Halo, Habr! Saya hadir untuk Anda terjemahan artikel "Visualisasi Model Terjemahan Mesin Neural (Mekanik Model Seq2seq Dengan Penuh Perhatian)" oleh Jay Alammar.
Model urutan-ke-urutan (seq2seq) adalah model pembelajaran mendalam yang telah mencapai sukses besar dalam tugas-tugas seperti terjemahan mesin, peringkasan teks, anotasi gambar, dll. Misalnya, pada akhir 2016, model serupa dibangun ke dalam Google Translate. Dasar-dasar model seq2seq diletakkan kembali pada tahun 2014 dengan merilis dua artikel - Sutskever et al., 2014 , Cho et al., 2014 .
Agar cukup memahami dan kemudian menggunakan model ini, beberapa konsep harus diklarifikasi terlebih dahulu. Visualisasi yang diusulkan dalam artikel ini akan menjadi pelengkap yang baik untuk artikel yang disebutkan di atas.
Model urutan-ke-urutan adalah model yang menerima urutan input elemen (kata, huruf, atribut gambar, dll.) Dan mengembalikan urutan elemen lainnya. Model yang terlatih bekerja sebagai berikut:
Dalam terjemahan mesin saraf, urutan elemen adalah kumpulan kata yang diproses secara bergantian. Kesimpulannya juga serangkaian kata-kata:
Lihatlah di bawah tenda
Di bawah tenda, model memiliki encoder dan decoder.
Encoder memproses setiap elemen dari urutan input, menerjemahkan informasi yang diterima ke dalam vektor yang disebut konteks. Setelah memproses seluruh urutan input, encoder mengirimkan konteks ke decoder, yang kemudian mulai menghasilkan elemen urutan output dengan elemen.
Hal yang sama terjadi dengan terjemahan mesin.
Untuk terjemahan mesin, konteksnya adalah vektor (array angka), dan encoder dan decoder, pada gilirannya, paling sering adalah jaringan saraf berulang (lihat pengantar untuk RNN - Pengantar ramah untuk Jaringan Syaraf Berulang ).

Konteks adalah vektor angka floating point. Lebih lanjut dalam artikel ini, vektor akan divisualisasikan dalam warna sehingga warna yang lebih terang sesuai dengan sel dengan nilai yang besar.
Saat melatih model, Anda dapat mengatur ukuran vektor konteks - jumlah neuron tersembunyi (unit tersembunyi) dalam encoder RNN. Data visualisasi menunjukkan vektor 4-dimensi, tetapi dalam aplikasi nyata, vektor konteks akan memiliki dimensi urutan 256, 512, atau 1024.
Secara default, pada setiap interval waktu, RNN menerima dua elemen untuk input: elemen input itu sendiri (dalam kasus encoder, satu kata dari kalimat asli) dan keadaan tersembunyi. Namun, kata tersebut harus diwakili oleh vektor. Untuk mengubah kata menjadi vektor, mereka menggunakan serangkaian algoritma yang disebut perkawinan kata. Embeddings menerjemahkan kata ke dalam ruang vektor yang berisi informasi semantik dan semantik tentangnya (misalnya, "raja" - "pria" + "wanita" = "ratu" ).
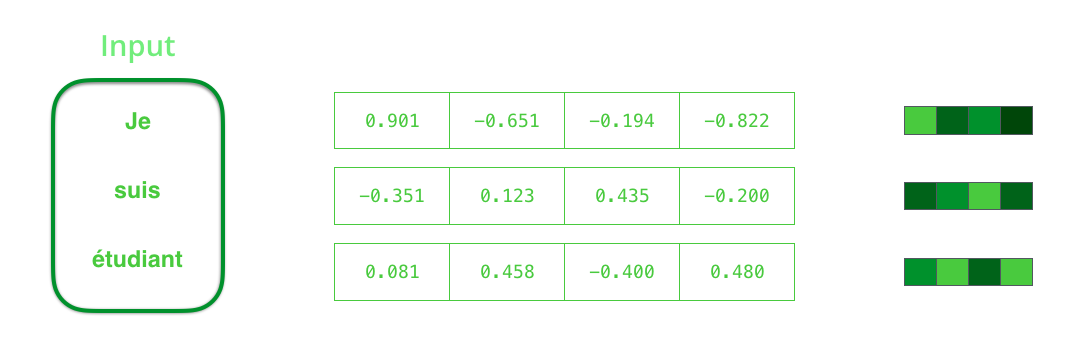
Sebelum memproses kata, Anda harus mengonversinya menjadi vektor. Transformasi ini dilakukan dengan menggunakan algoritma embedding kata. Anda dapat menggunakan embeddings pra-terlatih dan embeddings pada set data Anda. 200-300 - dimensi khas dari vektor embedding; artikel ini menggunakan dimensi 4 untuk kesederhanaan.
Sekarang setelah kami berkenalan dengan vektor / tensor utama kami, mari kita mengingat kembali mekanisme RNN dan membuat visualisasi untuk menggambarkannya:
Pada langkah berikutnya, RNN mengambil vektor input kedua dan keadaan laten # 1 untuk membentuk output pada interval waktu ini. Kemudian dalam artikel tersebut, animasi serupa digunakan untuk menggambarkan vektor di dalam model terjemahan mesin saraf.
Dalam visualisasi berikut, setiap frame menjelaskan pemrosesan input oleh encoder dan generasi output oleh decoder dalam satu interval waktu. Karena baik encoder dan decoder adalah RNN, pada setiap interval waktu, jaringan saraf sedang sibuk memproses dan memperbarui status tersembunyi berdasarkan arus dan semua input sebelumnya. Dalam kasus ini, status tersembunyi terakhir pembuat enkode adalah konteks yang dikirimkan ke dekoder.
Dekoder juga berisi status tersembunyi yang ditransfer dari satu slot waktu ke slot waktu lainnya. (Ini tidak ada dalam visualisasi, hanya menggambarkan bagian utama dari model.)
Kami sekarang beralih ke jenis visualisasi model urutan-ke-urutan lainnya. Animasi ini akan membantu untuk memahami grafik statis yang menggambarkan model-model ini - yang disebut tampilan tanpa gulungan, di mana alih-alih menunjukkan satu decoder, kami menunjukkan salinannya untuk setiap interval waktu. Jadi kita bisa melihat elemen input dan output pada setiap interval waktu.
Perhatikan!
Vektor konteks adalah hambatan untuk model jenis ini, sehingga sulit bagi mereka untuk berurusan dengan kalimat yang panjang. Solusi ini diusulkan dalam artikel oleh Bahdanau et al., 2014 dan Luong et al., 2015 , yang menyajikan teknik yang disebut mekanisme perhatian. Mekanisme ini secara signifikan meningkatkan kualitas sistem terjemahan mesin, memungkinkan model untuk berkonsentrasi pada bagian yang relevan dari urutan input.
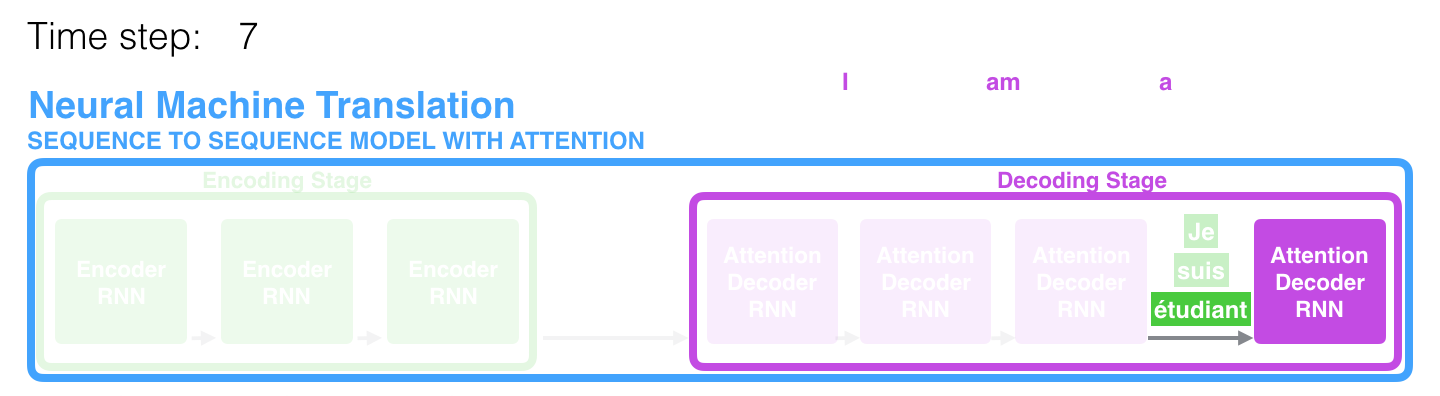
Dalam rentang waktu ke-7, mekanisme perhatian memungkinkan dekoder untuk fokus pada kata étudiant (siswa dalam bahasa Prancis) sebelum menghasilkan terjemahan ke dalam bahasa Inggris. Kemampuan ini untuk memperkuat sinyal dari bagian yang relevan dari urutan input memungkinkan model berdasarkan mekanisme perhatian untuk mendapatkan hasil yang lebih baik dibandingkan dengan model lain.
Ketika mempertimbangkan model dengan mekanisme perhatian pada abstraksi tingkat tinggi, dua perbedaan utama dari model urutan-ke-urutan yang klasik dapat dibedakan.
Pertama, encoder mentransfer lebih banyak data secara signifikan ke decoder: alih-alih hanya mentransmisikan status tersembunyi terakhir setelah tahap penyandian, encoder mengirimkan semua status tersembunyi ke dalamnya:
Kedua, decoder melewati langkah tambahan sebelum menghasilkan output. Untuk fokus pada bagian-bagian dari urutan input yang relevan untuk rentang waktu yang sesuai, decoder melakukan yang berikut:
- Melihat seperangkat status laten yang diterima dari pembuat enkode - masing-masing status laten berkorelasi paling baik dengan salah satu kata dalam urutan input;
- Tetapkan penilaian tertentu untuk setiap keadaan laten (jangan abaikan sekarang bagaimana prosedur estimasi terjadi);
- Mengalikan setiap kondisi tersembunyi dengan fungsi evaluasi yang dikonversi softmax, sehingga menyoroti status tersembunyi dengan peringkat besar dan menurunkan status tersembunyi dengan yang kecil ke latar belakang.
“Latihan penilaian” ini dilakukan pada dekoder pada setiap interval waktu.
Jadi, meringkas semua hal di atas, kami mempertimbangkan proses model dengan mekanisme perhatian:
- Pada dekoder, RNN menerima penyematan <END> token dan status tersembunyi awal.
- RNN memproses elemen input, menghasilkan output, dan vektor keadaan tersembunyi baru (h4). Outputnya dibuang.
- Mekanisme perhatian menggunakan status tersembunyi pembuat enkode dan vektor h4 untuk menghitung vektor konteks (C4) pada interval waktu tertentu.
- Vektor h4 dan C4 digabungkan menjadi satu vektor.
- Vektor ini dilewatkan melalui feedforward neural network (FFN), dilatih bersama dengan model.
- Output dari jaringan FFN menunjukkan kata output pada interval waktu tertentu.
- Algoritma diulang untuk interval waktu berikutnya.
Cara lain untuk melihat bagian kalimat mana yang menjadi fokus model di setiap tahap dekoder:
Perhatikan bahwa model tidak hanya menghubungkan kata pertama pada input dengan kata pertama pada output. Dia benar-benar mengerti selama proses pelatihan bagaimana mencocokkan kata-kata dalam pasangan bahasa yang dianggap ini (dalam kasus kami, Prancis dan Inggris). Contoh seberapa akurat mekanisme ini dapat bekerja dapat ditemukan di artikel tentang mekanisme perhatian yang disebutkan di atas.

Jika Anda merasa siap mempelajari cara menerapkan model ini, lihat manual Terjemahan Mesin Saraf (seq2seq) di TensorFlow.
Penulis