itu mudah! "Clickhouse" baru memiliki partisi. Saya ingin melakukannya dengan melepaskan partisi yang sudah usang. Jelas bahwa tidak akan ada rotasi pada level masing-masing item, tetapi ada trik di Zabbix: Anda dapat menentukan nilai global (misalnya, menyimpan seluruh riwayat selama tidak lebih dari 90 hari) - Anda dapat menghapus semua item, seluruh riwayat dari nilai global ini . Dan itu akan dilakukan! Ada lebih banyak tentang topik ini di Gitlab.
Kami ingin melakukan hak arsitektural: apakah akan memperluas History Interface, sehingga pada dasarnya akan menjadi ... Secara umum, saya tidak ingin meninggalkan hutang teknis, tetapi itu akan dilakukan. Karena itu perlu, semakin banyak "Clickhouse" mulai mendukung.
A: - Bagaimana perasaan Anda tentang ini? Anda, ternyata, melakukan cukup banyak pekerjaan non-penyedia.
MM: - Saya mungkin tidak mengatakannya dengan benar. Ini hobi saya! Saya bukan spesialis teknis - saya seorang manajer. Di waktu senggang saya berlatih.
A: - Saya pikir Anda melakukan ini sebagai bagian dari bisnis inti Anda ...
MM: - Bisnis memberi saya tempat yang keren untuk menguji. Bahkan, saya sangat merekomendasikan - ini menenangkan otak. Di suatu tempat di "hal" manajerial saya akan mengatakan ini - ketika Anda dapat beralih dari masalah manusia ke ini. Mereka sangat keren dipecahkan! Ini adalah masalah teknis. Anda memprogram, dan itu bekerja seperti yang Anda programkan! Sayang sekali orang tidak seharusnya melakukan itu.
A: - Apakah Anda menulis ke "Clickhouse" melalui beberapa proksi atau langsung?
MM: - Langsung. Bahkan, Antarmuka Sejarah yang diubah, yang digunakan untuk "Elastix", juga diwariskan. Url digunakan, yaitu, melalui antarmuka http "Zabbiks" mengirimkan "Clickhouse". Yang keren, Zabbix berkumpul ketika ada aliran besar sejarah, ribuan metrik dalam satu paket, dan ini dengan sangat keren jatuh di Clickhouse.
A: - Sebenarnya, dia menulis bachi untuknya?
MM: - Ya. Satu permintaan SQL yang dijalankan oleh url biasanya berisi seribu metrik. Admin "Clickhouse" hanya senang.
Presenter: - Ini adalah akhir dari program di ruangan ini. Ada program malam yang diselenggarakan, dan ada sesuatu yang hanya dapat Anda lakukan. Dan saya sarankan, sementara Anda akan berkomunikasi satu sama lain, untuk memikirkan hal-hal menarik apa yang dapat Anda lakukan ... Ketika Anda saling memberi tahu tentang kasus Anda, ini kemungkinan besar adalah hal yang dapat Anda laporkan. Dengan berdiskusi satu sama lain, Anda dapat menemukan hanya untuk menemukan garis besar - komite program akan menerima aplikasi Anda, mempertimbangkan dan membantu membuat cerita yang baik dan dikemas dari itu. Mungkin Anda punya semacam cerita tentang bekerja dengan komite program?
MM: - Sebenarnya, banyak umpan balik yang diberikan. Saya sangat beruntung: seseorang dari komite program tinggal di Chelyabinsk saya, dan Highload adalah satu-satunya konferensi yang bekerja sangat dekat dengan para pembicara. Saya belum pernah melihat yang seperti ini di tempat lain. Ini sangat bermanfaat! Tahap berbeda: orang-orang menonton video, memberikan komentar pada slide - itu benar-benar terjadi pada subjek (ejaan, kesalahan ketik). Sangat keren! Saya merekomendasikannya! Coba sendiri!
Sedikit iklan :)
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikan kepada teman Anda,
VPS berbasis cloud untuk pengembang mulai $ 4,99 ,
analog unik dari server entry-level yang diciptakan oleh kami untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps mulai dari $ 19 atau cara membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
Dell R730xd 2 kali lebih murah di pusat data Equinix Tier IV di Amsterdam? Hanya kami yang memiliki
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV dari $ 199 di Belanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - mulai dari $ 99! Baca tentang
Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?