R adalah alat yang sangat ampuh untuk bekerja dengan statistik: dari pra-pemrosesan hingga membangun model kompleksitas dan grafis yang sesuai.
Permintaan Google sederhana akan menyediakan sejumlah besar literatur tentang bagaimana "menggunakan R dengan mudah dan cepat." Akan ada banyak buku dan banyak catatan tentang Stack Overflow , yang, pada pandangan pertama, tampak seperti gudang contoh yang tak ada habisnya, masing-masing dalam dua hitungan akan mengumpulkan kode yang diperlukan untuk menyelesaikan masalah tertentu. Namun, pada kenyataannya ini sama sekali tidak benar. Ada sangat sedikit bahan yang akan memberi tahu, misalnya, bagaimana membangun jadwal sederhana "dari awal" dengan resep yang sudah jadi untuk memecahkan kesulitan yang akan timbul dalam proses penyelesaian masalah ini.
Untuk mengatasi masalah praktis, diperlukan petunjuk langkah demi langkah spesifik, dan bukan deskripsi terperinci tentang kekuatan penuh dari suatu paket. Selain itu, contoh pelatihan siap pakai ( iris yang sama) sering kali tidak banyak berguna, karena mereka segera melewati salah satu tahap terpenting dalam bekerja dengan statistik - pengumpulan awal dan pemrosesan data itu sendiri. Tetapi justru untuk pekerjaan ini bahwa hampir sebagian besar dari semua waktu sering dibutuhkan! Masalah terpisah adalah pembuatan jadwal yang sesuai dengan standar formal, dan lebih sering informal, dari lingkungan profesional tertentu.
Rekan-rekan saya dan saya secara teratur perlu melakukan lebih banyak visualisasi statistik dan model berdasarkan pada mereka untuk mempublikasikan hasil ilmiah. Karena studi ini menyangkut ekonomi, banyak dari karya ini mirip dengan jurnalisme profesional.
Pada titik tertentu, menjadi jelas bahwa untuk kerja tim yang efektif diperlukan semacam pipa pemrosesan statistik yang lengkap. Artikel ini lahir sebagai panduan pengantar untuk rekan kerja dan lembar contekan untuk menjalankan konveyor ini. Tampaknya materi ini dapat bermanfaat bagi khalayak yang lebih luas.
R Pain-Free Graphics: Panduan
Pengaturan dasar R
Untuk bekerja, Anda memerlukan bundel standar: R + RStudio . Mereka tersedia secara gratis untuk semua platform umum. R diinstal terlebih dahulu, kemudian RStudio. Biasanya tidak ada masalah.
Sebelum bekerja, lebih baik untuk segera menyimpan skrip baru di suatu tempat di sistem file Anda dan segera menginstal direktori kerja R di folder tempat skrip disimpan (menu Sesi - Atur Direktori Kerja - Untuk Sumber Lokasi File). Catatan terakhir penting, karena jika tidak, memulai skrip eksternal atau asli setelah me-reboot RStudio tidak akan terjadi. Untuk beberapa alasan, RStudio tidak melakukan ini secara default, yang logis.
Bahkan dalam paket dasar R ada alat visualisasi standar (fungsi plot ) yang memungkinkan Anda untuk membuat banyak jenis grafik, namun demikian, fitur-fitur ini jelas tidak cukup untuk ilustrasi yang lengkap dan sangat dapat disesuaikan.
Pustaka yang paling banyak digunakan untuk grafik dalam R adalah paket ggplot2 , yang juga akan kita gunakan.
Perlu juga segera menginstal paket readxl (untuk membaca file .xls, .xlsx) dan dplyr (untuk bekerja dengan array), skala (untuk bekerja dengan skala data yang berbeda), Kairo (untuk menggambar grafik dari ggplot ke file). Semua ini dapat dilakukan dengan satu perintah:
install.packages("ggplot2", "readxl", "scales", "dplyr", "Cairo")
Pengumpulan dan persiapan data
Hal yang paling mengejutkan adalah bahwa tahap ini dalam literatur apa pun, apakah itu buku teoritis yang serius tentang statistik teoretis terapan atau pedoman untuk paket statistik tertentu, dikhususkan untuk ruang dan waktu yang sangat kecil. Namun demikian, menurut pengalaman penelitian independen dan manajemen siswa dan kolega junior, diketahui bahwa pada tahap ini bagian terbesar dari waktu dan upaya dapat jatuh, oleh karena itu sangat penting untuk menyelamatkan mereka bahkan ketika memecahkan masalah teknis murni.
Ada dua pertanyaan di sini:
- Bagaimana memilih format file yang benar?
- Apa cara terbaik untuk menyusun data?
Dengan format, dilema itu sederhana: CSV versus Microsoft Excel (tidak begitu penting, "baru" .xlsx .xls lama). Banyak orang berpikir bahwa manfaat CSV dari kesederhanaan (pada kenyataannya, ini adalah file teks biasa di mana nilai kolom dipisahkan oleh koma atau titik koma) dan kecepatan. Tapi saya memilih Excel karena dua alasan: pertama, dalam file ini Anda dapat menyimpan beberapa tabel secara bersamaan pada tab yang berbeda, dan kedua, yang lebih penting, Anda tidak perlu berpikir tentang memilih pemisah kolom yang tepat dan tempat desimal. Untuk CSV, ini seringkali harus ditulis secara manual dalam kode R dan pastikan bahwa file data disimpan dengan pengaturan yang sama.
Penataan data adalah masalah yang lebih kompleks, membutuhkan pemahaman dasar tentang bagaimana database harus diatur. Jika Anda tidak masuk ke teori database relasional tentang berbagai bentuk normal, maka Tabel data harus berlebihan, mis. Berisi kolom tambahan. Ini diperlukan agar nanti dalam skrip di R Anda dapat secara fleksibel memilih informasi tertentu untuk diproses lebih lanjut. Misalnya, jika kita ingin menggambarkan rangkaian waktu primitif, maka kita harus membuat kolom yang sesuai dengan semua karakteristik pengelompokan yang mungkin. Misalnya, jika ini adalah serangkaian pengamatan tahunan populasi kota bersyarat Severovostochinsk, maka kita akan membutuhkan kolom berikut: tahun (tahun), var (nama indikator), nilai (nilai indikator).
Kami akan memberikan input data apa pun ke gaya penyajian informasi ini.
Contoh
Tujuan: untuk membangun perbandingan dinamika volume panen di Rusia, Distrik Federal Siberia, dan Wilayah Krasnoyarsk pada 2009-2018.
Memperoleh data untuk tugas ini cukup sederhana: cari saja indikator yang sesuai dalam Sistem Informasi Antar Departemen dan Statistik Terpadu . Kehalusan datang berikutnya. Anda dapat segera mengunduh data dalam format .xlsx dan kemudian menyusunnya secara manual seperti yang ditunjukkan di atas. Untungnya, beberapa sumber informasi (misalnya, EMISS) memungkinkan Anda melakukan ini dengan kemampuan layanan itu sendiri, yang sangat menyederhanakan pekerjaan dan mengurangi waktu yang diperlukan untuk menyelesaikannya.
Jadi, untuk EMISS sudah cukup untuk masuk ke mode "Pengaturan" (tombol yang sesuai di sudut kanan atas halaman data) dan memindahkan semua tanda, kecuali untuk "Periode" dari kolom "Kolom" ke kolom "Baris". Ternyata meja itu hampir siap untuk pekerjaan kita di masa depan. Selanjutnya, sudah di Excel (atau editor lain yang cocok), masuk akal untuk membawa struktur tabel ke bentuk yang mirip dengan yang disajikan di atas dan pastikan bahwa baris pertama hanya berisi nama variabel, dengan data dalam bahasa Latin (pada prinsipnya, R dapat bekerja dengan judul berbahasa Rusia) tapi ini merepotkan saat menulis kode). Hasilnya adalah tabel seperti itu (sebuah fragmen diberikan dalam beberapa baris).
Sekarang Anda dapat memanggil logging sheet ini, menyimpan seluruh buku ke file graphs.xlsx dan pergi ke RStudio.
Kami menghubungkan perpustakaan yang diperlukan.
library(ggplot2) library(readxl) library(Cairo) library(scales) library(dplyr)
Jika jadwal sedang disiapkan untuk publikasi berbahasa Rusia, Anda harus mengkonfigurasi lokasi yang sesuai. Opsi paling modern yang akan berfungsi dalam banyak kasus, tentu saja, pengkodean UTF-8:
Sys.setlocale("LC_ALL", "ru_RU.UTF-8")
Jika sistemnya sudah tua (beberapa Windows atau Linux kuno), maka Anda harus terlebih dahulu memahami pengkodean apa yang digunakan secara default - ini bukan tugas yang sederhana, yang jauh dari tujuan artikel ini.
Sekarang Anda perlu memuat data ke dalam R.
df_logging <- read_excel("graphs.xlsx", sheet ="logging")
Opsi sheet sini menetapkan nama lembar di dalam buku kerja Excel dari mana data akan dimuat.
Kami menyusun versi paling sederhana dari jadwal yang diperlukan.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location))

Pada prinsipnya, hampir "out of the box" ternyata menjadi jadwal yang sangat layak, yang cukup cocok untuk analisis awal dari proses yang diteliti, tetapi dari sudut pandang publikasi yang mungkin, masih membutuhkan penyempurnaan yang signifikan.
Pertama, mari kita bawa gaya grafis ke gaya yang lebih akademis. Paket ggplot2 memiliki beberapa tema dasar yang sudah jadi. Tema theme_classic dapat dikenali sebagai yang paling cocok untuk kasus kami. Sebagai bagian dari konfigurasinya, Anda dapat segera mengatur ukuran dasar font dan headset-nya. Preferensi pribadi saya milik sistem font modern PT Sans, PT Serif, PT Mono . Tapi, tentu saja, Anda bisa bertanya Times atau Helvetica yang lebih klasik. Juga, publikasi di mana publikasi tersebut direncanakan dapat memiliki instruksi khusus dalam hal ini. Titik dasar ditentukan secara empiris menjadi 12 pt.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location)) + theme_classic(base_family = "PT Sans", base_size = 12)
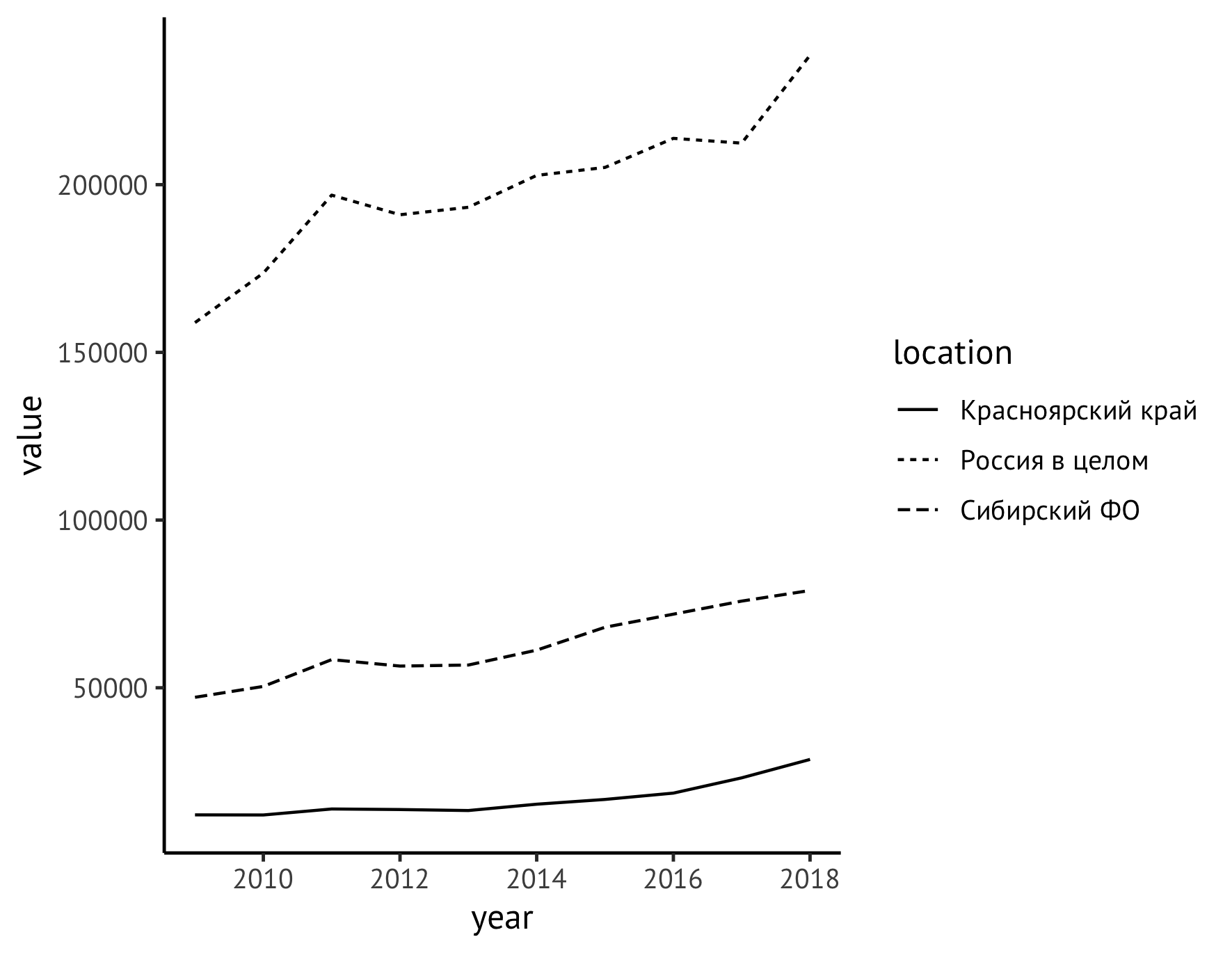
Selanjutnya, pindahkan legenda dari bidang kanan grafik ke bawah (menggunakan instruksi theme ) dan pada saat yang sama memberikan nama yang bermakna pada sumbu (instruksi labs ). Di sepanjang sumbu Y, kami menulis nama indikator dengan satuan pengukuran ("Volume penebangan, juta meter kubik"), dan menghapus label di sepanjang sumbu X sama sekali, karena jelas bahwa tahun ditandai di sana.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location)) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + labs(x = "", y = " , . . ", color="")

Untuk membuat satuan ukuran lebih nyaman untuk persepsi, kita akan bergerak dari seribu meter kubik. m hingga jutaan. Untuk melakukan ini, cukup bagi nilai-nilai dengan 1000, yaitu, sesuaikan baris pertama dari kode kami sebagai berikut:
ggplot(data=df_logging, aes(x=year, y=value/1000))
Pada saat yang sama, Anda perlu mengubah unit dalam prasasti:
labs(x = "", y = " , . ", color="")
Dan segera kami akan sedikit meningkatkan gaya gambar dengan menambahkan titik-titik untuk menunjukkan setiap nilai yang diamati, untuk itu kami akan menambahkan instruksi:
geom_point(size=2)
Anda juga dapat secara eksplisit mengatur gaya garis itu sendiri. Adalah logis untuk menjadikan indikator untuk Rusia garis yang solid, dan untuk Distrik Federal Siberia dan Wilayah Krasnoyarsk - versi intermiten yang berbeda:
scale_linetype_manual(values=c("twodash", "solid", "dotted"))
Sekarang kode umum dan grafik terlihat seperti ini:
ggplot(data=df_logging, aes(x=year, y=value/1000)) + geom_line(aes(linetype=location)) + geom_point(size=1) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + scale_linetype_manual(values=c("twodash", "solid", "dotted")) + labs(x = "", y = " , . ", color="")

Tetap menyelesaikan tugas yang lebih substantif - untuk meningkatkan konten informasi dari jadwal kami. Sekarang dapat dilihat dari itu bahwa, secara umum, indikator untuk semua objek pengamatan telah tumbuh, apalagi, sejak sekitar 2014 itu lebih kuat dari sebelumnya. Tetapi akan jauh lebih jelas jika kita menggambarkan langsung pada grafik juga nilai-nilai di tahun-tahun pertama dan terakhir dan, katakanlah, di puncak 2011. Pernyataan geom_text baru akan membantu:
geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8)
Pada pandangan pertama, itu terlihat agak rumit, dan saya harus mengatakan bahwa itu benar-benar tidak mudah untuk dirakit. Saya akan mencoba menjelaskan apa yang terjadi di sini. Dengan sendirinya, geom_text menambahkan label teks ke bagan. Untuk instruksi ini, satu set data diperlukan. Jika kami menentukan df_logging langsung di dalamnya, kami akan mendapatkan prasasti di atas setiap titik. Ini dilakukan cukup sering, tetapi untuk rangkaian waktu yang cukup sederhana seperti kita, pendekatan ini hanya akan menciptakan suara visual yang tidak perlu tanpa memberi kita informasi baru tentang perilaku indikator yang diamati. Oleh karena itu, kami hanya akan mengambil tahun-tahun yang penting untuk memahami dinamika indikator: 2009 (awal pengamatan), 2011 (puncak lokal), 2018 (akhir pengamatan). Ini akan membantu bagian standar.
Untuk tampilan angka yang benar sesuai dengan tradisi berbahasa Rusia, kita membutuhkan koma sebagai pemisah bilangan bulat dan desimal ( decimal.mark desimal), dan untuk memotong jumlah tempat desimal, instruksi digit. Berbagai eksperimen dengannya, termasuk penggunaan fungsi round , mengarah pada fakta bahwa jika kita membutuhkan satu tempat desimal, kita perlu memberikan nilai 3 ke digits .
Opsi check_overlap tidak diperlukan secara langsung di sini, tetapi dapat berguna dalam kasus lain: ini adalah kontrol otomatis label yang tumpang tindih. Opsi vjust mengontrol penempatan label secara vertikal. Nilai dipilih berdasarkan pertimbangan rasa.
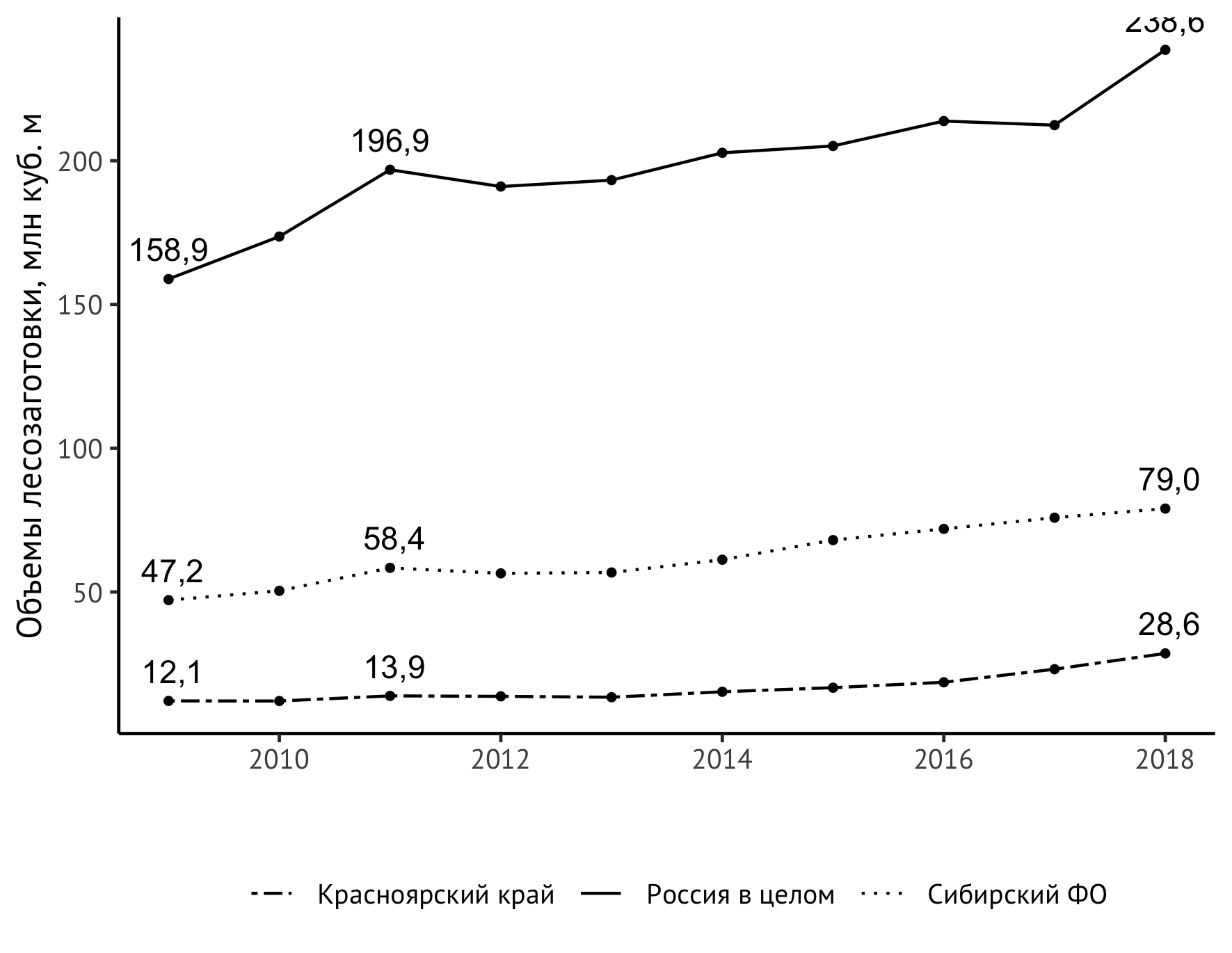
Sekarang jadwalnya benar-benar menarik untuk dipertimbangkan!
Tetapi masalah yang tidak terduga ditemukan - nilai kanan atas "dipotong" oleh ukuran vertikal gambar. Ada beberapa cara untuk mengatasi masalah ini. Saya keluar dengan sedikit bentangan skala sumbu vertikal dengan batas atas eksplisit 250 juta meter kubik. m:
scale_y_continuous(limits = c(0,250))
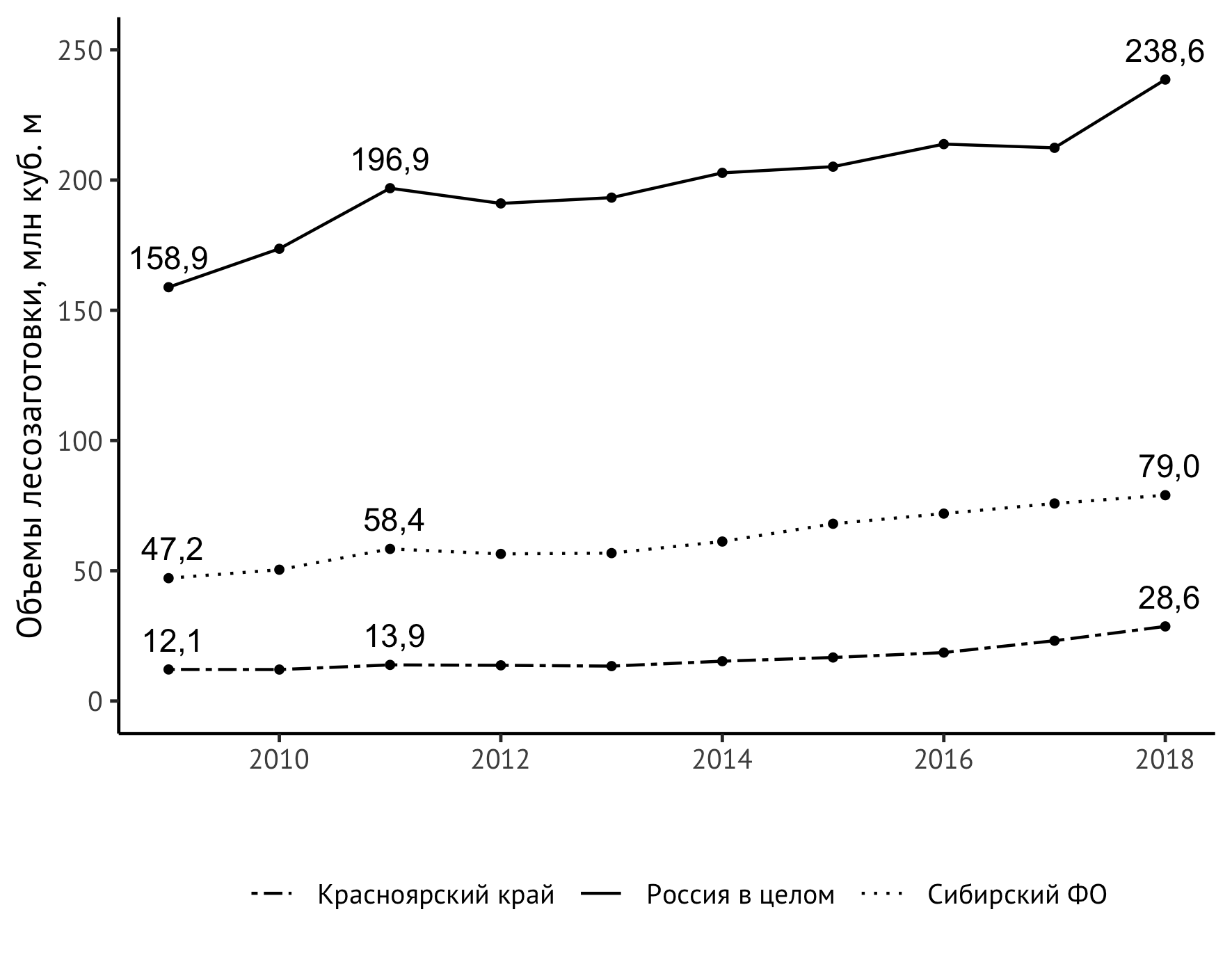
Selesai! Jadi, kode akhir terlihat seperti ini:
ggplot(data=df_logging, aes(x=year, y=value/1000)) + geom_line(aes(linetype=location)) + geom_point(size=1) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8) + geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8) + scale_linetype_manual(values=c("twodash", "solid", "dotted")) + scale_y_continuous(limits = c(0,250)) + labs(x = "", y = " , . ", color="")
Gambar yang dihasilkan dimasukkan dalam monograf: Modernisasi struktural sebagai faktor dalam meningkatkan daya saing daerah (pada contoh Wilayah Krasnoyarsk) / ed. Shishatsky N.G. - Novosibirsk: IEOPP SB RAS, 2020 (dalam publikasi).
Ekspor
Plug-in penglihatan grafik yang terintegrasi dengan RStudio memungkinkan Anda untuk mengekspor gambar dalam beberapa format tanpa perintah tambahan, hanya dalam beberapa klik. Masalahnya adalah bahwa untuk tugas-tugas praktis layanan ini praktis tidak berguna. Saat menyimpan ke format raster (.jpg, .png), pengaturan default sangat rendah, jadi ketika Anda mengimpor gambar, misalnya, di Word, itu akan kabur. Dengan vektor .eps atau .pdf, situasinya benar-benar lebih buruk: penyimpanan terjadi baik dengan kesalahan yang tidak memungkinkan membuka file, atau disimpan tanpa kemungkinan menggunakan prasasti berbahasa Rusia.
Solusinya adalah dengan menggunakan fungsi ggsave dari paket ggplot .
Jika output memerlukan file raster biasa, misalnya, dari format .png, semuanya cukup sederhana:
ggsave("logging.png", width=709, height=549, units="px")
Geometri (opsi width dan height ) dan satuan ukuran ( units ) dapat dihilangkan, tetapi kemudian secara default gambar akan diekspor persegi, yang hampir tidak nyaman. Oleh karena itu, lebih baik untuk membuat proporsi Anda sendiri dan ukuran yang diperlukan dan mengatur parameter ini secara manual, seperti yang dilakukan pada baris kode di atas.
Untuk penggunaan gambar selanjutnya dalam publikasi kertas, masuk akal untuk mengekspor gambar dalam format vektor, sehingga nantinya dalam tata letak ada kemungkinan untuk mengubah geometri gambar secara bebas. Banyak majalah lebih suka format .eps - juga nyaman untuk menggunakannya untuk ekspor ke Word. Kita akan membutuhkan driver Kairo yang sudah diinstal dan terhubung:
ggsave(filename = "export.eps", width=15, height=11.6, units="cm", device = cairo_ps)
File akan disimpan di direktori saat ini di mana skrip R berada.
Apa lagi yang harus dibaca
Literatur tentang grafik dalam R cukup banyak. Berikut adalah beberapa contoh, yang pertama adalah karya pembuat paket ggplot:
Mungkin buku terbaik dan terinci tentang grafik dalam R dalam bahasa Rusia adalah buku karya Timofei Samsonov. Visualisasi dan analisis data geografis dalam bahasa R. Ini adalah panduan terperinci yang sangat baik untuk banyak masalah umum dan khusus yang dapat diselesaikan dengan R.
Anda juga dapat merekomendasikan buku dalam bahasa Rusia tentang R secara umum:
Shitikov V.K., Mastitsky S.E. Klasifikasi, regresi, algoritma Data Mining menggunakan R. 2017 .
Contoh menarik dan memotivasi adalah presentasi yang kuat tentang penggunaan ggplot2 dalam mempersiapkan gambar untuk koran Financial Times yang berpengaruh .